1. Introduction
Large language models (LLMs), a subset of artificial intelligence (AI) systems, have revolutionized the way industry experts, as well as novices, perceive the future of models built on deep neural networks and trained on large corpora of datasets. As of now, LLMs are being utilized in a wide range of applications across various industries, including medicine, education, finance, and engineering (Hadi et al. 2023). ChatGPT and some other chatbots that use LLMs are becoming some of the most widely used LLM-based applications. In the middle of this revolution, the question of interest for us is how actuaries and insurance professionals can use them for their tasks. Although other industries have leveraged LLMs beyond simply generating text and answering questions, it remains unclear how actuaries can benefit from this growth. Can LLMs enable actuaries and industry professionals to conduct groundbreaking analyses of complex data streams, allowing for the discovery of hidden patterns while improving prediction accuracy and streamlining complex administrative functions throughout their systems? In this research, our motive is to answer whether LLMs can outperform standard machine learning techniques for classification tasks in the workers’ compensation insurance arena. The question stemmed from our reading of “Financial Statement Analysis with Large Language Models” (Kim, Muhn, and Nikolaev 2024). In this paper, the authors demonstrate that LLMs exhibit a relative advantage over human analysts when it comes to analyzing financial statements. They also concluded that LLMs can perform at the same level as narrowly trained, state-of-the-art machine learning models specifically designed to analyze financial statements. The paper has been retracted temporarily to revalidate its findings; however, the core idea remains of interest to researchers. In our own research, we aimed to investigate the potential utility of using LLM in workers’ compensation cases. In the next subsection, we will provide an overview of the workers’ compensation insurance program, as it is one of the two main components of this research.
1.1. Workers’ compensation insurance
The United States launched Workers’ Compensation as its initial social insurance program before developing Social Security and unemployment insurance systems. Workers’ Compensation exists to provide specific benefits, as defined by law, to employees who suffer injuries or develop illnesses due to their work-related activities. Workers’ compensation insurance policies cover medical treatment, temporary and permanent disability wage replacement, vocational rehabilitation services, supplemental job displacement assistance, and death benefits to dependents. The benefits a claimant can receive are determined by the specific details of their case.
The foundation of this system rests on the “exclusive remedy” doctrine. This rule establishes that employers are responsible for workplace injuries, regardless of who is at fault, and that workers’ compensation benefits become the sole legal remedy available to injured employees against their employer. Under this framework, employees generally cannot bring separate tort actions against their employer to seek additional damages from the same workplace incident (Workers Compensation Insurance 2016). The payments received by workers under workers’ compensation cases are known as indemnity payments and usually cover about two-thirds of lost wages. These payments depend on state regulations, which set minimum and maximum limits (Butler and Worrall 1983). The definition of a compensable injury has expanded beyond accidents to include long-term health issues from work. It’s important to distinguish “impairment” (medical loss of function) from “disability” (how much the impairment affects work). Compensation typically covers partial lost wages during recovery and lump sums for lasting disability, plus medical and rehab costs. Employers often invest in extra rehab services to help employees recover and return to work, which can be more cost-effective than paying for permanent disability (Guyton 1999).
Workers’ compensation claims are handled by state boards, but decisions can be appealed in court. However, the use of the state board process is more cost-effective than formal court litigation. Most of the time, states require employees to go through the state board or a judge designated for workers’ compensation cases before moving to higher courts. The workers’ compensation insurance workflow can vary from state to state, depending on local regulations. However, in general, the following process can be observed (New York City Bar Association 2025; California Department of Industrial Relations, Division of Workers’ Compensation 2023; Texas Department of Insurance, Division of Workers’ Compensation 2025). When job-related injuries occur, employees must inform their employers immediately. After the employer files the claim with the workers’ compensation insurance carrier, the carrier investigates and decides whether to approve or deny it. If the claim is denied or disputed, the next step is dispute resolution, which is usually handled by the state board. After exhausting the state board process, the employee may have a narrow path to litigate the case in the state court (https://www.ic.nc.gov/faqs.html).
At this point, we can identify several stakeholders with vested interests in the outcomes of workers’ compensation insurance claims. First, we have three primary stakeholders: the employee, the employer, and the insurance carrier. Beyond these, we have a state-designated regulatory authority that oversees claim disputes. Finally, the general public may also be interested in how these cases are handled. In this research, we take the perspective of an analyst in an insurance company and aim to understand how these claim disputes are ultimately resolved at the state regulatory board. This understanding would help the company decide whether denying a certain claim type is prudent by leveraging the insight gained from the predictive model.
The use of data analytics in the workers’ compensation insurance arena is not new to many. Traditional statistical-based methods and machine learning techniques have been employed to identify claim frequency, severity, injury rates, and many other critical factors (Meyers et al. 2018; Mathews 2016). Predictive models are applied to understand the cause of occupational injury, identify the most efficient healthcare provider for injured employees, and forecast compensation (Moniz 2019; Vinit Patwa 2024). Having discussed the workers’ compensation insurance process and the application of statistical and machine learning approaches therein, we will next proceed to discuss LLMs.
1.2. LLM models
LLMs are a foundational technology in the area of AI. Initially developed as a subfield within natural language processing (NLP) to enhance natural language understanding (NLU) and the generation of natural language (NLG), LLMs have become a focal point of the modern AI revolution (Chang et al. 2024). LLMs are generally characterized by their substantial parameter counts and extensive training on large datasets. Nowadays, LLMs have moved from training on traditional text corpus to computer codes, images, and many other formats, introducing multimodal models. These LLMs have demonstrated considerable potential across various industries, particularly those that analyze and process vast quantities of textual information.
The insurance industry is characterized by its use of large amounts of text data, which stem from claim descriptions, doctors’ notes, policy documents, customer communications, and various other sources. Traditionally, these unstructured text data were discarded, or used for qualitative understanding, or coded into categorical variables to use in traditional machine learning models. The traditional methods and techniques from NLP that can be used in the insurance industry were extensively discussed in Ly, Uthayasooriyar, and Wang (2020). Now, with the introduction of LLMs, the insurance industry is poised to reap the capabilities of new LLMs. Insurers can now utilize LLMs for tasks like client interaction, claims processing, underwriting, and automating processes that were previously handled manually. The challenges of implementing LLMs in the insurance industry range from model fairness and transparency to possible legal and ethical consequences (Ferrer et al. 2021).
According to Zhao et al. (2025), language models can be divided into four types: statistical language models such as n-gram models, neural language models such as word2vec, pretrained language models such as BERT, and LLMs such as GPT-4. The authors of this article describe LLMs as scaled-up versions of pretrained language models. However, they emphasize the unexplained “emerging abilities” of LLMs due to a large number of parameters in these models. The authors also discuss how the research community would struggle to develop their own LLMs due to the cost associated with developing these models from the ground up. Key categories of pretrained language models and LLMs can be divided into four types: decoder-only models, encoder-only models, encoder-decoder models, and multimodal. In language models, encoders are used to understand the input text sequence, and decoders are used to generate the output text sequence. Examples of decoder-only models are GPT family models such as GPT-2 and -3. An example of an encoder-only model is BERT. T5 and BART are examples of encoder-decoder models. Finally, Google Gemini and newer versions of OpenAI models are examples of multimodal LLMs, which use non-text data in the training phase. The next subsection is devoted to understanding current applications of LLMs in workers’ compensation insurance.
1.3. Text data, workers’ compensation insurance, and LLMs
Even though workers’ compensation insurance products are rich with textual information, the use of LLMs is still scarce. This marks a significant departure from other fields, such as finance, engineering, and medicine, where LLMs have gained rapid traction. Nevertheless, here we summarize several research studies conducted at the crossroads of LLMs, insurance, and actuarial science.
A general framework for analyzing the consistency of text in insurance claim reports derived from various sources was discussed in D. Li et al. (2025). The authors used ChatGPT and distance metrics to measure the discrepancies in texts in insurance claim reports. In this paper, authors also mentioned the scarcity of literature in use of LLMs to solve practical needs and applications of insurance and actuarial science. Possible use of LLMs in insurance were discussed in C. Cao et al. (2024). It proposed that the integration of LLMs allows insurance companies to improve customer service response time, streamline the claim process, and enhance the accuracy of risk assessment. However, the authors also mentioned unique challenges the insurance industry faces primarily due to the sensitive nature of the data and the high standards set forth by regulators. A systematic exploration of the effectiveness of GPT-4 in various multimodal tasks in insurance was conducted by Lin et al. (2024). The research used four types of insurance products: auto, health, agriculture, and property, to analyze how effective GPT-4 was at various tasks in a given insurance type. For example, for auto insurance, the authors analyzed whether GPT-4 is effective in vehicle underwriting, detecting dangerous driving behavior, vehicle claim processing, and fraud detection. The researchers concluded that GPT-4 is remarkable in its robust and comprehensive understanding of insurance scenarios. However, they also mentioned that GPT-4 struggles with detailed risk assessment and suffers from hallucination in image understanding. Applications of LLM specifically in actuarial science were discussed by Balona (2024).
At this point, we come back to our own research questions, which we pose formally in the next section. As of now, it is clear that LLMs offer substantial opportunities for the insurance industry to reshape how it uses text data collected through various sources.
2. Problem statement and hypotheses
An employee who suffers a workplace injury has the right to file a workers’ compensation claim against their employer or the employer’s designated insurance provider. After reviewing the claim, the employer may choose to reject it fully, offer a partial payment, or grant total compensation. The worker must decide whether to accept the employer’s resolution or challenge it by filing a dispute with state regulatory bodies. Specialized state commissions handle workers’ compensation disputes in most states. These commissions fulfill the role of dispute resolution bodies, but their proceedings follow a trial-like format with legal representatives present for both the employee filing the claim and the defending employer or insurance carrier. The hearing precedes the commission’s examination of evidence from both sides, including expert witness testimony, to determine whether the injury relates to work activities or other factors. The commission delivers a binding resolution that determines the winning party and defines settlement terms when applicable. Employees have a narrow pathway to challenge unfavorable commission decisions by taking their case to the established court system if they believe the decision to be incorrect.
Our research aims to investigate how historical workers’ compensation case records can aid in predicting outcomes for new cases using LLMs. We specifically focus on the following question: Can off-the-shelf, non-tuned, commercial LLMs outperform other specialized NLP techniques in predicting likely outcomes for workers’ compensation cases?
The question comes under the text classification task. We will use the following traditional NLP-based models versus LLM models to predict the likely outcome of workers’ compensation cases. For traditional NLP models, in order to convert text to numerical features, we used TF-IDF, word2vec, and BERT coupled with classification techniques such as random forest, gradient boosting, and XGBoost. For LLM models, we used eight: deepseek-chat (deepseek-v3), claude-3-haiku, gemini-1.5-pro, gemini-1.5-flash, gemini-2.0-flash, gpt-3.5-turbo, gpt-4.1-mini, and o4-mini.
2.1. Text classification of workers’ compensation data
Text classification is one of the main topics in the NLP domain. The purpose of text classification under supervised learning is to determine the category or label to which a given piece of text belongs (Campesato 2022). This touches on a variety of topics: fraud detection (Y. Wang and Xu 2018), plagiarism detection (Barrón-Cedeño et al. 2013), opinion and sentiment classification (Abbasi, Chen, and Salem 2008), and topic modeling, to name a few. With the explosive proliferation of digital documents, traditional manual text classification has become prohibitively labor-intensive and costly (Q. Li et al. 2022). This has led to the development of various machine learning–based models to automate the text classification process. According to Q. Li et al. (2022), text classification models can be divided into two broad categories: traditional statistical and machine learning models, and deep learning models. However, recent advancements in LLMs necessitate a reclassification of text classification models into three distinct categories: traditional statistical and machine learning models, traditional deep neural network models, and pretrained LLMs.
Text classification research within the insurance domain, particularly in actuarial science, has been relatively limited compared to other fields. However, textual information is abundant in insurance, encompassing sources such as medical reports, police reports, accident narratives, various correspondence letters, and repair estimates, to name a few. As mentioned in GV et al. (2021), these documents serve as the foundation for insurance claim processing workflows and are integral to various other business operations. Automating the classification and extraction of pertinent information from these documents has the potential to substantially enhance the efficiency of numerous business processes, curtail manual operational expenses, and elevate both the quality and reusability of critical data.
The latent Dirichlet allocation (LDA) text analysis approach to identifying insurance fraud in automobile insurance was discussed in Y. Wang and Xu (2018). This approach combined traditional numerical and categorical features from claims data with topical features extracted from textual descriptions using LDA. These features were then input into a deep neural network to predict the likelihood of a claim being fraudulent. In Kindbom (2019), researchers compared a deep neural network called long short-term memory (LSTM) with a simpler, interpretable random forest model for classifying insurance-related customer messages as questions or non-questions. These messages were received by the Swedish insurance company Hedvig from their customers. To train the random forest classifier, the authors used two variants of the bag-of-words (BoW) method to convert messages into feature vectors and tuned several of the model’s hyperparameters. For the LSTM model, they employed word2vec for word embedding and also tuned various hyperparameters. The study concluded that while the LSTM model marginally outperformed the simpler random forest model, both were outperformed by human classification. To establish a human baseline, the researchers enlisted eight randomly selected individuals.
Text classification in the worker’s compensation domain is almost nonexistent. Yamin et al. (2016) used a narrative text analysis method and workers’ compensation data to identify whether injuries are machine-related or not. Another study used Alaska workers’ compensation data to classify nonfatal work-related injuries (Lucas et al. 2020). Even though this study mentioned the free-from-text data, these were limited to claimant occupation and resident city, along with other coded categorical and numerical variables. Y. Cao, Chen, and Quan (2024) analyzed the risk an insurer faces due to litigation. In this research, the authors used more than 300,000 litigation outcome documents from a Chinese court. These documents were preprocessed, tokenized, and then embedded into various dimensional vectors using methods such as BERT, RoBERTa, BGE, and LLaMA. Then the authors either used a neural network classifier to predict whether the plaintiff won or lost, or fine-tuned those pretrained LLM models. The method was applied to both the original Chinese language texts and their English translations. This research can be directly related to our research discussed in this paper.
Our research fills one of the main gaps in the workers’ compensation domain by analyzing case records and predicting the likely outcome using LLMs. It will be equally valuable to actuaries, insurance companies, and legal professionals.
2.2. Dataset
A critical consideration for this research is the dataset. While some states make workers’ compensation data publicly available, this study specifically utilizes data from the North Carolina Industrial Commission, where disputed workers’ compensation claims undergo an administrative law process rather than traditional court litigation. The process includes:
-
Deputy commissioner hearing
-
Discovery and written arguments
-
Deputy commissioner’s decision
-
Appeal to the full Commission
-
Appeal to the courts
The data are collected through the public government database available at https://www.ic.nc.gov/database.html. The dataset encompasses information pertaining to the first three stages mentioned above. The process of downloading data is given in Appendix B. Typically, case documents presented before the deputy commissioner comprise the following sections:
-
Introduction: This section typically provides an overview of the case, including the case number, names of the parties involved, and a summary of the legal proceedings. It outlines the dates of hearings and depositions, any changes in the presiding deputy commissioner, and the final closure date of the case record. This section serves to establish the procedural context before presenting the findings and decision.
-
Appearances: This section lists the legal representatives for both parties, including the names of the law firms and attorneys for the plaintiff and defendants. It records the parties’ legal counsel as acknowledged in the pretrial agreement and during the hearing.
-
Stipulations: This section outlines the agreed-upon facts between the parties, confirming jurisdiction, the applicability of the Workers’ Compensation Act, and the employment relationship. It details the incident date, injury, insurance coverage, employee wages, compensation rate, and medical expenses covered by the defendants. Relevant documents, medical records, and other evidentiary materials are also included.
-
Issues for Hearing: This section clarifies the matters to be resolved and focuses the hearing on these essential questions to facilitate a fair and thorough adjudication of the case.
-
Findings of Fact or Evidence Admitted: The “Evidence Admitted” section, sometimes titled “Findings of Fact” or appearing alongside it, lists the exhibits accepted into the case record, such as a pretrial agreement, Industrial Commission forms, medical records, medical bills, personnel files, and discovery responses. Regardless of the title, this section serves the same purpose: to establish and document the evidentiary basis for the case’s findings and conclusions.
-
Conclusion of Law: This section clarifies the legal basis for the decision and ensures that the conclusions align with established legal precedents and statutory requirements.
-
Award: This section formalizes the financial and procedural outcomes based on the case’s findings and legal conclusions, ensuring that the claimant receives the appropriate relief and compensation.
We have used 15,406 workers’ compensation case records ranging from 1990 to 2024. However, these were reduced to 14,225 or 6,103 cases, depending on the independent variable. More details are given in the next section.
2.3. Independent and dependent variables
The workers’ compensation case files from the North Carolina Industrial Commission lack straightforward indicators of “winner” or “award amount” in their decisions, which makes extraction difficult. A human analyst reviewed each file and extracted data from the “Award” section into a column labeled “Decision.” The analyst recorded decisions as “1” for plaintiff win, “0” for plaintiff loss, and “2” for inconclusive. The cases that received dismissals for multiple reasons were recorded as a loss for the plaintiffs. In some cases, the court ordered both the plaintiff and defendant to pay different penalties to the state commission. At this stage, a subjective decision was made by the human analyst to determine if the plaintiff won, lost, or had an inconclusive result. A decision was recorded as a win when the state commission ruled in favor of most of the plaintiff’s requests. This research studies how well new LLMs and traditional NLP methods predict “win” or “lose” outcomes in workers’ compensation cases by using
-
“Issues” as the independent variable and “Decision” as the dependent variable, and
-
“Findings of Fact” as the independent variable and “Decision” as the dependent variable.
We believe issues are known to the plaintiff before they even contact a lawyer for their cases. Findings of fact also exist beforehand but may need extra effort to uncover, which is usually done during the hearing at the Industrial Commission through various testimony, such as by expert witnesses. However, for this study, we assume findings of fact also exist beforehand so that plaintiffs and employers both can make informed decisions.
Of the initial 15,406 records, 14,225 contained nonempty Findings of Fact and 6,103 contained nonempty Issues. Therefore, subsequent analysis contained two data frames, where one is of size 14,225 rows and the other is of size 6,103 rows. Summary statistics for the dependent variable are presented in Table B.1. The summary statistics for independent variables Preprocessed_Issues and Preprocessed_Facts in each training set are reported in Tables B.2, B.3, B.4, B.5, B.6, B.7, B.8, and B.9.
2.4. Limitations
A significant limitation of this research is the exclusive reliance on data from North Carolina. Given potential variations in legal regulations across states, the conclusions may not be directly applicable to other states without testing on their respective datasets. Another significant limitation is human decision-making. Most workers’ compensation cases have multiple claims and counterclaims by the plaintiff and the defendant (employer or insurance carrier). Thus, deciding the prevailing (winning) party is not easy and may become a subjective decision. One such approach, according to Geary (2024) is to “define the prevailing party as the party that prevails on the central claims advanced and receives substantial relief in consequence thereof.” But this is not an easy task, and the difficulty of deciding the result in workers’ compensation cases becomes a limitation itself. There is no standard approach to overcoming this limitation.
3. Methodology
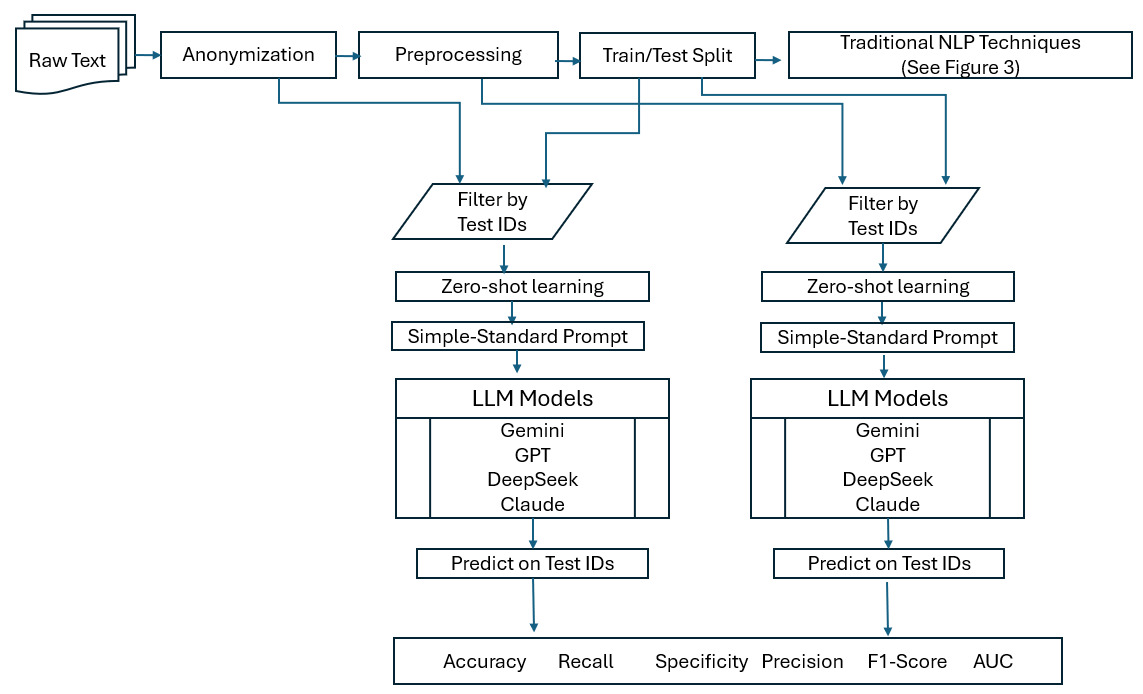
An overview of the research methodology used to compare traditional NLP techniques and LLMs in this study is shown in the flowchart in Figure 1.
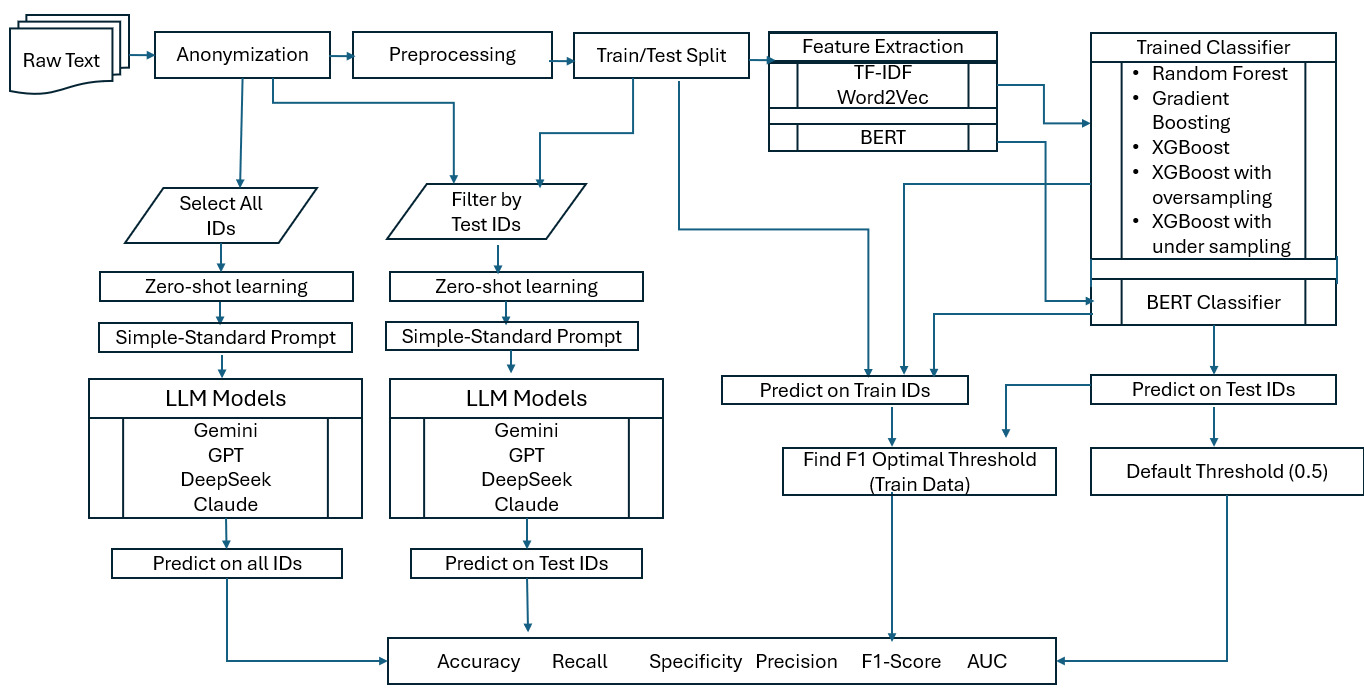
3.1. Traditional NLP model settings
The research incorporates traditional machine learning and NLP techniques as well as LLMs. The pipeline of text classification algorithms for traditional NLP models can be listed as follows: data preprocessing, feature extraction, classification, and evaluation (Kowsari et al. 2019).
3.1.1. Data preprocessing
The purpose of text preprocessing is to enhance the quality of raw data for feature extraction, hence improving the effectiveness of NLP models and leading to better insights. Therefore, text preprocessing includes cleaning, noise reduction, standardization, and many other techniques. A survey of text preprocessing can be found in Kadhim (2018) and Kathuria, Gupta, and Singla (2021). In our research, we used the following preprocessing techniques in the given order: anonymizing the text, removing HTML tags and markups, removing URLs, removing digits, removing all punctuation, unifying multiple spaces to a single space, tokenizing, removing stop words, stemming, lemmatizing, and joining tokens back into a string. Preprocessing of text other than anonymization was never done for LLMs, since they have built-in mechanisms. Anonymizing text for traditional NLP models was done in order to have similar prompts for both LLMs and traditional NLP techniques. The need for anonymization is discussed in detail later in section 3.2.2. Although it is uncommon to use both lemmatizing and stemming together, our initial tests showed improved metric scores when both were applied compared to using lemmatizing alone, even though lemmatization is generally considered superior to stemming.
3.1.2. Feature extraction
Once the text is cleaned, the next step is to convert it into numeric vectors suitable for machine learning. There are three approaches for this: text encoding (traditional encoding), static word embedding, and contextual word embedding (Campesato 2022). In text encoding, encoded values are calculated directly from the text. Bag-of-Words (BoW), N-grams, and term frequency-inverse document frequency (TF-IDF) are examples of this approach. The downside of text encoding is that it does not capture the semantic or contextual meaning of words. Under the static word embedding approach, one assumes that languages have a distributional structure (Sezerer and Tekir 2021) and calculates dense vector representations of words that capture their semantic meaning. Some of the popular static word embedding approaches are word2vec (Mikolov et al. 2013) and GloVe (Pennington, Socher, and Manning 2014). These approaches are efficient in capturing general semantic relationships between words; however, they are unable to capture contextual meaning. For example, these approaches use the same embedding for the word “bank” in “riverbank” and “financial bank”. Contextual word embedding, based on newly developed transformer architectures such as bidirectional encoder representations from transformers (BERT) (Devlin et al. 2019) embedding, considers the context of a word within a sentence before generating the embedding. For example, BERT would generate distinct embeddings for “bank” in “riverbank” and “financial bank” by considering the surrounding words. In this research, we utilized TF-IDF, word2vec, and BERT to convert text into numerical vectors. Each approach is then coupled with classification techniques at the next step.
3.1.3. BERT vs. LLM
In this research, we differentiate between BERT and other LLMs. BERT at heart is a language model; however, compared to today’s language models such as GPT-4 and Gemini, BERT is relatively small. It is an open question whether one can surpass the results from LLMs by fine-tuning small language models such as BERT (Bosley et al. 2023). Another big difference between current LLM models and BERT is architecture. BERT is an encoder-only transformer model with the base model using about 110 million parameters. Conversely, most LLM models are decoder-only or encoder-decoder models with parameters surpassing 100 billion. Also, BERT is trained using a masked language modeling approach, while newer LLMs are modeled for generation of the next word. Thus, we separated BERT from other LLMs models used in this study. Also, we used a pretrained version of BERT, bert-base-uncased, for our task.
3.1.4. Training vs. testing
Under traditional NLP techniques, we split data into training and test sets using the 80:20 rule. However, when we used LLMs, we took the entire dataset for testing. Train and test data sizes are given in Table 1.
3.1.5. Hyperparameter tuning
To optimize classification performance, we conducted hyperparameter tuning for random forest, gradient boosting, and XGBoost models using the RandomizedSearchCV framework. For each algorithm, a specific parameter search space was established to assess key hyperparameters impacting predictive power and generalization. The random forest optimization focused on the number of trees (n_estimators), minimum leaf size (min_samples_leaf), and the proportions of features and samples (max_features, max_samples). For gradient boosting, the tuning process considered the number of boosting stages (n_estimators), learning rate (learning_rate), sample and feature fractions (subsample, max_features), and maximum tree depth (max_depth). The XGBoost model’s tuning explored the number of boosting rounds (n_estimators), learning rate, regularization (gamma), subsampling ratios, and class weighting (scale_pos_weight) to address data imbalance.
For all models, RandomizedSearchCV was configured with 10 random parameter iterations and fivefold cross-validation. Recall was employed as the scoring metric to prioritize the correct identification of positive cases (employee winning the dispute case). Through parallel computation, the optimal parameter sets and their corresponding recall scores were determined, yielding tuned models that balance complexity, interpretability, and predictive performance. To address class imbalance, the XGBoost model’s hyperparameters were tuned separately for two resampling strategies. For oversampling, the model was optimized on a dataset balanced using the synthetic minority oversampling technique (SMOTE). In parallel, another optimization was performed on a dataset that was balanced through undersampling via RandomUnderSampler. This dual approach yielded two distinct models, each specifically tuned for its respective data balancing method.
For computing classification metrics, two approaches were used. The first approach used a default probability of 0.5. In the second approach, the trained model was used to predict again on the training dataset, and the F1-maximizing threshold was calculated. This threshold was then used on the predicted test data values to calculate evaluation metrics. The best approach would have been to use a validation dataset to find an F1-optimizing threshold, but, in this case, we have split the data only between training and testing without a holdout dataset for validation.
3.1.6. Non-determinism in word2vec and BERT embeddings
Neither BERT nor word2vec embeddings are strictly deterministic, as both the training and the inference processes of these methods have many sources of randomness. Random initialization, stochastic optimizers, and GPU or multi-threaded computations that update model parameters in a different order all contribute small amounts of noise. In practice, this means that rerunning these methods on the same input data can result in slightly different embeddings. To get an estimate of this uncertainty, we repeated the training of word2vec and BERT embeddings 20 times with different random seeds. This results in 20 different representations using word2vec and BERT. The resulting embedding is used as input for the classifier, and we then record the classification metrics: accuracy, recall, specificity, precision, F1-score, and AUC (area under the curve). For both word2vec and BERT, these metrics are computed in two cases: (1) with the default decision threshold of 0.5 and (2) with the F1-maximizing threshold estimated from the training data. The results from 20 runs are averaged for a more robust estimate of the performance for each embedding method. For TF-IDF embeddings, since the representation is deterministic, we do not need to rerun the embedding generation with different random seeds 20 times. We only need to compute the classification metrics with the default threshold of 0.5 and the F1-maximizing threshold. The above calculation was done separately for two data frames where “Preprocessed_Issues” and “Preprocessed_Facts” serve as independent variables.
3.2. LLM model settings
3.2.1. Reproducibility and consistency
Reproducibility, which is defined as the ability to achieve identical results upon repeating experiments under comparable conditions, is a crucial element for valid scientific research outcomes. However, with LLMs, obtaining reproducible results is a complex endeavor due to the probabilistic nature of the algorithm. Generating consistent outputs from LLMs remains a difficult task because of the many interacting elements involved. The probabilistic framework of LLMs stands as one of their most important characteristics. LLMs produce variations of human-like text through probabilistic predictions of subsequent words, unlike deterministic algorithms which always generate identical results for the same input. The inherent randomness of this process means that the same prompt can produce various outputs. Parameters such as temperature, top P, and top K manage this randomness.
In traditional machine learning algorithms, random seed plays a crucial role in reproducibility. However, even with a fixed random seed, LLMs may produce different outputs due to architectural differences, such as the use of CPU versus GPU. For example, PyTorch, a framework for building deep learning and LLMs, mentions in its documentation that “completely reproducible results are not guaranteed across PyTorch releases, individual commits, or different platforms. Furthermore, results may not be reproducible between CPU and GPU executions, even when using identical seeds” (PyTorch Documentation 2024). The other aspect of LLMs findings is consistency. In other words, how stable or uniform the result is when tests are conducted multiple times. If the answer shows less variation over time, we can conclude that the experiment produced consistent results. In one of the first comprehensive analyses of LLM output consistency and reliability (J. J. Wang and Wang 2025), the authors found that reproducibility and consistency vary by task, showing near-perfect stability in binary classification and sentiment analysis but greater variability in more complex tasks. They also noted that more advanced models do not consistently achieve higher consistency, with task-specific patterns emerging. However, in another study, researchers concluded that the results of Boolean query generation in LLMs are not reproducible (Staudinger et al. 2024), hence bringing no conclusive answer to the question of reproducibility and consistency in LLMs.
In our effort to make this research reproducible, we provided respective code and data sources, set random seeds for libraries, and set certain LLM parameters close to a deterministic level. We also provided the exact prompts we used for several models. We also measured the variability and consistency of predictions by choosing 20% of a sample and then running two LLMs 20 times. Some parameters that introduce variability in LLM are given in Table 2.
3.2.2. LLM and memory
One of the main questions that arises about LLM models is whether their performance is due to their memory. In other words, did the LLM already see the data we are using in our research beforehand, hence the better result than from a traditional model? In order to address this issue, Kim, Muhn, and Nikolaev (2024) proposed three techniques: anonymizing the text prompt, using the Sarkar and Vafa test (Sarkar and Vafa 2024), and conducting a clean out-of-sample test. Under the anonymization of the text prompt, we remove any contextual information, such as names, dates, location names, monetary units, etc., that the LLM can use to infer the outcome of the worker’s compensation case from its training data. By doing so, the LLM has to rely on the general language and context it has learned to infer the outcome rather than any specific historical information about the particular case it may have seen. A sample of anonymized Findings of Fact is given in Table A.1 in Appendix A. Under the Sarkar and Vafa test, given the anonymized workers’ compensation case data, we asked the LLM to predict the case number, year, plaintiff name, and defendant name. For conducting this research on a clean out-of-sample, which means finding workers’ compensation cases that happened after LLMs versions were released, we were unsuccessful, primarily due to the frequency of LLM updating.
3.2.3. LLM, prompts, and zero-shot learning
The performance of LLMs highly depends on the provided prompt. Because the result of an LLM can change dramatically with a different input, we examined the sensitivity of our final predictions by using a diverse set of 17 prompts from three different prompt families. The architecture of this strategy is illustrated in Figure 2. In this context, a prompt refers to the text input that is used to guide the output of the model for a specific task. Thus, designing effective prompts is essential for achieving good performance, and this has attracted a lot of attention (Santu and Feng 2023). Influential works have explored strategies for “designing appropriate” prompts (Ahn et al. 2022; Kojima et al. 2022; Webson and Pavlick 2022), while detailed surveys of the field can be found in Schulhoff et al. (2024) and Huttula (2025).
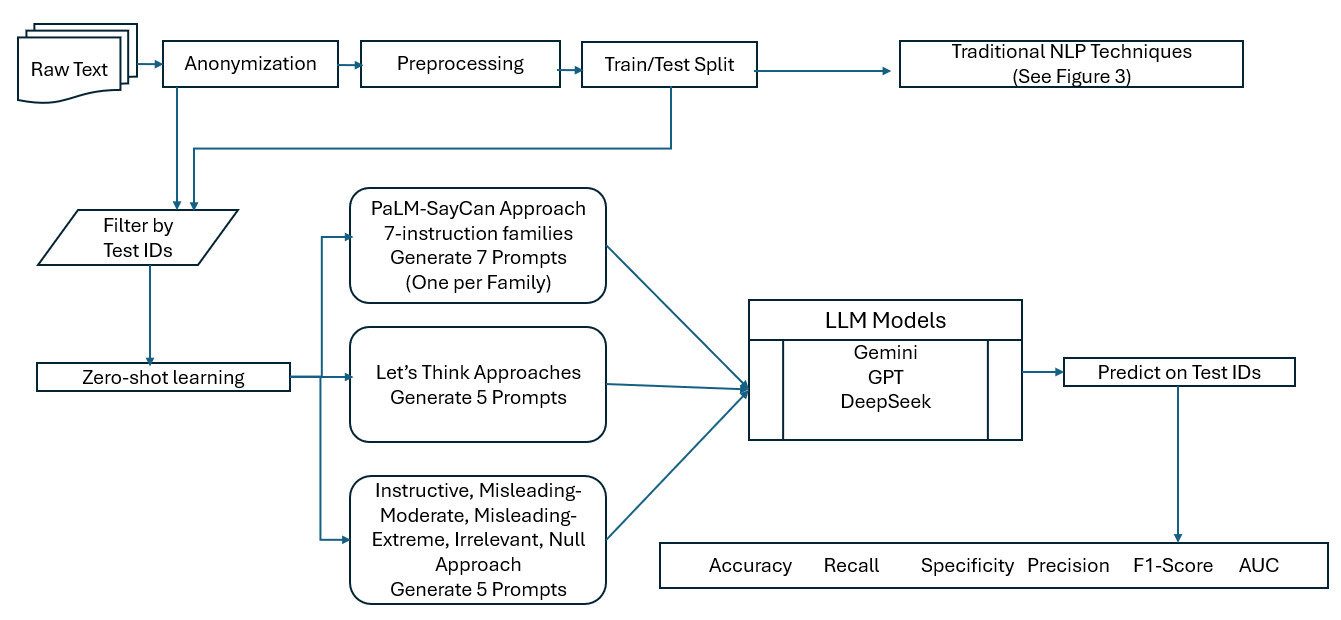
The first set of prompt families we examine are taken from Ahn et al. (2022). Their paper explores the use case of an LLM providing high-level linguistic instructions to an agent (a robot acting as the “hands and eyes” of the LLM). In order to provide a controlled comparison of their instructions to PaLM-SayCan system, the authors created a benchmark of 101 prompts organized into seven distinct prompt families. We have created one prompt for each of the seven families in Table A.13 for our experiments. The second set of prompts we examine are taken from Kojima et al. (2022). In this paper, they discovered that the simple addition of the phrase “Let’s think step by step” resulted in a huge accuracy gain for LLM predictions even when using zero-shot learning. They also attempted the prompt families from Ahn et al. (2022) but found that “Let’s think step by step” significantly outperformed them. We used five “Let’s think…” variations for this research, and these are given in Table A.14. Finally, we look at Webson and Pavlick (2022). The authors pose the question “Do prompt-based models really understand the meaning of their prompts?” and discover that models can learn just as quickly with a large number of prompts that are irrelevant or misleading as with similar “good” prompts. They created five distinct prompt templates, and we used five prompts, one from each template. See Table A.15 for prompts we created from this family.
Prompts are commonly categorized into “simple prompts” and “chain-of-thought (CoT)” prompts. A simple prompt is a single instruction or question to the LLM that requests the final answer and provides no context for the reasoning that led to that answer. By contrast, CoT prompting guides the model to articulate the series of logical steps taken to reach a conclusion (Wei et al. 2022). In a highly cited publication by Wei et al. (2022), researchers from the Google Brain team have demonstrated how CoT prompting can improve LLM performance. CoT prompting without step-by-step examples, using only a lead-in phrase like “Let’s think step by step,” can also lead to significant increases in accuracy (Kojima et al. 2022; Jeoung et al. 2025). We have categorized each prompt in Tables A.13, A.14, and A.15 as either a simple prompt or a CoT prompt.
Zero-shot learning (simply referred to as zero-shot in the LLM context) tasks the model to do a job without giving it any examples to learn. Few-shot learning gives the model several examples of how to do a task, complete with step-by-step reasoning to arrive at the correct answer. CoT prompting is usually done in combination with a few-shot example, but it also works in a zero-shot setting. This is achieved by simply adding instructional phrases like “go step-by-step through each fact” to the prompt, which triggers the model’s reasoning process without explicit examples. In this research, we exclusively used zero-shot strategy, employing either zero-shot simple prompts or zero-shot CoT prompts. Unless we check for prompt robustness, all other LLM-based calculations are done under the unique standard simple prompt given in Table 3.
3.2.4. LLMs and model type
In this research, we used the following LLM models: deepseek-chat (deepseek-v3), claude-3-haiku, gemini-1.5-pro, gemini-1.5-flash, gemini-2.0-flash, gpt-3.5-turbo, gpt-4.1-mini, and o4-mini. Model characteristics are given in Table A.2.
4. Main results
This section is dedicated to presenting the primary findings derived from this research. Given the intrinsic nature of the problem as a classification task, a comprehensive set of evaluative metrics has been employed. Specifically, the performance of the proposed model is assessed using accuracy, recall (sensitivity), specificity, precision, F1 score, and the AUC score. The interpretation of these metrics under the research context is provided in Table A.24.
4.1. Performance comparison of LLMs against traditional NLP techniques
Tables A.3 and A.4 display how traditional NLP technique approaches predict “Decision” results in workers’ compensation cases through analysis of “Preprocessed_Issues” or “Preprocessed_Facts” variables at default threshold of 0.5. Under the default threshold of 0.5, it is surprising to see simpler TF-IDF embedding approach coupled classifiers outperforming the other two advanced embedding-based classifiers most of the time. The gradient boosting method achieves a perfect recall score of 1.0 when combined with TF-IDF embedding techniques. In general we can see very high recall value for word2vec embedding coupled classifiers as well as most of the TF-IDF coupled classifiers. Recall answers the question: “Of all the actual plaintiff-winning workers’ compensation disputes, how many did the model correctly identify?” A high recall value means the model is capturing most of these cases.
However, because our dataset is imbalanced, with more plaintiff-winning cases than losing ones, recall alone can be misleading. For example, a model that always predicts the plaintiff wins would achieve a perfect recall of 1.0 but provide no useful discrimination. Yet, in practice, the stakeholders of this research: employees, employers, insurance companies, and analysts need balanced insights about both wins and losses. Here, specificity complements recall by answering: “Of all the actual plaintiff-losing cases, how many did the model correctly identify as losses?” High specificity ensures the model is not simply overpredicting wins and helps prevent unnecessary payouts by ensuring insurance companies do not mistakenly assume the employee will win the case.
Recall and specificity cannot both be maximized at the same time, because as the decision threshold changes, improving one typically reduces the other. Additionally, precision may be important to ensure predicted wins are reliable. Thus, metrics such as AUC (capturing the trade-off between recall and specificity across thresholds, hence overall discrimination) and F1 score (balancing recall and precision) are more informative. With this in mind, when we looked into Tables A.3 for Preprocessed_Issues and A.4 for Preprocessed_Facts, TF-IDF coupled with random forest always gives the highest AUC. For F1 score, TF-IDF coupled with XGB and TF-IDF coupled with random forest are highest. However, when performance is considered from a broader recall–specificity balance perspective, the more reliable choices appear to be TF-IDF with XGB (with undersampling applied) and BERT embeddings with SequenceClassification, regardless of the independent variable we used. Instead of using the default threshold, if one uses the F1 maximizing threshold, calculated from the training data to evaluate metrics on the test data, the summary metrics can be found in Tables A.9 and A.10. Even though AUC does not change in this scenario, other metrics do differ from those calculated at the default threshold. However, TF-IDF–based classifiers still show the highest values for specificity, precision, and AUC when Preprocessed_Facts are used. In this scenario, word2vec-based classifiers outperform other classifiers in terms of accuracy and recall.
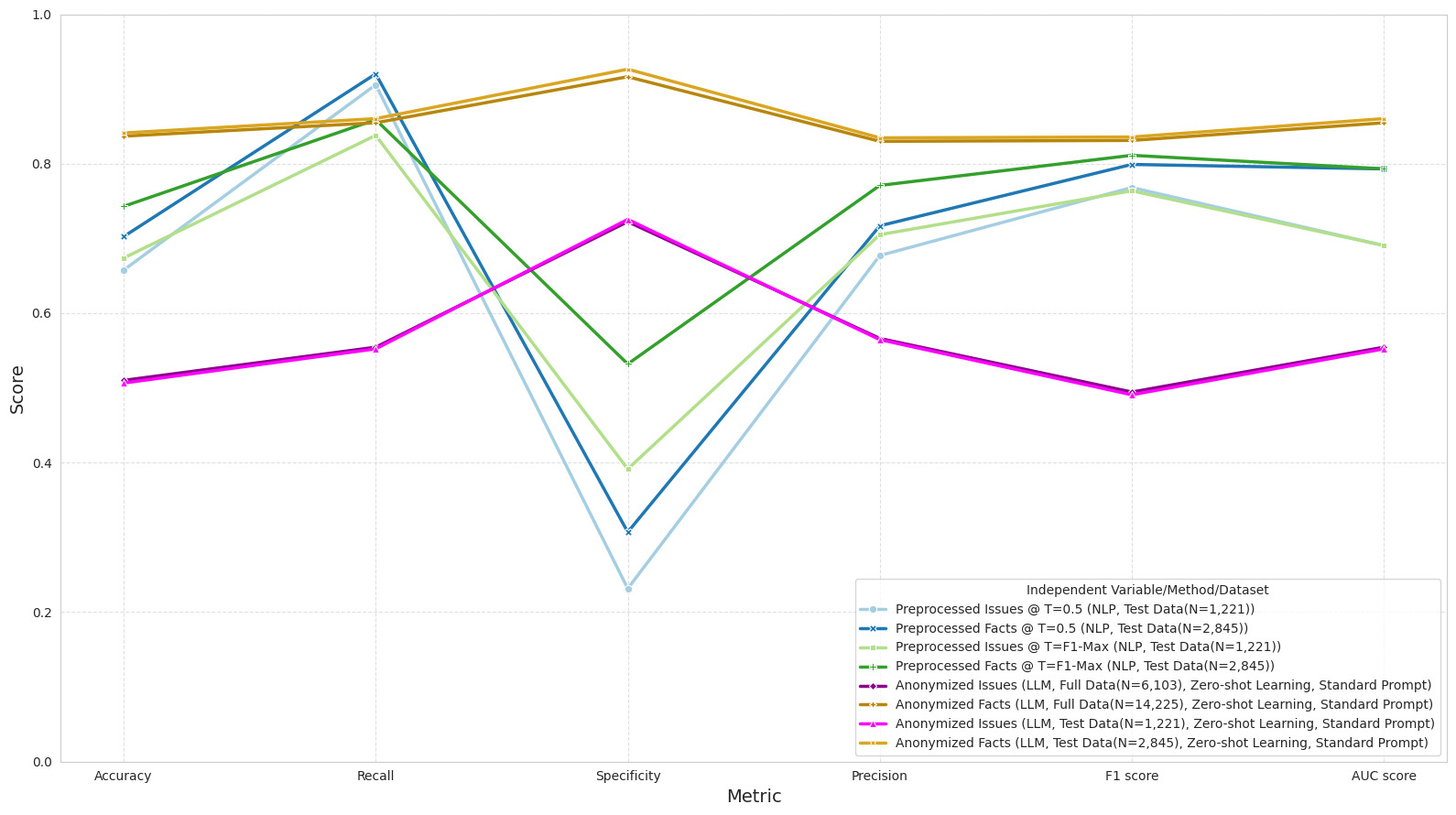
The comparison of the effect of the independent variable and the thresholding method on the performance of the traditional NLP technique is shown in Figure 3. It indicates that Preprocessed_Facts outperforms Preprocessed_Issues when focusing on the AUC metric. For the other metrics, in general, Preprocessed_Facts performs slightly better than Preprocessed_Issues. Regarding the thresholding method, the F1-maximizing threshold outperforms the default threshold when the concern is accuracy, specificity, and precision. But for the other metrics, the result is less clear cut.
_and_thresholding_on_traditional_nlp_.png)
LLMs demonstrate significantly reduced predictive power when Anonymized_Issues are used as the independent variable; in fact, none of the tested LLM models perform well in this scenario. However, LLM models show a significant improvement in performance when Anonymized_Facts are used as input data. Of the eight LLM models tested, the deepseek-chat model performs better than all others in every category, except for specificity. For specificity, the claude-3-haiku-20240307 model performs better than all other models considered. It’s worth noting that LLMs perform better than traditional NLP techniques when Anonymized_Facts are used with the standard simple prompt. This is evident by comparing the average of model metrics for LLMs given in Tables A.5 and A.6 against the average of model metrics for traditional NLP techniques under different thresholds given in Tables A.3, A.9, A.4, A.10, as well as through Figure 4.
The outcomes on the test data for the traditional methods may exhibit greater variability compared to those for the LLMs, since in Tables A.5 and A.6 the LLMs are evaluated on the entire dataset under the zero-shot learning approach, as explained in Figure 1. In contrast, the traditional NLP methods rely on a smaller test subset, which introduces more random variation in their results. The simplest way to address this concern is to show the results of the LLMs on the same test dataset as the traditional NLP methods. Thus, as explained in Figure 1, we tested the LLMs again using only the same test dataset used by the NLP techniques. The results are given in Tables A.11 and A.12 and Figure 4. This indicates that the LLMs can perform at the same level regardless of the dataset size.
4.2. Prompt robustness
As explained in Section 3.2.3, different prompts may yield different results. However, for actuaries and professionals in related fields, consistent and reliable outputs are essential. This requires two types of investigation. On the one hand, we need to understand how much the results deviate when using different prompts with the same LLM. On the other hand, we need to examine how much the results deviate when using the same prompt and the same LLM but providing the same data entry repeatedly.
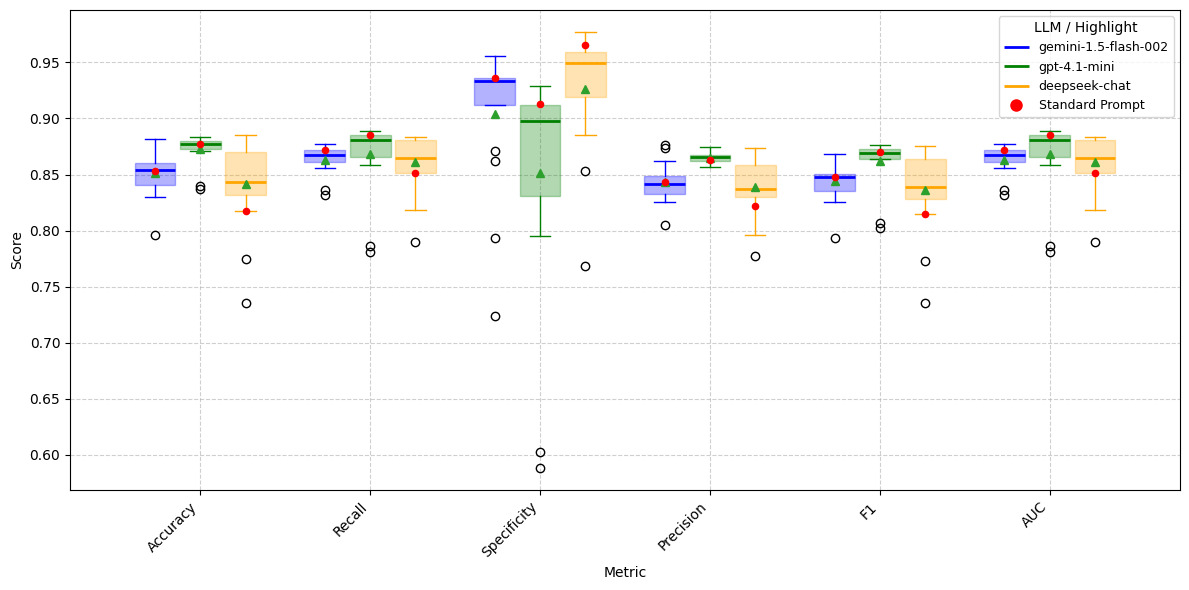
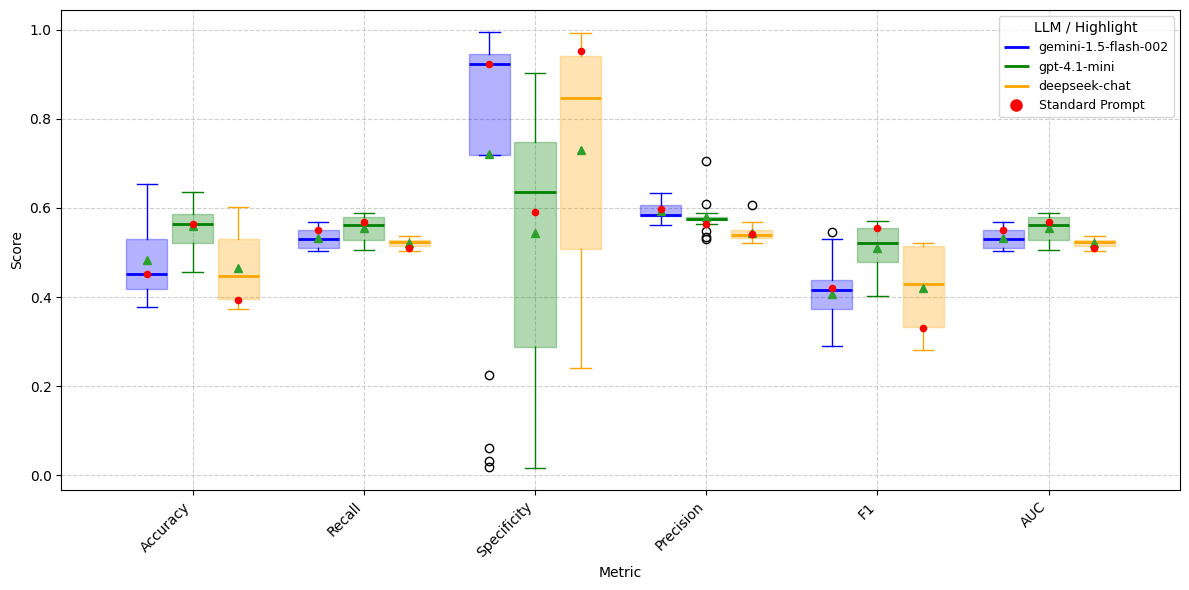
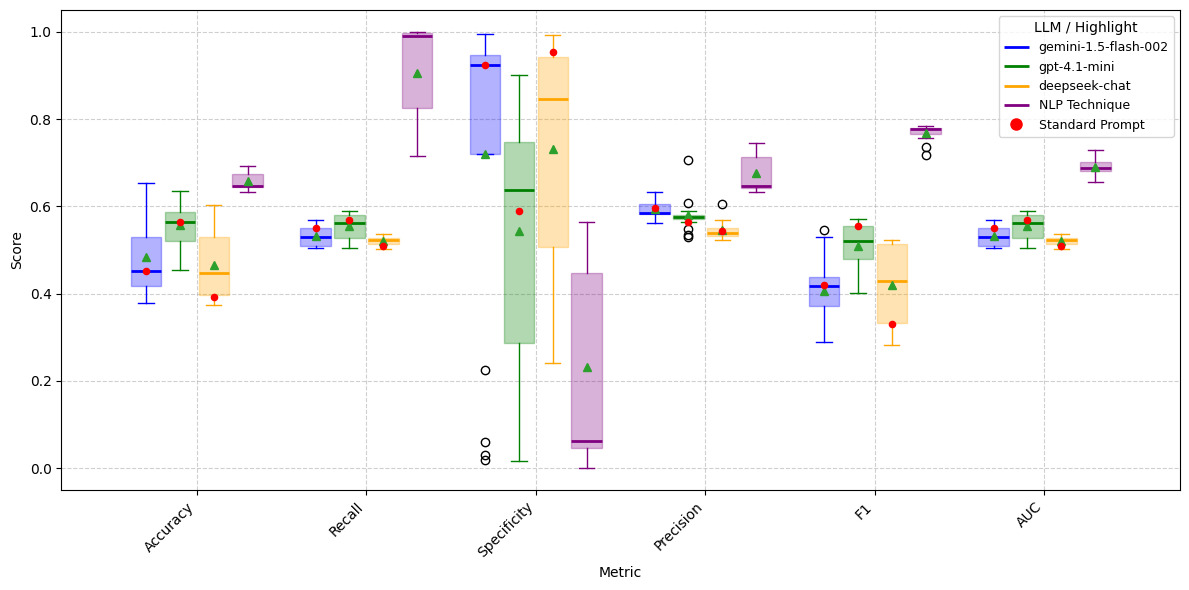
To answer the first question, we used three different prompt families and 17 different prompts drawn from those families as shown in Tables A.13, A.14, and A.15 on LLM models gemini-1.5-flash-002, gpt-4.1-mini, and deepseek-chat. Since we have observed that, regardless of dataset size, LLM models produce nearly identical results (see Figure 4), for this test, we used only the anonymized test dataset for Issues and Facts, respectively. The results are given in Tables A.16–A.21. Figures 5 and 6 present boxplots comparing the distributions of performance metrics across prompts for LLMs on Anonymized_Facts and Anonymized_Issues. These results are evaluated on the same test set as the traditional NLP techniques; however, unlike the NLP models, the LLMs are tested using anonymized data only (not anonymized + preprocessed). From these figures, it is evident that the gemini-1.5-flash-002 and gpt-4.1-mini models exhibit less variation in performance metrics when Anonymized_Facts are used as the independent variable. The standard prompt we employed also appears to be reasonably optimal for both gemini-1.5-flash-002 and gpt-4.1-mini. In contrast, for deepseek-chat, the standard prompt performance often falls within the first quartile, and in some cases at the minimum, illustrating that there is no universal prompt that performs well across all LLMs. Interestingly, the LLMs simultaneously achieve higher recall and specificity, which contrasts with the trade-off typically observed in traditional NLP techniques. Furthermore, when Anonymized_Issues are used as the predictor, model performance declines sharply and exhibits greater variability across the 17 different prompts for accuracy, specificity, and F1 score.
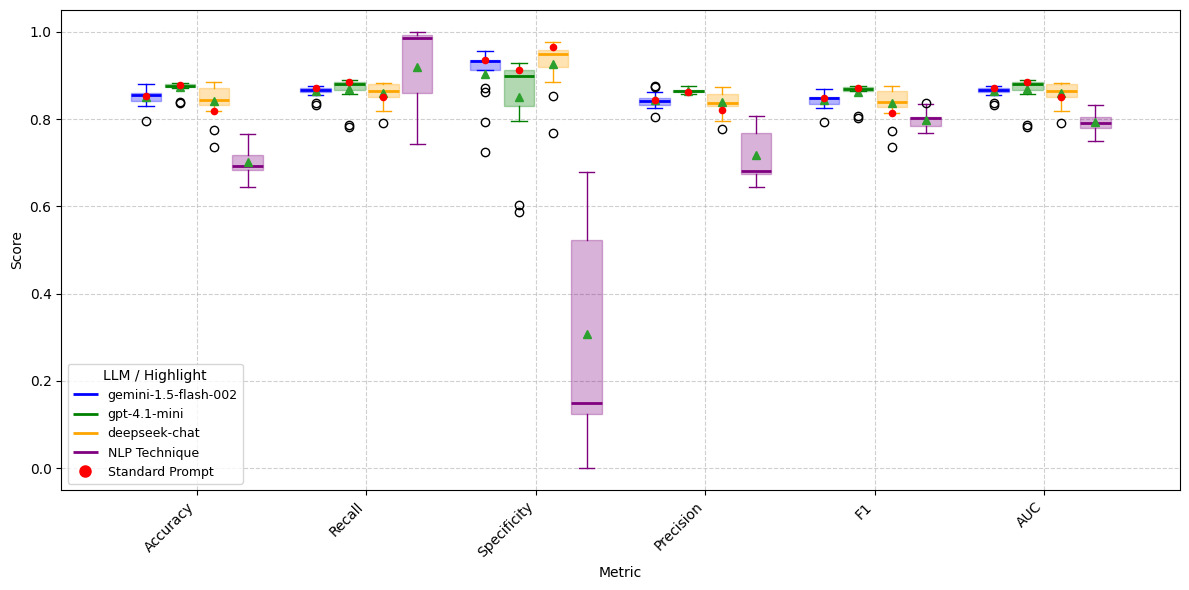
To compare LLM model performance across 17 different prompts against 11 traditional NLP techniques, we present boxplots of each LLM model alongside the NLP techniques. The results are shown in Figures 7 and 8. It is evident that, despite the variability introduced by 17 different prompts, LLM models consistently outperform traditional NLP techniques in accuracy, specificity, precision, F1, and AUC metrics when Anonymized_Facts are used as predictors. In contrast, when Anonymized_Issues serve as predictors, traditional NLP techniques consistently achieve superior performance.
To answer the second question, whether model performance changes when the same LLM, prompt, and entries are run multiple times, we used 20% of anonymized Findings of Fact (2,845 records) and 20% of anonymized Issues (1,220 records) to simulate case outcomes 20 times. We selected gemini-1.5-flash-002 and gpt-4.1-mini for this experiment due to their cost-effectiveness and speed, along with the standard prompt. We performed sampling once, then ran models 20 times on the same dataset repeatedly. Results are shown in Tables A.7 and A.8. The tables indicate that the standard deviation for gemini-1.5-flash-002 is 0.0000, showing identical results when the same question is asked repeatedly with the same prompt. For gpt-4.1-mini, the standard deviation is nonzero but very small, again implying consistent outputs for the same entry, same prompt.
4.3. Prompting strategy comparison: Simple vs. chain-of-thought in LLM predictions
Prompts we created in Tables A.13, A.14, and A.15 can be divided into CoT prompts and simple (direct) prompts. We have indicated which prompts we consider CoT prompts and which ones are simple prompts. The logic behind this categorization is whether the prompt explicitly asks LLMs to go step by step to achieve its conclusion in some form. If not, then the prompt was classified as a simple prompt. We understand that some of these prompts may feel like CoT prompts. This categorization resulted in 11 simple prompts and six CoT prompts. When comparing the metrics for CoT versus simple prompts, it appears that there is little difference, yielding an unexpected result. This can be seen by comparing the boxplots in Figures 9 and 10.
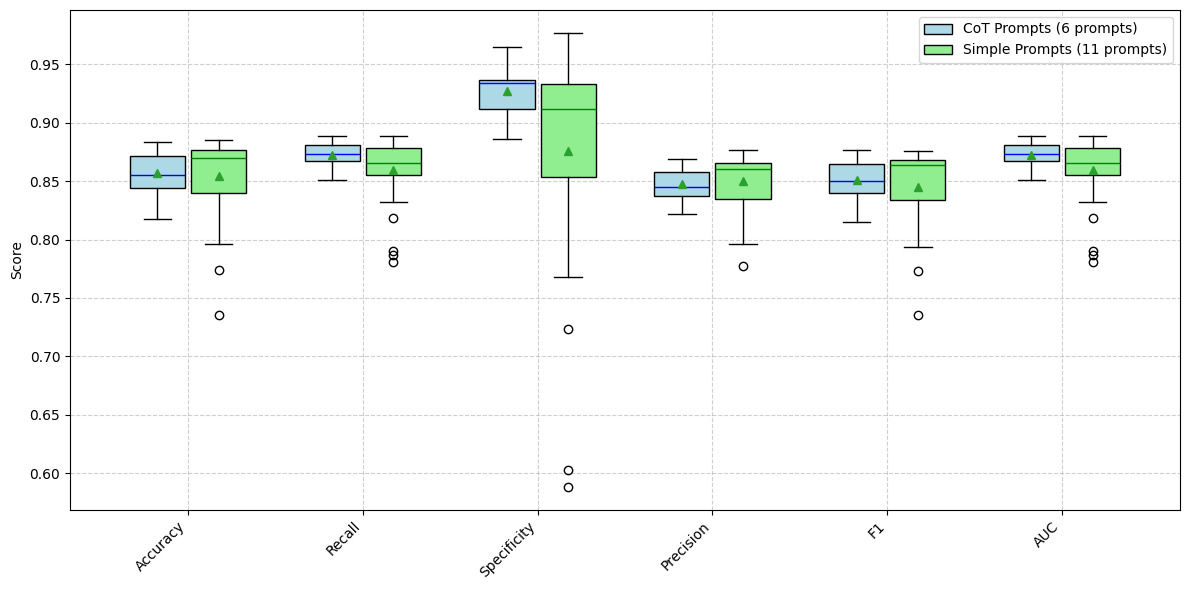
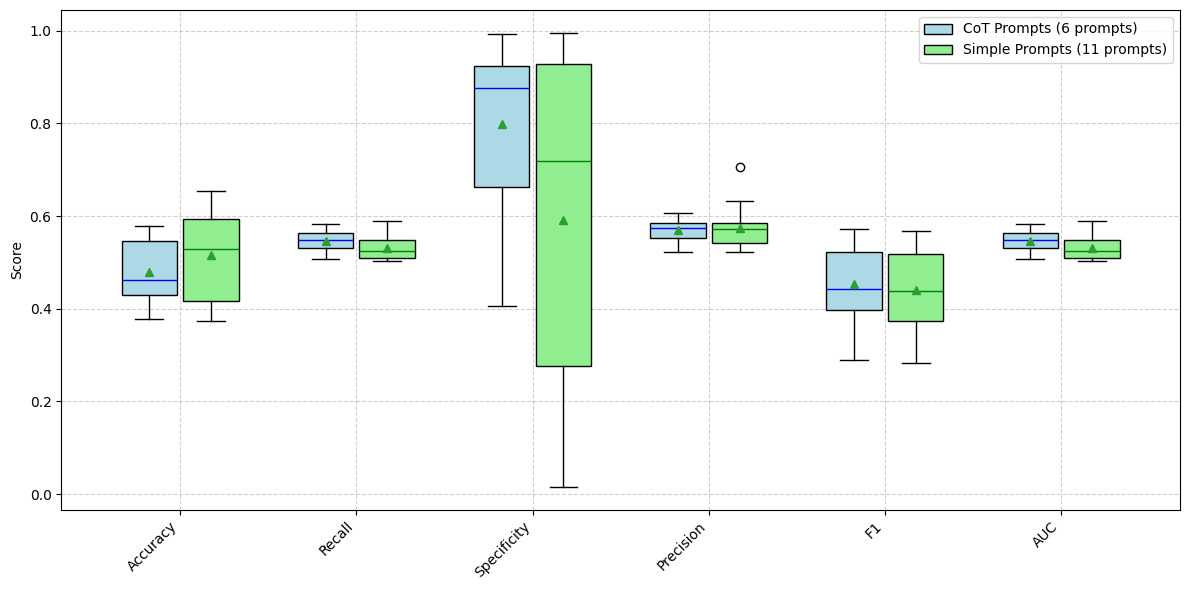
One possible reason is that the models’ internal reasoning doesn’t align with human judgments. In other words, what LLMs interpret as a “win” or “loss” through internal “thought” process may differ from the official case outcomes labeled by humans. This poses an interesting question: Who is right? Did the human label these cases correctly, or are LLM models correct? Given the cost constraint, we were only able to use deepseek-chat, gemini-1.5-flash-002, and gpt-4.1-mini for the prompt robustness analysis in the previous section and the CoT versus simple prompt comparison here. The result shows that CoT may not be a suitable prompting strategy for workers’ compensation case studies. Another reason there is little difference in the metrics for CoT versus simple prompts may be that the CoT prompt used by the researchers is not suitable and may need tweaking to achieve good results. It should be noted that the 04-mini model internally uses the CoT approach to make a decision. Thus, even though we used a simple prompt externally, some form of CoT was involved to produce the output.
4.4. Model predictions of case outcomes: Issues versus findings of fact
In this research, we used two different independent variables to predict the case outcome. Interestingly, with traditional NLP techniques, on average, there was little difference in accuracy, recall, specificity, precision, F1 score, and AUC score regardless of whether we used issues or finding of facts as the independent variable. However, for LLM models, when findings of fact were used, on average all metrics improved across models. One possible reason is that findings of fact contain more information. They are more formal and imitative of the legal findings presented in court. Thus, when one reads these findings of fact, they may get a sense of what is likely to happen during the final decision phase. In contrast, issues are items brought up at a very early stage of the case and may not reveal what the next step will be. In essence, the rich textual context in findings of fact may enable LLM models to predict outcomes more accurately than when using issues.
4.5. The LLMs training memory regarding the dataset
One key question about LLM performance is whether it stems from the model having seen the data during its training phase. Thus, for gemini-1.5-flash-002 and gpt-4.1-mini, we used the following prompt to verify whether the model could infer the case number, year, plaintiff’s name, and defendant’s name.
You are an expert at extracting case information from
legal summaries. Based solely on your internal
training data and knowledge (no web search),
identify the following for each anonymized
workers’ compensation case:
''Case_ID'': (string, predicted Case ID, or ''Unknown''
if not found)
''Year'': (string, predicted Year the case was heard,
or ''Unknown'' if not found)
''Plaintiff_Name'': (string, predicted Plaintiff's
Name, or ''Unknown'' if not found)
''Defendant_Name'': (string, predicted Defendant's
Name, or ''Unknown'' if not found)
If a piece of information is explicitly stated as
anonymized or cannot be confidently extracted, use
''Unknown'' for that specific key. Your response MUST
be a JSON object and contain ONLY the JSON object.
Do NOT include any other text or explanation.
We used 20% of the data for this test (Sarkar and Vafa test) and concluded that gemini-1.5-flash-002 and gpt-4.1-mini do not retain memory of the workers’ compensation cases used in this research. Hence, we generalize to other models, without testing them, due to cost constraints, that LLMs’ memory is not a significant contributing factor to the findings of this research. The Sarkar and Vafa test was applied to 2,845 (20%) randomly chosen rows of anonymized Findings of Fact and 1,220 (20%) randomly chosen rows of anonymized Issues. The outcome revealed that, given anonymized Findings of Fact or Issues, LLMs could not predict the Case_ID, year, plaintiff name, or defendant name.
4.6. Anonymized versus preprocessed predictors
In this research, we used anonymization only for LLMs and anonymization followed by preprocessing for the traditional NLP technique. A question may arise whether doing additional preprocessing before we enter workers’ compensation dispute data into LLMs would yield superior results. To test that, we followed the methodology explained in Figure 11.
The results can be found in Tables A.22 and A.23. They show that, in general, except for specificity, anonymization performs better than anonymization followed by preprocessing for LLMs. This surprising result indicates that LLMs may utilize extra information that we remove during the preprocessing step. Figures 12 and 13 clearly indicate that, except for specificity, all other metrics perform better when just anonymization is used. Smoothing/cleaning of text through preprocessing may not work well in the workers’ compensation case arena, according to this result.
_for.png)
_for.png)
Anonymization presents a major obstacle for legal LLM research. Legal text must be sanitized to mitigate reidentification risks. It must also retain contextual and semantic information for meaningful and accurate analysis, and it must also use the US legal system’s reliance on case law. Therefore, it requires more sophisticated techniques than the simple text redaction or masking used in this research. To understand why anonymization degrades LLM performance so significantly, it is crucial to understand the two primary knowledge sources an LLM utilizes: parametric knowledge (PK), which is stored and learned during pretraining, and contextual knowledge (CK), which is supplied at inference time through the prompt or context window (Cheng et al. 2024). Even though LLMs contain massive PK, empirical research found that LLMs overwhelmingly prioritize CK, even to the extent of suppressing their own parametric knowledge (Tao et al. 2025). This leads to a phenomenon known as PK suppression, where the model ignores its internal knowledge when CK is available, even if that CK is merely complementary or irrelevant, according to Tao et al. (2025).
For our research, this means the model relies on the immediate context of a workers’ compensation case file provided through prompt rather than its broader, pretrained understanding of legal principles. The problem is especially acute in US law, where case names, citations, courts, and factual details are not just metadata but essential components of legal reasoning. Under stare decisis (the legal principle that courts should follow past judicial decisions, or precedents, when making future rulings on similar cases), no precedent can be judged binding or persuasive without knowing its jurisdiction and court level. Thus, naive anonymization that redacts parties or case identifiers severs the logical links needed for reasoning, making it harder for LLMs to assess outcomes meaningfully.
4.7. Who is correct?
Another question we can raise is whether humans made the correct labels for workers’ compensation cases. Since we assume human decisions as absolute truth and evaluate traditional NLP techniques and LLMs against them, it is crucial to know whether the human decision is correct. However, in many workers’ compensation cases, deciding whether the plaintiff won or lost is not straightforward and may be subjective. Thus, the human decision may not be correct. If we assume each AI model acts like a human, we can determine the majority decision across AI models. Once we have this majority decision, we can compare it to the human decision and measure the difference. For this, we used anonymized Findings of Facts and the simple prompting strategy, with model outcomes in Table A.6. Using model predictions for these models, we calculated the majority decision for each case and then checked it against the human decision. Only 2,024 cases out of 14,225 had a different LLM-majority decision than the human decision, equivalent to 14.23%, where the majority of eight LLMs (deepseek-chat, claude-3-haiku, gemini-1.5-pro, gemini-1.5-flash, gemini-2.0-flash, gpt-3.5-turbo, gpt-4.1-mini, o4-mini) disagreed with the human decision on who won the workers’ compensation. When we checked the actual awards for a few of these mismatched cases, it appears that the human decision was correct. However, we have not reviewed all 2,024 mismatched cases individually.
5. Conclusion
In this research, we were interested in finding whether off-the-shelf LLMs can outperform other specialized NLP techniques in predicting likely outcomes for workers’ compensation cases. We used two different independent variables, namely “Findings of Fact” and “Issues,” to predict the case outcome “Decision.” These outcomes were then compared against the human decisions. We have used TF-IDF, word2vec, and BERT as our embedding approaches for traditional NLP techniques. These text-embedding approaches, coupled with random forest, gradient boosting, XGBoost, and a BERT Classifier (based on neural networks), serve as our traditional NLP techniques. For LLMs we have used eight models: deepseek-chat, claude-3-haiku, gemini-1.5-pro, gemini-1.5-flash, gemini-2.0-flash, gpt-3.5-turbo, gpt-4.1-mini, and o4-mini.
We first found that deterministic, simple TF-IDF classifiers either outperform or are on par with modern embedding–based classifiers, regardless of the predictor used. This is surprising but evident in Table A.3, Table A.4, and Figure 3. Next, our research shows that when Anonymized_Issues is used, LLMs’ performance becomes worse than that of traditional NLP techniques. However, when we use Anonymized_Facts, LLMs’ performance significantly improves and is either on par with or better than the traditional NLP techniques. LLM models show a better balance between recall and specificity compared to the traditional NLP model; Figure 4 illustrates this clearly. We have also noticed that the BERT model coupled with the BERT classifier did not outperform other traditional NLP techniques, except for accuracy, when “Issues” was used as the independent variable.
We have also found that the CoT prompting strategy did not improve the results as we expected. This is a curious outcome and needs further research to determine whether our CoT prompt requires modification or should move from zero-shot prompting to few-shot prompting, so LLMs have more avenues to learn the CoT approach. We have used 17 different prompts from three different popular prompt families. Of these prompts, 11 can be considered as simple, direct prompts, and the other six can be considered as CoT prompts. Figures 5 and 6 show the prompt robustness across three different LLMs from three different manufacturers. These figures show tight boxplots for each metric except for specificity. They also show that the standard prompt we used is either in the third or the fourth quartile for the Gemini and GPT models, performance-wise, but not for the DeepSeek model. Given the tight nature of the boxplots for each metric except specificity, we conclude that LLMs can be used by actuaries for workers’ compensation dispute outcome determination at a high level of accuracy, recall, precision, F1, and AUC (generally above 0.8) when coupled with Anonymized_Facts. When prompts are divided between CoT and simple prompts, it is clear that CoT did not improve the model metrics. This is clear from Figures 9 and 10.
Using the Sarkar and Vafa test, we found that these LLM models do not retain memory of the cases we tested, which lends significant validity to our research outcomes. It also shows that the models’ predictions are consistent, making them potentially useful for predicting future workers’ compensation cases. We found that LLMs produce consistent outcome with very small variability when the same prompt, LLM model, and entry are used. Thus LLMs decisions on workers’ compensation do not change with different runs. This is evident from the results given in Tables A.7 and A.8. We also tested whether anonymization alone or anonymization followed by preprocessing performs better for LLMs. From Figures 12 and 13 it can be seen that anonymization outperforms anonymization followed by preprocessing. This allows practical use of LLMs in industry scenarios, where less data preparation is needed to use off-the-shelf LLMs. We also observed that the performance of the LLM model remains unchanged with varying dataset sizes. This was evident when we tested LLM models on smaller test datasets, with results shown in Tables A.11 and A.12. This is promising for actuaries, indicating that LLMs can be leveraged for these tasks off the shelf.
Next, we tested whether humans made incorrect decisions on the cases. It turned out that only 14.23% of cases had decisions that did not agree with the majority of LLM decisions. Upon reviewing a few such cases, it seems that the human decision was correct. Thus, human decision-making still surpasses LLM decisions in determining who won workers’ compensation cases.
This research highlights that LLMs can be used proactively by actuaries, insurance companies, plaintiffs, and defendants to decide the likelihood of winning their cases if they have sufficient information on Findings of Fact. However, if they know only a few facts such as Issues, then the use of LLMs is not desirable. Finally, we conclude that LLMs outperform traditional NLP techniques in deciding who likely won workers’ compensation disputes when a large context window is provided to the LLMs. The finding is significant given that a layperson cannot use traditional NLP techniques without domain-specific knowledge, but LLMs do not require such knowledge. Also, LLMs are not trained to predict workers’ compensation case outcomes, whereas specialized NLP techniques are. Hence, the fact that just the base LLMs—without any modification—can perform on par with traditional NLP techniques specially trained to predict workers’ compensation cases proves our hypothesis that LLMs outperform traditional NLP techniques when the context window is sufficiently large and enriched.
We agree that, in some instances, the most immediate benefit appears to be ex post, that is after a claim is disputed and filings are made. However, even in this scenario, our work shows that LLMs could serve as a decision support tool. For example, an actuary, claims adjuster, or a legal staff person could use LLMs to assess case strength before taking it further, helping to triage disputes, manage resources, or make settlement offers. One may also ask about the endogenous cost related to our research outcome: must the user draft a hefty legal brief in order to use LLMs and see predictions? We view this less as a cost and more as a feature. Most of these documents are going to exist already as a matter of the routine processing of claims. The LLM isn’t looking for a fully realized and polished legal brief; in most cases it will work with factual summaries or incident reports that are quite routine in the early stages of the claims cycle. The LLM is thus a way to use these texts earlier in the cycle, before a formal legal review might be warranted.
The larger goal of our work, though, is to experiment with LLMs and show that they can be used in actuarially relevant applications, where at least some of the data is unstructured text. We chose workers’ compensation disputes as a use case not because it is the only use case or the final one, but because it is complex enough, with rich data and significant legal shading, that modeling the outcomes traditionally has been difficult to do from a structured actuarial perspective. The results presented in the paper are promising in this regard and suggest that LLMs can outperform traditional NLP approaches at predicting outcomes, especially with context. This suggests that LLMs are useful for uncovering latent features of legal language that may not be transparent or intuitive even to experienced actuaries or underwriters. Further, they may have even broader applications in the actuarial and underwriting world, especially where there are processes involving claims management, risk assessment, or policy review with substantial amounts of textual narrative content.
Acknowledgments
We gratefully acknowledge the assistance of the following Middle Tennessee State University students in determining the outcome of several workers’ compensation cases: Jiyao Luo, Aocheng Wang, Danlei Zhu, Jennifer Rody, Clifford Jones, Lala Yamazaki, and Derek Nehring.
Financial disclosure
This research was supported by the Middle Tennessee State University Data Science Seed Grant.
Data and Python code availability
Raw data are publicly available at the North Carolina Industrial Commission website: https://www.ic.nc.gov/database.html. Python codes are publicly available at https://github.com/cvajira/Workers_Compensation_Case_Studies. The anonymized dataset, which includes Anonymized Issues, Anonymized Findings of Fact, and Decisions, is available at: https://data.mendeley.com/datasets/b6n2vn2d69/1.
Conflict of interest
The authors declare that they have no financial or personal relationships that could inappropriately influence or be perceived to influence the work reported in this paper. No external commercial entities provided funding, materials, or in-kind support that could constitute a competing interest. All affiliations and sources of support are disclosed in the Acknowledgments and Funding sections.
AI Statement
The authors acknowledge the use of ChatGPT and Gemini to produce Python codes used in this research. Python codes are publicly available.