

1. Introduction
Insurance fraud has been a persistent problem in the commercial world, and health insurance fraud is among the most concerning because healthcare fraud and abuse (Becker, Kessler, and McClellan 2005; Yang and Hwang 2006) are major concerns in many countries (Joudaki et al. 2015). In 2018, $3.6 trillion was spent on healthcare in the United States, representing billions in health insurance claims. The National Health Care Anti-Fraud Association estimates that financial losses due to healthcare fraud total tens of billions of dollars each year. A conservative estimate is that fraud losses represent 3% of total healthcare expenditures, with some government and law enforcement agencies placing the loss as high as 10% of the annual health outlay, which amounts to more than $300 billion.[1] In 2019, India had over $5.4 billion in insurance fraud loses. Fraudulent health insurance claims can range from 15% to 35% of overall claims.[2]
Losses due to insurance fraud present a major business challenge for many reasons:
-
It is difficult to determine the exact value of fraud-related losses. Although precise numbers prove elusive, our study highlights the capacity to enhance our proficiency in estimating losses by strategically applying machine learning models.
-
Detected case numbers are much lower than the actual number of fraudulent cases (Joudaki et al. 2015; Kang et al. 2016). Our research illustrates that incorporating triggers into machine learning models proves instrumental in augmenting the detection of fraudulent cases.
-
An estimated 8.5% of industry-generated revenue is lost to fraud. Our models produced a higher level of accuracy in detecting fraud cases and concurrently identified a higher volume of fraudulent events. This could conceivably contribute to reducing the percentage of revenue lost; however, our study did not address this aspect.
Existing anti-fraud solutions include having claims managers investigate, with assistance from regulatory agencies (e.g., the Insurance Fraud Bureau and the Insurance Regulatory and Development Authority of India), or using specialized services and tools provided by private organizations. But these approaches have limitations:
-
Fraud detection is subjective and depends on the claims investigator’s expertise.
-
Although a few algorithms and statistical methods (J. Li et al. 2008) have been developed, they are poorly adapted to the problem (Major and Riedinger 2002).
The health insurance sector is growing rapidly and generating increasingly massive amounts of data. Unfortunately, many companies have legacy computer systems that do not capture sufficient details to identify and combat fraud.
Traditional healthcare fraud detection methods rely heavily on auditing and expert inspection, which are costly, inefficient, time consuming, and require significant human intervention. These methods typically focus on specific claims characteristics and pay little attention to relationships between factors. The healthcare insurance industry needs more efficient and effective fraud detection methods that can process vast amounts of data (Mesa et al. 2009).
The basis of this study is the extensive fraud detection research conducted by the SOA Research Institute (Lieberthal et al. 2018). Our study focused on customer-level fraud in healthcare by analyzing claim and policyholder records from the Ayushman Bharat universal health coverage scheme. We applied standard performance metrics to evaluate the performance of several machine learning models developed to detect fraudulent claims (M. E. Johnson and Nagarur 2016). We also compared fraud detection effectiveness in machine learning models (Bauder, Khoshgoftaar, and Seliya 2017; Bauder, da Rosa, and Khoshgoftaar 2018) both with and without integrated business rules.
Our results showed that adding triggers to the data improved machine learning model effectiveness for detecting fraudulent healthcare claims (S.-H. Li et al. 2012). By identifying fraud using an efficient and accurate method, we can reduce financial losses and improve the quality of patient care. This research contributes to the ongoing effort to develop more effective fraud detection methods in healthcare, which will ultimately benefit patients, healthcare providers, and insurers alike.
1.1. Actuarial methods and skill sets in fraud detection
Actuaries assess the financial risks of insurance policies. Insurance fraud not only results in significant financial losses for insurance companies but also increases policyholders’ premiums. One important risk mitigation method is claims control, where actuaries use data analysis to identify and quantify patterns of fraudulent behavior in insurance claims data, then develop strategies to mitigate these risks.
Actuaries are uniquely qualified to identify and analyze factors that contribute to insurance fraud. They have a thorough understanding of data, product value chains, claims, and policyholder behavior. Using their understanding of the motivations behind fraudulent behavior, actuaries design insurance products and pricing structures that deter fraud and minimize losses (Vanhoeyveld, Martens, and Peeters 2020). Actuaries also work closely with claims adjusters and other experts to investigate suspicious claims and identify potential cases of fraud. However, traditionally, actuaries are consumers of fraud analytics output. Research in preventing and detecting fraud using actuarial data science techniques will open opportunities for actuaries in this area (Richman 2018).
Ultimately, actuaries’ role in insurance fraud detection is critical to the success and sustainability of the insurance industry (Gupta, Mudigonda, et al. 2019). By effectively detecting and preventing fraud, actuaries help maintain insurance companies’ financial stability and their ability to provide affordable and reliable coverage to policyholders.
1.2. Machine learning to detect health insurance fraud
Health insurance industry growth has generated a massive amount of data. Unfortunately, many companies still rely on outdated systems that fail to capture sufficient details to identify and prevent fraudulent activity (Househ and Aldosari 2017). Most companies manage and control fraud; consequently, only a few fraud cases are ever identified, and those are often discovered years after they occurred.
To combat this problem, machine learning (ML) and deep learning (DL) fraud detection techniques are becoming increasingly popular in the health insurance sector (Gomes, Jin, and Yang 2021). These techniques analyze large amounts of data more accurately and faster (Zhou et al. 2020; Srinivasan and Arunasalam 2013) than methods that rely on humans manually analyzing data to detect patterns and anomalies (Sadiq et al. 2017; van Capelleveen et al. 2016) that may indicate fraudulent activities (Kose, Gokturk, and Kilic 2017). ML models recognize patterns in claims data that suggest fraud, such as abnormal billing patterns or excessive billing for a specific service, while DL models scrutinize medical records and claims data to identify potential fraud and flag the records for further investigation (Gao et al. 2018).
Moreover, ML and DL models can adapt to new fraud patterns and continue to learn from new data (Verma, Taneja, and Arora 2017), which is particularly critical in an industry where new types of fraud emerge quickly and require prompt detection and response (Thornton et al. 2013). Overall, the use of ML and DL techniques in health (J. M. Johnson and Khoshgoftaar 2019) insurance fraud detection (M. E. Johnson and Nagarur 2016) has the potential to lower fraud losses, improve the efficiency of identifying fraudulent activity, and reduce costs for insurance companies and consumers (Yoo et al. 2012). Table 1 describes distinctions between the ML and DL methods.
These distinctions make certain tasks uniquely suited for either ML or DL methods. Our study emphasized ML methods; we did not thoroughly explore DL techniques. However, it is important to acknowledge that DL methods have the potential to effectively identify fraud and may serve as a compelling area for future research.
2. Data
2.1. Dataset
Ayushman Bharat, also known as Pradhan Mantri Jan Arogya Yojana, is the world’s largest group health insurance scheme. It was launched by the government of India in September 2018, with the aim to provide health insurance coverage to economically vulnerable families in India. Eligible beneficiaries are entitled to free treatment for various medical conditions at empaneled hospitals across India. The program currently covers more than 100 million families (approximately 500 million individuals), making it the world’s largest government-funded healthcare program.
In addition to providing healthcare coverage, Ayushman Bharat also aims to establish health and wellness centers across the country, with the goal of promoting preventive healthcare and early detection of illnesses. This scheme is a major step toward achieving universal health coverage in India, which is a United Nations key sustainable development goal.
The data used for this research are from August 2019 to August 2020. We initially had two datasets: claims data and policy data. We later combined these to form a single dataset on which we conducted data preprocessing steps, such as missing values management (Frane 1976; Lin and Tsai 2020; Patidar and Tiwari 2013), feature scaling, and dimensionality reduction. During the dimensionality reduction step, we eliminated features with zero standard deviation and selected the top 20 unique values from columns with a high number of distinct values.
Zero standard deviation indicates that the feature values were constant, thereby offering no meaningful impact on the target variable (i.e., fraud) predictions. Consequently, these features were removed from consideration.
Certain categorical features exhibited a multitude of unique values, prompting us to narrow our focus to the top 20 (i.e., most frequent) occurrences. Values with limited recurrence are likely to have a minimal impact on predicting fraud. To facilitate model training in subsequent stages, we planned to convert these categorical features into factors through encoding. However, encoding all the unique values in a column with numerous possibilities would result in an extensive dataset, which would require computationally demanding training. Therefore, we opted to retain only the top 20 unique values for certain columns, ensuring a more manageable dataset for training models in later stages.
2.2. Reasons for fraud
We identified policyholder fraud reasons from the data and classified them into seven categories (Dietz and Snyder 2007; Villegas-Ortega, Bellido-Boza, and Mauricio 2021; Ekin, Musal, and Fulton 2015).
2.2.1. Using the wrong diagnosis to justify payment
To obtain medical reimbursements, individuals must complete claim forms that detail the services they received, which are typically based on a medical diagnosis. However, it is possible for policyholders to collude with medical service providers (Pande and Maas 2013) to deliberately manipulate the information provided to the insurance company to obtain reimbursement.
Reasons identified under this category included the following:
-
The policyholder, in collaboration with the medical service provider, filed a claim for a covered procedure, even though the treatment received was not a covered benefit under the policy.
-
The policyholder underwent an outpatient department procedure (Liou, Tang, and Chen 2008) but applied for reimbursement under the surgical package.
-
Medical documents that do not suggest any illness were submitted as proof of illness.
-
Photos that suggest surgery has not been done were submitted as proof of surgery.
-
The policyholder had surgery on a body part not covered by the insurance policy but submitted a claim for reimbursement that falsely stated the surgery was performed on a covered body part.
2.2.2. Price and document manipulation
Manipulating documents, such as clinical exams, certificates, medical prescriptions (Aral et al. 2012; Victorri-Vigneau et al. 2009), and other related documents, with the intention of obtaining an economic benefit, is a common practice (Fang and Gong 2017; Shin et al. 2012).
Reasons identified under this category included the following:
-
Providing documents from a pre-procedure instead of post-procedure as proof of the procedure. For example, x-rays, percutaneous transluminal coronary angioplasty frozen images.
-
Not submitting the relevant documents/photos for the package applied for. For example, hemodialysis chart, discharge summary, clinical notes, vital charts, treatment charts, mortality audit form, referral slips.
-
Sending the same document/photos for different dates.
-
Submitting reports that were not signed by any specialist.
-
Mismatched billing and discharge summary dates.
-
Date tampering on submitted documents.
2.2.3. Billing for services not provided
Patients may file fraudulent medical claims on their own or in collaboration with acquaintances or healthcare providers to obtain reimbursement for medical expenses they did not actually incur (Fang and Gong 2017; Shin et al. 2012).
Reasons identified under this category included the following:
-
Applied for reimbursement for a procedure that was not actually done. Examples include delivery, CT scan, surgery, stent, ventilator, ICU admission.
-
Applying for reimbursement of specialist charges when there was no specialist available in that hospital.
-
Applying for reimbursement for a procedure advised by the doctor, but the procedure was not done because the patient left against medical advice.
-
Applying for reimbursement for a procedure done in a hospital where the patient was initially admitted, but the procedure was not done because the patient was referred to another hospital.
-
Applying for reimbursement for a procedure, where the patient died before the procedure.
-
Registering multiple treatment packages on the same date to inflate the claim amount.
-
Applying for reimbursement for two procedures on the same day, when those two procedures cannot be done on the same day.
-
Seeking a package cost increase after discharge to inflate the claim amount.
2.2.4. Opportunistic fraud
Opportunistic fraud involves taking advantage of a real claim to introduce fictional preexisting or previous damages.
Reasons identified under this category include the following:
-
Providing photos from a past treatment.
-
Providing documents from treatments that were done before the insurance coverage started.
-
Applying for reimbursement even though the patient was not eligible for the scheme based on location.
-
Package enhancement was taken earlier than the minimum number of days before which enhancement is allowed.
-
Applying for reimbursement of a claim that has already been covered under another package.
-
Duplicate claims.
-
Applying for packages that require a minimum number of hospital admission days when the actual number of admitted days was below the minimum.
2.2.5. Identity fraud
Identity fraud involves acquiring and using another person’s health insurance card to receive medical treatment or other services. This may occur either with or without the knowledge or consent of the card owner.
Reasons identified under this category include the following:
-
A male patient applied for a delivery package.
-
Names on the discharge summary and clinical notes did not match.
-
Family members of the insured were admitted instead of the insured.
2.2.6. Misrepresenting eligibility
Patients may provide false or misleading information about themselves or their dependents to fraudulently obtain medical coverage for which they are not entitled.
Reasons identified under this category include the following:
-
Patients not revealing their alcohol habits when applying for insurance.
-
Misrepresenting the patient’s age to obtain a package for which they are ineligible based on age.
2.2.7. Delay
Delay refers to intentionally delaying claims submission or withholding necessary information to obtain a greater benefit from the insurance provider.
Reasons identified under this category include the following:
-
Preauthorization request raised after the patient was admitted to the hospital.
-
Preauthorization was generated after the patient was discharged from the hospital.
-
Admitting the patient several days after the approval.
-
Submitting the claim several days after discharge.
-
Claims submission delay ranging from 30 to 120 days.
-
Procedure was performed before the procedure approval date.
2.3. Exploratory data analysis
Table 2 provides an overview of the data and data types.
Table 3 shows the number of fraudulent claims, which comprise about 3% of the dataset.
2.4. Data dictionary
Table 4 contains the data dictionary.
3. Business rule triggers
Triggers are specific sets of activities that indicate potential fraud and raise suspicion. Identifying triggers is a complex task that requires a comprehensive understanding of the business processes involved. Moreover, triggers can vary depending on the stage at which the fraud is committed. To identify triggers and generate trigger data for the analysis, we built R functions based on several business rules. We then added the trigger data to the original dataset. The 10 triggers used in the analysis are described below.
3.1. Claim amount fraud trigger
A predetermined amount for each procedure is typically agreed upon by the insurer and medical service provider (Pande and Maas 2013), particularly for cashless claim processing. A claim amount that exceeds the established procedure-specific amount triggers a fraud alert.
3.2. Hospital admission days fraud trigger
A specific number of hospital admission days is deemed reasonable for each procedure. If the actual number of hospital admission days exceeds the established duration for the given procedure, a fraud alert is triggered.
3.3. Age fraud trigger
Specific medical procedures have expected age ranges assigned. When a claimant’s age falls outside the expected range for a particular procedure, a fraud alert is triggered. For this function to operate correctly, age must be correctly specified in both the claims file and the triggers file.
3.4. Gender fraud trigger
Certain medical procedures are specific to a particular gender, so a procedure performed on a claimant of the wrong gender generates a fraud alert. For instance, a gynecological procedure performed on a male claimant would trigger an alert. To operate correctly, gender must be specified correctly in both the claims file and the triggers file.
3.5. Claim count fraud trigger
The number of medical treatments for a specific condition are typically limited for policyholders, depending on the nature of the condition and treatment. If a policyholder has an unreasonably high frequency for a specific treatment, it may indicate fraud. This function detects all policyholders with an excessive number of treatments for the given condition.
3.6. Close proximity fraud trigger
A close proximity claim is when the treatment start date is very close to the policy start date. This condition will trigger a fraud alert.
3.7. Treatment date validity fraud trigger
Each policy has a start date and an end date within which the claim event (treatment) must occur. If the treatment date is outside these dates, a fraud alert is triggered.
3.8. Claim reporting delay fraud trigger
Each covered condition has a treatment start date and a treatment end date. The claim must be reported within the permissible number of days after the treatment end date (discharge date). A claim reported date that is outside the permissible limit will trigger a fraud alert.
3.9. Empaneled hospitals (medical service providers) fraud trigger
Insurers typically select hospitals to serve their policyholders through a process known as empanelment, whereby the insurer verifies that the hospital has the necessary facilities and has agreed to the specified tariff for each treatment. A fraud alert is triggered if the hospital specified in a claim is not included in the list of empaneled hospitals (Pande and Maas 2013).
3.10. Hospital distance fraud trigger
It is reasonable to anticipate that a policyholder will receive treatment at the nearest hospital. If the distance between the policyholder’s residence and the hospital location exceeds a predetermined threshold, a fraud alert is triggered.
4. Methodology
The methods adopted for fraud detection are described below (M. E. Johnson and Nagarur 2016; Kirlidog and Asuk 2012).
-
First, we addressed the problem of data imbalance through several oversampling techniques.
-
Then we conducted analyses
-
Methodology 1: ML models applied to data without triggers (M1).
-
Methodology 2: ML models applied to data with triggers (M2).
-
4.1. Handling data imbalance
Data imbalance is a common problem in health insurance claims data used for fraud detection. It occurs when the number of fraudulent claims in the dataset is significantly smaller than the number of legitimate claims (Mohammed, Rawashdeh, and Abdullah 2020; Thabtah et al. 2020).
With an imbalanced dataset, the fraud detection model trained on the data may be biased toward predicting that most claims are legitimate, since this will result in a high overall accuracy score. Consequently, the model may fail to detect fraudulent claims, leading to significant financial losses for insurance companies (Hassan and Abraham 2016; Gupta, Mudigonda, and Baruah 2021).
To address this problem, we used oversampling techniques where the minority class (fraudulent claims) would be oversampled until both classes had equal proportions.
It is important to note that while these techniques improve the performance of fraud detection models on imbalanced data, they cannot completely solve the problem. Therefore, it is important to carefully evaluate model performance (Seliya, Khoshgoftaar, and Van Hulse 2009) and continuously monitor the models to ensure that they are accurately identifying fraudulent claims (Frane 1976).
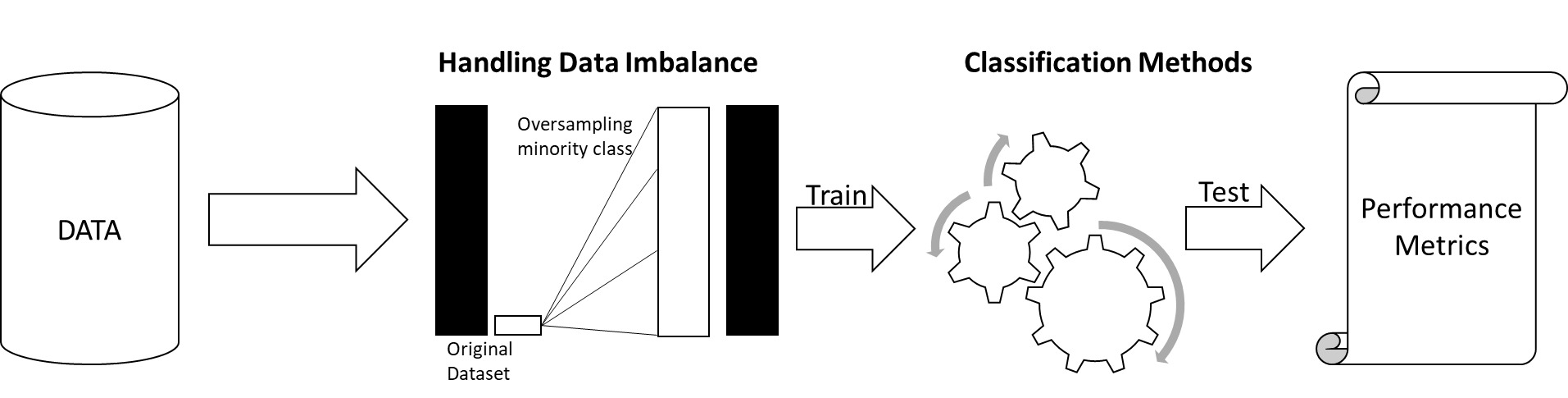
4.2. M1: ML models applied to data without triggers
First, we handled the data imbalance problem using four oversampling techniques (Aviñó, Ruffini, and Gavaldà 2018): random oversampling examples (ROSE), synthetic minority oversampling (SMOTE) (Chawla et al. 2002), majority weighted minority oversampling (MWMOTE) (Barua et al. 2014), and adaptive synthetic sampling (ADASYN) (He et al. 2008).
Then we used six classification models (Koh and Tan 2011) of supervised learning methods: decision tree, random forest (Ho 1995), XGBoost, naive Bayes, gradient boosting machine (GBM) (Gupta, Sai Mudigonda, et al. 2019), and generalized linear model (GLM) (H. Chen and Lindsey 1998; Hutcheson 2001) on the data without triggers.
Figure 1 shows the steps involved in M1.
4.3. M2: ML models applied on data with triggers
First, we generated data for the 10 trigger functions based on the business rules described in Section 3 and added the data columns to the original dataset.
Then, as with M1, we addressed the data imbalance problem using the same four oversampling techniques (ROSE, SMOTE (Chawla et al. 2002), MWMOTE (Barua et al. 2014), and ADASYN (He et al. 2008)) and applied the same six classification (Ali, Shamsuddin, and Ralescu 2015) models of supervised learning methods (decision tree (Patidar and Tiwari 2013), random forest (Ho 1995), XGBOOST, naive Bayes, GBM, and GLM (H. Chen and Lindsey 1998; Hutcheson 2001).
Brief descriptions of the ML models used in this study are as follows:
-
Decision trees represent a type of algorithm used in decision-making processes. The algorithms pose a series of questions that partition the data into subsets, and the process persists until a final decision or prediction is reached. Decision trees are visualized as hierarchical structures that resemble an inverted tree, where each node signifies a question and each branch corresponds to a possible answer. The aim is to create a model that effectively navigates through data, making informed decisions based on a systematic series of inquiries. Decision trees are widely used because they are easily interpreted and can handle both categorical and numerical data, making them a valuable tool for several domains, including finance, healthcare, and ML applications. Classification and Regression Trees (Breiman et al. 1984) presents a useful overview of decision trees.
-
Random forests (Ho 1995) comprise a combination of tree predictors such that each tree depends on random vector values sampled independently and with the same distribution for all trees in the forest (Breiman 2001). After many trees are generated, they vote for the most popular class. Instead of using the entire dataset, a sample of the dataset is used to train each of the trees, which is also the case for decision trees. Furthermore, not all variables are used for splitting the nodes. These steps ensure that the model does not overfit the data.
-
XGBoost is a highly effective and widely used ML method. Boosting grows trees sequentially by using information from previous trees, which differs from bagging methods, where bootstrapping is used. XGBoost is an optimized distributed gradient boosting (Guelman 2012) library designed for efficient and scalable training of ML models. It is an ensemble learning model that combines predictions from multiple weak models to produce a stronger prediction. XGBoost was introduced by T. Chen and Guestrin (2016) and has demonstrated success in various ML competitions in the Kaggle data science platform. To boost regression trees, we chose the number of splits to include in our tree, then created multiple trees of that size, where each new tree after the first was created by predicting the residuals of the previous tree.
-
GLM (H. Chen and Lindsey 1998; Hutcheson 2001) is a framework for extending linear regression models (Gupta et al. 2020) to handle different types of data distributions (Lu and Boritz 2005). It generalizes linear regression by incorporating a link function and a probability distribution to model a broader range of relationships.
-
Naive Bayes is a probabilistic classification algorithm rooted in Bayes’ theorem. It leverages a foundational assumption of feature independence given the class label, thereby simplifying computational processes. Widely applied in text classification, spam filtering, and categorization tasks, naive Bayes is an effective framework for making informed decisions based on probabilistic reasoning. It handles diverse datasets with efficiency, making it a preferred choice in scenarios where feature independence assumptions align with the nature of the data.
-
GBM is a boosting algorithm that constructs a sequence of weak models, strategically amalgamating them to form a robust predictive model. The optimization process involves learning from the errors of preceding models, iteratively refining accuracy over successive iterations. GBM’s iterative approach to model building enhances predictive performance by focusing on areas of misclassification, progressively refining the overall predictive capability. This algorithm is widely acknowledged for its ability to deliver high accuracy and resilience across diverse datasets, making it a valuable tool in predictive modeling and ML applications.
5. Results
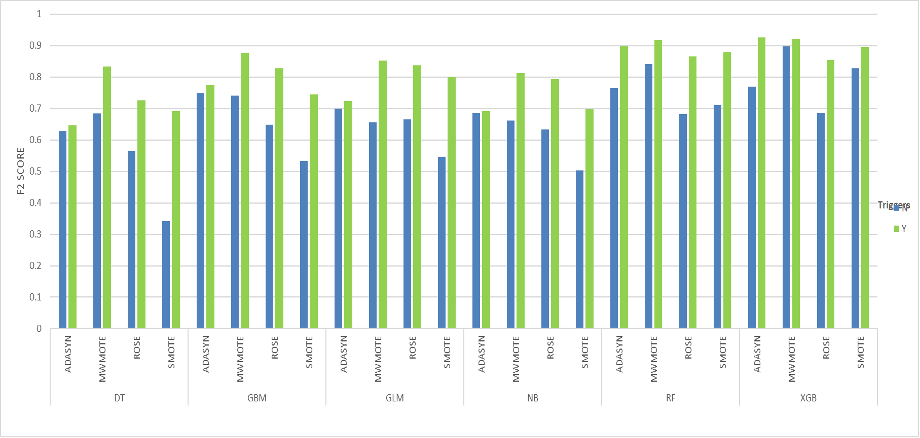
Performance of the six ML algorithms on data without triggers (N) and data with triggers (Y) is summarized in Table 5. Each algorithm was trained using the four synthetic oversampling methods discussed previously, resulting in 48 combinations.
Our primary objective was to minimize the financial damage resulting from fraudulent activities. Therefore, we aimed to increase the true positive rate and decrease the false negative rate in our classification model. While false positives may result in additional costs associated with conducting further investigations, these costs are generally less than the losses incurred due to false negatives. Since false negatives are more expensive than false positives, we used the F2 score to compare performance across models, because it prioritizes recall (true positive rate) over precision, which better captures model performance in identifying the minority class.
Table 6 shows the F2 score improvement for all model combinations. The rows in bold indicate the most improved combination for each ML model.
Based on the F2 score, the XGBoost model with ADASYN (He et al. 2008) balancing applied to the data with triggers (Y) demonstrated the highest performance, with a score of 0.9267. Overall, all models showed improved performance when applied to data with triggers, with the decision tree model with SMOTE (Chawla et al. 2002) showing the most improvement.
This finding may have resulted from including the trigger data, which provided the model with additional information, leading to better performance. Important features and information were extracted from the trigger data, which helped the model better predict fraud.
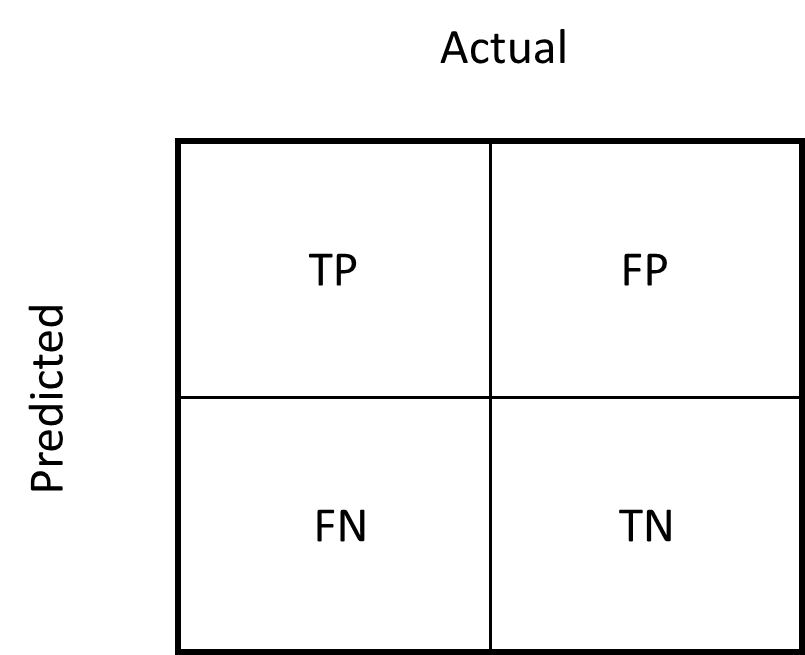
Figure 2 depicts the categories the model assigns to a claim and the related errors, where the positive class indicates fraud and the negative class indicates not fraud.
-
TP (true positive): Fraud identified as fraud by the model
-
TN (true negative): Not fraud identified as not fraud by the model
-
FP (false positive): Not fraud identified as fraud by the model
-
FN (false negative): Fraud identified as not fraud by the model
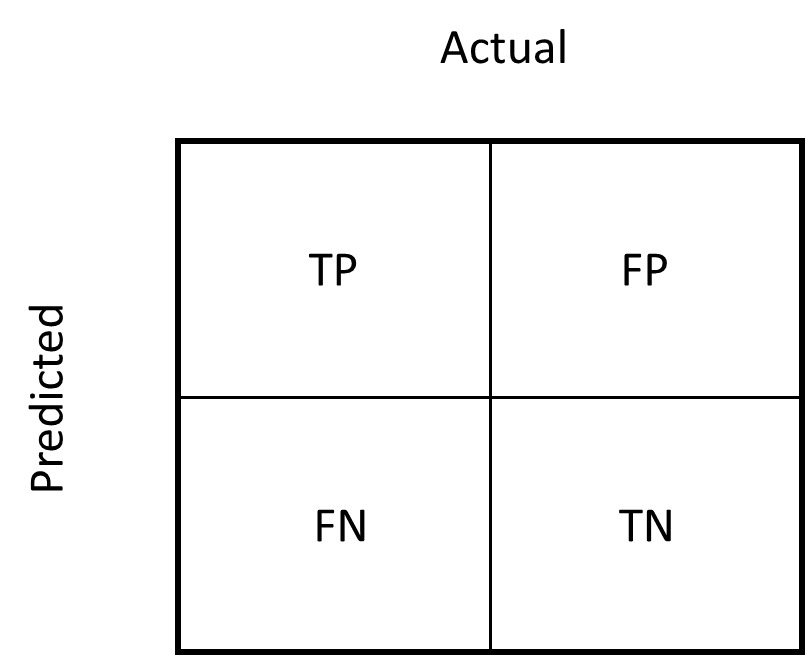
Figure 3 shows that the models run on data with triggers had improved F2 scores compared with the models run on data without triggers.

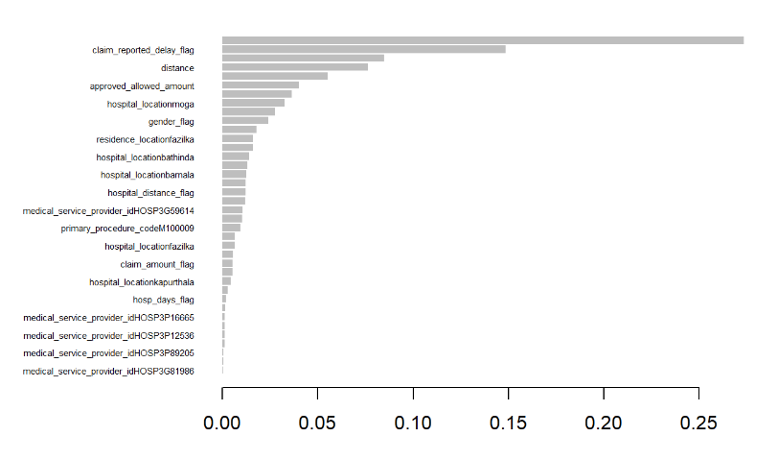
For example, for XGBoost with ADASYN (He et al. 2008) and trigger data, the claim_reported_delay_flag, distance, gender_flag, and hospital_distance_flag, which were generated from the trigger data, were all important for predicting fraudulent claims. This shows that integrating trigger functions into ML models improves model performance. In this model the F2 score increased from 0.77 to 0.93.
Figure 4 shows the results of XGBoost with ADASYN (He et al. 2008) without trigger data.

Figure 5 shows the results of XGBoost with ADASYN (He et al. 2008) with trigger data.

6. Conclusion
Our results show that including trigger data generally leads to improved model performance. However, the extent of this improvement is influenced by the model and imbalance method used. Therefore, it is crucial to select the optimal combination of model and imbalance method based on the specific requirements of the task. Additionally, the effectiveness of triggers on model improvement may also depend on the characteristics of the trigger data being used. Therefore, it is important to carefully evaluate the data before incorporating triggers. The primary objective of our project’s model was to optimize for the highest F2 score, making it the paramount criterion for selecting the XGBoost model integrated with the ADASYN (He et al. 2008) imbalance technique. Notably, the XGBoost algorithm was adept at enhancing model performance without overfitting the training data, which is another factor to consider when choosing XGBoost with ADASYN (He et al. 2008) as the optimal model.
Future studies could expand our work by
-
applying our method of integrating triggers into ML models to enhance fraud detection in other business domains,
-
investigating the interpretability of ML models to improve fraud detection,
-
performing network analyses to leverage relationship-based information for detecting organized fraud, and
-
performing fraud analysis from a healthcare provider prospective (subject to data availability).