1. Introduction
There are several instances in which actuaries are either forced to use fitted curves to interpolate data or find them preferable to other forms of analysis for interpolation. For example, when analyzing loss development for medium tail lines of business, it is not unusual to need to convert December-to-ultimate loss development factors (LDFs) to factors suitable for use with June data. It is not unusual to perform an increased limits analysis at a few choice points and then interpolate the remaining points.
There are concerns with the use of interpolation on insurance claims data. In many of the scientific disciplines, there are overriding laws that create specific forms for mathematical functions that underlie data points. So, given such a circumstance, all one need do is to determine which member of a family of functions is the specific one that underlies the data, then determine the intermediate values directly from the fitted curve.
However, in casualty actuarial science, there is generally no such functional family or form that perfectly describes either the pattern of loss development or the relative frequency of losses by size. Actuaries often attempt to use such models anyway. The Weibull curve is often used to model the loss emergence underlying loss development factors (see Heyer 2001 for an example). Many curve families, including the Pareto, lognormal, and gamma (among others) have been used to model loss severity distributions (Hogg and Klugman 1984). Those models are widely known to capture the general character of the underlying development or severity phenomenon. But they are also known to be very imperfect estimators of the values at any particular point. One need only compare the development triangle of a large insurance company with fully credible data to any Weibull curve to see that the fitted curve fits the data imperfectly. Similarly, typical fully credible short tail data by size rarely follows a perfect mathematical severity curve. Therefore, in the less-than-perfect situations of loss development triangles with intermediate credibility, and of long-tail loss severity data with limited credibility in the upper tail, one would not expect perfect compliance with any common mathematical curve.
The problem that arises in current usage involves a trade-off of errors. Using the fitted curve values directly as interpolated values creates a distortion because the curve is an imperfect fit. Specifically, the curve will not match the known values of the phenomenon being analyzed. In other words, when the goal is to interpolate from loss development factors or increased limits factors carefully and reliably calculated at a limited set of points, the fitted curve typically does not reproduce those carefully and reliably determined data points. On the other hand, one could reproduce those data points exactly by simply using linear interpolation between the known values. One might even use the exponential interpolation for loss payouts espoused in Berquist and Sherman (1977). But, since either interpolation process just involves two data points, it will likely miss the general overall shape of the curve that the fitted curve captures. This paper offers an alternative that incorporates what is best in both approaches, as an expansion of an analysis presented conceptually in a paper by Boor (2006).
2. The formula for interpolation along the curve
This alternative method begins by fitting a curve from the curve family that is expected to be close to the pattern underlying the data. Then each segment (between two adjacent actual data points) of the fitted curve is adjusted so that the curve exactly matches the two actual data points. In other words, if we have actual data points d(t0), d(t1), d(t2), . . . , d(tm) and a curve fitted to those points of g(t), and we desire an estimate at we take
\[ \hat{d}\left(t^{*}\right)=d\left(t_{a}\right)+\frac{g\left(t^{*}\right)-g\left(t_{a}\right)}{g\left(t_{a+1}\right)-g\left(t_{a}\right)}\left[d\left(t_{a+1}\right)-d\left(t_{a}\right)\right] . \tag{1} \]
So, the curve is used as a guidepost for the changes between the observed points, and the actual observed values are maintained.
Further, if the function approaches zero at infinity, values beyond the last observed data point may be obtained by extrapolation. If tm is the location of the last observation and t* > tm, then we get
\[ \hat{d}\left(t^{*}\right)=g\left(t^{*}\right) \times \frac{d\left(t_{m}\right)}{g\left(t_{m}\right)}, t^{*}>t_{m}, \tag{2} \]
which fits the observed values d(tm) and d(∞) = 0 exactly. So, a very nice property of this approach is that it allows for extrapolation[1] as well as interpolation. In fact, an astute observer can see that formula (2) is just a special case of equation (1) where d(∞) = g(∞) = 0. In fact, as long as d(∞) and g(∞) are known, finite and close enough to use g as a basis for approximation with large numbers, formula (2) may be used to extrapolate towards infinity when d(∞) ≠ 0.
3. Interpolating loss development factors along a Weibull curve
The example below shows how this approach may be used in practice. The starting point is a series of loss development factors. It should be clear that asymptotically the loss development factors will converge to unity, since all the claims must eventually be closed. And it is recognized within the actuarial profession that in most circumstances the loss development factors decline monotonically toward unity as the time since inception gets larger. But the loss development factor at time zero is infinity, not zero (since typically no claims are even reported at the beginning of the process). Further, as time wears on, the loss development factors approach unity, not zero. So, the loss development factors themselves are not an ideal candidate for this type of interpolation/extrapolation.
But the loss development factors may be readily adapted to the approach in this paper. First, one should divide unity by each loss development factor. That produces the percentage of ultimate loss that is expected to be reported at 12, 24, etc. months into the process. Then, the percentage of loss dollars that are “IBNR” at a given time value may be computed as
\[ \% \text { IBNR }=1-\frac{1}{\text {loss development factor}}. \tag{3} \]
So the “%IBNR” values across time begin at unity and decline monotonically to zero. Therefore, IBNR percentages are a better candidate for the approach in this paper.
Next, the question of what class of reference functions are to be used for the interpolation. The type of function regularly used by actuaries for this particular situation is the family of Weibull distributions, with
\[ \% \text { Reported }(t)=1-\% \operatorname{IBNR}(t) \approx 1-\exp \left(-c \times t^{b}\right) \text {, } \tag{4} \]
and
\[ \% \operatorname{IBNR}(t) \approx \exp \left(-c \times t^{b}\right) \tag{5} \]
A strong rationale for the use of the Weibull distribution is its match to the general reporting pattern of claims dollars. The incremental pattern, or the tendency for claims dollars to be newly reported at a particular time, is the derivative of the cumulative distribution function in equation (4), or
\[ \text {Incremental }\%\text{Reported}(t)=c b t^{b-1} \exp \left(-c \times t^{b}\right) \text {. } \tag{6} \]
So, this distribution starts low at zero, picks up size as increases, reaches a maximum, and then slowly tails off downward. That behavior is typical of the reporting pattern of insurance claims. So, the Weibull is a good choice for the family of interpolating distributions. Next, it is necessary to compute the coefficients b and c that define the specific Weibull distribution used in the interpolation. One may first take the natural logarithms of both sides of equation (5) to get
\[ \ln (\% \operatorname{IBNR}(t)) \approx-c \times t^{b} . \tag{7} \]
Then the sign of both sides may be switched, and another natural logarithm applied to produce
\[ \ln (-\ln (\% \operatorname{IBNR}(t))) \approx \ln (c)+b \ln (t) . \tag{8} \]
Then, ln(c) may be estimated as the intercept of a regression line and b as the slope of the same regression line.[2] The value of c may be determined by simply using the exponential function to invert the logarithm.
One may see the process of conversion to %IBNR, to curve fitting, and then converting back to loss development factors in Table 1. The c and b parameters are estimated by transforming the time and %IBNR values as noted in the table with the precise computations noted at the bottom.
For the sake of completeness, two technical items deserve mention that do not directly relate to the process of interpolating along the fitted curve, but do relate to the process of interpolating loss development factors. First, the number of months since the accident year began in the first column is converted to the average number of months of maturity of the losses in the data. This makes it possible to determine a loss development factor for an odd-shaped year. For example, if a company began writing policies at the beginning of the calendar year and sold them at a continuous rate, their accident year would have a triangular shape weighted towards the end of the year, with an average loss maturity of four months. So, the loss development factor corresponding to four months maturity could be used for that company.
Second, an adjustment is included to convert the loss development factors for stub periods (periods of loss data of less than a year in duration) to development factors suitable for a full year. This adjustment is necessary because the basis for all the fitted factors are loss periods that do not include losses that have not occurred as yet. Field experience with this methodology suggests that the adjustment is indeed necessary.
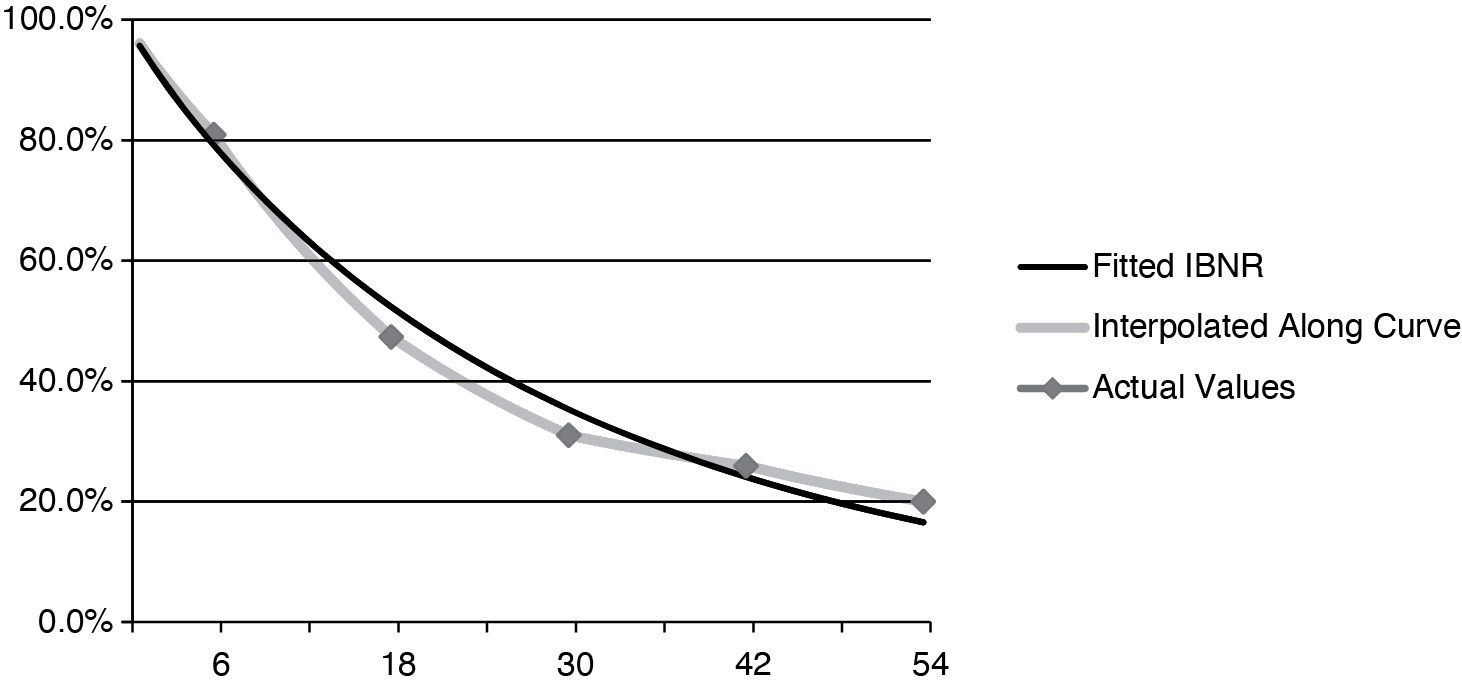
Figure 1 illustrates the relationship between the fitted IBNR, the values interpolated along the curve, and the data points that are being interpolated. The thin line represents the fitted curve, the thick line represents the values interpolated along the curve, and the diamonds are the actual values of the data that are to be interpolated. As one may see, the fitted curve provides the general shape, but the interpolation hits the actual values exactly.

4. Interpolating increased limits factors along a Pareto curve
Next, an example involving increased limits factors will be performed. In this case, the loss severity curve will be assumed to follow a Pareto distribution.[3] A little background is needed, though, to introduce the Pareto-based function for the increased limits factors. Mathematically, if the severity distribution is a Pareto distribution with parameter α and truncation point T, then, using the notation in Boor (2012) of E[Xc(L)] for the mean value of losses capped at L, and sX(x) and FX(x) for the loss severity function and its cumulative distribution function,
\[ E\left[X_{c}(L)\right]=\int_{0}^{L} x s_{x}(x) d x+L\left(1-F_{X}(L)\right) \tag{9} \]
Substituting in the specific functions associated with the Pareto distribution yields
\[ \begin{aligned} E\left[X_{c}(L)\right] & =\int_{T}^{L} x \alpha \frac{T^{\alpha}}{x^{\alpha+1}} d x+L \frac{T^{\alpha}}{L^{\alpha}} \\ & =\frac{T}{\alpha-1} \alpha-\frac{T^{\alpha-1}}{L^{\alpha-1}} . \end{aligned} \tag{10} \]
Then, if ILF(L, B) represents the increased limits factor relating costs associated with a limit of L to costs associated with a basic limit B, it has the value
\[ \operatorname{ILF}(L, B)=\frac{\alpha-\left(\frac{T}{L}\right)^{\alpha-1}}{\alpha-\left(\frac{T}{B}\right)^{\alpha-1}} . \tag{11} \]
That expression is initially undesirable, because it does not lend itself to a simple regression-type calculation of the parameters. However, most spreadsheet software in use today contains goal seek and other optimization functionalities. Those may be used in lieu of the regression approach used in fitting loss development factors.
It may help to provide an example using Pareto interpolation along a curve which requires goal seek for curve fitting. One might begin with the sample increased limits factors for $25,000, $100,000, $500,000 and $2 million in Table 2. Using equation (11), one could compute the increased limits factors that correspond to any assigned values of α and T. As is shown in Table 2, one might compute the squared differences between the known increased limits factors used as input in the process and those computed using the assigned values of α and T. Then, the sum of those squared differences may be computed, as is shown in a subsequent column in the table. The last step is simply to execute an instruction that directs the spreadsheet goal seek routine to find the values of α and T that minimize the sum of squared differences. After that, the α and T parameter values for the fitted curve are determined and may be carried to the next step.
Having the values of α and T determined, the next step is to show the fitted curve values at all the desired limit values. After that, one should rotate and scale the fitted curves in each interval using equation (1) so that they match the endpoints exactly. The result yields the desired estimates of the intermediate increased limits factors, as is illustrated in Table 3.
5. Mathematical rationale and summary
Again, note that a key assumption in this approach is that the data points d(t1), d(t2), . . . are fairly good approximations of the true underlying values, if not the exact underlying values. Further, it also assumes that whatever curve is fit to the data points is a reasonable approximation of the underlying pattern. Presumably, though, the fitted curve is not the true, more complex curve of the underlying phenomenon. Specifically, as long as the data points d(ti) are known to be much higher quality approximations to the true underlying phenomenon than the fitted curve values g(t1), g(t2), . . . , it is logically preferable to modify the curve to match the d(ti)'s exactly.
Another key question to ask involves how the mathematics justify this approach, especially when the Taylor series-based interpolation processes such as linear and polynomial interpolation are so prominent in mathematics. It is important to address why interpolation along the curve should be an improvement, in actuarial contexts, over that class of methods. First, purely linear approximations deserve attention. Obviously, the efficacy of these methods depends on the degree to which the character of the fitted curve captures the character of the underlying data pattern. But it would appear, to the extent that the general characteristics of the fitted curve used in the interpolation match the data pattern, that in some sense the method in this paper captures aspects of the second (and possibly higher) derivatives. So, while it is unlikely that an exact second derivative match will be generated by this approximation, the accuracy resulting from this enhancement should usually be superior to that of linear interpolation. A secondary consideration results from comparing this methodology to, say, cubic splines. While the cubic splines approach has more theoretical mathematical support, the method in this paper will work better in an actuarial context for four reasons:
-
As long as the value at infinity is finite, extrapolation along the fitted curve may be used, whereas cubic splines are not designed for extrapolation;
-
Business audiences are generally not receptive to methods that could feature unexplained reversals (e.g., a fitted curve going down, then up, then down again when locally it should decrease monotonically) such as can sometimes happen with higher order approximations;
-
The mathematics of this approach (at least as long as the curve fit is susceptible to easy explanation) may be presented in a relatively simple spreadsheet, whereas cubic splines require a more complex spreadsheet; and
-
Testing confirms (see section 6) that interpolating along the curve generally produces more accurate values than pure curve fitting.
So, this approach represents a significant enhancement over curve fitting, linear interpolation and cubic splines in a practical actuarial context.
6. Testing
The previous sections provide a strong argument that interpolation along a curve provides an improved prediction of loss development factors and increased limits factors at intermediate input values. However, it is relevant to provide some actual field testing of the efficacy of this approach. To that end, three major data sets were collected. First, industry aggregate development triangles for various Schedule P lines of business as of 12/31/2003 were provided by (and consequential data used here by permission of) the National Association of Insurance Commissioners. Secondly, 10 Schedule P triangles, each from a company with a limited volume of development data, were selected. Lastly, the National Council on Compensation Insurance provided two sets of seven copyrighted excess loss ratios, seven for 2007 and seven for 2008 (and gave permission for their use). Using those datasets, loss development factor and increased limits factor datasets were determined. Then, one may evaluate the accuracy of various approaches to interpolation by eliminating, for example, all the even-numbered values and interpolating them using the odd-numbered values. Since their true values are known, the interpolation error could then be computed precisely.
6.1. Test using the NAIC aggregate reserving data
One advantage of the NAIC Aggregate Reserving data is that any process variance volatility in the link ratios due to inadequate premium volume is minimal to nonexistent. So, this test measures the quality of interpolation of loss development factors when the true long-term average value of the loss development factors are known. To execute this test, 2003 aggregate industry triangles using Schedule P parts 2, 3, and 4 were prepared for the homeowners, private passenger auto liability, workers compensation, commercial multi-peril, occurrence medical malpractice, claims/made medical malpractice, occurrence other liability, claims/made other liability, occurrence products liability, and claims/made products liability. The case incurred (Part 2–Part 4) and paid loss and defense, and cost containment were entered into different tabs in the same workbook. Link ratios were mechanically selected as the weighted average of the last three link ratios. Tail factors were selected in a fairly mechanical fashion using the Sherman/Boor tail factor algorithm (Boor 2006). In some cases, link ratios below unity were observed.[4] Up to three link ratios in each development pattern might be replaced by factors of “1.0001”.[5] Consequently, all the paid and incurred loss development patterns could be made usable except that of the claims made medical malpractice incurred loss development. For each paid or case incurred development pattern, the factors at 12, 36, 60, and 84 months were extracted, and then a Weibull curve was fit to those extracted factors.[6] The results of that curve fit yielded the fitted curve estimates of the loss development factors at the intermediate maturities of 24, 48, 72, and 108. Further, the availability of the fitted curve values accommodated fitting along the curve as well. Geometric (exponential) interpolation, and linear interpolation of the loss development factors were performed. Lastly, linear and geometric interpolation[7] of the percentages paid or incurred were performed as well.
Since the goal was to score the various interpolating methods, two key datasets were created. First, the squared error between each estimate and the actual value from the curve was computed. Then, for each intermediate value, the interpolation method with the lowest squared error was determined.
As one may see, the interpolation along the curve has a much more consistent success percentage than the other other methods. Further, as noted in the last column of Table 4, it is not unusual for the Weibull interpolation to lie outside the endpoints of the range which are to be interpolated. Therefore, there is a strong reason to use the fitting along the curve as the benchmark interpolation approach.
To provide a more explicit accuracy test, the squared errors of each interpolation method for each target dataset were computed. Ratios of the squared error generated by the various approximations to each intermediate point to the benchmark interpolation along the curve were computed. The results were capped from below by 5% and above by 2000%,[8] and geometric averages computed across the intermediate values. The results are shown in Table 5.
As one may see, fitting along the curve is more accurate by an order of magnitude compared to the various non–curve fit methodologies. The unadjusted Weibull curve fit contains 336% as much error (180% as much standard error) as the fit along the Weibull curve described in this paper. So, the fit along the curve is demonstrably superior.
6.2. Test using the small company reserving data
As a contrast to the high data volume displayed in the NAIC aggregate data, 10 small company triangle sets were identified. All the paid loss and DCC triangles were usable, but only seven of the then incurred loss triangles could be used. Errors were computed as before, and the interpolation methods with the lowest errors are shown in Table 6.
As one may see, interpolation along the curve does not have as much benefit for small company data. Further, Table 7 shows the average error relative to the interpolation along the curve. Interpolation along the curve still produces benefits here, but it does not provide the same error reduction that it does with industry aggregate data. This suggests that interpolation along the curve tends to work best with larger, more reliable volumes of data.
6.3. Test using NCCI increased limits factors
As noted earlier, interpolation along the curve may be used to interpolate increased limits factors as well as loss development factors. Therefore, it makes sense to test interpolation along a curve in the context of estimating increased limits factors. To that end, the National Council on Compensation Insurance supplied tables of excess loss factors for Florida from 2007 and 2008, along with permission to use them. On review of the data, it was apparent that the 2008 factors were so close to the 2007 factors that they could not truly represent an independent test of the accuracy of the various interpolation methods. The NCCI data is available at a wide range of attachments and for seven hazard groups. To simulate the classic ILF interpolation problem, the excess factors were converted to ILFs centered at $250,000. For each of the seven hazard groups, ILFs were extracted for $25,000, $50,000, $75,000, $100,000, $150,000, $350,000, $500,000, $750,000, $1,000,000, $2,000,000, $3,000,000, $5,000,000, $7,000,000, and $10,000,000 in addition to the unity ILF at $250,000. As with the loss development factor interpolation testing, the increased limits factors were split into the odd numbered inputs and even numbered inputs. Using standard spreadsheet goal seek software, the Pareto-induced ILF that had a basic limit of unity at $250,000 and minimized the squared differences against the selected ILFs was computed for each hazard group, one using the even numbered ILFs, and another the odd ILFs. Then, as with the development factors, the accuracy of the various methods at filling in the (known) intermediate values was computed.
For reference, the percentage of the time that each method was the best estimate is shown in Table 8.
Note that interpolation along the curve is clearly preferable, in spite of the fact that the nature of the curve fit to the data excluding the basic limit forces the fitted curve to be a perfect approximation (i.e., unity).
The geometric averages[9] of the relative squared errors of the various interpolation methods are shown in Table 9.
As one may see, interpolation along the curve is a superior algorithm, at least for the increased limits problem analyzed above.
6.4. Comparison to cubic splines
The previous testing presents strong reasons to prefer interpolation along the curve to other common actuarial interpolation methods. However, one might argue that numerical analysis, with its focus on interpolating polynomials, could offer a superior methodology. One could then argue that the adjustments to the fitted curves inherent in interpolation along the curve are similar to numerical analysis concepts such as linear interpolation. However, it makes sense to compare interpolation to a representative interpolation method from numerical analysis. Therefore, interpolation along the curves is compared to interpolation via cubic splines within this section. An appendix is included for readers who are not familiar with the mathematics of cubic splines.
The three data sets used previously were reused in this section. The fitting to industry loss development data produced the results in Table 10.
As one may see, interpolation along the curve is preferable twice as often as cubic spline interpolation. Further, in several instances cubic splines interpolation suggests negative development when positive development is what is actually expected. In one case it even indicates that inception-date loss at one development stage is negative rather than positive. The number of those consistency errors is shown in the table. As further support for the preference[10] for interpolation along the curve, the ratios (with capping, as before) of the squared error in cubic splines to that of interpolation along the curve are shown in Table 11.
It is also relevant to evaluate the relative performance against the small company data. The winning percentage of cubic splines is shown in Table 12. The average error ratio (subject to the previous protocols) is shown in Table 13. As one may see, cubic splines performed slightly worse (relative to interpolation along the curve) on small company data than on the NAIC aggregate data.
To complete the review, cubic splines were compared to interpolation along the curve using the same NCCI increased limits data that was used in the previous testing. The winning percentage in this case was simply a single number. Specifically, interpolation along a Pareto curve produced more accurate answers in 66 (81%) of 77 cases. Further, the overall average ratio of cubic splines interpolation error to the error of interpolation along a Pareto curve across the seven hazard groups is 254%. In summary, interpolation along the curve appears to be a much more reliable method than cubic splines for interpolating actuarial data.
6.5. Summary of testing
The testing generally supports the main thesis of this paper—that interpolation along the curve is much more accurate and reliable overall than the alternative interpolation methods employed by actuaries. Further, it also suggests that, for common actuarial applications, it should be preferred to the standard cubic splines method employed by numerical analysts.
7. Summary
As the the analysis and testing in this paper show, interpolation along the curve is an enhancement to the use of curves fitted from some family of curves. Such a curve fit would often be performed anyway. Further, by adjusting the fitted curve to exactly match the observed data points, the interpolation along the curve should be more accurate[11] than curve fitting alone. So, use of this method should enhance the quality of actuarial predictions.