1. Introduction
Bootstrapping has become very popular in stochastic claims reserving because of the simplicity and flexibility of the approach. One of the main reasons for this is the ease with which it can be implemented in a spreadsheet in order to obtain an approximation to the estimation error of a fitted model in a statistical context. Furthermore, it is also straightforward to extend it to obtain the approximation to the prediction error and the predictive distribution of a statistical process by including simulations from the underlying distributions. Therefore, bootstrapping is a powerful tool for the most popular subject for reserving purposes in general insurance, the prediction error of the reserve estimates. It should be emphasized that to obtain the predictive distribution, rather than just the estimation error, it is necessary to extend the bootstrap procedure by simulating the process error. It is also important to realize that bootstrapping is not a “model,” and therefore it is important to ensure that the underlying reserving models are correctly calibrated to the observed data. In this paper, we do not address the issue of model checking, but simply show how a bootstrapping procedure can be applied to the Munich chain ladder model.
In the area of non-life insurance reserving, there are primarily two types of data used. In addition to the paid claims triangle, there is frequently a triangle of incurred data also available. The traditional approach is to fit a model to either paid or incurred claims data separately, and one of the most popular methods in this context is the chain ladder technique. While we do not believe that this is the most appropriate approach for all data sets, it has retained its popularity for a number of reasons. For example, the parameters are understood in a practical context; it is flexible; and it is easy to apply. This paper concentrates on methods which have a chain ladder structure, and in this context, two types of approaches exist: deterministic methods such as chain ladder, and the recently developed stochastic chain ladder reserving models. When the chain ladder technique is used (either as a deterministic approach or using a stochastic model), one set of data will be omitted—either the paid or the incurred data can be used, but not both at the same time. Obviously, this does not make full use of all the data available and results in the loss of some information contained in those data.
This leads us to consider whether it is possible to construct a model for both data sets, and to a consideration of the dependency between the two run-off triangles. A related issue also arises when traditional methods are applied separately to each triangle, which produces inconsistent predicted ultimate losses. In response, Quarg and Mack (2004) proposed a different approach within a regression framework, considering the likely correlations between paid and incurred data. Quarg and Mack (2004) called this new method the Munich chain ladder (MCL) model. It is this model that is the subject of this paper, and we show how the predictive distribution may be estimated using bootstrapping. Thus, in this paper an adapted bootstrap approach is described, combined with simulation for two dependent data sets. The spreadsheets used in this paper can be used in practice for any data sets and are available on request from the authors.
The paper is set out as follows. Section 2 briefly describes the MCL model using a notation appropriate for this paper. In Section 3, the basic algorithm and methodology of bootstrapping is explained. Section 4 shows how to obtain the estimates of the prediction errors and the empirical predictive distribution using the adapted bootstrapping and simulation methods. In Section 5, two numerical examples are provided, including the data from Mack (1993) as well as some real London market data. Finally, Section 6 contains a discussion and conclusion.
2. The Munich chain ladder method
The MCL model aims to produce a more consistent prediction of ultimate claims when modeling both paid and incurred claim data. It is specially designed to deal with the correlation between paid and incurred claims. The traditional models, such as the chain ladder model, sometimes produce unsatisfactory results by ignoring this dependence. It should be emphasized that the paid and incurred claims from the same calendar years are not correlated. It is that the paid claims (incurred claims) are correlated with the incurred claims (paid claims) from the next (previous) calendar year.
The fundamental structure of the MCL model is the same as Mack’s distribution-free chain ladder model (Mack 1993). In other words, the chain ladder development factors in the MCL model are obtained by Mack’s distribution-free approach. However, the MCL model adjusts the chain ladder development factors using the correlations between the observed paid and incurred claims. The adjusted chain ladder development factors therefore become individual not only for different development years but also for different accident years. The adjustment is explained in more detail in Sections 2.1 and 2.2.
2.1. Notation and assumptions
For ease of notation, we assume that we have a triangle of data. Although the data could be classified in different ways, we refer to the rows as “accident years” and the columns as “development years.”
Denote as cumulative paid claims and as cumulative incurred claims occurred in accident year development year where and for the observed data. The aim of the chain ladder technique and of MCL is to estimate the data up to development year This produces estimates for and where and and we thereforerefer to the complete rectangle of data in the assumptions:
Mack’s distribution-free chain ladder method models the pattern of the development factors, which are defined as for paid claims and for incurred claims. Also the ratios of paid divided by incurred claims and the inverse are introduced as and respectively.
Furthermore, define the observed data for accident year up to development year as and for paid claims, incurred claims and both, respectively.
The following assumptions are taken from Quarg and Mack (2004), Section 2.1.2.
Assumption A (Expectations)
(A1) For there exists a constant such that (for )
E[FPij∣Pi(j)]=fPj.
This assumption is for paid claims. It is necessary to make another analogous assumption for incurred claims since both data sets are taken into account.
(A2) For there exists a constant such that (for )
E[FIij∣Ii(j)]=fIj.
In order to analyze the two run-off triangles dependently, the following assumptions are also required.
(A3) For there exists a constant such that (for )
E[Q−1ij∣Pi(j)]=q−1j.
(A4) For there exists a constant such that (for )
E[Qij∣Ii(j)]=qj.
Note that assumptions (A3) and (A4) will apply that imply that is constant, which is con-tradictory-see Section 3.1.2 of Quarg and Mack (2004) for a discussion of this point.
Assumption B (Variances)
(B1) For there exists a constant such that (for )
Var[FPij∣Pi(j)]=(σPj)2CPij.
Again, the analogous assumption for the incurred claims is made as follows.
(B2) For there exists a constant such that (for )
Var[FIij∣Ii(j)]=(σIj)2CIij.
Also, for the ratios of incurred to paid and vice versa, the following variance assumptions are made.
(B3) For there exists a constant such that (for )
Var[Q−1ij∣Pi(j)]=(τPj)2CPij.
(B4) For there exists a constant such that for
Var[Qij∣Ii(j)]=(τIj)2CIij.
Assumption C (Independence)
Assumption (Independence) The usual assumptions for individual triangles are as follows:
(C1) The random variables pertaining to different accident years for paid claims, i.e., are stochastically independent.
(C2) The random variables pertaining to different accident years for incurred claims, i.e., are stochastically independent.
In fact, a stronger assumption is used (see Section 3.2 of Quarg and Mack 2004), which is independence of accident years across both paid and incurred claims:
(C3) The random sets are stochastically independent.
Using assumptions A to C, the Pearson residuals used in the MCL model can be defined as shown in Equations (2.1) to (2.4). These residuals are a crucial part of the bootstrapping procedures described in Section 4.
rPij=FPij−E[FPij∣Pi(j)]√Var[FPij∣Pi(j)],
rQ−1ij=Q−1ij−E[Q−1ij∣Pi(j)]√Var[Q−1ij∣Pi(j)],
rIij=FIij−E[FIij∣Ii(j)]√Var[FIij∣Ii(j)],
rQij=Qij−E[Qij∣Ii(j)]√Var[Qij∣Ii(j)].
Assumption D (Correlations)
(D1) There exists a constant such that (for )
E[rPij∣Bi(j)]=ρPrQ−1ij.
The following equation states that the constant is in fact the correlation coefficient between the residuals. Note that since the residuals have variance 1 , the correlation is equal to the covariance. The proof can be found in Quarg and Mack (2004).
Cov[rPij,rQ−1ij∣Pi(j)]=Corr[rPij,rQ−1ij∣Pi(j)]=Corr[FPij,Q−1ij∣Pi(j)]=ρP
Quarg and Mack (2004) derives expected MCL paid development factors adjusted by the correlation as shown in Equation (2.7).
E[FPij∣Bi(j)]=E[FPij∣Pi(j)]+√Var[FPij∣Pi(j)]Var[Q−1ij∣Pi(j)]×Corr[FPij,Q−1ij∣Bi(j)](Q−1ij−E[Q−1ij∣Pi(j)]).
(D2) Analogous to assumption (D1), for the incurred claims it is assumed that there exists a constant such that (for )
E[rIij∣Bi(j)]=ρIrQij.
Similarly, the constant measures the correlation coefficient or the covariance between the residuals. i.e.,
Cov[rIij,rQij∣Bi(j)]=Corr[rIij,rQij∣Bi(j)]=Corr[FIij,Qij∣Bi(j)]=ρI
Hence, the expected MCL incurred development factors adjusted by the correlation can be derived as follows:
E[FIij∣Bi(j)]=E[FIij∣Ii(j)]+√Var[FIij∣Ii(j)]Var[Qij∣Ii(j)]×Cov[FIij,Qij∣Bi(j)](Qij−E[Qij∣Ii(j)]).
2.2. Unbiased estimates of the parameters
In this section, we summarize the unbiased estimates of the parameters derived by Quarg and Mack (2004). For the paid data, estimates are required for the parameters of the development factors, the variances and also the correlation coefficient.
The estimates of the paid development factor parameters can be interpreted as weighted averages of the observed development factors or using as the weights
ˆfPj=∑n−ji=1CPi,j+1∑n−ji=1CPij=n−j∑i=1CPij∑n−ji=1CPijFPij
and
ˆq−1j=∑n−j+1i=1CIij∑n−j+1i=1CPij=n−j+1∑i=1CPij∑n−j+1i=1CPijQ−1ij.
The unbiased estimates of the variances are as follows:
(ˆσPj)2=1n−j−1n−j∑i=1CPij(FPij−ˆfPj)2
and
(ˆτPj)2=1n−jn−j+1∑i=1CPij(Q−1ij−ˆq−1j)2
Hence the Pearson residuals are
rPij=FPij−ˆfPjˆσPj√CPij
and
rQ−1ij=Q−1ij−ˆq−1jˆτPj√CPij.
Finally, the estimate of the correlation coefficient is given in Equation (2.17).
ˆρP=∑i,jrQ−1ijrPij∑i,j(rQ−1ij)2.
Similarly, for incurred data, the estimates of the development factor parameters can be interpreted as weighted averages of the development factors or using as the weights:
ˆfIj=∑n−ji=1CIi,j+1∑n−ji=1CIij=n−j∑i=1CIij∑n−ji=1CIijFIij
and
ˆqj=∑n−j+1i=1CPij∑n−j+1i=1CIij=n−j+1∑i=1CIij∑n−j+1i=1CIijQij.
Also, the unbiased estimates for the variance parameters are as follows:
(ˆσIj)2=1n−j−1n−j∑i=1CIij(FIij−ˆfIj)2.
and
(ˆτIj)2=1n−jn−j+1∑i=1CIij(Qij−ˆqj)2.
Hence the Pearson residuals are
rIij=FIij−ˆfIjˆσIj√CIij
and
rQij=Qij−ˆqjˆτIj√CIij.
And finally, the estimate of the correlation coefficient is given in Equation (2.24).
ˆρI=∑i,jrQijrIij∑i,j(rQij)2.
Assumptions A in Section 2.1 have defined the expectations of the development factors, given just the data in the respective triangles. In order to produce a single estimate based on the data from both paid and incurred data, Quarg and Mack (2004) also considers the expectations of the development factors given both triangles, and defines and Using plug-in estimates from Equations (2.11) to (2.17), the estimates of the paid MCL development factors are calculated using Equation (2.7):
ˆλPij=ˆfPj+ˆρPˆσPjˆτPj(Q−1ij−ˆq−1j).
Similarly, plug-in estimates from Equations (2.18) to (2.24) are used in Equation (2.10) so that the estimates of the incurred development factors are
ˆλIij=ˆfIj+ˆρIˆσIjˆτIj(Qij−ˆqj).
3. Bootstrapping and claims reserving
Bootstrapping is a simulation-based approach to statistical inference. It is a method for producing sampling distributions for statistical quantities of interest by generating pseudo samples, which are obtained by randomly drawing, with replacement, from observed data. It should be emphasized that bootstrapping is a method rather than a model. Bootstrapping is useful only when the underlying model is correctly fitted to the data, and bootstrapping is applied to data which are required to be independent and identically distributed. The bootstrapping method was first introduced by Efron (1979) and a good introduction to the algorithm can be found in Efron and Tibshirani (1993).
For the purpose of clarity we begin by giving a general bootstrapping algorithm and briefly reviewing previous applications of bootstrapping to claims reserving. In Section 4., we show how an algorithm of this type can be applied to the MCL. Suppose we have a sample and we require the distribution of a statistic θ̂. The following three steps comprise the simplest bootstrapping process:
- Draw a bootstrap sample from the observed data
- Calculate the statistic of interest for the first bootstrap sample
- Repeat steps 1 and times.
By repeating steps 1 and times, we obtain a sample of the unknown statistic calculated from pseudo samples, i.e., When the empirical distribution constructed from can be taken as the approximation to the distribution for the statistic of interest Hence all the quantities of the statistic of interest can be obtained, since such a distribution contains all the information related to
The above bootstrapping algorithm can be applied to the prediction distributions for the best estimates in stochastic claims reserving. England and Verrall (2007) contains an excellent review of the application. In addition, Lowe (1994), England and Verrall (1999), and Pinheiro, Andrade e Silva, and Centeno (2003) are also good resources for more details. England and Verrall (2007) showed how bootstrapping can be used for recursive models, following from the earlier papers (England and Verrall 1999; England 2002) which applied bootstrapping to the overdispersed Poisson model.
It should be noted here that the Pearson residuals are commonly used rather than the original data in the generalized linear model (GLM) framework. The Pearson residuals are required in order to scale the response variables in the GLM so that they are identically distributed. This is necessary because the bootstrap algorithm requires that the response variables are independent and identically distributed.
Other papers in the actuarial literature that consider triangles of dependent data include Taylor and McGuire (2007) and Kirschner, Kerley, and Isaacs (2008). It should be noted here that a model taking account of all information available could be very valuable, even when the data is dependent in practice. The dependence makes it difficult to calculate the prediction error theoretically. For these reasons, we believe that adopting bootstrap method for these models is worthy of investigation, particularly in order to obtain the predictive distribution of the estimates of outstanding liabilities.
4. Bootstrapping the Munich chain ladder model
This section considers bootstrapping the MCL model. In Section 4.1 we describe the methodology and in Section 4.2 we give the algorithm that is used.
4.1. Methodology
The method of bootstrapping stochastic chain ladder models can be seen in a number of different contexts. England and Verrall (2007) categorize the models as recursive and nonrecursive and show how bootstrapping methods can be applied in either case. Since we are dealing with recursive models here, we follow England and Verrall and consider the observed development link ratios rather than the claims data themselves. In other words, for Mack’s distributionfree chain ladder model the link ratios are randomly drawn against noting that
E[Fij∣Xij]=E[Xi,j+1Xij|Xij]=fj.
Here, is used to represent observed claims data in general. Note that the bootstrap estimates of the development factors which are obtained by taking weighted averages of the bootstrapped observed link ratios use rather than as the weights.
However, this method cannot be simply extended to the MCL method, since this model is designed for dealing with two sets of correlated data, the paid and incurred claims. This means that it is not possible to use the normal bootstrap approach because the independence assumption cannot be met.
In order to address the problem of how to adapt the existing bootstrap approach in order to cope with the MCL method for dependent data sets, the consideration of the correlation is crucial. It should be noted that the correlation which is observed in the data represents real dependence between the paid and incurred claims, and the model is specifically designed for this dependence. Therefore, it should remain unchanged within any resampling procedure. The straightforward solution is to draw samples pairwise so that the correlation between the two dependent original data sets will not be broken when generating a sampling distribution for a statistic of interest.
Obviously, when bootstrapping the recursive MCL method, the residuals of the paid and incurred link ratios are required instead of the raw data. The question arises of how to deal with these residuals in order to meet the requirement of not breaking the observed dependence between paid and incurred claims. The answer is to group all four sets of residuals calculated in the MCL method, i.e., the paid and incurred development link ratios, the ratios of incurred over paid claims from the previous years, and its inverse, individually. There are two reasons for this. First, the paid claims (incurred claims) are correlated to the incurred to the paid claims ratio (paid to incurred claims ratio) from the previous year, and doing this will preserve the required dependence. Second, the correlation coefficient of paid and incurred claims is equal to the correlation coefficient of those residuals, as stated in Equations (2.6) and (2.10).
Thus, in the case of the paid claims data, the triangles (which have the same dimensions) containing the residuals of the observed paid link ratios and the residuals of the ratios of incurred over paid (except the first column), are paired together. The same procedure is used for the incurred claims data. We do this for convenience, even though the ratios of the paid over incurred claims and the inverse give the same information. Note that these ratios should remain unchanged when pairing them with paid and incurred claims with the same dimensions. The consequence of this is that all four sets of residuals for paid, incurred link ratios and the ratios of incurred over paid claims and the inverse are all grouped together. (Note here that an alternative approach would be to group three sets of residuals: the residuals of the paid and incurred link ratios and either the residuals of the paid over incurred ratios or the inverse. This would produce the same results as grouping four sets of residuals, as the residuals of paid over incurred ratios and the inverse can always be calculated from each other. However, it is simpler to group the four sets, as the calculation of the fourth set of residuals is naturally skipped in this case.)
This combines the four residuals triangles into one new triangle that consists of these grouped residuals and we name it as the grouped residual triangle. In each unit from this triangle of quadruples, the residuals are from the same accident and development year and correspond to paid and incurred claims. Therefore, the new triangle of quadruples contains all the information available and meanwhile maintains the observed dependence.
When applying bootstrapping, this triangle is considered as the observed sample. The new generated pseudo samples are obtained by random drawing, with replacement, from the triangle of quadruples.
The resampled incurred and paid triangles can be obtained by separating the pairs in the pseudo sample generated as above and backing out the residual definition. The MCL approach can then be applied to calculate all the statistics of interest for the resampled paid and incurred triangles, i.e., the correlation coefficient for paid and incurred, the paid and incurred development factors, the ratios of paid over incurred or the inverse, and the variances. Finally, adjusting the paid and incurred development factors by the correlation coefficient using the MCL approach, the bootstrapped MCL reserve estimates are obtained. This completes a single bootstrap iteration.
Again, the bootstrap method provides only the estimation error of the MCL method. In order to include the prediction error and estimate the predictive distribution for the MCL estimates of outstanding liabilities, an additional step is added at the end of each bootstrap iteration, which is to add the process variance to the estimation error.
Note that we apply the final simulation for the process variance to paid and incurred claims independently. This is because, for a particular accident and development year, paid and incurred claims are actually independent. Under the assumptions of the MCL model, paid (incurred) claims are only correlated with previous incurred (paid) claims, and the forecasts produced by the bootstrapping will pick up this dependency.
In order to obtain a reasonable approximation to the predictive distribution, at least 1000 pseudo samples are required. For each of the pseudo samples, the row totals and overall total of outstanding liabilities are stored so that the sample means, sample variances, and the empirical distributions can be calculated and plotted. They are taken as the approximations to the best estimates of outstanding liabilities, the prediction errors, and the predictive distributions of the outstanding liabilities. Also, an estimate of any required percentile and confidence interval can be calculated from the predictive distribution.
In order to satisfy the assumption that the sample is identically distributed in the bootstrapping procedure, the Pearson residuals are calculated and used. As in England and Verrall (2007), we use the Pearson residuals of the observed development factors rather than those for the actual claims, since we are using recursive models. Note that a bootstrap bias correction is also needed, and the simplest way to do this is to multiply the residuals by
In addition to drawing the grouped sample for bootstrapping correlated data sets, there are also two other practical points that should be mentioned. The first is to note that the fitted values are obtained by starting from the final diagonal in each triangle and working backwards, by dividing by the development factors. The second is that the zero residuals which appear in both triangles are also left out.
4.2. Algorithm
This section provides the algorithm, step by step, which is needed in order to implement the bootstrap process introduced in Section 4.1.
-
Apply the MCL method to both the cumulative paid and incurred claims data to obtain the residuals for all four sets of ratios: the paid, incurred link ratios, the paid over incurred ratios, and the reverse. They can be obtained from following equations:
rPij=FPij−ˆfPjˆσPj√CPij,rQ−1ij=Q−1ij−ˆq−1jˆτPj√CPij,rIij=FIij−ˆfIjˆσIj√CIij and rQij=Qij−ˆqjˆτIj√CIij
-
Adjust the Pearson residual estimates by multiplying by to correct the bootstrap bias.
-
Group all four residuals together, i.e., and We write this as
-
Start the iterative loop to be repeated N times (N ≥ 1000). This consists of the following steps:
-
Randomly sample from the grouped residuals with replacement, denoted as from the grouped triangle so that a pseudo sample of the grouped residuals is created.
-
Calculate the pseudo samples of the four triangles for the paid, incurred link ratios, the ratios of paid over incurred, and the inverse by inverting the Pearson residuals definition as follows:
(FPij)B=(rPij)BˆσPj√CPi,j+ˆfPj,(Q−1ij)B=(rQ−1ij)BˆτPj√CPi,j+ˆq−1j,
and
(FIij)B=(rIij)BˆσIj√CIi,j+ˆfIj,(Qij)B=(rQij)BˆτIj√CIi,j+ˆqj.
-
Calculate the -weighted and weighted average of the bootstrap paid andincurred development factors as follows:
(ˆfPj)B=n−j∑i=1CPi,j∑n−ji=1CPi,j(FPij)B,(ˆq−1j)B=n−j+1∑i=1CPij∑n−j+1i=1CPij(Q−1ij)B
and
(ˆfIj)B=∑n−ji=1CIi,j∑n−ji=1CIi,j(FIij)B,(ˆqj)B=∑n−j+1i=1CIij∑n−j+1i=1CIij(Qij)B.
Note that the weights used here are from the original data sets and not from the pseudo samples.
-
Calculate the corresponding correlation coefficient for the resampled data using the pseudo residuals and as follows,
(ˆρP)B=∑i,j(rQ−1ij)B(rPij)B∑i,j((rQ−1ij)B)2 and (ˆρI)B=∑i,j(rQij)B(rIij)B∑i,j((rQij)B)2.
-
Calculate the variances for the bootstrap data as follows:
((ˆσPj)2)B=1n−j−1∑n−ji=1CPij((FPij)B−(ˆfPj)B)2((ˆτPj)2)B=1n−j−1∑n−ji=1CPij((Q−1ij)B−(ˆq−1j)B)2((ˆσIj)2)B=1n−j−1∑n−ji=1CIij((FIij)B−(ˆfIj)B)2((ˆτIj)2)B=1n−j−1∑n−ji=1CIij((Qij)B−(ˆqj)B)2.
Note that all the sums here are from 1 to n – j because the last diagonals of paid to incurred (and incurred to paid) are not included in the resampling procedure.
-
Calculate the bootstrap development factors adjusted by the correlation coefficient between the pseudo samples as follows:
(ˆλPij)B=(ˆfPj)B+(ˆρP)B(ˆσPj)B(ˆτPj)B((Q−1ij)B−(ˆq−1j)B)
and
(ˆλIij)B=(ˆfIj)B+(ˆρI)B(ˆσIj)B(ˆτIj)B((Qij)B−(ˆqj)B),
for the resampled bootstrap paid and incurred run-off triangles, respectively.
-
Simulate a future payment for each cell in the lower triangle for both paid and incurred claims, from the process distribution with the mean and variance calculated from the previous step. To do this, the following steps are required:
-
For the one-step-ahead predictions from the leading diagonal, a normal distribution is assumed, i.e., for 2 ≤ i ≤ n,
XPi,n−i+2∼Normal((ˆλPi,n−i+1)BXPi,n−i+1,((ˆσPn−i+1)2)BXPi,n−i+1)
for paid claims, and
XIi,n−i+2∼Normal((ˆλIi,n−i+1)BXIi,n−i+1,((ˆσIn−i+1)2)BXIi,n−i+1)
for incurred claims.
-
For the two-step-ahead predictions up to the n-step-ahead predictions, normal distributions are still assumed, but with the mean and variance calculated from previous predictions instead of from the observed data, i.e., for 3 ≤ k ≤ n and n − k +3 ≤ j ≤ n,
XPkl∼Normal((ˆλPi,l−1)BˆXPk,l−1,((ˆσPl−1)2)BˆXPk,l−1)
for paid claims, and
XIkl∼Normal((ˆλIi,l−1)BˆCIk,l−1,((ˆσIl−1)2)BˆXIk,l−1)
for incurred claims.
-
-
Sum the simulated payments in the future triangle by origin year and overall to give the origin year and total reserve estimates respectively.
-
Store the results, and return to the start of the iterative loop.
-
5. Examples
This section illustrates the bootstrapping approach to the MCL and uses two numerical examples to assess the results. The first example uses the data from Quarg and Mack (2004). Example 2 uses market data from Lloyd’s which have been scaled for confidentiality reasons. These data relate to aggregated paid and incurred claims for two Lloyd’s syndicates, categorized at risk level.
Example 1 is included in order to illustrate the results for the original set of data used by Quarg and Mack (2004). The purpose of example 2 is to illustrate that the MCL model does not necessarily provide better results in all situations. Our results indicate that it performs better when the data have less inherent variability and are less “jumpy.”
Example 1. In this section, we apply the bootstrapping methodology with 10,000 bootstrap simulations to the data from Quarg and Mack (2004).
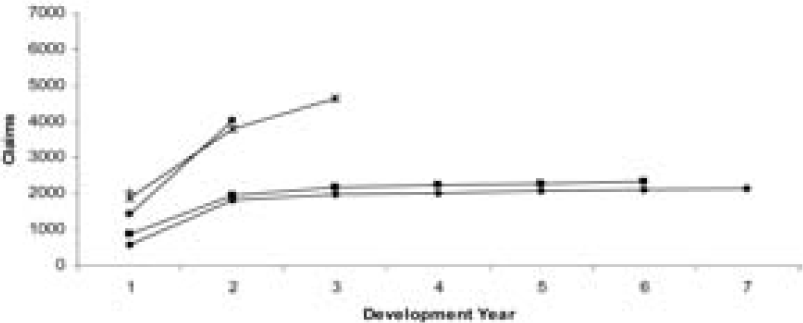
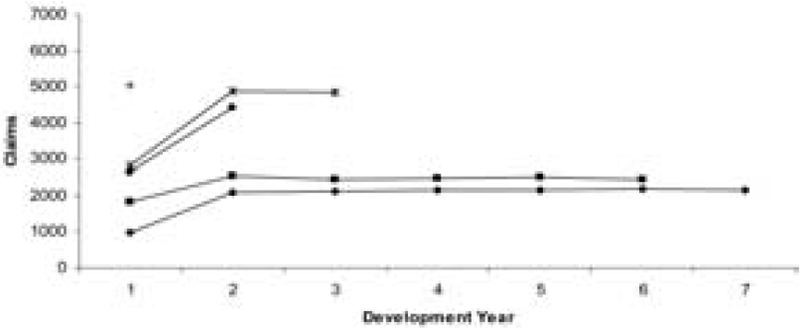
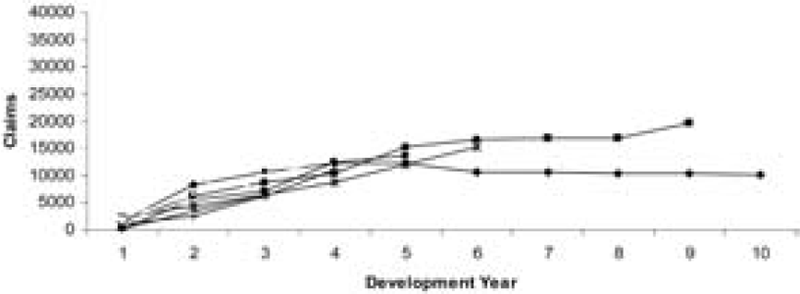
Tables 1 and 2 show the data. In order to illustrate the nature of the run-off of the data, Figures 1 and 2 are the plots of the data from Tables 1 and 2, respectively. From Figures 1 and 2, it can be seen that the data are stable and not excessively spread out.
The results of applying the bootstrap methodology described in this paper are shown below and are compared with the results from the straightforward chain ladder technique (noted as CL) and Mack’s method for the prediction errors. Table 3 shows that the theoretical MCL reserves (from Quarg and Mack 2004) and the mean of the bootstrap distributions, together with the chain ladder reserves when the triangles are considered separately. It can be seen that the bootstrap means are close to the theoretical values, for both the paid and incurred claims.
Table 4 displays the bootstrap prediction error of the MCL reserves projected by both paid and incurred claims. Also shown are the prediction errors for the Mack method. It can be seen that the MCL prediction errors are lower than those of the Mack method.
Since the purpose of the MCL method is to use more data to improve the estimation of the reserves, it is expected that the prediction errors should be lower than the Mack model. This is confirmed for these data by Table 5, which shows that the prediction error, as a percentage of the reserve, is lower for the MCL reserves than the prediction error of the reserves from the Mack model.
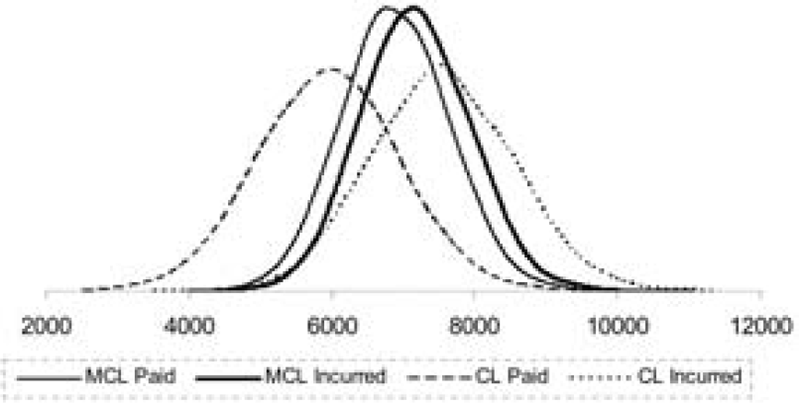
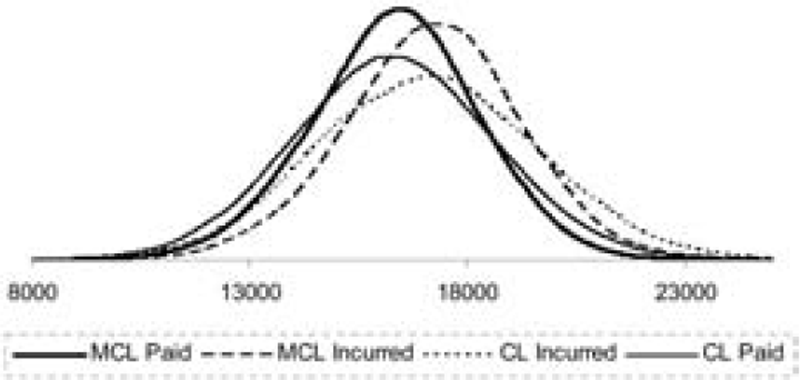
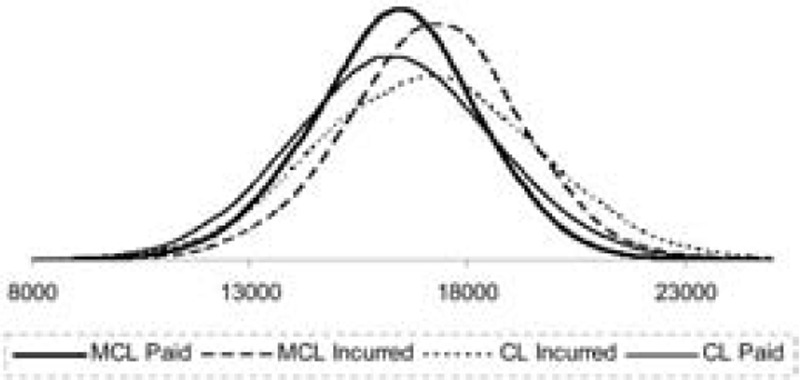
In Figure 3, the distributions of the MCL and CL reserve projections for paid and incurred claims are plotted. Figure 3 shows that the paid and incurred best reserve estimates are very close when using the MCL approach. In contrast, the paid and incurred best reserve estimates projected by the chain ladder method are much further apart. Furthermore, the CL method provides a much more spread-out distribution than the MCL approach, in the case of both paid and incurred claims.

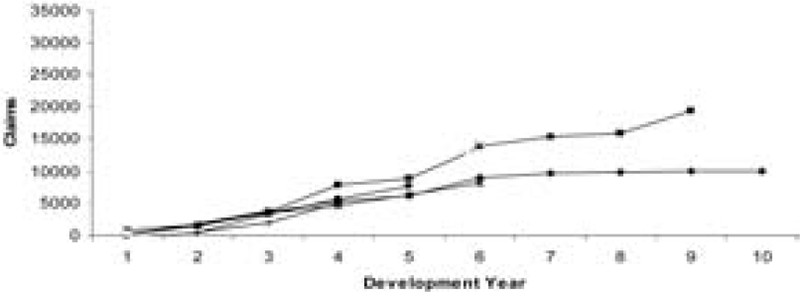
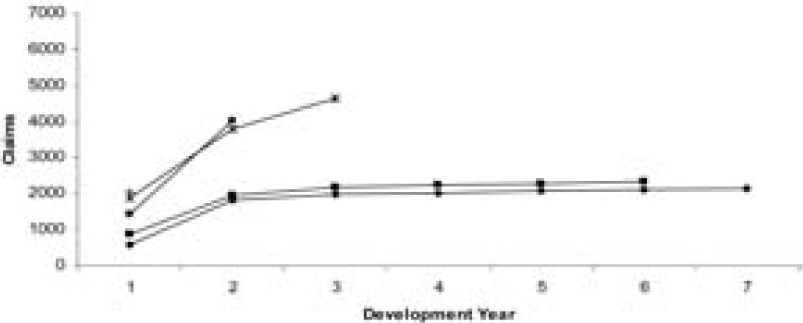
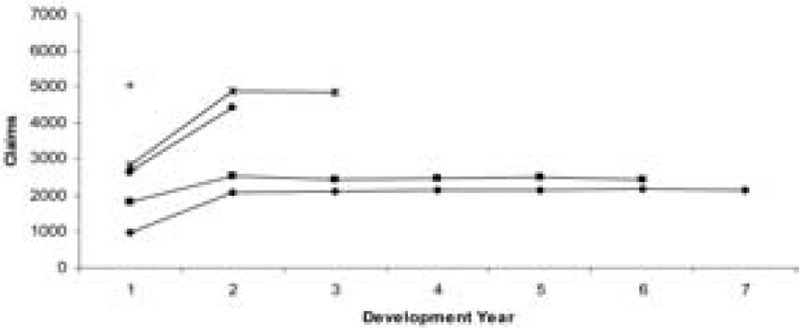
Example 2. In this section, a set of aggregate data from Lloyd’s syndicates is considered. In this case, the data are not as stable or well behaved and the results are quite different. Tables 6 and 7 show the data, which are plotted in Figures 4 and 5. It can be seen from these figures that the data are much more unstable and more spread out compared with the previous two examples.

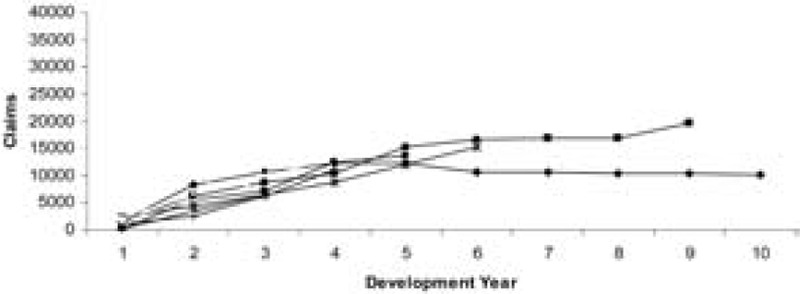
The MCL method still produces consistent ultimate loss predictions for this data set, as shown in Table 8. However, the prediction error contained in Table 9, estimated by the bootstrap MCL approach, appears not to offer such an improvement as was seen in Example 1.
Table 10 shows a comparison of the prediction errors as a percentage of the reserve, and again it can be seen that the results do not indicate that the MCL method is a significant improvement over the CL model. The conclusion from this is that although the MCL method uses more data, and should be expected to produce lower prediction errors, this is not always the case in practice. We believe that the reason for this is that the assumptions made by the MCL method—the specific dependencies assumed—are not as strong as expected in this case. A conclusion from this is that the data have to be examined carefully before the MCL method is applied.
This conclusion is reinforced by Figure 6, which shows the predictive distributions.
6. Conclusion
This paper has shown how a bootstrapping approach can be used to estimate the predictive distribution of outstanding claims for the MCL model. The model deals with two dependent data sets, the paid and incurred claims triangles, for general insurance reserving purposes. We believe that bootstrapping is well suited for these purposes from a practical point of view, since it avoids complicated theoretical calculations and is easily implemented in a simple spreadsheet. This paper adapts the method by taking account of the dependence observed in the data and resampling pairwise.
A number of examples have been given, which show that the MCL model does not always produce superior results to the straightforward CL model. As a consequence, we believe that it is important for the data to be carefully checked to test whether the dependency assumptions of the MCL model are valid for each data set before it is applied.
Acknowledgment
Funding for this project from Lloyd’s of London is gratefully acknowledged.