

1. Introduction
Two important operations in actuarial science—using data to construct a model and estimating parameters of interest based on the model—are used in the insurance industry. In this paper, both processes are presented in the context of a composite distribution.
Because insurance data is skewed via a fat tail, it is very difficult to find a classical parametric distribution to model data. The central limit theorem is not very useful for the insurance industry because insurance data usually has high frequencies for small losses, and large losses occur with small probabilities. Therefore, many researchers have developed composite models for insurance data or data with similar characteristics. Klugman, Panjer, and Willmot (2012) discussed how to use data to build a model in the actuarial science field and the insurance industry, including many important concepts, such as value at risk (VaR). VaR, one of the most important risk measures in the business world, is the percentile of the distribution of losses. It lets actuaries and risk managers look at “the chance of an adverse outcome” and helps them to make a decision. This paper uses Bayesian inference to estimate VaR based on a predictive model.
Teodorescu and Vernic (2006) introduced the composite exponential-Pareto distribution, which is a one-parameter distribution. They derived a maximum likelihood estimator for the unknown parameter θ, which represents the boundary between small and large losses in a data set. In a subsequent paper, the same authors worked on different types of exponential-Pareto composite models (Teodorescu and Vernic 2009). Both models have one unknown parameter. Researchers have proposed many other composite distributions. Preda and Ciumara (2006), for example, introduced the Weibull-Pareto and lognormal-Pareto composite models, pointing out that they could be used to model actuarial data collected from the insurance industry. The authors compared the models using different parameters, developed algorithms to find the maximum likelihood estimates for two unknown parameters, and compared the two models’ accuracy.
Pareto distribution has a fatter tail than normal distribution. Therefore, Pareto is a good model to capture large losses in insurance data, but it is not good for small losses with high frequencies. That is why many other distributions, such as exponential, lognormal, and Weibull, have been combined with the Pareto distribution to model losses with small values in a data set. Cooray and Ananda (2005) discuss modeling actuarial data based on a composite lognormal-Pareto composite model. Cooray and Cheng (2015) provide Bayes estimates for parameters of a lognormal-Pareto composite model. Scollnik and Sun (2012) discuss several Weibull-Pareto composite models.
The aim of this paper is to develop a Bayesian predictive density based on the composite exponential-Pareto distribution. In the Bayesian framework, a predictive density is developed via the composite density and then, based on a random sample, a Bayes estimate and the VaR are estimated. The following section develops a posterior probability density function (pdf) via an inverse gamma prior for θ. It also explains how to use a search method to compute the Bayes estimate for θ based on a sample. Section 3 derives the predictive density for Y, where its realization, y, is considered as a future observation from the composite distribution. The first moment, E[Y|x], of the predictive pdf is undefined because E[X] is also undefined for the composite pdf. Section 4 investigates the accuracy of VaR and shows, through a summary of simulation studies, that Bayes estimation of θ under a squared error loss function is consistently more accurate than maximum likelihood estimation (MLE). The section also gives a method for choosing the “best” values for hyperparameters of the prior distribution to get an accurate Bayes estimate. Section 5 contains a numerical example for computational purposes. Three Mathematica codes are given in the Appendix, one for computing the MLE of θ, the second for computing a Bayes estimate and VaR using a single sample, and the third for a simulation that can be used to search for the “best” values of hyperparameters to find an accurate Bayes estimate.
Teodorescu and Vernic (2006) developed the composite exponential-Pareto model as follows:
Let X be a random variable with the pdf
fx(x)={cf1(x)0<x≤θcf2(x)θ≤x≤∞,
where
f1(x)=λe−λx,x>0,λ>0
and
f2(x)=αθαxα+1,x≥θ
f1(x) is the pdf of an exponential distribution with parameter λ, and f2(x) is the pdf of a Pareto distribution with parameters θ and α.
In order to make the composite density function smooth, it is assumed that the pdf is continuous and differential at θ. That is,
f1(θ)=f2(θ),f′1(θ)=f′2(θ).
Solving the above equations simultaneously gives
λθ=1.35,α=0.35,c=0.574.
As a result, the initial three parameters are reduced to only one parameter, θ, for the composite exponential-Pareto distribution whose pdf is given by
fx(x∣θ)={.775θe−1.35xθ0<x≤θ.2θ.35x1.35θ≤x<∞.
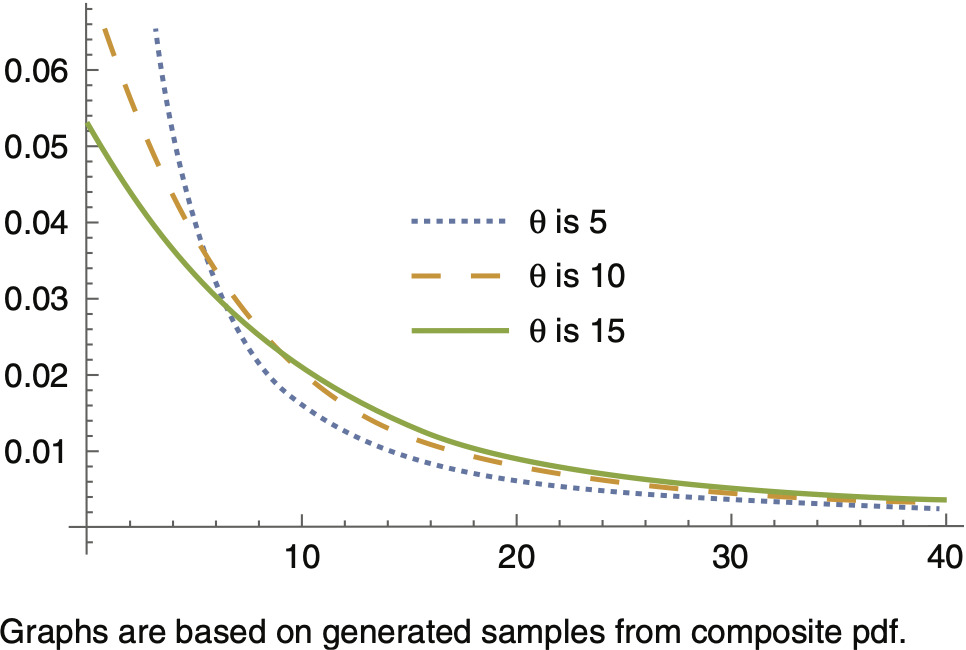
Figure 1.1 provides graphs of the composite pdf for different values of θ, revealing that as θ increases, the tail of the pdf becomes heavier. This implies that the percentile at a specific level, say 0.99, is increasing in θ. Teodorescu and Vernic (2006) compared the exponential distribution with the composite exponential-Pareto distribution and derived an MLE for θ via an ad hoc procedure using a search method. They concluded that when θ = 10, the composite distribution fades to 0 more slowly than the exponential distribution. The implication of this result is that the composite distribution could be a better choice to model insurance data containing large losses. In this situation, we could be able to avoid charging insufficient premiums to cover potential future losses.
2. Derivation of posterior density and Bayes estimator
Let x1, . . . , xn be a random sample for the composite pdf in (1.1) and, without loss of generality, assume that x1 x2 . . . xn is an ordered random sample from the pdf in (1.1). The likelihood function, also given in Teodorescu and Vernic (2006), is written as
L(x∣θ)=kθ0.35n−1.35me−1.35∑ni=1x1/θ,
where . To formulate the likelihood function, it is assumed that there is an m(m = 1, 2, . . . , n − 1) such that in the ordered sample xm ≤ θ ≤ xm+1.
To derive a posterior distribution for θ, we use a conjugate prior inverse gamma distribution for θ with the pdf
ρ(θ)=baθ−a−1e−b/θΓ(a),b>0,a>0.
From (2.1) and (2.2), the posterior pdf can be written as
f(θ∣x)=L(θ∣x)∗ρ(θ)∝e−b+1.35∑mi=1xiθθ−(a−0.35n+1.35m)−1.
It can be seen from (2.3) that the expression on the right-hand side is the kernel of inverse gamma (A, B), where and Therefore, under a squared error loss function, the Bayes estimator for is
ˆθBayes =E[θ∣x]=BA−1=b+1.35∑mi=1xia−0.35n+1.35m−1.
Given an ordered sample x1 x2 . . . xn, we need to identify the correct value of m in order to compute We use the following algorithm:
-
Start with j = 1, and check to see if ; if yes, then m = 1. Otherwise, go to step 2.
-
For j = 2, check to see if ; if yes, then m = 2. Otherwise, let j = 3 and continue until the correct value for m has been found.
The idea is to find the correct value for j so that . The Mathematica code used for simulation studies in this article is based on the above algorithm to compute
3. Derivation of predictive density
Let y be a realization of the random variable Y from the composite density. Based on the observed sample data x, we are interested in deriving the predictive density f(y|x). In the Bayesian framework, predictive density is used to estimate measures such as E[Y|x] or Var[Y|x], or other measures, such as VaR, which is considered in this paper.
f(y∣x)=∫∞0f(θ∣x)fY(y∣θ)dθ,
where
fY(y∣θ)={0.775θe−1.35yθ0<y≤θ0.2θ.35y1.35θ≤y<∞.
As a result, we get
f(θ∣x)f(y∣θ)={0.775Γ(A)θe−1.35yθθ−(A+1)BAe−B/θy<θ<∞0.2θ.35Γ(A)y1.35θ−(A+1)BAe−B/θ0<θ<y,
which reduces to
f(θ∣x)f(y∣θ)={0.775BAΓ(A+1)Γ(A)(B+1.35y)A+1h1(θ∣A+1,B+1.35y)y<θ<∞0.2BAΓ(A−.35)Γ(A)y1.35BA−0.35h2(θ∣A−0.35,B)0<θ<y,
where h1(θ|A + 1, B + 1.35y) is the pdf of the inverse gamma with parameters A + 1 and B + 1.35y. Also, h2(θ|A − 0.35,B) is the pdf of the inverse gamma distribution with parameters A − .35 and B. Using the above results, the predictive density, f(y|x), is given by
f(y∣x)=∫y0f(θ∣x)fY(y∣θ)dθ+∫∞yf(θ∣x)fY(y∣θ)dθ=K2(y)H2(y∣A−0.35,B)+K1(y)(1−H1(y∣A+1,B+1.35y))
K1(y)=0.775A∗BA(B+1.35y)A+1,K2(y)=0.2B.35Γ(A−0.35)Γ(A)y1.35.
H2 is the cumulative density function (cdf) of the inverse gamma distribution with parameters (A − 0.35, B), and H1 is the cdf of the inverse gamma distribution with parameters (A + 1, B + 1.35y). Similar to the composite density, for which E[X] is undefined, E[Y|x] is also undefined for the predictive pdf.
4. Simulation
This section describes simulation studies conducted to assess the accuracy of as well as VaR. For selected values of n, θ and the “best” values of hyperparameters (a, b), N = 300 samples from the composite density (1.1) are generated.
For each generated sample, observations are ranked and the correct value for m is identified through a
search method so that . Simulation results indicate that the accuracy of the Bayes estimate depends on the selected values for hyperparameters a and b. The following method is proposed to produce an accurate Bayes estimate.
For the inverse gamma prior distribution, we have
E[θ]=ba−1,Var(θ)=b2(a−1)2(a−2).
Also, note that A = (a − 0.35n + 1.35m) because one of the parameters of the posterior distribution must be positive, and that m takes values 1, 2, . . . , (n − 1). Therefore, a > 0.35n − 1.35m, and as a result, the value for a should be at least 0.35n – 1.35 to avoid computational errors. For example, for n = 50, a should be at least 17. Simulation studies indicate that for a given sample size n, generally larger values of a provide more accurate Bayes estimates. However, as a increases, for a desired level of variance in (4.1), b would need to increase. And this causes the expected value in (4.1) to increase. Simulation results, as shown in Table 4.1 for θ = 5,10, indicate that the accuracy of the Bayes estimate depends on the choice of a (b is found via a), which depends on n as well as θ. To identify a “good” value for a, we propose the following method.
Simulations indicate that a large θ produces larger sample points; as a result both the Bayes estimate of θ and its mean squared error (MSE) increase. To overcome this, we propose an upper bound on Var(θ) and let the upper bound be a decreasing function of n. Let
Var(θ)=b2(a−1)2(a−2)≤1n1/3.
The idea is to have a decreasing function of n on the right-hand side of (4.2). Other functions for an upper bound that are decreasing in n may also work, but simulations show that the above choice works very well. For a selected value of a, (4.2) is used to find b by solving
b2(a−1)2(a−2)≤1n1/3.
As shown in Table 4.1, for selected values of n and θ, the MSE of the Bayes estimate has a minimum when a takes its “best” value. For selected values of n and θ, Table 4.1 lists the turning points of the MSE. The Mathematica code for the simulation given in the Appendix can be used to make a list of “best” values of a as a function of n and θ. In this paper, n = 20, 50, 100, and θ = 5, 10 are considered.
Note that since, in practice, the true value of θ is unknown, it can be guessed by using its MLE. In particular, the MLE would be a good guess if n is large. Note that in simulation studies, in each iteration, the MLE was not used to find a and b because the variability in the MLE would create more variability in the Bayes estimate. For example, in simulation studies for each generated sample and a selected value of a, we tried to find via due to the E[θ] formula in (4.1), but under this method, the variability of becomes extremely large and the results are not desirable.
As mentioned earlier, VaR at the 0.90 level is a useful measure for big losses in the insurance industry. We used 0.70 to compute the Bayes estimate of VaR. Even with 0.70 and N = 300 interations, it takes several hours for the program to run. Computation of VaR via (3.1) cannot be done analytically, and therefore a numerical method is required. The idea is to find the value of y in (3.1) so that Mathematica is used to find an estimated value of y based on selected input parameters and a generated sample from the composite density (1.1). As mentioned above, computation of VaR at the 0.90 level is possible, but an extended computer memory is required (in particular when a is large) to solve equations in the code numerically.
Teodorescu and Vernic (2006) derived the MLE of θ. The MLE should satisfy ,
and it can be found via a search method for m = 1, 2, . . . , (n − 1). Simulation studies indicate that among many generated samples (k = 300), only a few (1 or 2 out of 300) lead to extremely large MLE values, and as result, the MSE of the MLE is inflated. Even when such outliers do not occur, the Bayes estimator still outperforms MLE.
Tables 4.2 and 4.3 summarize simulation studies carried out to assess the accuracy of the Bayes estimator, MLE, and VaR. Both tables use “best” values of from Table 4.1 to compare the Bayes estimate with the MLE. Tables 4.2 and 4.3 reveal that both and are more accurate for larger values of than for smaller ones. The tables also reveal that the average Bayes estimate, is closer to the actual value of than is the average of MLEs. For all values of in Tables 4.2 and 4.3, we note that Bayes is considerably smaller than
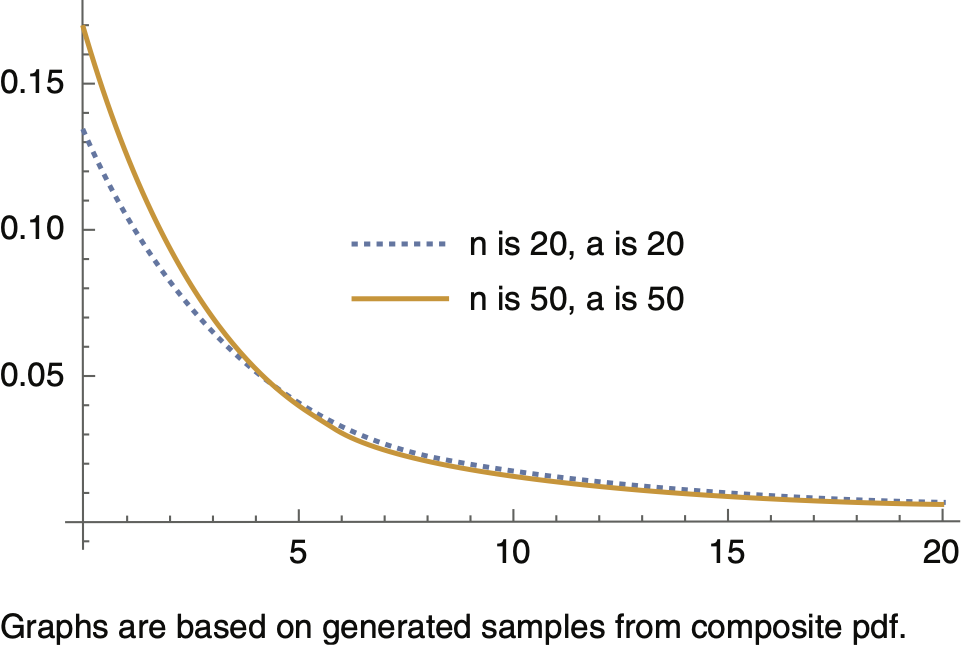
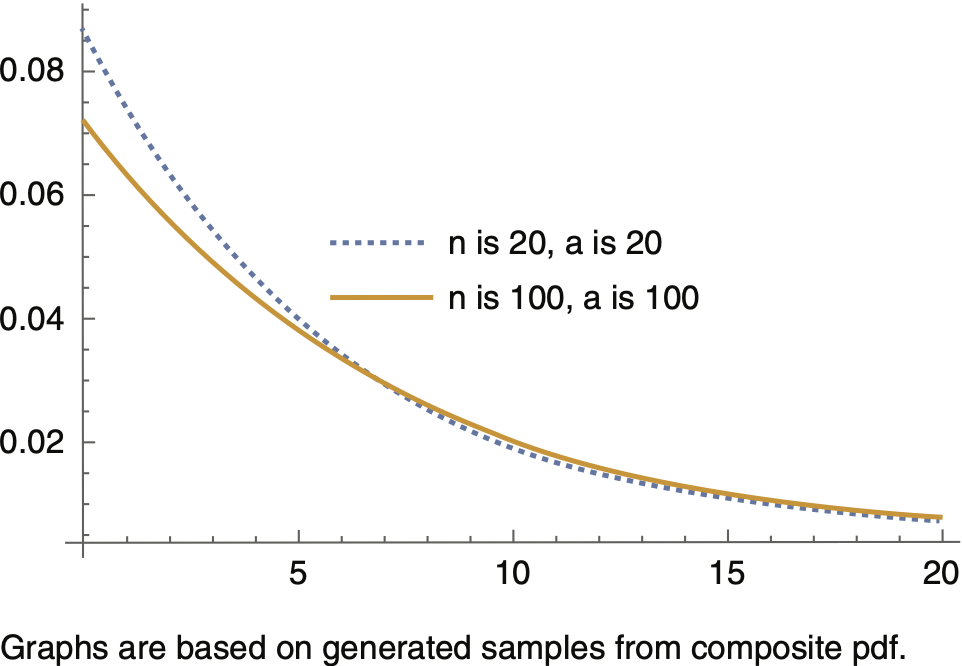
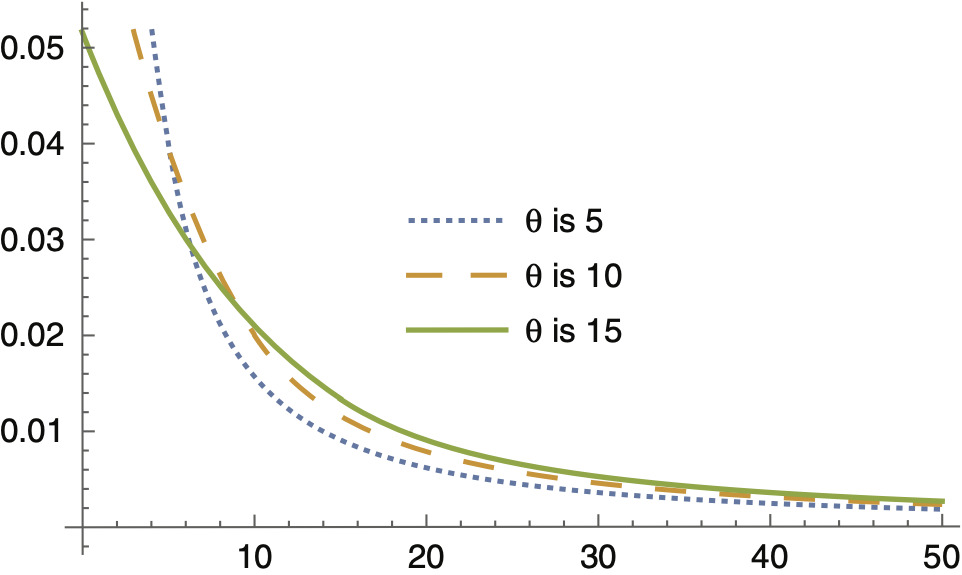
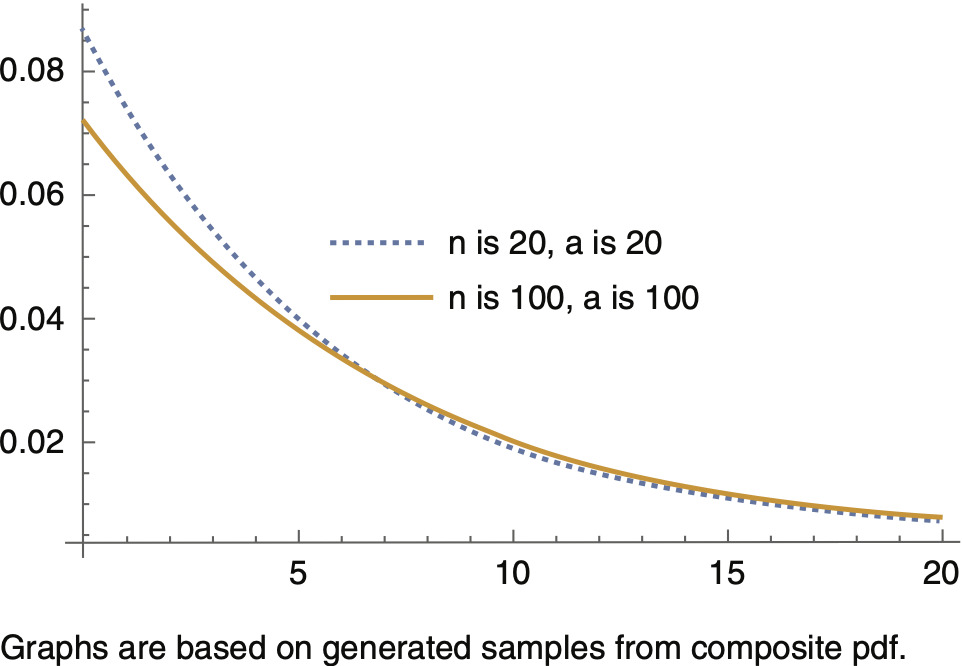
Figures 4.1 through 4.3 provide graphs of the predictive density for different values of θ and a, revealing that as n increases, the tail of the predictive density becomes heavier, and as a result, at a specific level, say 0.99, VaR increases. Simulation studies confirm this conclusion. Figure 4.3 is a graph of the predictive density for fixed values n = 50, a = 50, and for three different values of θ based on which samples from the composite pdf are generated. Similar to what is shown in Figure 1.1, as θ increases, the tail of the predictive density becomes heavier, causing VaR at a specific level, say 0.99, to increase.

5. Numerical example
The data set in Table 5.1 is a random sample of size 200 generated from the exponential-Pareto composite pdf (1.1) with parameter θ = 5. For this data set, the value of m is 86. The Bayes estimate is 4.9878, and the MLE is 4.935488. Simulation studies indicate that the Bayes estimator is more accurate than the MLE. Due to the long-tailed composite distribution, based on a sample of size n = 200, nine intervals of unequal widths are used to assess the goodness of fit of the data via a chi-square test. The observed and expected frequencies for the proportion of observations within each class-interval are given in Table 5.1.
In Table 5.2, denotes the observed percentage of observations in the class-interval denotes the expected proportion of observations in the class-interval Note that to get a Bayes estimate of 4.98786 for is used in the cdf of the composite distribution. At the 0.05 level of significance with 7 degrees of freedom, the critical value for the chi-square test is 14.067 . As a result, there is not enough evidence to reject the null hypothesis that
6. Conclusion
A Bayes estimator via inverse gamma prior for the boundary parameter θ, which separates large losses from small losses in insurance data, is derived based on the exponential-Pareto composite model. A Bayesian predictive density is derived via the posterior pdf for θ. The “best” value for a is selected through an upper limit (a decreasing function of n) on the variance of the inverse gamma prior distribution. Simulation studies indicate that even for a large sample size, the Bayes estimate outperforms MLE if the “best” values of hyperparameters a and b are used in computations. Having values for the hyperparameters, the predictive density is used along with a numerical method in Mathematica to compute VaR at the 70% level.