



1. Introduction
Risk aggregation is of fundamental importance for insurance. This is because risk aggregation is in fact a precursor of risk pooling, a principle that is seen by some as the insurance’s reason d’etre. To see how crucial risk aggregation is for risk pooling, consider a group of n ∈ N individuals (also, business lines, risk components in a portfolio of risks, etc.), where each one of i ∈ {1, . . . , n} faces a risk represented by the random variable (RV) Xi, then a sharing rule Y(X1, . . . , Xn) is called risk pooling if it is a function of the aggregate risk X1 + . . . + Xn, only, that is Y(X1, . . . , Xn) = Y(X1 + . . . + Xn) (e.g., Aase 2004 for details). Hence, it is clear that to reap the benefits of risk pooling, insurers must study and understand risk aggregation thoroughly. From now and on, X1, . . . , Xn stand for insurance risk RVs, and X1 + . . . + Xn ≔ Sn denotes the associated aggregate risk.
Specific examples of risk aggregation are naturally abundant in all areas of insurance business. For classical applications, one has to go no further than the renowned individual (e.g., Dhaene and Vincke 2004) and collective (e.g., Goovaerts 2004) risk models. Specifically, in the case of the individual risk models (IRMs), for a fixed n as hitherto and independent but not identically distributed risk RVs X1, . . . , Xn, the aggregate risk is as before denoted by Sn. Also, in the case of the collective risk models (CRMs), the number of risks, denoted by N is assumed random and independent of identically distributed and mutually independent (IID) RVs X1, . . . , XN; the aggregate risk is then denoted by SN ≔ X1 + . . . + XN.
In order to comprehend the implications of risk aggregation, and merely comply with the norms of the risk informed decision making, insurers are concerned with the stochastic properties of the RVs Sn and SN, that is, with the corresponding cumulative distribution functions (CDFs). Whether the IRM or CRM are considered, it is often tempting to approximate these CDFs with the use of the Lindeberg–Lévy central limit theorem (CLT). To this end, arguments like (i) the number of risks is large, (ii) the risks are not too heterogeneous, and (iii) the distributions of the risk RVs are not too skewed are quite common. Unfortunately, none of the above must be true in reality. Furthermore, statements (ii) and (iii) are often violated as insurance risk RVs due to distinct risk sources can be very unalike, and, as a rule, positively skewed. Another problem with the aforementioned variant of the CLT is that there are situations (not rare) where the risk RVs of interest have infinite second moments (e.g., Seal 1980 and references therein). We refer to Brockett (1983) and references therein for some interesting examples of how the CLT is misused in insurance applications.
The standard CLT-based approximation of the aggregate risk’s CDF, a.k.a. the normal approximation (NA), can be considered a moment matching approximation (MMA) that hinges on the first two moments only. A generalization of NA that incorporates skewness is the so-called normal-power (NP) approximation (e.g., Ramsay 1991). An alternative approach to count for skewness that is of great popularity among practicing actuaries is the shifted-gamma approximation (SGA), which aims to match the first three moments (Hardy 2004). Clearly, the choice of how many moments to match is somewhat ad hoc. Thus, more general approximations that aim at matching an arbitrary number of moments have been proposed (e.g., Cossette et al. 2016 for a recent reference).
Admittedly, MMAs, both the ones mentioned above and others alike, are convenient and intuitive to convey to upper management, yet rather problematic. For instance, even the two moments-based NA method requires finite second moments, and it is inapplicable otherwise. The approach of Cossette et al. (2016) achieves better accuracy at the price of requiring the finiteness of higher order moments. In addition, in the latter case, the method is often rather computationally intensive.
In this paper, we put forward a new efficient method to approximate the CDFs of the aggregate risk RVs Sn and SN. Our approach approximates the CDFs of interest to any desired precision, works equally well for light- and heavy-tailed CDFs and is reasonably fast, irrespective of the number of summands. We organize the rest of this paper as follows: Section 2 provides a high-level overview of our approach, and Sections 3, 4, and 5 explain in detail its three main pillars, which are, respectively, the class of Padé approximations, the family of generalized gamma convolutions, and the Gaver-Stehfest algorithm. The theory we propose is then elucidated by a variety of practical examples borrowed from Bahnemann (2015). More specifically, in Section 6 we demonstrate the effectiveness of the new MMA in the context of stand-alone risk RVs first and then in the context of aggregate risk RVs with and without policy modifications.
2. Brief description of the method
In order to outline the essence of our proposed technique in the simplest possible manner, in this section we consider the framework of the IRM; however, the ideas are equally applicable in the context of the CRM (Section 6 of this paper). Let be positive and mutually independent RVs with arbitrary corresponding CDFs Also denote by the Laplace transform (LT) of the RV Our goal is to approximate the CDF of the aggregate RV
Let also, denote the LT of the aggregate risk RV S, then we readily have
ϕ(z)=n∏i=1ϕi(z)
and
F(x)=L−1{ϕ(z)z}(x),x≥0.
Hence, by combining (1) and (2), we are able to obtain the desired approximation of the CDF given that there exist reliable methods to: (i) approximate each LT and (ii) invert LTs. Next in Sections 3-5, we demonstrate that (i) and (ii) can be achieved very successfully. Namely, in Section 3, we approximate the Laplace transform with the help of the Laplace transform of certain gamma convolutions, and we utilize the machinery of Padé approximations to determine the involved shape and rate parameters. In Section 4, we reintroduce the family of generalized gamma convolutions, and, finally, in Section 5, we briefly explain the Gaver-Stehfest method to invert Laplace transforms. The proposed MMA may at the first glance seem complex, but when implemented it is utterly user-friendly and requires minimal human involvement.
3. Padé approximations
To start off, we note that (1) requires approximating the LT of the RV (the CDF of the RV is then established via (2)). We accomplish this with the help of -fold convolutions of gamma-distributed RVs, succinctly In other words, we seek to choose the parameters and so that the CDF of the approximant of order is close in an appropriate sense to the CDF of the In the rest of the paper, we omit the subscript ( ) whenever the order of the approximation is fixed. Also, for the sake of the expositional simplicity of the discussion in the present section, and sometimes thereafter, we omit the subscript and write instead of and instead of
In terms of LTs, we seek to choose the parameters and so that the approximant LT
˜ϕ(z):=E[exp(−zm∑i=1Γi)]=m∏i=1(1+z/βi)−αi
is close to the function Our method is essentially an MMA. Note that the moments of can be computed as thus matching the first moments of and is equivalent to matching the derivatives (of order ) of and at However, our approach allows for a number of important improvements.
Note 1. A significant innovation of our method is that we match the derivatives of and not at but at some point This is crucial if we want our technique to be applicable to risk RVs with heavy tails, for which the moments (and thus the derivatives may fail to exist. If the risk RV X has exponentially light tails, we may as well choose but in general z* must be strictly positive.
Note 2. Another distinguishing feature of our approach is that converges to uniformly and exponentially fast, and in particular the approximant converges in distribution to the RV X.
Note 3. Our method requires parameters (unique up to permutation) to match the first moments of the RVs and As at least parameters are required to complete this task, the method we put forward herein is optimal in this sense.
3.1. Approximation of order two
In order to explain the main ideas behind our algorithm, let us consider a simple case where m = 2 and z* = 1. In this case the problem reduces to the following one: we want to find four positive numbers and such that the derivatives of the LT φ at z = 1 coincide with derivatives of the approximant LT
˜ϕ(2)(z)=(1+z/β1)−α1(1+z/β2)−α2
also at point z = 1. In order to compute the four constants and we need to have at least four equations, so now we need to solve the following system
dkdzk(1+z/β1)−α1(1+z/β2)−α2|z=1=ϕ(k)(1)k∈{1,2,3,4}.
If we were to compute the derivatives in the left-hand side of (3) and then to simplify the resulting equations, we would have obtained a fairly complicated system of four nonlinear equations in and However, analyzing these equations theoretically would not be feasible due to their complexity and even solving them numerically would be a major problem.
In order to avoid the complexity, we take logarithms before differentiating. Thus, instead of matching the derivatives and for we match the derivatives of and of order The end result is clearly the same, but computing and is much simpler, as we demonstrate in a moment. With this change, the system of four equations for finding and looks as follows:
dkdzkln[(1+z/β1)−α1(1+z/β2)−α2]|z=1=dkdzkln[ϕ(z)]|z=1,k∈{1,2,3,4}.
Let us denote As we see later, it is easy to compute sk numerically in each case of interest, thus for now we treat these numbers as known quantities. Computing the derivatives in the left-hand side of (4), we obtain a system of four equations
α1(1+β1)k+α2(1+β2)k+α2(1+β2)k+α2(1+β2)k=(−1)ksk−1,k∈{1,2,3,4}.
At this stage, that is in order to solve the nonlinear equations in (5) and find and we employ the toolbox of Padé approximations.
Namely, we introduce yet another function ψ(z) ≔ −φ′(z)/φ(z). Then system (4) is equivalent to
dkdzk[α1z+β1+α2z+β2]|z=1=ψ(k)(1),k∈{0,1,2,3}.
Note that we can write
α1z+β1+α2z+β2=A+B(z−1)1+C(z−1)+D(z−1)2
for some constants A, B, C and D. Now we can express system of four equations (6) in an equivalent way by saying that the first four terms of the Maclaurin expansion of the rational function
P(w)Q(w):=A+Bw1+Cw+Dw2
must match the corresponding terms of the Maclaurin expansion
ψ(1+w)=s0+s1w+s2w2+s3w3+…,
in other words we have a single equation
A+Bw1+Cw+Dw2=s0+s1w+s2w2+s3w3+O(w4),w→0,
(note that we have introduced here a new variable w ≔ z − 1). Equation (8) tells us that the rational function P(w)/Q(w) is a [1/2] Padé approximation to the function ψ(1 + w). In general, a [p/q] Padé approximation to a function f is a rational function P(w)/Q(w) (with deg(P) = p and deg(Q) = q) that has the same first p + q + 1 terms in Maclaurin expansion as the function f(w).
It turns out that single equation (8) contains all the information necessary for finding the constants A, B, C and D. By multiplying both sides of equation (8) by Q (w) = 1 + Cw + Dw2 we obtain
A+Bw=(1+Cw+Dw2)(s0+s1w+s2w2+s3w3+O(w4)),w→0.
Identifying the coefficients in front of powers of w in both sides of the above equation we obtain a system of four linear (!) equations
{A=s0,B=Cs0+s1,0=Ds0+Cs1+s2,0=Ds1+Cs2+s3.
Note that this system of four linear equations can be solved very easily by first finding C and D from the third and fourth equations, and then substituting these results into the first and second equations would give us the values of A and B.
Now that we have found A, B, C, and D, and so we can compute and by noting that
(1+β1+w)(1+β2+w)=1+Cw+Dw2,
and then the constants and can be found by the formula
αi=P(−1−βi)Q′(−1−βi)=A+BwC+2Dw|w=−1−βi.
Remarkably, all we have done so far is the partial fraction decomposition for the rational function P(w)/Q(w) as in (7). This process, which can be done by hand, has provided us with the desired constants and and so with the approximant LT φ̃(2).
3.2. Extension to the approximation of any order
To generalize the method described in the previous subsection to arbitrary orders m and arbitrary choice z*, we follow the same steps and arrive at the problem of finding [m − 1/m] Padé approximant to the function ψ(z* + w), that is, instead of (7) and (8) we have
m∑i=1αiz∗+βi+w=a0+a1w+⋯+am−1wm−11+b1w+b2w2+⋯+bmwm=s0+s1w+s2w2+⋯+s2m−1w2m−1+O(w2m),
where This allows us to find the coefficients by solving a system of linear equations similar to (10) and then to obtain the required numbers and by doing the partial fraction decomposition in (11).
The main input for this algorithm is the sequence of coefficients These coefficients are typically not available in closed form, but they can be easily computed numerically. Indeed, we first compute the numbers
gk:=ϕ(k)(z∗)=(−1)k∫∞0xke−z∗x dF(x),k≥0,
to a high precision by a numerical quadrature (the double-exponential quadrature of Takahasi and Mori (1974) is particularly well suited for such calculations). Next we observe that
ddzϕ(z)=−ψ(z)ϕ(z).
Rewriting this identity in terms of Taylor series centred at z* gives us
∑k≥0gk+1(z−z∗)k/k!=−(∑n≥0sn(z−z∗)n)×(∑k≥0gk(z−z∗)k/k!).
Comparing the constant term in the Taylor series in the left-hand side and the right-hand side of the above equation we find that s0 = −g1/g0, and comparing the coefficients in front of (z − z*)k gives us
sk=−1g0(gk+1k!+k−1∑i=0sigk−i(k−i)!),
which allows to compute sk recursively for all k ≥ 1.
3.3. A simple numerical example and a question arising from it
To illustrate our method on a numerical example of actuarial interest, let us assume that X is distributed Weibull with the probability density function (PDF)
f(x)=(3/4)x−1/4exp(−x−3/4),x≥0.
Weibull distribution has been frequently chosen to model insurance risks (Mikosch 2009; Klugman, Panjer, and Willmot 2012 for general discussions).
We fix m = 2 and z* = 1; by computing numerically the integral in (12) we calculate
g0≈0.5193711,g1≈−0.2123717,g2≈0.2179689,g3≈−0.3665409,g4≈0.8649004.
Then we use (14) to find
s1≈0.4089017,s2≈−0.252478,s3≈0.1638276,s4≈−0.1094817
and solving system of linear equations (10) we obtain
A≈0.4089017,B≈0.1766115,C≈1.0493709,D≈0.2472855.
The polynomial has two roots -2.7985663 and thus we find 1.79856636 and Using the formula we find and Thus we have found an approximation to the Weibull distribution of interest. Namely, we have approximated with the help of such that the latter RV is equal in distribution to with
We conclude this section with an important observation, which paves the path to the introduction of the class of GGCs latter on in the next section. Namely, let the RV X be distributed Weibull with the following PDF (the shape parameter is now greater than one)
f(x)=(3/2)x1/2exp(−x3/2),x≥0.
For this setup, we find that and do not belong to which shows that our algorithm does not always give a legitimate approximation in the form with This outcome is rather unfortunate, but similar inconveniences have been encountered in the context of other MMAs (e.g., Cossette et al. 2016).
This raises an important question:
Does there exist a (rich) class of CDFs for which the Padé approximations described above always yield meaningful results?
In the next section we show that the answer to this question is in affirmative, and we also discuss the convergence of our refined MMA method.
4. Generalized gamma convolutions
The class of Generalized Gamma Convolutions comprises distributions which are weak limits of the RVs of the form where and It seems that GGCs were first used by Thorin in 1977, who employed their properties to prove that the log-normal distribution is infinitely divisible (e.g., Bondesson 1992 for an excellent discussion).
The most convenient way to describe the class of GGCs is via LTs. Note that for a RV which is our approximant from Section 3, we have
E[exp(−z˜X(m))]=m∏i=1E[exp(−zΓi)]=m∏i=1(1+z/βi)−αi=exp(−∫∞0ln(1+z/t)U( dt)),
where is a discrete measure having support at points with mass Thus, the following result is not surprising.
Proposition 1. (Thorin 1977; see also Bondesson 1992) The distribution on [0, ∞) of the r.v. X is a GGC if and only if its Laplace transform is
ϕ(z):=E[exp(−zX)]=exp(−az−∫∞0ln(1+z/t)U( dt)) for Re(z)≥0
where a ∈ [0, ∞) is a constant, and U(dt) is a positive Radon measure, also called Thorin measure, which must satisfy
∫∞0min(|ln(t)|,1/t)U(dt)<∞.
It turns out that the algorithm outlined in Section 3 always produces meaningful results when the RV being approximated has a CDF that belongs to the class of GGCs. By meaningful results we mean that the algorithm produces a set of positive numbers and that determine the approximant where Moreover, it can be shown (Furman, Hackmann, and Kuznetsov 2019) that, as the LTs converge to the LT exponentially fast and uniformly in on compact subsets of One may wonder at this point whether the class of GGCs is rich enough. We note in this respect that it comprises, e.g., such important distributions for actuarial applications as gamma, inverse gamma, inverse Gaussian, Pareto, log-normal, and Weibull with the shape parameter less than one, among a great variety of other distributions.
To summarize the findings of Sections 3 and 4, we emphasize that our MMA (i) converges very fast, (ii) always provides legitimate outcomes if the risk RV to be approximated has a CDF in the class of GGCs, (iii) yields unique parameters of the approximant CDF, and (iv) is optimal in the sense that only 2m parameters are required to match the first 2m moments.
We conclude this section with outlining the cause for the algorithm described in Section 3 to be so well suited for the RVs having CDFs in the class of GGCs. This reason in fact stems from the fact that the function ψ(z) = −d/dzln(𝔼[exp(−zX)]) is given by
ψ(z)=∫∞0U( dt)t+z,
which can be easily obtained from (15). Functions of the form are called Stieltjes functions, and they have been shown to enjoy many nice analytical properties. In particular, it has been proved that Padé approximations to such functions always exist and converge exponentially fast and uniformly in z on compact subsets of (see Baker and Graves-Morris 1996). Since the algorithm outlined in Section 3 is essentially a Padé approximation method, this explains why RVs with CDFs in the class of GGCs fit perfectly within our approximation scheme.
5. Gaver-Stehfest algorithm
At this point of the discussion, we have hopefully convinced the reader that there is a mathematically sound way to approximate the risk RV X having a CDF in the class of GGCs with the help of an approximant RV X̃. The solution, however attractive, involves the corresponding LTs, that is φ̃ ≈ φ(z). However, our ultimate goal is to find the CDF of the approximant RV X̃, denoted by F̃. Thus, the remaining step is to recover this CDF from the LT φ̃. Doing that is a classical problem in analysis, and a variety of solutions exist. One popular method is to use Bromwich integral, which requires integration over a path in the complex plane. Another method, and this is what we do in the present paper, is via the Gaver-Stehfest algorithm. The main difference between the Gaver-Stehfest algorithm and the one based on the Bromwich integral, as well as most other Laplace inversion methods, is that it uses only the values of the Laplace transform on the positive real line and does not require any complex numbers. This method was invented in 1970 by Stehfest (1970), by improving upon the earlier method of Gaver, and since then it has been successfully used in many areas of applied mathematics, including in probability and statistics (Abate and Whitt 1992; Kou and Wang 2003), actuarial science (Badescu et al. 2005) and mathematical finance (Schoutens and Damme 2011).
The Gaver-Stehfest algorithm is very simple and easy to implement. To introduce it, consider a function f and its Laplace transform
ϕ(z):=∫∞0e−zxf(x)dx,
where we assume that φ(z) is finite for all z > 0. For all integers m ≥ 1 we define
fm(x):=ln(2)x−12m∑k=1ak(n)ϕ(kln(2)x−1),x>0,
where the coefficients are defined as follows:
\begin{array}{c} a_{k}(m):=\frac{(-1)^{m+k}}{m!} \sum_{j=[(k+1) / 2]}^{\min (k, m)} j^{m+1}\binom{n}{j}\binom{2 j}{j}\binom{j}{k-j}, \\ m \geq 1,1 \leq k \leq 2 m . \end{array}
It is known (Kuznetsov 2013) that the approximations fm(x) converge to f(x) if f is continuous at x and of bounded variation in a neighborhood of x. There is also a lot of numerical evidence that the approximations fm(x) converge to f(x) very fast, provided that f is smooth enough at x (e.g., Abate and Whitt 1992; Davies and Martin 1979). When using the Gaver-Stehfest algorithm one should be careful with the loss of significant digits in the sum (17). This is due to the fact that the coefficients ak(m) are very large (for large k and m) and of alternating signs. This problem is readily solved by using any high-precision arithmetic package.
6. Illustrative examples with log-normal, Pareto, and Weibull risks of varying tail thickness
In this section, we demonstrate the usefulness of our new MMA method by applying it to a number of examples of actuarial interest. More specifically, motivated by numerical examples in Bahnemann (2015), we consider applications to risks that are distributed log-normally, Pareto of the second kind, a.k.a., Lomax, and Weibull. These distributions have been routinely chosen to model insurance risks (e.g., Kleiber and Kotz 2003; Mikosch 2009; Klugman, Panjer, and Willmot 2012 for a general discussion).
In what follows, we denote the CDFs of the log-normal, Lomax, and Weibull distributions, by, respectively, FL, FP, and FW. All these CDFs have explicit forms given by
\begin{aligned} F_{L}(x ; \mu, \sigma)&=\frac{1}{2}\left[1+\operatorname{erf}\left(\frac{\ln x-\mu}{\sigma \sqrt{2}}\right)\right], \\ &\qquad \qquad \qquad x>0, \mu \in \mathbb{R}, \sigma>0, \end{aligned} \tag{18}
F_{P}(x ; \alpha, \beta)=1-\left(\frac{\beta}{x+\beta}\right)^{\alpha}, \quad x \geq 0, \alpha>0, \beta>0, \tag{19}
F_{W}(x ; \beta, \delta)=1-e^{-(x / \beta)^{\delta}}, \quad x \geq 0, \beta>0, \delta>0 . \tag{20}
In the above, σ, α and δ are shape parameters that stipulate how heavy-tailed the corresponding distributions are. Namely, in the case of the log-normal distribution, larger values of σ imply heavier right tails, whereas in the case of the Lomax and Weibull distributions, smaller values of α and δ, respectively, suggest heavier right tails. Interestingly, there has been ample practical evidence that these are the parameterizations that correspond to the heavier tails that are of particular interest in non-life insurance applications, yet in the theoretical literature the light-tailed examples prevail (e.g., Cossette et al. 2016; Tao, Provost, and Ren 2016 for recent references). In the rest of this section, we consider both heavy-tailed and light-tailed parameterizations of the CDFs FL, FP, and FW. Our choices of parameters are inspired by Bahnemann (2015).
6.1. Stand-alone risks
We begin by approximating CDFs (18), (19), and (20). Genuinely speaking, these approximations are not the ultimate goal of this paper, and hence we remind the reader that: (i) after we have the approximations for the just-mentioned CDFs of the stand-alone risks RVs, the CDFs of the aggregate risk RVs are obtained with the help of equations (1) and (2), (ii) in the context of the stand-alone risks, we are able to evaluate the accuracy of an approximation by comparing the approximant CDF with the actual CDF, and thus the discussion in this subsection can serve as an important evaluation of the various MMAs tested here.
To explore the effectiveness of the distinct MMAs, we employ the Kolmogorov-Smirnov (KS) metric to measure how close the distribution of an approximation is to the desired distribution. The KS distance of an approximant (with ) to the (with ), denoted is given by
d_{K S}(\tilde{X}, X)=\sup _{x \geq 0}|\tilde{F}(x)-F(x)| .
This metric yields the worst distance and, thus, small values of dKS suggest the approximation is good on the entire domain. However, on a different note, relatively large values of dKS do not necessarily mean the approximation is worthless, as it can turn out very reasonable in some regions of the CDFs domain.
In the examples below, we illustrate the effectiveness of our approximation by comparing it with three simple MMAs: the normal approximation, the normal power approximation (NPA), and the shifted gamma approximation, when applicable. These three MMAs are referred to as “the most commonly cited in practice” by Hardy (2004). In addition, we compare our approximation with the mixed Erlang distribution (MED) approach of Cossette et al. (2016), when applicable. The MED method uses the first m moments of a risk RV to determine a mixture of Erlang distributions for approximating this RVs CDF. We use the results in Cossette et al. (2016), for the log-normal distribution (μ = 0, σ = 0.5) and apply their algorithm to our additional cases of interest (Pareto and Weibull), when applicable. (When implementing the MED method, we only considered moment-matching of orders m = 3 and m = 4, as with m ≥ 5 the method requires a large number of computations.)
In what follows, we denote the CDFs of the log-normal, Lomax, and Weibull distributions, by, respectively, and All these CDFs have explicit forms given by
Example 1. To start off, let us consider log-normally distributed risk RVs. The log-normal distribution has been found appropriate for modeling losses originating from a great variety of non-life insurance risks (e.g., Mikosch 2009, Klugman, Panjer, and Willmot 2012). More specifically, Kleiber and Kotz (2003) mention applications in property, fire, hurricane, and motor insurances, to name just a few (also, e.g., Dropkin 1964; Bickerstaff 1972; O’Neill and Well 1972). Furthermore, the standard formula of the European Insurance and Occupational Pensions Authority explicitly assumes the log-normality of insurers’ losses (EIOPA-14-322 2014).
Table 1 provides the KS distances of several approximations for the parameter sets (μ = 0, σ = 0.5), (μ = 1.5240, σ = 1.2018), and (μ = 5.9809, σ = 1.8). The choice of the larger value of the σ parameters is motivated by Example 5.8 in Bahnemann (2015), whereas the choice of the smaller one is due to Cossette et al. (2016) and Dufresne (2007). As the parameter σ gets larger, it becomes increasingly difficult to obtain a valid approximation with any of the methods (this is perhaps the reason why in the examples manifesting in the academic literature, smaller values of the σ parameter are very common). With σ = 1.2018 and σ = 1.8, the MED method does not produce potential solutions using the parameters m = 4 and l = 70, in the former case, and m = 3, or 4 and l = 70, in the latter case. As suggested in Cossette et al. (2016), this can be remedied by increasing the parameter l; however, increasing this parameter too much results in the method being computationally infeasible.
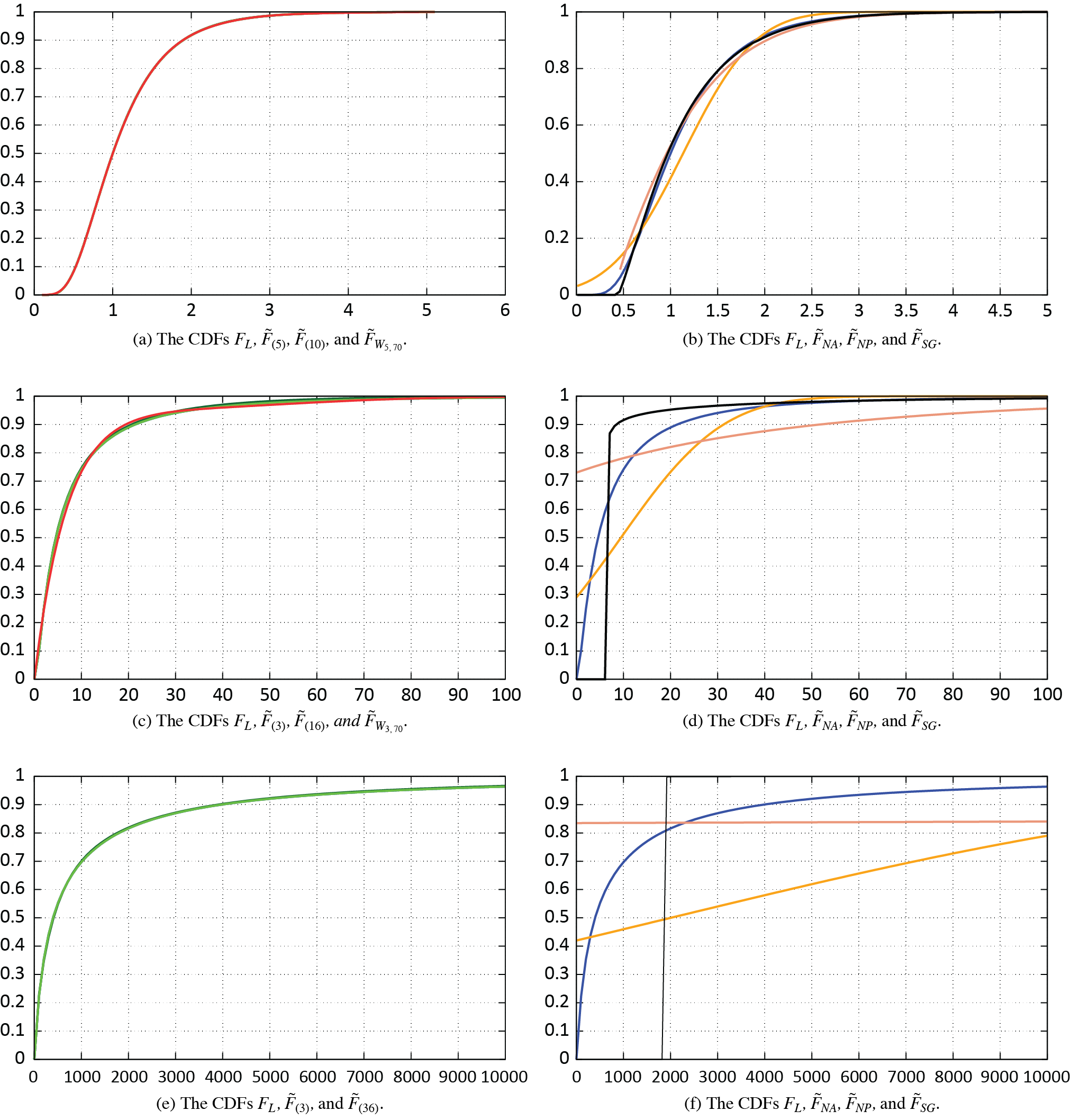
Figure 1 provides the plots of the approximating CDFs in Table 1 as well as the actual CDF FL (in blue). Figures 1a, 1c, and 1e depict our approximations (dark green and light green, where light green corresponds to the better approximation) and the MED approximation (in red, when applicable). Figures 1b, 1d, and 1f depict the simple moment-matching methods: NA (orange), NPA (salmon), and SGA (black). Apparently, the NA and NPA approximations are inadequate for the more skewed log-normal cases, that is, for the parameterizations (μ = 1.5240, σ = 1.2018) and (μ = 5.9809, σ = 1.8). This is not surprising, as it is well known that the NPA provides fairly accurate results for the skewness values not exceeding one (e.g., Ramsay 1991), whereas the two aforementioned cases of the log-normal distribution lead to the skewness values of 11.23 and 136.38, respectively. In the context of the SGA, higher skewness values imply very small scale parameters, and these in turn result in a nearly vertical rise in the corresponding CDF, thus aggravating the accuracy significantly.
.png)
Example 2. The next distribution we consider is Lomax. As in the case of the log-normal distribution discussed earlier, there is ample of evidence that the Lomax distribution is an adequate model to describing non-life insurance risks. We refer to Seal (1980) for a list of references, and in particular to Benckert and Sternberg (1957), Andersson (1971), and Ammeter (1971) for fire insurance losses, and Benktander (1962) for automobile insurance losses.
Table 2 provides the KS distances for two parameter sets: (α = 2.7163, β = 16.8759), and (α = 2, β = 3000) (e.g., Example 5.7 in Bahnemann 2015). Recall that the mth moment of the Pareto distribution is finite only when m < α. Consequently, most of the existing MMAs are not applicable for these examples; in the first case, only the NA method and MED method with m = 2, are applicable. In contrast, our approximation is feasible in both cases and works well.
Figure 2 compares the plots of the CDFs in Table 2 against the actual CDF FP (in blue). Figures 2a, and 2c depict our approximations (dark green and light green, where light green corresponds to the better approximation) and the MED approximation (in red, when applicable). Figure 2b depicts the normal approximation (orange).
.png)
Example 3. The final distribution we consider is Weibull, which is a GGC when δ < 1, and these are the values of interest when modeling non-life insurance risks (Bahnemann 2015). Very much like the log-normal and Pareto distributions, the Weibull distribution has been commonly chosen to model insurance data. We refer to Mikosch (2009); Klugman, Panjer, and Willmot (2012) for a general discussion, as well as to Hogg and Klugman (1983) for an application to hurricane loss data.
Table 3 provides the KS distances for the parameters β = 220.653 and δ = 0.8 (e.g., Example 2.13 in Bahnemann 2015).
Figure 3 compares the plots of the CDFs in Table 3 with the actual CDF FW (in blue). Figure 3a depicts our approximations (dark green and light green, where light green corresponds to the better approximation) and the MED approximation (red). Figure 3b depicts the simple moment-matching methods: NA (orange), NPA (salmon), and SGA (black).
.png)
In summary, we note with satisfaction that the proposed refined MMA method has performed exactly as expected in all of the three examples discussed above. That is, it has outperformed all other MMAs in the cases when the latter are applicable (e.g., the lighter-tailed log-normal CDFs with σ = 0.5, σ = 1.2018 and the Weibull CDF), and it has provided a feasible and accurate alternative, otherwise (e.g., the heavier-tailed log-normal CDF with σ = 1.8 and the Pareto CDFs).
We conclude this section by addressing a request of a referee to report the times required to compute the CDFs in Tables 1, 2, and 3 using the MMA approach put forward herein. These times are provided in Table 4. (All calculations were performed on a laptop computer with 12 GB of memory and an IntelCoreTM i5-5200U CPU.) The numbers represent the time, in seconds, required to perform the Gaver Stehfest algorithm described in Section 5 with m = 25 and arithmetic precision to 300 digits and precomputed coefficients of the approximant Laplace transforms. Remarkably, the computation speed can be significantly enhanced (without dramatic drop in accuracy) by reducing the degree of precision and using a smaller value for m. Specifically, we set m = 10 and the arithmetic precision to 100 digits. Then in, e.g., the log-normal case with μ = 5.9809 and σ = 1.8, F̃(3) and F̃(36) can be computed in 0.948 and 9.396 seconds, respectively, while achieving the KS distances of 7.968e−3 and 1.123e−06, respectively.
We further turn to the aggregate risk RVs, and we demonstrate that the advantages of our approximation method carry on.
6.2. Aggregate risks with full and partial coverage
We begin by approximating the CDF of the RV Sn = X1 + . . . + Xn - the individual risk model (e.g., Dhaene and Vincke 2004), and the CDF of the RV SN = X1 + . . . + XN - the collective risk model (e.g., Goovaerts 2004). In the former case, we sum n independent RVs with possibly different distributions. In the latter case, we sum a random number N of IID RVs. Furthermore, as ceding insurers often turn to a reinsurer in order to reduce the variability of the underwriting outcomes, we conclude the discussion in this section with the stop-loss reinsurance setup. We note briefly that due to Borch (1969), the variance of the cedent insurer’s payouts is the smallest under the stop-loss reinsurance contract. Irrespective of whether coverage modifications of the aggregate risks are allowed or not, we assume that the stand-alone risks have CDFs (18), (19), and (20). As explicit CDFs of the aggregate risks are not available, we use the Monte-Carlo (MC) method as a benchmark.
Example 4. Consider the CRM, SN = X1 + . . . + XN, where N has a Poisson(λ) distribution, and Xi, i = 1, . . . , N has a log-normal distribution with parameters μ = 5.9809, and σ = 1.8 (Bahnemann 2015, Example 5.9). The Laplace transform of the RV SN is given by
\phi_{S_{N}}(z)=\exp \left[\lambda\left(\phi_{X_{1}}(z)-1\right)\right] .
Thus we obtain an approximation for φ(z) ≔ 𝔼[exp(−zSN)] as follows
\tilde{\phi}(z)=\exp \left[\lambda\left(\tilde{\phi}_{1}(z)-1\right)\right] .
Then we evoke the Gaver-Stehfest algorithm to obtain the approximating CDF of the RV SN.
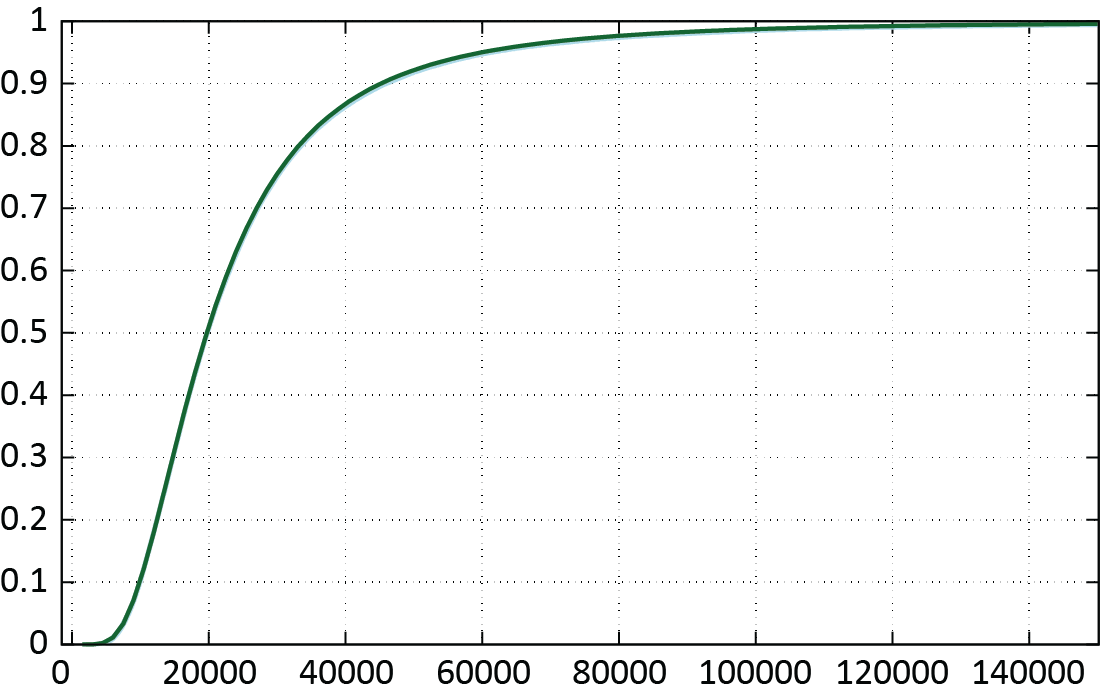
Figure 4 summarizes the results. Namely, Figures 4a, 4c, and 4e show the CDFs of our approximation (dark green; succinctly ) and the CDF produced by means of MC simulation with samples (blue; succinctly ), for and 15 , respectively. In each one of our approximations, we used to approximate the underlying log-normal severity distribution. Figures 4b, 4d, and 4f depict the MC CDF (blue), as well as the CDF obtained via NA (orange), NPA (salmon), and SGA (black).
___and_the__x_i_.png)
Example 5. Consider the IRM, Sn = X1 + . . . + Xn, with n = 15. We assume Xi, i = 1, . . . , 5, are distributed log-normally with parameters μ = 5.9809, σ = 1.8, Xi, i = 6,..10, are distributed Pareto with parameters α = 2, β = 3000, and Xi, i = 11, . . . , 15 are distributed Weibull with parameters β = 220.653, δ = 0.8; all independent. The LT of the aggregate risk RV Sn, denoted by φ(z) ≔ 𝔼[exp(−zSn)], is given by
\phi(z)=\left(\phi_{X_{1}}(z) \cdot \phi_{X_{6}}(z) \cdot \phi_{X_{11}}(z)\right)^{5}.
Thus we approximate the CDF of the RV Sn by first approximating the LTs of the severities and then evoking the Gaver-Stehfest method on
\tilde{\phi}(z)=\left(\tilde{\phi}_{1}(z) \cdot \tilde{\phi}_{6}(z) \cdot \tilde{\phi}_{11}(z)\right)^{5} .
Figure 5 shows our approximation of the CDF of (dark green; denoted by ) and the CDF obtained by means of MC simulation (blue). In this case, we used approximation orders and to approximate the underlying log-normal, Pareto, and Weibull CDFs, respectively. Note that the RV has only one finite moment and, hence, other MMAs are not applicable.
_(36)_(30)___and__f_m__for_the_individual_risk.png)
Example 6. In the previous examples we considered aggregate risks with full coverages, that is there were no deductibles, policy limits, or other policy modifications applied by the insurer to reduce the payouts of the benefits. However, this is not always the case. Consequently, in this example, we explored the so-called stop-loss r.v. Sr,l, which is given, for positive retention r and limit l, by
S_{r, l}=\left\{\begin{array}{ll} 0, & X<r \\ S-r, & r \leq X<r+l \\ l, & r+l \leq X<\infty \end{array}\right.
where the RV is the aggregate risk RV within either the IRM or CRM. It is a standard exercise to show that the CDF of the RV is given by
F_{r, l}(s)=\left\{\begin{array}{ll} \mathbb{P}[S \leq s+r), & s<l \\ 1, & l \leq s \end{array} .\right.
Consequently, the CDF of the risk RV is approximated similarly to the case in Example 4 (if the RV refers to the aggregate risk within CRM), and similarly to the case in Example 5 (if the RV refers to the aggregate risk within IRM). To demonstrate, we consider the following CRM: Poisson(15), and the 's are IID with log-normal distribution and the parameters For the sake of the demonstration, we set and Figure 6 depicts the approximating of the risk (dark green) and the CDF obtained by means of the MC simulation (blue).
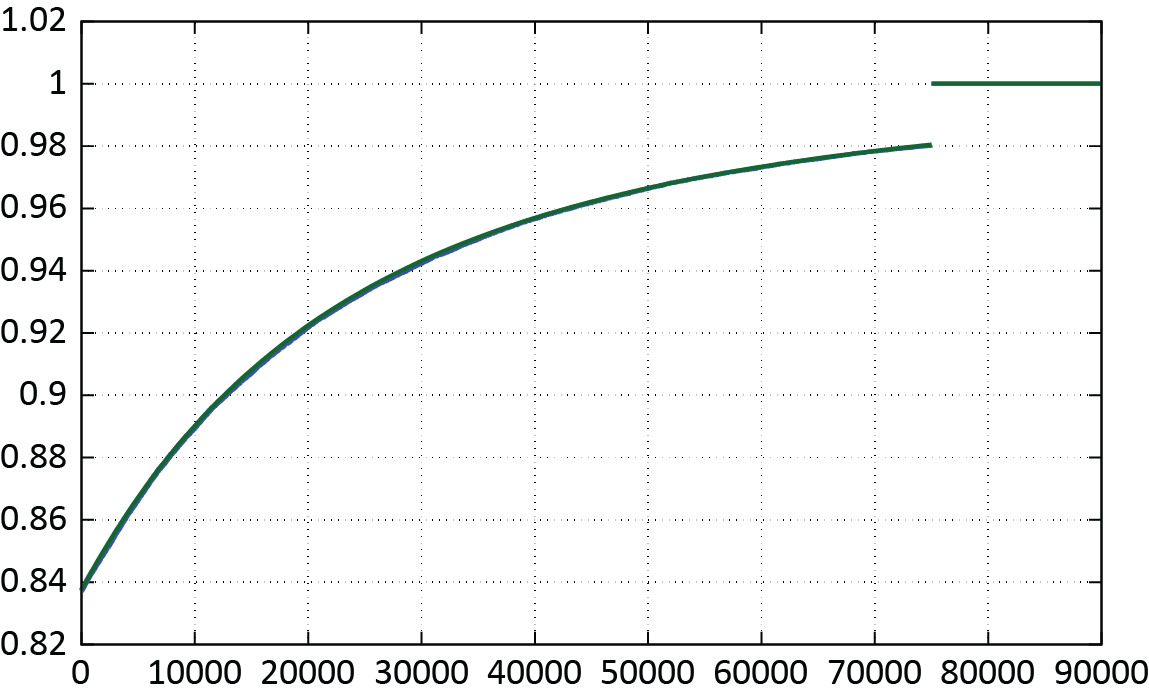
Acknowledgments
We are grateful to the Casualty Actuarial Society (CAS) and the Natural Sciences and Engineering Research Council (NSERC) of Canada for grants supporting our research. Constructive criticism and insightful suggestions of two referees and the editor are also greatly appreciated.