

1. Introduction
For a random vector (X, Y) with continuous marginal distributions F1 and F2, its copula is defined as
C(x,y)=P(F1(X)≤x,F2(Y)≤y) for 0≤x,y≤1.
Due to its invariant property with respect to marginals, requirements in Basel III for banks and Solvency 2 for insurance companies enhance the popularity of copula models in risk management. In practice the family of elliptical copulas is arguably the most commonly employed class because it is quite easy to use in simulations with different levels of correlations. Peng (2008) used elliptical copulas to predict a rare event, and Landsman (2009) used elliptical copulas for capital allocation. Two important classes of elliptical copulas are the Gaussian copula and the t-copula. It is known that financial time series usually exhibit tail dependence, but the Gaussian copula has an asymptotically independent tail while the t-copula has an asymptotically dependent tail. Breymann, Dias, and Embrechts (2003) showed that an empirical fit of the t-copula is better than the Gaussian copula. Some recent applications and generalization of t-copulas include: Schloegl and O’Kane’s (2005) formulas for the portfolio loss distribution when a t-copula is employed; de Melo and Mendes’s (2009) option pricing applications in retirement funds using the Gaussian and t-copulas; Chan and Kroese’s (2010) t-copula model used to estimate the probability of a large portfolio loss; Manner and Segers’s (2011) study of the tails of correlation mixtures of the Gaussian and t-copulas; grouped t-copula applications were given in Chapter 5 of McNeil, Frey, and Embrechts (2005); Luo and Shevchenko (2012) and Venter et al. (2007) extended the grouped t-copula; and studies of tail dependence for multivariate t-copulas and their monotonicity were studied by Y. Chan and Li (2008).
The t-copula is an elliptical copula defined as
C(u,v;ρ,v)=∫5(u)−∞∫π(v)−∞12π(1−ρ2)1/2{1+x2−2ρxy+y2v(1−ρ2)}−(v+2)/2dydx,
where ν > 0 is the number of degrees of freedom, ρ ∈ [−1, 1] is the linear correlation coefficient, tν is the distribution function of a t-distribution with ν degrees of freedom and tν− denotes the generalized inverse function of tν. When ν = 1, the t-copula is also called the Cauchy copula.
In order to fit the t-copula to a random sample (X1, Y1), . . . , (Xn, Yn), one has to estimate the unknown parameters ρ and ν first. A popular estimation procedure for fitting a parametric copula is the pseudo maximum likelihood estimate (MLE) proposed by Genest, Ghoudi, and Rivest (1995). Although, generally speaking, the pseudo MLE is efficient, its computation becomes a serious issue when applied to t-copulas especially with a large dimension. A more practical method to estimate ρ uses Kendall’s tau, defined as
τ=E(sign((X1−X2)(Y1−Y2)))=4∫10∫10C(u1,u2)dC(u1,u2)−1.
It is known that τ and ρ have a simple relationship,
ρ=sin(πτ/2).
By noting this relationship, Lindskog, McNeil, and Schmock (2003) proposed to first estimate ρ by
ˆρ=sin(πˆτ/2),where ˆτ=2n(n−1)∑1≤i<jsnsign((Xi−Xj)(Yi−Yj)),
and then to estimate ν by maximizing the pseudo likelihood function
n∏i=1c(Fn1(Xi),Fn2(Yi);ˆρ,v),
where is the density of the t-copula defined in Equation (1.1), = (n + 1)−1 and are marginal empirical distributions. In other words, the estimator ν̂ is defined as a solution to the score equation
n∑i=1l(ˆρ,v;Fn1(Xi),Fn2(Yi))=0,
where τ̂ is called the Kendall’s tau estimator. The asymptotic results of the pseudo MLE for the t-copula are shown in Genest, Ghoudi, and Rivest (1995). A recent attempt to derive the asymptotic distribution for the two-step estimator (ρ̂, ν̂) is given by Fantazzini (2010), who employed the techniques for estimating equations. Unfortunately the derived asymptotic distribution in Fantazzini (2010) is not correct since the Kendall’s tau estimator is a U-statistic rather than an average of independent observations. Numeric comparisons for the two estimation procedures are given in Dakovic and Czado (2011). Explicit formulas for the partial derivatives of logc(u, v; ρ, ν) can be found in Dakovic and Czado (2011) and Wang, Peng, and Yang (2013).
In this paper, we first derive the asymptotic distribution of the two-step estimator (ρ̂, ν̂) by using techniques for U-statistics. One may also derive the same asymptotic results by combining results in Genest, Ghoudi, and Rivest (1995) and Barbe et al. (1996). But one ends up with checking the (rather-complicated) regularity conditions in Barbe et al. (1996).
It is known that interval estimation is an important way of quantifying estimation uncertainty and is directly related to hypothesis tests. Efficient interval estimation remains a necessary part of the estimation procedure in fitting a parametric family to data. As showed in Section 2, the asymptotic covariance matrix for the proposed two-step estimators is very complicated, and hence some ad hoc procedures such as the bootstrap method are needed for constructing confidence intervals/regions for parameters and some related quantities. However, it is known that a naive bootstrap method performs badly in general; see the simulation study in Section 3. In order to avoid estimating the complicated asymptotic covariance matrix, we further investigate the possibility of applying an empirical likelihood method to construct confidence intervals/regions as the empirical likelihood method has been demonstrated to be effective in interval estimation and hypothesis testing. See Owen (2001) for an overview of the empirical likelihood method. Since Kendall’s tau estimator is a nonlinear functional, a direct application of the empirical likelihood method fails to have a chi-square limit in general; i.e., Wilks’ theorem does not hold. In this paper we propose to employ the jackknife empirical likelihood method from Jing, Yuan, and Zhou (2009) to construct a confidence interval for ν without estimating any additional quantities. We also propose a jackknife empirical likelihood method to construct a confidence region for (ρ, ν), and a profile jackknife empirical likelihood method to construct a confidence interval for the tail dependence coefficient of the t-copula.
We organize the paper as follows: Methodologies are given in Section 2. Section 3 presents a simulation study to show the advantage of the proposed jackknife empirical likelihood method for constructing a confidence interval for ν. Data analysis is given in Section 4. All proofs are delayed until Section 5.
2. Methodologies and main results
2.1. The asymptotic distribution of ρ̂, ν̂ and λ̂
As mentioned in the introduction, the asymptotic distribution for the two-step estimator (ρ̂, ν̂) only appears in Fantazzini (2010), who unfortunately neglected the fact that Kendall’s tau estimator is a U-statistic rather than an average of independent observations. Here we first derive the joint asymptotic limit of (ρ̂, ν̂) as follows.
Theorem 1. As n → ∞, we have
√n{ˆρ−ρ}=cos(πτ2)π√nn∑i=14{C(F1(Xi),F2(Yi))−EC(F1(X1),F2(Y1))}−cos(πτ2)π√nn∑i=12{F1(Xi)+F2(Yi)−1}+op(1)
and
√n{ˆv−v}=−K−1v{1√n∑ni=1l(ρ,v;F1(Xi),F2(Yi))+Kρ√n(ˆρ−ρ)+1√n∑ni=1∫10∫10lu(ρ,v;u,v){I(F1(Xi)≤u)−u}c(u,v)dudv+1√n∑ni=1∫10∫10lv(ρ,v;u,v){I(F2(Yi)≤v)−v}c(u,v)dudv}+op(1),
where
lu(ρ,v;u,v)=∂∂ul(ρ,v;u,v),lv(ρ,v;u,v)=∂∂vl(ρ,v;u,v),
and
Ka=E(∂∂al(ρ,v;F1(X1),F2(Y1)))=∫10∫10∂∂al(ρ,v;u,v)dC(u,v),a=v,ρ.
Using the above theorem, we can easily obtain that
√n(ˆρ−ρ,ˆv−v)Td→N((0,0)T,(σ21σ12σ12σ22)),
where σ21, σ12 and σ22 are constants whose values are given in the proof of Theorem 1 in Section 5.
Another important quantity related with t-copula is the tail dependence coefficient λ = 2tν+1 which plays an important role in studying the extreme co-movement among financial data sets. A natural estimator for λ based on the above two-step estimator is
ˆλ=2tˆı+1(−√(ˆv+1)(1−ˆρ)/√1+ˆρ),
and the asymptotic distribution of λ̂ immediately follows from Equation (2.3) as given in the following theorem.
Theorem 2. As n → ∞, we have
√n{ˆλ−λ}d→N(0,σ2),
where
σ2=(∂λ∂ρ)2σ21+(∂λ∂v)2σ22+2∂λ∂ρ∂λ∂vσ12
and
Using the above theorems, one can construct confidence intervals/regions for ν, ρ, λ by estimating the complicated asymptotic variance/covariance (see the values of σ21, σ12 and σ22 in Section 5 for instance). While estimators for σ21, σ12, σ22 can be obtained by replacing ρ and ν in those involved integrals by ρ̂ and ν̂, respectively, evaluating those integrals remains computationally non-trivial. Hence we seek ways of constructing confidence intervals/regions without estimating the asymptotic variances. A commonly used way is to employ the bootstrap method. However, it is known that a naive bootstrap method performs badly in general; see the simulation results given in Section 3 below. An alternative way is to employ the empirical likelihood method, which does not need to estimate any additional quantities. Due to the fact that Kendall’s tau estimator is non-linear, a direct application of the empirical likelihood method can not ensure that Wilks’ theorem holds. Here we investigate the possibility of employing the jackknife empirical likelihood method. By noting that ρ̂ is a U-statistic, one can directly employ the jackknife empirical likelihood method in Jing, Yuan, and Zhou (2009) to construct a confidence interval for ρ without estimating the asymptotic variance σ21 of ρ̂. Therefore in the following we focus on constructing confidence intervals/regions for ν, (ρ, ν) and the tail dependence coefficient
2.2. Interval estimation for ν
In order to construct a jackknife sample as in Jing, Yuan, and Zhou (2009), we first define for i = 1, . . . , n
ˆρi=sin(πˆτi/2),ˆτi=2(n−1)(n−2)∑1sjj<sn,jijlzzisign((Xj−Xl)(Yj−Yl)),
Fn,i,i(x)=1n∑jxiI(Xj≤x),Fn2,i(y)=1n∑jxiI(Yj≤y),
and then define the jackknife sample as
Zi(v)=n∑j=1l(ˆρ,v;Fn1(Xj),Fn2(Yj))−∑j=il(ˆρi,v;Fn1,i(Xj),Fn2,i(Yj)),
for i = 1, . . . , n.
Based on this jackknife sample, the jackknife empirical likelihood function for ν is defined as
L1(v)=sup{∏ni=1(npi):p1≥0,…,pn≥0∑ni=1pi=1,∑ni=1piZi(v)=0}.
By the Lagrange multiplier technique, we have
l1(v):=−2logL1(v)=2n∑i=1log{1+2λ1Zi(v)},
where λ1 = λ1(ν) satisfies
n∑i=1Zi(v)1+λ1Zi(v)=0
The following theorem shows that Wilks’ Theorem holds for the above jackknife empirical likelihood method.
Theorem 3. As n → ∞, l1(ν0) converges in distribution to a chi-square limit with one degree of freedom, where ν0 denotes the true value of ν.
Based on the above theorem, one can construct a confidence interval with level α for ν0 without estimating the asymptotic variance as
I1(α)={v:l1(v)≤χ21,α},
where χ21,α denotes the α-th quantile of a chi-square limit with one degree of freedom. The above theorem can also be employed to test H0: ν = ν0 against Ha: ν ≠ ν0 with level 1 − α by rejecting H0 whenever l1(ν0) > χ21,α. For computing l1(ν), one can simply employ the R package ‘emplik’ as we do in Section 3. For obtaining I1(α), one has to compute l1(ν) for all ν, which is usually done by step searching as we do in Section 4.
2.3. Interval estimation for (r, ν)
As mentioned previously, the Kendall’s tau estimator is not a linear functional, hence one can not apply the empirical likelihood method directly to construct a confidence region for (ρ, ν). Here we employ the jackknife empirical likelihood method by defining the jackknife empirical likelihood function as
L2(ρ,v)=sup{∏ni=1(npi):p1≥0,…,pn≥0,∑ni=1pi=1,∑ni=1piZi(v)=0,∑ni=1pi(nˆρ−(n−1)ˆρi)=ρ}.
Theorem 4. As n → ∞, −2logL2(ρ0, ν0) converges in distribution to a chi-square limit with two degrees of freedom, where (ρ0, ν0)T denotes the true value of (ρ, ν)T.
Based on the above theorem, one can construct a confidence region with level α for (ρ0, ν0)T without estimating the asymptotic covariance matrix as
I2(α)={(ρ,v):−2logL2(ρ,v)≤χ22,α},
where χ22,α denotes the α-th quantile of a chi-square limit with two degrees of freedom.
2.4. Interval estimation for the tail dependence coefficient λ
In order to construct a jackknife empirical likelihood confidence interval for the tail dependence coefficient λ for the t-copula, one may construct a jackknife sample based on the estimator λ̂ given in Section 2.1. This method requires calculating the estimator for ν without the i-th observation. Since ν̂ has no explicit formula, it is very computationally intensive to formulate the jackknife sample. Although the approximate jackknife empirical likelihood method in Peng (2012) may be employed to reduce computation, it requires computing the complicated partial derivatives of the log density of the t-copula. Here we propose the following profile empirical likelihood method by treating ν as a nuisance parameter.
Define
˜Zi(v)=2ntv+1(−√(v+1)(1−ˆρ)/√1+ˆρ)−2(n−1)tv+1(−√(v+1)(1−ˆρi)/√1+ˆρi)
for i = 1, . . . , n. Based on the jackknife sample for i = 1, . . . , n, and the fact that we define the jackknife empirical likelihood function for (ν, λ) as
L3(v,λ)=sup{∏ni=1(npi):p1≥0,…,pn≥0∑ni=1pi=1,∑ni=1piZ∗i(v,λ)=0}.
By the Lagrange multiplier technique, we have
l3(ν,λ)=−2logL3(ν,λ)=2n∑i=1log{1+2λT3Z∗i(ν,λ)},
where λ3 = λ3(ν, λ) satisfies
n∑i=1Z∗i(ν,λ)1+λT3Z∗i(ν,λ)=0.
Since we are only interested in the tail dependence coefficient λ, we consider the profile jackknife empirical likelihood function
lp3(λ)=minv>0l3(ν,λ).
As in Qin and Lawless (1994), we first show that there is a consistent solution for ν, say ν̃ = ν̃(λ), and then show that Wilks theorem holds for l3(ν̃(λ0), λ0), where λ0 denotes the true value of λ.
Lemma 1. With probability tending to one, l3(ν, λ0) attains its minimum value at some point ν̃ such that |ν̃ − ν0| ≤ n−1/3. Moreover ν̃ and λ̃3 = λ3(ν̃, λ0) satisfy
Q1n(˜ν,˜λ3)=0 and Q2n(˜ν,˜λ3)=0,
where
Q1n(v,λ3)=1nn∑i=1Z∗i(v,λ0)1+λτ3Z∗i(v,λ0)
and
Q2n(ν,λ3)=1nn∑i=111+λT3Z∗i(v,λ0){∂Z∗i(ν,λ0)∂v}Tλ3.
The next theorem establishes the Wilks’ theorem for the proposed jackknife empirical likelihood method.
Theorem 5. As n → ∞, l3(ν̃(λ0), λ0) converges in distribution to a chi-square limit with one degree of freedom.
Based on the above theorem, one can construct a confidence interval with level α for λ0 without estimating the asymptotic variance as
I3(α)={λ:l3(˜v(λ),λ)≤χ21,α}.
3. Simulation study
We investigate the finite sample behavior of the proposed jackknife empirical likelihood method for constructing confidence intervals for ν and compare it with the parametric bootstrap method in terms of coverage probability.
We employ the R package “copula” to draw 1,000 random samples with size n = 200 and 500 from the t-copula with ρ = 0.1,0.5,0.9 and ν = 3,8. For computing the confidence interval based on the normal approximation, we use the parametric bootstrap method. More specifically, we draw 1,000 random samples with size n from the t-copula with parameters ρ̂ and ν̂. Denote the samples by where j = 1, . . . , 1000. For each j = 1, . . . , 1000, we recalculate the two-step estimator based on the sample which results in Let a and b denote the largest [n(1 − α)/2]-th and [n(1 + α)/2]-th values of Therefore a bootstrap confidence interval for ν with level α is [ν̂ − b, ν̂ − a]. The R package “emplik” is employed to compute the coverage probability of the proposed jackknife empirical likelihood method. These coverage probabilities are reported in Table 1, showing that the proposed jackknife empirical likelihood method is much more accurate than the normal approximation method, and both intervals become more accurate when the sample size becomes large.
4. Empirical study
First, we fit the bivariate t-copula to the log-returns of the exchange rates between the Euro and the US dollar and those between the British pound and the US dollar from January 3, 2000 to December 19, 2007, which gives ρ̂ = 0.726 and ν̂ = 7.543. In Figure 1, we plot the empirical likelihood ratio function l1(ν) against ν from 4.005 to 14 with step 0.005. The proposed jackknife empirical likelihood intervals for ν are (6.025,10.230) for level 0.9, and (5.410,10.910) for level 0.95. We also calculate the intervals for ν based on the normal approximation method as in Section 3, which result in (4.656,9.618) for level 0.9 and (3.847,9.864) for level 0.95. As we see, the intervals based on the jackknife empirical likelihood method are slightly shorter and more skewed to the right than those based on the normal approximation method.
_is_plotted_against__from_4.005_to_14_with_step_0.png)
Second, we fit the bivariate t-copula to the data set of 3283 daily log-returns of equity for two major Dutch banks, ING and ABN AMRO Bank, over the period 1991–2003, giving ρ̂ = 0.682 and ν̂ = 2.617. The empirical likelihood ratio function l1(ν) is plotted against ν in Figure 2 from 1.501 to 3.5 with step 0.001, which shows that the proposed jackknife empirical likelihood intervals for ν are (2.280,3.042) for level 0.9 and (2.246,3.129) for level 0.95. The normal approximation based intervals for ν are (2.257,2.910) for level 0.9 and (2.195,2.962) for level 0.95. As we see, the intervals based on the jackknife empirical likelihood method are slightly wider and more skewed to the right than those based on the normal approximation method. Note that this data set has been analyzed by Einmahl, de Haan, and Li (2006) and Chen, Peng, and Zhao (2009) by fitting nonparametric tail copulas and copulas.
_isplotted_against__from_1.501_to_3.5_with_step.png)
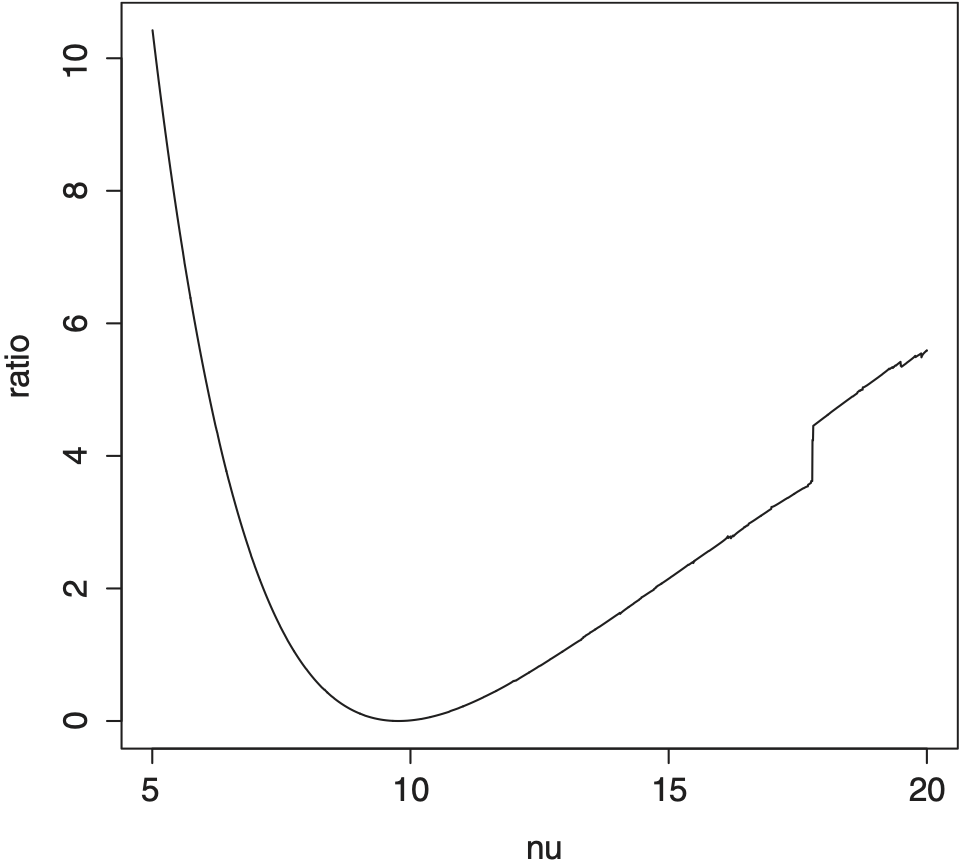
Finally, we fit the t copula to the nonzero losses to building and content in Danish fire insurance claims. This data set is available at www.ma.hw.ac.uk/~mcneil/, which comprises 2167 fire losses over the period 1980 to 1990. We find that ρ̂ = 0.134 and ν̂ = 9.474. The empirical likelihood ratio function l1(ν) is plotted in Figure 3 against ν from 5.005 to 20 with step 0.005. The proposed jackknife empirical likelihood intervals for ν are (6.830,16.285) and (6.415,17.785) for levels 0.9 and 0.95 respectively, and the normal approximation based intervals for ν are (0.978,12.719) and (−2.242,13.070) for levels 0.9 and 0.95 respectively. The above negative value is due to some large values of the bootstrapped estimators of ν, which is a disadvantage of using the bootstrap method. It is clear that the proposed jackknife empirical likelihood intervals are shorter and more skewed to the right than the normal approximation based intervals.
_isplotted_against__from_5.005_to_20_with_step0.png)
5. Proofs
Proof of Theorem 1. Define
g(x,y)=Esign((x−X1)(y−Y1))−τ=4{C(F1(x),F2(y))−EC(F1(X1),F2(Y1))}−2{F1(x)−12}−2{F2(y)−12},ψ(x1,y1,x2,y2)=sign((x1−x2)(y1−y2))−g(x1,y1)−g(x2,y2).
It follows from the Hoeffding decomposition and results in Hoeffding (1948) that
√n{ˆτ−τ}=2√nn∑i=1g(Xi,Yi)+2√nn(n−1)∑1sijjsnψ(Xi,Yi,Xj,Yj)=2√nn∑i=1g(Xi,Yi)+op(1),
which implies Equation (2.1). By the Taylor expansion, we have
0=1√nn∑i=1l(ˆρ,ˆv;Fn1(Xi),Fn2(Yi))=1√nn∑i=1l(ρ,v;Fn1(Xi),Fn2(Yi))+1√nn∑i=1{∂∂ρl(ρ,v;Fn1(Xi),Fn2(Yi))}(ˆρ−ρ)+1√nn∑i=1{∂∂vl(ρ,v;Fn1(Xi),Fn2(Yi))}(ˆv−v)+op(1)=1√nn∑i=1l(ρ,v;F1(Xi),F2(Yi))+1√nn∑i=1lu(ρ,v;F1(Xi),F2(Yi)){Fn1(Xi)−F1(Xi)}+1√nn∑i=1lv(ρ,v;F1(Xi),F2(Yi)){Fn2(Yi)−F2(Yi)}+1nn∑i=1{∂∂ρl(ρ,v;F1(Xi),F2(Yi))}√n(ˆρ−ρ)+1nn∑i=1{∂∂vl(ρ,v;F1(Xi),F2(Yi))}√n(ˆv−v)+op(1),
which implies Equation (2.2). More details can be found in Wang, Peng, and Yang (2013).
The values of σ21, σ12 and σ22 can be calculated in a straightforward manner by using the Law of Large Numbers, which are given by
\begin{array}{l} \sigma_{11}^{2}=\cos ^{2}\left(\frac{\pi \tau}{2}\right) \pi^{2}\left\{\begin{array}{l} 8 \int_{0}^{1} \int_{0}^{1}\left\{\begin{array}{l} 2 C^{2}(u, v) \\ -2(u+v) C(u, v)+u v \end{array}\right\} \\ d C(u, v)+\frac{5}{3}-\tau^{2}+2 \tau \end{array}\right\}, \\ \sigma_{2}^{2}=K_{v}^{-2}\binom{K^{2}+R_{1}+R_{2}+2 R_{3}+2 R_{4}+2 R_{5}+K_{\rho}^{2} \sigma_{1}^{2}}{+2 K_{\mathrm{\rho}}\left(L_{1}+L_{2}+L_{3}\right)}, \\ \sigma_{12}^{2}=-K_{v}^{-1}\left(K_{\rho} \sigma_{1}^{2}+L_{1}+L_{2}+L_{3}\right), \end{array}
where
\begin{aligned} K^{2}= & \int_{0}^{1} \int_{0}^{1} l(\rho, v ; u, v)^{2} d C(u, v), \\ R_{1}= & \int_{0}^{1} \int_{0}^{1} \int_{0}^{1} \int_{0}^{1} l_{u}\left(\rho, v ; u_{1}, v_{1}\right) l_{u}\left(\rho, v ; u_{2}, v_{2}\right) \\ & \left(u_{1} \wedge u_{2}-u_{1} u_{2}\right) d C\left(u_{1}, v_{1}\right) d C\left(u_{2}, v_{2}\right), \end{aligned}
\begin{aligned} R_{2}= & \int_{0}^{1} \int_{0}^{1} \int_{0}^{1} \int_{0}^{1} l_{v}\left(\rho, v ; u_{1}, v_{1}\right) l_{v}\left(\rho, v ; u_{2}, v_{2}\right) \\ & \left(v_{1} \wedge v_{2}-v_{1} v_{2}\right) d C\left(u_{1}, v_{1}\right) d C\left(u_{2}, v_{2}\right), \\ R_{3}= & \int_{0}^{1} \int_{0}^{1} \int_{0}^{1} \int_{0}^{1} l_{u}\left(\rho, v ; u_{1}, v_{1}\right) l_{v}\left(\rho, v ; u_{2}, v_{2}\right) \\ & \left(C\left(u_{1}, v_{2}\right)-u_{1} v_{2}\right) d C\left(u_{1}, v_{1}\right) d C\left(u_{2}, v_{2}\right), \\ R_{4}= & \int_{0}^{1} \int_{0}^{1} \int_{0}^{1} \int_{0}^{1} l_{u}\left(\rho, v ; u_{1}, v_{1}\right) l\left(\rho, v ; u_{2}, v_{2}\right) \\ & \left(I\left(u_{2} \leq u_{1}\right)-u_{1}\right) d C\left(u_{1}, v_{1}\right) d C\left(u_{2}, v_{2}\right), \\ R_{5}= & \int_{0}^{1} \int_{0}^{1} \int_{0}^{1} \int_{0}^{1} l_{v}\left(\rho, v ; u_{1}, v_{1}\right) l\left(\rho, v ; u_{2}, v_{2}\right) \\ & \left(I\left(v_{2} \leq v_{1}\right)-v_{1}\right) d C\left(u_{1}, v_{1}\right) d C\left(u_{2}, v_{2}\right), \\ L_{1}= & \cos \left(\frac{\pi \tau}{2}\right) \pi \int_{0}^{1} \int_{0}^{1} l(\rho, v ; u, v) \\ & \{4 C(u, v)-2 u-2 v\} d C(u, v), \\ L_{2}= & \cos \left(\frac{\pi \tau}{2}\right) \pi \int_{0}^{1} \int_{0}^{1} \int_{0}^{1} \int_{0}^{1} l_{u}\left(\rho, v ; u_{1}, v_{1}\right) \\ & \left\{4 C\left(u_{2}, v_{2}\right)-2 u_{2}-2 v_{2}\right\} \\ & \times\left\{I\left(u_{2} \leq u_{1}\right)-u_{1}\right\} d C\left(u_{1}, v_{1}\right) d C\left(u_{2}, v_{2}\right), \end{aligned}
and
\begin{aligned} L_{3}= & \cos \left(\frac{\pi \tau}{2}\right) \pi \int_{0}^{1} \int_{0}^{1} \int_{0}^{1} \int_{0}^{1} l_{v}\left(\rho, v ; u_{1}, v_{1}\right) \\ & \left\{4 C\left(u_{2}, v_{2}\right)-2 u_{2}-2 v_{2}\right\} \\ & \times\left\{I\left(v_{2} \leq v_{1}\right)-v_{1}\right\} d C\left(u_{1}, v_{1}\right) d C\left(u_{2}, v_{2}\right) . \end{aligned}
Proof of Theorem 2. It follows from Equation (2.3) and the fact that
\begin{aligned} \sqrt{n}(\hat{\lambda}-\lambda) & =\sqrt{n}(\lambda(\hat{\rho}, \hat{v})-\lambda(\rho, v)) \\ & =\sqrt{n} \frac{\partial \lambda}{\partial \rho}(\hat{\rho}-\rho)+\sqrt{n} \frac{\partial \lambda}{\partial v}(\hat{v}-v)+o_{p}(1) . \end{aligned}
Proof of Theorem 3. Here we use similar arguments in Wang, Peng, and Yang (2013). Write Zi = Zi(ν0). Then it suffices to prove the following results:
\frac{1}{\sqrt{n}} \sum_{i=1}^{n} Z_{i} \xrightarrow{d} N\left(0, \sigma_{3}^{2}\right) \text { as } n \rightarrow \infty, \tag{5.3}
\frac{1}{n} \sum_{i=1}^{n} Z_{i}^{2} \xrightarrow{p} \sigma_{3}^{2} \text { as } n \rightarrow \infty, \tag{5.4}
and
\max _{1 \leq i s n}\left|Z_{i}\right|=o_{p}(\sqrt{n}), \tag{5.5}
where σ23 = K2ν σ22.
Write
\begin{array}{l} \frac{1}{\sqrt{n}} \sum_{i=1}^{n} Z_{i}=\frac{1}{\sqrt{n}} \sum_{i=1}^{n} l\left(\hat{\rho}, v_{0} ; F_{n 1}\left(X_{j}\right), F_{n 2}\left(Y_{j}\right)\right) \\ \quad+\frac{1}{\sqrt{n}} \sum_{i=1}^{n} \sum_{j \times i}\left\{\begin{array}{l} l\left(\hat{\rho}, v_{0} ; F_{n 1}\left(X_{j}\right), F_{n 2}\left(Y_{j}\right)\right) \\ -l\left(\hat{\rho}_{i}, v_{0} ; F_{n 1, i}\left(X_{j}\right), F_{n 2, i}\left(Y_{j}\right)\right) \end{array}\right\} \end{array}
and using the arguments in the proof of Lemma 1 in Wang, Peng, and Yang (2013), we have
\frac{1}{\sqrt{n}} \sum_{i=1}^{n} \sum_{j \neq i}\left\{\begin{array}{l} l\left(\hat{\rho}, v_{0} ; F_{n 1}\left(X_{j}\right), F_{n 2}\left(Y_{j}\right)\right) \\ -l\left(\hat{\rho}_{i}, v_{0} ; F_{n 1, i}\left(X_{j}\right), F_{n 2, i}\left(Y_{j}\right)\right) \end{array}\right\}=o_{p}(1) .
Hence, it follows from Equation (5.2) that
\begin{aligned} \frac{1}{\sqrt{n}} \sum_{i=1}^{n} Z_{i}= & \frac{1}{\sqrt{n}} \sum_{i=1}^{n} l\left(\hat{\rho}, v_{0} ; F_{n 1}\left(X_{j}\right), F_{n 2}\left(Y_{j}\right)\right)+o_{p}(1) \\ = & \frac{1}{\sqrt{n}} \sum_{i=1}^{n} l\left(\rho, v_{0} ; F_{1}\left(X_{i}\right), F_{2}\left(Y_{i}\right)\right) \\ & +\frac{1}{\sqrt{n}} \sum_{i=1}^{n} l_{u}\left(\rho, v_{0} ; F_{1}\left(X_{i}\right), F_{2}\left(Y_{i}\right)\right) \\ & \left\{F_{n 1}\left(X_{i}\right)-F_{1}\left(X_{i}\right)\right\} \\ & +\frac{1}{\sqrt{n}} \sum_{i=1}^{n} l_{v}\left(\rho, v_{0} ; F_{1}\left(X_{i}\right), F_{2}\left(Y_{i}\right)\right) \\ & \left\{F_{n 2}\left(Y_{i}\right)-F_{2}\left(Y_{i}\right)\right\} \\ & +\frac{1}{n} \sum_{i=1}^{n}\left\{\frac{\partial}{\partial \rho} l\left(\rho, v_{0} ; F_{1}\left(X_{i}\right), F_{2}\left(Y_{i}\right)\right)\right\} \\ & \sqrt{n}(\hat{\rho}-\rho)+o_{p}(1) \\ = & -\frac{1}{n} \sum_{i=1}^{n}\left\{\frac{\partial}{\partial v} l\left(\rho, v_{0} ; F_{1}\left(X_{i}\right), F_{2}\left(Y_{i}\right)\right)\right\} \\ & \sqrt{n}\left(\hat{v}-v_{0}\right)+o_{p}(1) d \rightarrow N\left(0, \sigma_{3}\right), \end{aligned} \tag{5.6}
i.e., Equation (5.3) holds. Similarly we can show Equations (5.4) and (5.5).
Proof of Theorem 4. Write Similar to the proof of Theorem 3, it suffices to show that
\frac{1}{\sqrt{n}} \sum_{i=1}^{n}\left(Z_{i}, Y_{i}\right)^{T} \xrightarrow{d} N(0, \Sigma) \text { as } n \rightarrow \infty, \tag{5.7}
\frac{1}{n} \sum_{i=1}^{n}\left(Z_{i}, Y_{i}\right)^{T}\left(Z_{i}, Y_{i}\right) \xrightarrow{p} \Sigma \text { as } n \rightarrow \infty, \tag{5.8}
and
\max _{1 \leq i \leq n}\left\|\left(Z_{i}, Y_{i}\right)^{T}\right\|=o_{p}(\sqrt{n}), \tag{5.9}
where
\Sigma=\left(\begin{array}{ll} \sigma_{3}^{2} & K_{v} \sigma_{12} \\ K_{v} \sigma_{12} & \sigma_{1}^{2} \end{array}\right) .
Since almost surely, we have
\begin{array}{l} \frac{1}{\sqrt{n}} \sum_{i=1}^{n} Y_{i}=\sqrt{n}(\hat{\rho}-\rho)+\frac{n-1}{\sqrt{n}} \sum_{i=1}^{n}\left(\hat{\rho}-\hat{\rho}_{i}\right) \\ \quad=\sqrt{n}(\hat{\rho}-\rho)+\frac{n-1}{\sqrt{n}} \sum_{i=1}^{n}\binom{\frac{\pi}{2} \cos \left(\frac{\pi \hat{\tau}}{2}\right)\left(\hat{\tau}-\hat{\tau}_{i}\right)}{+O(1)\left(\hat{\tau}-\hat{\tau}_{i}\right)^{2}} \\ \quad=\sqrt{n}(\hat{\rho}-\rho)+O(\sqrt{n}) \sum_{i=1}^{n}\left(\hat{\tau}-\hat{\tau}_{i}\right)^{2} \\ \quad =\sqrt{n}(\hat{\rho}-\rho)+O(\sqrt{n}) \sum_{i=1}^{n}(O(1 / n))^{2} \\ \quad =\sqrt{n}(\hat{\rho}-\rho)+o_{p}(1) . \end{array}
Thus Equation (5.7) follows from Equations (2.3) and (5.6). Equations (5.8) and (5.9) can be shown by some similar expansions as in Wang, Peng, and Yang (2013).
Proof of Lemma 1. Similar to the proof of Theorem 3, we have
\begin{array}{l} \frac{1}{\sqrt{n}} \sum_{i=1}^{n}\left\{\tilde{Z}_{i}\left(\nu_{0}\right)-\lambda_{0}\right\} \\ \quad=\left\{\frac{\partial \lambda}{\partial \rho}\left(\rho_{0}, \nu_{0}\right)\right\} \sqrt{n}\left(\hat{\rho}-\rho_{0}\right)+o_{p}(1) \end{array}
and
\begin{array}{c} \frac{1}{\sqrt{n}} \sum_{i=1}^{n} Z_{i}\left(v_{0}\right)=-\frac{1}{n} \sum_{i=1}^{n} \frac{\partial}{\partial v} l\left(\rho_{0}, v_{0} ; F_{1}\left(X_{i}\right), F_{2}\left(Y_{i}\right)\right) \\ \sqrt{n}\left(\hat{v}-v_{0}\right)+o_{p}(1), \end{array}
where λ(ρ, ν) is defined in Theorem 2. That is, we can show that
\frac{1}{\sqrt{n}} \sum_{i=1}^{n} Z_{i}^{*}\left(\nu_{0}, \lambda_{0}\right) \xrightarrow{d} N\left(0, \Sigma^{*}\right), \tag{5.10}
where the covariance matrix Σ* can be calculated by Equation (2.3). Further we can show that
\frac{1}{n} \sum_{i=1}^{n} Z_{i}^{*}\left(\nu_{0}, \lambda_{0}\right) Z_{i}^{*^{T}}\left(\nu_{0}, \lambda_{0}\right) \xrightarrow{p} \Sigma^{*} \tag{5.11}
and
\max _{1 \leq i \leq n}\left\|Z_{i}^{*}\left(v_{0}, \lambda_{0}\right)\right\|=o_{p}\left(n^{1 / 2}\right) \tag{5.12}
Hence, the lemma can be shown in the same way as Lemma 1 of Qin and Lawless (1994) by using Equations (5.10)–(5.12).
Proof of Theorem 5. Using the same arguments in the proof of Theorem 1 of Qin and Lawless (1994), it follows from Equations (5.10)–(5.12) that
\binom{\tilde{\lambda}_{3}}{\tilde{v}-v_{0}}=S_{n}^{-1}\binom{-Q_{1 n}\left(v_{0}, 0\right)+o_{p}\left(n^{-1 / 2}\right)}{o_{p}\left(n^{-1 / 2}\right)},
where
\begin{aligned} S_{n} & =\left(\begin{array}{ll} \frac{\partial Q_{1 n}\left(v_{0}, 0\right)}{\partial \lambda_{3}} & \frac{\partial Q_{1 n}\left(v_{0}, 0\right)}{\partial v} \\ \frac{\partial Q_{2 n}\left(v_{0}, 0\right)}{\partial \lambda_{3}} & 0 \end{array}\right) \xrightarrow{p}\left(\begin{array}{cc} S_{11} & S_{12} \\ S_{21} & 0 \end{array}\right) \\ & =\left(\begin{array}{ll} -\mathrm{E}\left\{Z_{1}^{*}\left(v_{0}, \lambda_{0}\right) Z_{1}^{* T}\left(v_{0}, \lambda_{0}\right)\right\} & \mathrm{E}\left\{\frac{\partial Z_{1}^{*}\left(v_{0}, \lambda_{0}\right)}{\partial v}\right\} \\ \mathrm{E}\left\{\frac{\partial Z_{1}^{*}\left(v_{0}, \lambda_{0}\right)}{\partial v}\right\} T & 0 \end{array}\right) . \end{aligned}
By the standard arguments of the empirical likelihood method (see proof of Theorem 1 in Owen 1990), it follows from Lemma 1 that
\begin{aligned} l_{3}( & \left.\tilde{\boldsymbol{v}}\left(\lambda_{0}\right), \lambda_{0}\right)=2 \sum_{i=1}^{n} \log \left\{1+\tilde{\lambda}_{3}^{T} Z_{i}^{*}\left(\tilde{\mathbf{v}}, \lambda_{0}\right)\right\} \\ & =2 n\left(\tilde{\lambda}_{3}^{T}, \tilde{\mathbf{v}}^{T}-\boldsymbol{v}_{0}^{T}\right)\left(Q_{1 n}^{T}\left(v_{0}, 0\right), 0\right)^{T} \\ & \quad +n\left(\tilde{\lambda}_{3}^{T}, \tilde{\mathbf{v}}^{T}-v_{0}^{T}\right) S_{n}\left(\tilde{\lambda}_{3}^{T}, \tilde{\mathbf{v}}^{T}-v_{0}^{T}\right)^{T}+o_{p}(1) \\ & =-n\left(Q_{1 n}^{T}\left(v_{0}, 0\right), 0\right) S_{n}^{-1}\left(Q_{1 n}^{T}\left(v_{0}, 0\right), 0\right)^{T}+o_{p}(1) \\ & =-\left(W^{T}, 0\right)\left(\begin{array}{ll} S_{11} & S_{12} \\ S_{21} & 0 \end{array}\right)^{-1}\left(W^{T}, 0\right)^{T}+o_{p}(1), \end{aligned} \tag{5.13}
as n → ∞, where W is a multivariate normal random variable with mean zero and covariance matrix S11. Since
\left(\begin{array}{ll} S_{11} & S_{12} \\ S_{21} & 0 \end{array}\right)^{-1}=\left(\begin{array}{ll} S_{11}^{-1}-S_{11}^{-1} S_{12} \Delta^{-1} S_{21} S_{11}^{-1} & S_{11}^{-1} S_{12} \Delta^{-1} \\ \Delta^{-1} S_{21} S_{11}^{-1} & -\Delta^{-1} \end{array}\right),
where Δ = S21 S−111 S12, we have
\begin{aligned} -( & \left(W^{T}, 0\right)\left(\begin{array}{ll} S_{11} & S_{12} \\ S_{21} & 0 \end{array}\right)^{-1}\left(W^{T}, 0\right)^{T} \\ = & -W^{T}\left\{S_{11}^{-1}-S_{11}^{-1} S_{12} \Delta^{-1} S_{21} S_{11}^{-1}\right\} W \\ = & \left\{\left(-S_{11}\right)^{-1 / 2} W\right\}^{T} S_{11}^{1 / 2}\left\{S_{11}^{-1}-S_{11}^{-1} S_{12} \Delta^{-1} S_{21} S_{11}^{-1}\right\} \\ & S_{11}^{1 / 2}\left\{\left(-S_{11}\right)^{-1 / 2} W\right\} \\ = & \left\{\left(-S_{11}\right)^{-1 / 2} W\right\}^{T}\left\{I-S_{11}^{-1 / 2} S_{12} \Delta^{-1} S_{21} 1_{11}^{-1 / 2}\right\} \\ & \left\{\left(-S_{11}\right)^{-1 / 2} W\right\} . \end{aligned} \tag{5.14}
Since
\operatorname{tr}\left(S_{11}^{-1 / 2} S_{12} \Delta^{-1} S_{21} S_{11}^{-1 / 2}\right)=\operatorname{tr}\left(\Delta^{-1} S_{21} S_{11}^{-1} S_{12}\right)=1
we have Hence it follows from Equations (5.13) and (5.14) that as n → ∞.
Acknowledgment
We thank the anonymous Variance reviewers for their helpful comments. Peng’s research was supported by the Actuarial Foundation.