1. Introduction
Actuarial activities have long relied on judgment from experts. For instance, reserving for long-tailed classes of business beyond the width of the triangle requires actuarial judgment from a variety of inputs, both technical and non-technical (see, for example, p. 86 of Herman, Shapland, and Party 2013). Among many modeling tasks, expert judgment is often used to calibrate or validate the parameters of actuarial models. The case for its use is clear when data is lacking, as is often the case in the P&C industry. But even when data is available, judgment is required to determine what data should be used and what should be excluded. Moreover, even the use of the most sophisticated parameterization technique backed by an abundance of data would require subject experts to supply any so-called “broken-leg cues.” These cues are additional pieces of information that would significantly change one’s original estimates based on history (see, for example, Bunn and Wright 1991). Insights into how we interpret information to form judgments are therefore welcome in the industry and useful to actuaries.
Thus far, literature on expert judgment in the P&C industry has been limited to publications outside the traditional peer-reviewed journals. Certainly, various documents on expert judgment in relation to Solvency II exist (see, for example, Chapter 5 of GIRO IMAP Working Party 2012). Actuarial conferences and practitioner magazines are now peppered with topics such as cognitive heuristics and biases (Barley and Ellis 2013; Fulcher and Edwards 2013; Lo 2013; Lo, Tredger, and Hlavka 2013; Mango 2012).
To use the terminology of section 2.2 of O’Hagan (2006), experts in the P&C industry can be classified into two groups: the substantive experts and the normative experts. Roughly speaking, the substantive experts are subject experts in their own fields. They are likely to be underwriters, claims handlers, and investment officers in a P&C company. The normative experts are those who have expertise in statistics and probability theory. They are likely to be the actuaries and statisticians. Both groups in the P&C company will likely provide input into modeling parameters. It is therefore of immense interest to consider if these two groups make their judgments significantly differently from one another.
One can reasonably speculate as to the various reasons why the two groups might make different judgments in general. There may be information asymmetry. Different incentives—financial or nonfinancial—could cause material judgmental biases. There may also be a personality difference, anecdotally associated with the roles the experts hold in the company. The bright and entrepreneurial underwriters might make more optimistic judgments than the gloomy and cautious actuaries. Of these three reasons, the last is perhaps the most difficult to manage, and most in need of further understanding. While information asymmetry could be addressed by better sharing of information, and incentivization is to some extent a clear and given feature in any organization, issues related to personality traits can be very hard to spot. We have therefore focused on the role factor in a (re)insurance company, leaving the other two factors for future studies.
To explore how forming judgments relates to one’s role in a company, we devised a prediction survey consisting of four questions (Section 2). There were specific features of the survey that helped all respondents to be equally informed and equally incentivized. One hundred and twenty responses were obtained, split roughly evenly between the two expertise groups: underwriters and analysts. The quantitative predictions and any qualitative comments were analyzed to detect any significance differences between the two groups.
From the quantitative predictions, we did not find evidence to suggest that the two groups make different judgments when they had the same information and were similarly incentivized (Section 3). From the qualitative comments, we obtained insights as to how our respondents interpreted the given information to come up with their predictions (Section 4). The presence of an outlier in the most recent data point was influential. Where comments were not revealing, we also made conjectures to potentially explain observed differences (Section 5).
Besides presenting findings from our internal prediction survey, this paper argues for further scientific research in the area of expert judgments in actuarial activities (Section 7). This research can be scientific in the sense that testable hypotheses are made and tested, to further explain and predict how experts make judgments in the P&C context. Such research would form a key ingredient into devising effective policies and guidance for working with actuarial models. Our small-scale study is a first attempt, which will hopefully encourage better-funded and larger-scale research to be made in this important actuarial area.
Before we proceed, we note that the study was designed to gain insights into how experts form judgments, rather than to give estimates for any particular concrete commercial purposes, which would require more involved estimation processes. The reader should therefore not rely on findings presented here outside of the intended purpose of the study. In particular, the views expressed in this paper are solely those of the authors and no official views from the authors’ employer organization should be deduced from the paper.
2. The challenge
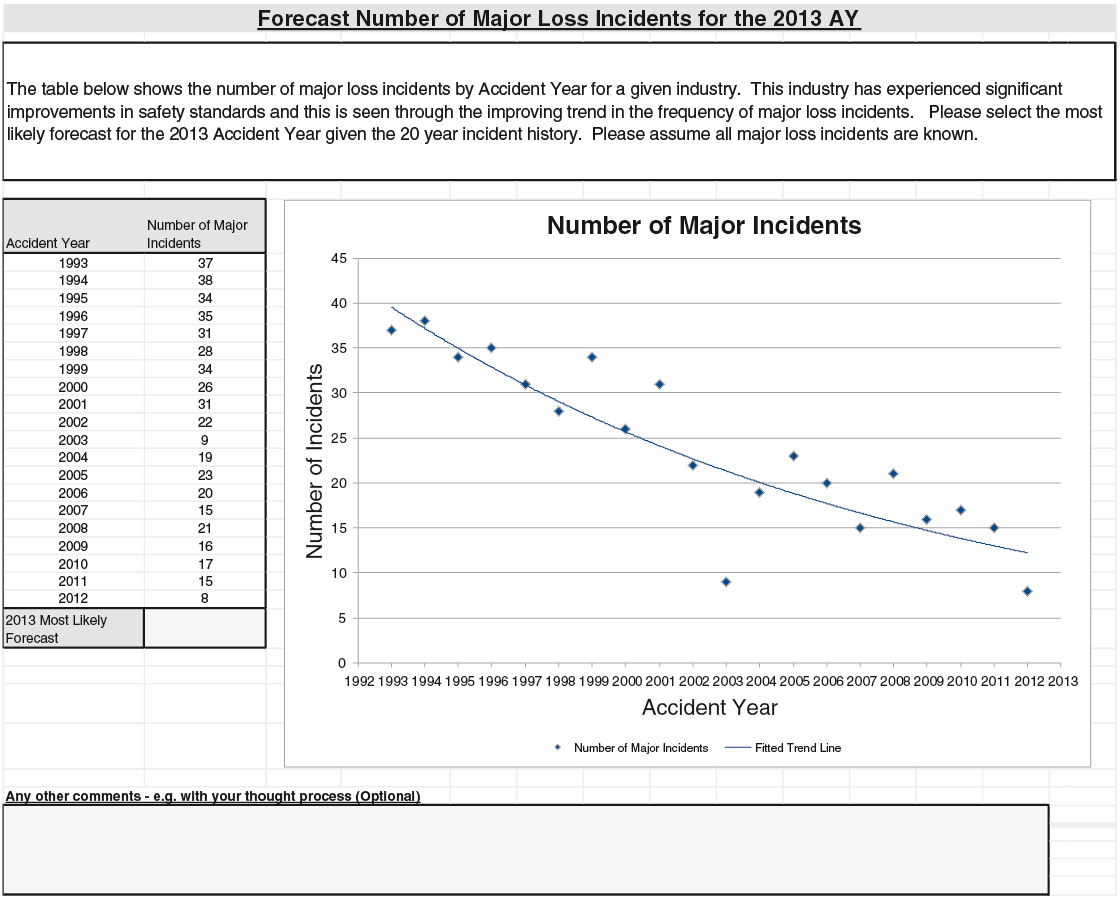
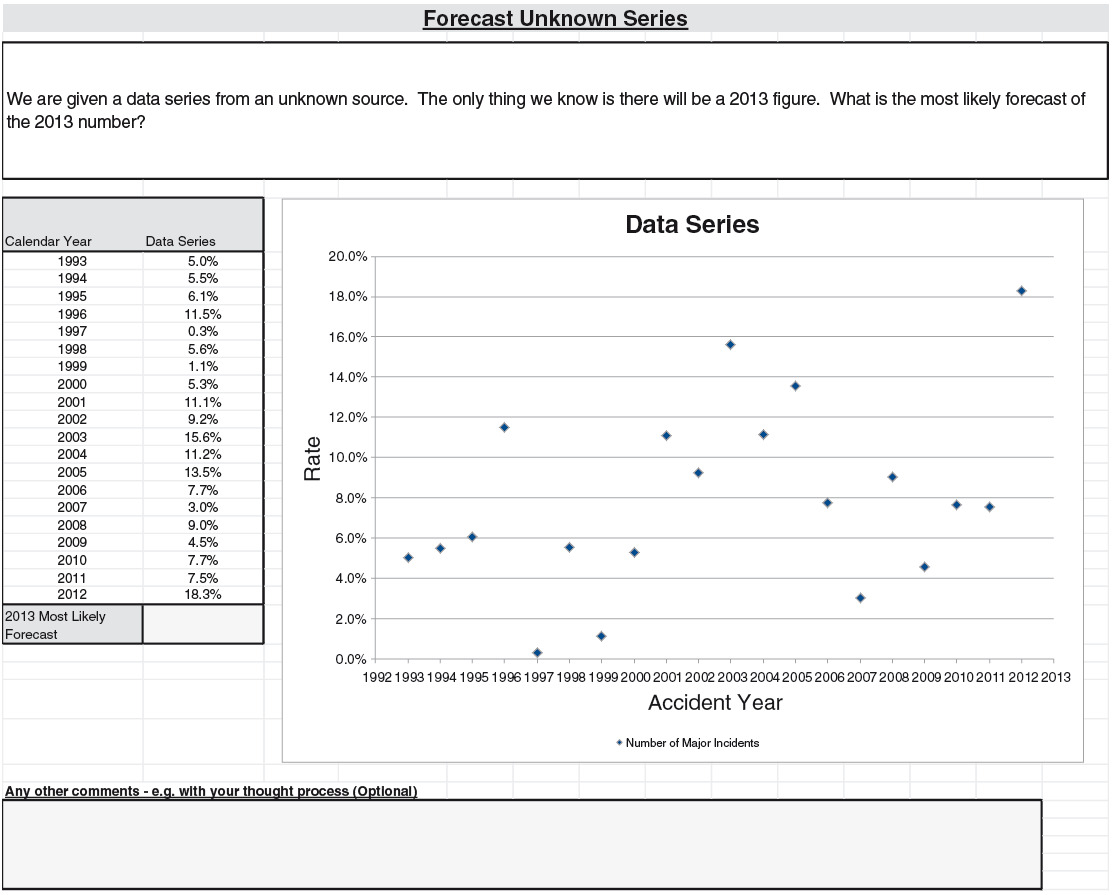
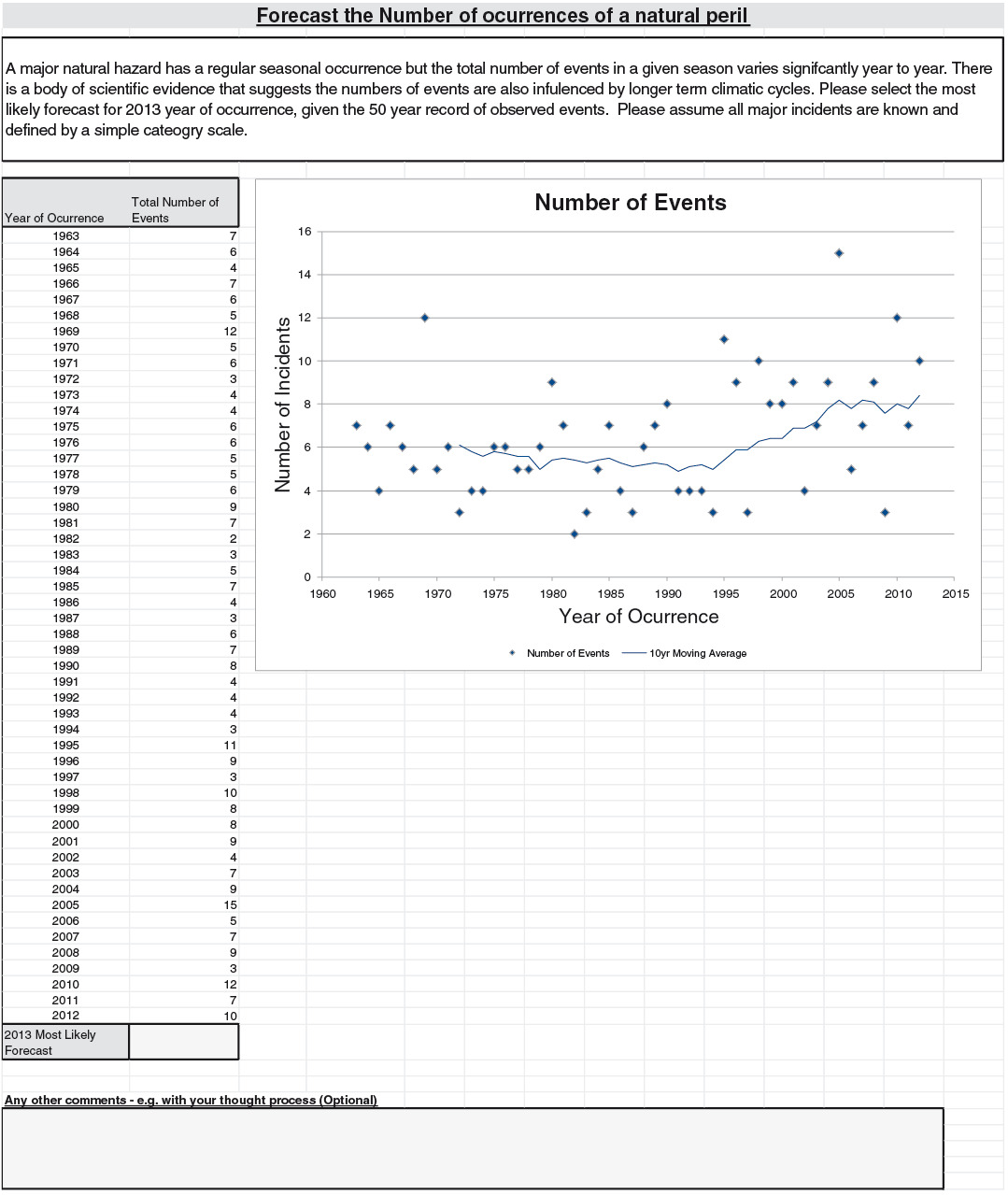
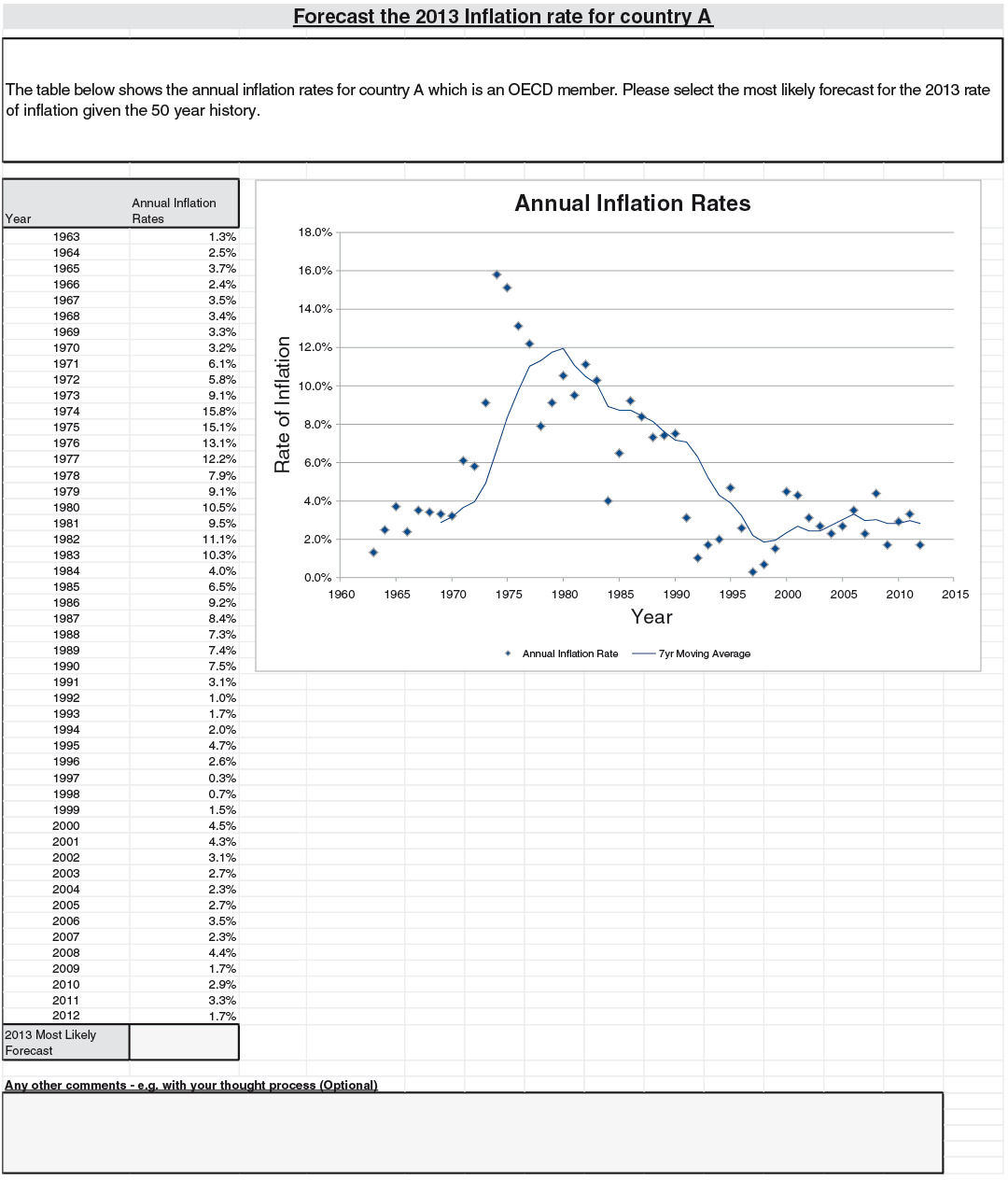
The survey consisted of four prediction problems that were P&C related. All of them contained a few sentences that described the general context, a table of annual data series, and a chart that represented the series. The chart has various features such as trend lines that are typical in other similar data analyses.
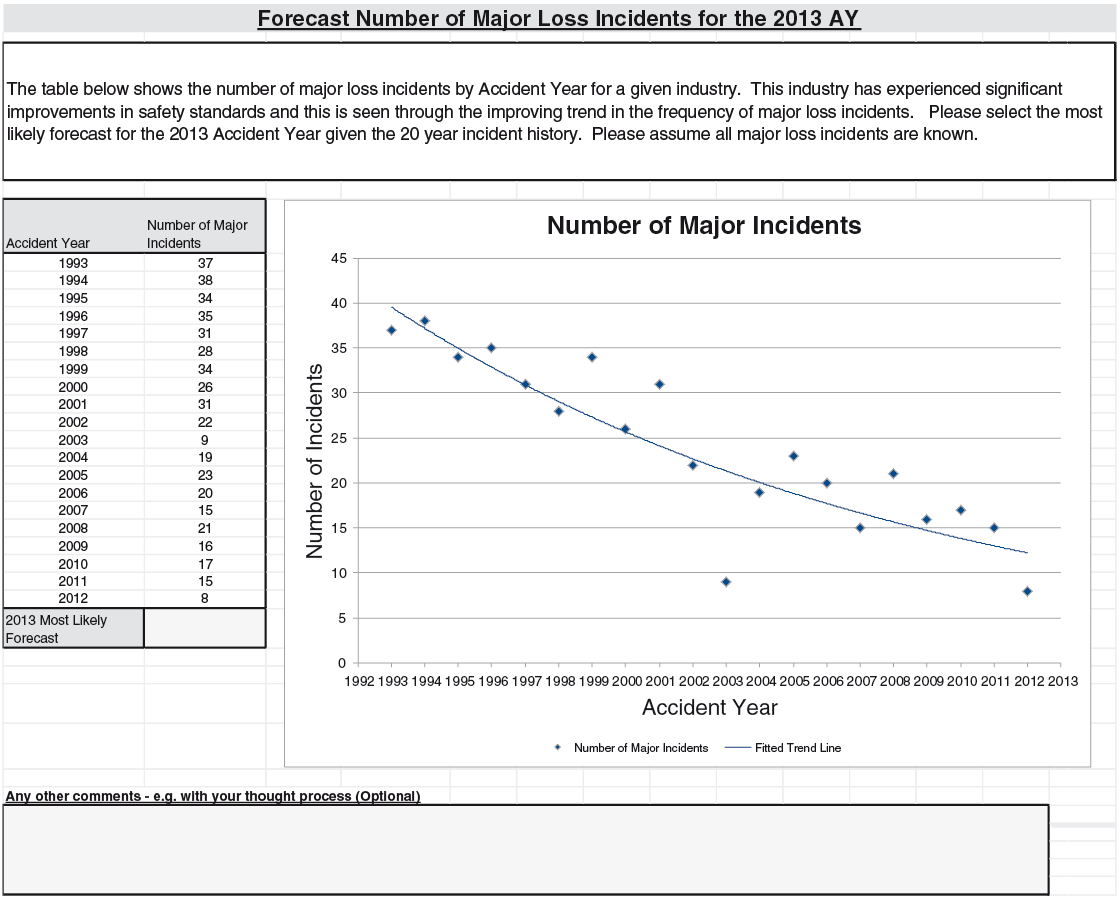
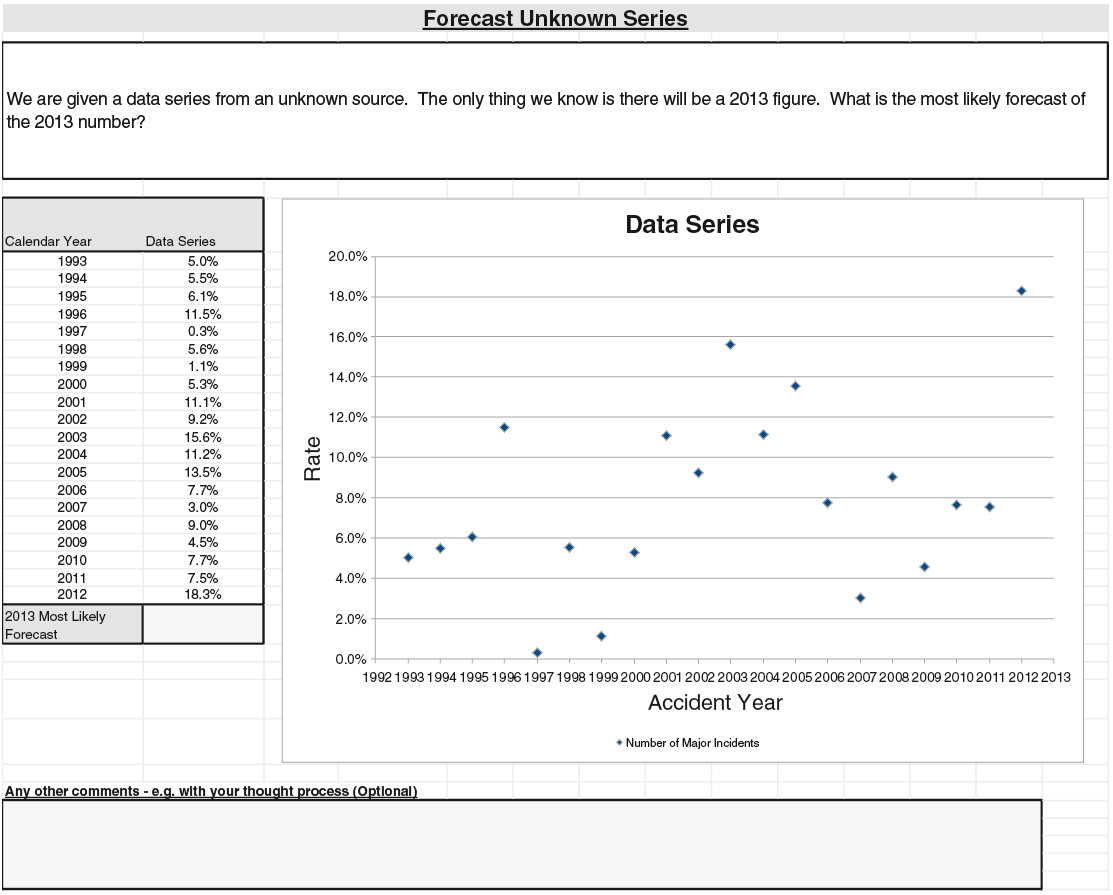
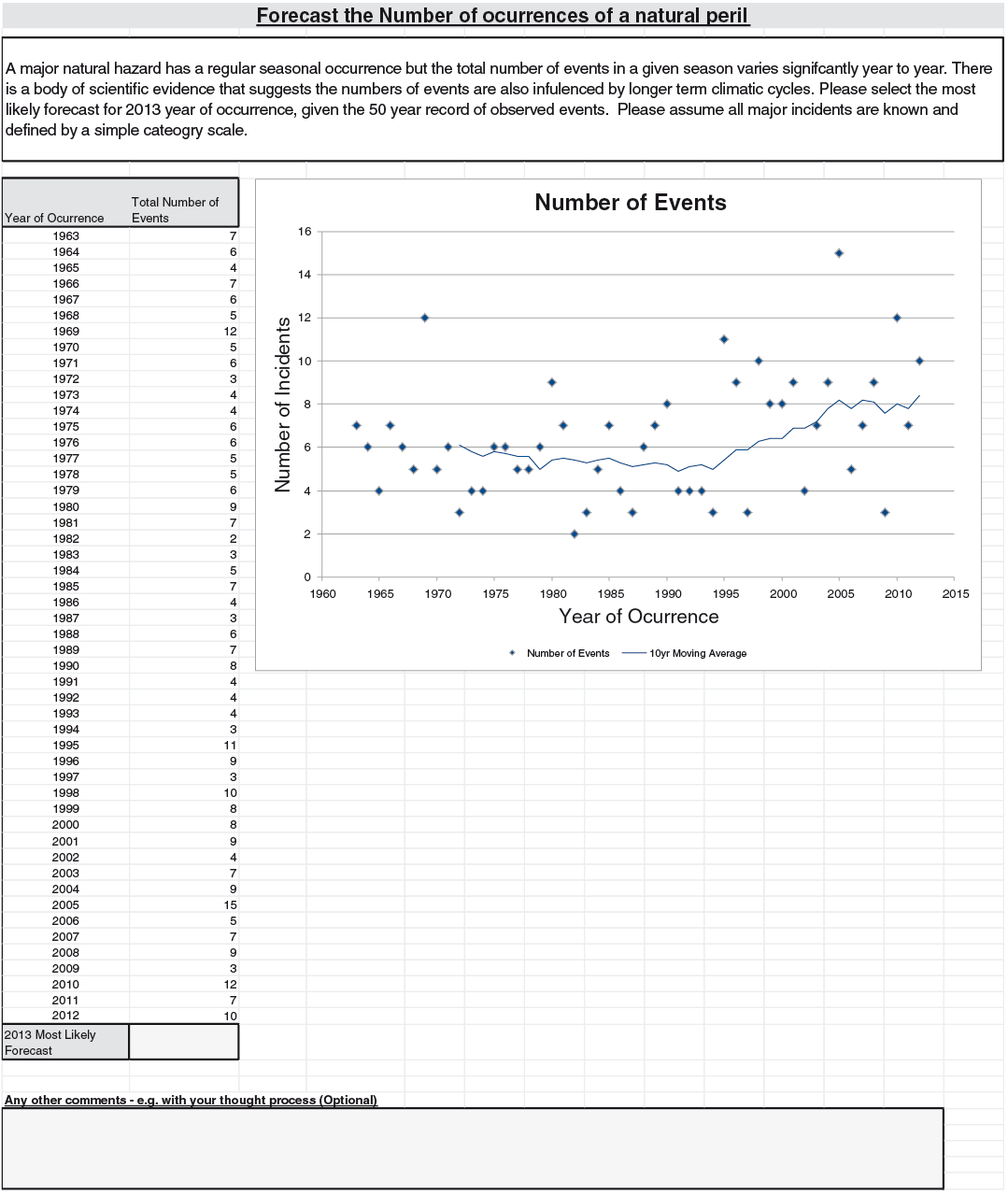
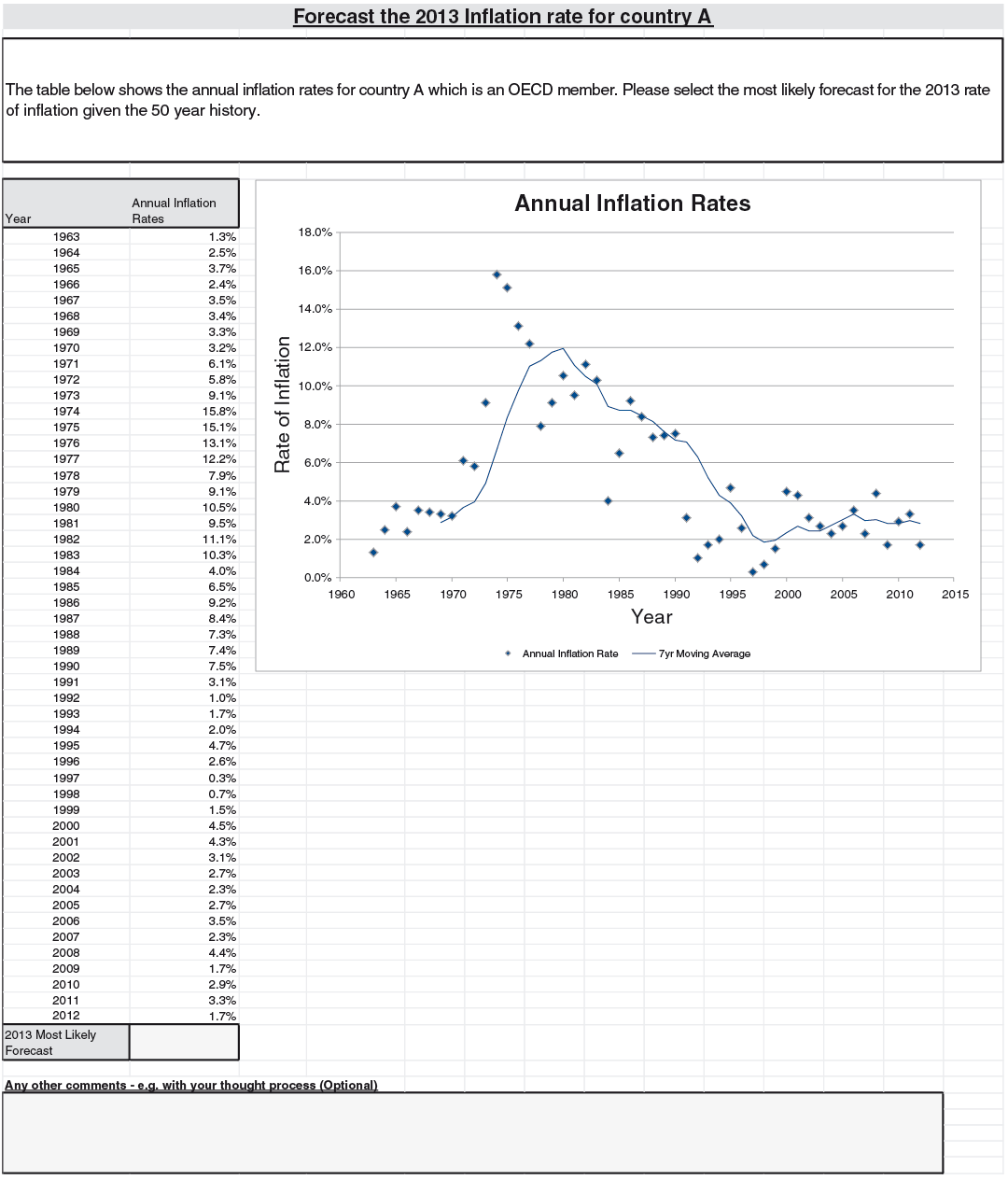
The four problems were based on (Q1) annual counts of major airline incidents, (Q2) an independently generated series, (Q3) annual counts of small North Atlantic hurricanes, and (Q4) Australian inflation rates. For (Q1), “major” is defined to be an airline accident that involves at least one fatality, with the series spanning from 1993 to 2012. The independence mentioned in (Q2) is where we have generated a set of 20 independent data points from the normal distribution for the data series, labelled from 1993 to 2012. For (Q3), we have used the annual frequency of category 1 hurricanes from 1963 to 2012, and for (Q4) we have used the price inflation figures from Australia for the same period. The respondents were asked to provide a most likely value for 2013 for each series.
For everyone to have roughly similar amounts of information, the problems were made relatively generic. (Q1) only described the events as “major loss incidents,” and did not mention the class (“aviation”) explicitly. Hurricanes were not mentioned in (Q3), only the phrase “natural peril.” For (Q4), “an OECD country” was described rather than suggesting Australia by name. Moreover, the series had twists to them, so that even those with coincidental subject expertise would not gain too much of an advantage. For example, for hurricane occurrence, we limited ourselves to category 1 hurricanes.
The requested forecast was described as “most likely”—or, statistically, we were looking for the mode. This was judged the most expedient. The mean can be very difficult to estimate properly via quick judgments and would not help towards considering the hypothesis at hand. The median can be challenging to ask for: “a point, under and over which the 2013 figure would lie with equal probability” is a more confusing phrase than “2013 most likely forecast.”
The survey was formulated in an Excel workbook with four tabs: one for each question. A list of underwriters (including claims adjusters) and analysts (risk management, cat risk management, actuarial, finance) was constructed. The survey workbook was sent to them by email as an attachment on 22 July 2013. They were asked to spend at most around 15 minutes on the survey. The initial deadline of mid-September 2013 was extended ultimately to end of September. The Appendix reproduces the information that was presented in the workbook to our respondents.
There were two incentives. First, to encourage participation, the respondents knew that we would be donating a small sum to a developmental charity for each response. Second, to encourage best effort, respondents knew that there would be a prize for the best response.
3. The responses
There were in total 120 responses, split evenly between underwriters (UW, 62) and analysts (A, 58). We have not been able to keep track of who saw our email invitation to participate in the survey and who did not in our organization. By indication, there are approximately 1.5 times as many subject experts such as underwriters and claim adjusters, which we would class in the UW group, as there are analytic experts such as actuaries, risk managers, and those in finance, which we would class in the A group.
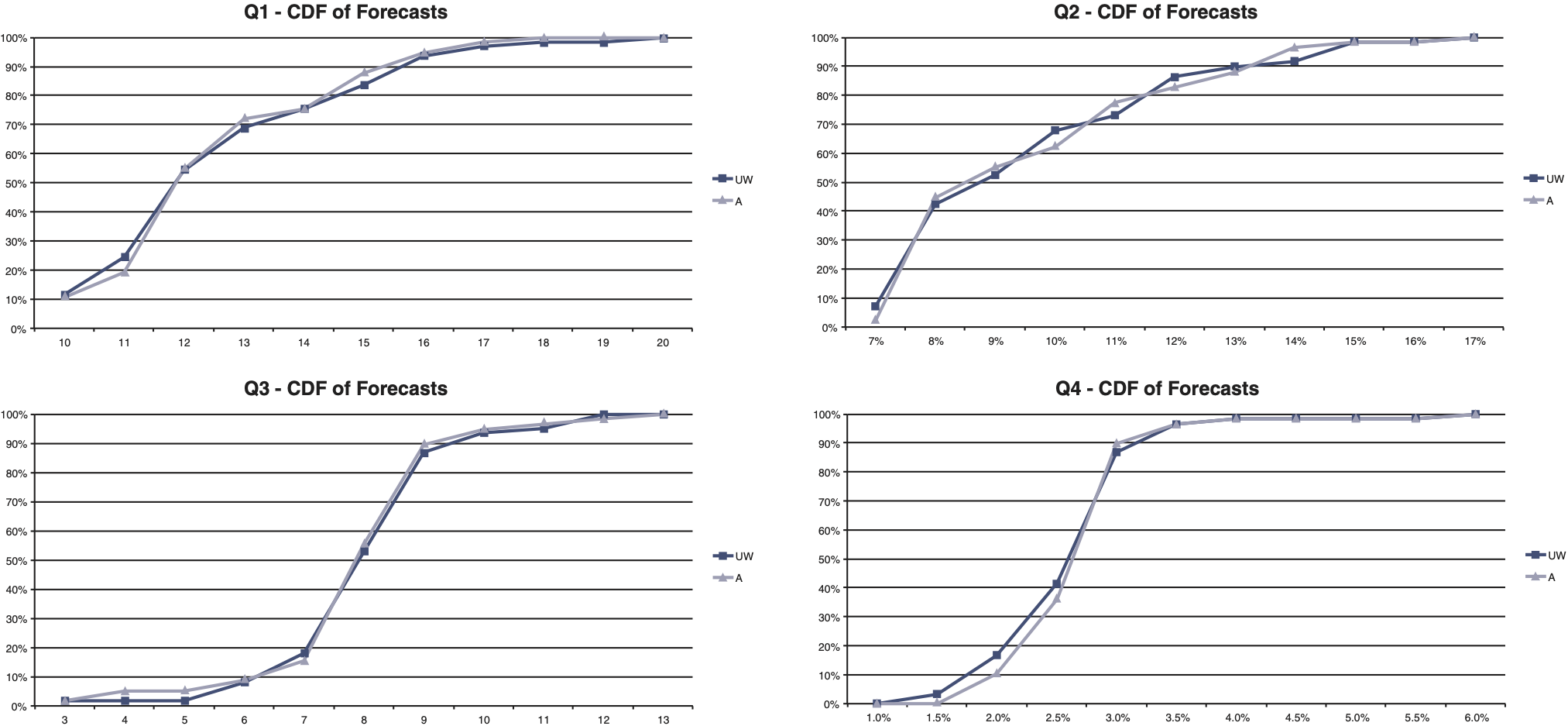
Organizing the predictions into CDF plots as in Figure 1, one immediately sees that there is very little difference between the collective responses of the two groups.
_and_(uw)_groups.png)
The simple normal mean tests did not show any statistical significance. Only three instances of binomial tests showed a significant result—corresponding to the answer of 7% for (Q2), and to the answers of 4 and 5 for (Q3).
What is striking in this test is the consistency of results from the four very diverse problems. In each case, we have seen the same overlapping features in the CDF plots. An obvious conclusion to make would be that differences in judgment do not stem from one’s own professional background in a P&C organization. We note further that the shapes of the CDFs also differ from one question to the other.
It can be argued, however, that the way in which our survey was engaged with could also have contributed to the results, thus making the obvious conclusion less decisive. Selection biases are a potential, although not entirely clear-cut, way to explain the overlapping CDF plots. It is possible that there are selection biases in the type of respondents choosing to respond to the survey: there is a lower number of responses from the UW group to the number of invited UW members, than the corresponding numbers from the A group. One way to explain the similarity of the CDFs between the two groups is to suggest that those choosing to respond to the survey—whether in the A or UW group—have a similar analytical outlook, thereby giving similar judgments. We observe that our invited experts had numerous other priorities, and that responding to a survey was often declined due to perceived lack of time for engagement. The perception of whether one has time for a particular survey could surely have links with whether one thought the subject surveyed was judged important to them. However, there may also be other reasons, such as whether the invitees were particularly busy during the survey period, or even whether they enjoyed responding to surveys in general. This multitude of reasons for not responding to the survey suggests to us that we need to be cautious of using selection biases as a key explanatory factor.
Furthermore, we shall comment in more detail in Sections 4 and 5 that there are large variations in responses, whether they come from the UW group or the A group. To a large extent, the variations are driven by how the respondents interpreted the data (Section 4). We shall also consider how cognitive heuristics and biases may play an important part (Section 5). Both sections, then, downplay the A-UW group split as a main factor for differences in judgments, emphasizing the judgmental processes internal to the respondents instead.
4. Two ways of thinking
Around 40% of the answers from respondents were accompanied by comments. Analyzing these comments suggested that, for each of the four problems, there were two broad ways to interpret the data: these are summarized in Table 1. Depending on which way the respondents followed, their forecasts can be very different. In this section, we focus on this 40% of the respondents who gave comments.
(Q1): The 2013 point is thought to either follow a general downward trend that appears throughout the data history or to be part of a new regime that was introduced at around the year 2002. The 51% of respondents that followed the first line of thought gave forecasts that averaged 11.7; those 34% following the second line naturally gave higher forecasts, averaging at 15.3.
The 2012 point was influential. In total, 15 comments (around 28% of the total) explicitly mentioned this point as an outlier. However, only one-ninth of those in the trending group mentioned this, while only two-thirds in the new-regime group were aware of this 2012 point. To put this in perspective, the 2003 data point—arguably also an outlier—was explicitly commented on much less frequently: there were only three such comments. The focus on recent outliers by experts is echoed in the literature (see, for example, p. 245 of Goodwin and Wright 2009).
(Q2): The question here is whether to make use of the perceived trend or not. Around 21% of respondents made use of an upward trend, giving predictions that averaged 12.1%. Some 54% used methods that were based on there being no trend, to give predictions that averaged 8.5%. The second group naturally gave a better answer, as the generating distribution was a normal with 8.0% mean.
(Q3): At issue here was how to treat the data points from before 1995. The suggested climatic cycle was evaluated against the volatility shown in the data points. Around 58% of the respondents did not make use of data before 1995 for their estimates of the 2013 point. A significant minority of 20% explicitly made use of this data before 1995 (the remaining 22% did not comment either way). The difference in the mean forecast is relatively small: 8.5 for the first group compared with 7.5 for the second.
(Q4): Inflation is an economic factor on which our respondents had much to say. A range of economic and political points were made, from quantitative easing to the effectiveness of political institutions in OECD countries to control inflation. Around 41% of respondents made use of such information. Nevertheless, around 46% focused only on graphical features (the remaining 13% did not explicitly comment either way). The two groups gave very similar answers on average.
5. The availability heuristic
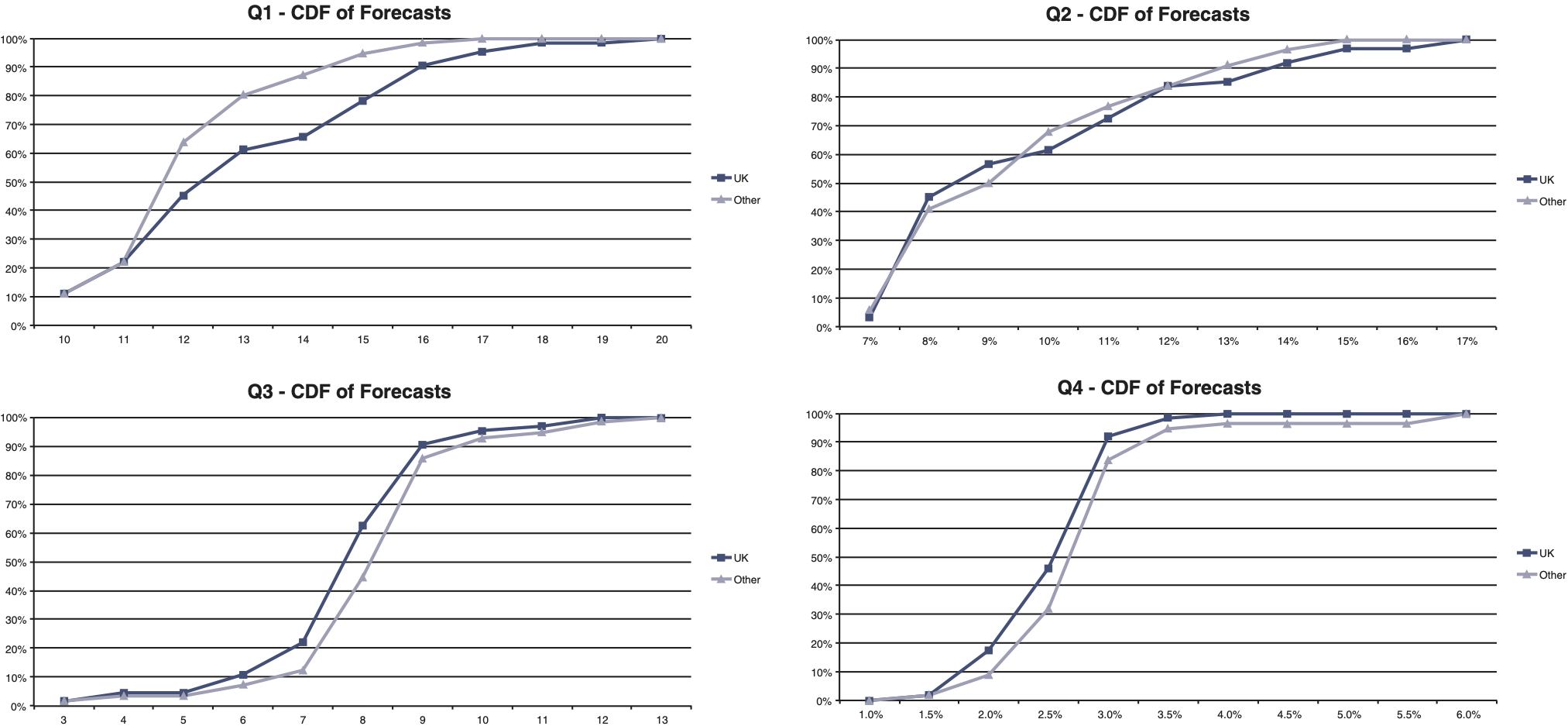
The location of respondents could drive different levels of forecasts. Figure 2 gives the CDF plots of the responses for those based in the U.K. and those outside the U.K. The demographic of the responses was such that there were 64 responses from the U.K., with the remaining 56 from outside. We did not further split the non-U.K. group due to statistical credibility. We note that the majority, 34 responses, in this group were from the U.S. The rest were shared between Bermuda, continental Europe, and Singapore.
_and_(nonuk)_groups.png)
On the one hand, the binomial tests gave significant results at the 5% level for central answers of 12 to 16 for (Q1), 7 to 8 for (Q2), and 2.0% to 3.0% for (Q4). This indicates a level of association between location and level of forecast.
On the other hand, there seems to be very little in the comments to give us clues on how the respondents thought about the problem differently by location. For instance, there is little to suggest that the U.K. group followed a particular way of thinking, mentioned in Section 4 above.
The cognitive heuristics are natural candidates to explain the observed differences between the two groups. As well as being real, they operate through intuition, with the consequence that any influence from such heuristics would be unlikely to be documented in our respondents’ comments. One such well-known heuristic is the availability heuristic. This is where frequency estimates are made according to the ease with which events or incidences are called to mind (Section 3.4.1, O’Hagan 2006). To the extent that an overestimation of probabilities for high event occurrence affects levels of forecast, the availability heuristic would affect our respondents’ estimates.
That (Q2) did not reveal significant differences between underwriters and analysts supports the presence of the availability heuristic. The lack of contextual information associated with (Q2) means that there are no obvious events or incidences which the respondents could call to mind with ease or otherwise. The availability heuristic is not expected to work for (Q2).
From (Q1)'s perspective, one could conjecture that the U.K. respondents might be more impacted by reports of “major incidences,” due to their proximity to the London Market, one of the world’s largest marine and aviation insurance markets. This in turn could translate into higher estimates for event occurrence from this group, as the respondents could more easily call to mind large losses.
For (Q3) and (Q4), speculation could be made that respondents in the U.S. were in an environment where the natural perils and economic issues were more intensely discussed and debated. The coincidence between the period of the survey and the first half of the hurricane season might have heightened the issue. We note that the U.S. is unique in the recent heated public discussions about the public debt ceilings, a debate that one might imagine would overflow into inflation considerations.
As we did not set out to test for a hypothesis on the availability heuristic, the survey was not designed to confirm it. More tailor-made tests could be designed to test this effect in the P&C context. While the discussion of this section seems plausible, the authors are also aware that they could be open to the confirmation bias—another famous cognitive bias, under which one tends to look for evidence to support one’s hypotheses!
6. Implications
Being mindful of the present small-scale nature of the research that was conducted under the specific context of a particular global and diverse P&C company, any conclusions will likely be somewhat tentative in nature. However, the following suggestions do not seem unreasonable:
-
It is unlikely that being an actuary or being an underwriter per se would give rise to relative biases in initial judgments—at least in our own survey sample, and for the type of exercise in one-step predictions of data series. If anything, this should help set aside anecdotal preconceptions surrounding how specific personality traits or characteristics associated with particular expertise would generally lead to different judgments. This, in turn, would help focus attention on other areas pertaining to fruitful collaborations, such as divergent interpretations on the same pieces of information, information asymmetry, or differing incentivization.
-
With our four problems, there were consistently two (and potentially more) very different ways to interpret the data series. We saw that in at least two of the cases, these can lead us to very different projections. As the experts contemplate the problem beyond initial judgments, they could usefully be exposed to different interpretations of the data. The pairs discussed in our analyses of Section 4 would be a good start, although no doubt there would be more. Considering why one’s estimates may be wrong can also be helpful (see, for example, Principle 14.6 of Armstrong 2001). We highlight the importance of considering if the latest data point is an outlier, which has also been observed by, for example, Harvey (2001) and references therein.
-
The availability heuristic can be strong in experts, even when presented with exactly the same hard datasets. One obvious candidate to dilute the effects of the availability heuristic is to involve another expert who may be exposed to very different environments. This other expert may be based overseas or may have a substantially different experience history. However, judging who to choose for this second pair of eyes could be tricky, as often the availability heuristic could act indirectly (see Section 3.4.1 of O’Hagan 2006). Another candidate is the first principle to reduce overconfidence in Arkes (2001), which encourages the experts to consider alternatives. Helpfully, even if ironically so, the availability heuristic also operates on imagined situations, so that even just thinking about (alternative) scenarios could help. For the natural hazard question (Q3), how might my judgement change, if, in the last few years, natural catastrophes happened to have been much lighter (or heavier) in my country? Would I give a different estimate for the inflation question (Q4) if the recent intense political debates were absent in the national newspapers and media?
7. Research questions
We conclude the paper by highlighting three areas where research would be helpful.
-
The survey was very much an exercise among a group of experts in a P&C company. We would encourage other practitioners to embark on similar projects within their own organizations and share their findings as well. Results from refined re-runs of this experiment can be interesting. For instance, responses from the analyst group could be analyzed further for differences between actuaries and other analytical professionals. In other settings, the non-U.K. group could be more granularly considered to bring to light how professionals from different cultural backgrounds might consider judgmental problems.
The project certainly helped us understand in a deeper and more tangible way how experts think in our organization. It also gave us a chance to critique different ways of presenting and communicating information. More importantly, in terms of progressing actuarial knowledge in general, with the ultimate aim of the actuarial profession being to provide better services to the public, the sharing of high-level findings is especially important. In scientific studies, it is commonly advocated that confirmation through independent experiments is important to establish assertions. Moreover, the meager empirical information in the literature does not help generate hypotheses for further testing.
-
If the above suggests similar tests on other groups of experts, we would also suggest new tests to be devised to follow up on the results in this paper.
The incentive factor is worth understanding more. We stress, however, that it should not be limited to remuneration alone. One would imagine that the attachment of experts to a subject they have spent their whole career championing can be immense, even in the absence of hard financial incentives.
Another interesting line of inquiry is to consider how one might revise one’s initial judgments. Even if analysts and underwriters of Section 3 gave similar CDFs, random pairs of individuals are very likely to give materially different answers. In reality, this pair of individuals would share their findings and their estimations may undergo revisions before final selections are made. Research into this process can give helpful insights and suggest practical collaboration modes.
The particular one-step prediction exercises can be very simple. In reality, actuaries and underwriters are often challenged by more complex prediction problems. The two- and possibly three-dimensional question of projecting claim triangles immediately comes to mind for reserving and pricing. Extensions into the probabilistic dimension are also critical for capital modeling. Another area of interest is how weights are selected for the different historical data points when fitting distributions under different circumstances. Finally, how perception of insurance risk is judgmentally translated into pricing is an interesting and relevant issue, the results of which would enrich the discussion on capital allocation methods and their implementation.
The roles played by the actuary and the underwriter are surely different in actual applications and in different organizations. But to the extent that collaborations and communications between the two groups are relied upon for successful modeling, understanding how the two groups would deal with these more complex questions on their own would be a good topic to investigate.
-
Our third research area relates to cognitive heuristics and biases. Very little empirical research has been done on actuarial subjects. Sporadic studies among professionals in their field of expertise have been performed in the past: for example, on life underwriters (Wright, Bolger, and Rowe 2002) and on auditors (Asare and Wright 1995). More studies among actuaries and underwriters would be interesting to validate general psychological findings in the work of the P&C industry more specifically.
There are two useful areas to consider. One is how the general cognitive heuristics and biases are operative among insurance experts in their expertise areas. We see that, with training, quick and apparently intuitive decisions can be appropriate and accurate (see, for example, Chapter 22 of Kahneman 2011). Confirming this, and considering where the limits are, would be helpful for general quantitative work in the P&C industry.
Another area is to devise and test the effectiveness of ways to counter known cognitive heuristics and biases. For example, we have suggested two potential ways to counter the availability heuristic: to ask for a second opinion from an overseas colleague or one with a substantially different experience history and to imagine a totally different environment in one’s own mind. Empirical testing could be done to evaluate the merits of the two methods.
Acknowledgments
The authors thank Mr. Peter Mills for his help in the design and organization of the survey. The research was performed under the Acorn framework, an actuarial research network internal to the authors’ organization. They, therefore, also express their gratitude for the support their organization has given through this network over the course of the study. The paper also incorporates helpful comments from our reviewers.