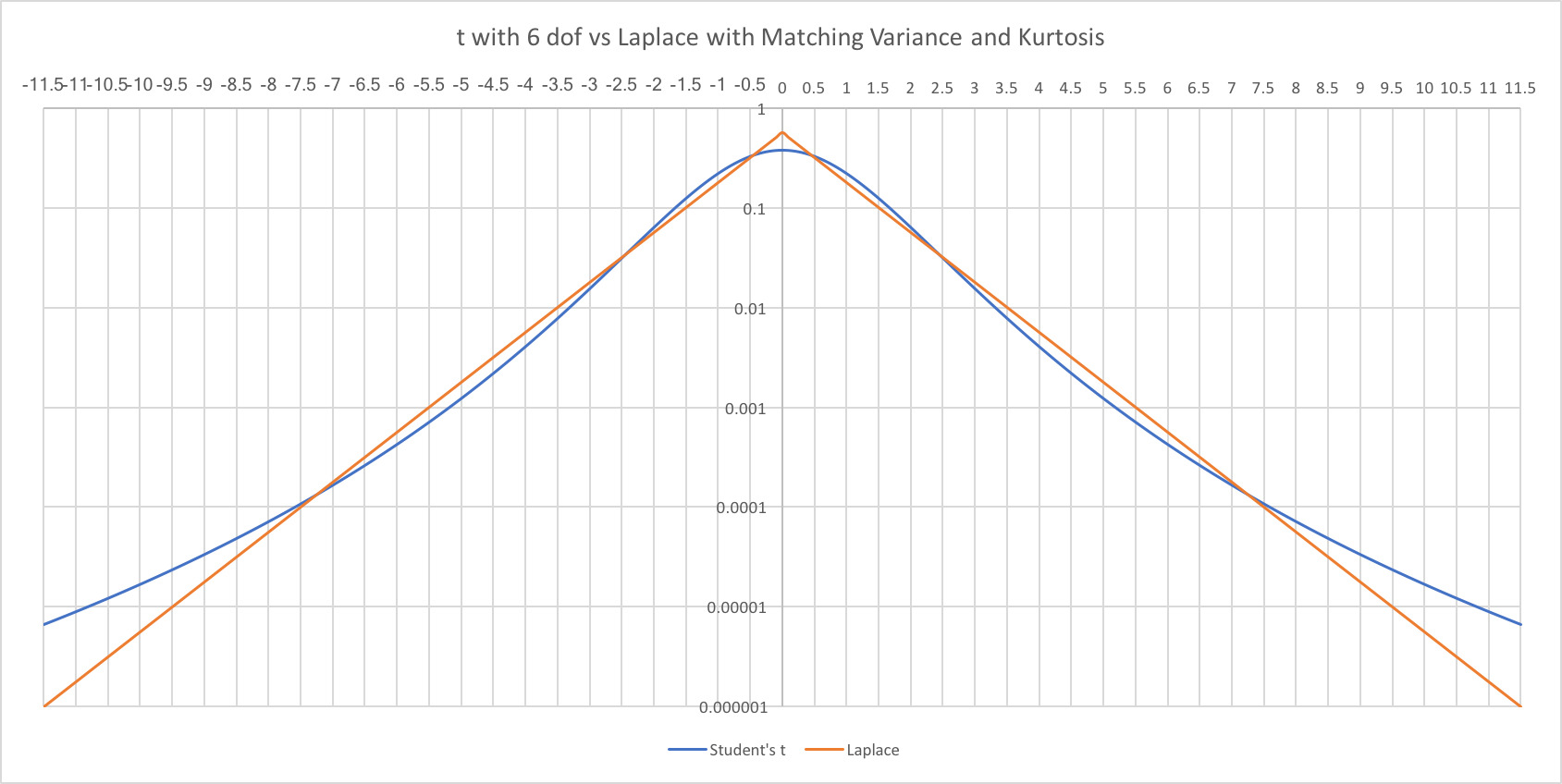



1. Background
Overparameterized models tend to be less accurate in their predictions than those with fewer parameters. For instance, the popular textbook by Burnham and Anderson states, “Overfitted models … have estimated (and actual) sampling variances that are needlessly large (the precision of the estimators is poor, relative to what could have been accomplished with a more parsimonious model)” (2002). Also see J. Frost (2015). Such discussions are framed in terms of fitting the model to the sample versus to the population. Getting the right balance between these two fits is the goal of a lot of statistical methodology.
Fitting parameterized curves to row or column factors is one way to mitigate overfitting, but finding the right curves can be an issue. Often actuaries keep a parameter for every row and every column, in part because it is not clear how to eliminate them, even though many of them are not statistically significant. The methodology discussed in this paper—of shrinking fitted values toward the overall mean—addresses that issue by reducing the predictive variance.
Credibility theory shrinks class estimates toward the mean using the average for the variance of individual classes over time and the variance of the class averages. The James-Stein estimator (described in Stein 1956) does so as well, but it uses model assumptions to quantify the average individual variance. Starting with Hoerl and Kennard (1970), statisticians have developed methods that shrink the estimated mean for each observed point toward the overall mean by using a shrinkage parameter, λ, which is selected based on how well the model works on predictions for holdout samples. Typically λ is tested by dividing the data set into 4–10 groups, which are left out one at a time and predicted by the model fit on all the other groups, with various values of λ. This procedure is called “cross-validation.”
The original regularization method is ridge regression, which uses parameters βj to minimize the negative log-likelihood (NLL) plus λΣ More popular recently is the least absolute shrinkage and selection operator, or LASSO, which minimizes NLL plus λΣ|βj|. This has the practical advantage that as λ increases, more and more parameters, and eventually all but the mean, go to exactly 0. This makes LASSO a method of variable selection as well as estimation, so the modeler can start with a large number of variables and the estimation will eliminate most of them. As λ gets smaller, the parameter size penalty vanishes, and thus the maximum likelihood estimate is obtained. Hoerl and Kennard (1970) proved that some λ > 0 always produces a lower error variance, so shrinkage can always improve predictive accuracy.
Usually all the variables are standardized by a linear transformation to make them mean 0, variance 1. That way parameter size is comparable across variables. The additive part of the variable transformations is picked up by the mean, which is not included in the penalty for the sum of the parameters and so is not shrunk. The other parameters end up being pushed toward zero, which in turn pushes each fitted value toward the mean. Blei (2015) and Hastie, Tibshirani, and Wainwright (2015) are good references.
A straightforward application of regularization would be to apply it to generalized linear model (GLM) modeling in ratemaking. Such modeling is just like regular GLM except that shrinking the parameters shrinks the fitted values toward the mean; thus, it is like GLM plus credibility, but with the shrinkage coming from the method instead of from within and between variances. Adding interaction terms would be convenient with shrinkage, as many of them would be shrunk to or toward zero unless they actually have predictive value. It would be easy to extend this method to distributions beyond those that GLM uses. Loss reserving, however, as discussed below, takes a little more doing to get into a regression form to which shrinkage can be applied.
Bayesian versions of regularization work by giving the parameters shrinkage priors, which are mean-zero priors—normal distributions for ridge regression and double exponential for LASSO. There are generalizations that use other shrinkage priors. The advantages of the Bayesian form are that it gives a distribution of parameters for parameter uncertainty calculations and that it has a goodness-of-fit measure analogous to the Akaike information criterion (AIC) for model comparisons. AIC, the Bayesian information criterion (BIC), and others do not work with regularized models due to parameter counting problems with shrinkage. Markov chain Monte Carlo (MCMC) estimation can numerically produce samples of the posterior distribution without needing to specify conjugate posteriors for the priors.
A classical approach similar to Bayesian estimation is random effects modeling. Instead of parameters having distributions, the effects being modeled have shrinkage distributions, such as a mean-zero normal distribution. The terminology used is that this method projects effects instead of estimating parameters. For instance, the differences between the frequency of an event in a territory and the statewide frequency of the same event could be a mean-zero random effect. The only parameter would be the variance of these effects, but the model projects each territory’s effect. One common method of projection is to maximize the product of the likelihood function with the probability of the effects. This turns out to be the same thing as computing the posterior mode in the Bayesian interpretation, but it can be done as a classical optimization. Ridge regression and LASSO are special cases of random-effects modeling.
A typical assumption in random effects is that each random effect has its own variance parameter. However, using the generalized degrees of freedom approach of Ye (1998), Venter, Gutkovich, and Gao (2017) found that having so many scale parameters can use up many degrees of freedom—that is, including them in the model makes the fitted values much more responsive to hypothetical small changes in the data points. Most random effects software allows users to specify the existence of just one variance parameter for the whole model, which seems to give a considerably more parsimonious model without sacrificing too much in goodness of fit. This procedure would get to the same result as ridge regression or LASSO.
For reserve applications, the starting point is a row-column factor model. To make it applicable in this context, the fitted value is the row parameter times the column parameter times a constant. For identifiability, there is no parameter for the first row or column other than the constant—that is, the factor for that row and column is 1.0. The problem with applying parameter shrinkage in this form is that if any parameter is eliminated, that row or column also gets only the constant. However, if the model is set up so that each parameter is the change in the row or column factor from the previous one, then when a variable is eliminated, that row or column just gets the factor for the previous row or column. Since the first row and column get 1.0 anyway, the factor for the second row or column is its parameter change plus 1.
This paper takes this activity one step further—instead of the parameters being these first differences, they are the second differences in the factors at each point. Then if one of these is 0, the modeled first difference does not change at that point, so the factor is on a line defined by the previous two factors. This seems to be a bit more realistic in actual triangles and allows for more parsimonious models.
The row-column model is a special case of the row-column-diagonal model. The latter is actually in wide use in the social sciences, where it is called the age-period-cohort (APC) model. The history of these models traces back to Greenberg, Wright, and Sheps (1950), who in turn referred to data analysis by W. H. Frost (1939). In actuarial work, a column-diagonal model was discussed by Taylor (1977), who called it the “separation model,” a term still used. The first actuarial reference to the full APC model appears to be the reserve model of Barnett and Zehnwirth (2000). Mortality modelers have been using various forms of APC models since Renshaw and Haberman (2006).
Parameter shrinkage methodology is starting to be applied in actuarial modeling. Venter, Gutkovich, and Gao (2017) modeled loss triangles with row, column, and diagonal parameters in slope change form fitted by random effects and LASSO. Venter and Şahın (2018) used Bayesian shrinkage priors for the same purpose in a mortality model that is similar to reserve models.
Gao and Meng (2018) used shrinkage priors on cubic spline models of loss development. Some precursors include Barnett and Zehnwirth (2000), who applied shrinkage to reduce or omit piecewise linear slope changes in reserve modeling; Gluck (1997), who did something similar for the Cape Cod model; and England and Verrall (2002), who used cubic spline modeling for loss triangles.
Section 2 discusses the row-column model for cell means and goes into more detail on applying parameter shrinkage. Section 3 discusses loss distributions for individual cells given their fitted means. The fitting methods and properties of the distributions are illustrated in Section 4 by fitting to frequency, severity, and aggregate loss data from a published triangle. Extensions of the row-column model are discussed in Section 5. Section 6 concludes. Appendices 1, 2, and 3 cover, respectively, distribution details, coding methods including examples and output, and the sensitivity of goodness of fit to the degree of shrinkage used.
2. Parameter shrinkage methodology
The data are assumed to be for an incremental paid triangle. A constant term, C, is included, and the first row factor and first column factor are set to 1.0. In the basic row-column model, the mean (or a parameter closely related to the mean, depending on the distributional assumptions) for the (w,u) cell is the product of row and column factors:
μw,u=AwBuC
Here Aw is the parameter for accident year (AY) w and Bu is the parameter for lag u. This basic model will be used for frequency, severity, and aggregate losses by cell.
There can get to be a lot of parameters, with one for every row and column. Parameter shrinkage aims at getting more parsimonious models that avoid overfitting and so predict better. This is the goal of regularization in general. Here there will still be a parameter for every row and every column, but several adjacent parameters could be on line segments.
When all of the observations are positive, an exploratory fit can be done using regression with shrinkage on the logs of the losses. Then the fitted values are the sums of the row and column log parameters, plus a constant. This can be set up in regression format with (0,1) dummy variables identifying the row and column an observation is in. This allows the use of commonly available estimation applications. The model in which the parameters are second differences can still be set up this way, but the variables become sums of more complicated dummies. This is illustrated in the example. For the distributions in the examples, an exponential transformation of this model is done, with the dependent variable being the dollar losses.
Some background on MCMC will help clarify the methodology. MCMC numerically generates a collection of samples from the posterior distribution when only the likelihood and prior are known. With data X and parameters β, Bayes’ theorem says the following:
p(β|X)=p(X|β)p(β)p(X)
The left side is the posterior distribution of the parameters given the data, and the numerator of the right side is the likelihood times the prior. The denominator p(X) is a constant for a given data set, so maximizing the numerator maximizes the posterior. In random effects, the numerator is called the “joint likelihood,” so maximizing it gives the posterior mode. The original MCMC methodology, that of the Metropolis sampler, uses just the numerator. It has a proposal generator to create a possible sample of the parameters from the latest accepted sample. If this increases the numerator, it is added to the collection of samples. If it doesn’t, there is an acceptance rule to put it in or not, based on a (0,1) random draw. After a warm-up period, the retained samples end up being representative of the posterior.
A refined version of the Metropolis sampler, the Metropolis-Hastings sampler, is more efficient. Further refinements include Hamiltonian mechanics and the no-U-turn sampler, which evolve the proposal generator dynamically. The latter is the basis of the Stan MCMC package, which is available in R and Python applications. Another methodology is the Gibbs sampler, which draws parameters sequentially from the posterior distribution of each parameter given the data and the latest sample of all the other parameters. The JAGS (Just Another Gibbs Sampler) package uses that method.
Basically, then, MCMC is looking for parameters that give relatively high values to the log-likelihood plus the sum of the logs of the probabilities of the parameters, using their priors. The posterior mode is at the set of probabilities that maximizes this sum. (This is also called the “maximum a posterior,” or MAP.) The posterior mode using the normal or Laplace prior gives the parameters estimated by the ridge or LASSO regression.
2.1. Posterior mean versus posterior mode
While classical shrinkage methods agree with the Bayesian posterior mode, the posterior mean is the basic Bayesian estimator. The mode is very similar to classical estimation in that both methods optimize some probability measure—such as the NLL or joint likelihood.
The posterior mean is a fundamentally different approach. It does not maximize a probability. Instead it looks at all the parameter sets that could explain the data, and weights each according to its probability. The most likely set of parameters has appeal, but it has more risk of being a statistical fluke. If it is similar to many other possible parameter sets, then it would probably be only very slightly higher in posterior probability and not much different from the mean. But if it is very different, it could be overly tailored to that specific data set. In that case, only a small percentage of the MCMC samples would be close to that point. The posterior mean is aimed at getting an estimate that would still perform well on other samples.
2.2. Measuring goodness of fit
Traditional goodness-of-fit measures, such as AIC, BIC, and so on, penalize the log-likelihood with parameter-count penalties. This is already problematic for nonlinear models, as the parameter count does not necessarily measure the same thing for them. Ye (1998) developed a way to count parameters using what he called “generalized degrees of freedom,” which measures how sensitive the fitted values are to slight changes in the corresponding data points. This is accomplished by taking the derivative of each fitted value with respect to the data point, usually numerically. It agrees with the standard parameter count given by the diagonal of the hat matrix for linear models.
Parameter shrinkage also makes the parameter count ambiguous, and from Ye’s perspective, the shrunk parameters do not allow as much responsiveness to changes in the data, so they do not use up as many degrees of freedom. For LASSO, the gold standard of model testing is leave-one-out, or LOO, estimation. The model is fitted over and over, each time leaving out a single observation, with the log-likelihood computed for the omitted point. The sum of those log-likelihoods is the LOO fit measure.
Both LOO and Ye’s method are computationally expensive and do not work well with MCMC anyway because of sampling uncertainty. To address these shortcomings, Gelfand (1996) developed an approximation for a sample point’s out-of-sample log-likelihood using a numerical integration technique called “importance sampling.” In his implementation, that probability is estimated as its weighted average over all of the samples, using weights proportional to the reciprocal of the point’s likelihood under each sample. That methodology gives greater weight to the samples that fit the point poorly, which would be more likely to occur if that point had been omitted. The estimate of the probability of the point comes out to be the reciprocal of the average over all samples of the reciprocal of the point’s probability in the sample. This is the harmonic mean of the point’s probabilities. With this calculation, the sample of the posterior distribution of all of the parameters as generated by MCMC is enough to do the LOO calculation.
That technique gives good, but still volatile, estimates of the LOO log-likelihood. Vehtari, Gelman, and Gabry (2017) addressed that issue using something akin to extreme value theory—fitting a Pareto to the probability reciprocals and using the fitted Pareto values instead of the actuals for the largest 20% of the sample. They called this technique “Pareto-smoothed importance sampling.” It has been extensively tested and has become widely adopted. The penalized likelihood measure is labeled loo, standing for “expected log pointwise predictive density.” It aims at doing what AIC and the other measures were trying to address as well—adjusting the log-likelihood for sample bias.
The Stan software provides a LOO estimation package that can work on any posterior sample, even those not from Stan. It outputs loo as well as the implied log-likelihood penalty and something Stan calls LOOIC—the LOO information criterion—which is ‑ loo, in accordance with standards of information theory. Since the factor is not critical, here the term “LOOIC” is used for loo, which is the NLL increased by the penalty.
2.3. Selecting the degree of shrinkage
Selecting the scale parameter of the Laplace or Cauchy prior for MCMC, or the λ shrinkage parameter for LASSO or ridge regression, requires a balancing of parsimony and goodness of fit. Taking the parameter that optimizes loo is one way to proceed, and that was the approach taken by Venter and Şahın (2018). However, this approach is not totally compatible with the posterior mean philosophy, as it is a combination of Bayesian and predictive optimization. An alternative would be to give a sufficiently wide prior to the scale parameter itself and include that in the MCMC estimation. This is called a “fully Bayesian” method and produces a range of sample values of λ. Gao and Meng (2018) is a loss reserving paper using the fully Bayesian approach. That is the approach taken here.
LASSO applications, such as the R package glmnet, use cross-validation to select a range of candidate λ values. An alternative is to build in more of the Bayesian approach. The Laplace (double exponential) prior is discussed in Appendix 1. There, the log density is given as log[f(β|σ)] = ‑log(2) – log(σ) – |β|/σ, with σ = 1/λ. Summing over the k parameters makes the negative log probability = k * log(2) – k * log(λ) + λΣ|βj|. This is the LASSO penalty on the NLL of the data, but if λ is a given constant, the first two terms are dropped. In addition, if λ itself is given a uniform prior with density = C over some interval, the second term needs to be included, but the uniform density is a constant that can be dropped. Thus the quantity to be minimized over λ, βj is as follows:
NLL−k∗log(λ)+λ∑|βj|
The uniform prior is an arbitrary but reasonable choice, so values of λ that are not at the exact minimum of this are possible candidates as well.
2.4. Estimation issues
Instead of doing MCMC, a nonlinear optimizer such as the Nelder-Mead method could be used to get the posterior mode through classical estimation. Good starting parameters seem to be needed, however. One advantage of MCMC is that it seems to be able to find reasonable parameter sets better than classical optimization. That might in fact be one of its historical attractions. However, MCMC can also find a lot of local maximums that are not very good fits. The lingo of MCMC appears to be that this will happen if the model is “poorly specified.” In practice, that seems to mean if the priors are too wide. Running the estimation with starting values from the previous better fits also can help avoid bad local maximums.
Starting with LASSO can give a starting point for MCMC. Stan is good at pointing out which parameters are not contributing to the fit, but the second-difference variables are negatively correlated and thus work in groups, which makes some individual parameter ranges less indicative of the value of those parameters. LASSO gives parameter sets that work together at each value of λ.
The Stan software used here is not able to include R packages such as tweedie and gamlss.dist. With good starting parameters from related Stan fits, classical estimation in R can maximize the posterior mode for the Tweedie and Poisson–inverse Gaussian (PiG) distributions discussed in Appendix 1, and it can at least compare fits by the posterior mode probabilities. Some of that was done in the examples below. Unfortunately, neither the posterior mean nor the LOOIC can be computed this way, so the comparisons are essentially suggestive.
3. Distributions for reserve modeling
The LOOIC measure provides a way to compare the fits for different residual distributions. In addition, MCMC—and to some extent maximum likelihood—makes it easy to estimate distributions that are not in the linear exponential family that GLM modeling requires. This feature allows better modeling of the residual distributions and better estimation of reserve range distributions. The distributions explored here provide more flexible modeling of mean-variance relationships across the triangle as well as skewness and higher moments.
Detailed distribution formulas are included in Appendix 1, but there are a few key takeaways:
-
Development triangles are subject to a unique form of heteroskedasticity. The variance is not constant among the cells, but it often decreases less than the mean does across the triangle, due to volatile large losses paying later. This phenomenon is addressed by introducing an additional variance parameter. The easiest example is that of the normal distribution—instead of a constant variance, the variance, and so the standard deviation, is sµk. If k < 1, the variance decreases more slowly than the mean. Something similar can be done for any distribution and is labeled as the “k form.” The Weibull k is particularly interesting as its skewness changes more than is seen in other distributions, often in a helpful way. In GLM the mean-variance relationship also determines the skewness and other shape features, but now these can all be modeled independently.
-
The Tweedie distribution, usually parameterized with variance = φµp, p ≥ 1, is reparameterized in a, b, p to have mean = ab, variance = ab2, and skewness = pa‑1/2. Then the distribution of the sum of variables with the same b and p parameters is Tweedie in Σaj, b, p. Also, if Z is Tweedie in a, b, p, then cZ has parameters a, bc, p. This puts the focus on controlling the skewness with the p parameter. In the usual form, the skewness is still p times the coefficient of variation (CV), but the skewness relationship is overshadowed by the variance. This additive feature makes it possible to fit a severity distribution even if only the number and total value of payments are known for each cell—the individual payments are not needed. This is the case for the normal k as well, but with a slightly different formula. The reparameterization also makes it easier to represent mixtures of Poissons by a Tweedie, which generalizes the negative binomial and PiG.
-
Choosing which parameter of a distribution to fix among the cells can also change the mean-variance relationship across the triangle. For example, the gamma with mean µ = ab and variance ab2 has variance = bµ = µ2/a, so fixing a in all the cells makes the variance proportional to the mean squared, but fixing b makes it proportional to the mean. This then works the same way with any Tweedie distribution, which allows either mean-variance relationship with any skewness/CV ratio, as determined by p. The form with variance proportional to mean often works fairly well, depending on how the larger loss payments are arranged. The Tweedie-mixed Poissons, such as the negative binomial, are related to this. They come in two forms with different mean-variance relationships, which arise from the mixing Tweedie having a or b fixed across the cells. When fitted to a single population—that is, to only one cell—the fits from the two forms are identical.
-
The typical overdispersed Poisson (ODP) assumption has variance proportional to mean, but the actual ODP in the exponential family takes values only at integer multiples of b, which is not what is needed for losses. Thus the ODP is usually applied to reserving with the quasi-likelihood specified but without any identified distribution function. The essential feature of this method is that the variance is proportional to the mean, so any Tweedie with fixed b, p could represent such an ODP, and in fact the gamma is often used in ODP simulations, where an actual distribution function is needed. But the gamma can be fitted directly by maximum likelihood estimation, which would allow the use of the Fisher information for parameter uncertainty instead of bootstrapping. (The parameters are asymptotically normal, but for positive parameters and usual sample sizes, a gamma with a normal copula usually works better for the parameter distribution.) Here we fit this form of the gamma by regularization.
Details are also given for the shrinkage distributions used in MCMC, and generalizations of classical LASSO and ridge regression are discussed along with them.
4. Example
As an example of this methodology, we model a loss triangle, including exposures, counts, and amounts, from Wüthrich (2003). With the additive property of the Tweedie, only counts and amounts are needed to model the severity distributions across the cells, and with exposures, the frequency distributions can also be modeled. The respective triangles are shown in Tables 1 and 2.
4.1. Exploratory analysis
It is often useful before fitting models to do some simple fits on an exploratory basis. The row-column factor model expresses the (w,u) cell mean as the product of row and column factors:
μw,u=AwBuC=exp(pw+qu+c).
The log additive form is often set up as a linear model, and before getting into the distributional issues, multiple regression on the logs of the losses can reveal much of the structure of the data. This step can be done if there are no 0 or negative data points, and in fact some conditional distributions for the data given the fitted means, such as the gamma, also require positive observations.
4.1.1. Design matrix
To set up multiple regressions, the whole triangle has to be put into a single column as the dependent variable. In building the design matrix, it is also helpful to have three columns that identify the row, column, and diagonal, respectively, that each data point comes from.
The design matrix has a column for each variable. Here, for specificity, the first row and column are not given parameters, and therefore design matrix columns are needed for the variables in triangle rows 2–9 and columns 2–10. It usually helps to put in a name for each column and the triangle row or column number above each name. For a typical regression or GLM model for a triangle, the variable for a row will be 1 for a cell if the cell is from that row, and 0 otherwise, and similarly for the columns.
The model favored here, where the variables are slope changes, can also be represented by a design matrix with dummy variables, but they are no longer (0,1) dummies. A row parameter is the sum of its previous first differences, written as and the first differences are sums of the previous second differences, so Then p2 = f2 = a2, p3 = f2 + f3 = 2a2 + a3, p4 = f2 + f3 + f4 = 3a2 + 2a3 + a4, and so on. Then the row parameter dummy ai is set to max(0, 1 + k − i) for a cell in row k. The same formula holds for column parameters, with slope changes denoted by bi. The entry for an observation in the design matrix is the number of times any slope change is added up for that observation. Table 6 shows the design matrix for the initial model.
Regressions can be done on both matrices. Calling the log column y and the design matrix x, this is easy enough to do in Excel with matrix functions, giving the parameter vector β = (x’x)‑1x’y. It is even easier with regression functions such as those available in the package Real Statistics. It and, in fact, all packages used here assume that the constant term is not in the design matrix, so from now on, x refers to the design matrix without the constant term.
4.1.2. Regression
Both the levels regression and the slope change regression give the same overall fit—see Table 3—but the t-statistics are different. Tables 4 and 5 show these for the two regressions. Usually t-statistics with absolute values greater than 2 are considered significant. By that measure, most of the row parameters in the levels regression are not significant, although those in the columns are. That might make this triangle a good candidate for the Cape Cod model. Parameter reduction will end up allowing some degree of variability among the rows, much in the same way as the generalized Cape Cod of Gluck (1997).
The trend regression parameters are in general less significant, but a lower threshold for t may be appropriate in that adjacent parameters are strongly negatively correlated—raising one and lowering the next would offset each other in all but one row. Thus they are more significant together than they are individually. When a trend change is low, that means the previous trend continues. The a2 parameter is probably significant, which would show a general upward trend from the first row. The column trend changes are significant in the beginning, with some fluctuation in direction, and then lose significance, which would mean a continuing trend.
4.1.3. LASSO
For large design matrices of second-difference variables, Stan can have difficulty finding good initial parameter values. In those cases, LASSO is often more efficient at identifying variables that are likely to end up with parameters close to zero and thus with no change in slope for the fitted piecewise linear curve. These variables can then be eliminated, producing the same effect. Usually I like to use a low shrinkage value, λ, for this purpose, so that not too many variables are eliminated in LASSO. Generally some more can be eliminated later—those that Stan estimates to have posterior distributions centered near zero—as long as omitting them does not degrade the LOOIC. This isn’t variable selection in the usual sense, as the variables eliminated would have parameter values of 0 if left in, so the whole design matrix is being used. It is more a matter of tidying up the model. The design matrix can feed right into LASSO software to get a start on parameter reduction. This step was not needed here since it is a pretty small triangle, but it is shown for possible use in other models.
Appendix 2.1 shows code for the R package glmnet. The program estimates the parameters for up to 100 values of λ, depending on some internal settings. It can print a graph of the parameter values as a function of decreases in λ, also shown in Appendix 2. Cross-validation is done in a function called cv.glmnet, which produces a target range for λ between lambda.min and lambda.1se, for this example the range (0.0093,0.1257). Here the variables with nonzero parameters for values of λ near 0.03 were passed on to Bayesian LASSO.
The range of λs is not passed on to Stan. I usually start Stan with a fairly wide prior for s = 1/λ, which is the Laplace scale parameter, but allowing s to be too high can lead to divergent estimation. After seeing the posterior distribution I might tighten the prior to exclude ranges that aren’t being used for the sake of efficiency. This seems to have no effect on the posterior distribution of s.
Bayesian LASSO has several advantages over classical, including giving a sample distribution of parameters for risk analysis, being able to include a distribution of values of λ, and having a goodness-of-fit measure, the LOOIC. The second and third columns of coefficients shown in Appendix 2 have the same nonzero variables, except for V10, V11, and V15. Keeping the variables in the second column except for V15 leaves the seven variables a2, a6, b2, b3, b4, b5 and b7, plus the constant. These are used in a reduced design matrix in Stan to do the MCMC estimation.
4.2. Aggregate triangle
The models to be estimated by MCMC are coded in Stan. Appendix 2.2 shows the code used for estimating the gamma distribution with fixed b, so with variance proportional to mean, from any design matrix x1. The model is as follows:
-
c is uniform(‑4,16)
-
logbeta is uniform(‑20,20)
-
beta = exp(logbeta)
-
logs is uniform(‑5, ‑0.2)
-
s = exp(logs)
-
v is double exponential(0,s)
-
alpha = exp(x1 * v + c) * beta
-
y is gamma(alpha,beta), where in Stan, beta = 1/b
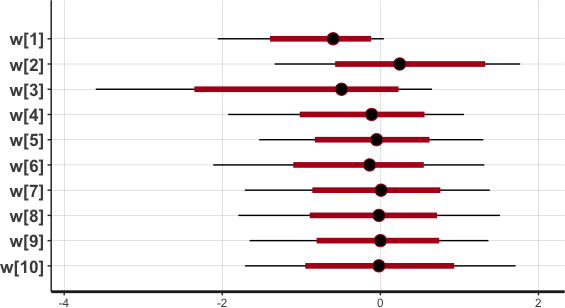
The output includes a graph of (0.05,0.95) and (0.2,0.8) percentile ranges for the parameters, shown in Figure 1. This is where parameters that are near zero with large positive and negative ranges can be reviewed for removal from the model. None of our results are like that. The resulting row and column parameters are compared with those from the full lognormal regression (Tables 3 and 4) in Figure 2. Not shown is the s parameter, which is in the range (0.32,0.77).
.png)
Normal k, GiG, gamma, and Weibull k distributions were fitted to the triangle. All have very similar row and column parameters but different LOOICs, due to the different distribution shapes. Table 7 shows the LOOIC, the NLL, and their difference, the parameter penalty. All except the gamma have a parameter for the power in the variance = s * meank relationship, but here all of those powers came out very close to 1.0. The gamma was fitted with the b parameter constant across the cells, so it also has the power k = 1 implicitly. This procedure thus saves a parameter. The GiG has one more parameter for the percentage normal, which is 30%.
The best-fitting distribution is the Weibull k, which is the Weibull with an adjustment fitted to the mean-variance relationship. It has the most variability by cell in skewness, which apparently helps for this data set. The 0 skewness of the normal k does not work well for these data even though the variance is proportional to the mean.
The Weibull k and gamma fits have about the same mean and CV by cell, but the skewnesses are different. Figure 3 graphs the common CV and the two skewnesses by lag for the second row, the last row that has all columns. Because the rows are all pretty similar, this graph would look about the same for any row. The gamma skewness is twice the CV, but the Weibull is consistently lower than the gamma. This appears to provide a better representation of the observations under the row-column model.

Appendix 3 looks at the sensitivity of the LOOIC measure to changing values of λ.
4.3. Severity
The data do not have individual payment observations, but due to the additive property of the Tweedie, the counts and total payments in a cell are enough to model the severity distribution. Severity is typically modeled with a constant CV across the cells. That requires the Tweedie severity a parameter to be constant. Each cell gets its own b parameter from the row-column model. Then the losses in a cell are modeled as Tweedie in a times the number of payments in the cell and the b for the cell, with any p. Here p = 2 and p = 3, so the gamma and the inverse Gaussian are fitted. The model with constant b, so with variance proportional to mean, is tested for comparison. If severity is normally k–distributed in µw,u, s, k, the payment total is distributed normally with mean = µw,u ∗ (counts) and variance = ∗ (counts).
For the gamma, the model equations are similar to those shown in 4.2 for aggregate losses, but now α is fixed across cells, not β, and counts are used in the calculation of severity. The y variable is the observed severity means by cell, which have variances of ab2/count, given the gamma claims severity with mean ab = α/β and variance ab2 = α/β2. This makes the severity mean gamma with both α and β multiplied by the counts. The model equations are as follows:
-
c is uniform(‑30,0) for the severity
-
logalpha is uniform(‑30, ‑1)
-
alpha = exp(logalpha)
-
s is uniform(0.01,0.02), although it was wider in earlier runs
-
v is double exponential(0,s)
-
beta = alpha/exp(x1 * v + c), so alpha/beta is mean
-
y is gamma(alpha * counts, beta * counts), where in Stan, beta = 1/b
The starting point is to use the same seven variables that were optimal for aggregate losses. For the gamma distribution, the parameter graph with (5%,95%) and (20%,80%) ranges is shown in Figure 4. From the graph, v[6], which is the coefficient for the column 5 slope change, has a mean close to zero and a wide range—just the sort of graph that indicates a parameter is not needed. Indeed, eliminating that parameter improves the LOOIC slightly. The remaining variables are the slope changes for rows 2 and 4, and for columns 2, 3, 4, and 7.
.png)
The design matrix for those data is now used for the three distributions. The gamma with a fixed is the best fit. For the inverse Gaussian, holding b constant, which makes the variance proportional to the mean, is actually slightly better than fixing a. Fit measures and the fitted moments are in Table 8, showing that the variance power appears to bear an inverse relationship to the skewness—that is, the more skewed distributions have the lowest power.
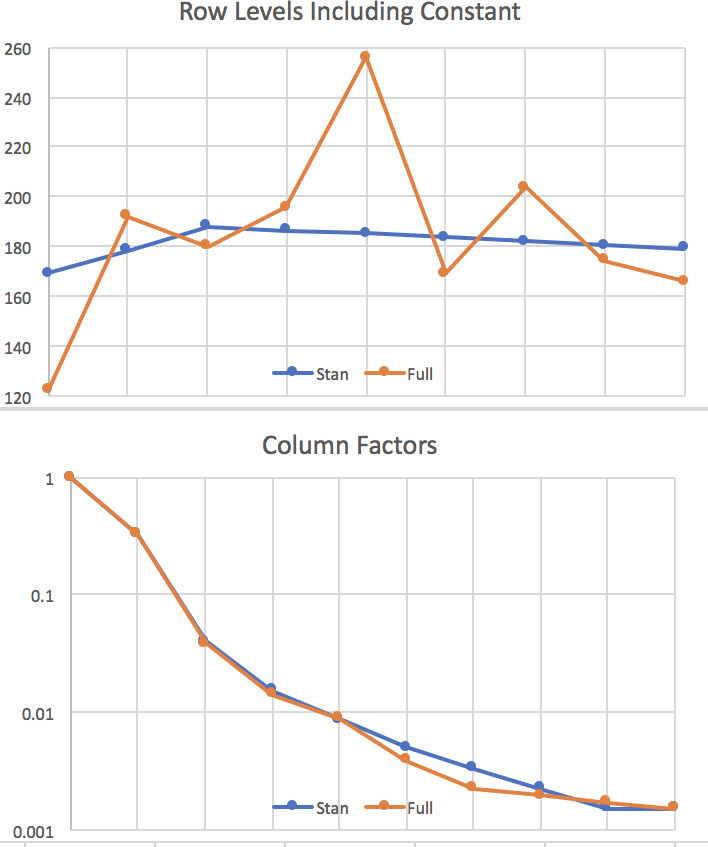
Figure 5 graphs the resulting level factors (not differences) for the gamma and the inverse Gaussian. The column factors are indistinguishable for the two distributions. Severity grows fairly steadily across AYs, and it is highest at the fifth lag. The raw severity mean is highest for the seventh and eighth columns but is also highly volatile there.

It is not possible to use the R Tweedie package within Stan, but it can be used with a nonlinear optimizer, such as optimx, to estimate the posterior mode parameters. That requires a short R program to compute the product of the prior, which takes a closed form, with the density from the Tweedie package for the cells, whose means come from the linear model. We now try that for the Tweedie with a fixed across the cells using a Cauchy prior with σ = 0.1. It produces an estimate of p = 2.1. This is close to the gamma distribution value of p = 2 and therefore looks pretty good.
4.4. Frequency
Cell counts and AY exposures are in the available data, so mean frequency in a cell is modeled with the row-column model, and the number of claims is modeled with its mean equal to the cell frequency mean times the row exposure. The Poisson distribution and two forms of the negative binomial (NB) are fitted. NB1 is the one with variance proportional to the mean, and NB2 has variance as a quadratic function of the mean.
The fit measures are shown in Table 9. NB2 is clearly the best fit. Its row and column factors for six chains are graphed in Figure 6. Payment frequency declines slightly by row and sharply by column.
NB2 takes two parameters, µ, φ, with mean µ varying by cell and with variance = µ + µ2/φ for constant φ. As usual, µ comes from the exponentiation of the linear model but then is multiplied by exposures by cell. The log of φ is given a uniform prior.
The PiG probability mass function is technically of closed form, but it uses modified Bessel functions that cannot be computed for large arguments in double-precision arithmetic by the usual methods. However, the dPIG function in the R package gamlss.dist is able to calculate it. We use this method to maximize the posterior mode as was done above for the Tweedie severity. The PiG’s NLL is a little worse than that of NB2, and its LOOIC is probably similar, assuming the shrinkage is comparable. It is a more skewed distribution, so the NB2 appears to have enough skewness for these data.

5. Extensions of the row-column model
We now discuss a few extensions of the basic row-column model for this methodology. The aggregate triangle with the gamma distribution is used with fixed b, so variance is proportional to mean, as it is a good-fitting model and its estimation is fast—one or two seconds typically.
5.1. Additive component
Müller (2016) suggested expanding the multiplicative model with an additive component. He argued that some part of loss development is from late-reported claims, and these could be more related to exposure than to losses that have already emerged. Any AY exposure variable, such as premium or policy count, would be the starting point. This would be multiplied by coefficients by column and then added to the row-column mean for the cell. Even a constant exposure for all the rows could be used if exposure is not available or has already been included, as in a loss ratio triangle. Also, the coefficients could be on a curve fitted across the columns, just as the other parameters are. The resulting model for the cell mean, µw,u, is
μw,u=AwBuC+DuEw,
where Ew is the exposure for AY w (or just a constant) and Du represents column parameters.
The idea that this comes from late-reported claims suggests that the coefficients would all be positive, but another possible interpretation is that this is an additive term to adjust for bias from a purely multiplicative model. Then it would not have to be positive.
Next, we fit a positive factor by column and apply it to AY exposures, with the result added to the row-column means. This can be done in logs with another design matrix, x2, for the slope changes for the column parameters. This design matrix is the same as the column parameter design matrix, except that it includes a dummy variable for the first column as well. There is also a vector called expo that has the exposures by row, scaled down by 100,000 so the coefficients don’t have to be too minuscule. Key model steps are these:
-
logbeta is uniform(‑20,20)
-
beta = exp(logbeta)
-
v is double exponential(0,s)
-
w is double exponential(0,s)—this represents the additive column parameters
-
alpha = exp(x1 * v + c) * beta + expo * exp(x2 * w) * beta (one could use the dot product for expo)
-
y is gamma(alpha,beta), where in Stan, beta = 1/b
The resulting additive parameter ranges are shown in Figure 7. Most of these are centered near zero, with wide ranges. Keeping just the first three gives a good fit to the triangle, with LOOIC and NLL of 99.9 and 90.1, respectively, compared with 103.6 and 93.8 for the row-column gamma model. There are nominally three extra parameters here, but the LOO parameter penalty is about the same, at 9.9, as the 9.8 of the base model. The penalty comes from the out-of-sample fit, which is apparently better with the exposures included. Perhaps the exposures allow more shrinkage of the other parameters. The exposure factor is 0.653 for the first column and 0.606 for the second. After that, it falls by a multiple of 0.545 for each subsequent column. This is believable as an effect of claims incurred but not reported, as it is strongest early on and then practically disappears by the end.

5.2. Calendar-year effects
Inflation can operate on payment years more than on AYs per se, as jury awards and building costs are typically based on price levels at the time of payment. This phenomenon can be modeled by adding calendar-year factors to the model or by using them instead of AY factors. With just diagonal and column factors, this approach has been called the “separation model” since Taylor (1977).
Another type of calendar-year effect comes from changes in loss processing, which could speed up or slow down payments in just a few diagonals. Only one or two diagonal parameters are able to model this. Such effects do not need to be projected, but adjusting for them can reduce estimation errors on the other parameters. Venter (2007) applied that principle to the triangle of Taylor and Ashe (1983), for example.
Either way, the mean for the multiplicative model with calendar-year effects included is
μw,u=AwBuGw+u−1C
The cell in row w and column u will be on diagonal w + u – 1, assuming the columns start at 1, and rows and diagonals start with the same number. Gw+u–1 is thus the trend factor, and in this framework it is the exponentiation of a cumulative sum of the modeled second differences that have shrinkage priors, just as the As and Bs are.
Including diagonal parameters can make row and column factors ambiguous, so some constraints are needed if all row, column, and diagonal factors are to be used. One approach is to adjust for row levels by such means as dividing by premiums or exposures. In that case, it is fair to assume there is no overall trend in the AY direction and therefore all the trend is on the diagonals. We can still have row factors, but in the estimation we make them the residuals to a trend that runs through them, so that a trend line fitted to them would simply be the x-axis. This idea is discussed in more detail by Venter and Şahın (2018). But if parameter reduction eliminates a fair number of parameters, this step might not be necessary.
A good starting point for the exploratory analysis is to fit both the row-column and the diagonal- column models with log regressions in second-difference form. This can give an indication as to whether the row or the diagonal factors are more explanatory. Usually before this procedure, the triangle should be divided by an appropriate AY exposure measure, such as premiums, policy counts, or similar. In a row-column model, the row parameters can pick up such known row effects, but even in that model, adjusting for them first can help with parameter reduction. We apply this method to the sample triangle using the exposures above (divided by 100,000 to keep the loss numbers in the same range).
This triangle with 9 rows actually has 11 diagonals, as 2 short rows usually found at the bottom of the triangle are not provided. The two initial regressions, with all rows and columns or all columns and diagonals, have very similar R squared values: 95.75% for rows and 95.76% for diagonals. But since there are more diagonals, the respective adjusted R squared values reverse, at 94.1% and 93.8%. But none of the row or diagonal t-statistics are greater than 1.8 in absolute value. This again suggests a Cape Cod model. Just small differences among row effects end up as an aspect of the resulting MCMC estimation.
Again LASSO is a good starting point for parameter reduction. The negatively correlated variables make it difficult to know which individually insignificant variables to leave out. LASSO selects groups of variables for each λ. Running it for each of the two regressions gives possible variable sets for use in MCMC. Since all of the row and diagonal parameters are individually insignificant, the lambda.min variables are taken; with the choices set out above, this λ gives the largest set of variables, some of which can be eliminated later. All of the columns except 6, 8, and 9 are included, as are rows 2, 3, and 6, and diagonals 5, 8, and 11.
The best row model is with rows 2 and 3 and columns 2, 3, 4, 5, 7, and 9. It gives a LOOIC of 103.3 with an NLL of 92.6 and a penalty of 10.7. These are not strictly comparable to the results obtained without dividing the triangle by the exposures. The best diagonal model is not as good, with a LOOIC of 111.1, an NLL of 101, and a penalty of 10.1. This includes only diagonal 5, although including 5 and 8 works about as well. Thus the rows provide a better account of this triangle than do the diagonals. In fact, when the calendar-year trend is fairly constant, there is usually no need for diagonal parameters, since the trend is projected on the row and column factors.
Since there are only a few row and diagonal parameters, they can all be included in a single model. Doing so and then eliminating parameters near zero leaves just row 2; columns 2, 3, 4, 5, and 7; and diagonals 5 and 8. The LOOIC and NLL are 99.0 and 89.7, respectively, with a penalty of 9.3. This is easily the best-fitting model by these measures. Similarly to the exposure adjustment, a lower penalty results, even with the same number of nominal parameters.
5.3. Calendar-year effects with exposure adjustment
Finally, putting it all together, the exposure adjustment is included in the row-column-diagonal model. Since the whole triangle has already been divided by the exposures, just a constant is used instead of the actual exposures by row. This simplifies the coding. To keep factors in the same scale, the constant used is 10. The code is in Appendix 2.2.
In this model, column 7 is no longer significant. Table 10 shows the estimated parameters, and the resulting factors for rows, columns, diagonals, and exposures are in Figure 8. The exposure factors by column are denoted by d. The resulting LOOIC and NLL are 97.4 and 87.1, respectively, with a penalty of 10.3. The exposure parameters do increase the penalty a bit in this case. There are nominally 12 parameters in this model, but since they have been shrunk, fewer degrees of freedom are used—probably about 7. This is thus a fairly parsimonious model to produce the 40 row, column, diagonal, and exposure factors plus the constant and β.

5.4. Parameter distributions
It is easy in Stan to extract the sample distributions of the parameters. Code for this procedure is in Appendix 2.3. It is used here to make a correlation matrix of the parameters, shown in Table 11.
The diagonal parameters c5 and c8 have a lot of correlations with row and column parameters, as does the constant. The exposure parameters d1, d2, and d3 are negatively correlated with each other, as they represent adjacent slope changes and thus somewhat offset each other. The first row and column parameters, a2 and b2, have a degree of correlation as well, and they are both negatively correlated with the constant, which offsets them to some degree—especially a2, as it is the only row parameter.
6. Conclusion
Reducing overparameterization is known to improve the predictive accuracy of models, and parameter shrinkage is a proven way to reduce the error variances by reducing the actual and effective number of parameters. In loss reserving, eliminating factors is not usually possible, but making factors from the cumulative sum of slope changes facilitates parameter reduction. Building a design matrix of slope change variables is the starting point, and then LASSO and Bayesian parameter shrinkage can be applied to do the estimation. There are R packages for these operations that require minimal programming.
In the end, LASSO is more or less a feeder to the MCMC estimation, as MCMC provides better tools for determining the degree of shrinkage and for measuring predictive accuracy as well as providing parameter uncertainty distributions. MCMC also can handle most probability distributions. Still, the negative correlation of the slope change variables makes it harder to tell which combination of variables to eliminate. LASSO is a good starting point for this purpose, especially in big data sets.
Extensions of the row-column factor model can improve performance. Here, using diagonal trends and including an additive exposure-based component both prove helpful. These are not unusual findings—including an exposure component almost always seems to help, and correcting for diagonal events often does.
The gamma distribution with the scale parameter held constant across cells makes the variance proportional to the mean, which is useful for reserve modeling. The variance-mean relationship can be further controlled by adding a parameter for it, as in the normal k and generalized inverse Gaussian distributions. Modeling skewness can improve the range predictions. Special cases of the Tweedie distribution are useful for that, and they also allow for modeling of the severity distribution with only counts and amounts in total, not individual claims. The Weibull k distribution provides a different skewness effect, which can sometimes be appropriate. Mixing Poissons by the Tweedie gives two versions of popular frequency distributions.
6.1. Ideas for further research
After the bulk of the work on this paper was completed, a new R MCMC package became available. BayesianTools does MCMC estimation with a version of the Metropolis sampler for any probability distribution whose likelihood can be computed in R. This would include the Tweedie and PiG distributions along with the Sichel—a more generalized, heavy-tailed count distribution. It is not mature software like Stan and seems to crash easily by getting parameter values that generate infinities, but it is promising. Preliminary tests confirm the random effects–posterior mode results for the Tweedie and PiG discussed in Sections 4.3 and 4.4 by getting the posterior mean fits. The main difficulty is the package’s delicacy in needing good starting points.
The heavy-tailed count distributions can be useful to actuaries now and then, but the reparameterized Tweedie would appear to have a lot of potential applications, for both severity and aggregate samples. Most triangles have aggregate losses. This Tweedie variance and mean use just the a and b parameters, and the skewness needs just a and p. This makes it easy to get a desired moment combination. It is more convenient this way than using most of the transformed beta-gamma family, for instance.
For 1 < p < 2, the Tweedie has a positive probability at 0 and so can accommodate data with some 0 values, which occur often in triangles. The standard parameterization also accommodates 0 values of p, with slightly different moments, so the two could be compared to fine-tune the fit. Both parameterizations will work with the R Tweedie package and so could have parameter shrinkage applied. Quasi-likelihood is usually used for the standard version, but it is not clear how to apply shrinkage there. Probably it could be done by adapting the random effects–posterior mode approach, and there might be a way to get MCMC to treat the quasi-likelihood as a likelihood. But there seems little reason to do that if the density is already calculable in R.