1. Introduction
Cyber risk has emerged as one of the most significant threats in the digital age. Cyber attacks may have severe consequences, such as exposure of sensitive information, identity fraud, and substantial financial losses. The sophistication of modern cyber attacks often outpaces protective measures, as evidenced by the increasing number of data breaches organizations have recently experienced. For instance, the Privacy Rights Clearinghouse reported 18,353 data breaches between 2010 and 2021, resulting in nearly 1.5 billion breached records (Privacy Rights Clearinghouse, n.d.). The Identity Theft Resource Center and Cyber Scout reported a significant increase in data breach incidents in 2022, exposing over 422 million records, a stark rise from the nearly 294 million records exposed in 2021 (Identity Theft Resource Center, n.d.). The financial implications of these breaches are substantial. According to NetDiligence, small-to-medium enterprises (i.e., those with less than $2 billion in annual revenue) faced an average breach cost of $170,000, excluding an average crisis service cost of $110,000 and an average legal cost of $82,000. For larger companies (i.e., those with $2 billion or more in annual revenue), the average breach cost rose to $15.4 million, with an average crisis service cost of $4.1 million and a legal cost of $3.1 million (NetDiligence, n.d.). Cybersecurity Ventures expects global cybercrime costs to grow by 15% per year over the next few years, reaching US$10.5 trillion annually by 2025.[1]
In traditional centralized networks, vulnerabilities can often be mitigated through patches and upgrades to the operating systems. However, modern networks, particularly those incorporating Internet of Things devices with lightweight operating systems and limited computational capabilities, present unique challenges. It is not always possible to identify and patch vulnerabilities in these networks, making risk assessment and prioritization essential for optimizing resource allocation and protective efforts. However, analyzing network risks in isolation provides a limited perspective on network security owing to the complex interdependency between vulnerabilities. In this context, Bayesian Attack Graphs (BAGs; Koller and Friedman 2009) offer a powerful framework for representing prior knowledge about vulnerabilities and network connectivity, which can illustrate the potential paths an attacker could take through the system by exploiting successive vulnerabilities.
Our study objective was to develop a practical probabilistic approach for pricing cyber risks in modern networks using BAGs. BAGs are graphical models that represent knowledge about network vulnerabilities and their interactions, illustrating the various paths an attacker can take to compromise a given objective by exploiting a set of vulnerabilities (Poolsappasit, Dewri, and Ray 2011). Each attack path involves a sequence of exploited vulnerabilities, with each successful exploit granting the attacker additional privileges toward their goal. Modeling cyber risk using BAGs has been a recurrent theme in the literature, predominantly within the realm of cybersecurity. For instance, Poolsappasit, Dewri, and Ray (2011) proposed a risk management framework that leverages BAG, allowing system administrators to quantify the likelihood of network compromise across static risk assessment, dynamic risk assessment, and risk mitigation analysis. Muñoz-González et al. (2017) delved into belief propagation and junction tree algorithms for exact inferences in BAGs, focusing on static and dynamic network risk assessments. Sun et al. (2018) pioneered a probabilistic approach with the ZePro system, which was designed for zero-day attack path identification and demonstrates the efficacy of BAG in revealing such paths. d’Ambrosio, Perrone, and Romano (2023) extended the applicability of BAG to insider threats, formulating a Bayesian Threat Graph for cyber risk management. Kim et al. (2023) proposed adaptive moving target defense operations based on BAG analysis that uses a knapsack problem to optimize vulnerability reconfiguration in software-defined networking. In the field of actuarial science, however, the use of BAG for insurance pricing remains relatively limited. Noteworthy contributions include Shetty et al. (2018), who developed a cyber risk assessment method based on BAG to address the challenges posed by the absence of historical data and the dynamic nature of cyber risk. While they focused on estimating attack probabilities through asset-at-risk monitoring and continuous software vulnerability scoring, their work leaned toward descriptive rather than probabilistic modeling. Tatar et al. (2020) presented a probabilistic framework for assessing enterprise cyber risk using BAG to compute attack likelihoods based on scenario examples.
Two key aspects distinguish our work from existing studies. First, we focus on modern networks, presenting a practical methodology to identify vulnerabilities and estimate exploit probabilities. Second, we introduce a novel top-down approach for computing joint exploit probabilities, departing from the conventional variable elimination algorithm prevalently employed in the studies mentioned earlier. Further, our contribution extends to exploring pricing strategies based on BAG analysis, a dimension yet unexplored in the current literature. Our contributions are summarized as follows:
-
Practical approach for identifying and characterizing cyber risks in modern networks: We propose a practical method to identify and characterize cyber risks in a modern network. This involves detailing the modern network and the vulnerabilities present in network devices, including reports from vulnerability scanners (Walkowski et al. 2020), vulnerability dependency details, and scores assigned to the vulnerabilities by standards such as the Common Vulnerability Scoring System (CVSS; “Common Vulnerability Scoring System,” n.d.) and the Exploit Prediction Scoring System (EPSS; Jacobs et al. 2023). These details are abstracted into a vulnerability graph for modeling purposes.
-
Modeling cyber risks in modern networks via BAGs: We formulate the nodes of the graph as device vulnerabilities and the edges as vulnerability dependencies. We identify potential attack initiation points in the network and model them as source nodes. Similarly, potential target points, toward which attacks may be directed, are identified and modeled as sink nodes. We analyze the abstracted vulnerability graph via the BAG and propose a novel top-down approach to compute the joint exploit probability across the network.
-
Cyber insurance pricing: We explore various cyber insurance pricing strategies based on the exploit probabilities within the modern network. Through a simulation study, we scrutinize these strategies, perform sensitivity analysis, and discuss the impact of dependence on the insurer.
2. A quantitative framework for modeling and pricing cyber risks over modern networks
Despite the growing importance of cyber risk management, few studies have modeled cyber risks in modern networks from an insurer’s perspective. Our study presents a quantitative framework for modeling and pricing cyber risks within a modern network. This framework comprises three key components: (1) identifying vulnerabilities that incur cyber risks, (2) modeling cyber risks and computing compromise probabilities, and (3) determining premiums.
2.1. Identifying and characterizing cyber risks in modern networks
Modern networks, with their inherent complexity and heterogeneous structure, present a large attack surface (Denning, Kohno, and Levy 2013; Davis, Mason, and Anwar 2020). From an insurer’s perspective, it is crucial to identify these risks using a simple yet efficient approach. To this end, we propose identifying risks based on vulnerabilities present in a modern network.
A common approach to assessing vulnerability primarily relies on the CVSS, which calculates the severity of a vulnerability based on its characteristics and the impact on an information system’s confidentiality, integrity, and availability. The CVSS base score, which ranges from 0 to 10, is the most commonly used component, with a higher score indicating a higher threat level. Almost all known vulnerabilities are published on the National Vulnerability Database’s website.[2] Each vulnerability, identified via common vulnerabilities and exposures (CVE), includes the CVE identifier, description, and references discussing the vulnerability. However, it is important to note that the CVSS score does not reflect the probability of a vulnerability being exploited in an attack, since only a small proportion of vulnerabilities are exploited in practice. Therefore, it is necessary to convert the CVSS into an exploitation probability. Jacobs et al. (2021) proposed a data-driven framework, the EPSS,[3] for assessing the probability that a vulnerability will be exploited within a certain period after public disclosure.
To identify cyber risks in modern networks, we first identify the exploitable elements in the network and the devices in which they reside. These exploitable elements are associated with the network because of inherent vulnerabilities in different network devices. Attackers may concatenate these exploitable elements to form channels to reach critical resources in the network. This identification can be completed via vulnerability scanners (Walkowski et al. 2020). Further, the network details, including topology, configuration, connectivity among devices, and access control policies, are used to create the vulnerability graph.
The following are performed to identify cyber risks in modern networks:
-
Scan vulnerabilities: Typically, the vulnerability report generated by vulnerability scanners includes vulnerability dependency details and CVSS scores (Walkowski et al. 2020).
-
Create the vulnerability graph: The vulnerability graph is created based on the vulnerability details.
-
Determine exploitation probabilities: Vulnerabilities’ exploitation probabilities can be determined from the vulnerability graph based on vulnerability details.
For illustration, consider a smart home network with three discovered vulnerabilities: CVE-2021-21736 CVE-2018-3919 and CVE-2022-22667 The vulnerability graph is created based on the attack scenario: the attacker exploits a vulnerability in a smartphone operating system (CVE-2022-22667) over the wireless network and compromises the smartphone. This grants the attacker access to the operating system, which allows the attacker to pivot into the smart home network to compromise the smart home hub by exploiting the vulnerability (CVE-2018-3919). Further, the attacker exploits the vulnerability (CVE-2021-21736) in the smart camera to gain control over it. The vulnerability graph can be represented as a path of two edges, V3→V2→V1. The CVSS base scores for these vulnerabilities are 7.8 9.9 and 7.2 The EPSS probabilities are and respectively. This example illustrates how vulnerabilities in a modern network can be identified, characterized, and graphically represented, providing a basis for assessing and pricing cyber risks.
2.2. Modeling the cyber risks in modern networks via BAGs
This section discusses how to model the risk over a modern network via BAGs and develops a new approach to compute the compromise probability.
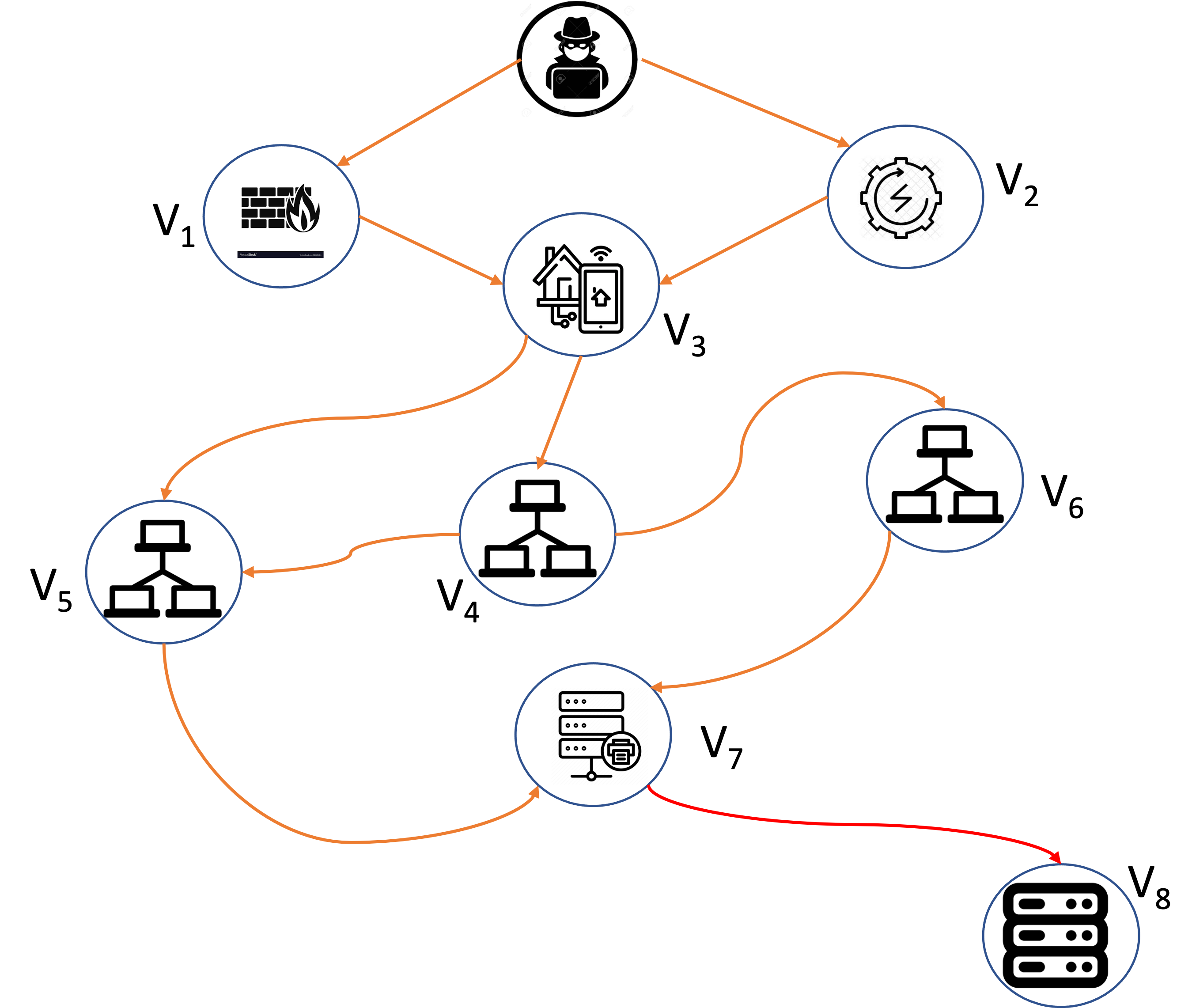
Let represent the vulnerability graph over a modern network, where is the set of vulnerabilities with size and is the set of edges. Note that node represents vulnerability in the network, and edge represents the possibility of exploitation from vulnerability to vulnerability Figure 1 illustrates a modern industrial network with the graphical representation of vulnerability relations.

We consider two possible attack scenarios:
-
Attack scenario 1: The attacker exploits the firmware vulnerability : CVE-2017-9861) in the network and compromises it. This grants the attacker access to the local operating system. The attacker can use this access to pivot into the internal network and further compromises the building management system in the network by exploiting the vulnerability : CVE-2012-4701). Further, the attacker exploits the vulnerability : CVE-2013-0640) in the LAN user machine to obtain limited privileges in the machine. The attacker then exploits a privilege escalation vulnerability : CVE-2017-11783) to gain local admin privileges on the same machine. The attacker uses the directory traversal vulnerability : CVE-2008-0405) to access unauthorized files in the file and print server. The password vulnerability of the central server : CVE-2010-2772) can be exploited via the file and print server to compromise and control the whole system, which can cause catastrophic financial losses. The attack path can be represented via edges as
-
Attack scenario 2: The attacker exploits the vulnerability : CVE-2017-9859) in the inverter unit of the building power management and then exploits the vulnerability : CVE-2012-4701) in the building management system. The attacker can further exploit the vulnerability : CVE-2013-0640) in the LAN user machine and attack the vulnerability : CVE-2013-0640). After that, an attack is further launched into the file and print server through the vulnerability : CVE-2008-0405). Then, the password vulnerability of the central server : CVE-2010-2772) can be exploited. This attack path can be represented via edges as
Let be a random variable representing vulnerability and represent the associated loss with the exploited vulnerability Then, the total loss can be presented as
L=N∑j=1Lj=N∑j=1I(Vj)Xj,
where is the identity function and is the loss associated with the exploited vulnerability Note that the joint probability of vulnerabilities can be represented via BAG as
P(V1=v1,…,VN=vN)=N∏i=1P(Vi=vi|pai),vi=1,0,
where is the parent node set of vulnerability node (e.g., vulnerability node in Figure 1 has the parent node set and
vi={1,Compromised,0,Otherwise.
For example, in Figure 1, we have
P(V1,V2,V3,V4,V5,V6,V7,V8)=P(V1)P(V2)P(V3|V1,V2)P(V4|V3) ⋅P(V5|V3,V4)P(V6|V4)P(V7|V5,V6)P(V8|V7).
Note that the conditional exploitation probability of can be represented as
ej=P(Vj=1|paj)={0∀Vi∈paj,Vi=0;1−∏Vi∈paj,Vi=1(1−eij),Otherwise
where Computing the compromise probability is challenging because it involves many possible attack paths and is an NP-Hard problem. In the literature, an effective approach for computing the exploitation probability is known as the variable elimination (VE) algorithm (Liu and Man 2005; Muñoz-González et al. 2017; Koller and Friedman 2009). This approach identifies a small number of variables to compute the joint distribution and avoids generating them exponentially many times.
To illustrate, we use the VE approach to calculate the probability using the following elimination ordering: The step-by-step procedure is as follows:
-
Eliminating : We evaluate the expression
τV1(V2=v2,V3=v3)=1∑v1=0P(V1=v1)P(V3=v3|V1=v1,V2=v2),
where
-
Eliminating : We derive the equation
τV2(V3=v3)=1∑v2=0τV1(V2=v2,V3=v3)P(V2=v2).
-
Eliminating : We calculate
τV3(V4=v4,V5=v5)=1∑v3=0τV2(V3=v3)P(V4=v4|V3=v3)P(V5=v5|V3=v3,V4=v4),
where
-
Eliminating : We use the expression
τV4(V5=v5,V6=1)=1∑v4=0τV3(V4=v4,V5=v5)P(V6=1|V4=v4).
-
Eliminating : We determine
τV5(V6=1,V7=v7)=∑V5τV4(V5=v5,V6=1)P(V7=v7|V5=v5,V6=1),
where
-
Eliminating : We compute
τV7(V6=1,V8=v8)=1∑v7=0τV5(V6=1,V7=v7)P(V8=v8|V7=v7),
where
-
Eliminating : Finally, we obtain
P(V6=1)=1∑v8=0τV7(V6=1,V8=v8).
It is important to note that the VE approach is essentially a bottom-up method for computing the exploitation probability, as it consistently considers the parent nodes and eliminates all other nodes except the one of interest. In the subsequent section, we present a top-down approach for computing the joint exploitation probability, which draws inspiration from the back elimination (BE) approach introduced in Da et al. (2020).
Theorem 2.1. Let be the vulnerability graph of a modern network. Assume that target node vector does not include any leaf node,[4] then it holds that,
P(Vi1=…=Vil=1)=∑D0⊂DleafˆL∑L=1(∑DL−1⊂V∖(D0∪D1∪⋯∪DL−2)⋯∑D1⊂V∖D0P(((Vi1=…=Vil)∖(DL−1∪⋯∪D0))=1,1|DL−1)L−2∏j=0P(Dj+1,1|Dj))P(D0)
where is the longest path of the BAG.
P(D0)=∏i∈D0pi∏Dleaf∖D0(1−pi),
where represents the set of leaf nodes, and is the outside compromise probability for node
P(DL,1|DL−1)=∏j∈DL(1−∏i∈DL−1(1−eijαij))⋅∏j∈¯D0∪⋯∪DL∏i∈DL−1(1−eijαij)
where and is the adjacent matrix of the BAG.
Proof: Let be the set of originally compromised nodes chosen from leaf nodes in BAG. Then, we have
P(V0=1)=∑D0⊂DleafP(V0=1|D0)P(D0),
where
P(D0)=∏i∈D0pi∏Dleaf∖D0(1−pi),
and is the outside compromise probability for node Assume that is the number of steps needed to reach all the targets. Thus, we have
P(V0=1,L|D0)=P(V0∖D0=1,L|D0).
Let be the set of compromised nodes in the first step. Denote Then, we have
P(V1=1,L|D0)=∑D1⊂V∖D0P(V1=1,L|D1,D0)P(D1,1|D0)=∑D1⊂V∖D0P(V1=1,L−1|D1)P(D1,1|D0)=∑D1⊂V∖D0P((V1∖D1)=1,L−1|D1)P(D1,1|D0).
The second equation holds because given and the status of only depends on As a result, we can eliminate from the BAG, and is reduced by 1. Using a similar argument, denote it holds that
P(V2,L−1|D1)=∑D2⊂V∖(D0∪D1)P(V2=1,L−1|D2,D1)P(D2,1|D1)=∑D2⊂V∖(D0∪D1)P(V2=1,L−2|D2)P(D2,1|D1)=∑D2⊂V∖(D0∪D1)P((V2∖D2=1,L−2|D2)P(D2,1|D1).
By applying the same iterative argument, we have the following explicit expression:
P(Vi1=…=Vil=1)=∑D0⊂DleafˆL∑L=1(∑DL⊂V∖(D0∪D1∪⋯∪DL−1)⋯∑D1⊂V∖D0P((VL−1∖DL−1)=1,1|DL−1)P(DL−1,1|DL−2)⋯P(D2,1|D1)P(D1,1|D0))P(D0),
where
P(DL,1|DL−1)=∏j∈DL(1−∏i∈DL−1(1−eijαij))⋅∏j∈¯D0∪⋯∪DL∏i∈DL−1(1−eijαij),
and can be obtained from the EPSS and is the adjacent matrix of the BAG.
For illustration and comparison, we employ Theorem 1 to calculate the probability in Figure 1. The network can only be compromised through implying that In the following discussion, we focus on the scenario where while the other cases can be similarly analyzed. When the next compromised node can only be Notably, given the value of does not depend on Consequently, we have
-
If the value of is no longer influenced by Consequently, in the third step, node can compromise As per Theorem 1, the probability of this event is given by:
P(D0={V1})P(D1={V3}|D0={V1})⋅P(D2={V4,V5}|D1={V3})⋅P(V6=1|D2={V4,V5}).
-
If the value of is no longer influenced by Consequently, in the third step, node can compromise As per Theorem 1, the probability of this event is given by:
P(D0={V1})P(D1={V3}|D0={V1})⋅P(D2={V4}|D1={V3})⋅P(V6=1|D2={V4}).
-
If the value of is no longer influenced by However, in the third step, node cannot directly compromise As a result, according to Theorem 1, the probability of this event is:
P(D0={V1})P(D1={V3}|D0={V1})⋅P(D2={V5}|D1={V3})⋅P(V6=1|D2={V5})=0.
For the cases of and the resulting next step is in both cases, and the subsequent steps follow the same discussion as above. Consequently, the probability can be obtained. The new BE approach is a top-down method compared with VE, as it consistently identifies the offspring nodes and eliminates nodes along the attack path without the need to eliminate unrelated nodes such as and
Table 1 presents the probability of compromise for each where when and for using the explicit formula derived from Theorem 1 as well as through 1,000,000 simulations. The results obtained from Theorem 1 align perfectly with the outcomes of the simulations, affirming their consistency and reliability.
We can also use Theorem 1 to calculate the compromise probability between any two vulnerabilities. However, for the sake of simplicity, Table 2 presents only the compromise probabilities between (or and s. Once again, we observe that the calculated probabilities and the simulated probabilities are very close.
Comparison between VE and BE. Compared with the VE approach, the proposed BE approach confers the following advantages.
-
Expandability. The BE approach efficiently computes compromise probabilities when new vulnerabilities surface, leading to the expansion of the BAG. For illustration, assume that there is a newly discovered vulnerability which only connects to as the parent node in Figure 1. Then Eq. (1) changes to
P(V1,V2,V3,V4,V5,V6,V7,V8,V9)=P(V1)P(V2)P(V3∣V1,V2)P(V4∣V3)⋅P(V5∣V3,V4)P(V6∣V4,V9)⋅P(V7∣V5,V6)P(V8∣V7)P(V9).
To compute the probability of with elimination ordering: as mentioned previously, the VE approach requires recalculating from step (iv) to step (vii) and adding one more step for That is,
-
iv*) Eliminating : We use the expression
τ∗V4(V5=v5,V6=1,V9=v9)=1∑v4=0τV3(V4=v4,V5=v5)P(V6=1|V4=v4,V9=v9).
-
v*) Eliminating : We determine
τ∗V5(V6=1,V7=v7,V9=v9)=1∑V5=0τ∗V4(V5=v5,V6=1,V9=v9)P(V7=v7|V5=v5,V6=1),
where
-
vi*) Eliminating : We compute
τ∗V7(V6=1,V8=v8,V9=v9)=1∑v7=0τ∗V5(V6=1,V7=v7,V9=v9)P(V8=v8|V7=v7),
where
-
vii*) Eliminating : We have
τ9(V6=1,V9=v9)=1∑v8=0τ∗V7(V6=1,V8=v8,V9=v9).
-
viii*) Eliminating : Finally, we obtain
P(V6=1)=sum1v9=0τ9(V6=v6,V9=v9)P(V9=v9).
Conversely, the BE approach does not need to be recalculated because it is based on attack paths. We only need to compute the probabilities of newly generated attack paths with or Further, if cannot be exploited from outside, the exploit probability of does not change, which can be seen directly from the BE approach.
-
Interpretability. The BE approach offers the attack path interpretability and computational convenience by eliminating the need to consider unrelated nodes, which streamlines the calculation process. For illustration, assume that we are interested in in Figure 1. The VE approach requires repeating steps (i)–(vii) to eliminate to except for and to recalculate the newly generated functions. In essence, VE requires considering all conceivable states of vulnerabilities, excluding the targeted Conversely, the BE approach simplifies this process by selectively eliminating vulnerabilities in tandem with attack paths, as delineated in Table 3. To illustrate, upon establishing and the BE approach efficiently omits elimination since it has no bearing on the state of Analogously, subsequent elimination of follows, paving the way for calculating the compromise probability of based on This highlights the interpretability of the computational process within the BE approach. Note that the state of and need not be considered, further facilitating the computational efficiency of the BE approach.
In summary, the BE approach not only efficiently incorporates new vulnerabilities but also enhances interpretability by focusing on attack paths, leading to a more streamlined computational process compared with the VE approach. The R script of the computation based on Theorem 1 is available upon request.
We acknowledge that implementing the BE approach may pose challenges when dealing with an excessively large BAG. To illustrate this point, consider the construction of a 15-node BAG by introducing an additional to in Figure 1, preserving the same structure as to and connecting to Further complexity is introduced by adding another set of nodes, creating a 22-node BAG with the inclusion of to similarly structured to the 15-node BAG. In practical terms, the time required to compute rises from 0.331 seconds for the 15-node BAG to 0.734 seconds and rises significantly more to 24.156 seconds for the 22-node BAG. These computations were conducted on a desktop computer featuring an Intel Core i5 processor, 8.00 GB RAM, and a 64-bit Windows 10 operating system. The computational demand increases with the expansion of the BAG. However, it is crucial to emphasize that real-world networks are typically equipped with security monitoring systems that effectively reduce vulnerabilities. Therefore, under practical conditions, the proposed BE approach remains viable and can be employed.
2.3. Determining premiums
To price the cyber risks of a modern network, we consider the following four actuarial premium principles:
-
Expectation principle: where is the loading parameter that reflects the risk preferences of the insurer.
-
Standard deviation principle:
-
Gini mean difference (GMD) principle: where
GMD(L)=E[|L1−L2|],
is a statistical measure of variability, and and are a pair of independent copies of (see Furman, Wang, and Zitikis 2017; Furman, Kye, and Su 2019).
-
Conditional tail expectation: ρ4(L)=E[L|L≥VaRβ], where is the value-at-risk at level
VaRβ=minγ{γ:P(L≤γ)≥β}.
For more details on the conditional tail expectation, please refer to Hardy (2006) and Tasche (2002).
In our analysis, we assume that and are independent, and s are also independent, Then, we have
E[L]=N∑j=1E[I(Vj)]E[Xj].
Further,
Var[L]=N∑j=1Var[I(Vj)Xj]+2∑1≤i<j≤NCov(I(Vi)Xi,I(Vj)Xj),
where
Var[I(Vj)Xj]=(Var[Xj]+E2[Xj])E[I(Vj)]−E2[I(Vj)]E2[Xj]
and
Cov(I(Vi)Xi,I(Vj)Xj)=E[Xi]E[Xj]Cov(I(Vi),I(Vj)).
Therefore, the mean and variance of the loss can be explicitly computed based on Theorem 1.
3. Case study
In this section, we perform a case study of the modern network in Figure 1. We assume that and for
3.1. Exponential loss
Assume loss severities s have exponential distributions with different parameters:
X1,X2∼exp(1/2),X3∼exp(1/20),X4,X5∼exp(1/200),X6,X7∼exp(1/2000),X8∼exp(1/20000).
Table 4 provides the summary statistics for the loss of each exploited vulnerability and the total loss based on 1,000,000 simulations, as well as the corresponding true means and standard deviations (SDs) obtained from Eqs (4) and (5). The results show that the simulated means and SDs align closely with their theoretical counterparts, indicating the reliability of the simulation methodology. Among the individual loss variables, stands out as having an exceptionally large loss (namely, a maximum of 79,438.556). This can be attributed to its considerably high mean (20,000) and substantial SD. Note that the compromise probability of is found to be extremely small in Table 1. Therefore, the 99.99% percentile value of is observed to be 0. Combined, these factors result in an extreme loss value for contributing significantly to the overall variability in the total loss Conversely, exhibits the smallest maximum value and mean compared with other loss variables. This is primarily due to its smallest mean and small compromise probability, indicating a relatively lower risk associated with Consequently, contributes less to the overall variability of the total loss Analyzing the total loss it is evident that it has a relatively small mean but a substantial SD. This characteristic is mainly driven by the influence of which exhibits a significant loss magnitude and contributes to the overall variability.
Table 5 exhibits the calculated Pearson correlation coefficients from Eq. (5), highlighting the interplay of losses and their influence on the overall variance of the total loss As is evident from the table, the loss of shows a notably larger correlation with the loss of nodes directly descended from it (i.e., son nodes). For instance, in row 4, the correlation coefficients of with and distinctly exceed the correlation of with other losses in the same row. This pattern arises because and are son nodes of thereby implying a direct influence of on and However, the correlation between and is lower compared with and because is influenced by both and whereas is solely influenced by Furthermore, an ascending pattern in the correlation between total loss and individual losses to can be observed. For example, the correlation between and is the smallest, while has the strongest correlation with the total loss This can be attributed to the fact that the total loss is an aggregation of to and larger losses dominate the sum.
Sensitivity analysis and pricing. Consider a portfolio with 500 policyholders whose networks are approximately the same. The profit and loss ratio (LR) are defined as follows:
Profit=Premium−Claim,LR=ClaimPremium,
where and represents the coverage limit. Note that we assume the deductible is 0 since the premium is generally low in our discussion. The is set to be and the permissible mean loss ratio is 40%, which results in the premium being We perform the sensitivity analysis of each pricing principle in the following scenarios:
-
S1: Increasing the compromise probability of from 0.1 to 0.5. This tests how the severe outside compromise probability affects the profit and LR.
-
S2: Increasing and from 0.1 to 0.5. This tests the influence of vulnerability
-
S3: Increasing from 0.1 to 0.5. This evaluates the influence of vulnerability
-
S4: Increasing and from 0.1 to 0.5. This tests the influence of vulnerability
-
S5: Increasing from 0.1 to 0.5. This evaluates the influence of vulnerability
-
S6: Increasing and from 0.1 to 0.5. This tests the influence of vulnerability
-
S7: Increasing from 0.1 to 0.5. This evaluates the influence of vulnerability
These scenarios provide a robust landscape to test the effect of each vulnerability on the profit and LR. In each scenario, we ensure all other probabilities are held constant. Our baseline case provides a context for pricing principles’ parameters, denoted as Table 6 presents the mean LRs and profits, along with their SDs under each scenario. The LRs of the pricing formulas and hold steady around 40%. This invariance to the change in losses can be attributed to their definition in Eq. (6) (the slight deviation from 40% can be attributed to rounding errors). The highest premium across all pricing principles is observed under scenario S2, suggesting that exerts the most significant influence on the determination of the premium. Interestingly, while could result in the largest loss, the premium under scenario S7 is not the highest among all scenarios. This observation suggests that the relationship between vulnerability and premium might not be linear and could depend on other factors. The percentage increase in premium/profit varies from roughly 70% (in S5) to 367% (in S2) for and For the mean LR surpasses 40% for scenarios S1 to S5, even as the premium increases in each scenario. Conversely, in scenario S7, the mean LR falls below 40%. These observations suggest that the pricing formula might require adjustments to adapt to changes in the compromised environment. It is also worth noting the significant SDs in the mean LR and profit under each scenario, which call for caution in interpreting these results.
3.2. General loss
This section considers more general distributions for loss severities while the corresponding means are kept approximately the same:
X1,X2∼exp(1/2),X3∼exp(1/20),X4,X5∼Γ(200,1),X6,X7∼Lognormal(7,1.2),X8∼Lognormal(9,2).
The summary statistics of 1,000,000 simulations are summarized in Table 7. We again observe that the simulated means and SDs align closely with their theoretical counterparts. Since and remain unchanged, their corresponding losses and show comparable statistics to Table 4. However, for and where and have been modified to a gamma distribution, we observe that the 99.99% quantiles (226.842 and 225.895, respectively) and maximum values (258.400 and 257.584, respectively) are notably less than those of their counterparts in Table 4. This change underscores the lower variance characteristic of the gamma distribution. In contrast, when and are transformed to a lognormal distribution, the maximum values of and increase significantly to 20,417.797, 20,703.799, and 180,211.322, respectively. These higher values highlight the lognormal distribution’s capacity for right-skewness and longer tails, leading to an increased potential for extreme values. This is further reflected in the total loss which now has a larger maximum value of 185,932.760, a result of the larger maximum values for and Furthermore, the SDs of and and total are larger than those in Table 4, denoting an increase in the variability due to the change in distributions. This analysis highlights how altering the severity distribution, while maintaining the same mean values, can profoundly influence risk outcomes, particularly in terms of extreme potential losses and overall variability.
Table 8 displays Pearson correlation coefficients. Table 5 and Table 8 show that changes in loss severity distribution can affect the relationships among the losses. As shown, the correlation between and and and increases to 0.216 and 0.222, respectively, indicating a stronger interaction between these losses. Similarly, the correlation between and increases to 0.178, while the correlation between and strengthens to 0.188. Conversely, the correlation between and decreases to 0.136, suggesting a reduced mutual impact. As for the total loss its correlation with rises to 0.941, indicating that the change in loss influences the total loss. Overall, the loss severity distribution changes lead to shifts in the correlations between individual and total losses. This underlines the importance of considering severity distributions and their interdependencies in assessing risks.
Sensitivity analysis and pricing. Similarly, we performed the sensitivity analysis under the same setting as the previous study, except we increased the coverage limit to 200,000. Table 9 summarizes the results. Using a baseline case for the context of pricing principles’ parameters,
(θ1,θ2,θ3,β)=(1.58,0.0258,0.81,0.613),
we can derive some interesting observations. Regarding the LRs, the pricing formulas and consistently hold their values close to 0.4 across all scenarios, with slight deviations likely due to rounding errors. For in scenarios S1 to S5, despite increasing premiums, the mean LR surpasses 0.4. Conversely, in scenario S7, the mean LR falls below 0.4. This observation again suggests that may be more sensitive to changes in risk factors and might require certain adjustments to maintain stability in different risk environments. Examining the premiums, the highest value across all pricing principles consistently appears under scenario S2, indicating the pronounced impact of risk factor Despite the significant loss caused by the premium under scenario S7 is not the highest among all scenarios, suggesting that the relationship between risk factors and premium levels may not be directly proportional. The percentage increase in premium varies significantly across scenarios and pricing principles. For and it ranges from approximately 55% (in S5) to 328% (in S2), whereas for it ranges from about 20% (in S5) to 200% (in S2). Again, the high SDs in the mean LR and profit under each scenario underscore the need for careful interpretation of these results.
3.3. Common vulnerabilities
Within modern networks, policyholders may experience a unique form of interdependence arising from systemic risk—a risk category rooted in common vulnerabilities. In the event of a successful exploitation of such common vulnerabilities, simultaneous exploitation occurs effortlessly across multiple networks. This synchronized vulnerability exploitation, devoid of additional effort, has the potential to trigger catastrophic financial losses for insurers.
To illustrate, consider Figure 1, where two common vulnerabilities, denoted as and are present. In this scenario, if, for instance, for a given policyholder (with taking values of 1 or 2), then all other policyholders share the same vulnerabilities. Subsequently, we examine the repercussions of common vulnerabilities on the insurer, assuming an exponential loss model with the same premium (i.e., 10.60) as outlined in Section 3.1.
The summary statistics for LRs associated with independent and dependent risks resulting from common vulnerabilities, specifically and are outlined in Table 10. It is interesting to observe that the median LR for dependent risk is 0, contrasting with the 0.233 median for independent risk. This discrepancy can be attributed to the absence of breach risk for all policyholders when both vulnerabilities remain unexploited. However, the quantiles of LRs reveal a substantial difference between the two scenarios. For instance, the 90th quantile in the independent case is 0.751, surging to 1.363 in the dependent scenario. This underscores the substantial impact of common vulnerabilities in causing significant losses for insurers. Another noteworthy observation is that while the mean LRs are comparable for independent and dependent risks, the SD in the dependent scenario is markedly larger.
In summary, the dependence risk induced by common vulnerabilities substantially elevates the potential for losses, consequently heightening insolvency risk for insurers. Moreover, the larger variability in the LR in the dependence scenario suggests that using high quantiles rather than mean LRs for practical risk assessment is a prudent approach.
4. Conclusion and discussion
This study presents a practical approach to pricing cyber risk in a modern network via BAGs, encompassing three key components: vulnerability identification, cyber risk modeling via BAGs, and premium determination. We propose a novel top-down approach for computing the joint exploitation probability, which efficiently identifies offspring nodes and eliminates nodes along the attack path without the need to eliminate unrelated nodes. Sensitivity analysis reveals that premiums can significantly increase when the risk associated with a single vulnerability escalates. Furthermore, our analysis underscores the importance of considering the distribution of potential losses, showing that changes in the severity distribution, even while maintaining the same mean values, can significantly impact risk outcomes.
We also discuss the impact of dependence risk induced by common vulnerabilities on the insurer and discover that the dependence risk can significantly increase the probability of insolvency.
From a practical standpoint, this study provides a robust framework for identifying and characterizing cyber risks in modern networks. This can assist in optimizing resources and efforts required for network protection, potentially mitigating the financial and operational impact of cyber incidents.
However, this study is not without limitations. The explicit computation of compromise probabilities based on the proposed top-down approach may be time consuming for large vulnerability networks. Yet, in practice, defenders should strive to minimize network vulnerabilities, which often result in smaller vulnerability networks despite the physical network’s size. Additionally, the pricing strategies discussed are based on the mean LR, which may not be suitable from a conservative perspective because of its large SD resulting from extreme losses. Alternative criteria, such as the high quantile of LR (e.g., 99.5th quantile), may be more appropriate in certain scenarios.
While our findings underscore the significant risk to insurers posed by interdependence among policyholders, a thorough and comprehensive investigation is imperative to scrutinize the impact of this dependence on both profitability and insolvency. Finally, the study does not explore the impact of various mitigation strategies and heterogeneous networks on cyber risk pricing, which could provide valuable guidance for network operators and insurers. While important, these limitations also pave the way for future research in cyber risk management and cyber insurance.
https://cybersecurityventures.com/cybercrime-to-cost-the-world-9-trillion-annually-in-2024/
If any target node is a leaf node, the compromise probability can be directly inferred.