1. Introduction
The concept of excess losses is widely used in reinsurance and retrospective insurance rating. The mathematics of it has been studied extensively in the property and casualty insurance literature. See, for example, Lee (1988) and Halliwell (2012). The first moment of the excess losses has been tabulated into the Table of Insurance Charges (Table M) for use in the NCCI retrospective rating plan. Higher moments of excess losses can be used to measure the volatility of excess losses. However formulas for them are not readily available in the property casualty actuarial literature. One could refer to Section 2 of Miccolis (1977) for some discussions. In fact, the formulas for calculating higher moments of excess losses do exist in the literature of stochastic orders, where the nth moment of excess losses is named the nth order stop-loss transform (see, for example, Hürlimann 2000). Therefore, in the first part of this paper, we introduce the simple formulas for calculating higher moments of the excess losses to the property casualty actuarial literature. More importantly, using a detailed numerical example, we show that the higher moments can be obtained directly from Table M.
In the second part of this paper, we introduce the concept of bivariate excess losses, which has its origin in the reliability theory literature. See, for example, Zahedi (1985) and Gupta and Sankaran (1998). In the context of stochastic ordering, Denuit, Lefevre, and Shaked (1998) presented a formula for the joint moments of multivariate excess losses. In this paper, we show that the joint moments of bivariate excess losses can be computed through methods similar to the ones used in the univariate case. We provide examples to illustrate possible applications of bivariate excess loss functions.
The remaining parts of the paper are organized as follows. Section 2 introduces formulas for higher moments of excess losses and show how they may be computed using Table M. Section 3 presents the theory of bivariate excess losses. Section 4 provides examples and Section 5 concludes.
2. Univariate excess losses
We begin by introducing some notations and basic facts.
2.1. Preliminaries
Let X be a random loss variable taking non-negative values and have cumulative distribution function F and survival function S. Then the limited loss up to a retention level d is defined by
Xd0={X if X≤dd if X>d
The loss in the layer (d, l) is defined by
Xld=Xl0−Xd0={0 if X≤dX−d if d<X≤ll−d if X>l
The excess loss over a limit d is defined by
X∞d=(X−d)+=X−Xd0={0 if X≤dX−d if X>d
It is well known that the expected value of the limited loss is given by (see, for example, Lee 1988)
E(Xd0)=∫d0S(u)du
Due to the importance of (1), we next give a short proof of it. The method used in the proof can be readily extended to the bivariate situation.
Proof: First of all, it is easy to verify that
Xd0=∫d0I(X>u)du
where I(.) is an indicator function that is equal to one when its arguments are true and zero otherwise. Then we have that
E[Xd0]=E[∫d0I(X>u)du]=∫d0E[I(X>u)]du=∫d0S(u)du.
Because Xld = Xl0 − Xd0, we have for the layered losses that
Xld=∫ldI(X>u)du
and
E[Xld]=∫ldS(u)du
For the excess losses,
E[X∞l]=∫∞lS(u)du
2.2. Higher moments of excess losses
Higher moments of the excess loss Xl∞ can be obtained using the following Proposition.
Proposition 2.1. Let
R1(l)=E[X∞l]
and for i ≥ 1, let
Ri+1(l)=∫∞lRi(u)du
Then
Ri(l)=1i!E[(X∞l)i], for i≥1
The proof of the proposition was obtained in Denuit, Lefevre, and Shaked (1998) and Hrlimann (2000), and it is included here for the completeness of this paper.
Proof:
We use mathematical induction. For i = 1, Equation (6) is true by definition. Assume that it is true for i, then
Ri+1(l)=∫∞lRi(u)du=∫∞l1i!E[(X−u)i+]du=1i!E[∫∞l(X−u)i+du]
=1(i+1)!E[(X−l)i+1+]=1(i+1)!E[(X∞l)i+1]
If the distribution of the underlying loss X is known, then one could compute [(Xl∞)k] for any integer k using Proposition 2.1 iteratively. More importantly, we point out that since Table M in fact lists values of R1(l), one may compute Rk(l), k > 1 directly from it recursively, in a similar fashion as one would compute R1(l) from the survival function S(l). This way, [(Xl∞)k], k ≥ 1 can be obtained directly from Table M. We next show the method with a numerical example.
Consider problem 4 of Brosius (2002). Let X represent the loss ratio for a homogeneous group of insureds; it is observed to have values 30%, 45%, 45% and 120%, respectively. Let Y = X/ (X) be the corresponding entry ratios and thus take values 0.5, 0.75, 0.75, 2. Table M, constructed using the method described in Brosius (2002), gives the mean excess loss function of Y:
R1(r)=E[Y∞r]
Then the second moment of the excess losses [(Xl∞)2] may simply be obtained by numerically integrating R1(r) and multiplying the result by 2. Realizing that R1(r) is piecewise linear between entry ratio values, the numerical integration is implemented by
R2(r)=∑k≥0R1(r+kΔ)+R1(r+(k+1)Δ)2Δ
where Δ is the interval between entry ratio values.
Table 1 shows the details of the calculation. The third column is the Table M charge, the fourth column (R2 in layer), corresponding to an entry ratio r, is calculated by where Δ is the interval between entry ratios, which is 0.25 in the example. The fifth column (R2(r)) is the cumulative summation of the fourth column. The last column is just the fifth one multiplied by 2.
This example shows the important fact that the higher moments of the excess losses can be obtained directly from Table M. No other information is needed!
The second moment of the layered losses [(Xdl)2] is also of interest. We have
E[(Xld)2]=E[(X∞d−X∞l)2]=E[(X∞d)2]+E[(X∞l)2]−2E[(X∞d)(X∞l)]=E[(X∞d)2]+E[(X∞l)2]−2E[(Xld+X∞l)(X∞l)]=E[(X∞d)2]−E[(X∞l)2]−2E[(Xld)(X∞l)]
The first two terms of (8) can be obtained from Table M, as shown in the previous example. The last term can again be obtained from Table M by applying Equation (12) derived in Section 3.
3. Bivariate excess losses
Let (X, Y) be a pair of random loss random variables with joint distribution function F(x, y) = P (X ≤ x, Y ≤ y) and joint survival function S(x, y) = P (X > x, Y > y).
Similar to Formula (2) for the univariate case, we have the following formula for the first joint moment of the layered losses Xl~x~dx~~ and Yl~y~dy~~.
Proposition 3.1.
E[XlxdxYlydy]=∫lxdx∫lydyS(u,v)dvdu.
Proof: As in (2.1), first notice that
XlxdxYlydy=∫lxdxI(X>u)du∫lydyI(Y>v)dv=∫lxdx∫lydyI(X>u)I(Y>v)dvdu.
Then we have
E[XlxdxYlydy]=∫lxdx∫lydyE[I(x>u)I(y>v)]dvdu=∫lxdx∫lydyS(u,v)dvdu
With this, the covariance between and is given by
Cov(Xlxdx,Ylydy)=∫lxdx∫lydyS(u,v)dvdu−∫lxdxSx(u)du∫lydySy(v)dv,
where Sx and Sy denote the marginal survival function of X and Y respectively. A somewhat similar formula can be found in Dhaene and Goovaerts (1996).
As shown in Denuit, Lefèvre, and Mesfioui (1999), higher joint moments of the bivariate excess losses can be computed using the following result.
Proposition 3.2.
Let
R11(lx,ly)=∫∞lx∫∞lyS(u,v)dvdu
and for (i, j) > (1, 1), let
Rij(lx,ly)=∫∞lxRi−1,j(u,ly)du=∫∞lyRi,j−1(lx,v)dv
Then,
Rij(lx,ly)=1i!j!E[(X∞lx)i(Y∞ly)j]
Proof:
We again use mathematical induction. For i = j = 1, the statement is true by Proposition 3.1. Assume that it is true for i, j, then
Ri+1,j(lx,ly)=∫∞lxRi,j(u,ly)du=∫∞lx1i!j!E[(X−u)i+(Y−ly)j+]du=1i!j!E[(Y−ly)j+∫∞lx(X−u)i+du]=1(i+1)!j!E[(X−lx)i+1+(Y−ly)j+]
The derivation for Ri,j+1(lx, ly) is symmetric. ■
Similar to Section 2, Proposition 3.2 can be used to construct a bivariate Table M to tabulate the joint moments of the bivariate excess losses. Example 4.2 in the next section provides an illustration.
In the rest of this section, we show that Proposition 3.2 may shed some light on the joint moments of the amount in different layers of a random loss. To this end, setting X = Y, we have
S(u,v)=P[X>u,Y>v]=P[X>max(u,v)]=Sx(max(u,v))
where Sx(.) denotes the survival function for X. Then for two non-overlapping layers (d1, l1) and (d2, l2) of X with d2 ≥ l1, we have
\begin{aligned} \mathbb{E}\left[X_{d_{1}}^{l_{1}} X_{d_{2}}^{l_{2}}\right] & =\int_{d_{1}}^{l_{1}} \int_{d_{2}}^{l_{2}} S(u, v) d v d u \\ & =\int_{d_{1}}^{l_{1}} \int_{d_{2}}^{l_{2}} S_{x}(v) d v d u \\ & =\left(l_{1}-d_{1}\right) \mathbb{E}\left[X_{d_{2}}^{l_{2}}\right] . \end{aligned} \tag{12}
As a result, the covariance of and is given by
\operatorname{Cov}\left[X_{d_{1}}^{l_{1}} X_{d_{2}}^{l_{2}}\right]=\left(l_{1}-d_{1}-\mathbb{E}\left[X_{d_{1}}^{l_{1}}\right]\right) \mathbb{E}\left[X_{d_{2}}^{l_{2}}\right], \tag{13}
which is Equation (39) of Miccolis (1977).
As mentioned in Section 2.2, Formula (12) is useful in computing the second moment of layered losses Xld. In fact, applying it to (8) yields
\small{ \mathbb{E}\left[\left(X_{d}^{l}\right)^{2}\right]=\mathbb{E}\left[\left(X_{d}^{\infty}\right)^{2}\right]-\mathbb{E}\left[\left(X_{l}^{\infty}\right)^{2}\right]-2(l-d) \mathbb{E}\left[X_{l}^{\infty}\right] } \tag{14}
Notice that all three terms on the right-hand side of (14) can be obtained from Table M.
Another formula to compute the second moment of the layer losses is:
\begin{aligned} \mathbb{E}\left[\left(X_{d}^{l}\right)^{2}\right] & =\int_{d}^{l} \int_{d}^{l} S(u, v) d v d u \\ & =2 \int_{d}^{l} \int_{d}^{u} S(u, v) d v d u \\ & =2 \int_{d}^{l} \int_{d}^{u} S(u) d v d u \\ & =2 \int_{d}^{l}(u-d) S(u) d u \end{aligned}
from which we may write
\begin{aligned} \mathbb{E}\left[\left(X_{d}^{l}\right)^{2}\right] & =2 \int_{d}^{l}(u-d) S(u) d u \\ & =-2 \int_{d}^{l}(u-d) d R_{1}(u) \\ & =-\left.2(u-d) R_{1}(u)\right|_{u=d} ^{l}+2 \int_{d}^{l} R_{1}(u) d u \\ & =2\left(R_{2}(l)-R_{2}(d)-(l-d) R_{1}(l)\right) \end{aligned} \tag{15}
which agrees with Equation (14).
4. Numerical examples
In this section, we present three examples. In the first example, we derive formulas for the joint moments of excess losses for a bivariate Pareto distribution. In the second example, we show that a bivariate Table M can be constructed to tabulate the covariances between layers of losses from two lines of businesses. In the third example, we apply the formulas derived herein to study the interactions between per-occurrence and stop-losses limits when they coexist in an insurance policy.
Example 1: Bivariate Pareto Distribution
Following Wang (1998), assume that there exists a random parameter Λ such that for i = 1, 2, Xi | Λ = λ are independent and exponentially distributed with rate parameter Then the conditional joint survival function is given by
S_{X_{1}, X_{2} \mid \Lambda=\lambda}\left(x_{1}, x_{2}\right)=e^{-\lambda\left(\frac{x_{1}}{\theta_{1}}+\frac{x_{2}}{\theta_{2}}\right)}
Assume that Λ follows a Gamma (α, 1) distribution with moment generating function MΛ(t) = (1 − t)−α. Then the unconditional distribution of (X1, X2) is a bivariate Pareto with the joint survival function
S(x, y)=\left(1+\frac{x}{\theta_{1}}+\frac{y}{\theta_{2}}\right)^{-\alpha} \tag{16}
As an extension of univariate Pareto distributions, bivariate Pareto distributions are useful in modeling bivariate losses with heavy tails. From the joint survival function (16), we have that
\begin{aligned} \mathbb{E}\left(X_{d_{x}}^{l_{x}} Y_{d_{y}}^{l_{y}}\right)= & \int_{d_{x}}^{l_{x}} \int_{d_{y}}^{l_{y}}\left(1+\frac{x}{\theta_{1}}+\frac{y}{\theta_{2}}\right)^{-\alpha} d y d x \\ = & \frac{\theta_{1} \theta_{2}}{(\alpha-1)(\alpha-2)}\left(\left(1+\frac{d_{x}}{\theta_{1}}++\frac{d_{y}}{\theta_{2}}\right)^{-\alpha+2}\right. \\ & \left.-\left(1+\frac{l_{x}}{\theta_{1}}++\frac{l_{y}}{\theta_{2}}\right)^{-\alpha+2}\right) \end{aligned}
In addition, the next equations are easily obtained and will be used in the following example.
\mathbb{E}\left(X_{l}^{\infty}\right)=\frac{\theta_{1}}{(\alpha-1)}\left(1+\frac{l}{\theta_{1}}\right)^{-\alpha+1}
\mathbb{E}\left(X_{l_{x}}^{\infty} Y_{l_{y}}^{\infty}\right)=\frac{\theta_{1} \theta_{2}}{(\alpha-1)(\alpha-2)}\left(1+\frac{l_{x}}{\theta_{1}}+\frac{l_{y}}{\theta_{2}}\right)^{-\alpha+2},
and
\begin{aligned} \mathbb{E}\left[\left(X_{l}^{\infty}\right)^{2}\right] & =2 \int_{l}^{\infty}(x-l)\left(1+\frac{x}{\theta_{1}}\right)^{-\alpha} d x \\ & =\frac{2 \theta_{1}^{2}}{(\alpha-1)(\alpha-2)}\left(\frac{\theta_{1}+l}{\theta_{1}}\right)^{-\alpha+2} . \end{aligned}
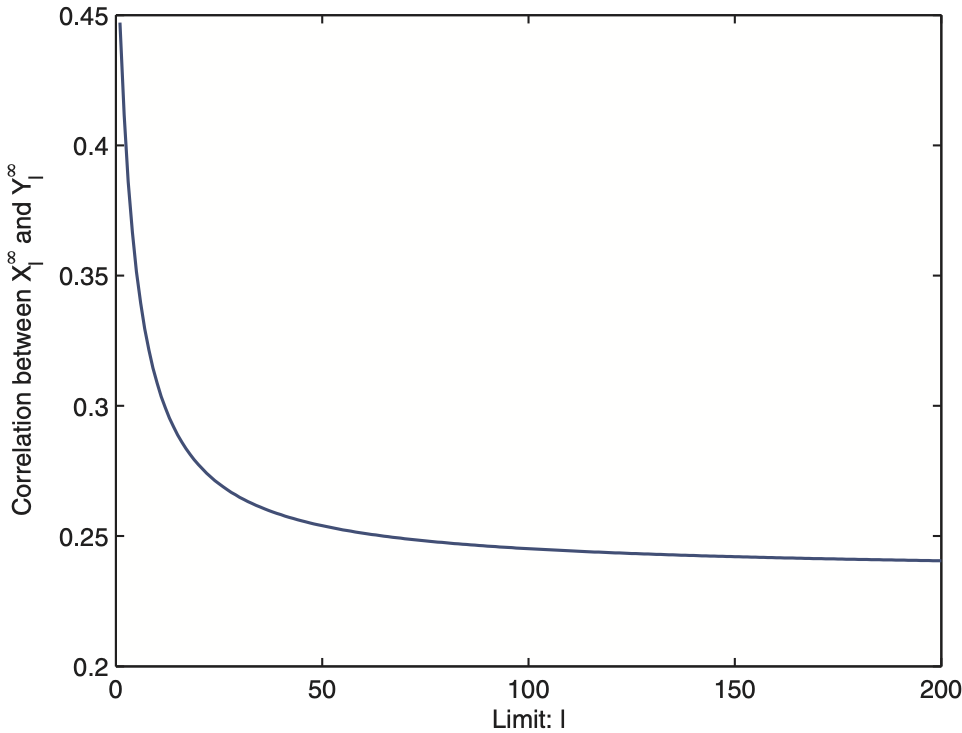
One might wonder how the dependence between (Xl∞) and (Yl∞) varies with the retention level l. For illustration, we assume that α = 3, θ1 = 5, θ2 = 10 and calculated the correlation coefficients between Xl∞ and Yl∞
\operatorname{corr}\left(X_{l}^{\infty}, Y_{l}^{\infty}\right)=\frac{\mathbb{E}\left(X_{l}^{\infty} Y_{l}^{\infty}\right)-\mathbb{E}\left(X_{l}^{\infty}\right) \mathbb{E}\left(Y_{l}^{\infty}\right)}{\sqrt{\operatorname{Var}\left(X_{l}^{\infty}\right) \operatorname{Var}\left(Y_{l}^{\infty}\right)}}
for different values of l. The relationship between the correlation coefficients and the retention level l is illustrated in Figure 1. It shows that for this particular joint distribution, the correlation coefficient decreases to some limit as the retention level l increases.

Example 2: A bivariate Table M
This example shows that a bivariate Table M can be constructed for the bivariate excess losses in a similar way to the univariate Table M.
Assume that one observes a sample of a pair of bivariate loss ratio random variables (X, Y) as shown in Table 2.
To compute the joint moments of the bivariate excess of losses (X∞dx~~Y∞dy~~), we basically need to construct their empirical joint survival function and then numerically implement the double integration in Equation (9). The detailed steps are shown in a companion Excel table (http://www.variancejournal.org/issues/10-02/Exel-table-Ren-paper.xlsx). The Excel table is easy to use, for example, [X∞dx~~Y∞dy~~] is simply given by the value in column J and the row with loss ratio values dx and dy. If it is desired to calculate the higher joint moments of X∞dx~~ and Y∞dy~~, one can proceed to do some more numerical integrations in the spreadsheet.
Example 3: Per-occurrence and stop-loss coverage
This example follows the one in Section 2 of Homer and Clark (2002) with some modifications. Assume that the size of Workers Compensation losses from a fictional large insured ABC, denoted by Z, follow a Pareto distribution with the survival function
S(x)=\left(1+\frac{x}{\theta}\right)^{-\alpha}
where α = 3 and θ = $100,000. Assume that the number of losses N follows a negative binomial distribution with the probability generating function (see, for example, Klugman, Panjer, and Willmot 2012)
P_{N}(z)=(1-\beta(z-1))^{-r} \text {, }
where β = 0.2 and r = 25.
An insurance company, XYZ, has been asked to provide a per-occurrence coverage of $50,000 excess of d0 and then a stop-loss coverage on an aggregate basis of $500,000 excess of d1.
As an actuary of XYZ, you are trying to determine an optimal combination of d0 and d1, so that your objective function—the ratio between the expected payments and the standard deviation of the payments—is maximized. Notice that the expected payments can be considered as a proxy for the expected underwriting profits assuming a risk loading level, and the standard deviation of the payments of course may represent the risk level. Therefore, the objective function bears some resemblance to the Sharpe ratio (Bodie, Kane, and Marcus 2010) used in portfolio analysis.
We introduce the following notations to mathematically describe the problem. The monetary unit we use is in thousands of dollars. Let the amount that ABC has to pay per occurrence be denoted by
Z_{A}=Z_{0}^{d_{0}}+Z_{d_{0}+50}^{\infty}
Let the amount that XYZ has to pay per occurrence be denoted by
Z_{X}=Z_{d_{0}}^{d_{0}+50}
Let
V=\sum_{i=1}^{N} Z_{X, i}
denote the aggregate amount that XYZ pays for the per-occurrence coverage and let
U=\sum_{i=1}^{N} Z_{A, i}
be the aggregate amount ABC pays after the per-occurrence coverage but before the stop-loss coverage. Then the total amount XYZ has to pay under the insurance treaty is given by
W=V+U_{d_{1}}^{l_{1}}
where l1 = d1 + 500.
Our goal is to select values of d0 and d1 so that the objective function where stands for the standard deviation of W, is maximized.
To solve the problem, we could apply the following steps:
-
Assign some values to d0 and d1.
-
Construct a matrix containing the joint probability distribution function of (U, V). This can be obtained by applying the bivariate fast Fourier transform (FFT) method as proposed in Homer and Clark (2002).
-
Construct a matrix for the joint survival function, S(U,V), from the matrix for the joint probability function obtained in step 2. Construct two vectors containing values for the marginal survival functions SU and SV, respectively.
-
Construct vectors containing values of the functions R1(l) and R2(l) for random variables U and V by applying Equations (4) and (5) to the corresponding survival functions SU and SV. Then compute [V], [Ul~1~d
1], [V2], and [(Ul~1~d1)2] using Equations (6) and (15). -
Construct a matrix containing values of the function R11 from S(U,V) using Equation (10) and compute [Ul~1~d
1V] by applying (11). -
Compute the mean and variance of W = Ul~1~d
1+ V using quantities obtained in steps 4 and 5, then evaluate the objective function -
Repeat steps 1–6 for different values of d0 and d1 and compare the values of the objective function.
Tables 3, 4, and 5 shows values of [W], and the objective function for some combinations of d0 and d1, respectively. It appears that when the per-occurrence entry point d0 is low and the stop-loss coverage entry point d1 is high, the objective function is maximized. In addition, the tables can be used to detect inefficient combinations of d0 and d1. For example, the (d0, d1) = (250, 1000) combination results in lower expected losses but a higher standard deviation than the (d0, d1) = (200, 1500) combination. Therefore, the former is inefficient.
Conclusions
We first showed that higher moments of excess losses may be obtained from Table M. Then we showed that the joint moments of bivariate excess losses can also be obtained in a similar fashion. These techniques are useful in reinsurance and retrospective insurance rating when losses from two sources of risks are considered.