

1. Introduction
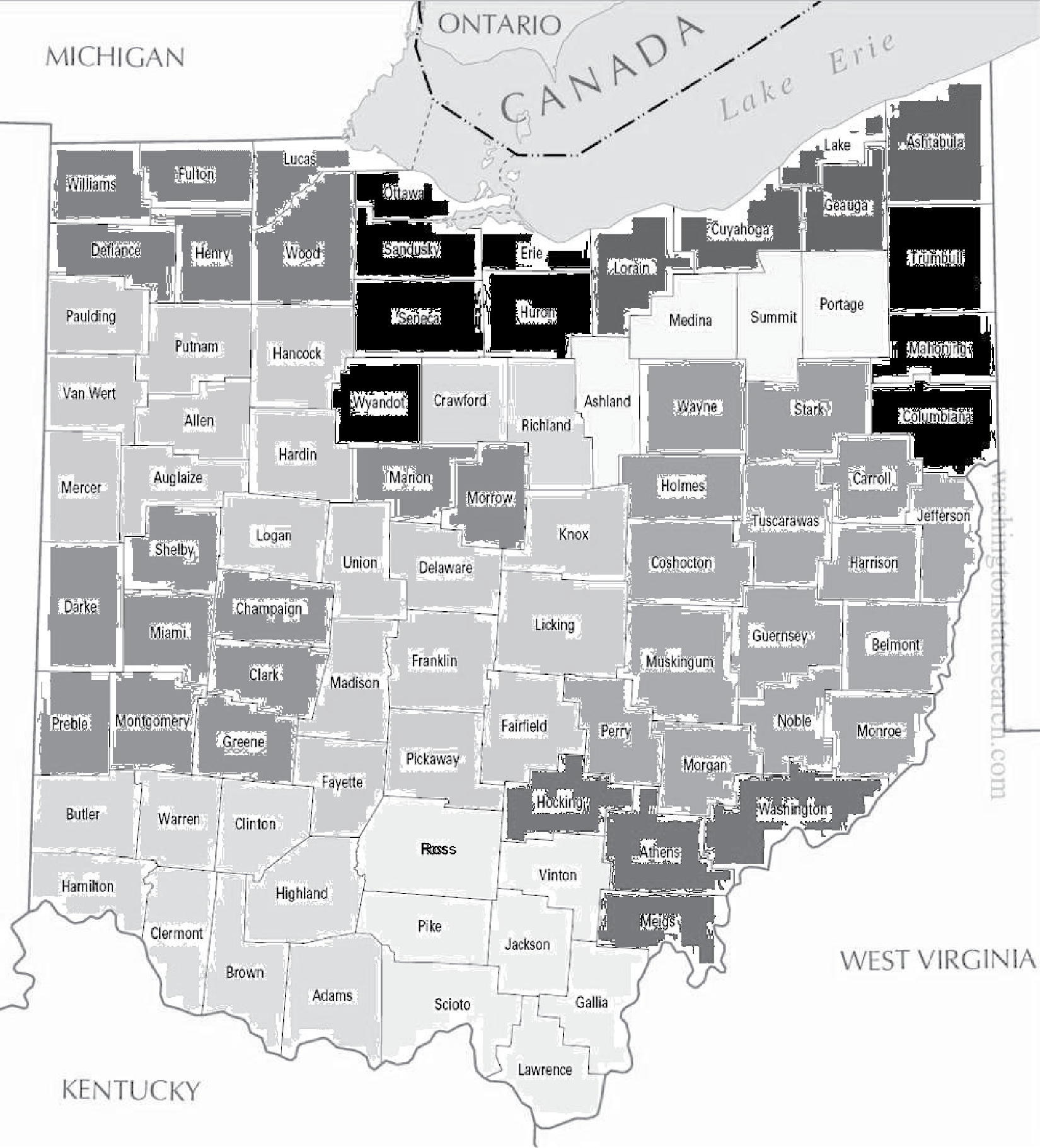
Geographical variability of claims in health insurance is a well-known issue that is important in pricing insurance products. The relevant research is known as geographical ratemaking in property and casualty insurance (e.g., Grize 2015; McClenahan 1990). Area of residence is one of the factors that health insurers can use when adjusting premiums by the Patient Protection and Affordable Care Act, as it helps to account for the spatial variability that cannot be explained by other factors such as age and smoking status (e.g., Kofman and Pollitz 2006; NAIC and CIPR 2011). A common way to handle the spatial variation is by clustering small geographic regions (e.g., at the county level or zipcode level) into larger areas, each of which has its own rate in product pricing (e.g., Werner and Modlin 2010). These grouped areas are usually called geographic rating areas. Although geographic rating is permitted in most states, it is limited by state/federal regulations to the use of the first three digits of zipcode or county (https://www.cms.gov/cciio/programs-and-initiatives/health-insurance-market-reforms/state-gra.html). For example, Figure 1 is a sample rating area map of Ohio approved by the Ohio Department of Insurance, where 88 counties in the state are grouped into 17 rating areas.

Rating areas need to be defined with actuarial justifications. Early rating areas were defined based on subjective information such as agent feedback or loss ratios that may have lacked credibility; some historical territory definitions lacked statistical support and may have lost meaning over time (Jennings 2008, 34). Modern clustering methods, non-model based or model based, have been applied to residuals from standard models such as generalized linear models (GLMs), (Haberman and Renshaw 1996; McCullagh 1984) to group basic geographic units such as counties into clusters based on historical experience, modeled experience, or well-defined similarity rules (Werner and Modlin 2010; Yao 2008). A unique requirement of the cluster analysis in this context is that there are various social and regulatory acceptability constraints such as the minimum area or geographic contiguity of each territory (Weibel and Walsh 2008). The homogeneity of risk classification in a rating area can be assessed by the within cluster variance as a percentage of the total variance (Jennings 2008; Miller 2004). Rating areas with territorial boundaries from clustering methods are coarse, as shown in Figure 1, in that: (1) units within one rating area may not be that homogeneous; and (2) neighboring units across a boundary may not be that different. Further, clustering methods cannot handle geographic units with no observations, which is not uncommon in less populated areas.
Because of the spatial contiguity and the “spill-over” effect, it is reasonable to assume that the geographic risk surface is smooth. With the aid of geographic information systems, local smoothing and inverse distance weighted averages have been used to define ratings at the basic geographical unit level without territorial boundaries (Brubaker 1996; Christopherson and Werland 1996). These methods are often applied to the residuals from models that account for large scale variation explained by other predictors. Therefore, the smoothing and the modeling are in two separate stages, which makes inference on the ratings difficult and often disregarded. A modeling strategy that unifies the two stages is the generalized additive model (GAM) framework (Hastie and Tibshirani 1990) with spatial random effects at the basic geographic unit level. A GAM allows the covariate effects to be smoothly varying instead of linear, a highly desired feature in capturing the large scale variation. The spatial random effects account for the structured, small scale variation across the basic geographic units. Additional unstructured random effects can be included to account for the spatial heterogeneity for each basic unit.
Such models are termed generalized geoadditive models (Kammann and Wand 2003) and have been applied to insurance data (Fahrmeir, Lang, and Spies 2003; Fahrmeir, Sagerer, and Sussmann 2007; Lang and Brezger 2004). Inferences about generalized geoadditive models are often made in the Bayesian framework with the Markov chain Monte Carlo (MCMC) method (Fahrmeir, Kneib, and Lang 2007; Fahrmeir and Lang 2001; Klein et al. 2014; Klein, Kneib, and Lang 2015). Due to the computing intensive MCMC, however, the model has not been widely applied to geographic rating despite its natural potential. Practical applications are further complicated by excess zeros commonly observed in claims, resulting in semicontinuous data. The most relevant work in Klein et al. (2014) used zero-inflated generalized geoadditive models in non-life ratemaking, but implementable rating areas using the spatial random effects were not suggested and actuarial implications were not fully discussed.
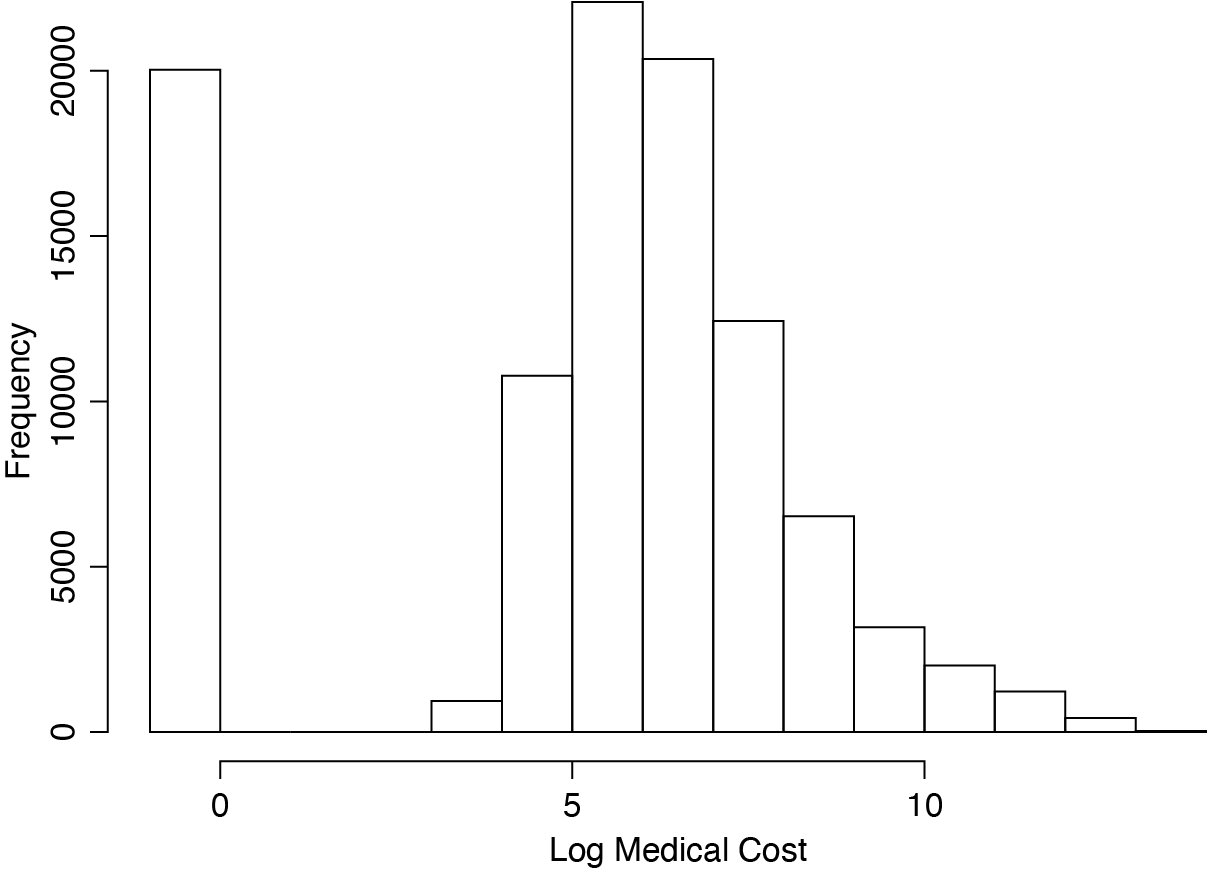
This paper aims to provide a practical method for geographical rating with a two-part generalized geoadditive model, using a fast alternative to MCMC, the integrated nested Laplace approximation (INLA) (Rue, Martino, and Chopin 2009). The implementation is available in R package INLA (Martins et al. 2013), which could reduce computing time from days to hours for large data sets. Because real health insurance data are privileged, we choose to use a simulated data to demonstrate the models and methods, which mimic the real data from a company, with features such as spatial dependence, excess number of zeros, and nonlinear covariate effects. An additional advantage of simulated data is that the true model and true parameter values are known, facilitating model fitting assessment that is otherwise not possible with real data. Our code is in supplementary materials to ensure reproducibility. The simulated data are healthcare expenses and covariates at the individual level, including the basic geographical unit where each individual resides such as zipcode or county. The expenses typically have a positive probability mass at zero (about 20% in the simulated example in Section 2), and a two-part model is used for such data (Deb, Munkin, and Trivedi 2006; Frees and Sun 2010). The first part models the binary response of whether or not the expense is positive, and the second part models the expense amount if it is positive. Nonlinear covariate effects, structured spatial random effects, and unstructured random effects are included in both parts. The structured spatial random effects are in the form of Gaussian Markov random fields (GMRF) (e.g., Rue and Held 2005).
The rating for each basic geographical unit is derived as a ratio based on the two sets of structured spatial random effects. The ratings vary smoothly on the map without territorial boundaries, and they are justified by the unified fully Bayesian modeling framework. Units containing no individual data can still be rated with the built-in information borrowing mechanism of the inference procedure. The resulting ratings are more fair to customers, more accurate in predicting expenses, and more profitable for insurers. We further compare models with spatial effects at the county level and those at the zipcode level, due to regulation restrictions. Models at the county level already perform much better than models without any spatial effect, but modeling at the finer zipcode level, if allowed by regulations, could lead to additional gain. Although the methods are motivated and illustrated with healthcare insurance, they can be applied to property and casualty insurance also.
The ratings vary smoothly on the map without territorial boundaries, and they are justified by the unified fully Bayesian modeling framework. Units containing no individual data can still be rated with the built-in information borrowing mechanism of the inference procedure.
The rest of the paper is organized as follows. A simulated data set mimicking a health insurance claim data set in reality is introduced in Section 2. The generalized geoadditive model and its inferences using the INLA package are presented in Section 3. A definition of ratings at the zipcode level with the spatial random effects in the model is developed in Section 3.6. The simulated data is analyzed, with results discussed and ratings map presented in Section 4. A discussion concludes in Section 5. Details about the data generation and INLA are relegated to the Appendix.
2. Healthcare expense data
A simulated dataset is used to illustrate the proposed methods which avoids the proprietary restrictions from using real data. The data generating mechanism was designed to generate data with features mimicking those of real data that are typically available for geographic rating; see details in Appendix A. Healthcare expenses of one month for n = 20,000 members in Ohio were generated with their age, gender, income, and zipcode. The variable income does not need to be income; it can represent a continuous variable of importance other than the demographics. The use of age and gender in pricing is subject to state or federal regulations, so their usage here is for illustration purposes. The covariates of the simulated data were generated independently. In a practical setting, they can be correlated, which should be handled the same way as done in a multiple regression model. Moderate correlation does not bring extra difficulty to our methodology; too high correlation causes collinearity, which can be fixed, for example, by constructing new predictors from a principal component analysis. The geographic distribution of the n members in 1197 zipcode areas and their ages were generated to approximately match those from the census data (http://www.census.gov/popest/). The resulting dataset has five variables for n members: expense, zipcode, age, gender (male = 1), and income (on log scale). Table 1 shows the first 5 rows of the dataset.
The simulated healthcare expense data has several realistic features. First, about 20% of the members have zero expense; Figure 2 shows the histogram of the healthcare expense per month on the log scale, with the leftmost bar representing the frequency of zeros. Second, children and seniors are associated with higher expenses; that is, the age effect is nonlinear, V-shaped. Lastly, everything else held constant, members in urban zipcode areas are more likely to have higher expenses than those in rural zipcode areas. This was enforced by the structural spatial effects with higher values assigned to urban zipcode areas; see details in the Appendix A. A reasonably good geographic rating method should address the challenges from these three features: 1) the positive probability of zero expense; 2) nonlinear effect for some risk factors; and 3) the smoothly varying ratings at the zipcode (or county) level. The proposed methods address these challenges by a two-part model that allows smooth covariate effects and spatial random effects. Although the spatial effects were generated at the zipcode level, it is also of interest to investigate the impact of a restriction that only allows county level geographic rating.

3. Models and methods
3.1. Generalized geoadditive model
For i = 1 , . . . , n, let Yi be the response variable. In the geographic rating application, the response variable can be a binary variable indicating the presence/absence of healthcare expense, or the log transformed healthcare expense if it is positive. Let Xi and Zi be a p × 1 and a q × 1 covariate vector, which have linear and nonlinear effects, respectively. Let si be the region (zipcode area) in which subject i resides, si {1, . . . , R}, where R is the number of regions (which could be zipcode areas or counties). A generalized geoadditive model (Kammann and Wand 2003) is
g(μi)=X⊤iβ+q∑j=1fj(Zij;α)+γsi+ϵsi
where g is a known link function, β is a p × 1 vector of coefficients for Xi, fj, j = 1, . . . , q, are smooth nonlinear functions with parameter vector are structured spatial random effects (spatially dependent) at the region level to be further described below, and are unstructured random effects at the region level. The joint distribution of is where IR is identity matrix of dimension R, and τε is a precision parameter.
Model (3.1) encompasses the GAM and GLM as special cases. For example, when γ is not present, the model is a GAM with an unstructured random effect at the region level; when neither γ nor ε is present, the model is a GAM; when no covariate has smooth nonlinear effect, the model is a GLM with structured and unstructured region level random effects. Since the smooth nonlinear effects fj, j = 1, . . . , q, are confounded via the intercept, constraints are needed for their identifiability. The best constraints are for all j, which makes each fj orthogonal to the intercept and leads to minimum width confidence intervals for the constrained fj (Wood 2006).
The structured random effects in model (3.1) account for a smooth geographical surface across all the regions. In contrast to the unstructured random effects which capture the heterogeneity across the regions, the spatial random effects are usually surrogates of unobserved factors. As most of the unobserved factors vary smoothly over the space, two neighboring regions are more alike than two regions further apart. The local dependence structure is described by an Intrinsic GMRF, which adopts an intuitive conditional specification:
γs∣γt:t≠s,τγ∼N(1ns∑t∼sγt,1nsτγ)
where ns is the number of neighbors of region s, t ∼ s indicates that region t and region s are neighbors, and τγ is a precision parameter. The joint distribution of can be equivalently specified as
γ∼N(0,τ−1γ(IR−W)−1),
where W = (wst), wst = I (t ∼ s)/ns. Model (3.3) specifies an improper distribution because the precision matrix IR – W is not of full rank. It can, however, be used as a prior for γ. This model is known as an intrinsic conditional autoregressive (ICAR) model, because model (3.2) is the limit of an autoregressive model as the autoregressive coefficient ρ = 1. As such, it can accommodate stronger dependence than models with ρ 1.
3.2. Two-Part generalized geoadditive model
As patient level healthcare expenses have a large percentage at zero, applying model (3.1) directly would not be appropriate. Two-part models have been developed for zero-modified data; see Neelon and O’Malley (2014) for a recent review. We consider a two-part generalized geoadditive model. A generalized geoadditive model is used for the probability of non-zero expense in the first part, and a second generalized geoadditive model is used for the positive expense in the second part.
We consider a two-part generalized geoadditive model. A generalized geoadditive model is used for the probability of non-zero expense in the first part, and a second generalized geoadditive model is used for the positive expense in the second part.
Let be the expense of subject i, i = 1, . . . , n. In the first part, the response variable is the indicator variable By adding a superscript “(1)” to all the components in model (3.1), the first part model is
Y(1)i∣μ(1)i ind ∼Bernoulli(μ(1)i),i=1,…,n,g(1)(μ(1)i)=X⊤iβ(1)+q∑j=1f(1)j(Zij;α(1))+γ(1)si+ϵ(1)si,γ(1)∼ICAR(τ(1)γ),ϵ(1)∼N(0,τ(1)−1ϵIR),
where and the ICAR model is defined as model (3.3). The link function g(1) was chosen to be the logit link in the data analysis in Section 4.
In the second part, the response variable is Yi(2) = provided With superscript “(2)”, the second part model is
\begin{aligned} Y_{i}^{(2)} \mid \mu_{i}^{(2)} & \stackrel{\text { ind }}{\sim} F\left(y ; \mu_{i}^{(2)}, \delta\right), \quad i=1, \ldots, n \\ g^{(2)}\left(\mu_{i}\right) & =X_{i}^{\top} \boldsymbol{\beta}^{(2)}+\sum_{j=1}^{q} f_{j}^{(2)}\left(Z_{i j} ; \boldsymbol{\alpha}^{(2)}\right)+\gamma_{s_{i}}^{(2)}+\epsilon_{s_{i}}^{(2)} \\ \boldsymbol{\gamma}^{(2)} & \sim \operatorname{ICAR}\left(\tau_{\gamma}^{(2)}\right) \\ \boldsymbol{\epsilon}^{(2)} & \sim N\left(0, \tau_{\epsilon}^{(2)^{-1}} I_{R}\right) \end{aligned} \tag{3.5}
where and F(y; μ, δ) is a distribution function specified by a mean parameter μ and possibly another parameter δ. In the data analysis in Section 4, the link function g(2) was the identity link and F is the normal distribution with mean μ and variance δ. Flexible distributions such as generalized gamma can be used for F in the second part to capture the skewness in the observed data (Liu et al. 2010; Manning, Basu, and Mullahy 2005). The covariates Xi and Zi in the two parts do not have to be the same, although they are the same in the analysis in Section 4.
3.3. Bayesian inference and INLA
Models (3.4) and (3.5) contain many Gaussian components that can be taken advantage of in inference under the Bayesian framework. Consider the first part (3.4) with logit link as an example, where Gaussian prior distributions are imposed on β(1)⸆ and α(1)⸆, with hyperparameter vectors τβ(1) and τα(1). The prior for γ(1) is defined as model (3.3) with a precision parameter τγ(1). The prior for ε(1) is normal with mean 0 and precision parameter τε^(1)^. Define w(1) = (β(1)⸆, α(1)⸆, γ(1)⸆, ε(1)⸆)⸆, the vector of all unknown Gaussian variables of interest in the model. Let θ(1) = (τβ(1)⸆, τα(1)⸆, τγ(1), τε(1))⸆ and let π(θ(1)) be the prior of θ(1). Let π(•|•) denote the conditional distribution of its arguments. Then π(w(1)|θ(1)) is Gaussian with zero mean and precision matrix Q(θ(1)).
Since Yi are independent given all covariates and latent Gaussian variables, the posterior can be written as
\begin{array}{c} \pi\left(\boldsymbol{w}^{(1)}, \boldsymbol{\theta}^{(1)} \mid \boldsymbol{Y}\right) \propto \\ \pi\left(\boldsymbol{\theta}^{(1)}\right) \pi\left(\boldsymbol{w}^{(1)} \mid \boldsymbol{\theta}^{(1)}\right) \prod_{i=1}^{n} \pi\left(Y_{i} \mid w_{i}^{(1)}, \boldsymbol{\theta}^{(1)}\right), \end{array}
where π(Yi|wi(1), θ(1)) is the Bernoulli likelihood under model (3.4), and Y = {Y1, . . . , Yn}. The posterior density for the second part model (3.5) can be worked out similarly with superscript “(2)”.
A common approach for inference in such a model is to use MCMC. As pointed out by Rue, Martino, and Chopin (2009), however, performance of MCMC with component-wise updates in this context is poor due to strong dependence among w(1) itself, and between w(1) and θ(1), especially when n and R are large. Consequently, the computational efficiency of MCMC is very low. Long chains are needed for convergence to occur, which may take days.
INLA is a new approach to statistical inference for latent Gaussian models (Martino and Rue 2010; Rue, Martino, and Chopin 2009). It provides fast, accurate approximations to the posterior densities of parameters and latent Gaussian variables of interest. A sketch of the approximation algorithms is in Appendix B. We refer readers to Rue, Martino, and Chopin (2009) for more details. The INLA methodology is efficiently implemented, and includes sparse matrices operations (Martino and Rue 2009). By using INLA, days of computing time using MCMC can be reduced to hours (e.g., Carroll et al. 2015; Taylor and Diggle 2014). The software package uses OpenMP to speed up the computations for shared memory machines, i.e., multicore processors which are equipped on most personal computers nowadays. An R package is available for ease of usage, and was used in the data analysis in Section 4. The software is open-source and can be downloaded from the website www.r-inla.org, which also includes many applications and case studies.
3.4. Model comparison
Since the two parts of the model are separated using different parts of the data, model comparisons can be done for each part separately. The deviance information criterion (DIC) is a commonly used model comparison criterion in the Bayesian framework (Spiegelhalter et al. 2002). Taking the first part as an example, let ξ(1) = (θ(1), w(1))⸆ be the vector of all unknown parameters of interest in the model. The DIC is defined as
\mathrm{DIC}=\bar{D}+p_{D}.
where D, as a measure of fit, is the expectation of the deviance of the model with respect to the posterior distribution of ξ(1), and pD is the effective number of parameters measuring the model complexity. Specifically, D = Eξ^(1)^[D(ξ(1))] and D(ξ1)) = –2logp(Y(1)|ξ(1)). Several methods have been proposed for calculating pD. Spiegelhalter et al. (2002) proposed to use
p_{D}=\bar{D}-D\left(\bar{\xi}^{(1)}\right) \text {, }
where ξ(1) is the posterior mean of ξ(1). Gelman et al. (2014) suggested
p_{D}=\frac{1}{2} \operatorname{Var}\left[D\left(\xi^{(1)}\right)\right]. \tag{3.6}
INLA uses an alternative method to (3.6) proposed by Watanabe (2010),
p_{D}=\sum_{i=1}^{n} \operatorname{Var}\left[\log p\left(Y_{i}^{(1)} \mid \xi^{(1)}\right)\right]
This method is more stable than (3.6) because it computes the variance separately for each data point and sums; the summing yields stability (Gelman, Hwang, and Vehtari 2014). A smaller DIC indicates a better model. In general, rules of thumb suggest that differences of 3 or more in DIC should be regarded as significant (Spiegelhalter et al. 2002). Although the DIC is widely used, it is known that it underpenalizes complex models with many random effects (Plummer 2008; Riebler and Held 2009).
Another popular model comparison criterion is the conditional predictive ordinate (CPO) (Geisser 1993; Pettit 1990), which is also provided in the INLA package. The CPO of observation i is the predictive density of the ith observation given the rest of the data Y–i(1) that excludes the ith observation:
\mathrm{CPO}_{i}=\pi\left(Y_{i}^{(1)} \mid \boldsymbol{Y}_{-i}^{(1)}\right) .
To assess the overall predictive quality of the model being considered, the logarithm of the pseudomarginal likelihood (LPML) (Geisser and Eddy 1979) can be computed,
\mathrm{LPML}=\sum_{i=1}^{n} \log \mathrm{CPO}_{i}.
A scaled version –LPML/n is known as the cross-validated log-score (Gneiting and Raftery 2007). A larger value of LPML indicates a better predictive model. The difference of two models in LPML is the logarithm of the pseudo-Bayes factor (PsBF) (Dey, Chen, and Chang 1997; Geisser and Eddy 1979). The asymptotic distribution of PsBF (Gelfand and Dey 1994) may be used to calibrate PsBF in a similar way to calibration for Bayes factors (Kass and Raftery 1995): a difference of 1–2 indicates strong preference and more than 2 will be decisive.
3.5. Predictive performance
Not considering administrative costs, the premium of a customer with a given set of covariates is the predicted healthcare expense. The predictive performance of models can be evaluated by using hold-out data. Commonly used measures are mean absolute error (MAE), mean absolute percentage error (MAPE), and root mean squared prediction error (RMSPE) (e.g., Frees, Jin, and Lin 2013). A more recent measure by Quiroz, Prates, and Rue (2015) brings randomness into selecting training and testing data sets. This approach can be applied to all predictive accuracy measures. Taking RMSPE as an example, the process has four steps:
-
Randomly select V out of the n observations to be the testing data and the rest to be the training data.
-
Fit proposed models on the training data.
-
Make predictions on the testing data using the posterior mean of the parameters and obtain RMSPE for each fitted model
\mathrm{RMSPE}=\sqrt{\frac{1}{V} \sum_{i=1}^{V} d_{i}^{2}},
where di is the prediction error of the ith testing data.
-
Repeat steps 1–3 M times, and take the average of the M resulting RMSPE values as the mean RMSPE (MRMSPE) for each model.
The same procedure can be applied to get mean MAE (MMAE).
The variation of each accuracy measure is also of interest. The standard deviation from the M replicates for each measure implies the stability of the performance under the measure. Smaller standard deviation is preferred.
Other measures for predictive modeling comparison such as Gini or lift score could also be used, if the goal of the prediction is ranking.
3.6. Geographic rating
Geographic ratings can be defined based on the two-part model, where the structured spatial effects from both parts contribute. In the logistic part, the spatial random effects γ(1) are the zipcode (or county) level adjustments on the probability of having non-zero expense for patients with the same covariate vector. The adjustments take effect on the scale of the log odds. In the lognormal part, the spatial random effects γ(2) are the zipcode (or county) level adjustments on the log scale of the expense if the expense is positive. Ideally, the two effects should be combined to give a single adjustment for each region in geographic rating.
Geographic ratings can be defined based on the two-part model, where the structured spatial effects from both parts contribute.
We propose a method motivated from the prediction of the model. Given the covariates of patient i, the mean healthcare expense is predicted to be
\hat{\mu}_{i}=\hat{\mu}_{i}^{(1)} \exp \left[\hat{\mu}_{i}^{(2)}+\hat{\delta} / 2\right], \tag{3.7}
where and are estimates of and in models (3.4)–(3.5). The additional term δ̂/2 is due to the expectation of a log-normal random variable with variance δ on the log scale. We need to transform the individual level prediction to a regional level adjustment for ease of practical operation as needed in geographic rating.
It is clear in model (3.5) that the region level adjustment in is simple due to the log link—just a scale of exp The region level adjustment in is not readily available as seen from model (3.4): since is on the scale of log odds, the impact of the spatial random effect depends on the individual covariates Xi, Zi. We propose to average over all individuals in each region to form a regional level adjustment factor on the probability of non-zero expense. For each region r, we take the mean of the linear predictor in (3.4) over all the observed individuals in this region to form a region level linear predictor. In particular, let be the regional average of over all i such that si = r. This regional level linear predictor is then combined with the region level spatial random effect to form a regional level probability of non-zero expense for region r
\hat{\phi}_{r}=\operatorname{logit}^{-1}\left[\bar{\eta}_{r}+\hat{\gamma}_{r}^{(1)}\right] \text {. }
We propose to use as the region level adjustment in place of in (3.7). Combining the two parts, the proposed region level geographic rating adjustment for region r, r = 1, . . . , R, is
\rho_{r}=\hat{\phi}_{r} \exp \left[\hat{\gamma}_{r}^{(2)}\right] .
This adjustment is a multiplicative effect in predicting the healthcare expense that is applied after the individual covariate effects. It combines effects from both parts of the two-part model. In the case where a large proportion of policyholders in a region had no expense but the remaining policyholders had very high expenses, the effect obtained from the log-normal part exp will be very high, but it will be downweighted by the effect from logistic part which would be much smaller.
4. Illustration
As an illustration, the two-part model was fitted to the simulated data described in Section 2 with the logit link in the first part and the identity link on the log scale in the second part. The effect of age was set to be nonlinear in both parts. Although INLA offers completely nonparametric specifications of nonlinear effects through random walk priors, we chose to describe the nonlinear effect with basis spline regression, in which case, the coefficients of the basis are estimated the same way as those in linear effects, and the computing cost is much lower. The spline basis was constructed with the bs function in R package splines, and a sum to zero constraint was imposed on each basis such that the intercept in the model becomes identifiable. The degrees of freedom of the spline basis could be chosen with the DIC or LPML, which is beyond the scope of this manuscript. In our analysis, we used cubic splines with 5 degrees of freedom (and 2 internal knots), which provided sufficient flexibility in recovering the true curve.
The mean components of the two-part model (3.4)–(3.5) are
\begin{aligned} \operatorname{logit}\left(\mu_{i}^{(1)}\right)= & \beta_{0}^{(1)}+\beta_{1}^{(1)} G_{i}+\beta_{2}^{(1)} I_{i}+B_{i}^{\top}\left(A_{i}\right) \theta^{(1)} \\ & +\gamma_{s_{i}}^{(1)}+\epsilon_{s_{i}}^{(1)}, \end{aligned}
\mu_{i}^{(2)}=\beta_{0}^{(2)}+\beta_{1}^{(2)} G_{i}+\beta_{2}^{(2)} I_{i}+B_{i}^{\top}\left(A_{i}\right) \theta^{(2)}+\gamma_{s_{i}}^{(2)}+\epsilon_{s_{i}}^{(2)},
where G is gender, I is log income, A is age, and B(Ai) represents the spline basis expansion of age. The spatial random effects and are possibly restricted by regulations. To investigate the impact of the regulations, we fit models with spatial effects at two different levels: zipcode level (correct specification with R = 1197) and county level (misspecification with R = 88). The models are referred to as the zipcode level rating model and the county level rating model, respectively. As the data were generated with zipcode level spatial effects, county level rating is less optimal than zipcode level rating, but may still be better than no geographic rating.
Since the smoothing effects are decomposed into several linear effects, the hyperparameters θ(1) and θ(2) are reduced to (τγ(1), τε(1)) and (τγ(2), τε(2), 1/δ), respectively. The priors for these hyperparameters are set on logθ(1) and logθ(2) in INLA as gamma distributions with shape 1 and scale 20,000. The priors for (β(1), β(2), θ(1), θ(2)) are normal with some mean μ and precision τ which are typically unequal to the default values. Users can specify values of priors μ and τ through the inla function in the INLA package. Examples are given in the supplemental code[1]. The structured random effects and account for a smooth geographical surface across all the rating areas while the unstructured random effects and capture the heterogeneity across the rating areas.
4.1. Statistical analysis
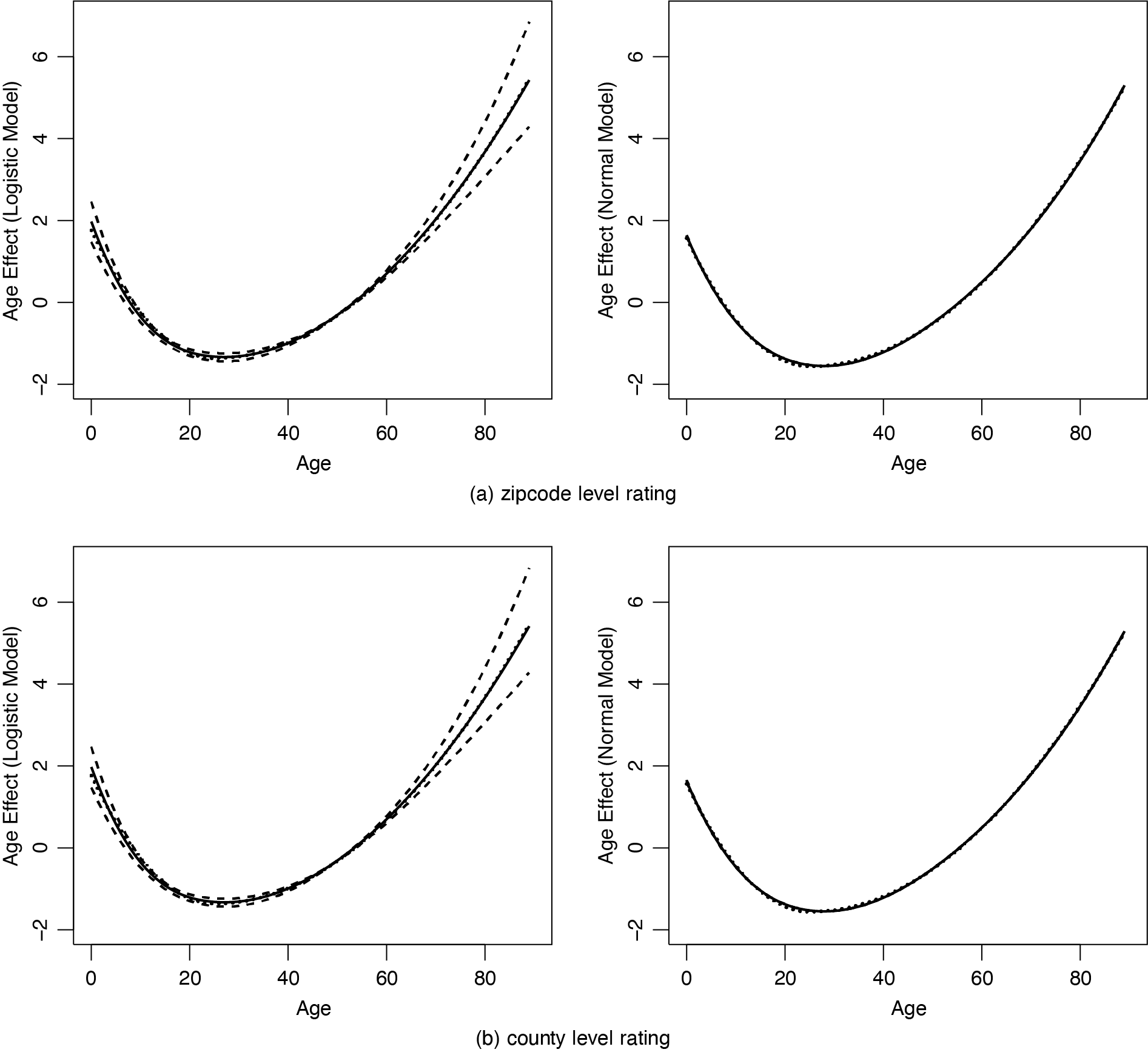
Posterior means, standard errors, and 95% credible intervals of the fixed effect coefficients are summarized in Table 2. With such a large sample at the individual level, these effects are all estimated quite accurately, very close to the true values (2, 0.1, 1) and (6, 1, 0.4) in the logistic part and log-normal part, respectively. The uncertainty in estimation is much higher in the logistic part than in the log-normal part, because this part contains less information due to the binary nature of the response. The effects estimated from the zipcode level rating model are very similar to those from the county level rating model, except with higher bias for the intercept and higher standard errors for the two coefficient parameters (gender and income) in the log-normal part. The estimated nonlinear effects of age are shown in Figure 3, which recover the true curves very closely in both parts of the model. Again, the uncertainty is much higher for the logistic part than for the log-normal part, and the results from models with different geographic rating levels are very similar.
_and_county_leve.png)
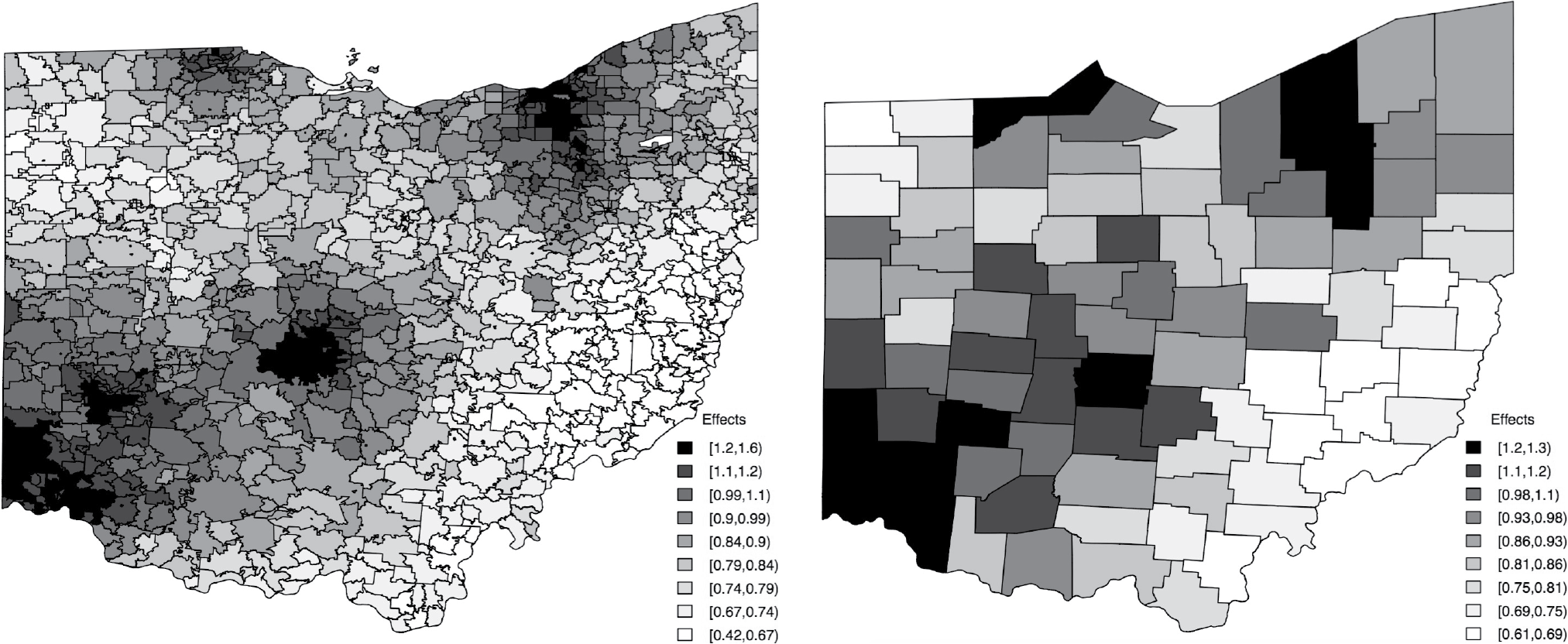
The posterior mean of the spatial effects in both parts, and are shown in Figure 4 using 9 levels of gray scales categorized by their quantiles, with darker colors indicating higher spatial effects. For models with zipcode level and county level spatial effects, the overall color patterns of the estimates are very similar to that of the true effects in Figure 6 in Appendix A. Urban areas are estimated to have higher effects than rural areas. Nonetheless, the zipcode level spatial effects vary more smoothly over space due to its much finer resolution than the county level spatial effects. Further, the county level spatial effects have a much smaller magnitude than the zipcode level spatial effects, because the former is coarser so that zipcode effects within the same county get averaged. The finer resolution of zipcode spatial effects, if allowed by regulations, allows for improved predictions over territory rating methods based on counties or even bigger territories as shown in Figure 1.
_and_county_level_.png)
To compare rating models with or without spatial effects, we fit several variations of the two-part model by dropping the structured spatial effects and/or the unstructured random effects at both zipcode and county levels. Model 1 has neither structured nor unstructured effects; Model 2 has zipcode level unstructured effects but no structured effects; Model 3 has zipcode level structured effects but no unstructured effects; Model 4 has both structured and unstructured effects at zipcode level; Model 5 has unstructured effects but no structured effects at county level; Model 6 has structured effects but no unstructured effects at county level; and Model 7 has both structured and unstructured effects at county level. Estimation results from Model 4 and Model 7 are reported in Table 2 and Figures 3–4. The DIC and LPML for all seven models are summarized in Table 3. Some numbers appear identical in the table only because of rounding. Model 1, with no spatial component, is clearly out-performed by all others. Among the zipcode level rating models, the correctly specified Model 4 is the winner in both parts, but its advantage is much clearer in the log-normal part than in the logistic part in both DIC and LPML. The county level rating models are quite competitive in the logistic part, but even their best competitor, Model 7, is far inferior to Model 4 in the log-normal part in both DIC and LPML. The comparison suggests that, if the spatial effects in the data were at a finer scale like zipcode, which is often a reasonable assumption, then modeling it at a larger scale due to regulation restrictions is not ideal but can be much better than not modeling the spatial effects at all.
The models we considered are only a few choices from many possibilities. Other models using a Tweedie distribution combined with spatial random effects could be competitive for a real data where the true distribution is unknown. The models we presented are for illustration purposes, and the model with the correct specification is expected to perform the best given the data size.
4.2. Actuarial implications
To compare the predictive performance of the models in pricing, we use MMAE and MRMSPE computed with V = 5,000 and M = 100. That is, instead of fitting the model to all 20,000 observations, at each replicate, we randomly split the data into a training data of 15,000 observations and a testing data of 5,000 observations. MAE and RMSPE are obtained on the testing data based on the fit to the training data for each model given each replicate of training/testing division. MAPE is not used because the true expenses could be exactly zero.
Table 4 summarizes the MMAE and MRMSPE from 100 replicates. Model 1 which has no geographic rating component has the largest prediction errors, the zipcode level rating models (Models 2–4) have much smaller errors, and the county level rating models (Models 5–7) fall in between. The standard deviations of both measures have the same pattern. Within the zipcode level rating models, the correctly specified model (Model 4) does better, but the differences are relatively small. The three county level rating models have very close errors. These errors and their standard deviations have units in dollars. They reflect the accuracy of pricing based on the model given covariates. The results suggest that rating models with spatial effects do improve the predictive power, and if modeling them at the zipcode level is not allowed or possible, modeling them at the coarser, county level is still well worth it. Moreover, note that around 200 out of 1197 zipcode areas have no observations in the training data at each replicate, but the zipcode level rating model can still estimate the spatial effect of these areas by using information from their neighboring areas.
Since healthcare expenses have a probability mass at zero and are highly skewed to the right, the predictions on zeros and extremely large expenses could have very different performance across different models. Thus, it may also be valuable to compare the predictive power within each observation group categorized by the values of the expenses. Eight brackets are created based on the percentiles of the expenses. The first bracket are all zero which comprises of about 20% of the data, and the last bracket contains expenses over $2,000, which also comprises of about 20% of the data on the right tail. Table 5 summarizes the MRMSPE of Models 1, 4, and 7, and their standard deviations from 100 replicates. In bracket 1, Model 7 gives the lowest MRMSPE with a small edge over Model 4, but in all other brackets, Model 4 is the clear winner with much reduced MRMSPE and standard deviation. Both Model 4 and 7 do much better than Model 1. In particular, in the last bracket with large expenses, which is of most concern to insurers, the MRMSPE of Model 4 is about less than a half of that of Model 7, and less than a quarter of that of Model 1.
Finally, we plot the maps of geographic ratings ’s proposed in Section 3.6 for Ohio in Figure 5, from the zipcode level rating model (left) and the county level rating model (right). As expected, the maps have patterns very similar to those of the structured spatial effect maps in Figure 4 because the estimated probabilities of non-zero expense at all zipcode areas or counties have a small range. The two maps in Figure 5 are similar in darkness pattern, but their scales are very different; the range is (0.42,1.6) from the zipcode level rating and (0.61,1.30) from the county level rating. This means the former has much more flexibility than the latter to adjust the premium to account for the spatial variation that cannot be explained by the fixed effects such as gender, age, and income. Compared to the map in Figure 1 which has solid boundaries, the zipcode level rating in the left panel of Figure 5 changes in a much smoother way over all the zipcode areas on the whole map. The smoothing borrows strength from neighboring zipcode areas locally, and eliminates the need for justifying boundary lines in the traditional method.
_and_coun.png)
5. Discussion
We proposed a new geographic rating method based on a two-part model with a spatial random effect in each part of the model. The method removes the solid boundaries between traditional rating areas and regards each basic geographical region such as zipcode area as an individual rating area of its own. The structured spatial random effects enforce smoothness on the resulting ratings at the basic region level. The method can be carried out with the computationally efficient INLA package in a Bayesian framework without the standard MCMC. The ratings can be modified frequently upon the arrival of new data. As the two-part geoadditive model gives more precise predictions of the expenses of interest, the method has the potential of substantial profit gains for insurance companies if adopted. Even when the zipcode level rating is restricted by regulations, modeling the spatial effects on a coarser spatial scale (e.g., county level) still gives better rating than not modeling them in both the statistical and actuarial sense. The methods can be applied to property and casualty insurance, in particular personal markets which may have more flexibility in geographic rating.
In real application, some practical issues will need to be considered. For example, some healthcare expenses due to inpatients or emergency room usage may be too extreme to be observed from lognormal distributions. Extreme value analysis may help to address the events at the tail. A three-part model can be constructed with a logistic model for zero or nonzero expense, a log-normal model for moderate-sized expenses, and an additional extreme model for overly large expenses. Another issue is how the INLA package can handle big data. If the method is applied to data from multiple states, the number of policies, as well as the number of zipcode area, increases significantly. The dimension of the neighborhood structure matrix increases very fast which may cause some difficulties in computation, so application under the big spatial data would be challenging. The two-part model with spatial random effects is a general modeling framework, which does not restrict specific distributional assumptions to the ones illustrated in our demonstration. The lognormal distribution of the nonzero expenses could be replaced with gamma distributions (the computational advantage from INLA will be limited by the distributions implemented in it, though). The compound Poisson distribution or Tweedie distribution may be combined with spatial random effects in principle. When the individual data has uneven exposure in practice, the exposure can often be included as an offset in the model.
Acknowledgment
The authors thank Drs. Emiliano Valdez and Jiafeng Sun for stimulating discussions on the actuarial implications of the proposed methods.
_and_simula.png)