


1. Background
Workers’ compensation insurance covers all work-related injuries and illnesses with medical care, wage replacement, and death benefits. In California private and public employers are required to have workers’ compensation insurance for their employees. Most public entities self-insure their exposures below a Self-Insured Retention (SIR) and insure their exposure above the SIR through an excess workers’ compensation insurance policy. The SIR is the amount specified in the insurance policy that must be paid by the insured before the excess insurance policy will respond to a loss. Public employers may purchase excess insurance through entities such as the California State Association of Counties-Excess Insurance Authority (CSAC-EIA).
There has been some interest in alternative reserving methodologies for the calculation of future payments for the expected lifetime of the injured worker using a table of mortality rates. The State of California requires self-insured plans to estimate future medical reserves on permanently disabled workers as a product of the average of the last three years’ medical costs and life expectancy of the injured worker, based on the U.S. Population table.
To legally self-insure, employers must comply with the reserving policy of the California Office of Self-Insured Plans (OSIP). Reserves are established to cover the future medical costs that are expected for each claimant, including costs associated with expected surgeries, prescription drugs, rehabilitation, physical therapy, etc. The statutorily established reserving methodology for Permanent Disability (PD) claims (State of California 2011) requires that Future Medical (FM) reserves for claimant i at time t be calculated as:
Future Medical (FM) Reservesi,t=[13∑k=t−1k=t−3(Medical Paymentsi,t)]∗(Life Expectancyi)
In this model life expectancy depends only on the age of claimant i and is independent of time t. Historical medical payments may be adjusted to remove outliers and to include costs for known future procedures, where these are expected to be greater than the historical average. Permanent Disability (PD) is defined as any lasting disability that results in a reduced earning capacity after maximum medical improvement is reached.[1] Whether a disability is considered partial or total depends on the Permanent Disability Rating, a percentage that estimates how much a job injury permanently limits the kinds of work the claimant can do. A rating of 100% implies permanent total disability; a rating less than 100% implies permanent partial disability.
The OSIP reserving methodology requires that life expectancy be calculated using the most recent U.S. Life Tables (2011 for our analysis) separately for males and females, which is provided by the CDC/NCHS National Vital Statistics System (Arias 2015). The U.S. Life Tables provide mortality rates at each age for the U.S. population, and allow the derivation of an estimate of future life expectancy in the usual actuarial way, namely: where ėx is the complete expectation of life for an individual of age x and tpx is the probability that the individual will survive for t years. (See, for example, Dickson, Hardy, and Waters 2013.) Life expectancy is used in this model as a measure of duration to claim termination. A workers’ compensation claim may terminate due to death, recovery or settlement, although the latter two statuses are not common in the case of permanently disabled claimants. Because the U.S. Life Tables measure life expectancy for the population as a whole, including both healthy and disabled lives, they may not be representative of claims termination rates for PD claimants.
2. Prior use of survival models to estimate survival of permanently disabled populations
There are two major strands of research in this area: the workers’ compensation actuarial literature and the health services literature. There are a number of health services studies estimating the future lifetimes of injured workers, for example, Ho, Hwang, and Wang (2006), Sears, Blanar, and Bowman (2014), Sears et al. (2013), Liss et al. (1999), Lin et al. 2012, and Wedegaertner et al. (2013). These studies cover permanently disabled workers in different countries, industries and injury types. Cox proportional hazard and Kaplan Meier models are used in some (but not all) of these studies to compare the mortality hazard with that of a comparison population. Uniformly, the studies cited found that expected lifetimes of permanently disabled workers are shorter than those of standard populations.
Workers compensation actuaries frequently estimate future liabilities by some form of chain ladder projection. The lack of long duration data makes estimation of costs in “the tail” difficult. Several studies have tackled the issue of estimation of tail liability, including Sherman and Diss (2006), Jones et al. (2013), CAS (2013), Schmid (2012), and Shane and Morelli (2013). This has led Jones et al. (2013) to find that “adverse reserve development in older accident years [is] a persistent problem . . . traditional actuarial methods typically used to project “bulk” incurred but not reported reserves often fall short.” The authors go on to note that a mortality-based method of reserve setting can help address the causes of reserve misestimation. Despite some interest in the use of a mortality-based method for estimating future reserves, there is relatively little literature on this topic. Gillam (1993) tested whether injured worker mortality differed from population mortality. The Gillam study found that injured worker mortality was higher than population mortality under age 60, but equal between 60 and 74. The author calculates that the average pension of injured workers will be 1.6% lower than that calculated using the standard table, at a 6% discount rate. Gillam concludes that “higher mortality in these cases doesn’t make current reserves significantly redundant.” However, the study focused on the indemnity cost (effectively a disabled life pension) rather than the medical cost. Jones et al. (2013) note that medical trend is one reason for persistent reserve understatement in recent years. Unfortunately, Jones et al. do not compare their reserve estimates based on discounted contingent cash flows with traditional triangle based estimates, although they list a number of advantages of a mortality-based method.
3. Hypothesis
If mortality of disabled lives is higher than that of the standard population, by using a population life table rather than a disabled life table the current methodology potentially overstates claimant longevity as well as the FM Reserves on PD claims. We tested the null hypothesis stating that termination rates in the claimant population are equal to the termination rates according to the current U.S. Life Table. Additionally, we developed a specific disabled termination table based on PD claimant data. While another table would be better than the U.S. Life Table if the null hypothesis is rejected, we demonstrate that the empirical termination table is better suited for the FM PD reserving calculation. Because our data includes a number of different variables, we have developed termination rates that depend on covariates, enabling the workers’ compensation claims adjuster to estimate duration to termination more accurately for a specific claimant.
If mortality of disabled lives is higher than that of the US population, then by using a population life table rather than a disabled life table the current methodology potentially overstates claims reserves. We tested the null hypothesis that termination rates in the claimant population are equal to the termination rates according to the current U.S. Life Table and found that experience termination rates of the sample population significantly exceed those of the population table.
4. Dataset description
Our dataset was provided by CSAC-EIA (the excess insurance carrier) which accumulates its data from third-party administrators of workers’ compensation claims as well as its own data. The data reflected detailed loss calculations for program years 1967/68 through 2015/16, evaluated annually from June 30, 1999 to June 30, 2016; there was little data prior to 1995. Although the data was provided by an excess insurer, all claims were recorded by the excess insurer are on a first dollar basis, whether or not the claim was a primary claim or an excess claim. While smaller entities may be more likely to seek excess insurance, we have no reason to suspect that this selection results in bias in terms of claimant terminations. The data included both indemnity and medical claim histories for all claim types (medical only, temporary partial, temporary total, permanent partial, and permanent total).
Our initial data set consisted of 1,124,473 claim records for 121,110 unique claimants. Each data record corresponded to a different evaluation year of the claim, so that there were multiple records for each claimant depending on the date of the initial occurrence, how many years the annual claim evaluations were performed by an adjuster and when the claim eventually “closed.” The extract date was June 30, 2016. Claims remaining open at the extract date were considered “censored.”
The original dataset included 126 variables. Some of these variables were duplicate columns, some had data quality issues, and many related to indemnity reserving. Table A.1 in the Appendix provides a summary of 18 variables from the original dataset that we considered for our analysis.
5. Data processing
In order to perform our survival analysis we processed the dataset to include only those variables that were necessary for our analysis, as well as creating several derived variables. The data cleaning and mapping steps are illustrated in Figure 1.

In order to use the data for our PD survival analysis, it was first necessary to identify all PD claims (both permanent partial and permanent total) and their accompanying claim histories. Some claims were identified as temporary disability (TD) while they were undergoing initial evaluation and rating, and later changed to permanent disability after further examination. A claim classified initially as TD and later re-classified as PD was re-classified as PD from inception. There was no single (reliable) variable indicating that a claim was a permanent disability. Therefore, we combined several variables from the original dataset (Claim Type, PD Incurred Flag, and Future Medical Award) to identify PD claims. This reduced the number of records from over 1.1 million in the original dataset to 146,208 records and 19,053 unique claims in our analysis dataset.
The quality of the data in the analysis dataset was generally good, aside from three variables: Entity Group, Body Part and Gender.
-
Entity Group: Because of the large number of different occupations we started with a higher level aggregation of occupations, labeled Entity Group, in order to reduce the dimensionality of the Occupation variable. However, the Entity Group data field provided with the original data was found to have many errors in terms of its mapping from the variable Occupation; over 50% of the occupations were coded as the ‘General Government’ occupation class. (For example the occupation ‘Police Officer’ was frequently coded as the ‘General Government’ entity group, when it should correctly have been coded as ‘Police, Corrections, and Security’ entity group.) We created our own mapping using keywords found in various occupation descriptions to re-code the occupations into 15 Entity Groups.
-
Body Part: The original data file contained a numeric body part code to describe the body part(s) involved in the injury, but the field was poorly coded. The original data files had a Body Part description variable, a Nature of Injury variable, and a Cause of Loss variable which allowed us to re-map the body part descriptions to the appropriate body part code.
-
Gender: The Gender variable had a large percentage of missing values (19%). We tested the effect of missing values using a data imputation routine described in the next section.
In addition, we created a new variable to indicate the severity of the injury or illness in terms of the likely cost of medical treatment. The new variable, labeled “Severity,” is the average annual claim amount paid during the duration of the claim. (Note that this definition of Severity is specific to our analysis. Although similar, it is not the same as the traditional general insurance definition of severity.) We also created a new variable “Duration” which is the length of time from Date of Loss (DOL) to Date Closed.
Next, we removed all variables that would not be used in our analysis in order to create our analysis dataset. This was done for ease of use as well as to improve the organization of our data. The variables in the analysis dataset are shown in Table 1.
Finally, multiple years of claims were merged into a single line per claim.
5.1. Data imputation for gender
The ‘Gender’ variable contained the values ‘Male,’ ‘Female’ and ‘Unknown/Other.’ We treated the ‘Unknown/Other’ values as missing. We considered two options for handling missing data: delete the rows with missing gender values, or use imputation methods to predict the gender of the individual. We found that approximately 19% of the unique claims have the ‘Unknown/Other’ value for gender. Deleting the claims with missing gender values would significantly reduce our sample size. We therefore imputed the missing gender values using a logistic regression-based routine in R called MICE (Multivariate Imputation by Chained Equations) (For description of the routine and its application see, for example, van Buuren and Groothuis-Oudshoorn (2011, 2017) and Analytics Analytics Vidhya (2016)). MICE uses observed values to fill in missing values on a variable-by-variable basis using logistic models for each variable and assuming that the gender values are MCAR (missing completely at random). It then takes our predictors and data with known gender values to find the most accurate model for imputing those with missing gender values through a parametric and stochastic search algorithm. The algorithm imputes incomplete values by generating ‘plausible’ synthetic values given other columns in the data; each incomplete column has its own specific set of predictors. The result of running the MICE algorithm is a derived Gender variable.
6. Methodology
6.1. Survival analysis
In many areas (such as biomedical, engineering, and social science), we are often interested in knowing duration until an event occurs. Statistical analysis dealing with lifetime data is known as survival analysis. What makes these lifetime data sets unique and challenging to analyze is the presence of censored information. Time until failure is not observed for all subjects during the study period, due to the fact that some subjects may be dropped out or lost to follow up. Our dataset contains right censored data, in which the event in question occurs at an unknown time after censoring. We also assume that censoring time is independent of survival time. Some important notation:
-
Survival function: S(t) = P(T > t), which gives the probability of surviving beyond time t.
-
Failure function: F(t) = 1 – P(T > t), which is the probability of failing before time t.
-
Hazard function: h(t) = f(t)/S(t), which is the instantaneous rate of death at time t, given that the claimant is alive at time t.
-
Cumulative hazard function: H(t) = t0h(s)ds, which gives the cumulative rate of death up to time t, given that the claimant is alive at time t.
6.2. Kaplan-Meier estimator
Kaplan-Meier is a well-known method to estimate the survival function from given lifetime data. The overall survival time is divided into small intervals (ti) by ordering the distinct failure times. Within each interval, the survival probability is calculated as the number of lives surviving over the number of observed lives at risk. A simple estimate of Pr(T > ti|T ti) is:
number of subjects surviving beyond ti number at risk at ti=Yi−diYi
An estimate of S(t) is where Yj is the number of subjects alive at time tj and dj is the number terminating at time tj.
Subjects who have died, dropped out, or who have unobserved survival times are not at risk. Subjects that are considered as censored are counted in the denominator. Probability of surviving up to any point is estimated from the cumulative probability of surviving each of the preceding time intervals. A limitation of this method is that towards the end of the experiment, there are fewer observations, which makes the estimation less accurate than at the beginning of the study.
6.3. Cox proportional hazards model
Cox regression (proportional hazards or PH model) is an extension of regression techniques in survival analysis that allows us to examine the effect of multiple covariates on the hazard function. It is one of the most common models applied to survival data because of its flexible choice of covariates and ease of interpretation, as well as being fairly easy to fit using standard software. Let T be the continuous lifetime variable and X be a p × 1 vector of fixed covariates. The hazard function for T given X takes the form:
h(t∣X)=h0(t)r(X;β)
In the above equation, ho(t) is a baseline hazard function. The Cox regression function does not have any specific distribution assumption. Instead, r(X; β) is a function of known form which, if taking the natural logarithm ln(r), is assumed to be linear with coefficients β defined as r(X; β) = eβ′X. This exponential form is convenient and flexible for many purposes allowing, among others, for the hazard function to have positive values (which is always the case by definition). Notice that no intercept term is included in β′X. Instead, it is subsumed in ho(t). The covariates are fixed at inception of the study and do not vary with time. Hazards are always positive. The model has two separate components: the baseline hazard function and the coefficients for covariates. Values of β can be estimated using the partial likelihood method (Kleinbaum and Klein 2012). However, the proportional hazards and functional form (linear combination of covariates) are strong assumptions which require careful examination (diagnostics). Extensions of Cox models, such as a time-dependent model or stratified Cox regression, can be applied in cases where the PH assumption is violated. The time-dependent model is beyond the scope of this paper. However, we consider a stratified Cox regression as one of our final models.
Assume covariates X1, X2, . . . , Xp satisfy the PH assumption while a covariate Z does not. The stratified Cox model is given by:
h(t∣X)=hog(t)eβ′X
where g = 1, . . . , n are levels within covariate Z. Notice that the set of coefficients for each level is the same. The only difference is the shape of the baseline function for each level. The stratified Cox model allows the underlying baseline function to be varied across the levels by incorporating the covariate that violates the PH assumption into the baseline.
6.4. Model building and validation method
We created two different Cox models, one for imputed data and another for non-imputed data. In both cases, we randomly selected a training set consisting of 70% of observations with the remaining observations forming the validation set. The metric for model validation is the concordance index (c-index/c-statistic), which is a generalized version of area under the Receiver Operating Characteristic curve (ROC curve). The concordance index is equivalent to rank correlation, where rank of predicted risk using the model for actual low risk observations (risk of experiencing the event) would be small while rank of predicted risk for high risk observations would be large. Therefore C > 0.5 implies good predictive power, C = 0.5 implies predictive power is equivalent to 0, and C 0.5 implies model does a poor job at prediction.
6.5. Actuarial methods
The 2011 Life Tables provide values of the one-year probability of death qx from age x to x + 1. Workers compensation claims terminate for reasons other than death. The OSIP methodology requires the use of the mortality probabilities to estimate the future claim duration, so the qx values represent all terminations, not just death. We estimate empirical values of qx from the data as where:
-
dx = number of terminations between ages x and x + 1.
-
lx = number of claimants aged x
-
Cn = number of censored claimants
-
wx = number of claimants terminating during the year for any reason, including claims that are censored (denoted Cn), or still open at the end of the observation period.
-
In our model wx = dx + cx
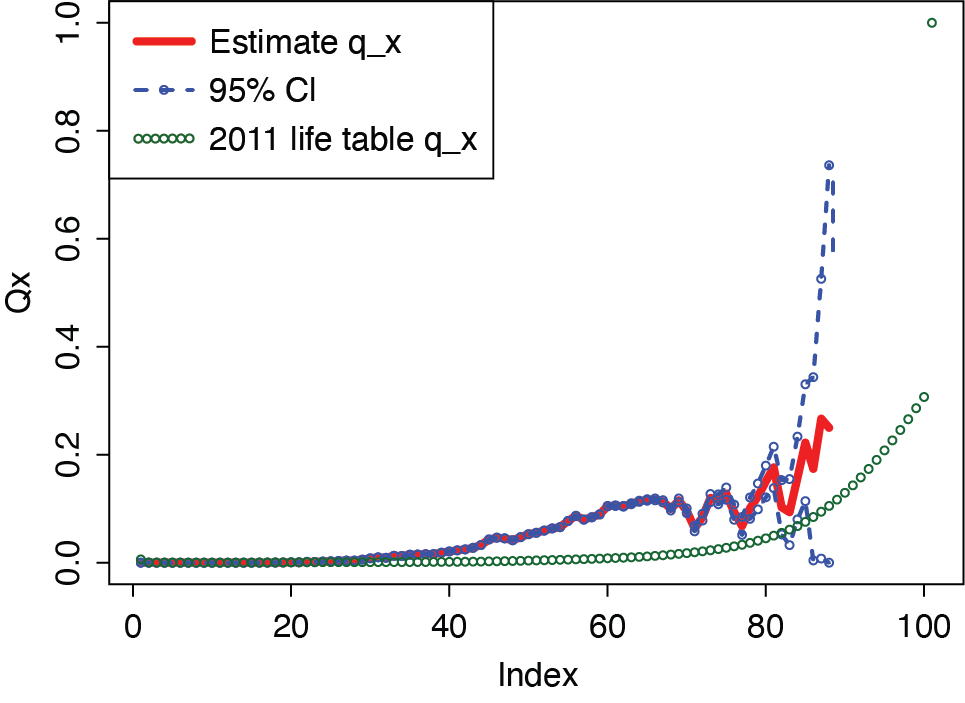
In order to compare directly the modeling dataset to the 2011 U.S. Life Table we iterated through every claim and created vectors tracking the number of individuals in the system, the number that were censored (open) and the number observed (closed) at every age in the range 0 to 100, in order to match the 2011 Table’s range. To determine whether an individual was censored/observed and at which age, we used the indicator variable, the Age at DOL and the duration of each claim. By adding duration to the Age at DOL, it could be determined at what age every claim terminates, and by the indicator variable whether termination was censored or observed. The first array, denoted lx, tracks the number of claims in the system at every age, with an initial count of 19,053 (the total number of claimants). The other two arrays, cx and dx respectively, count the number open (censored) and closed (observed) claimants at each age. With these arrays, it is possible to calculate estimates of given that wx = dx + cx, as defined above. is now an array of probabilities of claim closure for every age from 0 to 100. Finally we reduced the age range to 17 to 88 due to the lack of data outside of this range. The U.S. Life Table exists in both sex-specific and unisex forms. Below, we tested the consistency of our estimated with both the unisex table (Figure 2) and sex-distinct tables (Figure 3–4). It is clear that our estimated values diverged from those of the 2011 Life Table, thus implying that termination rates are higher in our data. In order to determine whether this divergence is significant, the 95% confidence interval for each age range was calculated by using Greenwood’s Approximation which estimates the variance of Kaplan Meier models, survival models equivalent to our values. In Greenwood’s Approximation,
.png)
.png)
.png)
This approximation allowed us to calculate the 95% confidence interval for as In Figure 2, the lower bound of the confidence interval falls above the 2011 tabular rate at all ages except the highest (above age 85) at which there are very few observations.
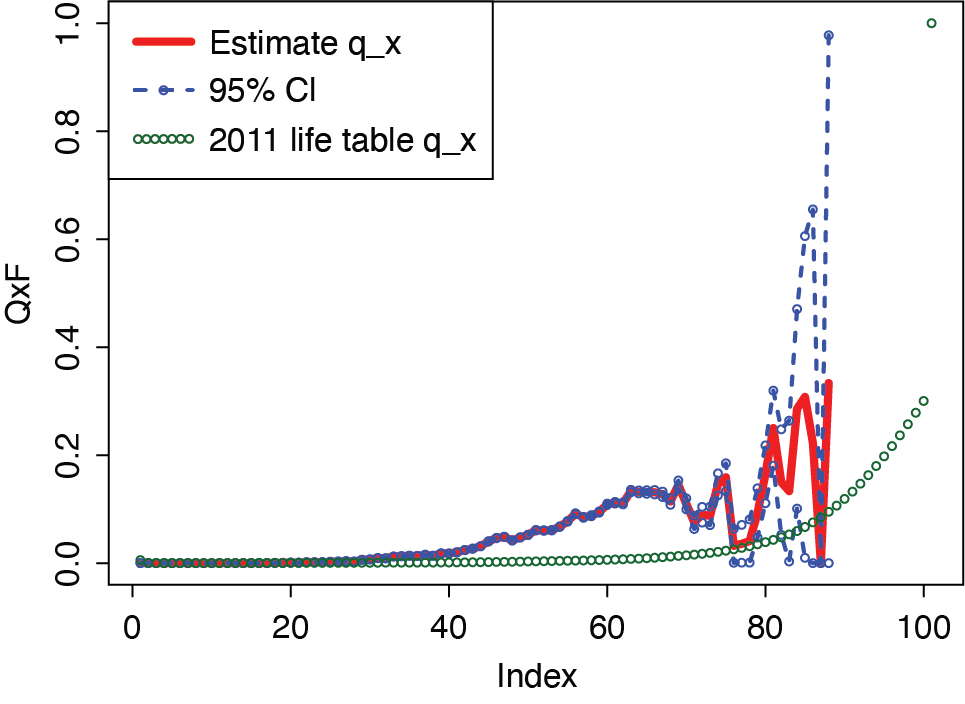
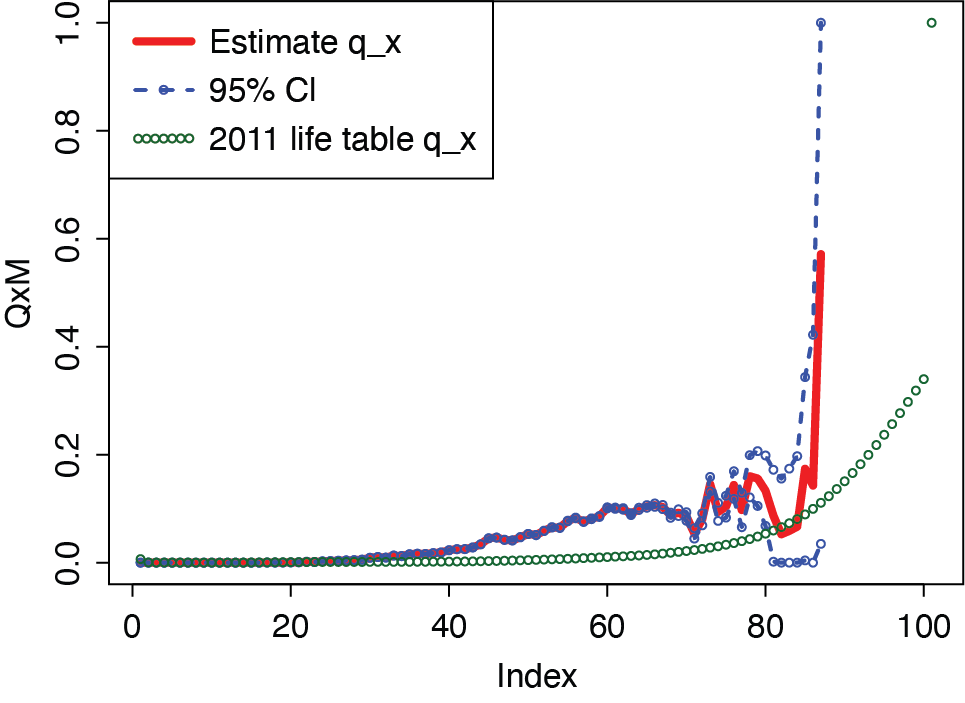
In Figures 3 and 4 we examined the values for males and females separately. The results were similar to those of the unisex table, with the exception that some estimated values are less than the tabular values at very high ages at which there are very few observations. We concluded that in the age range 35–75 termination rates for both males and females are well in excess of the 2011 tabular rates. We also performed a one-sided Kolmogorov-Smirnov goodness-of-fit test to test whether the distribution between the 2011 life table and the estimated is identical. Specifically, we compared the empirical distribution function between two samples given that we do not have an assumption for the distribution of the samples. We assumed two samples are from the common distribution versus the alternative hypothesis that the CDF (cumulative density function) of the estimated is greater than the CDF of the 2011 life table. Because the p-value was less than the level of significance, we rejected the null hypothesis, confirming our conclusion that termination rates for both males and females are greater than the 2011 life table rates.
6.6. Fitted actuarial models
Given that the 2011 U.S. Life Table does not represent termination rates of the workers’ compensation permanently disabled population, the question arises whether we can derive a better model for qx?
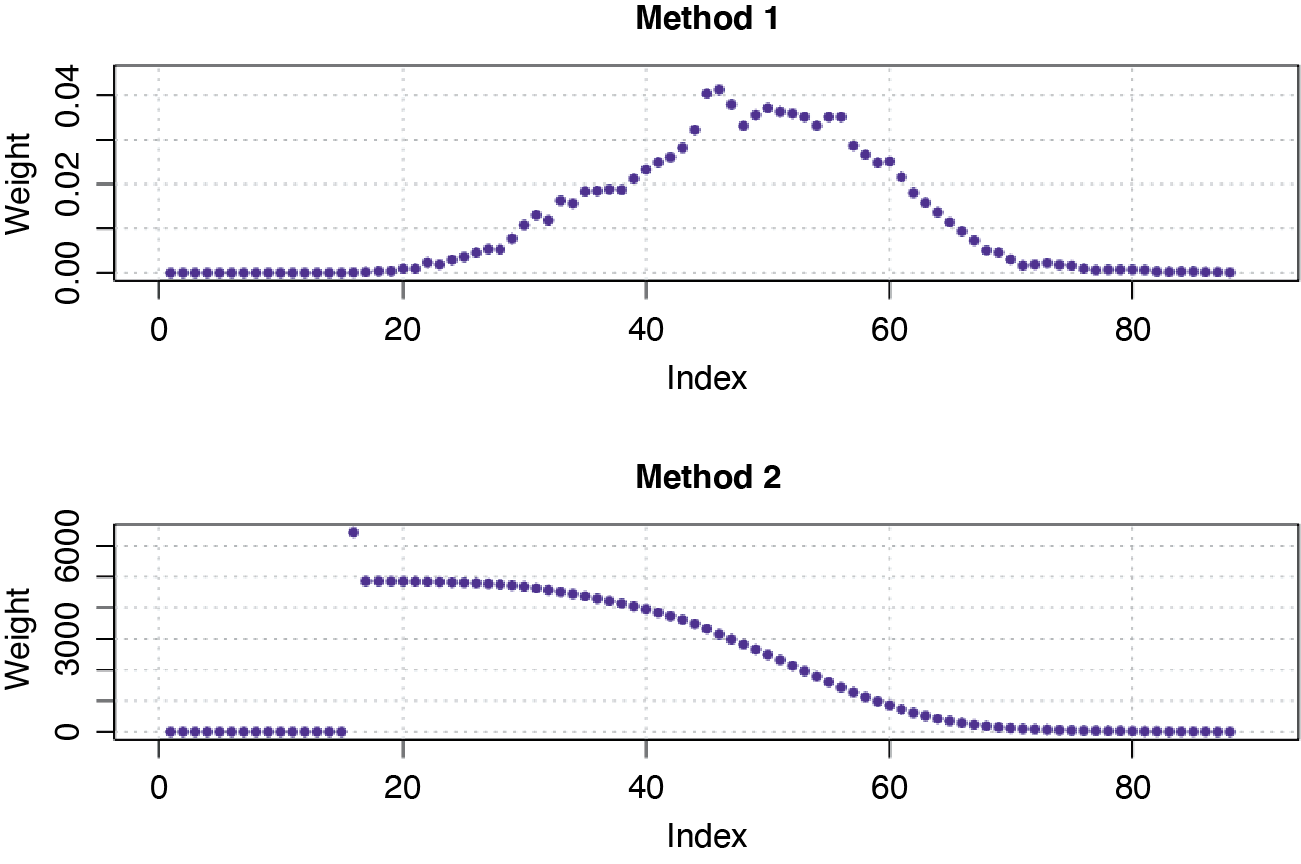
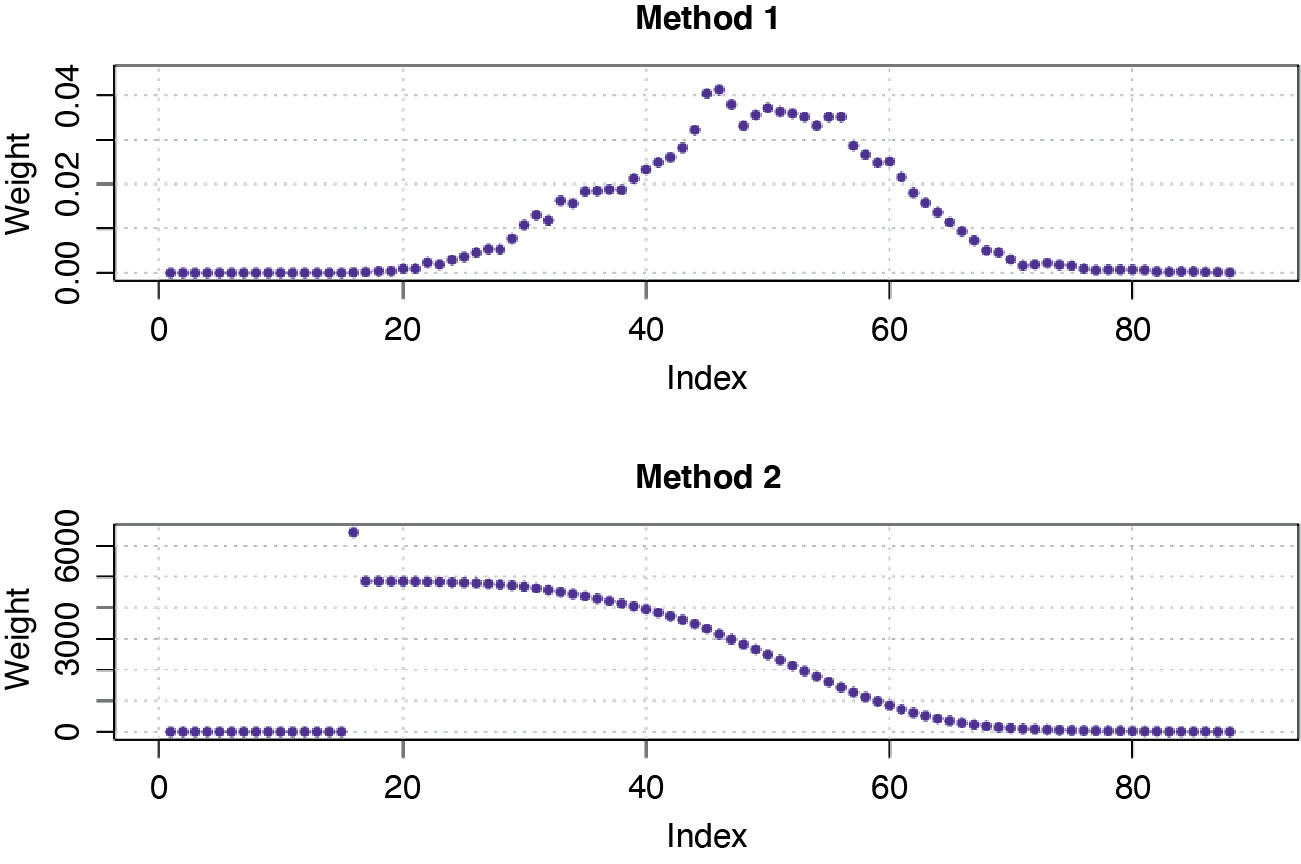
Note that all of the following regression models were tested assuming normal distribution errors and with two different types of weights included to represent the number of observations in each age interval. The two methods to determine the weights were:
-
Method 1: The weight for each age interval is the proportion of the number of claims within the corresponding interval to the total number of claims in the data.
-
Method 2: The weight for each age interval is the inverse of the length of each 95% confidence interval of the estimates.
We incorporated the weights into the regression models due to the observed pattern of heteroscedasticity (the constant variance in the errors is violated). Specifically, Method 2 allowed us to apply more weight to the observations with smaller standard errors as these observations carry more information in the data. In Figure 5 the two methods have different scales. The younger and older age intervals have relatively small weights in Method 1. For Method 2, early ages have higher weights, reflecting the lower variance at these ages, while higher ages are under-weighted, reflecting their higher variance.
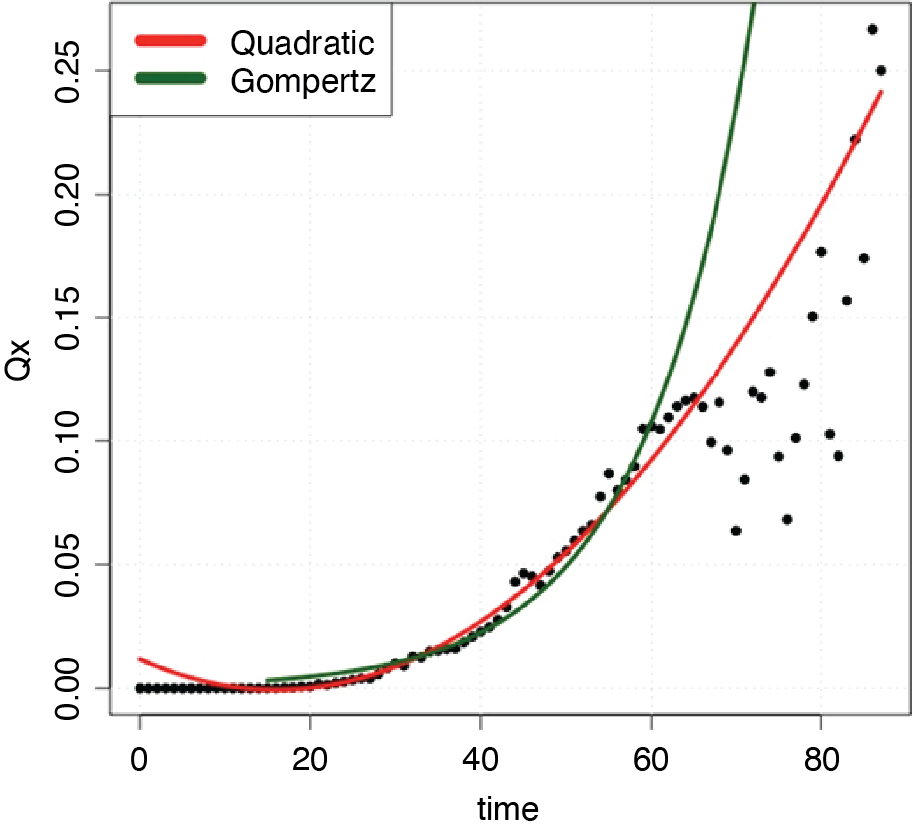
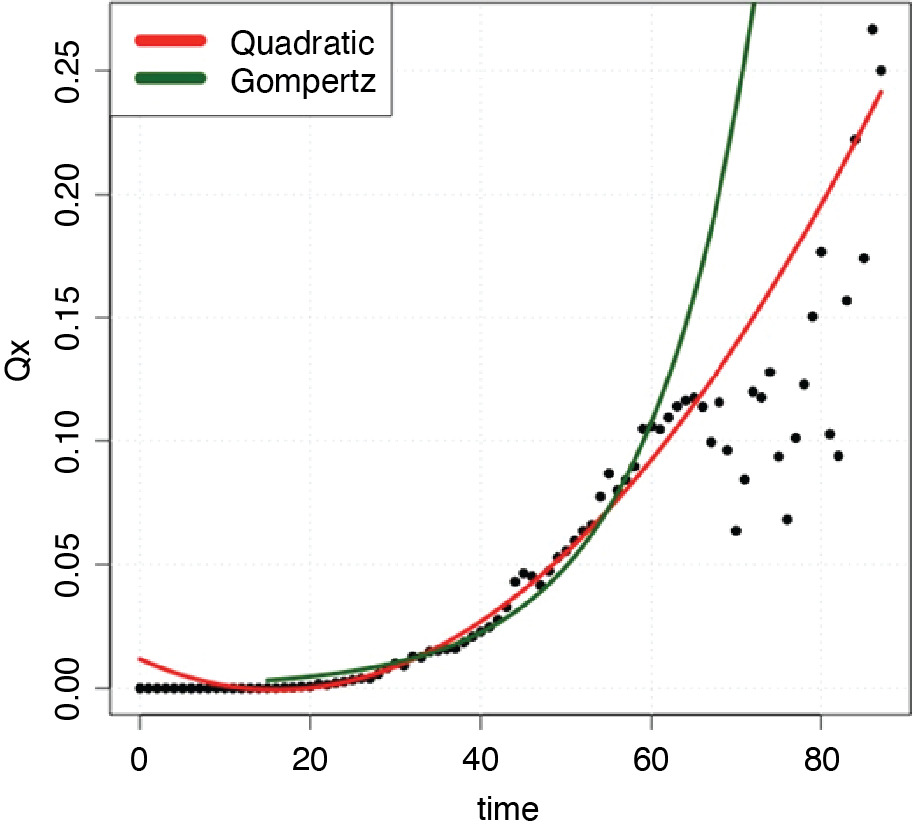
We first fitted a quadratic function because this form appears to fit the observed values. The best fit quadratic model which included the set of weights in Method 2 was = 0.0666 + 0.6289x + 0.2601x2, which was selected via the AIC (Akaike Information Criterion) model selection method. AIC is found by computing 2k – 2lnL̂, where L̂ is the Maximum Likelihood function and k is the number of free parameters to be estimated.
Next we considered fitting the Gompertz model, which is one of the most commonly used parametric survival distributions to model human mortality. The Gompertz model assumes that the hazard rates are exponentially distributed where the hazard rates are analogous to the life table values qx and are some parametric function of age (MacDonald, Richards, and Currie 2018). In the Gompertz model the hazard rate function, generally has the following form: where x denotes age of individual, and and qx are related as follows:
In this formula, the two parameters represent an age-dependent (β) and age-independent component (α). The log transformation of this hazard rate function is a linear function α + βx. We estimated the parameters of the Gompertz model by performing linear regression on the log transformation of the ’s. The diagnostic plots of the log transformation for normality confirmed that we could proceed with the linear regression. To select the best Gompertz model, we first computed the lognormal log-likelihood for the log-transformed response, then calculated the AIC value. The resulting Gompertz model has the following form: using the set of weights in Method 1.
The chosen Gompertz and quadratic models are shown in Figure 6, compared with the observed values for qx. The age range on the x-axis is determined empirically based on available data (ages 16 to 88). The y-axis contains the estimates, or the probability of claim closure for a given age, x. Both the Gompertz and quadratic models fit the data reasonably well up to age 60, although, as shown in Table 2, the quadratic model fits better (lower AIC value). Thereafter, the Gompertz model significantly over-estimates termination, as does the quadratic model above age 70.
7. The Cox model applied to imputed data
7.1. New grouping of entity, cause of loss, and body parts
Several covariates such as Entity Groups, Cause of Loss, and Body Parts are categorical with many levels. For example, the Body Parts variable contains 56 values that indicate the location of the injury. While the translation of the Body Part description into numeric values is convenient for coding purposes, Body Part is a nominal variable where levels do not have any natural order. A drawback of fitting Cox regression is model complexity: each covariate level costs a degree of freedom to estimate, whereas a majority of these levels are not significant. We therefore required a method to simplify the multi-level variables to a smaller number of groups. We applied the Kaplan Meier (KM) approach to re-group levels based on median survival time. We first applied KM to estimate the survival function to obtain median survival time. Second, we ranked median survival times in increasing order and re-grouped the original levels into four different groups. We then repeated this procedure for Entity, Cause of Loss, and Body Parts. Table 3 shows the new grouping of the Entity variable. (See Appendix A2 for groupings of the Cause of Loss and Body Parts variables).
The new grouping is based on the application of the KM method to the training set; we then applied the same groupings to the test set.
7.2. Stratified Cox model
The final model contains two interaction terms: interaction between Sex and Age at DOL, and between Body Parts and Cause of Loss. The Entity Group covariate did not satisfy the PH assumption, and we therefore created stratified Cox models for the different levels of Entity.
The functional form of the stratified Cox model is
ˆh(t∣X)=hog(t)∗exp[ˆβ1age+∑4j=2ˆτjIbody =j}+∑4j=2ˆγjI{CL group =j}+ˆβ3 severity +ˆβ4 sex +ˆβ5 years +ˆβ6 sex: years +∑4j=2ˆδjI{body =j}I{CL group =j}]
where I{CL group =j}={1, cause loss group =j(j=2,3,4)0, otherwise
I{body=j}={1, body =j(j=2,3,4)0, otherwise
g=1,2,3, and 4 levels within entity group.
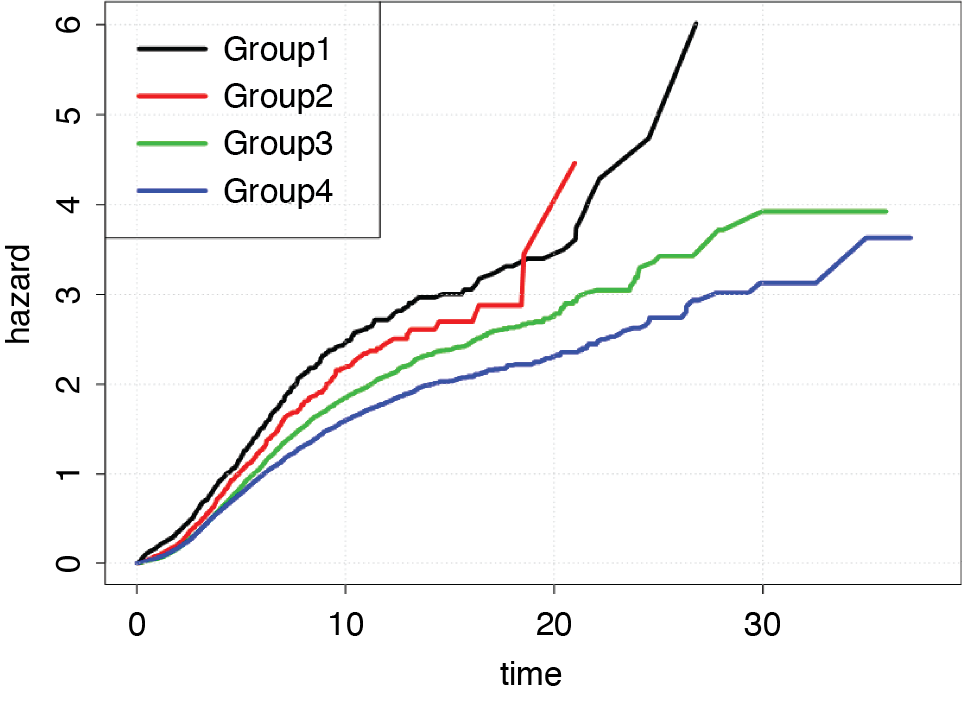
Figure 7 shows the shapes of the baseline hazard functions for each entity group. The shapes of the cumulative baseline hazard functions for the entity levels are not always parallel; in particular the group 2 function crosses group 1, violating the PH assumption. Three different tests, the likelihood ratio test, Wald’s test, and log-rank test are conducted to test the global hypothesis that β = 0 (overall goodness-of-fit). As p-values for all three tests are close to 0, we reject the null hypothesis, indicating that the model is an appropriate fit for the data set.

7.3. Model interpretation
Coefficients of the Cox model are related to the hazard rate. For example, the coefficient value of −0.008 for Years Employed at DOL indicates that the log hazard ratio increases by a unit of −0.008 for each additional unit increase in years of employment while other variables are kept constant. In practice, it is more meaningful to interpret the result using hazard ratio (or relative risk) instead of log hazard ratio.
The hazard ratio is obtained by taking the exponential of the coefficient. Specifically, the hazard ratio of years employed is e(−0.008) = 0.992, indicating that for each additional unit increase in duration of employment while holding other variables constant, the hazard ratio increases by a factor of 0.992. In other words, the risk of claim termination decreases by about 1% for each yearly increase in number of years employed.
The final model contained two significant interaction terms: interaction between Sex and Age at DOL (categorical vs. continuous) and interaction between Body Parts and Cause of Loss (two categorical variables). When interaction terms are significant, the interpretation of the coefficients becomes much more complex. For example, interpretation of “Sex and Age at DOL” is not as simple as Years Employed. The significant interaction between Sex and Age at DOL implies that the effect of DOL on the survival rate varies for each sex (male and female). Specifically, for each unit increase in age at DOL for a male claim, the hazard ratio increases by a factor of 1.010.
7.4. Model diagnostics
We tested the validity of the assumptions made in the model with model diagnostics.
(a) Overall fit
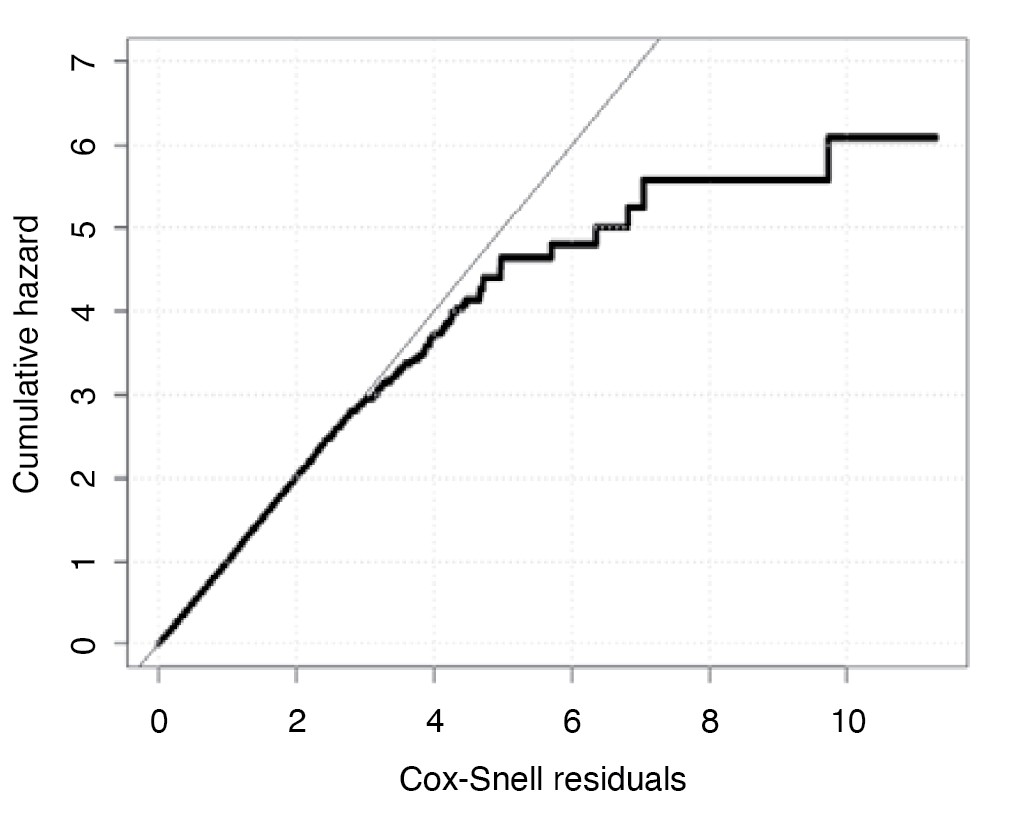
Cox-Snell residuals, defined as can be used to assess the overall fit of our Cox Proportional Hazards model. If the model is correct, a plot of the residuals of the estimated cumulative hazard rates versus ri should follow a straight line through the origin. In Figure 8, we see the estimated cumulative hazard is close to the diagonal line for all but large values of Cox-Snell residuals.

Overall, the model fits the data well as the proportion of the observations in the early range [0,4] of Cox-Snell residuals is approximately 99.8% of the whole training set. The departure of the estimated cumulative hazard as Cox-Snell residuals get larger indicates the presence of the potential outliers in the data.
(b) Appropriateness of the proportional hazard assumption
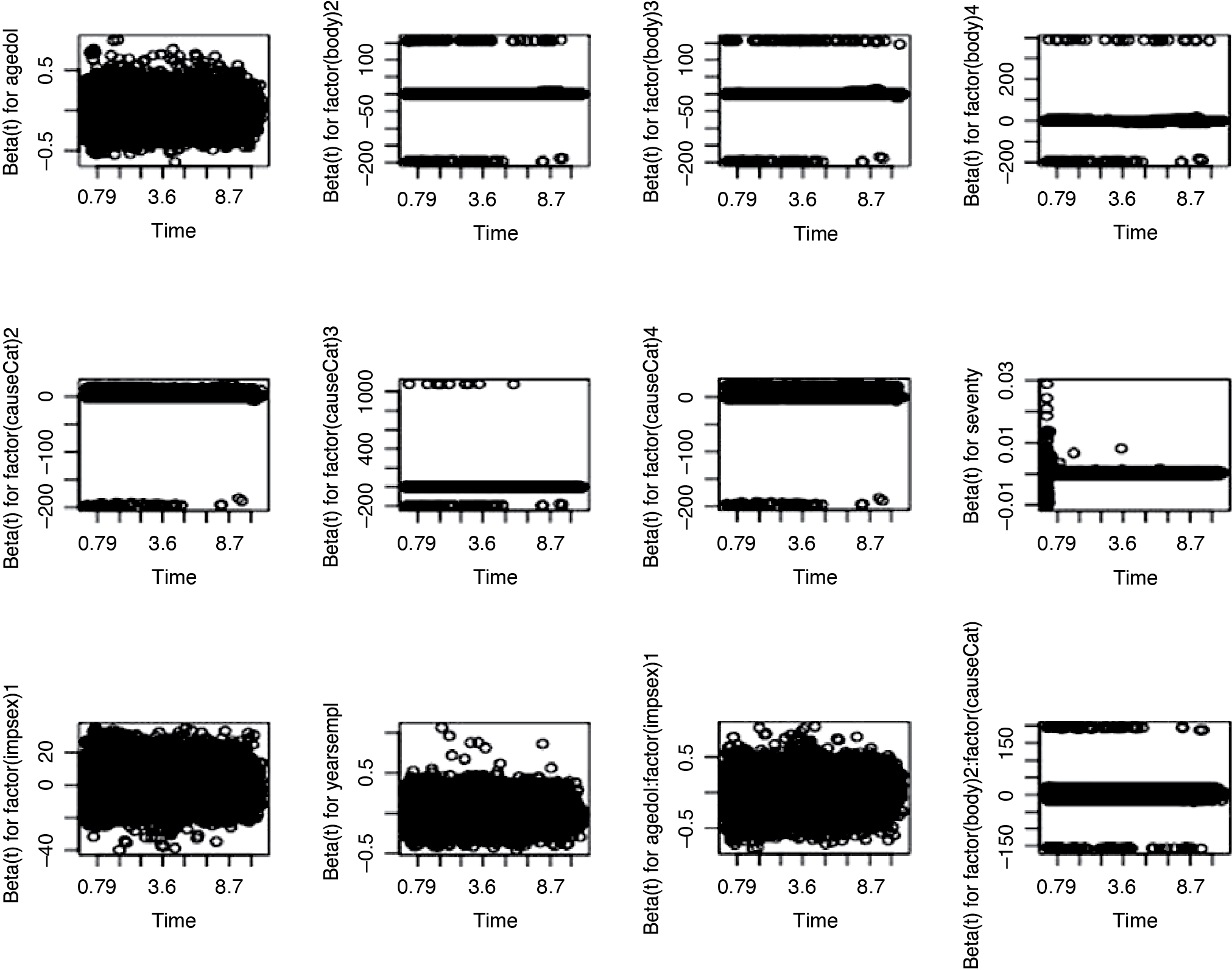
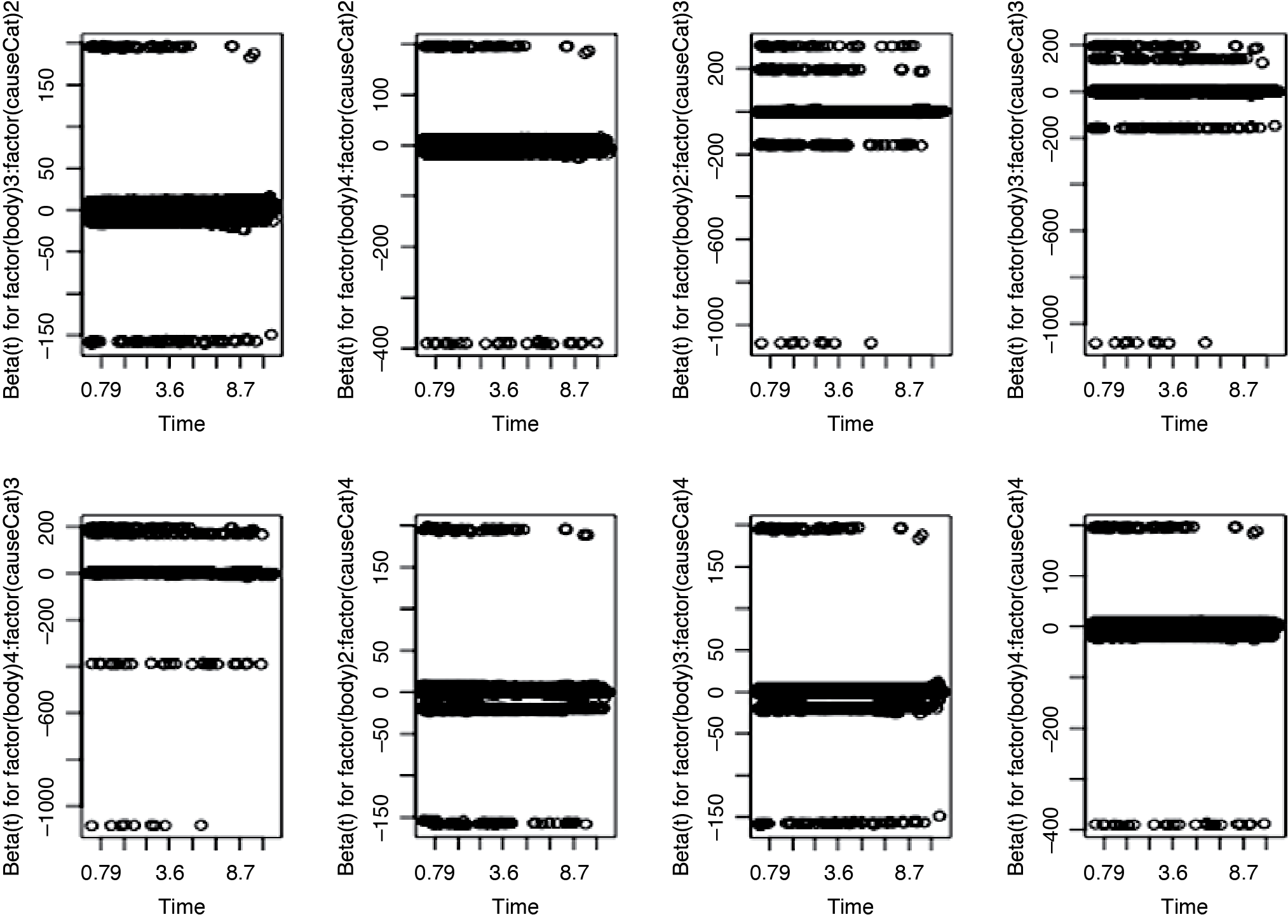
The departure from proportionality could lead to an incorrect model. We examined the PH assumption in two ways: by plotting the Schoenfeld residuals and performing a formal hypothesis test for correlation between Schoenfeld residuals and time.
If the PH assumption is true, we should expect that the trend of β(t) versus time to be a horizontal line for each covariate. As we see in Figures 9.1 and 9.2, the pattern of each plot looks horizontal around zero with little violation, implying that the PH assumption is valid.
.png)
To examine PH assumption more carefully, we performed a hypothesis test which Grambsch and Therneau (1994) proposed. Each parameter in the model is allowed to depend on time (i.e., We tested the value of the correlation parameter if we would reject the hypothesis that parameters are time-dependent. We conducted this test using function cox.zph in R and observed that all p-values are not significant (Table 5). In summary, we did not have sufficient evidence to reject the null hypothesis that the PH assumption is valid.
(c) Linear form of covariates
We further examined whether the linear combination of covariates is the best functional form to describe the effect of the covariates on survival. To do this, we plotted the martingale residuals versus each covariate. The results in Figure 10 implied that we did not need any polynomials or transformation of the covariates.
(d) Outliers and influential points
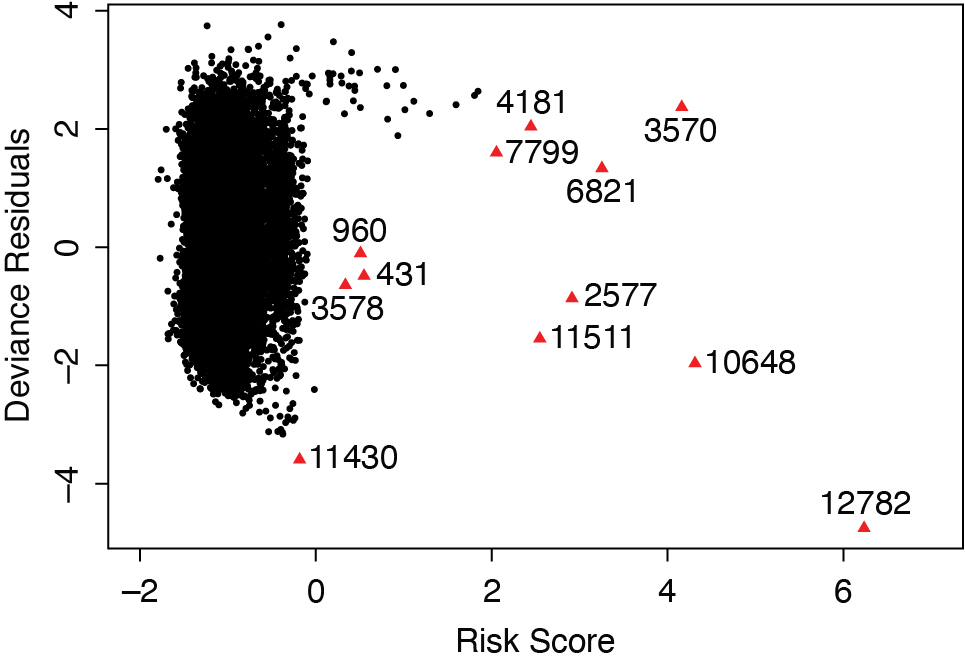
We examined the accuracy of the model for predicting the survival of a given subject. In other words, we tried to find claims whose survival time differed significantly in comparison to their model predictions. The deviance residuals plot versus risk scores is helpful to detect which claims are potential outliers, which perhaps should be excluded from the analysis. In Figure 11, we observe that the deviance residuals are randomly scattered in the panel and some observations (marked as triangles with indices) are the detected potential outliers. “Risk Score” is defined as ∑βx, where β is the vector of coefficients and x is the matrix of value of covariates. We performed further sensitivity analysis by removing these outliers and refitting the model. The new fitted model is not far off from the model presented in Table 3, and predictive power for both models using c-index is similar.

We also examined the influence of each claim on the model fit. The scaled score statistics versus covariate plot allows us to find influence points. Figure 12.1 and 12.2 show score residuals for each covariate. Using the plot between severity and the scaled score statistics, we observed several points that were further away from the majority of the observations, although this distance does not appear to be significant, suggesting that these points may be exercising influence on the fit.
.png)
7.5. Model prediction
We applied the final Cox model to the test set and calculated the concordance index. A C-index of 0.58 indicates the model does a moderately good job at predicting the risk of the claim being terminated.
8. Results of Cox model on non-imputed data
We will not repeat specific details for this section as all the procedures are similar to imputed data. Table 6 presents the final form of the Cox model on the non-imputed data. It contains three interaction terms: between Sex and Age at DOL, between Entity Group and Sex, and between Body Parts and Cause of Loss. When applied to the test dataset, the C-index of 0.57 indicates that model does a good job at predicting the risk of the claim being terminated.
8.1. Discussion
Workers’ compensation reserves for future medical liabilities are usually calculated in bulk using a triangle method. Although this standard method is widely used, there are examples of studies using reserving methods based on mortality projections, recognizing that explicit incorporation of injured worker mortality may reduce the potential inaccuracy in the bulk reserves. The State of California requires an explicit calculation for each permanently injured worker, assuming that termination of the claim follows the most recent U.S. Life Table. The literature shows that injured worker mortality is higher than that of the overall population, which could lead to over-reserving of future medical liabilities. We examined claims termination rates of injured workers using the experience of the California Association of Counties-Excess Insurance Authority (CSAC-EIA). We applied a number of different methods, including direct calculation of the termination rates (both raw and fitted to polynomials) to compare with the tabular rates, and found that for most ages, termination rates are in excess of those implied by the tabular rates. Finally, we applied Cox Proportional Hazards modeling to develop termination hazard rates based on our dataset. The Cox PH model is powerful in that it allows us to incorporate covariates and to assess the influence of individual covariates on the termination hazard. Tests of the proportional hazard assumptions show that the Cox model fits the data well, and that we can have confidence in the derived model.
We applied Cox Proportional Hazards modeling to develop termination hazard rates based on our dataset. The Cox PH model is powerful because it allows us to incorporate covariates and to assess the influence of individual covariates on the termination hazard. Tests of the proportional hazard assumptions show that the Cox model fits the data well, and that we can have confidence in the derived model. The effect of covariates on the hazard rates provides more information to claims managers about the likely survival of specific claimants than the standard table.
8.2. Conclusion
Analysis of the CSAC-EIA data shows that the use of the standard population mortality table as the basis for permanent disability claim projections may be inappropriate because the table overestimates injured worker survival. However, it is important to remember that the life expectancy of the injured worker is only one component of the reserve calculation; the other component is the average 3-year cost of medical claims. Because the claims cost component excludes a provision for medical trend, it may underestimate the future medical cost component. The result of combining an over-estimate of survival with an underestimate of future medical costs may well result in reasonable reserves in total; however, if the intention is to produce accurate reserves for future medical claims, more accurate methods of estimating both life expectancy and future medical claims would be appropriate.
8.3. Limitations
This study was performed on the experience of one pool, incorporating a number of different third-party administrators. Changes in reporting requirements and administrators over time may affect the accuracy of the data. As noted in our conclusion, life expectancy is only one component of the reserving calculation, and reserves calculated according to the State of California methodology may be appropriate because different components of the calculation offset each other.
Acknowledgments
The authors acknowledge with gratitude the collaboration of CSAC-EIA and its chief actuary, John Alltop FCAS MAAA, in the preparation of this study, as well as UCSB students Shannon Nicponski, MS; Elizabeth Riedell, BS; and Jerrick Zhang, BS, who performed the initial analysis. This work was supported in part by a CAE 2016 grant from the Society of Actuaries.