
1. Introduction and motivation
A non-life insurance company needs to hold sufficient reserves on its balance sheet in order to meet the future claims payment cashflow. Therefore, given the available information about the past claims payment cash flow and the claims settlement process as well as external knowledge from experts and prior information (e.g., premium, number of contracts, data from similar run-off portfolios, market statistics), the prediction of the outstanding loss liabilities and the quantification of the uncertainties in these predictions is a major task in actuarial practice and science. It is the basis for proving solvency on the one hand and it allows for reliable premium calculations on the other hand (see, e.g., CAS (Casualty Actuarial Society) 2001 and Teugels and Sundt 2004).
In this paper we consider the claims reserving problem in a multivariate context. That is, we consider a portfolio consisting of several correlated run-off portfolios (e.g., subportfolios of certain lines of business) and we apply the multivariate generalization of the well-known credibility model proposed by Bühlmann and Straub (1970) for predicting outstanding loss liabilities. This simultaneous study of several individual run-off triangles is motivated by several important facts (cf. Merz and Wüthrich 2008b).
Since in actuarial practice the conditional mean square error of prediction (MSEP) is the most popular risk measure to quantify the uncertainties in claims reserves, we provide an estimator of the conditional MSEP. Such studies of uncertainties for correlated run-off portfolios are especially crucial in the development of new solvency guidelines for the quantification of risk profiles for different insurance companies. However, they do not provide a complete picture of the uncertainty associated with the predictor of the claims reserves for the total portfolio. This can only be provided by the whole predictive distribution of the claims reserves calculated under very restrictive model assumptions or by applying numerical algorithms such as bootstrapping methods and Markov chain Monte Carlo (MCMC) methods (cf. England and Verrall 2007 and Wüthrich and Merz 2008). However, in practical applications and solvency considerations, estimates for second moments such as the conditional MSEP and its components conditional process variance/estimation error are often sufficient, since in most cases one fits an analytic overall distribution using these first two moments by the method of moments. Moreover, analytic solutions are important because they allow for explicit interpretations in terms of the parameters involved and enable sensitivity analysis with respect to parameter changes.
1.1. Claims reserving methods and credibility theory in a multivariate context
The calculation of the conditional MSEP for the predictor of the ultimate claim for a whole portfolio of several correlated run-off portfolios is more sophisticated than for only one run-off portfolio. Holmberg (1994) was probably the first one to investigate the problem of dependence between run-off portfolios of different lines of business. Later Halliwell (1999) and Quarg and Mack (2004) proposed the first bivariate models which express the dependence between the paid and incurred losses of a single run-off portfolio. Braun (2004) and Merz and Wüthrich (2008a, 2008b) generalized the well-known univariate chain-ladder model of Mack (1993) to the bivariate and the general multivariate case, respectively, by incorporating correlations between different run-off portfolios. They derived an estimate of the conditional MSEP for the predictor of the ultimate claim of the total portfolio. Merz and Wüthrich (2009a) study a special case of the multivariate additive loss reserving model proposed by Hess, Schmidt, and Zocher (2006) and derive an estimate for the conditional MSEP. Moreover, Dahms (2012) presented a general class of models that contains most models mentioned above.
In the present paper we give a credibility approach to the claims reserving problem in a multivariate context. Univariate and multivariate credibility methods are widely used in insurance pricing, but for claims reserving they are less used (though they are also useful in this context). In the claims reserving context univariate credibility methods can, e.g., be found in Benktander (1976), De Vylder (1982), Neuhaus (1992), Mack (2000), Witting (1987), and Gisler and Wüthrich (2008). More recently, Dahms and Happ (forthcoming) presented in a credibility framework a very general class of (multivariate) claims reserving methods, which contains most of the methods mentioned above as special cases. In the present paper we choose a multivariate claims reserving method different from Dahms and Happ (forthcoming) and apply the multivariate generalization of the credibility model of Bühlmann and Straub (1970) to the (multivariate) claims reserving problem.
1.2. Claims development triangle and notation
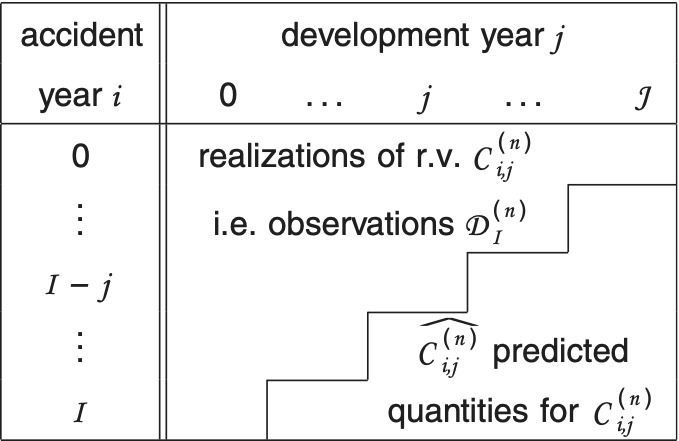
Throughout this paper all random variables are square integrable random variables defined on a common probability space (Ω, ℱ, P). We consider the situation where we have N ≥ 1 portfolios. The associated losses of each portfolio are represented by run-off triangles (claim development triangles). We assume for the reason of simplicity that all run-off triangles are of the same size (the whole theory presented in this paper can be easily generalized to different sizes but the notation then becomes more complicated) and we denote by I (J) the last accident (development) year. The claims development data have the structure shown in Figure 1. Thereby we denote by the incremental claim payments for accident year and development year of run-off portfolio
The cumulative claims payments of triangle n for accident year i up to development year j are denoted by
C(n)i,j=j∑k=0X(n)i,k.
For simplicity, we always assume that I = J, i.e., we deal with development triangles (for I ≥ J we have development trapezoids), but all results also hold true under slight modifications for the case I ≥ J.
Usually, at time I we have the sets of observations (σ-algebras)
D(n)I=σ(C(n)i,j;i+j≤I)⊆F
for all run-off portfolios n ∈ {1, . . . , N}. The total of observation over all run-off portfolios is then given by
DNI=σ(N⋃n=1D(n)I).
For the following derivations it is convenient to write the data of the N run-off portfolios in vector form. Thus we define the N-dimensional random vectors
Xi,j=(X(1)i,j,…,X(N)i,j)′
and
Ci,j=(C(1)i,j,…,C(N)i,j)′
of incremental and cumulative claims payments, respectively. The vector of outstanding claims payments for accident year i ∈ {1, . . . , I} is defined by
Ri=(R(1)i,…,R(N)i)′=Ci,J−Ci,−Ii=J∑j=I−i+1Xi,j.
Furthermore, we define the N-dimensional column vector consisting of ones by 1 = (1, . . . , 1)′ ∈ ℝN and the N × N-dimensional identity matrix by I.
2. Multivariate Bühlmann-Straub credibility model
Bayesian methods are often an appropriate tool to combine data with expert opinion, or, in other words, to combine internal data (observations) with external given prior information. However, in most Bayesian models the derivation of the posterior distribution is infeasible and numerical methods such as MCMC or numerical integration have to be applied. Analytical posterior distributions can only be calculated under very restrictive (distributional) model assumptions, for example, if one restricts to distributions from the exponential dispersion family with associated conjugated prior (cf. Bühlmann and Gisler 2005). For an example of this strategy applied in claims reserving we refer to Hashorva, Merz, and Wüthrich (2013). However, in many models it is impossible to express the Bayesian predictor in an analytical closed form. In this case the best we can do is to restrict the class of possible predictors to the class of so-called credibility predictors, which are affine-linear functions of the observations with minimum MSEP; see (2.7). These predictors have the big advantage that prior knowledge and data can be combined for the prediction and that they can be calculated under less restrictive model assumptions than Bayesian predictors. For a detailed introduction and more details on credibility predictors, see Bühlmann and Gisler (2005).
Applied to our multivariate claims reserving problem, this means that we are interested in the predictor of the ultimate claim for accident year which is the best affine-linear function of the components of the observations at time with respect to the MSEP. We study this problem in the framework of the multivariate BühlmannStraub model (cf. Bühlmann and Gisler 2005). In order to formulate the model assumptions of the multivariate Bühlmann-Straub model, we introduce latent random variables which describe the risk characteristics of the different accident years Moreover, we assume that there are (known) volume measures and (unknown) incremental loss development patterns (cash flow patterns) for the development triangles such that
E[X(n)i,j]=γ(n)jμ(n)i
for all i = 0, . . . , I. This leads to the normalized incremental claims payments given by
Y(n)i,j=X(n)i,(γ(n)jμ(n)i
for all and To shorten notation we define the cumulative loss development patterns by
β(n)0=γ(n)0>0 and β(n)j−β(n)j−1=γ(n)j>0 for j=1,…,J.
In vector form we have for i = 0, . . . , I and j = 0, . . . , J:
γγj=(γ(1)j,…,γ(N)j)′ββj=(ββ(1)j,…,ββ(N)j)′μμi=(μ(1)i,…,μ(N)i)′Yi,j=(Y(1)i,j,…,Y(N)i,j)′.
In the following we denote by
D(a)=(a10⋱0aN) and D(a)b=(ab10⋱0abN)
the N × N-diagonal matrices of the N-dimensional vectors a = (a1, . . . , aN)′ ∈ ℝN and (ab1, . . . , aNb)′ ∈ ℝN for an admissible exponent b ∈ ℝ, respectively. Then we have for the normalized incremental claims
Yi,j=D(wi,j)−1Xi,j,
where with for all and
Having this notation the multivariate Bühlmann-Straub model is then given by:
Model Assumptions 2.1 (Multivariate Bühlmann-Straub model)
- Conditionally, given the normalized incremental claims are independent with
E[Yi,j∣Θi]=μμ(Θi)
Var(Yi,j∣Θi)=D(wi,j,ξ,δ)−1/2⋅Σ(Θi)⋅D(wi,j,ξ,δ)−1/2=(σ21(Θi)w(1)i,j,ξ,δ0⋯00⋱⋮⋮⋱00⋯0σ2N(Θi)w(N)i,j,ξ,δ)
where with and The matrix is the -diagonal matrix of
- The pairs for are independent and the latent variables are identically distributed.
Remarks
-
From (2.4) it follows that the normalized incremental claim payments of accident year are higher or lower than the normalized incremental claim payments of another accident year This means there are accident years which are systematically better or worse than other ones.
-
We assume that the prior volumes are known and that the incremental loss development pattern is unknown.
-
The weights ξ ∈ [0, 2] and δ > 0 reflect the relation of the (conditional) expected value Equation 2.4 and its variance Equation 2.5. For a discussion and a motivation of choices ξ = 0 and ξ = 1 we refer to Mack (2002). Although the cases ξ = 0 and ξ = 1 can be clearly interpreted, we allow for ξ ∈ [0, 2]. In Section 4 we show how appropriate choices for ξ and δ can be derived.
-
The parameter Θi tells us whether we have a good or a bad accident year i. For a more detailed explanation in the framework of tariffication and pricing we refer to Bühlmann and Gisler (2005).
-
It is straightforward to show that in the case of one-dimensional observations (i.e., N = 1), the assumptions of the (classical) one-dimensional Bühlmann-Straub model are satisfied.
-
For the normalized incremental claims and the cumulative claims we obtain
E[Yi,j]=E[μμ(Θi)]=1
and, respectively,
E[Ci,j∣Θi]=D(ββj)D(μμi)μμ(Θi)E[Ci,j]=D(ββj)μμi
for all i = 0, . . . , I and j = 0, . . . , J. Moreover, we obtain for the claims reserves
E[Ri∣Θi]=(D(ββJ)−D(ββI−i))D(μμi)μμ(Θi)E[Ri]=(D(ββJ)−D(ββI−i))μμi
for all i = 1, . . . , I.
In the following we define the MSEP of an N-dimensional predictor for an N-dimensional random variable X = (X1, . . . , XN)′ by
msepx(ˆX)=N∑n=1E[(ˆXn−Xn)2].
In the multidimensional credibility theory one looks now for a predictor of that minimizes the MSEP (2.7) among all -dimensional predictors whose components are affine-linear in the components of the N -dimensional observations with That is, one has to solve the optimization problem
^μμ(Θi)=argminˆx∈(D′0,1))msepμ(θi)(ˆX),
where
L(DNI,1)={ˆX;^Xk=a+∑Ii=0∑I−ij=0∑Nn=1a(n)i,jX(n)i,j with a,a(n)i,j∈R}.
We define the structural parameter matrices
S=E[∑(Θi)]T=Var(μμ(Θi))
and obtain:
Theorem 2.2 (Bühlmann-Straub predictor)
Under Model Assumptions 2.1 the optimal affine-linear predictor of µ(Θi) is given by
^μμ(Θi)cred =AiKi+(I−Ai)1
for 1 ≤ i ≤ I, where
Ki=(∑I−ij=0γ(1)−1jβ(1)I−i,jμ(1)iX(1)i,j,…,∑I−ij=0γ(N)ξ−1jβ(N)I−i,jμ(N)iX(N)i,j)′Ai=T(T+D(ββI−i,j)−1/2D(μμi)−δ/2SD(μμi)−δ/2D(ββI−i,ξ)−1/2)−1ββ(n)I−i,5=∑L−ij=0γ(n)5jββI−iξ=(ββ(1)I−iξ,…,ββ(N)I−i,ξ)′
Proof: The normalized incremental claim payments fulfill the model assumptions of the multidimensional Bühlmann-Straub model. Hence, Theorem 2.2 is a direct consequence of Theorem 7.8 in Bühlmann and Gisler (2005).
Remarks
- It is usual to compress the data in an appropriate manner so that we have a single observation vector which has the same dimension as :
Ki=(∑I−ij=0w(1)i,j,ξ,δ∑I−ij=0w(1)i,j,ξ,δY(1)i,j,…,∑I−ij=0w(N)i,j,δ,δ∑I−ij=0w(N)i,j,ξ,δY(N)i,j)′=(∑I−ij=0γγ(1)jββ(1)I−i,ξμμ(1)i(1)X(1)i,j,…,∑I−ij=0γγ(N)ξ−1jββ(N)I−i,jμμ(N)iX(N)i,j)′.
Observe that the compressed vector only depends on the observations of accident year i. This is a consequence of the independence assumption between different accident years. Vector contains all information which is relevant for accident year i, and its n-th component is defined as the weighted average of the normalized incremental claims over all observed development years
- Note that
D(ββI−i,ξ)−1/2D(μμi)−δ/2SD(μμi)−8/2D(ββI−iξ)−1/2
where for
-
Credibility predictor (2.9) is unbiased for the prior mean
-
In the case of one-dimensional observations and ξ = 1 predictor (2.9) reduces to the one-dimensional credibility predictor applied to the claims reserving problem (cf. Wüthrich and Merz 2008).
To obtain a predictor for the outstanding claim payments we have to determine an estimator for the parameter and respectively. An unbiased estimator for is given by
^γγj=D(I−j∑i=0μμi)−1I−j∑i=0Xi,j
for all j = 0, . . . , J. Thus the estimator
^ββj=i∑k=0^γγk
is an unbiased estimator for for all This leads to the following predictor:
Predictor 2.3 Under Model Assumptions 2.1 we have the following predictors for the ultimate claims
^Ci,Jcred =Ci,−i−i+D(^ββJ−^ββI−i)D(μμi)^μμ(ΘΘi)(cred
for 1 ≤ i ≤ I.
For the numerical calculation of the predictor (2.12) we have to estimate the structure parameter matrices S and T. This will be done in Section 4.
Under Model Assumptions 2.1 the predicted outstanding claim payments are given by
ˆRcred i=(^R(1)i(red ,…,^RR(N)icred )′=D(^ββj−^ββI−i)D(μμi)^μμ(Θi)cred
for 1 ≤ i ≤ I.
For the derivation of the (conditional) MSEP in the next section the following lemma on the quadratic loss matrices of the multidimensional credibility predictors will be used:
Lemma 2.4 In the multidimensional Bühlmann-Straub Model (2.1), the quadratic loss matrices for the credibility predictors are given by
E[(^μ(Θμ(ΘˆΘi)cred −μμ(Θi))⋅(^μμ(Θi)cred −μμ(Θi))′]=(I−Ai)T
for 1 ≤ i ≤ I.
Proof: The stated quadratic loss of the credibility predictor in Lemma 2.4 is a direct consequence of Theorem 7.5 in Bühlmann and Gisler (2005).
3. Conditional mean square error of prediction
In the last section we have provided predictors for the ultimate claims and the outstanding claim payments. In this section we quantify the prediction uncertainty of these predictions for single and aggregated accident years in terms of second moments. More precisely, our goal is to derive an estimate for the conditional MSEP of the predicted outstanding claim payments for single as well as aggregated accident years
N∑n=1^R(n)di=1′ˆRcred iI∑i=1N∑n=1^R(n)ed i=I∑i=11′ˆRcred i.
We derive these estimators under the assumption that all parameters in the Bühlmann-Straub credibility predictor in are known. Afterwards, all parameters are replaced by their estimates. This approach is generally applied for such kind of questions and is known as “empirical credibility approach.”
3.1. Single accident years
The conditional MSEP for a single year given is defined by
msep∑R(n)iDNin(∑Nn=1^R(n)icred )=E[(∑Nn=1^R(n)icred −∑Nn=1R(n)i)2∣DNI]=1′E[(ˆRcred i−Ri)(ˆRcred i−Ri)′∣DNI]1.
It can be decomposed into conditional process variance and conditional estimation error:
msep∑R(n)i∣DNin(∑Nn=1^R(n)icred )=1′Var(Ri∣DNI)1⏟conditional process variance +1′(ˆRcred i−E[Ri∣DNI])(ˆRcred i−E[Ri∣DNI]))′⏟condional estimaion error .
Note that for this decoupling we use the fact that is known/observable at time (i.e., is -measurable). For the conditional process variance we obtain the following result:
Lemma 3.1 Under Model Assumptions 2.1 the conditional process variance for a single accident year i ∈ {1, . . . , I} is given by
1′Var(Ri∣DNI)1=1′D(μμi)2−8E[Σ(Θi)∣DNI]∑Jj=I−i+1D(γγj)2−ξ1+1′D(ββJ−ββI−i)D(μμi)Var(μμ(Θi)∣DNI)D(ββJ−ββI−i)D(μμi)1
Proof. See Appendix.
The conditional process variance originates from stochastic movements of If we approximate and by and respectively, and if we replace the development pattern as well as the structure parameters and by their corresponding estimators (see Section 4) we obtain the following estimator of the conditional process variance for a single accident year:
Estimator 3.2 (Conditional process variance for single accident years)
Under Model Assumptions 2.1 we have the following estimator for the conditional process variance of a single accident year i ∈ {1, . . . , I}:
1′^Var(Ri∣DNI)1=1′D(μμi)2−8ˆSJ∑j=I−i+1D(^γγj)2−ξ1+1′D(^ββJ−^ββI−i)D(μμi)׈TD(^ββJ−^ββI−i)D(μμi)1
(see Section 4 for estimates of the structure parameter matrices S and T.)
The conditional estimation error in (3.2) reflects the uncertainty in the prediction of the conditional expectation (mean value) by After some calculations (see Appendix) and replacing the unknown parameters by their estimates (see Section 4) we obtain the following result:
Estimator 3.3 (Conditional estimation error for single accident years)
Under Model Assumptions 2.1 we have the following estimator for the conditional estimation error of a single accident year i ∈ {1, . . . , I}:
1′^Var(ˆRcred i∣DNI)1=−1D(μμi)D(^ββJ−^ββI−i)ˆAiˆTD(^ββJ−^ββI−i)D(μμi)1+1′D(μμi)D(^μμ(Θi)cred )^Var(^ββJ−^ββI−i)×D(^¯μμ(Θi)cred )D(μμi)1,
where
^Var(^ββJ−^ββI−i)=∑j,l>I−iD(∑I−jm=0μμm)−1[δjlD(^γγj)2−ξ⋅∑I−jk=0D(μμk)2−8ˆS+D(^γγj)∑k=0I−max
{\widehat{\widehat{\pmb{\mu}\left(\Theta_{i}\right)}}}^{\text {cred }}=\widehat{A}_{i} \widehat{\mathbf{K}}_{i}+\left(I-\widehat{A}_{i}\right) \mathbf{1} \tag{3.7}
\widehat{\mathbf{K}}_i=\left(\sum_{j=0}^{l-1} \frac{\left(\hat{\gamma}_j^{(1)}\right)^{\xi-1}}{\hat{\beta}_{l-i j}^{(1)} \pmb{\mu}_i^{(1)}} X_{i j}^{(1)}, \ldots, \sum_{j=0}^{t-i} \frac{\left(\hat{\gamma}_j^{(N)}\right)^{\xi-1}}{\hat{\pmb{\beta}}_{l-i<k}^{(N)} \mu_i^{(N)}} X_{i j j}^{(N)}\right)^{\prime}\tag{3.8}
\widehat{A}_{i}=\widehat{T}\left(\widehat{T}+\mathbf{D}\left(\hat{\pmb{\beta}}_{I-i, \xi}\right)^{-1 / 2} \mathbf{D}\left(\pmb{\mu}_{i}\right)^{-\delta / 2} \hat{S} \mathbf{D}\left(\pmb{\mu}_{i}\right)^{-\delta / 2} \mathbf{D}\left(\widehat{\pmb{\beta}}_{I-i, \xi}\right)^{-1 / 2}\right)^{-1} \tag{3.9}
and if and else (see Section 4 for estimates of the structure parameter matrices and
Combining Estimators 3.2 and 3.3 leads to the following estimator for the conditional MSEP of the predicted outstanding claim payments for a single accident year:
Estimator 3.4 (Conditional MSEP for single accident years)
Under Model Assumptions 2.1 we have the following estimator for the conditional MSEP of a single accident year i ∈ {1, . . . , I}:
\begin{array}{l} =\mathbf{1}^{\prime} \widehat{\operatorname{Var}}\left(\mathbf{R}_{i} \mid \mathcal{D}_{I}^{N}\right) \mathbf{1}+\mathbf{1}^{\prime} \widehat{\operatorname{Var}}\left(\widehat{\mathbf{R}}_{i}^{\text {cred }} \mid \mathcal{D}_{I}^{N}\right) \mathbf{1}, \end{array} \tag{3.10}
where the two terms on the right-hand side of (3.10) are given by (3.4) and (3.5), respectively.
Remarks
-
Predictor (3.7) is the so-called empirical credibility predictor, which results from the credibility predictor (2.9) by replacing the structural parameters by their estimates.
-
For N = 1 (i.e., only one run-off portfolio) estimator (3.10) leads to the following estimator
\begin{array}{l} \widehat{\operatorname{msep}}_{R_{i, 1} \mathcal{D}_{l}}\left(\widehat{R}_{i}^{\text {cred }}\right)=\underbrace{\mu_{i}^{2-\delta} \hat{S} \sum_{j=I-l+1}^{J} \hat{\gamma}_{j}^{2-\xi}+\mu_{i}^{2}\left(\sum_{j=l i+1}^{J} \hat{\gamma}_{j}\right)^{2} \hat{T}}_{\text {conditional l process variance }} \\ \underbrace{\left.-\mu_{i}^{2}\left(\sum_{j=I-i+1}^{J} \hat{\gamma}_{j}\right)^{2} \widehat{A}_{i} \widehat{T}+\mu_{i}^{2}\left(\widehat{\widehat{\mu\left(\Theta_{i}\right.}}\right)^{\text {cred }}\right)^{2} \widehat{\operatorname{Var}}\left(\sum_{j=I-i+1}^{J} \hat{\gamma}_{j}\right)}_{\text {conditional etimation error }}, \end{array} \tag{3.11}
where
\begin{array}{l} \widehat{\operatorname{Var}}\left(\sum_{j=I-i+1}^{J} \hat{\gamma}_{j}\right)=\sum_{j, l l \mid-i}\left(\sum_{m=0}^{I-j} \mu_{m}\right)^{-1}\left(\sum_{m=0}^{I-l} \mu_{m}\right)^{-1} \\ {\left[\delta_{j i} \hat{\gamma}_{j}^{2-\xi} \sum_{k=0}^{I-j} \mu_{k}^{2-\xi} \hat{S}+\hat{\gamma}_{j} \hat{\gamma}_{l} \hat{T}^{I-\max (i, i)} \sum_{k=0}^{2} \mu_{k}^{2}\right]} \end{array} \tag{3.12}
and
{\widehat{\overline{\mu\left(G\left(\Theta_{i}\right)\right.}}}^{\text {red }}=\widehat{A}_{i} \widehat{K}_{i}+\left(1-\widehat{A}_{i}\right) 1
with
\widehat{K}_{i}=\frac{\sum_{j=0}^{I-i} \hat{\gamma}_{j}^{\xi-1}}{\hat{\beta}_{I-i, \xi} \mu_{i}} X_{i, j} \quad \text { and } \quad \hat{A}_{i}=\frac{\hat{\beta}_{I-i, \xi}}{\hat{\beta}_{I-i, \xi}+\frac{\hat{S}}{\mu_{i}^{\delta} \hat{T}}} .
3.2. Aggregated accident years
At first we consider the case of two different accident years We have to be careful if we aggregate the estimators and because they use the same observations for estimating the parameters and respectively. Therefore, they are not independent. We define the conditional MSEP of two aggregated accident years and by
\begin{array}{l} \operatorname{msep}_{\sum_{n}^{\left.R_{i}^{(n)}\right)}} \sum_{n_{k}^{R_{k}^{(n)} \mid D_{l}^{N}}}\left(\sum_{n=1}^{N}{\widehat{R_{i}^{(n)}}}^{\text {cred }}+\sum_{n=1}^{N}{\widehat{R_{k}^{(n)}}}^{c \text { cred }}\right) \\ \quad=E\left[\left(\sum_{n=1}^{N}\left({\widehat{R_{i}^{(n)}}}^{\text {cred }}+{\widehat{R_{k}^{(n)}}}^{\text {cred }}\right)-\sum_{n=1}^{N}\left(R_{i}^{(n)}+R_{k}^{(n)}\right)\right)^{2} \mid \mathcal{D}_{I}^{N}\right] \end{array}
As for a single accident year we have the decomposition
\begin{array}{l} \operatorname{msep}_{\sum_{n}^{R_{i}^{(n)}}+\sum_{n}^{R_{k}^{(n)} \mid \mathcal{D}_{I}^{N}}}\left(\sum_{n=1}^{N}{\widehat{R_{i}^{(n)}}}^{\text {cred }}+\sum_{n=1}^{N}{\widehat{R_{k}^{(n)}}}^{\text {cred }}\right) \\ =\mathbf{1}^{\prime} \operatorname{Var}\left(\mathbf{R}_{i}+\mathbf{R}_{k} \mid \mathcal{D}_{I}^{N}\right) \mathbf{1} \\ \quad+\mathbf{1}^{\prime}\left(\widehat{\mathbf{R}}_{i}^{\text {cred }}+\widehat{\mathbf{R}}_{k}^{\text {cred }}-E\left[\mathbf{R}_{i}+\mathbf{R}_{k} \mid \mathcal{D}_{I}^{N}\right]\right) \times \\ \quad\left(\widehat{\mathbf{R}}_{i}^{\text {cred }}+\widehat{\mathbf{R}}_{k}^{\text {cred }}-E\left[\mathbf{R}_{i}+\mathbf{R}_{k} \mid \mathcal{D}_{I}^{N}\right]\right)^{\prime} \mathbf{1} \end{array}
Using the independence of different accident years, the conditional MSEP of two aggregated accident years can be represented as follows:
\begin{array}{l} \operatorname{msep}_{\sum_{n}^{R_{i}^{(n)}}+\sum_{n} R_{k}^{(n)} \mathcal{D}_{i}^{N}}\left(\sum_{n=1}^{N}{\widehat{R_{i}^{(n)}}}^{\text {cred }}+\sum_{n=1}^{N}{\widehat{R_{k}^{(n)}}}^{\text {cred }}\right) \\ =\operatorname{msep}_{\sum_{n} R_{i}^{(n)} \mid D_{i}^{N}}\left(\sum_{n=1}^{N}{\widehat{R_{i}^{(n)}}}^{c \text { cred }}\right)+\operatorname{msep}_{\sum_{n}^{R_{k}^{(n)} \mid D_{i}^{N}}}\left(\sum_{n=1}^{N}{\widehat{R_{k}^{(n)}}}^{(r e r d}\right) \\ +2 \cdot \mathbf{1}^{\prime}\left(\widehat{\mathbf{R}}_{i}^{\text {cred }}-E\left[\mathbf{R}_{i} \mid \mathcal{D}_{I}^{N}\right]\right)\left(\widehat{\mathbf{R}}_{k}^{\text {cred }}-E\left[\mathbf{R}_{k} \mid \mathcal{D}_{I}^{N}\right]\right)^{\prime} \mathbf{1} . \end{array} \tag{3.13}
Since we have already derived an estimator for the first and second term on the right-hand side of (3.13) (cf. Estimator 3.4) we only have to derive an estimator for the third term to obtain an estimator for the MSEP (3.13). After some calculations (see Appendix) and replacing the parameters by their estimates (see Section 4) we obtain for the third term the following estimator:
\begin{array}{l} 2 \cdot \mathbf{1}^{\prime} \mathbf{D}\left(\pmb{\mu}_{i}\right) \mathbf{D}\left({\widehat{\overline{\pmb{\mu}\left(\Theta_{i}\right.}}}^{\text {cred }}\right) \widehat{\operatorname{Cov}}\left(\hat{\pmb{\beta}}_{J}-\hat{\pmb{\beta}}_{I-i}, \hat{\pmb{\beta}}_{J}-\hat{\pmb{\beta}}_{I-k}\right) \times \\ \mathbf{D}\left({\widehat{\overline{\pmb{\mu}\left(\pmb{\Theta}_{k}\right.}}}^{\text {cred }}\right) \mathbf{D}\left(\pmb{\mu}_{k}\right) 1, \end{array} \tag{3.14}
where
\begin{array}{l} \widehat{\operatorname{Cov}}\left(\hat{\pmb{\beta}}_{J}-\hat{\pmb{\beta}}_{I-i}, \hat{\pmb{\beta}}_{I}-\hat{\pmb{\beta}}_{I-k}\right) \\ =\widehat{\operatorname{Var}}\left(\hat{\pmb{\beta}}_{J}-\hat{\pmb{\beta}}_{I-i}\right)+\sum_{\substack{-i<i j \\ I-k<l-i}} \mathbf{D}\left(\sum_{m=0}^{I-j} \pmb{\mu}_{m}\right)^{-1} \mathbf{D}\left(\hat{\gamma}_{J}\right) \times \\ \sum_{s=0}^{I-\max \{j i l\}} \mathbf{D}\left(\pmb{\mu}_{s}\right) \hat{T} \mathbf{D}\left(\pmb{\mu}_{s}\right) \mathbf{D}\left(\hat{\gamma}_{l}\right) \mathbf{D}\left(\sum_{m=0}^{I-l} \pmb{\mu}_{m}\right)^{-1} \end{array} \tag{3.15}
and is given by (3.6). For more details on the derivation, see the Appendix.
For the generalization on more than two accident years we use the decomposition
\begin{array}{l} +2 \sum_{1 s i<k s I} \cdot 1^{\prime}\left(\widehat{\mathbf{R}}_{i}^{c r e d}-E\left[\mathbf{R}_{i} \mid \mathcal{D}_{I}^{N}\right]\right)\left(\widehat{\mathbf{R}}_{k}^{c r e d}-E\left[\mathbf{R}_{k} \mid \mathcal{D}_{I}^{N}\right]\right)^{\prime} 1 . \end{array}
This leads to the following estimator for the conditional MSEP of aggregated years:
Estimator 3.5 (Conditional MSEP for aggregated accident years)
Under Model Assumptions 2.1 we have the following estimator for the conditional MSEP for aggregated accident years:
\begin{array}{l} \widehat{\mathrm{msep}} \sum_{i} \sum_{n}^{\left.R_{i}^{(n)}\right)_{l}^{N}}\left(\sum_{i=1}^{L} \sum_{n=1}^{N} \widehat{R_{i}^{(n)}}{\mathstrut}^{\text {cred }}\right) \\ =\sum_{i=1}^{I} \widehat{\operatorname{msep}} \sum_{n_{i}^{(n)} \mid D_{i}^{N}}\left(\sum_{n=1}^{N}{\widehat{R_{i}^{(n)}}}^{\text {cred }}\right) \\ +2 \sum_{1 \leq i<k s} \mathbf{1}^{\prime} \mathbf{D}\left(\mu_{i}\right) \mathbf{D}\left({\hat{{\pmb{\mu}\left(\Theta_{i}\right)}^{c}}}^{\text {cred }}\right) \\ \widehat{\operatorname{Cov}}\left(\hat{\pmb{\beta}}_{s}-\hat{\pmb{\beta}}_{I-i}, \hat{\pmb{\beta}}_{s}-\hat{\pmb{\beta}}_{I-k}\right) \mathbf{D}\left({\widehat{\pmb{\mu}\left(\pmb{\Theta}_{k}\right)}}^{\text {cred }}\right) \mathbf{D}\left(\pmb{\mu}_{k}\right) \mathbf{1}, \end{array} \tag{3.16}
with given by (3.15).
Remark
For N = 1 (i.e., only one run-off portfolio) Estimator 3.5 leads to the estimator
\begin{array}{l} \widehat{\operatorname{msep}} \sum_{i_{i}^{R_{i} \mid D_{i}^{N}}}\left(\sum_{i=1}^{I} \widehat{R}_{i}^{\text {cred }}\right)=\sum_{i=1}^{I} \widehat{\operatorname{msep}}_{R_{i} \mid D_{l}^{N}}\left(\widehat{R}_{i}^{\text {cred }}\right) \\ +2 \sum_{1 s i<k I} \mu_{i} \mu_{k}{\widehat{\widehat{\mu\left(\Theta_{i}\right)}}}^{\text {cred }}{\widehat{\mu\left(\Theta_{k}\right)}}^{\text {cred }} \widehat{\operatorname{Cov}}\left(\sum_{j=I-i+1}^{J} \hat{\gamma}_{j}, \sum_{j=I-k+1}^{J} \hat{\gamma}_{j}\right), \end{array}
where is given in (3.11) and
\begin{array}{l} \widehat{\operatorname{Cov}}\left(\sum_{j=I-i+1}^{J} \hat{\gamma}_{j}, \sum_{j=I-k+1}^{J} \hat{\gamma}_{j}\right)=\widehat{\operatorname{Var}}\left(\sum_{j=I-i+1}^{J} \hat{\gamma}_{j}\right) \\ \quad+\sum_{\substack{I-i<j \\ I-k<\leq I-i}}\left(\sum_{m=0}^{I-j} \mu_{m}\right)^{-1}\left(\sum_{m=0}^{I-l} \mu_{m}\right)^{-1} \hat{\gamma}_{j} \hat{\gamma}_{l} \widehat{T}^{I-\max \{j, l]} \sum_{s=0}^{2}, \end{array}
with given in (26).
4. Parameter estimation
The estimators of the development pattern and are given in (2.10) and (2.11). In this section we first give estimators for the structure parameter matrices and for known and Then, we replace and by their estimators (2.10) and (2.11) in order to get the final estimators. Under Model Assumptions 2.1 is a diagonal matrix, where the diagonal elements can be estimated by (see Bühlmann and Gisler 2005):
\hat{\mathbf{\sigma}}_{n}^{2}=\frac{1}{I} \sum_{i=0}^{I-1} \frac{1}{I-i} \sum_{j=0}^{I-1} \gamma_{j}^{\xi^{(n)}} \pmb{\mu}_{i}^{\delta^{(n)}}\left(\frac{X_{i, j}^{(n)}}{\pmb{\gamma}_{j}^{(n)} \pmb{\mu}_{i}^{(n)}}-\pmb{K}_{i}^{(n)}\right)^{2} . \tag{4.1}
We replace by in (4.1) and thus the estimator of the structure parameter matrix S is given by
\hat{S}=\left(\begin{array}{cccc} \hat{\pmb{\sigma}}_{n}^{2} & 0 & \cdots & 0 \\ 0 & \ddots & & \vdots \\ \vdots & & \ddots & 0 \\ 0 & \cdots & 0 & \hat{\pmb{\sigma}}_{n}^{2} \end{array}\right) .
For the estimation of the diagonal elements of T we define
\hat{T}_{n, n}^{\circ}=c \cdot\left(\sum_{i=0}^l \frac{\beta_{\xi, l-l}^{(n)} \mu_i^{\delta^{(n)}}}{\sum_k \beta_{\xi, l-k}^{(n)} \mu_k^{(n)}} \cdot\left(K_i^{(n)}-\bar{K}^{(n)}\right)^2-\frac{I \cdot \hat{\sigma}_n^2}{\sum_k \beta_{\xi, l-k}^{(n)} \mu_k^{\delta^{(n)}}}\right)
with
c=\left(\sum_{i=0}^{I} \frac{\pmb{\beta}_{\xi, I-i}^{(n)} \pmb{\mu}_{i}^{\delta^{(n)}}}{\sum_{k} \pmb{\beta}_{\xi, I-k}^{(n)} \pmb{\mu}_{k}^{\delta^{(n)}}} \cdot\left(1-\frac{\pmb{\beta}_{\xi, I-i}^{(n)} \pmb{\mu}_{i}^{\delta^{(n)}}}{\sum_{k} \pmb{\beta}_{\xi, I-k}^{(n)} \pmb{\mu}_{k}^{(n)}}\right)\right)^{-1}
and
\bar{K}^{(n)}=\sum_{i=0}^I \frac{\pmb{\beta}_{\xi, l-l}^{(n)} \pmb{\mu}_i^{\delta^{(n)}}}{\sum_k \pmb{\beta}_{\xi, l-k}^{(n)} \pmb{\mu}_k^{\delta^{(n)}}}\cdot K_i^{(n)}=\sum_{i=0}^I \frac{\mu_i^{\delta-1} \frac{\sum_{j \leq 1-1}^{(n)}} \sum_j^{\delta_j^{-1}\left(1^{(n)}\right)} X_{i, l-i}^{(n)}}{\sum_k \beta_{\xi, l-l}^{(n)} \mu_k^{\delta^{(n)}}}.
Observe, that for δ = 1 we have for all n = 1, . . . , N. Since could be negative, we take
\hat{T}_{n, n}=\max \left(\hat{T}_{n, n}^{\circ}, 0\right) \tag{4.2}
as estimator for the diagonal elements of T. An estimator for the non-diagonal elements of T (i.e., Tn,m with n ≠ m) is given by (see also Bühlmann and Gisler 2005)
\begin{aligned} \hat{T}_{n, m}= & \operatorname{sgn}\left(\frac{\hat{T}_{n, m}^{a}+\hat{T}_{n, m}^{b}}{2}\right) \\ & \cdot \min \left(\frac{\left|\hat{T}_{n, m}^{a}+\hat{T}_{n, m}^{b}\right|}{2}, \sqrt{\hat{T}_{n, n} \cdot \hat{T}_{m, m}}\right), \end{aligned} \tag{4.3}
where
\hat{T}_{n, m}^a=c_a \cdot\left(\sum_{i=0}^l \frac{\beta_{\xi,I-i}^{(n)} \mu_i^{\delta^{(n)}}}{\sum_{k} \beta_{\xi, I-k}^{(n)} \mu_k^{\delta^{(n)}}} \cdot\left(K_i^{(n)}-\bar{K}^{(n)}\right) \cdot\left(K_i^{(m)}-\bar{K}^{(m)}\right)\right)
with
c_{a}=\left(\sum_{i=0}^{I} \frac{\pmb{\beta}_{\xi, I-I}^{(n)} \pmb{\mu}_{i}^{\delta^{(n)}}}{\sum_{k} \pmb{\beta}_{\xi, I-k}^{(n)} \pmb{\mu}_{k}^{\delta^{(n)}}} \cdot\left(1-\frac{\pmb{\beta}_{\xi, I-i}^{(n)} \pmb{\mu}_{i}^{\delta^{(n)}}}{\sum_{k} \pmb{\beta}_{\xi, I-k}^{(n)} \pmb{\mu}_{k}^{\delta^{(n)}}}\right)\right)^{-1}
and
\hat{T}_{n, m}^b=c_b \cdot\left(\sum_{i=0}^{I} \frac{\beta_{\xi,I-i}^{(m)} \mu_i^{\delta^{(m)}}}{\sum_k \beta_{\xi, I-k}^{(m)} \mu_k^{\delta(m)}} \cdot\left(K_i^{(n)}-\bar{K}^{(n)}\right) \cdot\left(K_i^{(m)}-\bar{K}^{(m)}\right)\right)
with
c_{b}=\left(\sum_{i=0}^{I} \frac{\beta_{\xi, I-i}^{(m)} \mu_{i}^{\delta^{(m)}}}{\sum_{k} \beta_{\xi, I-k}^{(m)} \pmb{\mu}_{k}^{\delta^{(m)}}} \cdot\left(1-\frac{\beta_{\xi, I-I}^{(m)} \pmb{\mu}_{i}^{\delta^{(m)}}}{\sum_{k} \beta_{\xi, I-k}^{(m)} \mu_{k}^{\delta^{(n)}}}\right)\right)^{-1} .
The estimator in (4.3) takes the value zero if or is zero. In this case, we have an estimator of T which is not invertible, which leads to an estimator of Ai that is also not invertible. Alternatively to (4.3) we can take as estimator for the non-diagonal elements of T
\hat{T}_{n, m}=\frac{\hat{T}_{n, m}^{a}+\hat{T}_{n, m}^{b}}{2} \tag{4.4}
By replacing with their estimators in (4.2) and (4.3) we get an estimator of which we denote by
The estimators n = 1, . . . , N are unbiased estimators for the components of S and the estimators are unbiased estimators for the components of T. However, the estimators are no longer unbiased. Apart from that, we cannot state anything about the unbiasedness of
Finally, we get an estimator of Ai by replacing all structure parameters by their estimators, that is
\begin{aligned} \hat{A}_{i}= & \hat{T}\left(\hat{T}+\mathbf{D}\left(\hat{\pmb{\beta}}_{\bar{\xi},-i}\right)^{-1 / 2} D\left(\pmb{\mu}_{i}\right)^{-\delta / 2}\right. \\ & \left.\cdot \hat{S} \cdot \mathbf{D}\left(\hat{\pmb{\beta}}_{5, l-i}\right)^{-1 / 2} D\left(\pmb{\mu}_{i}\right)^{-\delta / 2}\right)^{-1} . \end{aligned}
For the specific choice of the weights ξ ∈ [0,2] and δ > 0 we propose the method of minimum sum of squared residuals. That means we estimate ξ and δ by
(\hat{\xi}, \hat{\delta})=\underset{(\hat{\xi}, \hat{\delta})}{\operatorname{argmin}}\{S S E(\hat{\xi}, \hat{\delta})\},
with
\operatorname{SSE}(\xi, \delta)=\sum_{0 \leq i+j \leq l} \sum_{n=1}^{N}\left(X_{i, j}^{(n)}-\hat{X}_{i, j}^{(n)}\right)^{2} . \tag{4.5}
Another possible way to determine ξ by means of exploratory data analysis is given in Mack (2002).
5. Example
We consider two portfolios A and B (i.e., N = 2) from General Liability Reinsurance and Auto Liability Reinsurance containing incremental claim payments with I = 16 accident and J = 10 development years. The corresponding data sets are provided in the end of this section. In this case the last accident year is greater than the last development year, i.e., I > J. However, all results we presented except the parameter estimate (4.1) also hold for this case. The estimator (4.1) has to be adapted as follows:
\begin{aligned} \hat{\sigma}_{n}^{2}= & \frac{1}{I} \sum_{i<L-J} \frac{1}{J} \sum_{j=0}^{J} \gamma_{j}^{\varepsilon_{j}^{(n)}} \mu_{i}^{\delta^{(n)}}\left(\frac{X_{i, j}^{(n)}}{\gamma_{j}^{(n)} \mu_{i}^{(n)}}-K_{i}^{(n)}\right)^{2} \\ & +\frac{1}{I} \sum_{i=L-J}^{I-1} \frac{1}{I-i} \sum_{j=0}^{I-i} \gamma_{j}^{\left.\varepsilon_{j}^{(n)}\right)} \mu_{i}^{(n)}\left(\frac{X_{i, j}^{(n)}}{\gamma_{j}^{(n)} \mu_{i}^{(n)}}-K_{i}^{(n)}\right)^{2} . \end{aligned} \tag{5.1}
We assume different prior means for the different accident years and use the prior means given in Table 1 which result as the ultimate claim predictions of the classical CL method.
Next we calculate the estimator (2.10) for the incremental development pattern (note that this estimator is independent from the specific values of and ) which are given in Table 2. We see that about to of the expected claim payments are due in the first two development years. Moreover, holds for all development years fulfilling Model Assumptions 2.1. However, by briefly studying the incremental claims payment pattern of the two portfolios we obtain some “untypical” accident years. Unlike the other accident years, the accident years 2 and 13 show an extremely slow decline, whereas accident year 3 shows a fast decline of the incremental claim payments.
We calculate the credibility predictors (2.9) in order to determine the claims reserves (2.13) for every accident year i ∈ {0, . . . , I}. For illustrative purposes we restrict the analysis to four explicit parameter choices ξ ∈ {0, 2} and δ ∈ {0, 2}.
The credibility predictors (2.13) for these four parameter choices are given in Table 3. In a second step we choose the parameters ξ ∈ {0, 2} and δ ∈ {0, 2}, which provide the best model fit to the data.
Goodness-of-Fit
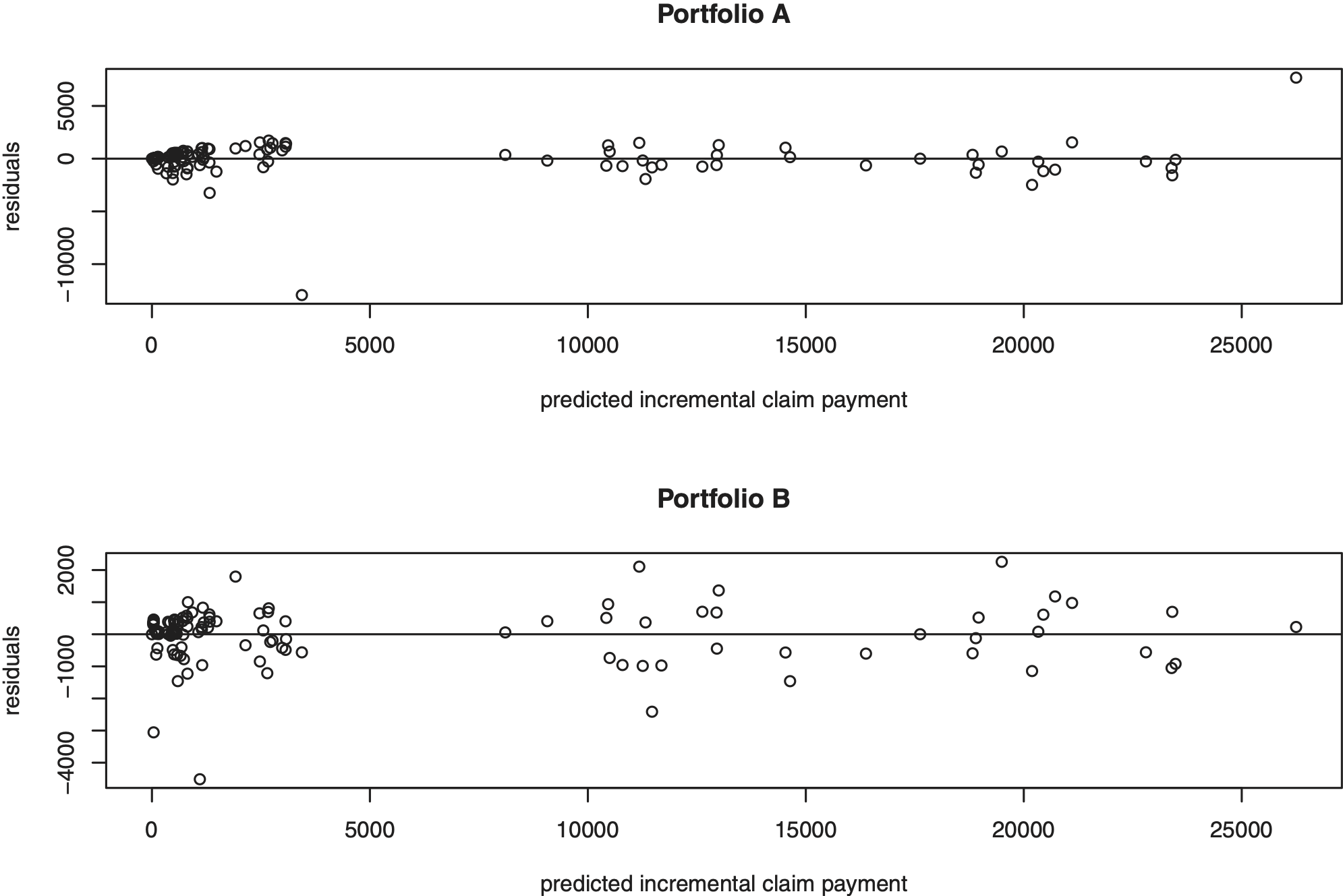
In order to choose specific and we use as a goodness-of-fit criterion the see (4.5), and take the parameter combination with minimum This method is also proposed in Chapter 11 in Wüthrich and Merz (2008) for comparing the fit to the data of different claims reserving methods. Table 4 shows that provides a much better fit than which can be explained as follows: In Model Assumptions 2.1 the incremental claim payments are of the type with and In the case of the conditional variance does not depend on development year and we assume homogeneous variances of although this assumption seems quite unrealistic. Then the weights of the standardized incremental claim payments in the compressed data vector in Theorem 2.2 also do not depend on the development year j . This leads to high credibility predictors for the untypical accident years (2 and 13) and small predictors for accident year 7 for (see Table 3 ) and consequently to a high The decreases by about if these “untypical” accident years (2, 7, and 13) are left out in the calculation of Heterogeneous variances are respected in the case leading to a much better model fit (see Table 4). Figure 2 shows the predicted claim payments versus the corresponding residuals. There is no clear trend in the plot, and the data are (approximately) centered. However, there remains the problem of untypical accident years which cannot be fitted appropriately. This problem is visualized in Figure 2, where in Portfolio A and B the highest and lowest values (outliers) result from accident years 7 and 13. The decreases by about (from 19,996 to 8,512 ) if the untypical accident years (2, 7 and 13 ) are ignored.
.png)
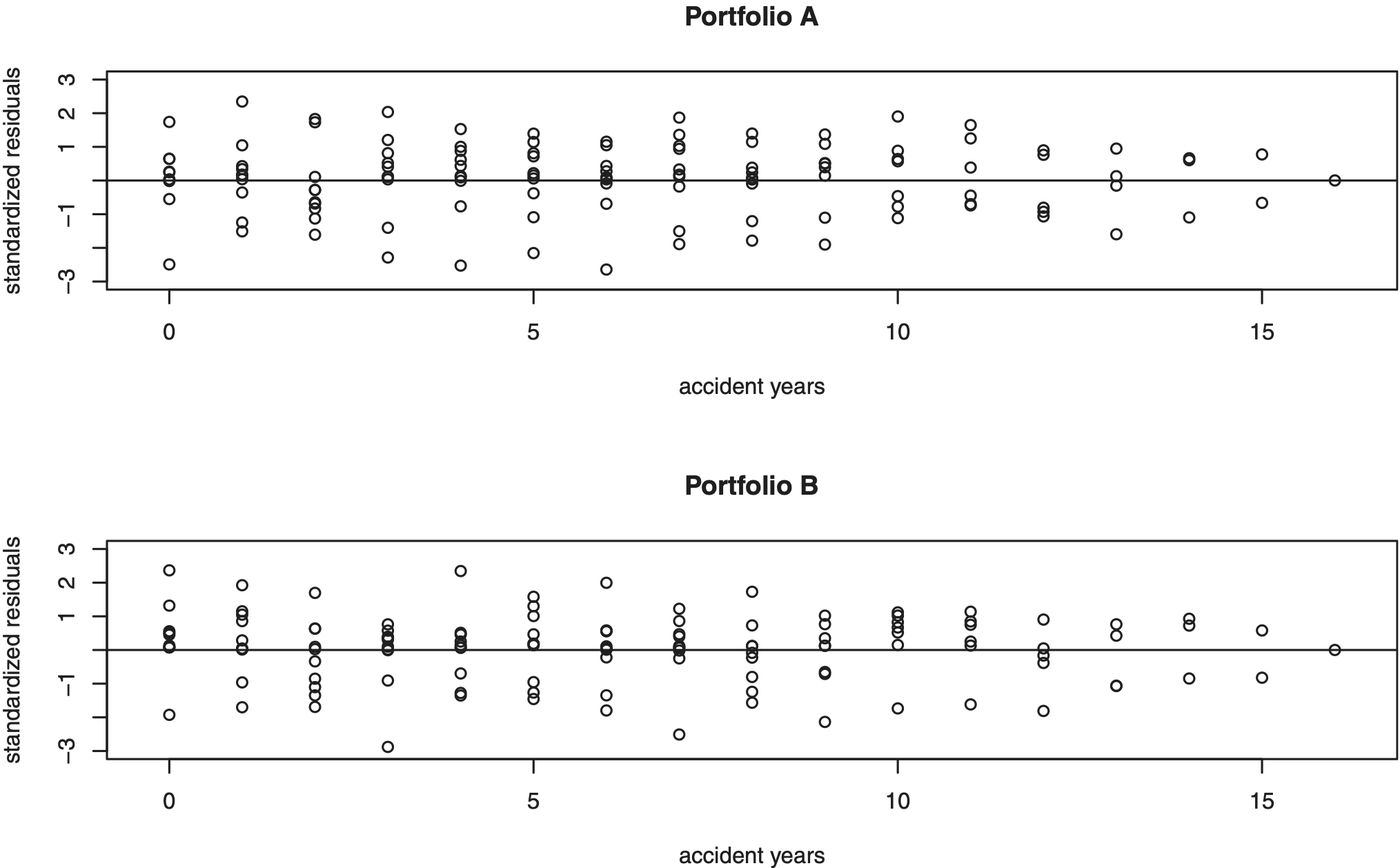
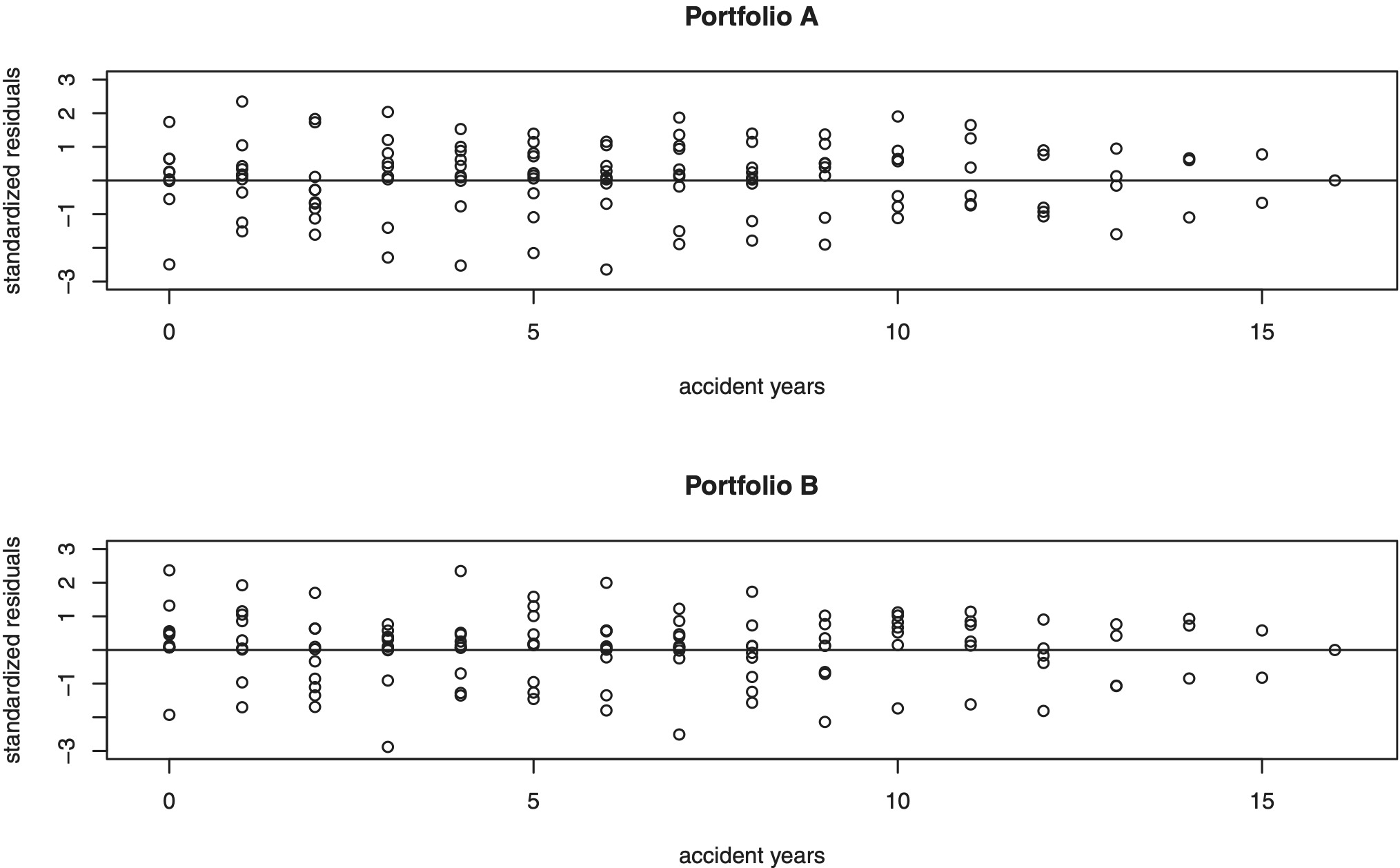
For ξ = 2 and δ = 0 we analyse the standardized residuals given by
\mathbf{r}_{i, j}=\mathbf{D}\left(\mu_{i}\right)^{-2} \Sigma\left(\Theta_{i}\right)^{-1}\left(\mathbf{X}_{i, j}-\mathbf{D}\left(\gamma_{j}\right) \mathbf{D}\left(\mu_{i}\right) \pmb{\mu}\left(\Theta_{i}\right)\right) . \tag{5.2}
These standardized residuals have, conditionally given Θi, zero mean and diagonal identity matrix as covariance matrix. Replacing all unknown parameters in (5.2) by their estimates leads to the empirical standardized residuals For Portfolio A and B, Figure 3 shows the empirical standardized residuals which are (approximately) centered and do not seem to have a trend.
We consider for the case ξ = 2 and δ = 0 the corresponding reserves 2.13 as well as the associated prediction uncertainty. Table 5 shows the estimates for the aggregated claims reserves, conditional process standard deviation, squared conditional estimation error and conditional standard error of prediction for the aggregated reserves over all accident years resulting by the multivariate Bühlmann-Straub (ξ = 2 and δ = 0), chain-ladder and additive loss reserving model. The last two columns contain the estimates of the fourth iteration for the multivariate chain-ladder and additive loss reserving model, respectively (see Merz and Wüthrich (2008), Chapter 8, for more details to the models). We obtain in the Bühlmann-Straub model higher reserves as well as a higher prediction uncertainty compared to the other two models. The difference can partly be explained by the fact that allowing for different “accident years qualities” (through in the multivariate Bühlmann-Straub model increases the parameter uncertainty and the process variance of the model. Tables 6 and 7 show the observed incremental claim payments in Portfolios A and B.