

1. Introduction
In the current property and casualty insurance practice, actuaries often need to predict the value of a future claim based on data from previous claims. They do so by first specifying a statistical model for claims depending on some unknown parameters, learning about the parameters in some specified way based on the observed claim data, and then converting this fitted model into a predictive distribution for the future claim. This process of predicting a future claim can be carried out in a variety of ways, some discussed below, but there is an issue of practical importance lurking behind the scenes. In most applications, many candidate models can be fitted to the observed claim data, but the actuary will not be sure of which one to use. Standard practice is to pick one of the candidate models, maybe by using one of the many model selection tools available in the statistical literature, treat the selected model as if it were certain, and proceed with model fitting and prediction as usual. Since the distribution theory used to derive properties of the predictive distribution assumes a fixed model, there is reason to be concerned that these properties may fail if the data are used to select a model. Prediction errors can adversely affect the insurer’s pricing, potentially hurting its profitability; they can also lead to insufficient reserves and hence jeopardize the insurer’s solvency. Therefore, the prediction risk is a serious concern to both the insurer and the regulator. Motivated by this fact, the goal of this paper is to assess the effects of model uncertainty and selection on the quality of the predictive distribution. While we choose a regression model as a main vehicle for our presentation, the issue under consideration and our conclusion carry over to actuarial model selection in general.
In the extant actuarial science literature, parameter and model uncertainty has received some attention; see, e.g., Cairns (2000); Peters, Shevchenko, and Wüthrich (2008); Hartman and Groendyke (2013); Bignozzi and Tsanakas (2016); Huang, Hartman, and Brazauskas (2016); and Venter and Sahasrabuddhe (2016). The present paper is different in that its focus is on the effect of model selection. Only recently have the potentially devastating effects of selection on inference been noted in the statistical literature, so bringing these issues to the attention of actuaries is important and of general interest. We will conduct our investigation in the context of prediction because accurate prediction is a crucial task for all actuaries, and even in the statistics literature there has been virtually no work (except Kabaila 1995 and Leeb 2009) concerning the effect of model selection on the validity of predictive distributions for future loss variables and their corresponding prediction intervals.
A variety of model selection criteria are available to actuaries, such as the Akaike information criterion (AIC), the Bayesian information criterion (BIC), Sp, and Mallows’ Cp, to name a few. Essentially, each model selection criterion can be classified as either “consistent” or “conservative.” For a conservative model selection criterion, such as the AIC, Cp, and Sp, the probability of selecting an incorrect model is asymptotically 0, while for a consistent model selection criterion, such as the BIC and the description length criterion, the probability of selecting the most parsimonious correct model is asymptotically 1. Kabaila (1995) shows that if a consistent model selection criterion is used, then the resulting predictive intervals will not obtain the correct coverage, even asymptotically. Virtually no similar work has been done to investigate the effect of selection on the predictive interval; one exception is Leeb (2009), who develops a selection tool based on a version of cross-validation and rigorously proves that the corresponding prediction intervals are approximately valid. However, Leeb’s approximate validity result holds only when either (1) the dimension p is large compared with n, or (2) p is not large but n is unrealistically large; see his proposition (4.3) (Leeb 2009). Therefore, we conclude that Leeb’s method is not satisfactory for the typical case, in which actuaries face relatively small p and moderate n. In view of the above-mentioned result in Kabaila (1995), investigation along this line should be made using conservative model selectors. The present investigation focuses primarily on selection based on the AIC criterion. But limited investigations using lasso and stepwise selection procedures reveal similar conclusions.
The remainder of the paper is organized as follows. Section 2 gives a brief review of the classical theory of prediction in regression. Section 3 is devoted to reviewing some of the investigations in the statistical literature on the effect of model selection on inference. Next, in Section 4, we shift our focus to the effect of model selection on prediction. There, based on our numerical investigations of the available statistical tools for the cases of practical relevance to actuaries and on the real-life dangers of prediction errors, we conclude that the best strategy for making valid predictions is to use the full model, i.e., not to carry out a variable selection step using a model selector. Finally, Section 5 concludes the paper with several remarks and open questions. R code for implementing the simulation study in this paper can be found at https://www4.stat.ncsu.edu/~rmartin.
2. Prediction in regression
Property and casualty actuaries often need to model the relationship between the loss (response) variable, Y, and a set of rating (predictor) variables, X1, . . . , Xp. For example, in personal auto insurance, Y might be the claim amount (or a transformation thereof) and X1, . . . , Xp might include driver age, education level, gender, income, marital status, vehicle model, territory, etc. (see, e.g., Werner and Modlin 2010). Once the model is fully specified and the relationship between the X and Y variables is known, then actuaries can use this model to predict the value of a new loss, Ỹ, corresponding to a new set of values, x̃1, . . . , x̃p, of the rating variables. For an introduction to these regression models, see Frees (2010); Frees, Derrig, and Meyers (2014); and the references therein. For concreteness, and because it is the most widely used, we will focus our attention on the standard linear regression model,
Y=Xβ+σε,
where Y is the n-vector of loss variables, X is the n × p matrix of rating variables, e is an n-vector of independent and identically distributed (iid) standard normal errors, β is the p-vector of regression coefficients, and σ > 0 is the scale parameter; if the model includes an intercept term, then the first column of X consists of an n-vector of 1s. The points we make in this paper, however, are not unique to this simple linear model. Indeed, the same conclusions would apply to, say, generalized linear models (McCullagh and Nelder 1989; de Jong and Heller 2008) among others, but the arguments and calculations would be less transparent for the more complex models.
In the remainder of this section, we review the classical theory of prediction in the linear regression model, but with a slight twist. According to equation (4.6) in Frees (2010), if the goal is to predict a future claim Ỹ, corresponding to a vector of rating variables x̃, possibly different from those in our model (2.1), a 100(1 − α)% prediction interval is
˜xTˆβ±tn−p(α/2)ˆσ{1+˜xT(XTX)−1˜x}1/2,
where tν(α) denotes the upper αth quantile of the Student t-distribution with ν degrees of freedom. If we denote this prediction interval as Cα(Y), omitting the dependence on X and x̃, then we say that the prediction interval is valid in the sense that
P{Cα(Y)∋˜Y}=1−α,
where the probability is with respect to the joint distribution of (Y, Ỹ) under model (2.1). In other words, validity means that the actual prediction coverage of Cα(Y) equals the nominal level 1 − α. To summarize this result over all values of α simultaneously, we can construct a predictive distribution for Ỹ, given Y, which has a density function given by
πY(˜y)={1+˜xT(XTX)−1˜x}−1/2×fn−p(˜y−˜xTˆβ{1+˜xT(XTX)−1˜x}1/2),
where fν is the density function corresponding to a Student t-distribution with ν degrees of freedom, and again, we suppress the dependence on X and x̃ in the notation. Then the 100(1 − α) % prediction interval described above is exactly the 1 − α highest predictive density interval corresponding to πY(ỹ). We will use this predictive density primarily for visualization purposes in what follows.
3. Effects of model selection on inference
Inference and prediction based on model (2.1) and the least squares distribution theory is standard, but the actuary often will not know which of the rating variables X1, . . . , Xp are relevant to explaining the variation in loss Y; in other words, the actuary may want to consider which of the coefficients βj, j = 1, . . . , p are 0. To facilitate this discussion, it will help to expand a bit on the usual notation. Rewrite the parameter β as a pair (S, βS), where S ⊆ S: = {1, 2, . . . , p} is the model, i.e., the set of indexes, j, corresponding to nonzero βj, and βS is the corresponding |S|-vector of nonzero values. This expanded notation helps to make clear that S might also be uncertain, which is not easily reflected in (2.1).
Established approaches for dealing with an uncertain model, such as the AIC (Akaike 1973) and the BIC (Schwarz 1978), first use the data to select a suitable model, say Ŝ, and then estimate the corresponding parameter, βŜ, via least squares as usual (see, e.g., Frees 2010, Chapter 5). An alternative to AIC and BIC is the least absolute shrinkage and selection operator, or lasso (Tibshirani 1996), which attempts to estimate simultaneously the pair (S, βS); a recent reference on lasso in the actuarial science literature is Duncan, Loginov, and Ludkovski (2016), and a detailed summary of its many variants is given in Hastie, Tibshirani, and Friedman (2009). While AIC, BIC, lasso, forward stepwise, and others are simple and widely used, some concerns are often overlooked.
Our focus here is on the so-called selection effect; i.e., using the data first to select a model, Ŝ, will affect the distribution theory for the least squares estimators, which may invalidate inference and/or prediction. Here we give an example to illustrate the potentially serious problems that may arise; a different example, with a similar message, can be found in Lockhart et al. (2014). As a first step in a regression analysis, one often will carry out a full F-test to determine whether any of the coefficients βj, j S, for a fixed S ⊆ S, are statistically significant (see, e.g., Frees 2010, Chapter 4, and de Jong and Heller 2008, Chapter 4). Under the null hypothesis that all the coefficients are 0, the p-value for the F-test will have a Unif(0,1) distribution. But, as discussed above, standard practice is to use data to help select a candidate model, say Ŝ. Here we consider a choice of Ŝ based on the AIC criterion; this is easy to implement using the R function regsubsets provided in the leaps package (Lumley 2009). What happens when the F-test is applied after model selection via AIC? Is the distribution of the p-value still Unif(0,1)?
To investigate this question, we carry out a simulation study. Let the rating variables X1, . . . , Xp be iid N(0,1), and let β1 = . . . = βp = 0, so that the null hypothesis is true no matter what model is selected; here we take p = 10 and n = 50. For each data set, we select a model based on the AIC, carry out the F-test as usual on the selected model, and evaluate the p-value. We repeat this process for 250 data sets. Figure 3.1 plots the empirical distribution function of the F-test p-value. While different repetitions may not yield selected models with the same number of predictors, and therefore the reference F distribution under the null hypothesis may be different for different repetitions, the p-values are uniformly distributed under any of the null distributions, and therefore transforming the test statistic at each repetition into a p-value allows for comparing the distribution of the classical F-test null p-values with their actual distribution post-selection. The classical theory suggests that this empirical distribution function should match that of Unif(0,1), the diagonal line in the plot, but clearly it does not. The p-values after selection are stochastically considerably larger than Unif(0,1), so that the classical F-test, applied post-selection, is not valid.

The effect of model selection on inference is a serious concern, and it has become something of a hot topic in the statistics literature in recent years; important references include Benjamini et al. (2005), Leeb and Pötscher (2005, 2006, 2008), Berk et al. (2013), Efron (2014), Fithian (2015), and Taylor and Tibshirani (2015, 2017). Aside from identifying issues that arise as a result of model selection, there are important questions about what the inferential target even is, post-selection. The aforementioned papers address some of these issues and propose various corrections for the selection effect. It is beyond the scope of this paper to review the various proposals; besides, this is still a very active area of research, so new developments are to be expected. However, we should mention briefly one of the general strategies that can be used to correct for the selection effect, one that we will consider in the next section. As was made clear in Figure 3.1, the act of selecting a model prior to using it to make predictions changes the classical distribution theory. To correct for the selection effect, one needs only to understand how the classical distribution theory changes. Only in rare cases can this selection-adjusted distribution theory be worked out analytically, but numerical approximations may be possible. In Section 4 we will consider an approach to adjust for the selection effect based on the bootstrap method (Efron 1979; Klugman, Panjer, and Willmont 2012).
4. Effects of model selection on prediction
4.1. Setup and first observations
Given the apparently damaging effects that model selection can have on the validity of statistical inference, it is imperative to ask whether these effects carry over to the insurer’s prediction problem. That is, are actuaries safe to base their predictions on the model given in equation (2.3) when the data have first been used to select the model? Despite the surge of interest in statistics on post-selection inference, as discussed above, the effect of selection on prediction has not received much attention. The only work along these lines that we are aware of is Leeb (2009); however, see our discussion in Section 5.
When only a subset, S, of the predictor variables are to be considered, then the prediction methodology described above can be modified in an obvious way. Indeed, the 100(1 − α) % prediction interval becomes
˜xTSˆβS±tn−|S|(α/2)ˆσS{1+˜xTS(XTSXS)−1˜xS}1/2,
and we can proceed to define a corresponding predictive distribution, as in equation (2.3), which we will denote by πY(ỹ|S) to highlight the dependence on the model S. If Så is the “true” model, i.e., βj = 0 for all j Så, then all the distributional properties of the prediction interval and so on carry over to this case. But what happens if data are used to select a model Ŝ? We will investigate the effect of selection on prediction by looking at the corresponding predictive density πY(ỹ|Ŝ), which depends on data in two different ways—one is direct, just like it is in equation (2.3), and the other is indirect, through Ŝ. For the discussion that follows, again we will focus on Ŝ chosen via AIC because this is the preferred method in prediction applications and because convenient R functions (e.g., regsubsets) are available for doing best subset selection via AIC. In some limited experiments using other selection methods, such as BIC and lasso, we found results similar to those presented here.
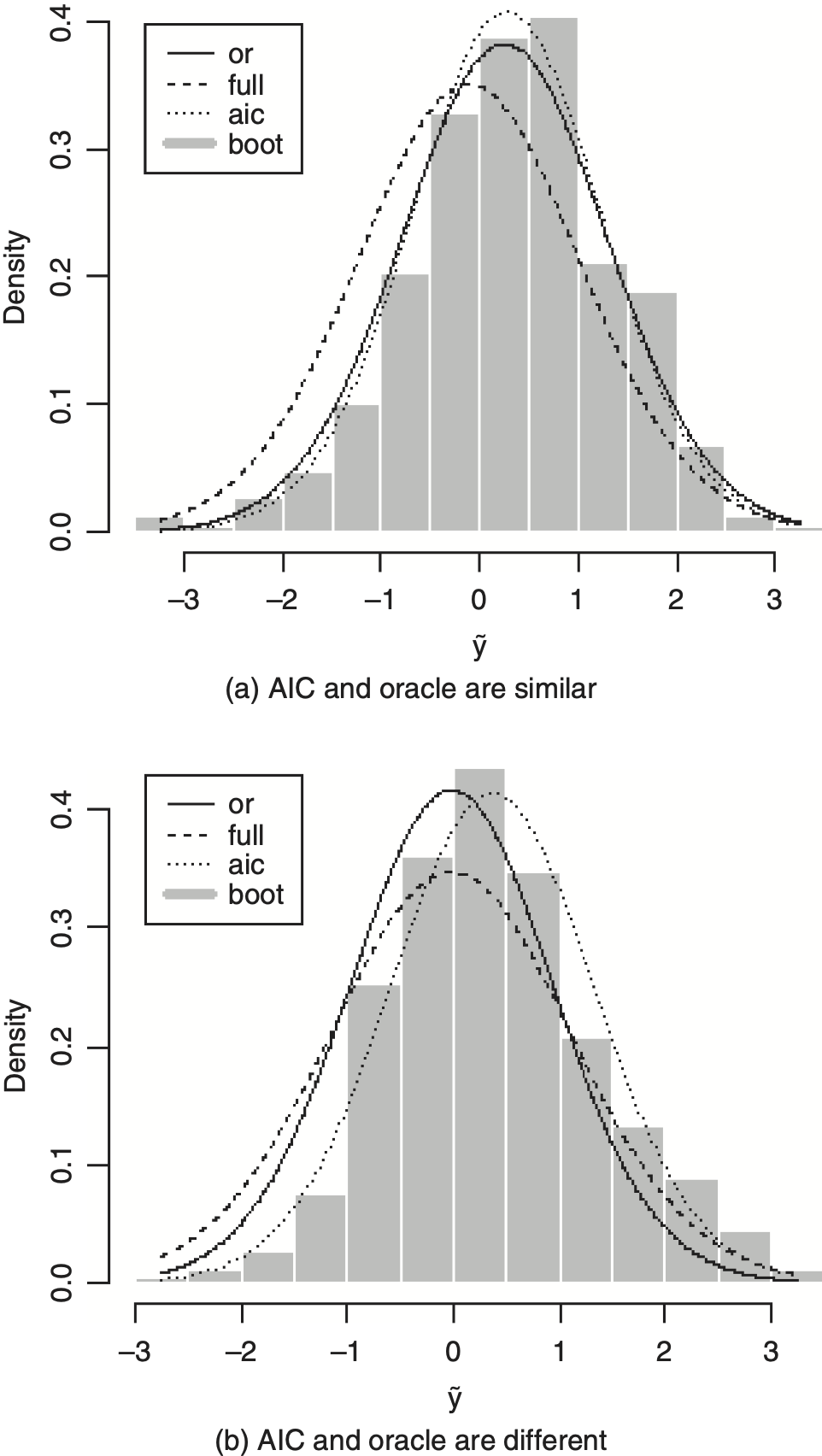
To see the effect of selection on prediction, we consider three alternative predictive distributions besides the AIC predictive distribution. The first is the oracle predictive distribution, πY(ỹ|Så), based on knowledge of the true model, Så. This is the “gold standard” predictive distribution, ideal for comparison purposes, but unfortunately it is not available to the actuary in practice because he or she typically will not know Så. The second is the predictive distribution πY(ỹ|S), based on the full model that includes all the rating variables. This is a simple, conservative choice that may be inefficient, for a variety of reasons, compared with the other, more sophisticated methods. Finally, following our discussion above, we consider a predictive distribution that accounts for the possible departure from the usual least squares distribution theory, caused by selection. The exact distribution theory, accounting for selection, is not available in closed form, but we can easily get a bootstrap approximation via resampling (see, e.g., Davison and Hinkley 1997, Section 6.3.3), which we denote by π̂Y(ỹ|Ŝ). Here and throughout this paper, we take the bootstrap sample size to be B = 500. Of course, among these four methods (oracle, full, AIC, and bootstrap-AIC), the oracle predictive distribution is the best. Prediction based on the full model should also be reasonable, but its inefficiency will manifest in its having a wider predictive density than the oracle. It is not clear, however, what to expect from the two AIC-based predictive distributions.
To build some intuition about the performance of the various predictive distributions, we revisit the example from Section 3. Suppose the loss variables, X1, . . . , Xp, with p = 10, are iid N(0, 1), and all the β coefficients are 0. We then fit the various models and evaluate the corresponding predictive distributions based on another set, x̃, of iid N(0, 1) values of the 10 rating variables. We carried out this process for a number of simulated data sets, and two distinct cases emerged, one in which the AIC-based predictive distributions were similar to those of the oracle, and one in which they were different. Panels (a) and (b) of Figure 4.1, respectively, are representative of these two cases. Note that in each panel, both AIC-based predictive densities have a slightly smaller spread than that of the oracle, and the main difference between the two panels is an apparently not-so-substantial location shift of the AIC-based predictive densities away from that of the oracle in panel (b).

4.2. Further investigations
A number of interesting and important questions arise from the limited results described above, in particular the following:
-
Do the prediction intervals derived from the AIC selection–based predictive distribution have adequate prediction coverage?
-
If so, then how does its length compare with that of the oracle?
-
If not, then why, and does the bootstrap adjustment do better somehow?
In this section we carry out some further simulation studies to address these questions and, ultimately, to make a recommendation for what method practitioners ought to use based on the currently available statistical tools.
The experiments carried out above are somewhat unrealistic in the sense that the rating variables were independent and, in fact, none of them contributed to the loss variable distribution because the coefficients were all 0. Here we consider a more realistic scenario in which there is some dependence between rating variables and there are some nonzero coefficients, with varying magnitudes.
-
We consider X1, . . . , Xp to be multivariate normal, with standard normal marginals and with first-order autoregressive correlation structure; i.e., the correlation between Xj and Xk is 0.5|j–k| for j, k = 1, . . . , p.
-
In an effort to reach some conclusions independent of a fixed choice of the nonzero values of β, we consider three classes—weak, moderate, and strong—and then randomly sample from these classes. In particular, we first sample 3 of the 10 rating variables and, for each of those 3, we sample the corresponding βjs iid from N(μ, 1); the other 7 all have βj = 0. The weak, moderate, and strong classes correspond to μ = 1, μ = 3, and μ = 5, respectively.
For each of the weak, moderate, and strong cases, and for each “true” β sampled from the class, we simulate 200 data sets according to the model for rating variables above and equation (2.1), and evaluate 95% prediction intervals based on the various methods described above. The average lengths and prediction coverage proportions of these predictive intervals can be computed for each β. Figure 4.2 gives a summary of these results over 20 βs sampled from the respective classes. Throughout, we keep n = 50, p = 10, and σ = 1 fixed.

The first observation is that both the oracle and the full model produce prediction intervals with the right coverage, but the full model intervals tend to be longer, by up to 10%, confirming the claims we made previously. Second, we see that the AIC selection–based intervals are both a bit shorter than those of the oracle, on average, and therefore tend to under-cover, especially the bootstrap version.
Is there any explanation for the AIC’s less-than-fully-satisfactory performance? First, it is known that AIC tends to overfit; that is, if Ŝ is the set of rating variables selected by AIC, then AIC tends to overfit in the sense that, typically, ŜSå (Hurvich and Tsai 1989; Zheng and Loh 1995). It follows from theorem 1 in Hong, Kuffner, and Martin (2018) that AIC overfitting implies variance underestimation; i.e., ŜSå implies ̂Ŝ2 ̂2S^å^. And for relatively large n, the width of the prediction intervals is chiefly determined by these variance estimates. Indeed, for n appreciably larger than p,
-
the critical value tn–|S| in model (2.2) will not differ much for S = Så or S = Ŝ, and
-
since n is large, XSTXS nΣS, where ΣS is the corresponding submatrix of Σ, when the rows of X are N(0, Σ); therefore,
˜xTS(XTSXS)−1˜xS≈˜xTS∑−1S˜xSn.
Since the numerator on the right-hand side, as a function of x̃S ∼ N(0, Σs), is a chi-square random variable with |S| degrees of freedom, it should be small compared with the n in the denominator. Therefore, the AIC and oracle prediction intervals will not be affected by the{1 + x̃ST (XSTXS)–1x̃S}1/2 term, either.
Thus, any noticeable difference in the prediction intervals for AIC versus the oracle must be due to the variances σ̂2S^å^ and σ̂Ŝ2. Since AIC tends to overfit, and overfitting implies variance underestimation, the shorter length and under-coverage of the AIC-based prediction intervals is to be expected. And given the under-coverage of the AIC selection-based prediction interval, a possible explanation for the bootstrap’s slightly worse coverage is the dilation phenomenon described in Efron (2003).
Based on the results presented here, and keeping in mind that incorrect predictions can jeopardize an insurer’s solvency, we have to recommend that practitioners use the full model to derive their predictions. This is indeed a conservative recommendation, but solvency is an important concern and none of the other methods seem to provide valid prediction intervals in general. Our recommendation would surely change if the problems being considered by actuarial scientists were “high-dimensional”—i.e., if they had large p compared with n—or if a new statistical methodology for valid post-selection prediction were developed.
5. Conclusions and further questions
This paper has considered the effect of model selection on both inference and prediction. The material in Section 3 is mostly a review of some recent work in the statistics literature, but bringing the concerns about inference after model selection to the attention of practicing actuaries is important and one of our main goals. On the other hand, the observations made in Section 4 are, to the best of our knowledge, new. Our conclusion is that post-selection prediction—based on either a naive application of the usual least squares theory or a bootstrap adjustment—is unsatisfactory in the sense that the corresponding prediction intervals tend to under-cover. Therefore, we make the following recommendation:
Actuaries should not carry out a selection step if valid prediction is the goal; that is, they should construct their predictive distribution, intervals, and so on based on the full model and the usual least squares distribution theory.
This is indeed a conservative recommendation since the full model might not be the most efficient one. But since prediction errors may jeopardize the insurer’s solvency, we argue that conservatism is a prudent position to take. Naturally, our recommendation could potentially change if the problem setting were different, if something other than prediction were the goal, or if a new statistical methodology were developed.
The high-dimensional regression problem, where p » n, has received considerable attention in the statistics literature, but this situation is still rare in actuarial science applications. However, as new technology develops, one would expect that, eventually, the high-dimensional problem would be one that actuarial scientists would be interested in, and naturally, the question of how to make valid predictions in such cases would be relevant. When p » n, our recommendation to use the full model for prediction is no longer feasible, so some entirely new considerations would be needed.
One important question for future research is how to correct for the selection effect when the goal is valid prediction. To really answer the question, we would need to derive the form of an optimal prediction interval correction that makes the intervals asymptotically honest. This is a substantial endeavor, a focus of our ongoing work.
Acknowledgments
The authors thank the six anonymous referees for their comments and suggestions, which led to significant improvements in this paper. This work is supported by the Society of Actuaries through the 2016 Individual Grant.