
1. Introduction
Aggregate claim distributions have been widely discussed in the actuarial literature. For example, see Heckman and Meyers (1983), Teugels (1985), Pentikäinen (1987), Papush, Patrik, and Podgaits (2001), Hardy (2004), and Reijnen, Albers, and Kallenberg (2005). In the context of insurance theory, the aggregate claims can be viewed as a sum of individual claim amounts for a random number of claim counts over a fixed time-period. In other words, it can be represented as a sum of individual claim amounts for a random number of claim counts over a fixed time-period. In other words, it can be represented as a sum (S) of individual claim amounts where is the random number of claim counts over a fixed time period. Conditional on the random variables are assumed to be positive, mutually independent, and identically distributed. It is also assumed that the common distribution of ’s is independent of One can easily write the cumulative distribution function (c. d.f) of aggregate claims random variable (S) as
CFs(x)=P(S≤x)=∞∑n=0P(N=n)P(X1+X2+…+XN≤x∣N=n).
The computation of this compound distribution function or corresponding tail probability or probability density function is generally quite cumbersome. For most combinations of distributions of N and the Xi’s, the exact distribution of S is not available analytically, but the above distributional values may be obtained numerically. For discrete severity distributions, one often uses the well-known recursive method introduced by Panjer (1981) to evaluate the aggregate claims distribution. For exponential severities, simple analytical results for exact probabilities can easily be obtained (Klugman, Panjer, and Willmot 2012). For other cases, the computation in (1.1) requires tedious numerical integrations. In this situation, one often prefers to use an approximate distribution to avoid the computational complexity of distributional values. Several approximations have been developed and studied by many authors in the actuarial literature. Here, we have considered only four of them, which are NP2, gamma, IG, and gamma-IG mixture approximations. The NP2 approximation provided by Pesonen (1969) and the gamma approximation introduced by Bohman and Esscher (1963) are well known to the actuarial community. Chaubey, Garrido, and Trudeau (1998) introduced IG and gamma-IG mixture approximations to aggregate claims distribution. They compared these approximations with NP2 and gamma approximations for some choices of the distributions of claim counts and claim sizes. The authors stated that the gamma-IG mixture approximation uniformly improves the accuracy, especially in the tails. However, this approximation requires numerical evaluation of incomplete gamma functions. Seri and Choirat (2015) have studied a number of approximations for compound Poisson processes only and discussed their findings. Alhejaili and Abd-Elfattah (2013) discussed the saddlepoint approximation, introduced by Lugannani and Rice (1980), for some stopped-sum distributions and noted that the approximation shows a great accuracy compared to exact distribution. Recently, Thiagarajah (2017) has studied extensively the saddlepoint approximation to the tail probabilities of aggregate claims for various combinations of claim counts and claim severity distributions. The author has compared the approximate tail probabilities with the exact probabilities and concluded that the accuracy of this approximation is quite good in all applications considered in the paper.
The paper is organized as follows: In Section 2 we present a brief description of five of the above approximations to the cumulative distribution function of aggregate claims. In Section 3, we compare the accuracy of these approximations numerically in terms of relative errors for various combinations of claim count and claim size distributions. The relative error is computed as (approximate probability − exact probability)/exact probability. If the exact probabilities are not available analytically, we obtain them through simulations. In that case, we first generate a random number N from a claim count distribution, and then generate N random values from a claim size distribution. The aggregate claim amount (S) is taken as the sum of those N values. Each probability is based on 100,000 replications. The final section contains the conclusion.
2. Approximations
In this section, we provide five approximations for the distribution of the aggregate claims. We need mean, variance, skewness, or kurtosis of the aggregate claims distribution for these approximation methods. These quantities can easily be obtained from the cumulant generating function, which is the natural logarithm of the moment generating function. Let us denote the cumulant generating function (c.g.f) of as Then, we can write the mean the variance the third central moment and the fourth central moment Now, we express the skewness as and the kurtosis as
2.1. NP2 approximation
Using the well-known central limit theorem, one can approximate the aggregate claims distribution by a normal distribution. This method works only for a large volume of risks. Pesonen (1969) provided the following expression, which is called normal power (NP2) approximation, as an adjustment to the normal approximation:
CF(x)≈Φ[√1+9γ2s+6Zγs−3γs],
where and γS is the skewness of S. The μS and σS are the mean and the standard deviation of S. Pentikäinen (1977) claims that this approximation method gives very satisfactory results, provided that the skewness of the distribution of interest is very small.
2.2. Gamma approximation
Bohman and Esscher (1963) discussed this approximation, which is based on incomplete gamma function. Here, the aggregate claims distribution is approximated by a simple gamma distribution. An improvement to the simple gamma distribution is referred to as the gamma approximation, which is given in (2.2).
CF(x)≈1Γ(α)∫α+Z√α0e−yya−1dy,
where and . Seal (1977) commented that the NP2 method should be abandoned in favor of this gamma approximation. Gendron and Crépeau (1989) claimed that this approximation provides satisfactory results when the claim size distribution is inverse Gaussian. Pentikäinen (1977) stated that both NP2 and gamma approximations provide similar outcomes, and both are acceptable approximations when the skewness of the aggregate claims distribution is less than two.
2.3. IG approximation
Chaubey, Garrido, and Trudeau (1998) proposed this approximation, which was developed by matching the moments, as in the previous two methods. They approximated the random variable S by a shifted IG(m, b) distribution by matching the first three central moments. This means
CF(x)≈Gm,b(x−x0),
where G is the cumulative probability of the shifted IG distribution. The parameters m and b can be written as and x0 = CS(1)(0) − m. The authors claim that the approximation is almost as good as the gamma approximation.
2.4. Gamma-IG mixture approximation
Chaubey, Garrido, and Trudeau (1998) also introduced this approximation as a weighted average of gamma and IG approximations. The approximation was given as
CF(x)≈wCF1(x)+(1−w)CF2(x),
where and κ stands for kurtosis. This is an improvement of the accuracy of both gamma and IG approximations.
2.5. Saddlepoint approximation
Lugannani and Rice (1980) introduced a method based on the saddlepoint technique, which can be applied to continuous and discrete distributions. It is a simple and accurate approximation for distribution function, which avoids any integration. For continuous severity distributions of Xi’s, the saddlepoint approximation to the cumulative distribution function of S can be written as
CF(x)≈{Φ(ˆω)+ϕ(ˆω){1ˆω−1ˆu},x≠μ12+C(3)S(0)6√2π(C(2)S(0))3,x=μ
where and are the respective cumulative distribution function and the probability density function of a standard normal random variable, is the mean of the distribution, and The saddlepoint is the unique solution to the equation For more mathematical details of this approximation, we refer the readers to Lugannani and Rice (1980) and Daniels (1987).
3. Some compound distributions
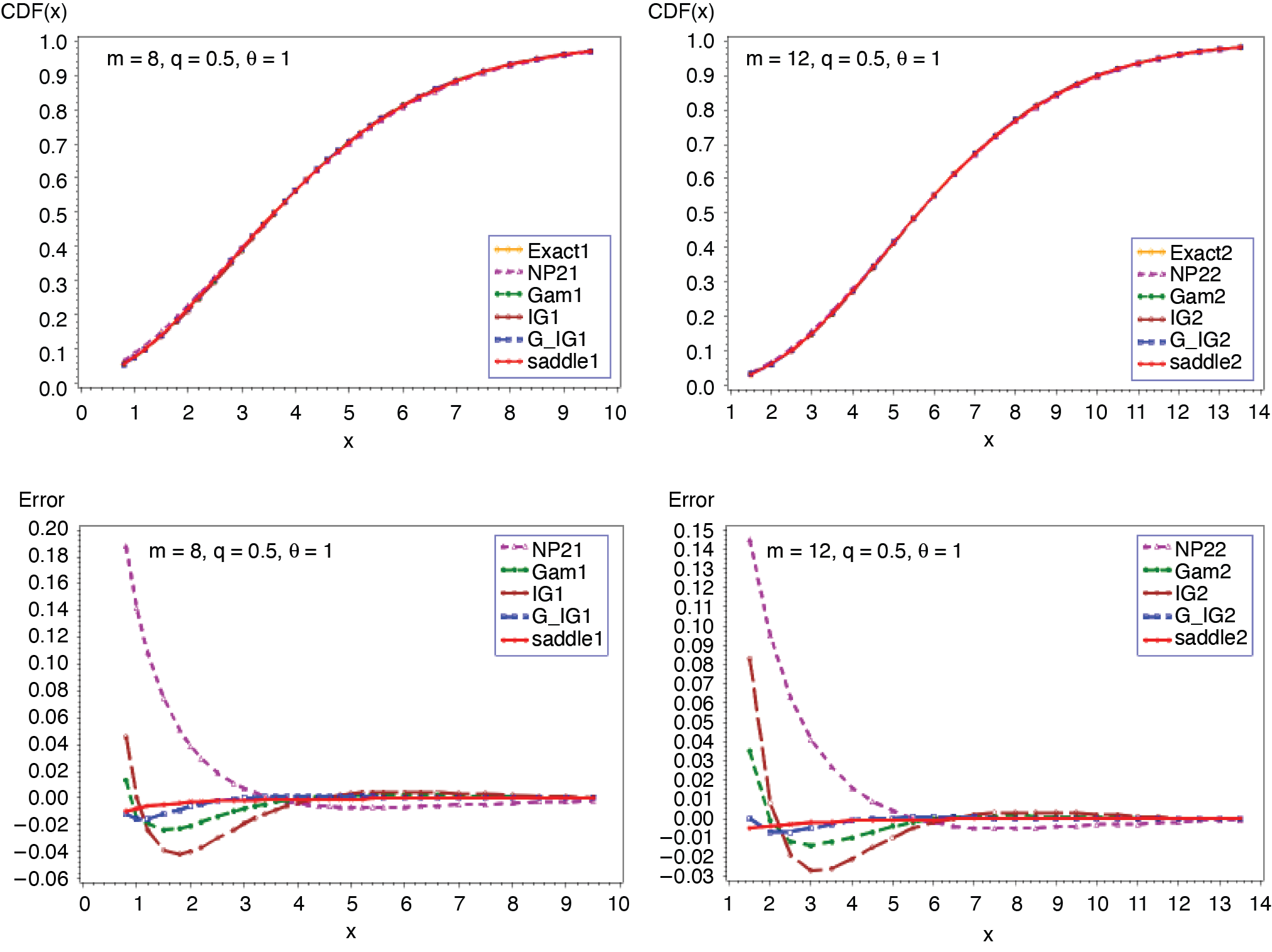
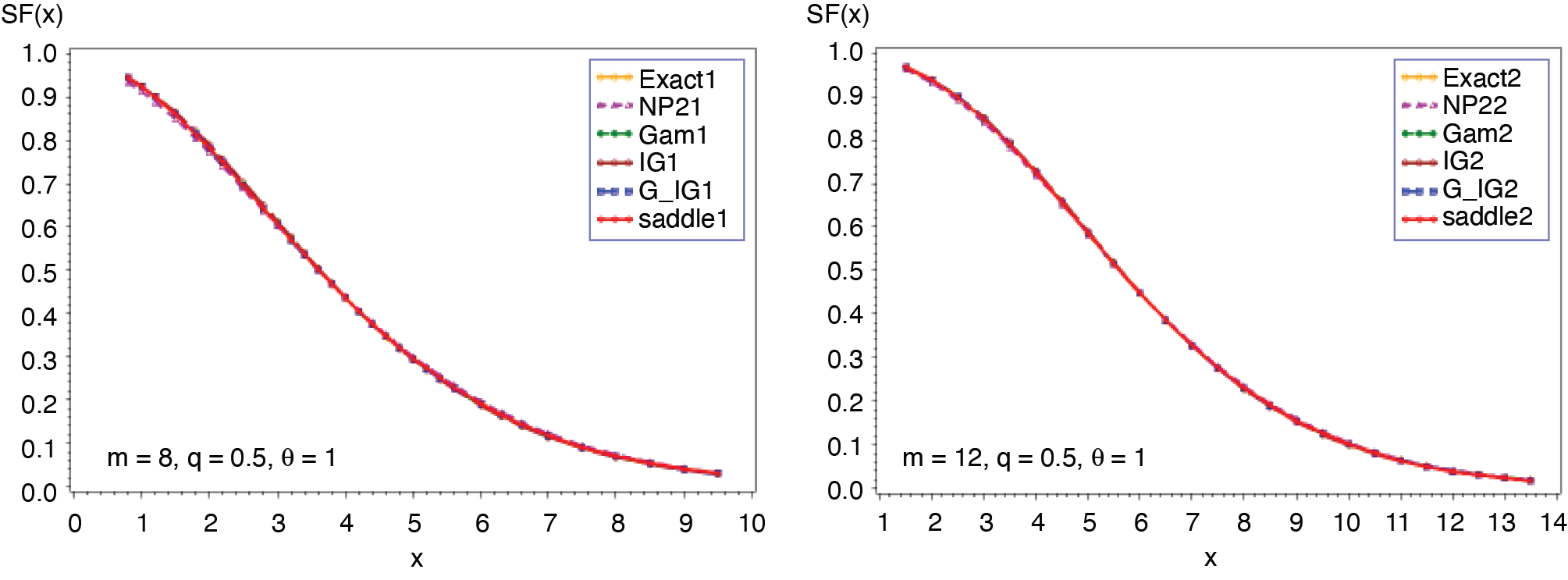
3.1. Poisson-gamma distribution (λ, α, θ)
In this example, the number of claims has a Poisson distribution with parameter λ, and the common severity distribution is gamma with parameters α and θ. The cumulant generating function (c.g.f.) of S and its first derivative are as follows:
CS(t)=λ[(1−θt)−α−1],t<1/θ
C(1)S(t)=λαθ(1−θt)−(α+1).
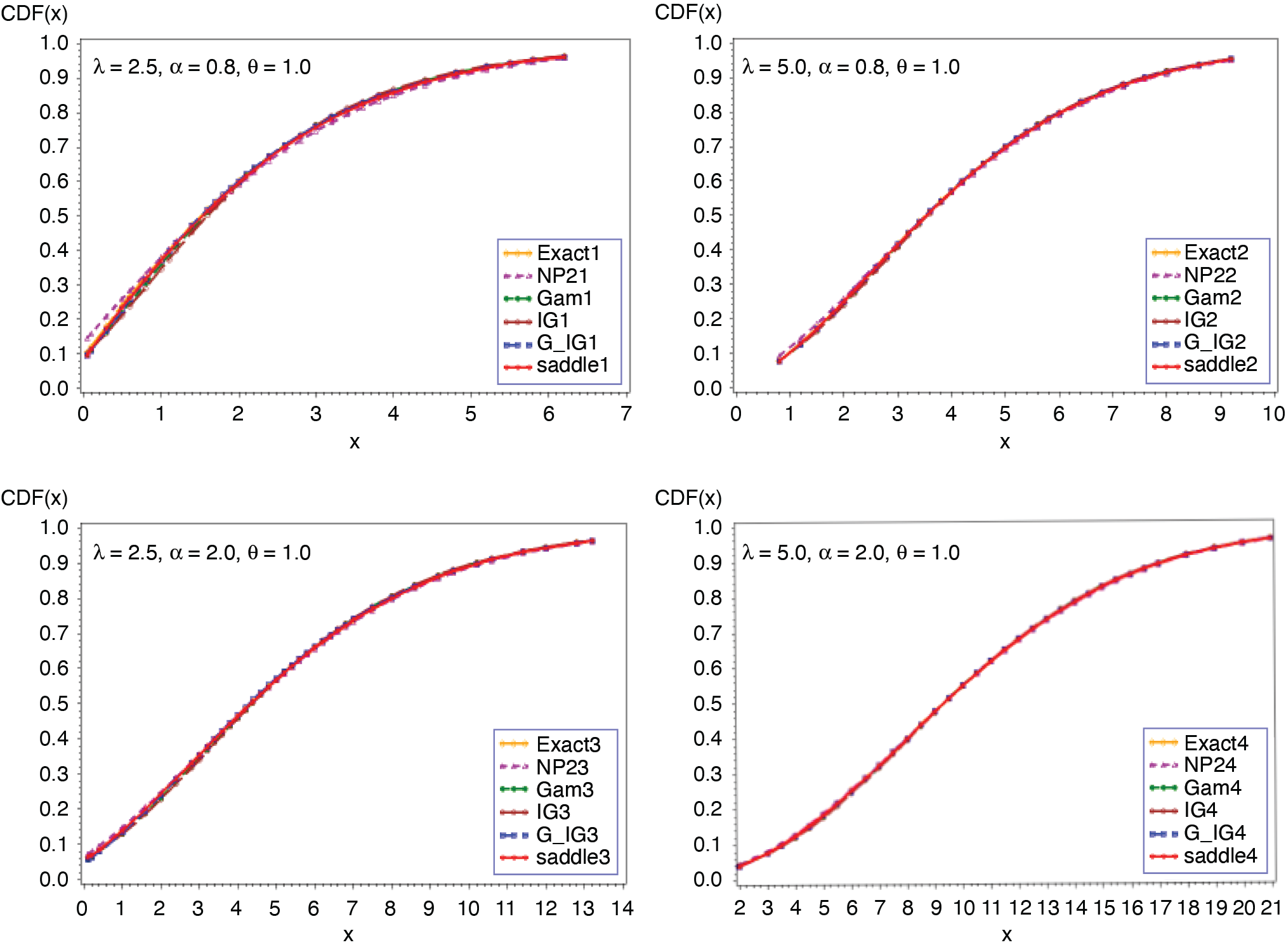
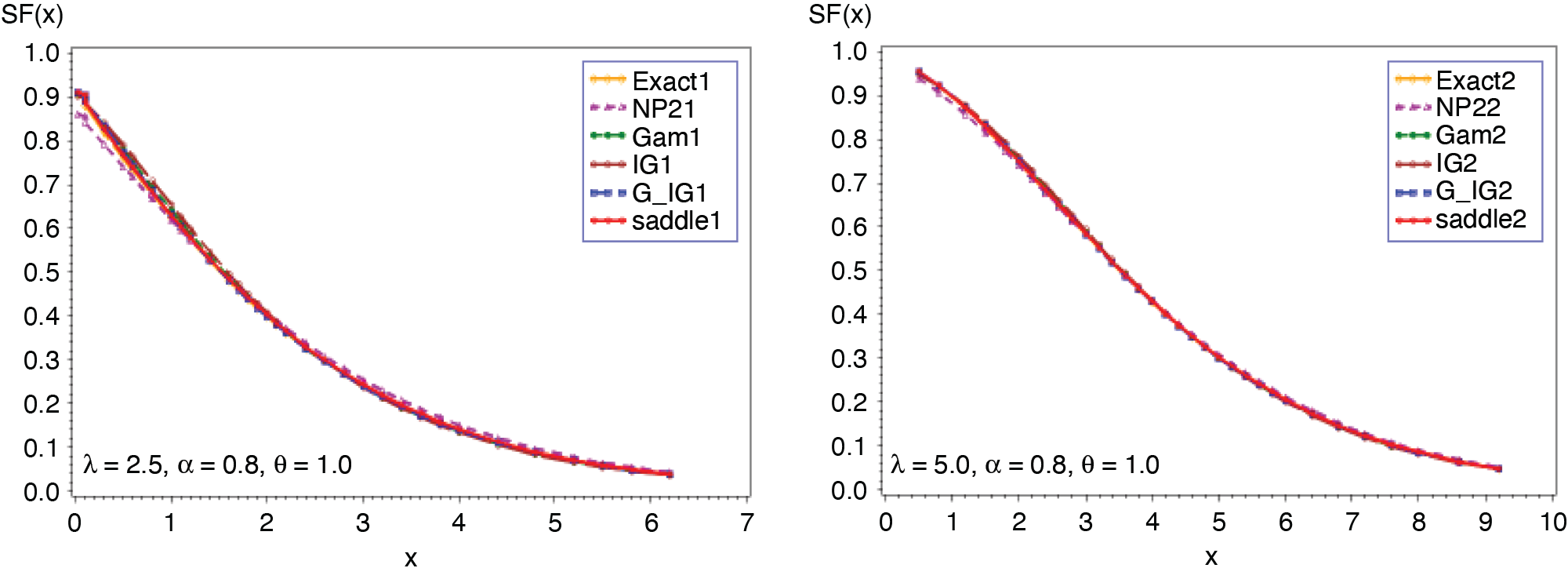
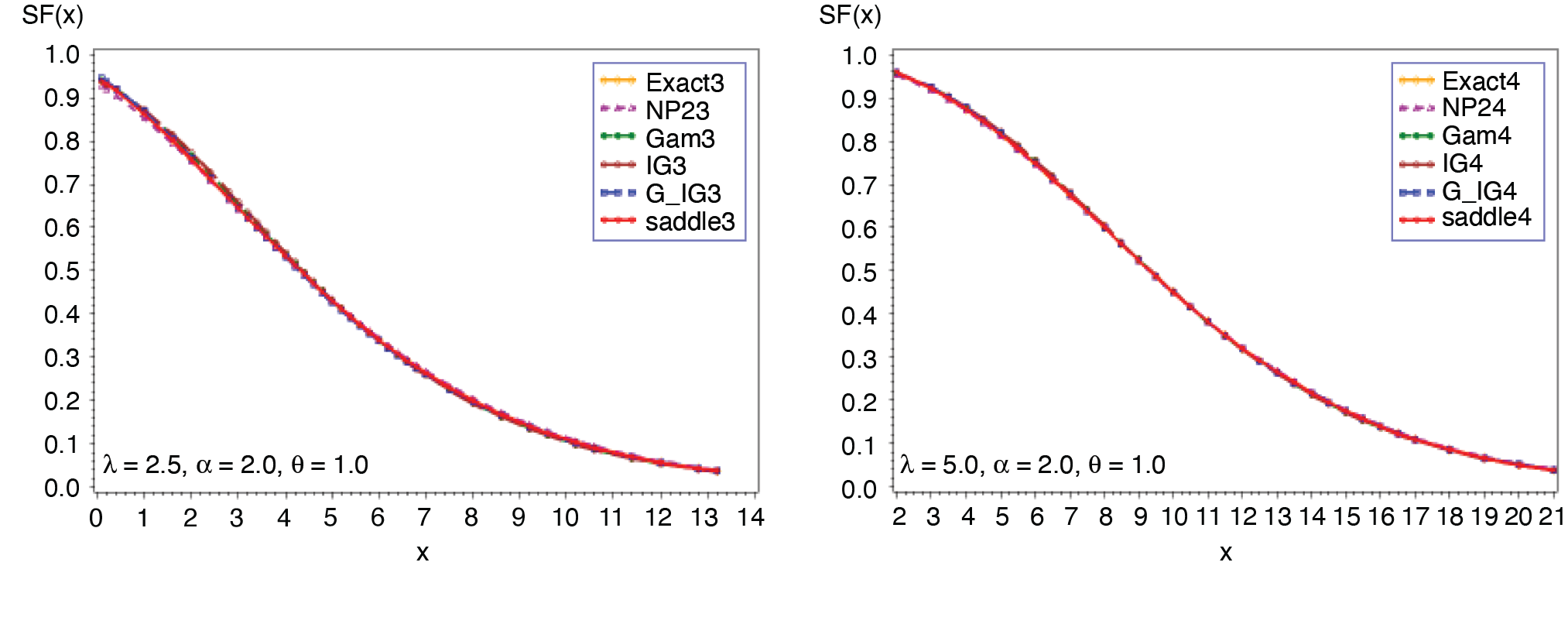
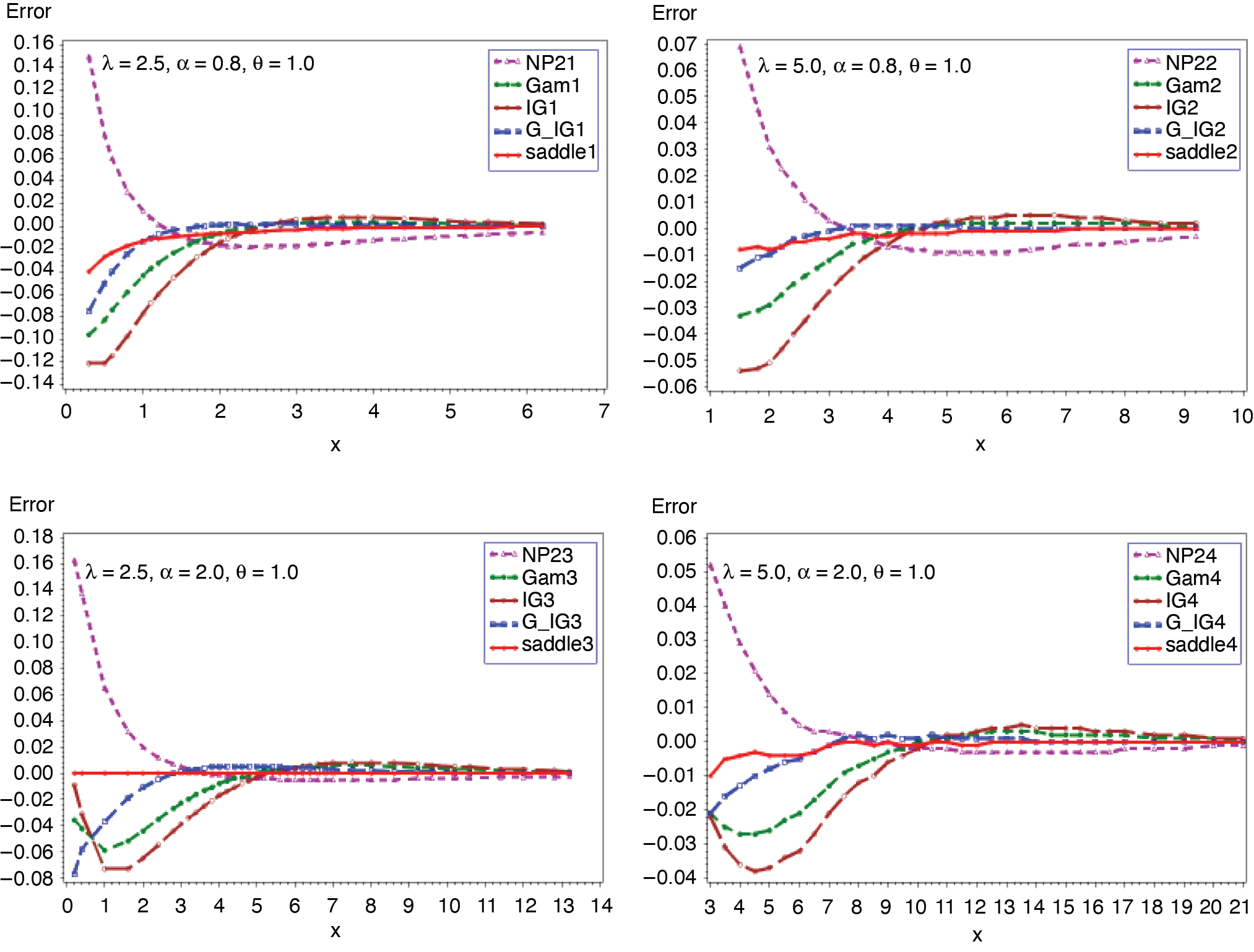
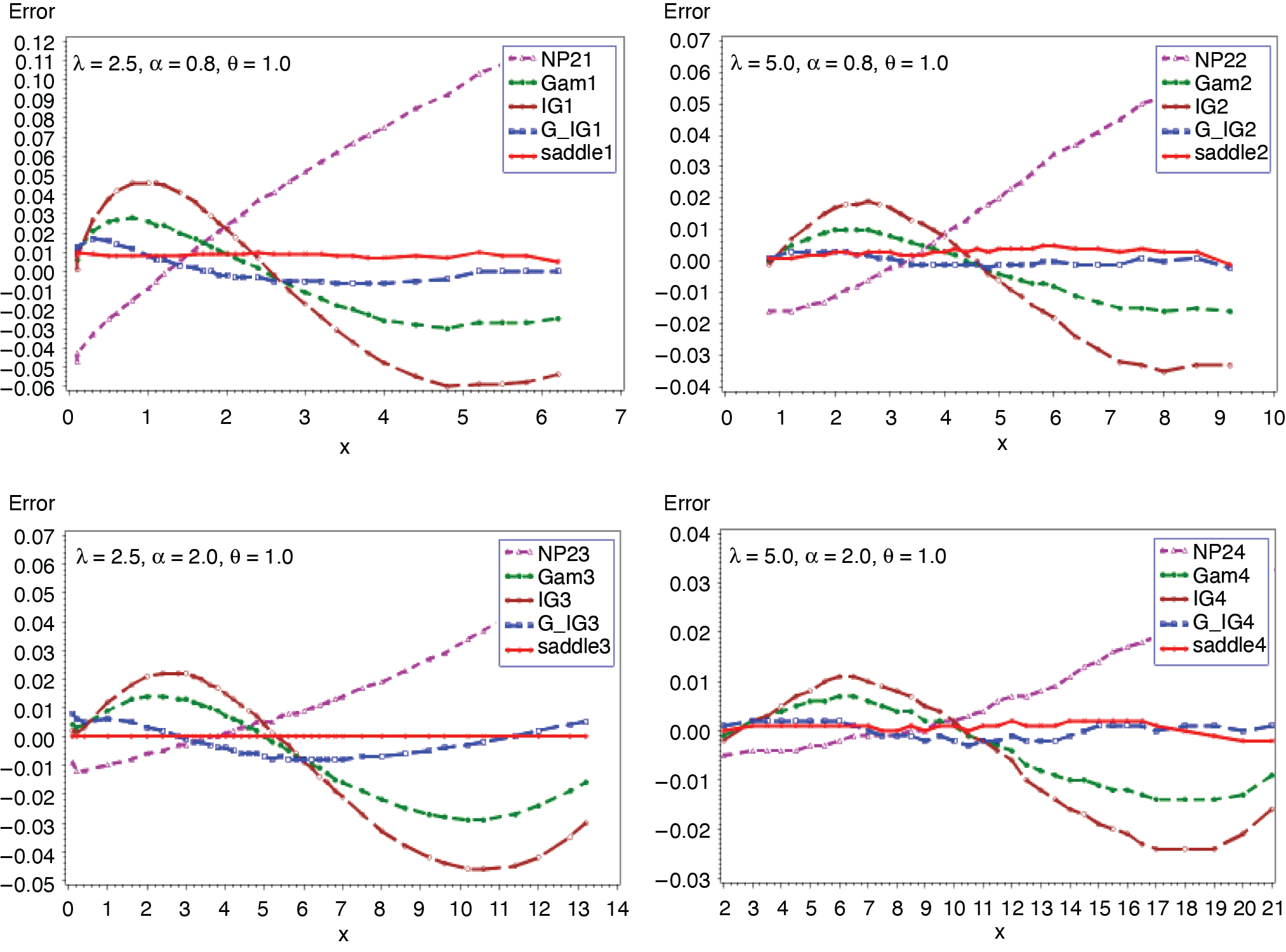
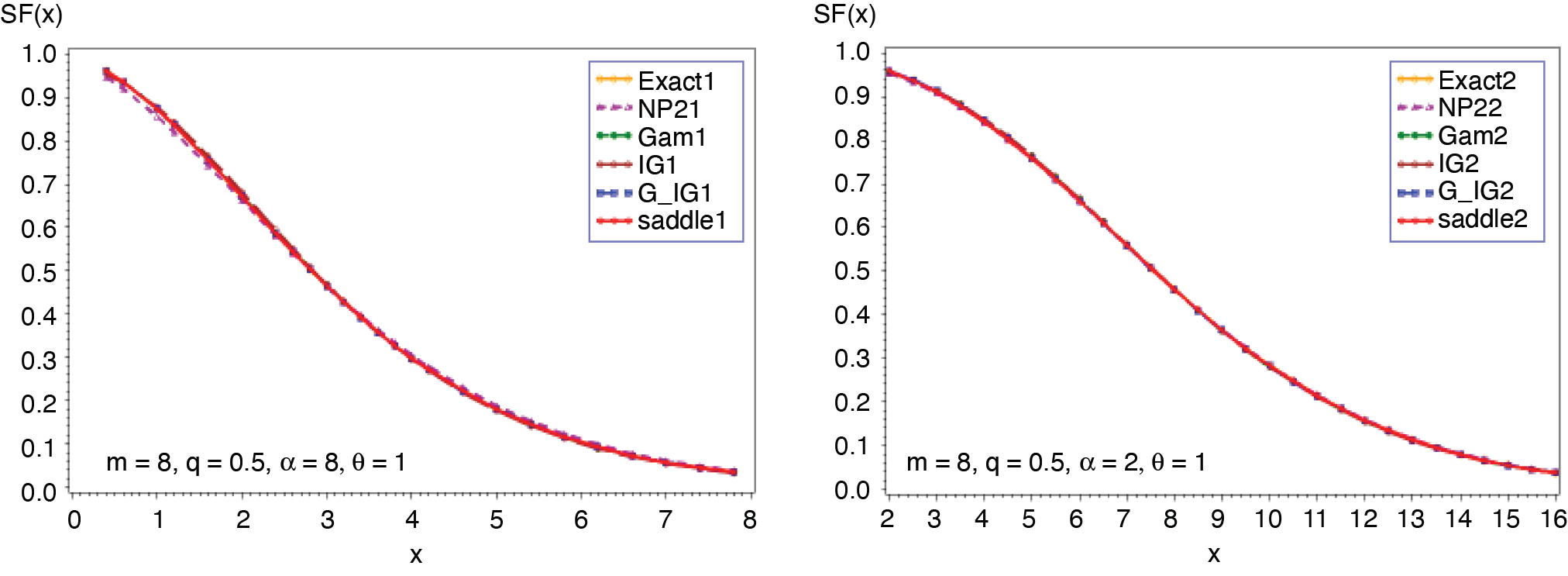
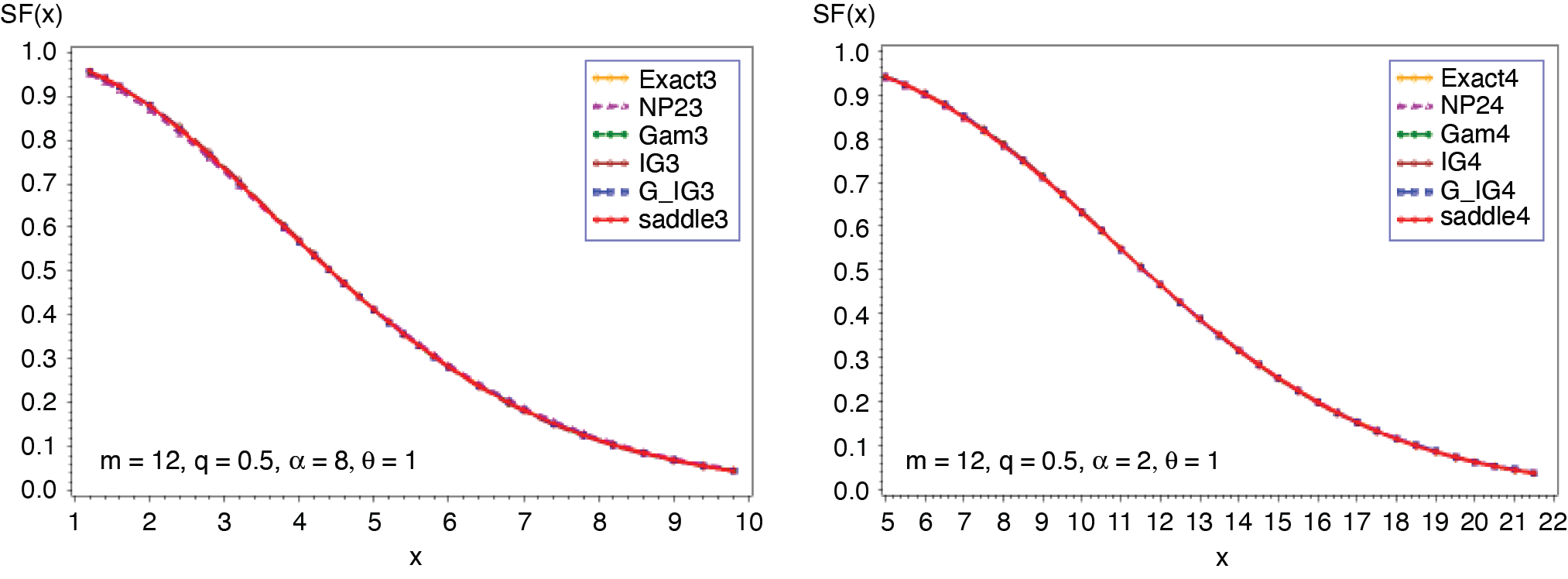
Expression in (3.2) yields the saddlepoint as From (3.1), we obtain the first four moments which are given as ; ; Figures 1 and 2 display the cumulative (CF) and the tail probabilities (SF) for different parameter combinations. Figures 3 and 4 illustrate the relative errors for those combinations. For all cases, the approximation (2.5) gives excellent results, followed by gamma-IG mixture approximation.
_.png)
_.png)
__(*continued*).png)
_.png)
_.png)
3.2. Poisson-IG distribution (λ, μ, θ)
In this example, the claim count random variable (N) follows a Poisson distribution with parameter λ, and the common severity random variable (X) has inverse Gaussian distribution with parameters μ and θ, defined as in Klugman, Panjer, and Willmot (2012). The c.g.f of S and its first derivative are
CS(t)=λ{exp[θμ(1−√v)]−1},t<θ2μ2
C(1)S(t)=λμ√vexp[θμ(1−√v)],
where The saddlepoint, can be obtained by solving the following equation numerically:
lnv2+θ√vμ=θμ−ln(xλμ).
Equation (3.3) yields the following quantities:
μs=λμμ2(s)=λ(μ+θ)μ2/θμ3(s)=λ(3μ2+3μθ+θ2)μ3/θ2μ4(s)=λ[15μ2(μ+θ)+θ2(6μ+θ)+3λθ(μ+θ)2]μ4/θ3.
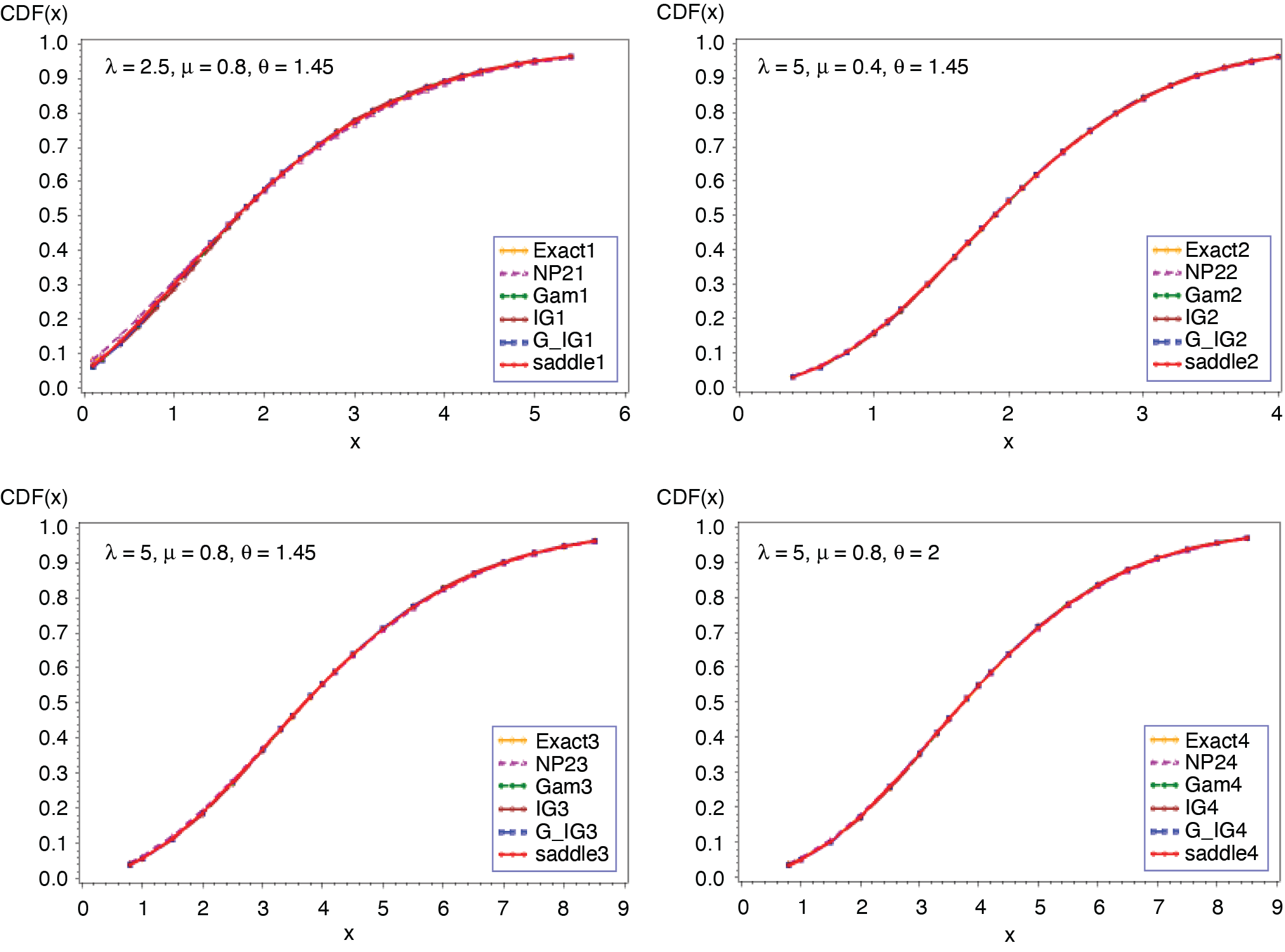
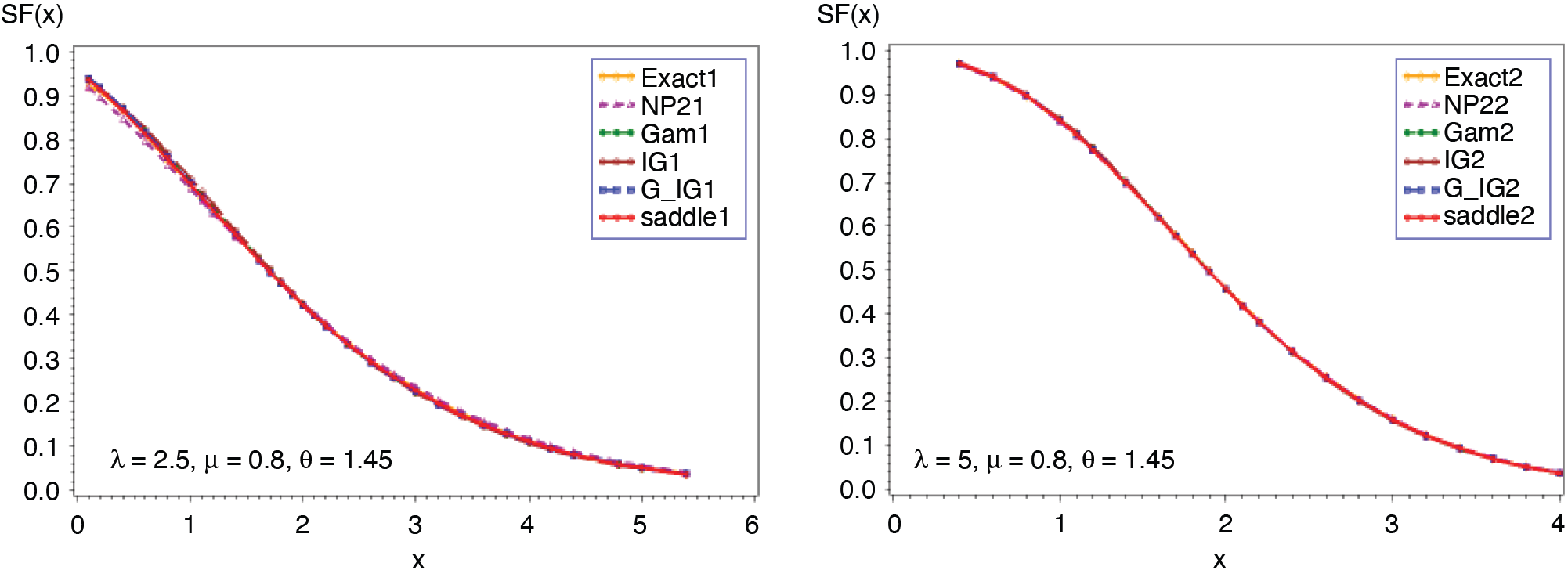
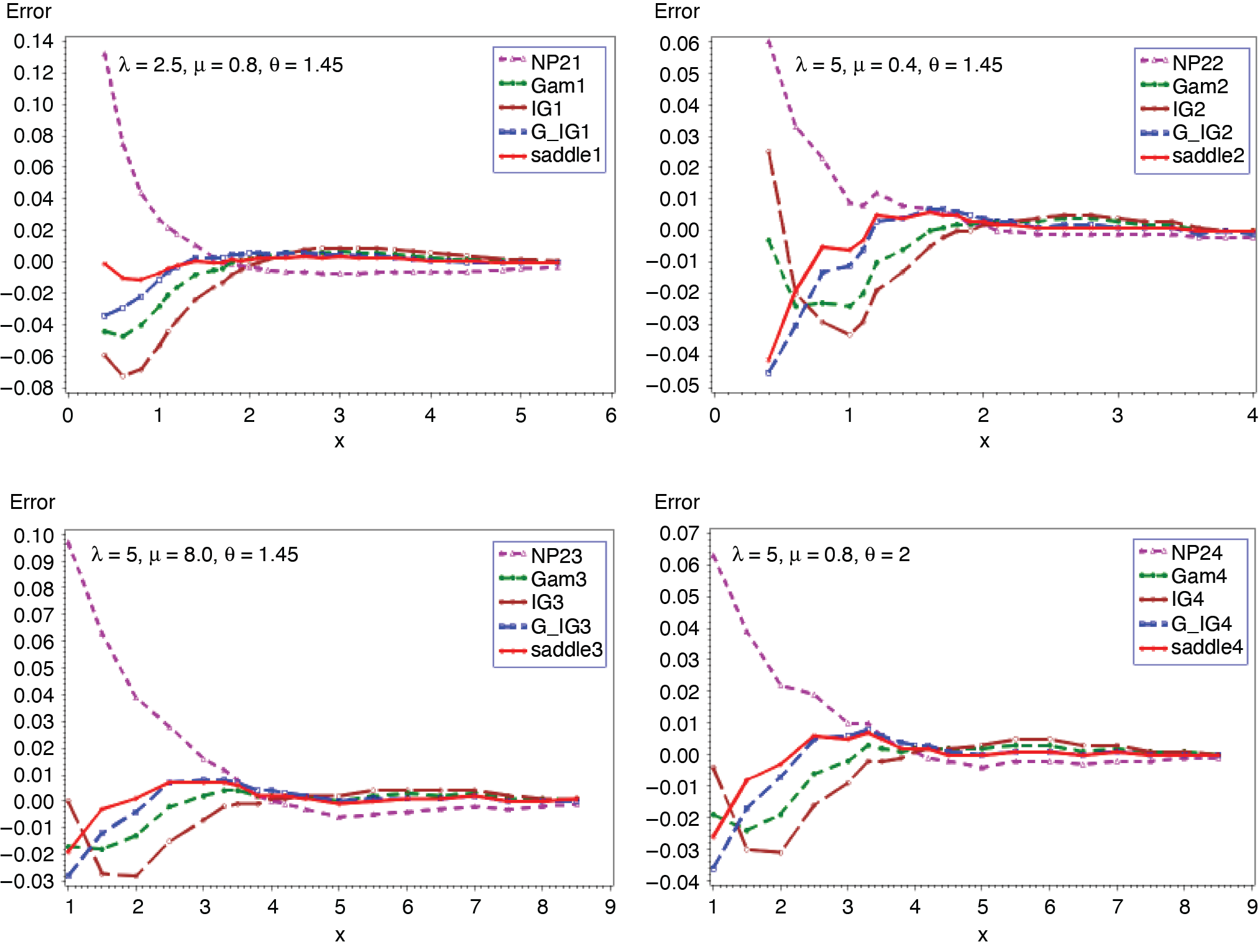
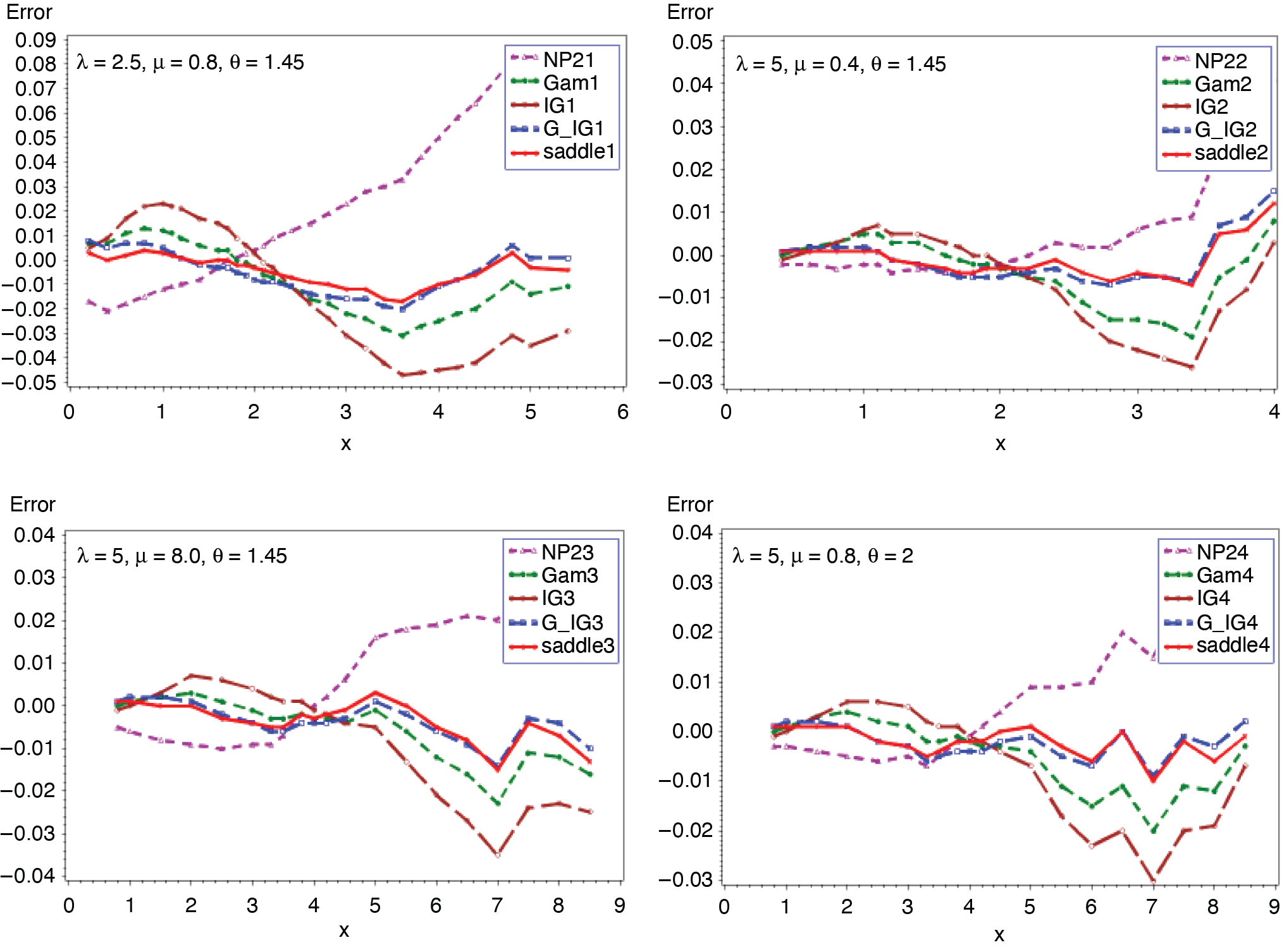
Figures 5 and 6 present the cumulative and the tail probabilities for various parameter choices of frequency and severity distributions. Figures 7 and 8 display the relative errors for those cases. The approximations given in (2.4) and (2.5) are seen to have remarkably small relative errors for all cases.
_.png)
_.png)
__(*continued*).png)
_.png)
_.png)
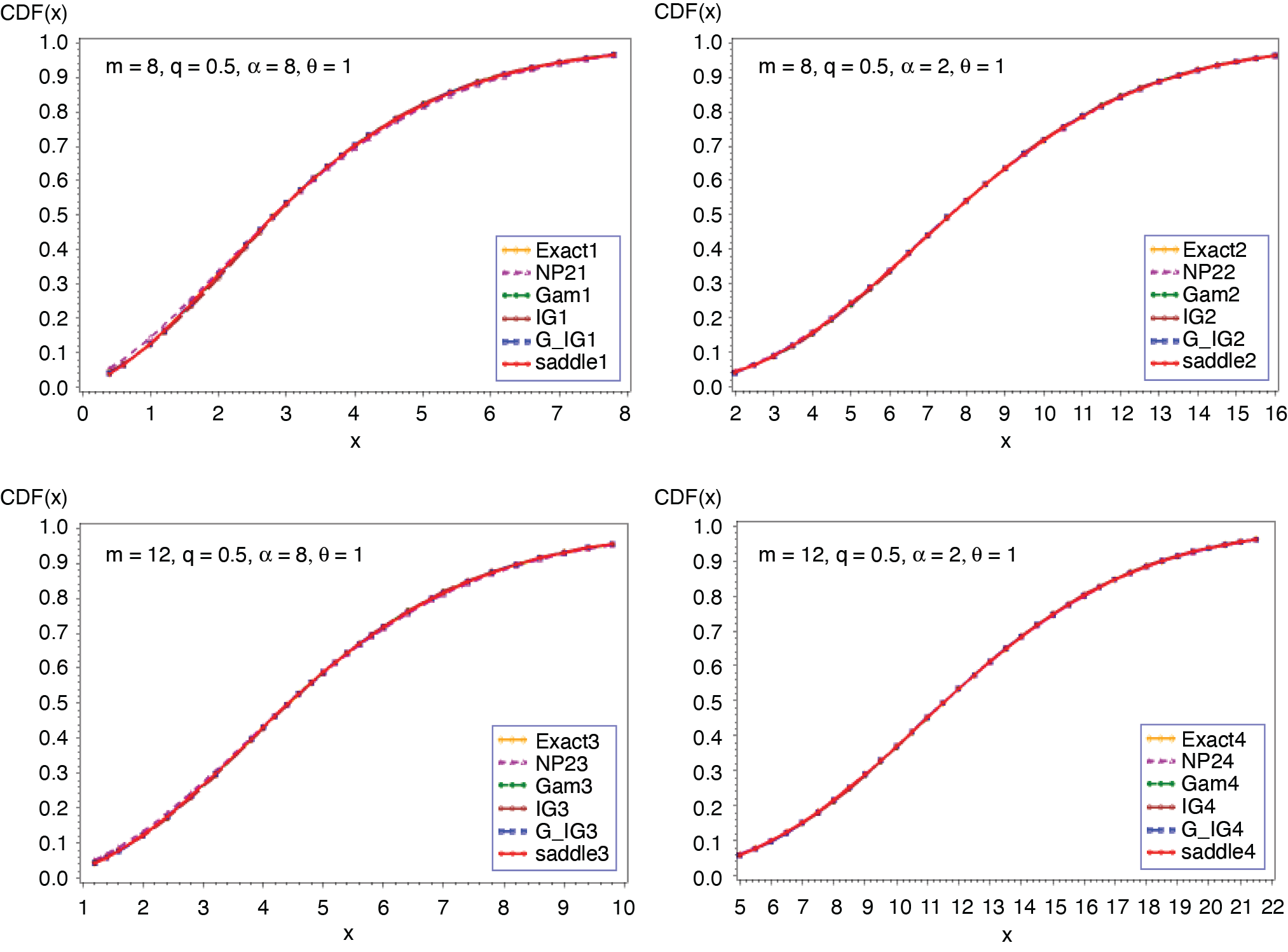
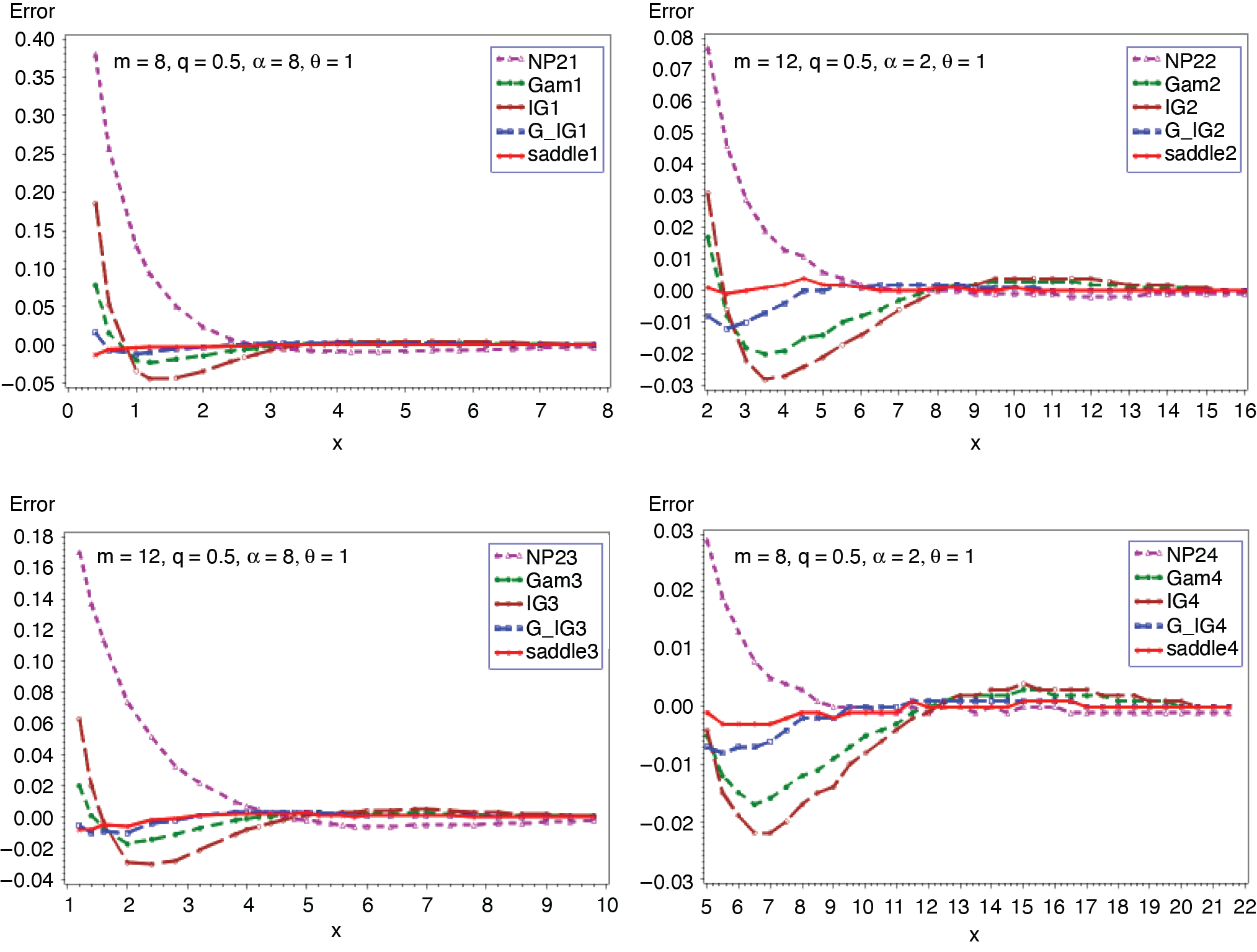
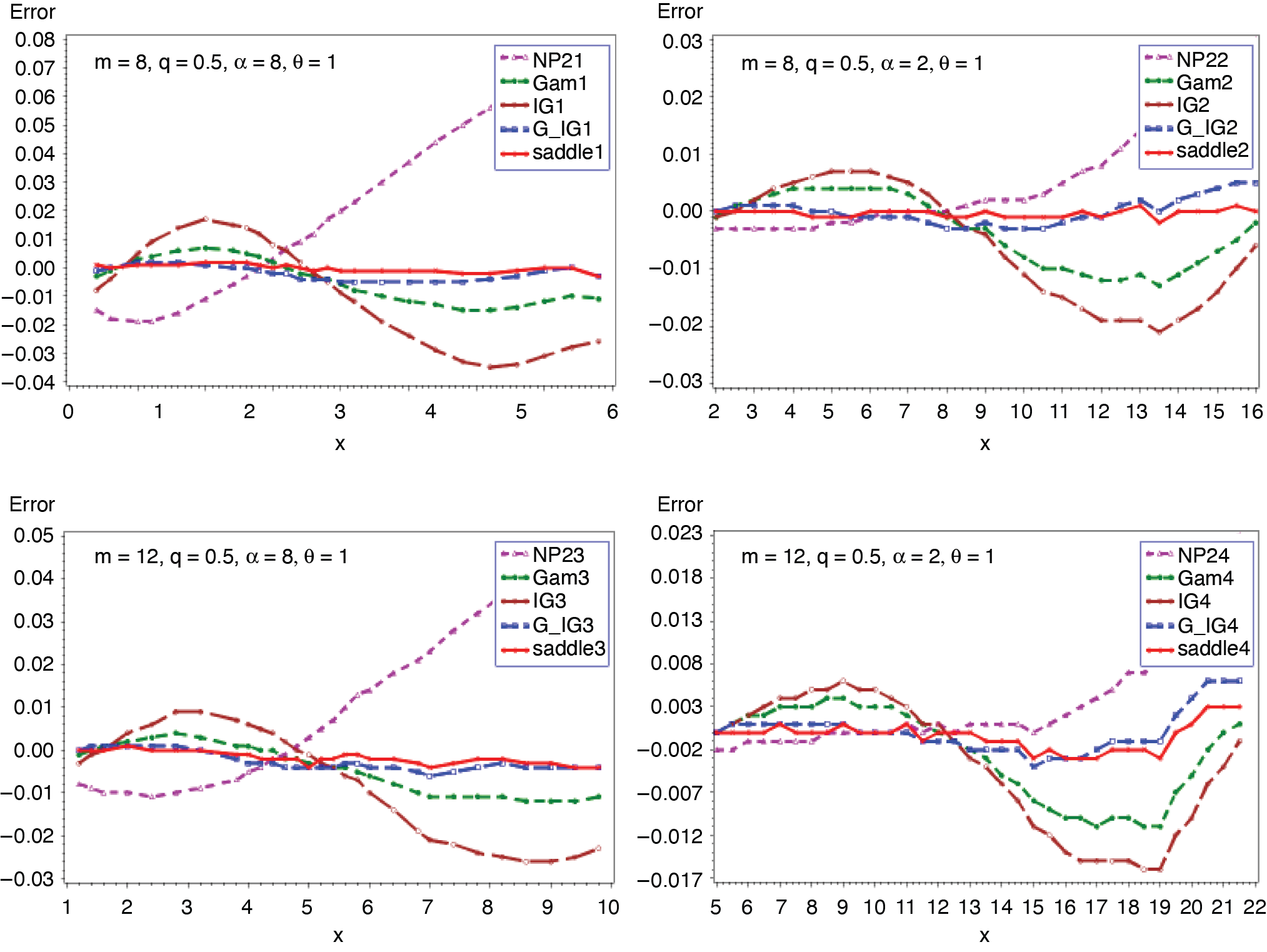
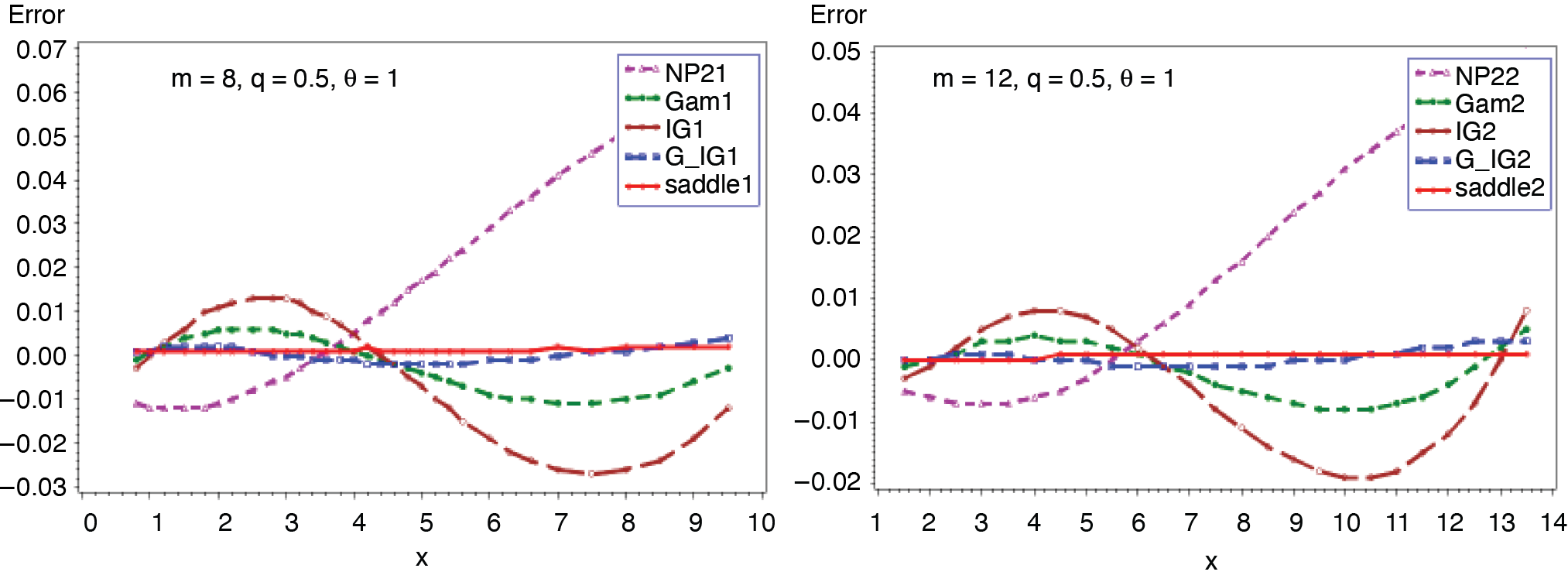
3.3. Binomial-gamma distribution (m, q, α, θ)
In this example, the number of claims random variable follows a binomial distribution with parameters m and q. The common severity random variable has a gamma distribution with parameters α and θ. The c.g.f. of S and its first derivative are given as
CS(t)=mln{1−q+q(1−θt)−α},t<1/θ
C(1)S(t)=mqαθ[(1−θt)−α−11−q+q(1−θt)−α].
.png)
.png)
__(*continued*).png)
.png)
.png)
The saddlepoint, can be obtained numerically from
mqαθ[(1−θt)−α−11−q+q(1−θt)−α]=x.
The required moments obtained from (3.6) are as follows:
μs=mqαθμ2( s)=mqα[1+(1−q)α]θ2μ3( s)=mqα[δ1+2α2q2]θ3μ4( s)=mqα[δ2−6α3q3+3mqα{1+(1−q)α}2]θ4,
where δ1 = (α + 1)(α + 2) − 3α(α + 1)q and δ2 = (α + 1){(α + 2)(α + 3) − α(7α + 11)q + 12 α2q2}. Figures 9 and 10 present the cumulative and the tail probabilities for various choices of parameter values. Figures 11 and 12 depict the relative errors for those combinations. The outcomes are the same as in the previous applications. When α = 1, the above distribution modifies to binomial exponential (m, q, θ). The c.g.f. of S and its derivative reduce to
CS(t)=ln(1+qθt1−θt)m,t<1/θ
C(1)S(t)=mθ[11−θt−1−q1−θt+qθt].
The saddlepoint equation leads to the explicit solution
ˆt=(2−q)−√q2+4mq(1−q)θx2(1−q)θ.
μs=mqθμ2( s)=m[1−(1−q)2]θ2μ3( s)=2m[1−(1−q)3]θ3μ4( s)=3m[2{1−(1−q)4}+mq2(2−q)2]θ4.
The analytical expression for the cumulative probability of S, which can easily be obtained from (1.1), is
CF(x)=1−m∑n=1(mn)qn(1−q)m−nn−1∑j=0(x/θ)jexp(−x/θ)j!.
Cumulative and tail probabilities, along with the relative errors of the approximations, are presented in Figures 13 and 14. The exact probabilities are obtained from (3.12). As can be seen in the previous examples, the results in Figures 13 and 14 indicate that the saddlepoint approximation gives very satisfactory accuracy.
.png)
.png)
_(*continued*).png)
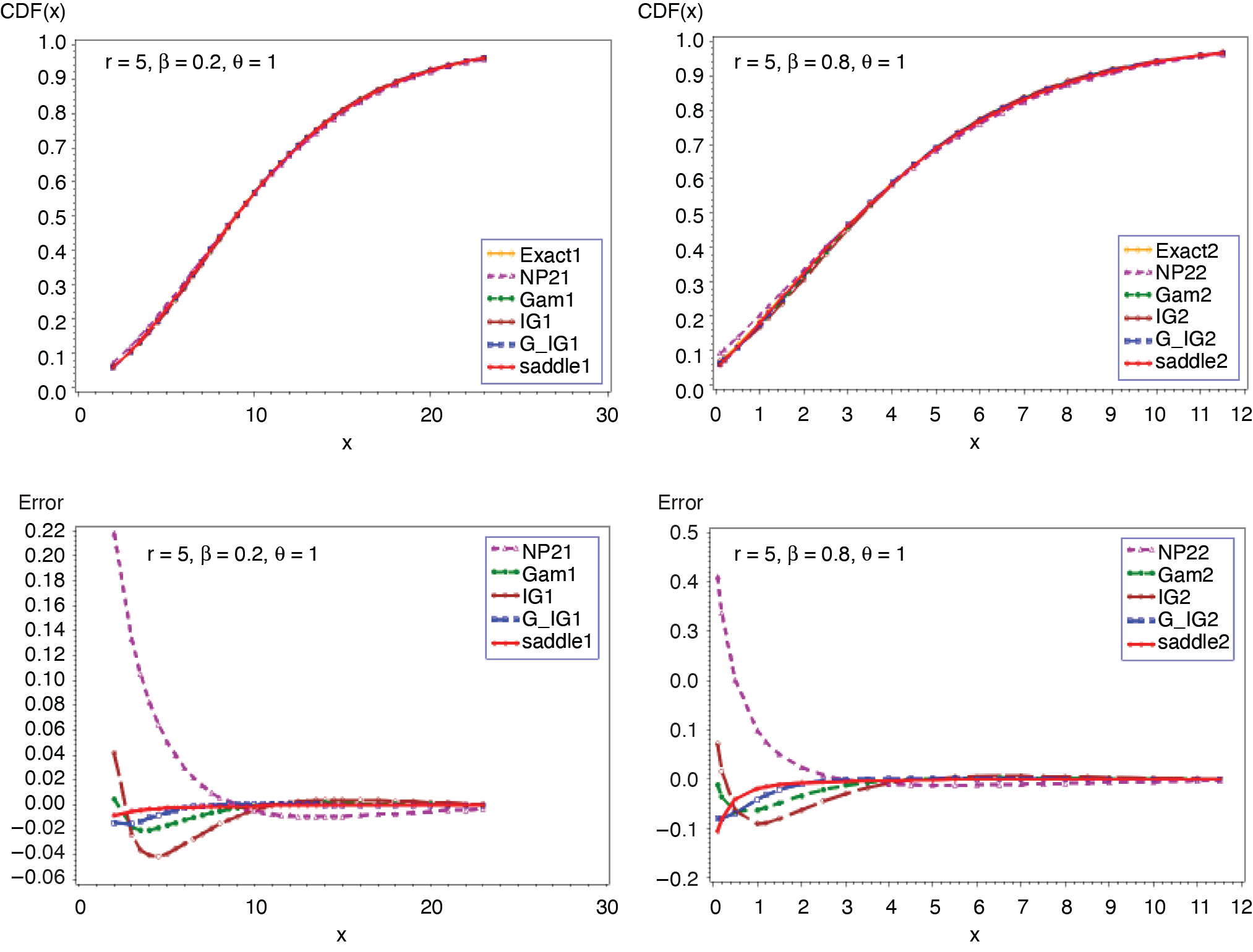
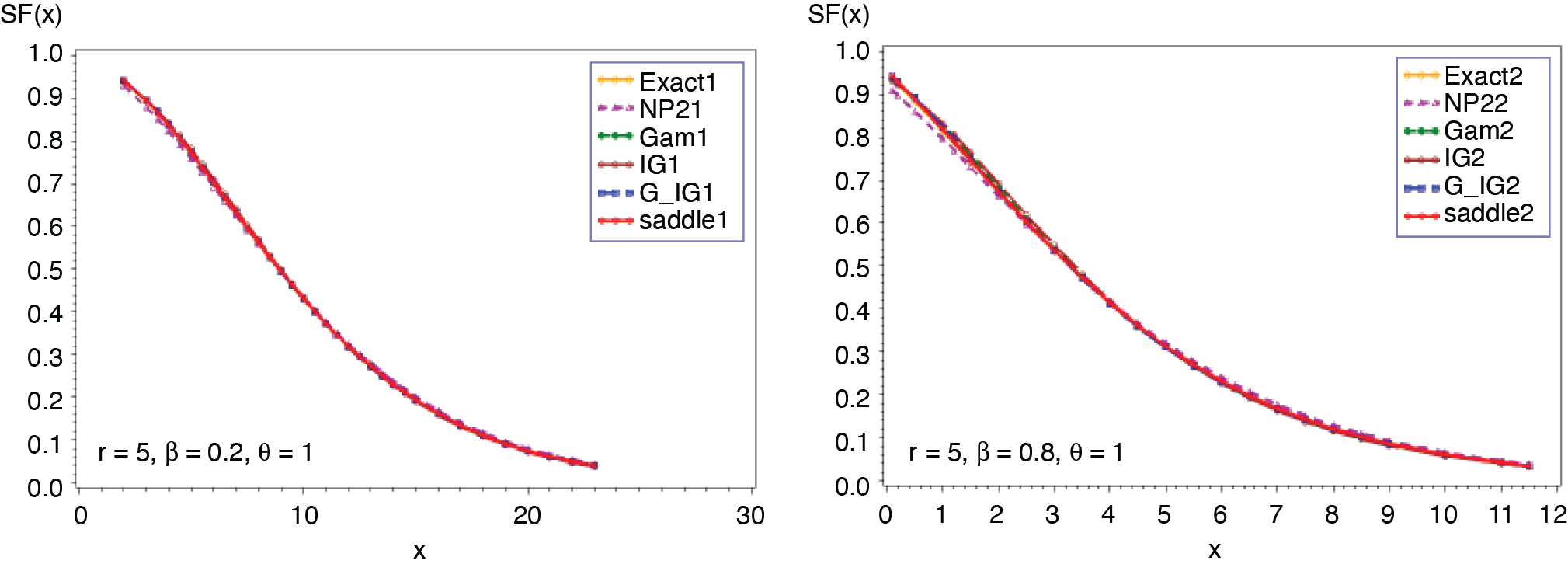
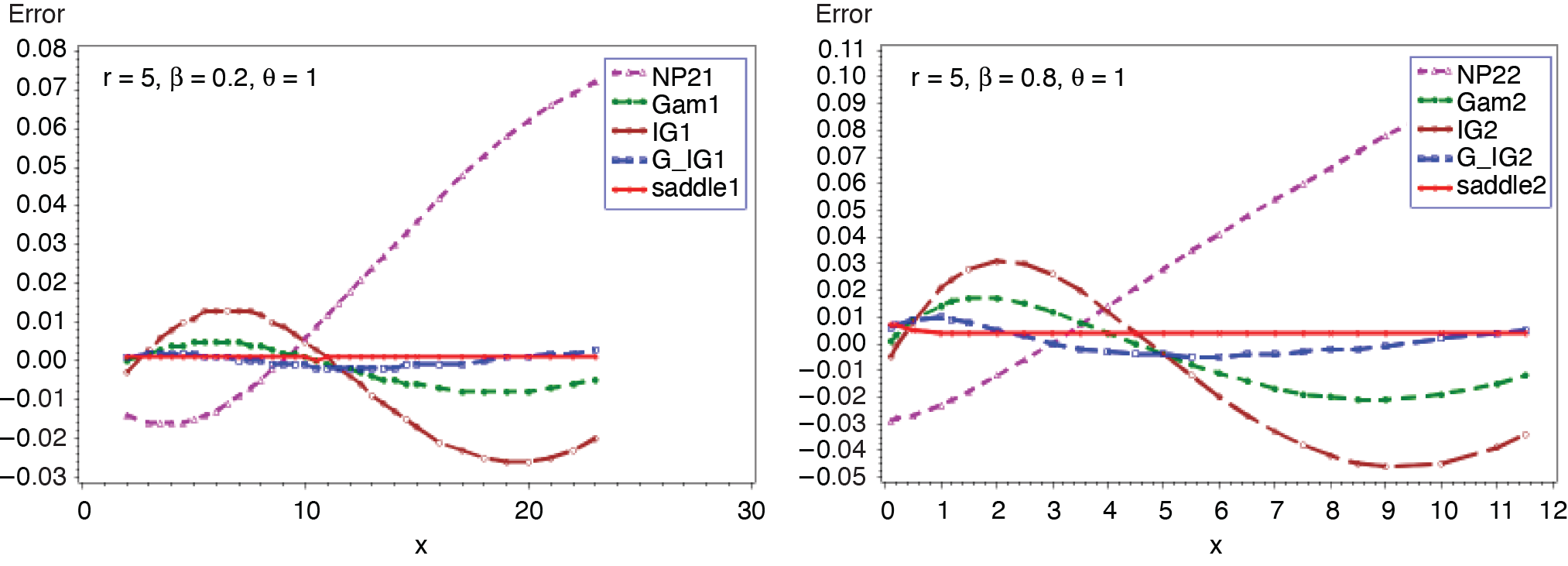
3.4. NB-exponential distribution (r, β, θ)
In this example, frequency distribution is negative binomial with parameters r and β, and the common severity distribution is exponential with parameter θ. The c.g.f. of S and its first derivative can be written as
CS(t)=rln(1−θt1−θt−βθt)
C(1)S(t)=rβθ(1−θt)(1−θt−βθt).
Equation (3.14) yields an explicit saddlepoint solution:
ˆt=(β+2)−√β2+4rβθ(1+β)x2θ(1+β).
Equation (3.13) yields the following moments:
μs=rβθμ2( s)=rβ(β+2)θ2μ3( s)=2r[(1+β)3−1]θ3μ4( s)=3r[2{(1+β)4−1}+rβ2(β+2)2]θ4.
The following analytical expression for the cumulative probability can be obtained from (1.1):
CF(x)=1−r∑n=1(rn)(β1+β)n(11+β)r−nn−1∑j=0(x/θ(1+β))je−x/θ(1+β)j!.
Figures 15 and 16 present the comparison of all five approximations. The exact probability is computed based on the analytical expression given in (3.16). The outcomes in Figures 15 and 16 reveal that the approximation given in (2.5) outperforms the other four, followed by the gamma-IG mixture approximation provided in (2.4). Corresponding results for geometric-exponential distribution (β, θ) can be obtained by letting r = 1.
_.png)
_.png)
__(*continued*).png)
4. Conclusions
The purpose of this paper is to compare the accuracy of the saddlepoint approximation, introduced by Lugannani and Rice (1980), with four other approximations to the distribution of aggregate claims. The approximate cumulative probabilities and tail probabilities have been computed for several compound distributions and are compared with the exact results in terms of relative errors. Based on the results in Figures 1–16, it is clear that the saddlepoint approximation gives very satisfactory accuracy, followed by the gamma-IG mixture approximation in all of the examples considered. The gamma and the IG approximations behave in a similar manner. The NP2 approximations consistently produce higher relative errors compared to the other four. Suppose claim amounts distribution is gamma or inverse Gaussian. The saddlepoint approximation is simple and easy to compute with great accuracy, requiring only the first three derivatives of the cumulant generating function.
Acknowledgment
Author would like to thank the editor and three anonymous reviewers for their constructive comments/suggestions that greatly improved the manuscript.