

1. Introduction
Sequential statistical methods refer to data that are collected in real time. The sample size is not fixed in advance. At any moment, either a decision is taken, or it is deferred until more data become available. For example, when a statistical hypothesis is tested sequentially, after each new observation, either the null hypothesis is rejected, or it is accepted, or no decision is made at this point and sampling continues (e.g., Wald 1947; Govindarajulu 2004; Tartakovsky, Nikiforov, and Basseville 2014).
Actuaries routinely make decisions that are sequential in nature (e.g., Tse 2009). During each insured period, the new claims and losses data are collected, and together with the new economic and financial situation and other factors, they are taken into account for the calculation of revised premiums and risks. For all the policyholders, several decisions are made regularly, at least once per each insured period: whether the coverage should continue, whether the coverage should be changed, and what premium should be charged.
Conventional methods tend to ignore the facts of sequentially developing data and recurrence of actuarial decisions. They use nonsequential statistical procedures that are based on the assumption of only one statistical inference that will not be repeated. This leads to lower than nominal confidence levels and higher than nominal probabilities of Type I and Type II errors. That is, the probability of committing an error at least once during repeated tests is substantially higher than the nominal level of each test. Controlling these errors at the specified levels is one of the benefits of the proposed sequential methodology.
One important sequential problem is testing an insured cohort for full credibility. Credibility estimation combines the real data R and the hypothetical prior information H and uses a compromise estimator
C=ZR+(1−Z)H
where Z is the credibility factor. Assigning full credibility, Z = 1, means that the real data about a cohort are deemed sufficient for decision making, without referring to other sources of information. When the real data are not sufficient, partial credibility is used according to (1.1). Compromise estimators of type (1.1) are widely used for the estimation of pure premium, a part of the total premium, the expected amount that the insurer will have to pay to cover the policyholder’s losses during the next insured period. The resulting estimator is also called credibility premium. Let us further refer to Bühlmann (1970), Bühlmann and Gisler (2005), and Herzog (2004) for foundations of credibility; and Klugman, Panjer, and Willmot (2012) and Venter (1990) for the current status of credibility theory and practice.
When does a cohort deserve full credibility? This can be determined, among other methods, by the classical limited fluctuation credibility approach. According to that approach, the cohort is fully credible if its total loss S is likely to fall within a desired margin from its expected value E(S), the pure premium, namely,
P{|S−E(S)|≤cE(S)}≥1−q.
Under the aggregate loss frequency-severity model (Klugman, Panjer, and Willmot 2012), widely used in actuarial science, condition (1.2) for full credibility can take a simple form of hypothesis testing. The model assumes X losses during the insured period, and thus the total loss amount S is the sum of a random number X of losses with severities Y1, . . . , YX,
S=X∑i=1Yi
Assumptions
We assume a Poisson number of losses X with the frequency parameter λ = E(X). For the Poisson distribution, λ also equals Var (X). The loss amounts are assumed independent of each other and independent of the number of losses, with expected value and variance E(Yi) = μ and Var(Yi) = σ2. Under this model, E(S) = λμ, Var(S) = λ(σ2 + μ2), and the standardized total loss (S – E(S))/Std(S) has approximately standard normal distribution, provided that the number of losses is sufficient for normal approximation (Herzog 2004; Klugman, Panjer, and Willmot 2012; also see Hossak, Pollard, and Zehnwirth 1983; Longley-Cook 1962).
In view of this standardization, condition (1.2) becomes equivalent to inequality
c√λ√1+γ2≥zq/2
where γ = σ/μ is the coefficient of variation of individual losses (severity parameter), and zq/2 is the (1 – q/2)th standard normal quantile.
Condition (1.3) is a statistical hypothesis that is being tested every insured period in order to decide on the full credibility. Conducting this test each time at a nominal level of 5% does not guarantee that the probability of at least one wrong decision is within 5%. For example, there is a probability of 1 – (1 – 0.05)10 40% that a Type I error is made at least once during the course of 10 independent periods, when the probability of Type I error during each period is only 5%.
For this reason, we develop a sequential method for testing for full credibility. It specifies a stopping time, when full credibility can be awarded to a cohort, simultaneously controlling for the probability of Type I error (assigning full credibility to a cohort that does not deserve it) and the probability of Type II error (assigning only a partial credibility whereas the full credibility should be given). As a practical result, precise criteria are derived under which an insured cohort becomes fully credible.
For some cohorts, full credibility can be granted at an early stage; for others, at a later stage. But regardless of the time, the proposed sequential tests control the probability of Type I error at a specified level α and the probability of Type II error at a specified level β. In other words, the probability that a cohort with insufficient credentials is (by a sampling error) considered fully credible is controlled at the desired level throughout the entire time of data collection and decision making.
A sequential test for full credibility is developed in Section 2 as an application of classical sequential methods to credibility theory. Examples of using the new tool under the popular loss models are shown in Section 3. Proposed methods are then applied to the data generated by the Actuarial Loss Simulator in Section 4. Section 5 contains summary and conclusions, and all the lengthy proofs are found in Section 6.
2. Derivation of the sequential test
In this section, a level α sequential test for full credibility is derived. As shown in Section 1, the limited fluctuation condition for full credibility is equivalent to inequality (1.3), and thus, when deciding between the full and partial credibility, an actuary needs to conduct a test of
H0:cη≤zq/2−δ vs HA:cη≥zq/2
where is the tested parameter of interest, and a region of indifference of length δ separates the null and alternative hypotheses. An insured cohort is considered fully credible when there is sufficient evidence in the data that condition (1.3), equivalent to HA, is satisfied.
The sequential test of (2.1) is derived through a series of steps. First, parameter η is estimated by a statistic Tn that is based on the first n time periods of observation. This statistic is shown to have an asymptotically normal distribution for any n. For most of the loss models, the distribution of Tn contains unknown nuisance parameters which affect its variance only. In this case, the problem reduces to testing the location parameter of a normal distribution with unknown variance, and the sequential t-test (Govindarajulu 2004, sec. 3.2; Tartakovsky, Nikiforov, and Basseville 2014, sec. 3.6.2) is applied.
2.1. Test statistic and its distribution
We assume that the claim and loss data are collected for a large insured cohort over a sequence of days (weeks, months). During day k, a random number of claims Xk is observed, with random loss amounts The typical actuarial frequency-severity model assumes that the claims occur at random times, according to a Poisson process with intensity λ = E(Xk) claims per day, whereas the losses Ykj are independent variables that follow distribution FY(y) with expected value μ = E(Ykj), variance σ2 = Var(Ykj), and coefficient of variation γ = σ/μ, independently of claim times.
Based on the observed claim frequencies and severities over days, parameter is estimated by
Tn=√ˆλn√1+ˆγ2n=√ˉXn√1+s2n/ˉY2n
Here parameters λ, μ, and σ are estimated at time n by the corresponding sample statistics available by that time, namely, Xn, the average frequency or the average number of claims per time period; Yn and sn, the sample mean and sample standard deviation of severity.
This yields a sequence of statistics T1, T2. . . . Besides their main purpose of testing (2.1), they can also be used for estimating the partial credibility factor Z = cη/zq/2 by Zn = cTn/zq/2. This factor is applied to the compromise estimation of the pure premium when H0 is not rejected, and only partial credibility is assigned.
Next, we show that statistic Tn has asymptotically normal distribution under mild assumptions on the frequency and severity distributions.
Suppose that the frequency variables Xk and the severity variables Ykj are not degenerate for k = 1, . . . , n and j = 1, . . . , Xk; Ykj is not a multiple of a Bernoulli random variable; E(Xk2) ∞; and E(Ykj4) ∞.
Then, as n → ∞, statistic Tn is asymptotically normal, and
√n(Tn−η)d→Normal(0,VT), as n→∞,
where
VT=μ24μ2+μ22−μμ3μ22+μ2(μ4−μ22)4μ32
and μm = E(Ymkj) are non-central moments of the severity distribution for m = 2, 3, 4.
The proof of this result is deferred to the Appendix.
Two important conclusions follow from the form of Tn and its asymptotic variance.
The distribution of Tn is free of a scale parameter of the loss distribution.
One can see that by noticing that each fraction in (2.3) has its numerator and denominator of the same dimension. This is expected because parameter η, estimated by Tn, depends on the loss distribution only through its coefficient of variation γ. In particular, Corollary 1 implies that our decision on full credibility is independent of the currency in which the losses Ykj are valuated.
The second conclusion is important for the practical implementation of the proposed sequential scheme. In typical actuarial data, a large portion of loss amounts are entered as zeros (Sect. 8.6 of Klugman, Panjer, and Willmot 2012). In particular, this phenomenon is observed in the data obtained from the Actuarial Loss Simulator in Section 4. Zero payments are often caused by the claims exceeding policy limits or not meeting deductibles, and also by wrong coding or repeatedly submitted claims.
Allowing for a considerable probability of a zero loss clearly affects the modeling of both severities and frequencies. None of the common actuarial loss models (gamma, Pareto, log-gamma, log-normal, Burr, etc.) accounts for such a large number of zeros. Fortunately, the introduced test statistic Tn is independent of the inclusion of zero losses. According to the next corollary, these losses can simply be deleted from the data when the test for full credibility is conducted.
Let X̃k be the actual number of claims during the k-th time period and Xk be the number of claims excluding zero losses (Ykj = 0) for all k. Consider statistics and where γ̃n and γ̂n are the sample coefficients of variation based on all the observed severities and based on the no-zero severities only. Then P{T̃n = Tn} = 1 for all n.
This result follows immediately from an alternative expression for statistic Tn given below.
Statistic can also be expressed as
Tn=1nn∑k=1Xk∑j=1Ykj/√1nn∑k=1Xk∑j=1Y2kj
the average loss per day normalized by the root of the total of squared losses per day.
The proof is given in the Appendix. Clearly, all Ykj = 0 can be simply dropped in (2.4) without affecting any sums, and Corollary 2 follows. Lemma 1 is also used in the proof of Theorem 1.
2.2. Sequential scheme
Based on the asymptotically normal distribution of test statistic Tn, a sequential test for full credibility is developed in this section. The proposed procedure follows the ideas of Wald’s sequential probability ratio test, or SPRT (Wald 1947; Govindarajulu 2004; Tartakovsky, Nikiforov, and Basseville 2014). This test is based on the -likelihood ratio where represents a vector of all the data collected by the time To attain the Type Ierror probability and the Type II error probability the stopping boundaries and are then introduced, with the following sequential decisionmaking strategy (Fig. 1). Sampling continues as long as When sampling stops, and is rejected in favor of When sampling stops, and is not rejected. For a test of simple hypotheses, when does not contain unknown parameters, this SPRT guarantees the Type I and Type II error probabilities of and

Suppose for a moment that the distribution of Tn is free of nuisance parameters. It happens, for example, when the loss model is parameterized only by a scale parameter, according to Corollary 1. In this case, the SPRT statistic for testing (2.1) is
Λn=Λ(n,δ,t)=lnfTn(t∣HA)fTn(t∣H0)=n2VT{(t−zq/2−δc)2−(t−zq/2c)2}
where t is the value of Tn observed at time n.
Now turn to the general case of an arbitrary loss distribution. As seen in Theorem 1, additional parameters can affect the asymptotic variance but not the mean of Tn. To handle nuisance parameters, Wald (1947) proposed the method of weight functions w(θ), integrating both components of the likelihood ratio with respect to the unknown parameter θ,
\Lambda_{n}=\frac{\int f\left(\boldsymbol{x}_{n} \mid H_{A}\right) w(\theta) d \theta}{\int f\left(\boldsymbol{x}_{n} \mid H_{0}\right) w(\theta) d \theta}
Then, the same stopping boundaries a and b (Fig. 1) control the integrated Type I and Type II error probabilities, namely,
\begin{array}{c} \int \boldsymbol{P}\left\{\text { reject } H_{0} \mid \theta, H_{0}\right\} w(\theta) d \theta=\alpha, \\ \int \boldsymbol{P}\left\{\text { do not reject } H_{0} \mid \theta, H_{A}\right\} w(\theta) d \theta=\beta \end{array} \tag{2.6}
Applying this approach to our case of a normally distributed statistic with an unknown variance, a sequential t-test is detailed in Govindarajulu (2004, Sect. 3.2). This method essentially follows Wald’s SPRT with a special choice of a constant weight function w(θ) = 1 on θ (0, h). Letting h → ∞ yields the test statistic
\begin{aligned} \Lambda_{n} & =\ln \lim _{h \rightarrow \infty} \frac{\int_{0}^{h} f_{T_{n}}\left(t \mid \theta, H_{A}\right) d \theta}{\int_{0}^{h} f_{T_{n}}\left(t \mid \theta, H_{0}\right) d \theta} \\ & =\ln \lim _{h \rightarrow \infty} \frac{\int_{0}^{h} \frac{1}{\sqrt{V_{T}(\theta)}} \exp \left(-\frac{\left.\left(t-\frac{z_{q / 2}}{c}\right)^{2}\right)}{2 V_{T}(\theta) / n}\right) d \theta}{\int_{0}^{h} \frac{1}{\sqrt{V_{T}(\theta)}} \exp \left(-\frac{\left(t-\frac{z_{q / 2}-\delta}{c}\right)^{2}}{2 V_{T}(\theta) / n}\right) d \theta} . \end{aligned} \tag{2.7}
As we shall see in Section 3, the limit in (2.7) can often be taken by the L’Hôpital’s Rule, erasing both integrals. Multiple integrals appear in the case of a multidimensional nuisance parameter θ.
Based on Λn, one makes a decision according to the rule,
\left\{\begin{array}{ll} \text { Reject } H_{0} \text { in favor of } H_{A} & \text { if } \Lambda_{n} \geq a=\ln \frac{1-\beta}{\alpha} \\ \text { and assign full credibility, } & \text { if } \Lambda_{n} \leq b=\ln \frac{\beta}{1-\alpha} \\ \text { Accept } H_{0} \text { and assign } & \text { if } \Lambda_{n} \in(b, a) \\ \begin{array}{ll} \text { pontinue observation and credibility, } \\ \text { defer decision. } \end{array} \end{array}\right. \tag{2.8}
Until Λn exits from the interval (b, a) (which eventually happens with probability 1), the null hypothesis (2.1) is neither rejected nor accepted. During this time, the final decision is deferred, and the partial credibility factor estimated by Ẑ = cTn/zq/2 is used. The same factor is applied if H0 is finally accepted, and the partial credibility is assigned.
According to Wald (1947), testing scheme (2.8) attains
\begin{array}{c} \boldsymbol{P}\left\{\text { Type I error } \mid c \eta=z_{q / 2}-\delta\right\}=\alpha \\ \text { and } \quad \boldsymbol{P}\left\{\text { Type II error } \mid c \eta=z_{q / 2}\right\}=\beta \end{array} \tag{2.9}
Here the Type I error occurs when full credibility is given to a cohort that does not deserve it, and the Type II error means not giving full credibility where it is deserved.
Probabilities α and β are to be chosen before the test. This choice affects the test accuracy as well as the time it will take to reach a decision. For example, choosing smaller α and/or β results in lower probabilities of making a Type I or a Type II error. At the same time, smaller α and β result in wider stopping boundaries a and b, according to (2.8), expanding the continue-sampling region. Thus, it will generally take longer for the statistic Tn to reach the boundaries. Then, a decision will be based on a larger sample, increasing its accuracy, in terms of lower error probabilities.
When the method of weight functions is used in the presence of nuisance parameters, the probabilities in the right-hand sides of (2.9) are understood in the integral form (2.6), which can also be interpreted as probabilities under the joint distribution of data and nuisance parameters.
3. Implementation for common loss distributions
In this section, the introduced sequential testing scheme is elaborated for commonly used loss models (Klugman, Panjer, and Willmot 2012)—Poisson number of losses Xk and exponential, gamma, log-normal, Pareto, or Weibull loss amounts Ykj. Each example requires calculating the asymptotic variance VT according to Theorem 1, using it in the likelihood ratio statistic (2.5) or (2.7), and stating the sequential decision rule in terms of Λk or Tn statistics, according to (2.8).
3.1. Example 1: Exponential and Weibull loss models
As a special and simple case, consider the exponential loss distribution. It is special because the asymptotic variance VT appears free of nuisance parameters (by Corollary 1). Indeed, when Ykj ∼ exponential (θ), the moments are E(Ykjm) = m!θm. Substituting them into (2.3), we obtain VT = 1/4 for any θ.
By (2.5), the SPRT statistic in this case is
\begin{aligned} \Lambda_{n} & =2 n\left(\left(T_{n}-\frac{z_{q / 2}-\delta}{c}\right)^{2}-\left(T_{n}-\frac{z_{q / 2}}{c}\right)^{2}\right) \\ & =\frac{4 n \delta}{c} T_{n}-\frac{4 n \delta z_{q / 2}}{c^{2}}+\frac{2 n \delta^{2}}{c^{2}}, \end{aligned}
with stopping boundaries {b, a}. That is, sampling continues while
b<\frac{4 n \delta}{c} T_{n}-\frac{4 n \delta z_{q / 2}}{c^{2}}+\frac{2 n \delta^{2}}{c^{2}}<a .
Solving for Tn, we obtain the stopping boundaries for the statistic Tn,
\left\{\frac{b c}{4 n \delta}+\frac{z_{q / 2}}{c}-\frac{\delta}{2 c}, \frac{a c}{4 n \delta}+\frac{z_{q / 2}}{c}-\frac{\delta}{2 c}\right\}
When Tn attains the upper stopping boundary, the cohort is considered fully credible. If it attains the lower boundary, only partial credibility is assigned. Between the boundaries, the decision about the full credibility is deferred until one of the boundaries is crossed.
Similarly, the asymptotic variance VT is constant for any Weibull distribution with a known shape parameter. For example, when Ykj ∼ Weibull (θ, 1/2), the mth moment is μm = θmΓ(1 + 2m), which leads to VT = 17/12 and the SPRT statistic
\Lambda_{n}=\frac{12 n \delta}{17 c} T_{n}-\frac{12 n \delta z_{q / 2}}{17 c^{2}}+\frac{6 n \delta^{2}}{17 c^{2}}
Reject H0 and give full credibility after n insured periods when Λn ≥ a, or, equivalently,
T_{n} \geq \frac{17 a c}{12 n \delta}+\frac{z_{q / 2}}{c}-\frac{\delta}{2 c}
3.2. Example 2: Gamma loss model
Extending the exponential model, let Ykj ∼ gamma (r, θ), with the mth moment μm = E(Ym) = θmΓ(r + m)/γ(r). Substituting these moments into (2.3) and simplifying, we obtain
V_{T}=\frac{r^{2}+r+2}{4(1+r)^{2}}
As stated by Corollary 1, the asymptotic variance of Tn is free of the scale parameter of the underlying gamma loss distribution; however, it contains the nuisance shape parameter r. It can be seen that both integrals in (2.7) diverge to ∞ as h → ∞, justifying application of the L’Hôpital’s Rule. Then, taking the limit as h → ∞, we obtain the same formula as for the exponential distribution,
\Lambda_{n}=\frac{4 n \delta}{c} T_{n}-\frac{4 n \delta z_{q / 2}}{c^{2}}+\frac{2 n \delta^{2}}{c^{2}}
and again, H0 is rejected and full credibility is given after n insured periods if
T_{n} \geq \frac{a c}{4 n \delta}+\frac{z_{q / 2}}{c}-\frac{\delta}{2 c} .
3.3. Example 3: Log-normal loss model
For Ykj ∼ log-normal (μ, σ), the mth moment is μm = exp(mμ + m2σ2/2), and from (2.3),
V_{T}=1-e^{\sigma^{2}}+\frac{1}{4} e^{3 \sigma^{2}}
In this case, both integrals in (2.7) converge as h → ∞, so that the nuisance parameter θ = σ2 is being integrated out with the improper prior Then the sequential probability ratio test statistic is
\Lambda_{n}=\frac{\int_{0}^{\infty}\left(1-e^{\theta}+e^{3 \theta} / 4\right)^{-1 / 2} \cdot \exp \left\{-\frac{n}{2} \frac{\left(t-\frac{z}{c}\right)^{2}}{1-e^{\theta}+e^{3 \theta} / 4}\right\} d \theta}{\int_{0}^{\infty}\left(1-e^{\theta}+e^{3 \theta} / 4\right)^{-1 / 2} \cdot \exp \left\{-\frac{n}{2} \frac{\left(t-\frac{z-\delta}{c}\right)^{2}}{1-e^{\theta}+e^{3 \theta} / 4}\right\} d \theta}
In this case, there is no simple closed form for the stopping boundary for Tn; however, the inequality b Λn a can be solved for Tn numerically.
3.4. Example 4: Pareto loss model
For the Pareto (r, θ) loss distribution, the mth moment is μm = θmΓ(m + 1)Γ(r – m)/Γ(r). Substituting into (2.3), we obtain the asymptotic variance
V_{T}=1-\frac{3}{4} \frac{(r-2)(r-6)}{(r-3)(r-4)}
and by the L’Hôpital’s Rule, the same test statistic
\Lambda_{n}=\frac{4 n \delta}{c} t-\frac{4 n \delta z_{q / 2}}{c^{2}}+\frac{2 n \delta^{2}}{c^{2}}
as in the gamma case. Thus, full credibility should again be assigned as soon as
T_{n} \geq \frac{a c}{4 n \delta}+\frac{z_{q / 2}}{c}-\frac{\delta}{2 c} .
Table 1 summarizes the stopping boundaries for test statistic Tn (the stopping boundary for Tn does not have a closed form in the case of a log-normal distribution). These are conditions that allow to assign full credibility.
4. Analysis of actuarial data
In this section, we apply the developed sequential techniques to the actuarial data generated by the CAS Public Loss Simulator. This simulator was written by Goouon under a research agreement with the Casualty Actuarial Society (CAS) and was made publicly available at http://www.goouon.com/loss_simulator_project.html. It generates data sets close to the real data by simulating all the features usually observed in actuarial records.
Below, we discuss four data sets that are generated in order to illustrate situations leading to different decisions on the full credibility. In these examples, we consider a single-payment model, where each loss event is shortly followed by valuation that results in either no payment or one payment. The probability of no payment is set to p0 = 0.2, which means that roughly 20% of submitted claims are denied. As we know from Corollary 2, the test is independent of the appearance of zero losses in the data. The simulated insured records start on 01/01/2000 and continue for the next 12 years, with the insurance contract being renewed and premium being revised once a year. At these times of renewal, the credibility decisions are to be made.
Claim frequencies Xk are Poisson, and the non-zero loss amounts Ykj are generated from gamma and Pareto distributions. The limited fluctuation criterion (1.2) for full credibility is applied with the relative precision c = 0.1 and probability q = 0.05, and the corresponding hypothesis is tested with the indifference margin δ = 0.02. With these parameters, test (2.1) reduces to testing
H_{0}: \eta \leq \frac{z_{q / 2}-\delta}{c}=19.4 \quad \text { vs } \quad H_{A}: \eta \geq \frac{z_{q / 2}}{c}=19.6 \tag{4.1}
Thus, whether a cohort deserves full credibility is determined by the unknown parameter Its sequential estimator Tn and the corresponding stopping boundaries are calculated according to Equation (2.2) and Table 1, and the sequential test is conducted for each data sequence resulting in a definite decision on full credibility.
4.1. Gamma loss model
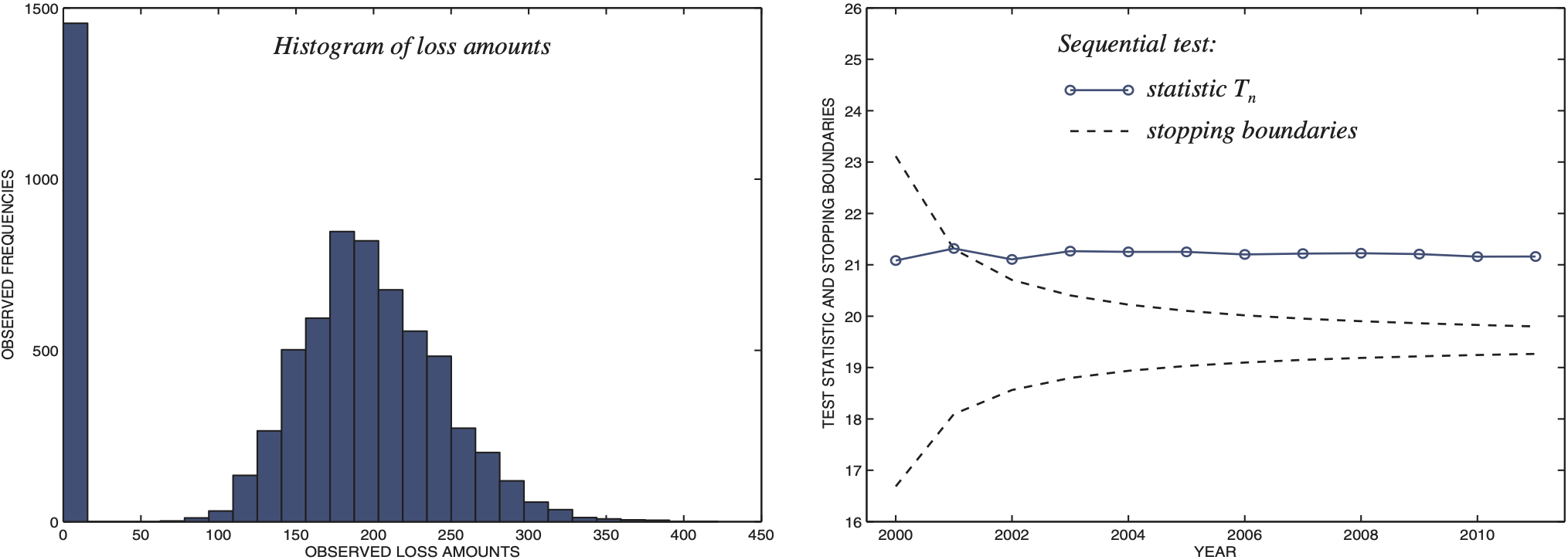
We start by generating a 12-year record of gamma distributed losses with shape parameter r = 20, scale parameter θ = 10 (average claim μ = $200), and the frequency of λ = 600 claims per year, 20% of which are not covered. This results in η = 21.4, high enough to support full credibility, according to the limited fluctuation credibility approach.
The histogram of observed losses is on Fig. 2, where a tall column on the left reflects a large portion of uncovered claims (Ykj = 0). As we anticipated, the null hypothesis is rejected, claiming full credibility. The test statistic Tn converges to the true value of η = 21.4, supporting the result of Theorem 1, and quickly exceeds the upper rejection boundary. At this time (in 2001, two years after signing the first contract), the null hypothesis is rejected, and full credibility is assigned.

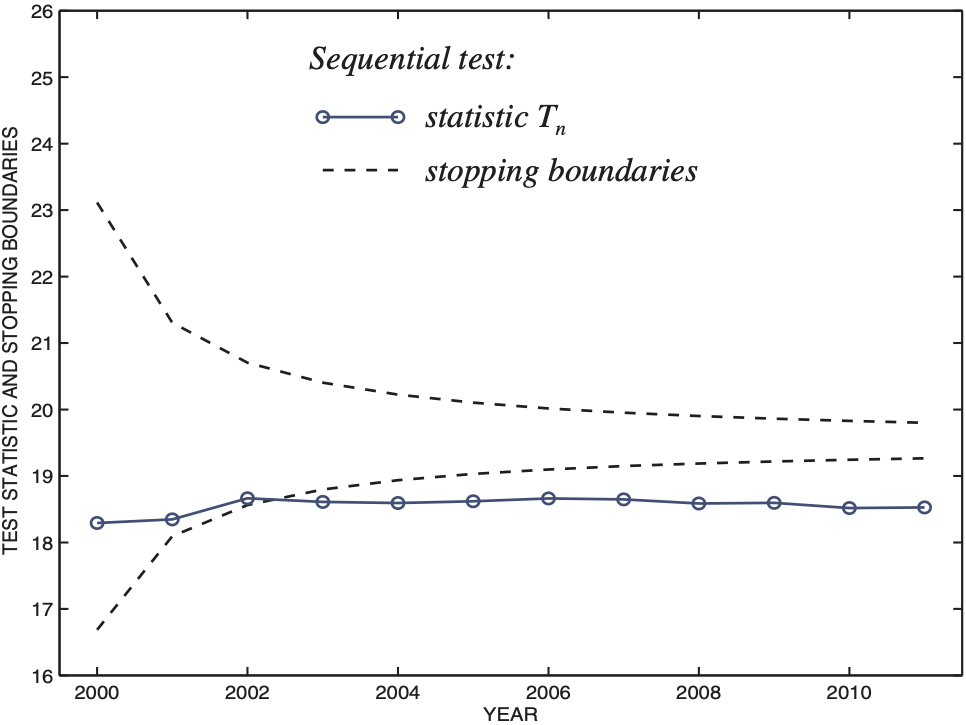
Should fewer claims occur per year, their frequency may be insufficient for the full credibility even if the loss distribution is the same. In the next simulation, the loss model is still gamma(r = 20, θ = 10), however, the frequency is only λ = 450 claims per year, of which 20% are not covered.
Based on this data, the test statistic Tn converges to the new value of η = 18.5, crossing the lower stopping boundary, as on Fig. 3. Hence, after three years of no decision, the full credibility is finally denied in 2003 due to a significance evidence of insufficient frequency of claims. Partial credibility will then be assigned with the credibility factor estimated by Ẑ2003 = cT2003/zq/2 = 0.949.

4.2. Pareto loss model, heavy tail
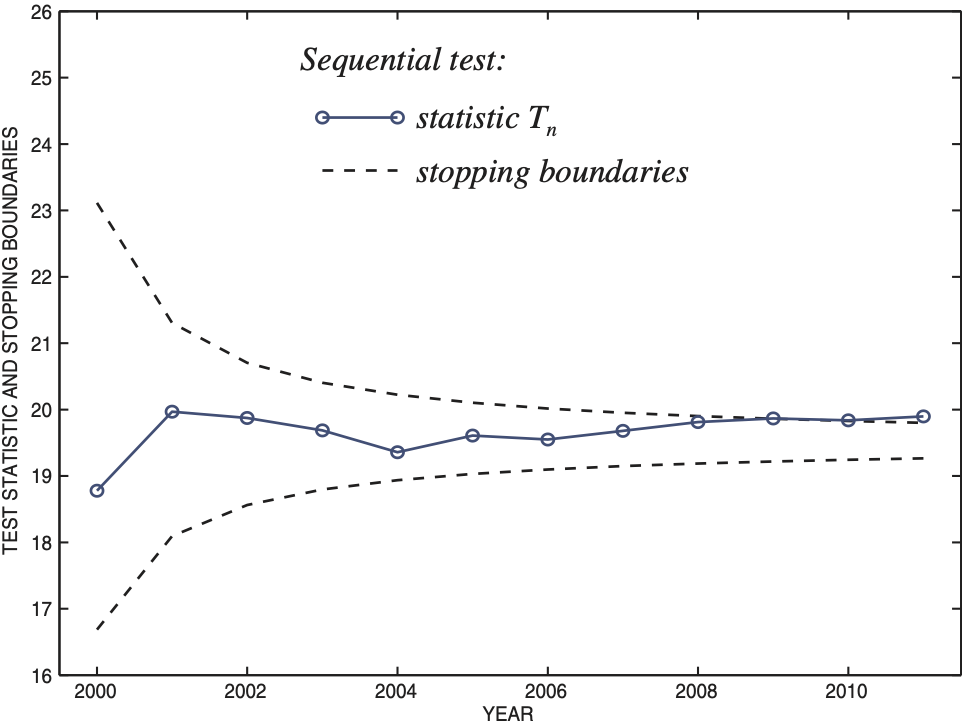
How will the test results of Section 4.1 change if we replace the gamma loss model with a heavy-tail distribution, say, Pareto? In this section, we again generate 12 years of claims, 01/01/2000 through 12/31/2011. As in our first example (Fig. 2), the frequency of claims is λ = 600 per year, 20% of them are not covered, and the average covered claim amount is μ = $200. The only difference is that now the loss distribution is Pareto(r = 5, θ = 800) instead of gamma. Notice that under this model, E(Ykj) = θ/(r – 1) matching the gamma(20,10) expected value; however, the standard deviation is much higher due to the heavy tail, compared to gamma’s
The heavy-tail loss distribution implies a higher variability of the real data, so the limited fluctuation criterion for full credibility is no longer satisfied with the same frequency of claims. Parameter η = 13.4 is much lower than the tested value in (4.1). As a result, full credibility is denied at the first opportunity (Fig. 4), and partial credibility is applied with the credibility factor Ẑ2000 = cT2000/zq/2 = 0.60. Due to high variability of loss amounts, only 60% of the compromise estimator of the pure premium is based on the actually observed data, and the remaining 40% have to come from other sources such as the prior distribution.

Recall that with the same frequency of claims and the same average loss, the full credibility was quickly awarded in the example on Fig. 2, where losses had gamma distribution.
With Pareto losses, the frequency of claims should be more than twice higher in order to satisfy the condition for full credibility. In Fig. 5, the frequency is λ = 1300 claims per year, and again 20% of claims are denied. This is almost the minimum λ required for full credibility, as the parameter η = 19.75 barely agrees with the alternative hypothesis HA. As a result of this borderline η, it takes ten years until 2009 before the decision is made and full credibility is finally applied.

In all the considered examples, our scheme, with sequentially estimated parameters and sequentially re-tested hypotheses (2.1), eventually agreed with the standard limited fluctuation credibility approach that assumes known parameters. However, since the frequency and severity parameters are in practice estimated from the data, results can differ, and a Type I or a Type II error can occur. Probabilities of that are controlled by (2.9).
5. Conclusion
This paper introduces sequential methods in actuarial science. It is motivated by a number of routine decisions that actuaries make at regular time intervals, based on sequentially collected data. Using elementary statistical tools without accounting for multiple tests, the error rate increases with the number of decisions made and considerably exceeds the nominal significance level of each test. On the other hand, applying properly designed sequential techniques, one can control the error rate at the specified level. Level α and power (1 – β) sequential tests for full credibility are derived in this paper. As a result, conditions are determined under which an insured cohort becomes fully credible, according to the limited fluctuation credibility approach. A stopping rule is derived when the sequential test for full credibility rejects the null hypothesis, in which case full credibility can be assigned.
Although the introduced method is elaborated for credibility assessment, sequential methods in general and the proposed method of handling nuisance parameters can be applied to other areas. In any situation when a decision is made as soon as the data collected to the moment shows significant evidence, one should be looking for proper sequential methods in order to control the overall error rate.
Acknowledgments
Support of this research by The Casualty Actuarial Society is greatly appreciated.