





1. Introduction
Text mining is a knowledge-intensive process in which the dataset is represented by documents (Bash 2015). Originally introduced for descriptive purposes only, it has recently evolved to include methods able to classify documents according to their latent topic or to infer information about the “sentiment” of customers or the users of social networks. The approaches have been boosted by the evolution of both the computational efficiency of the algorithms necessary to analyze textual data and the technology needed to store information.
This work does not aim to explain in detail what text mining is. Relevant and comprehensive references are provided by Bash (2015) and Feldman and Sanger (2006). What we wish to show is how insurance companies can exploit this methodology to extract valuable information from unstructured data. In insurance, as in many other contexts, there is a strong need for text classifiers because companies collect an enormous quantity of text data every day from multiple sources, such as customer feedback, claims adjuster notes, underwriter notes, police reports on accidents, medical records, surveys, e-mail messages, web documents, social media posts, etc. Text analysis could help companies to refine the following:
-
Marketing campaigns
-
Brand management
-
Fraud detection
-
Claims management and compensation
-
Subrogation
-
Relationships between the help center and clients
-
Analysis of contract clauses
To assess the possibilities offered by text mining, a UK insurer[1] recently introduced a motor insurance policy that granted discounts to first-time drivers who agreed to give the company access to their Facebook profiles[2] (recent changes to data privacy regulations do not allow the experiment to be repeated). Given access to the profiles, the company developed an algorithm that analyzed all user posts, likes, and GPS locations in order to perform a personality test. By analyzing each user’s style of writing, the algorithm could uncover positive and negative traits. In this way, personality traits could be used as predictors of a customer’s life and driving behavior and to assess criteria for determining eligibility for an insurance discount.
As suggested by this experiment, one of the potential competitive advantages of text exploration in insurance is the possibility of enriching customer risk profiles based on the standard structured “Company DB” customer database. Ideally, we are referring to a framework in which actuaries gather information from an unstructured “Cloud DB,” fed by an external source (e.g., documents, web sources, etc.). The Cloud DB shares information with the Company DB through appropriate link variables that are able to connect the Cloud DB profiles and the company’s customers, thereby allowing the aggregation of the two apparently disjointed data sources.
Text mining is a challenging research field. Issues include the need to analyze very large quantities of data, the unstructured nature of text data, and the complexity of finding keys to standardize language for inferential purposes. For example, in the case of insurance companies, the language in text data varies from colloquial to formal. In police reports or claims adjuster notes, we might find that the terminology used is often repetitive, with lexical structures that are sometimes fixed and predictable, but this does not apply to social media, which is always changing and therefore cannot be analyzed using standard methods.
This contribution fits into the big data paradigm (Bühlmann et al. 2016). Generally speaking, big data may be depicted as an unstructured, large, heterogeneous, and unstable data set that often hides latent relevant information not measurable through a standard sampling process. Big data may include documents; the tweets on the web; any social network; sentiment about the health of the economy, the status of a country, or a company; or the flow of documents produced during daily work (e.g., reports, recipes, phone calls, e-mails). Using an extensive description of a case study, we aim to show the possibilities offered by text mining to extract latent information that might be used by insurers to fine-tune policy pricing or to better assess customer risk profiles.
The paper is organized as follows. Section 2 briefly describes how a document can be analyzed using text mining. Section 3 shows how natural language processing (NLP) (Clark, Fox, and Lappin 2010) algorithms may be used to classify a document. Section 4 tests the efficacy of text mining in extracting latent information useful for insurance pricing and presents results of NLP applied to a collection of reports produced by the National Highway Traffic Safety Administration (NHTSA 2008) about accidents that occurred in the United States between 2005 and 2007.[3] Conclusions are provided in the final section.
2. N-grams and the prediction of words
Documents are the focus of text mining. A collection of documents is known as a corpus. Once we have chosen the document unit, we need to set the granularity level of the analysis, after which we can analyze single characters, words, phrases, or even groups of phrases.
One of the most common tools used to analyze a document is the n-gram, a sequence of n words (or even of characters) obtained from a document. This is a sort of rolling window of size n: by moving this window by one position at a time, we obtain a list of new n-grams. For example, let us consider the sentence “The police stopped a vehicle without insurance.” We can build different n-grams by varying the length n:
-
n = 1 (unigram) returns {“The,” “police,” “stopped,” “a,” “vehicle,” “without,” “insurance”}
-
n = 2 (bigram) returns {“The police,” “police stopped,” “stopped a,” “a vehicle,” “vehicle without,” “without insurance”}
-
n = 3 (trigram) returns {“The police stopped,” “police stopped a,” “stopped a vehicle,” “a vehicle without,” “vehicle without insurance”}
The choice of the size of the n-grams is linked to the complexity of the problem and to the scope of the analysis. Using a high value of n means incorporating more context into the units of the document, while a low n value means that the basic unit of data will be more granular.
An n-gram model can also be seen as a Markov chain of elements, where m is the length of the sentence (e.g., number of words). Therefore, the outcome of the n-grams might be seen as a stochastic process that predicts words given a certain history or context. Since the model is a Markov chain, it does not take into account all the history of the previous words but considers only the most recent word/history. This is a simplification of how documents are written because it does not focus on grammar rules to estimate words but only on their context. According to this framework, we can build the joint probability of words in a sentence using the chain rule:
P(w1w2…wm)=m∏i=1P(wi|w1w2…wi−1)
where is the i-th word of a sentence of length m and equals when It is worth noting that we obtain the joint probability of a document by multiplying the probability of each word conditioned over all the previous words. For the sentence reported above, we obtain:
P(‘‘The police stopped a vehicle without insurance")=P(The)×P(police|the)×P(stopped|The police)×P(a|The police stopped)×P(vehicle|The police stopped a)×P(without|The police stopped a vehicle)×P(insurance|The police stopped a vehicle without)
To compute the probability, this approach requires counting and dividing the occurrences of each word for all the possible sentences. An example is:
P(vehicle|The police stopped a)=#(The police stopped a vehicle)#(The police stopped a)
Unfortunately, this will lead nowhere because we will rarely have enough data to compute these probabilities consistently. To avoid this issue, an n-gram language model is used. The aim is to limit the context in which a word is used. Instead of using all the previous word history, we take only a subset of it. Therefore, equation (2.1) can be approximated using an n-gram model of order n according to:
P(w1w2…wm)=m∏i=1P(wi|w1w2…wi−1)≅m∏i=1P(wi|wi−(n−1)…wi−1)=#(wi−(n−1)…wi−1,wi)#(wi−(n−1)…wi−1)
where the number of words used to condition the probabilities is n − 1.
For instance, in the case of a bigram language model, each word probability will be conditioned only by the previous word. In our example we have:
P(‘‘The police stopped a vehicle without insurance")=P(The)×P(police|The)×P(stopped|police)×P(a|stopped)×P(vehicle|a)×P(without|vehicle)×P(insurance|without)
The use of an n-gram model allows us to reduce the number of cases in which occurrences are counted. Intuitively, as the order of the n-gram model increases, the n-gram frequency decreases. This is because every character sequence obtained from the model needs to be matched over the entire corpus (for example, “stopped a vehicle”).
The above description is an oversimplified approach to document analysis. In every text mining application, a key point is to understand how words and punctuation are joined together to express concepts. The definition of grammar rules is certainly crucial, but to assure a proper representation of data we need to simplify these issues.
The “bag-of-words” model is an approach used to deal with the complexity of text data. It assumes that all the terms have the same importance in a document; that is, there is no distinction between different parts of speech (verbs, nouns, adjectives, etc.). We are not interested in their position in the text, and so they can be seen as a set of strings without meaning. The term bag of words is self-explanatory because it refers to a document as a bag of words that can be extracted without considering the order.
2.1. Representing text data
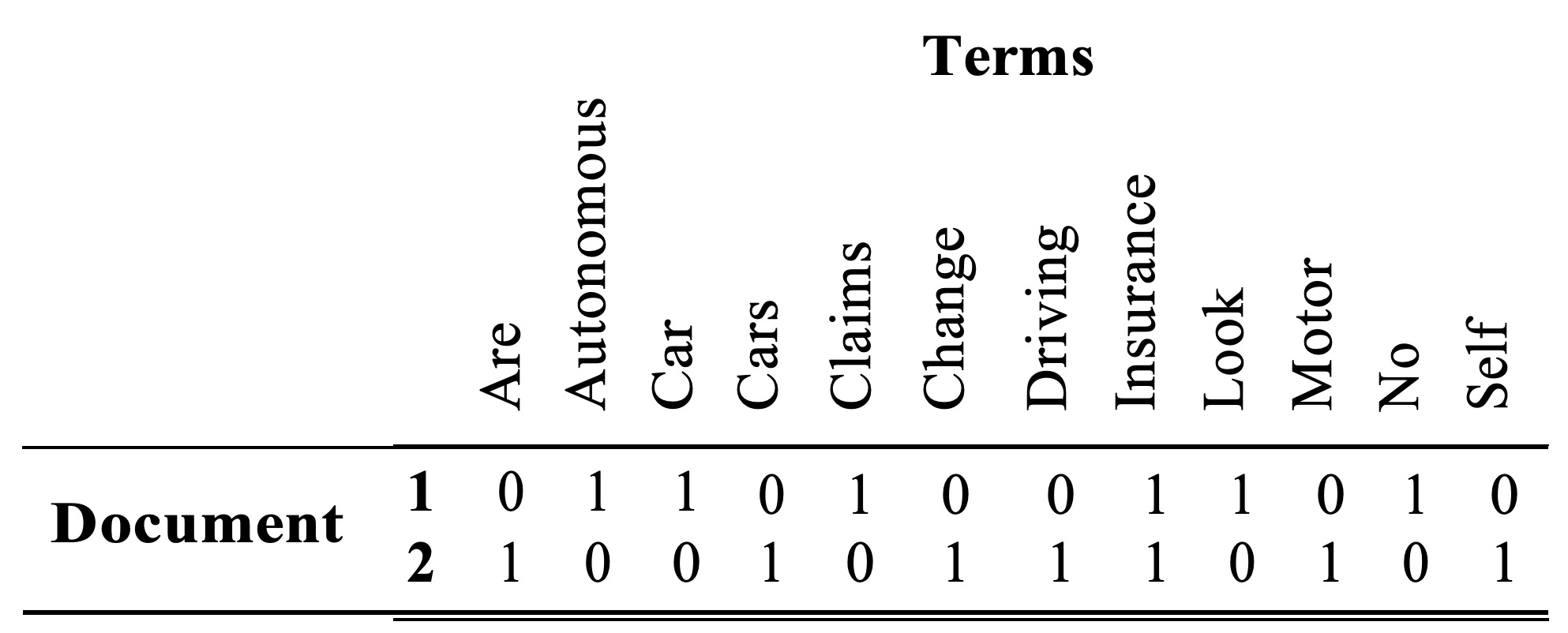
To show how a document can be numerically represented, let us consider, for instance, the following two simple phrases (which will be generically called documents):
-
“Autonomous car insurance. Look, no claims!”
-
“Self-driving cars are set to change motor insurance radically.”
Next, let us consider a matrix on whose columns we place every unique term in the corpus and on whose rows we place the document IDs. When terms are present / not present in documents, the cells will take the value 1/0, thereby giving the matrix a non-negativity connotation.
This representation allows us to move from unstructured data (i.e., a collection of text documents) to structured data that can be analyzed by applying data mining methods. This numerical structure also has three important properties: sparsity, non-negativity, and side information. Punctuation also plays an important role in giving context to documents, especially when we have corpora composed of documents retrieved from the Internet, e-mails, and other sources of data in which informal language is typically used. We can add the frequency with which signs are present among classified documents. This will give us an indication of how frequently some punctuation signs are in documents.
To obtain a simpler numerical representation of the corpus, we can opt to reduce the number of features, e.g., prepositions, “generic” verbs (be, have), etc. In Table 1 we have eliminated duplicated terms, punctuation, derived words, and so on. These are a few of the dimensionality reduction techniques applied in the following paragraphs to reduce the complexity of document representation.
2.2. Tokenization
Tokenization is a process that consists of breaking up documents (classified as words, n-grams, or phrases) into elements called tokens, which are used as an input to text mining procedures.
Tokens might be similar but stylistically very different from one another: for example, some have capital letters while others have numbers or punctuation signs in them. In addition, some tokens have no meaning and thus would add no information to the documents’ representation. To resolve these issues, we apply the most commonly used normalization techniques to the tokens to obtain the most meaningful subset of them. Examples of nonrelevant tokens are case, punctuation, numbers, hyperlinks, and spelling.
A relevant example is given by American and British English spelling. Despite the fact that both fall under the English language category, there are cases in which the spelling of certain words differs:
-
Analyze – Analyse
-
Program – Programme
-
Center – Centre
In an information extraction problem, this causes difficulties: even if the words have the same meaning, the fact that they are spelled differently prevents us from obtaining matches during search operations. Obviously, the same holds for words that are used differently in the two dialects: holiday or vacation, hire purchase or installment plan, and so on.
Once the tokenization process is completed, we reduce the number of features to select the more significant ones by removing the so-called stop words. We can think of stop words as words that are useful for the syntactic construction of phrases but whose semantic value is important relative to the context in which they are inserted. For example, the use of the preposition to or for can change the interpretation of phrases (“I’ll take it to him” and “I’ll take it for him” have different meanings). Thus, in this case, removing the prepositions might affect the interpretation of the phrases and undermine the document’s meaning. To deal with stop words we use a stop words dictionary, which is a collection of all the terms that we consider unnecessary to our specific problem and that can thus be removed. Since stop words dictionaries are already available in all of the most common languages, a dictionary can be downloaded and then tweaked by adding or removing specific terms.
2.3. Stemming and lemmatization
Once the removal of numbers and punctuation has been completed, we can further simplify the features using a stemming or a lemmatization process. In English, as well as in other languages, verbs have different inflectional forms or suffixes to which they are related. For example:
-
see, saw, seen → see
-
insurance, insurer, insure, insured → insur
Stemming is merely a heuristic process that truncates the end of every word to reduce it to its common base, also called the root. In English a process that truncates the last characters of every term may have success in removing excess characters, leaving only the common base for the matching algorithms. The most common stemming algorithm for the English language is the one proposed by Porter (1980).
To improve the accuracy of the truncation process, we can use another technique called lemmatization. Basically, instead of defining rules to truncate words, we use a lemmatizer, which carries out a full morphological analysis to accurately identify the so-called lemma for each word. Lemmatization removes inflection suffixes and compresses words into the lemma, which we define as the canonical form of a term, stripped of most conjugation suffixes and transformations. Intuitively, we can think of a lemma as the word we look up in a dictionary when searching for a specific term.
To show the impact of these processes, we refer to a corpus of documents collected from Twitter. We have retrieved tweets regarding the insurance sector in Italy. The tweet-gathering process was spread across three months, making it possible to collect 15,909 tweets that included the word "assicurazione" (Italian word for “insurance”). The number of documents in this corpus is far greater than the number of documents used to explain how to prepare a text before the representation. Table 2 emphasizes how the processes outlined above are able to reduce the document complexity.
The original corpus of 15,909 documents is composed of 237,091 tokens. This number indicates the total number of words from the tokenization process. Note that after the stop words have been eliminated, the quantity of the tokens was reduced to 6% of the original data set.
2.4. Vector space models
Once the list of tokens is ready, we need to find a way to describe the whole document. One choice is to use vector space models (Lappin and Fox 2015, Ch. 16).
A document can be seen as a vector whose dimensions are given by the number of features (Turney and Pantel 2010). This representation is called a document-term matrix. By switching columns and rows, we obtain the so-called term-document matrix.
Placing documents into a multidimensional space requires an accurate coordinate system. Ideally, documents that are similar are also close to each other, while documents that are semantically different need to be distant. Using only term frequency is not enough to capture similarities if there are no informative words with a high occurrence rate. Hence, the tf-idf (term frequency–inverse document frequency) technique is typically used; this is a statistic that reflects the importance of terms in a corpus.
In general, a term is more important than others when it occurs multiple times in a document and when it is also rarer than other terms in the corpus. If we are analyzing a collection of documents from a division of an insurance company, we may find that terms such as claims, underwriter, premium, and reserve appear quite frequently. However, their presence is common to every document in the collection, and so the value of the tf-idf statistic will not be as high as we would have expected while using only term frequency. Terms such as windstorm, subrogation, and tsunami may be less frequent than the previous ones, but they are more peculiar and rarer. Peculiarity and rarity are two qualities we look for when representing documents. To this end, the td-idf statistic combines two quantities:
-
Term frequency
-
Document frequency
2.4.1. Term frequency
Term frequency is the frequency of the term in the document It is the result of a simple tabulation process of the document text:
tf(t,d)=ft,d=(dTtT
where is the number of occurrences of in while is the total number of terms in the document. One problem with term frequency regards long documents. Longer texts have a high probability that some words will be repeated, thereby leading us to conclude that the term frequency of these words is higher than what we would expect in shorter documents. To mitigate this effect, we can use a normalized term frequency that includes the use of a smoothing parameter based on a combination of a weighting parameter and a damping function: where is the maximum term frequency of all the terms in the document and is the smoothing parameter that can assume values between 0 and 1 (typically around 0.4–0.5).
2.4.2. Document frequency
Document frequency indicates the inverse document frequency of the term t in the collection of documents. It is equal to the log of the ratio between the number of documents in the collection, and the number of documents in which the term t appears:
{idf}(t,N) = \log\left( \frac{N}{N_{t}} \right) \tag{2.4}
This quantity describes how many rare terms there are in the corpus. Thus, in the presence of a rare term, equation (2.4) assumes a high value; otherwise, when many documents share the word, equation (2.4) takes on a small value.
2.4.3. Term frequency–inverse document frequency
Ultimately, we can compute the tf-idf statistic for each document by simply multiplying the term frequency and inverse document frequency as follows:
tf - idf(t, N) = tf (t, d) \times idf (t, N) \tag{2.5}
tf-idf assumes a high value in the case of a high term frequency and a low frequency in the collection. To better explain how the tf-idf works, we use the following five documents:
-
“Autonomous car insurance. Look, no claims!”
-
“Self-driving cars are set to change motor insurance radically.”
-
“Insurers agree that, reputationally, their brand image is often made or broken during the claims process.”
-
“Industry executives broadly agree that advanced analytics can be used to drive value in insurance.”
-
“Progress has been slower in other lines of business, such as general liability, most specialty lines, and other elements of life insurance.”
We proceed by building a term-document matrix using the tf-idf statistic. Table 3 shows how common stems such as insur, claim, and agre have low tf-idf values because of their presence in multiple documents. The statistic enables us to describe documents by considering peculiar terms and avoiding a representation based on common terminology. In fact, the stem insur has value 0—despite its high frequency, the highest among all the stems—meaning that it will not affect the representation of the corpus at all. Words that appear only once in a document will have a high tf-idf value and influence the position of the document in the multidimensional space.[4]
2.5. Placing documents in a multidimensional space
Having represented the documents in a space, it is also interesting to compare pairs of documents to understand document similarities.
When using vector space models, the closer the document vectors are, the more similar the documents are (see, for example, Pennington, Socher, and Manning 2014). To evaluate the position of the documents, we use a measure called cosine similarity, a statistic that also implies a length normalization process. Given only two documents, let and be the two column vectors containing the tf-idf values for the terms in the collection. The cosine similarity is defined as
\cos(\theta)\mathbf{=}\frac{\mathbf{V}_{1}\mathbf{\cdot}\mathbf{V}_{2}}{\left\| \mathbf{V}_{1} \right\|\left\| \mathbf{V}_{2} \right\|}
We report below the matrix computed by using the corpus of the five documents described above. Values show that this collection includes very dissimilar documents. The small size of the collection and the limited number of stems justify the results. In this case, the use of tf-idf has overweighted the search for rare terms with high discrimination abilities.
\left\lbrack \begin{matrix} 1.000 \\ \ 0.086 \\ \ \ 0.071 \\ \ \ 0.000 \\ \ \ 0.000 \\ \end{matrix}\begin{matrix} \ \ 0.086 \\ \ \ 1.000 \\ \ \ 0.000 \\ \ \ 0.000 \\ \ 0.000 \\ \end{matrix}\begin{matrix} \ \ 0.071 \\ \ \ 0.000 \\ \ 1.000 \\ \ \ 0.038 \\ \ \ 0.000 \\ \end{matrix}\begin{matrix} \ \ 0.000 \\ \ \ 0.000 \\ \ \ 0.038 \\ \ 1.000 \\ \ \ 0.000 \\ \end{matrix}\begin{matrix} \ \ 0.000 \\ \ \ 0.000 \\ \ \ 0.000 \\ \ \ 0.000 \\ \ \ 1.000 \\ \end{matrix} \right\rbrack
3. Natural language processing
After the very demanding process of document normalization, we are ready to find statistical methods that can “naturally” process language to extract information. We are looking for efficient statistical methods that “simulate” the process of our brain when we are reading or listening to people speaking.
The n-gram approach may fail in this task. It does not take into account the overall context of a phrase unless the size of the n-gram windows is very wide; however, when the size of the n-gram increases, the accuracy of estimated word probabilities decreases. Supervised machine learning methods are not able to deal with this issue without a time-consuming and sometimes painful calibration of the training phase.
NLP uses a mix of artificial intelligence, computer science, and computational linguistics to extract meaning from documents; recognize text; and, ultimately, model and shape text in order to compose original content (Bowman et al. 2015).
In insurance, NLP may be useful in making inferences about fraud (Kolyshkina and van Rooyen 2006; Stout 1998) or customer sentiment (Liu 2015; Ceron, Curini, and Iacus 2016), or (see our case study) in extracting latent information that cannot be measured by standard methodologies.
A revolutionary method to process language is the so-called word2vec. Word2vec is not just an algorithm but a class of algorithms introduced by Mikolov et al. (2013a, 2013b) that contains two different models: continuous bag of words (CBOW) and skip-gram. These algorithms are an example of deep learning (Wiley 2016). Deep learning is a branch of machine learning based on multilayered neural networks that involve both linear and nonlinear transformations. The algorithms in Mikolov, Chen, Corrado, et al. can be defined as two instances of a shallow neural network (with only one hidden layer). The importance of word2vec methods does not lie only in their predictive abilities. We show that these methods also enable us to provide a meaningful representation of words. Instead of trying to represent words in relation to their use in a document, the representation of words obtained with word2vec models concentrates on the meanings of the words themselves. For example, using the concept of a “window” in the n-gram models, we define the context as the words that surround the central word window itself. For example, in the string “deep learning methods,” the words deep and methods compose the context of the central word learning.
3.1. Continuous bag of words
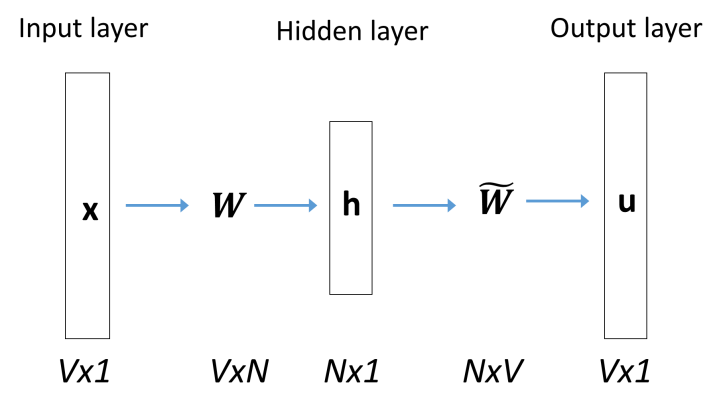
The continuous bag of words (CBOW) model was introduced by Mikolov et al. in 2013. We start by describing the simplest version based on a one-word context. In this version, the model predicts one word, given only one context word, to form a bigram. For example, given the word insurance, the model will try to predict the immediately following word.
To achieve this aim, we train the neural network based on the structure reported in Figure 1 (see also Rong 2014).

For each word we are interested in, we use a vocabulary of size from the corpus of documents we are analyzing. Each word will be represented by one-hot vector of dimension Next, we shrink the dimensions into a smaller space of size (hidden layer). The transition is made by using the weight matrix. Each node of the neural network is defined by the simple linear activation transformation The transition from the hidden layer to the output layer is performed by using the matrix
These matrices provide the score computed for every word in the vocabulary.
Let be the input vector (for instance, the word insurance), and suppose we want to maximize the probability where is the word we expect to find next to (say, policy). Once we have computed an initial score by using the stochastic gradient descent (Guelman 2012), it is possible to update the weights of and until convergence. The scores reveal what words within V are closer to
One of the advantages of the word2vec algorithms is that is also used to obtain a denser and more meaningful representation of the words included in the input layer. From a practical point of view, the dimensions of represent the word similarity, i.e., the words that are most likely to be close to the words used in the training phase. Using the notion of cosine similarities described in Section 2.5, we can compute the similarities between words and obtain additional information about terms and their semantics.
Another property of word2vec models regards “clustering themes,” or the ability of these models not only to find similar words but also to discover a class of items relating to similar topics. These models do not typically perform topic modeling, but practical evidence shows that a topic can be assigned to similar word vectors. Therefore, terms that appear in the same context can be interpreted as observations of a latent topic distribution over words.
Hence, word2vec models can be useful in discovering semantic relationships between words. This is one of the most important features of this class of algorithms, allowing us to overcome the simple similarity between words. Similarities between groups of words, known as linguistic regularities (Mikolov et al. 2013b), can indeed be detected.
4. Insurance case study
We analyzed 6,949 police reports (written by National Motor Vehicle Crash Causation Survey researchers sent to crash scenes) on accidents in the United States between 2005 and 2007. The researchers listened to police scanners; interviewed everyone on the scene; and collected structured data such as the date and time of the accident, weather and road conditions, driver use of medications, driver use of a cell phone, and so on. Then the researchers wrote a brief report, describing the accident in a maximum of 1,200 words.
In the literature, an example of applying text mining to this database was proposed by Borba (2013, 2015), who extracted dichotomous variables (called flags) from documents to study the impact on accidents of weather conditions, the status of the cars, the use of mobile phones while driving, the dynamics and the locations of accidents, and the driver’s condition (presence of driver fatigue, use of a cell phone, medications, drugs, alcohol, prescriptions).
Our purpose is to classify documents not only according to “accident-specific” keywords. In particular, we look for information that can uncover new risk covariates that might be used to fine-tune policy pricing or to improve customer risk profiles. To achieve this aim, a straightforward application of n-grams may be misleading. For example, a key issue is the profiling of drivers on the basis of the substances reported in the police reports, if available. The difficulty here is that, on the one hand, the words medication, drug, prescriptions, and alcohol are not always explicit in police reports, and on the other hand, some substances could belong to more than one category. In addition, some verbal expressions such as “he was not taking medication” or “the driver was aggressive but the BAC results were negative” could easily lead to the wrong classification. Therefore, without a supervised check by an expert, the n-gram approach could fail. To avoid these pitfalls, we have improved the analysis of documents by training an NLP system, based on a word2vec algorithm, to “automatically” classify the substances. In what follows we will focus mainly on this case, but the same procedure can be applied to other contexts, such as driver-related factors (distracted, using a cell phone, etc.).
The procedure we used to analyze the data set is based on the following seven steps:
-
Obtain the data set
-
Apply a text normalization procedure
-
Select substances (word2vec)
-
Tag parts of speech
-
Filter off-topic cases
-
Create the n-gram structure and flags
-
Apply the prediction model
4.1. Obtaining the data set
Unfortunately, at least at the time of the present paper’s submission, the data set containing the accident narratives cannot be directly downloaded in a user-friendly format. The data set is published online, where it can be queried using the search form created by the NHTSA. Each case is stored in an XML file that can be downloaded. The peculiar trait of XML is that it can encode any piece of a document. Indeed, as it is a markup language, it allows tags to be created to host new and different types of information. An example is provided in Figure 2, which shows how information regarding driver fatigue during an accident can be encoded.

Given the structure of XML, each case is stored differently. The quality of the information collected depends on how detailed the report is. Each request made from the interface is passed to the server containing the database using the HTTP GET method. The result of the GET request is a webpage that reads the underlying XML code of the selected case and displays it clearly.
Once we have downloaded the XML file of all the cases, we need to parse them to understand the information encoded in the XML language. The objective of the procedure is to extract the information encoded in sections or tags and store it in a structured form. Figure 3 is an example of an accident narrative we have extracted.

4.2. Performing text normalization
To simplify the text mining approach, we divided each document into phrases, using the dot as a string separator. The corpus size increases from the initial 6,949 document cases to 198,480 phrases. The next step in the normalization process consists of polishing up the phrases by removing punctuation signs, symbols, and numbers. We also removed the stop words during the normalization process.
For example, the next-to-last phrase (in bold in Figure 3) will be changed to “driver was crash three weeks prior crash was taking medications ibuprofen vicodin ultram.”
4.3. Selecting substances
Once we have normalized the text, we focus on the identification of substances (over-the-counter and prescription medications, narcotics, and alcohol) that will be used to filter the on-topic cases that will be analyzed later. Instead of creating a list of possible substances, we opted to use word2vec methods. We were indeed able to train a neural network to predict the context words given a central word as input. This representation allows us to grasp word similarities and to uncover thematic clusters in the text.
In our particular application, we started by finding the terms that had greater cosine similarity to common illegal substances (cocaine, heroin, and so on). We filtered out the corresponding names and collected them in a list. This list was used to calibrate the classification of other drugs, illegal and not. We proceeded to refine the list by searching for the term closer to the term medication or narcotic to identify substances recorded during the accident investigations. In this way, 290 (legal and illegal) substances were “automatically” detected.
For instance, in Figure 4 we provide a visual representation of the results obtained using the similarity scores between medication and narcotic. Given a word in the list, the higher of the two scores allows us to define the classification as belonging to either the “narcotics” or “medications” group. We can see how the substances are correctly separated based on their similarity scores. For example, the word medication has a medication score of 1, since the two words are equal. The same word has a 0.6 narcotics score; this means that, within the corpora of police reports, there are instances in which the word narcotic is located near the word medication, contributing to the high narcotic score for the word medication. In general, the illegal drug names are found closer (but not exclusively) to the word narcotics, while prescription substances are more likely (but not exclusively) closer to the word prescription.
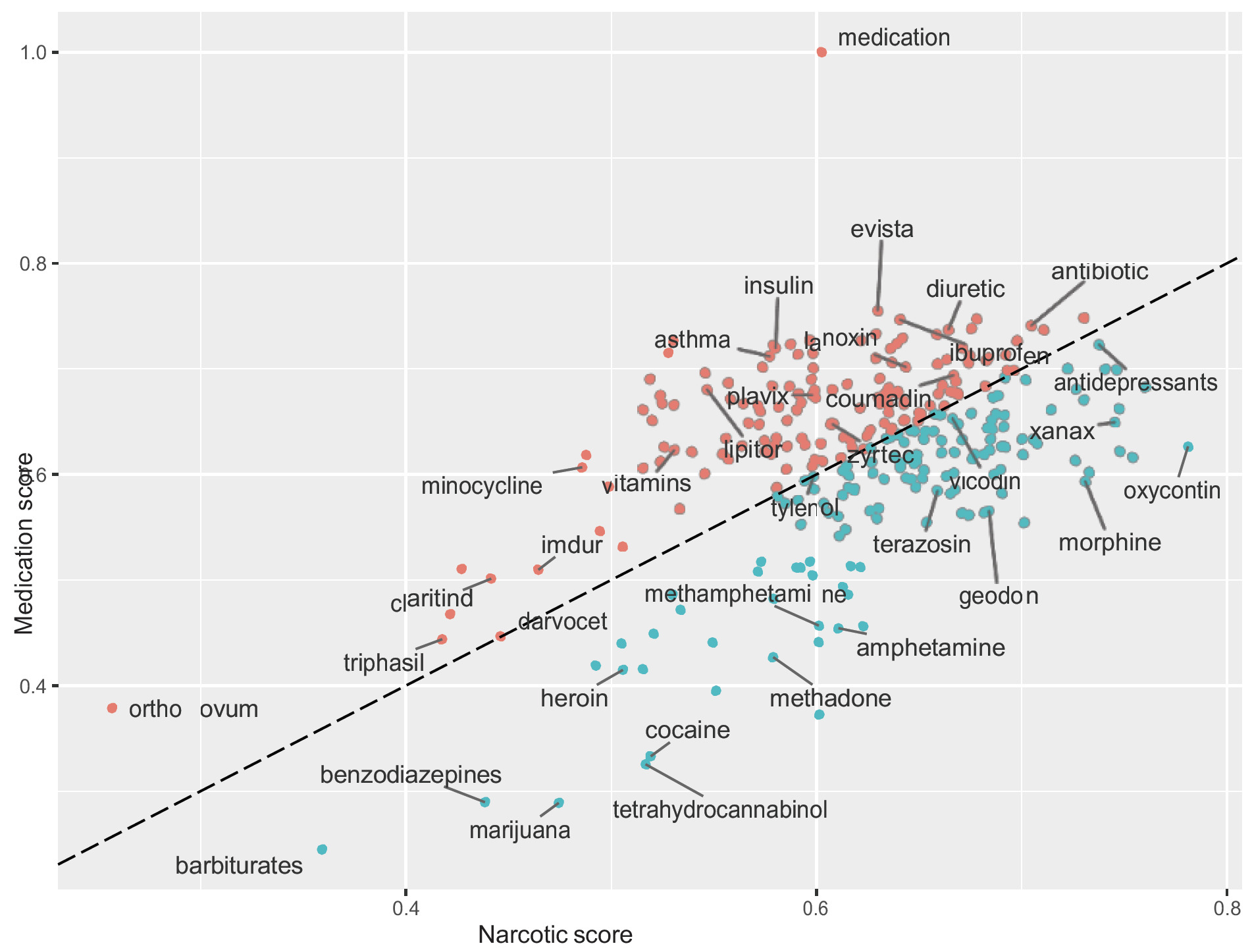
Based on the texts used for the training, if a word is placed above/below the diagonal it means that it is more similar to the word placed on the y/x axis.
It is worth mentioning that the scores computed by the word2vec model are not representative of the real similarities between any kinds of drugs. Thus, we should not interpret the scores as a direct representation of the real classification of each substance. Instead, word2vec creates a word embedding for each term of the specific corpus. The word embedding depends on the documents used in the training process, and thus substance discrimination reliability requires accurate and precise documents.
The previous result can be used in the reverse order: in general, even if a word is not mentioned in a document but it occurs often in other documents when other medications/substances/narcotics are mentioned, then it inherits some degree of similarity to the reference group in question. For example, the word xanax never appears closer to the term narcotics, but it occurs frequently in phrases containing the term heroin. Therefore, based on the transitive property, the term xanax will be considered more likely to belong to narcotics than to the medications group. The extreme case is when no substance is reported: by using word similarity we can classify a document into one of the categories we have chosen.
The bottom line for using the word2vec model is that we have created an efficient method to discriminate between illegal and legal substances with little to no effort. In fact, the ideal word2vec model is one that uses millions or billions of documents (for example, the entire Wikipedia library) to understand word similarities or thematic clustering. However, we are pleased to see how, with just under 7,000 documents, we were still able to reach our goals.
4.4. Tagging parts of speech
One of the advantages of analyzing text is that we have the possibility to use verbs to detect actions that we are interested in. In order to detect verbs, we use a part-of-speech tagger, a function that assigns a grammar role to each word in a phrase. Since the process used to assign the tag is based on a set of heuristic rules, the procedure can be faulty, especially when new words are presented in input (this happens often with the names of certain drugs). However, for known and common words we were able to extract what we were looking for: the gerund of verbs to understand if an action was in progress or not (“the driver was calling” versus “the driver called”).
4.5. Filtering off-topic cases
To identify topics, we compute n-grams. Building a database containing all the n-gram information is very expensive from a computational point of view. We estimated that, in our case, this would have led to a structure containing more than 10 million unique expressions. To reduce this number, we needed to find a way to filter some of the phrases created by the normalization procedure. One way to accomplish this task was to search phrases that contain words that are crucial to our application. Using the list of substances created with the word2vec model, we were able to filter the phrases, thereby reducing the database to a more manageable size. The filtering process is quite computationally intensive. However, 97.6% of phrases are labeled as off-topic (see Table 4).
Table 4 shows that 4,270 accident narratives can be labeled as off-topic since none of their phrases mentioned the presence of drugs or alcoholic beverages. Drugs or drinks are mentioned in 38.5% of the total narratives. We still cannot say if those factors are really present (or not present) because we could have stumbled upon a false positive—for example, cases that mentioned drugs or drinks only to state that they were not present. To overcome this pitfall, we implemented an n-gram strategy to understand the text. Until now, we have focused on a unigram model that considers only whether specific terms are mentioned in the text.
4.6. Creating the n-gram structure and flags
Building the n-gram structure is only the first step toward extracting information from the accident narratives. To be able to understand the expressions written in the documents, we created a series of flags that exploit the structure we have created. These flags were then used to indicate the presence of drugs, illegal narcotics, and alcohol in the accident narratives. Four different n-grams were investigated.
4.6.1. Unigram
We created four different flags:
-
Flag 1 indicates a reference to medications in the text.
-
Flag 2 indicates a reference to prescriptions in the text.
-
Flag 3 indicates a reference to narcotics in the text.
-
Flag 4 indicates a reference to alcohol in the text.
As described above, focusing only on single words does not allow us to obtain the full context. We are not able to capture negations and other more complex text expressions.
4.6.2. Bigram
Hence, we expanded our focus to pairs of words. Exploiting a bigram, we tried to detect two particular patterns:
-
Negations: A flag is created to indicate the presence of a negation (no, non, not, none) followed by the name of a drug or an alcoholic beverage.
-
Actions: A flag is created to indicate the presence of an action (verb with -ing) followed by the name of a drug or an alcoholic beverage. We are interested in the gerunds because they are commonly used to express real, fixed, or completed actions.
Transitioning from words to pairs of words has many implications. On the one hand, we could refine our search for substances by accounting for particular combinations of terms. On the other hand, we needed to deal with the ceiling represented by the complexity of the analysis. In the previous step, we had to analyze only 3,261 unigrams, while 16,692 bigrams were generated.
To take an example, using the phrase of the accident narrative highlighted in bold in Figure 3 produces the following bigrams:
1. “driver was”; 2. “was crash”; 3. “crash three”; 4. “three weeks”; 5. “weeks prior”; 6. “prior crash”; 7. “crash was”; 8. “was taking”; 9. “taking medications”; 10. “medications ibuprofen”; 11. “ibuprofen Vicodin”; 12. “vicodin ultram”
Only a fraction of these bigrams are effectively used in the analysis.
4.6.3. Trigram
Regarding trigrams, there are 24,900 combinations of word triplets—49% more items than are produced with the bigram structure and almost 7 times more than with the unigram structure.
Considering triplets instead of pairs of words further increases the complexity of the analysis, since numerous expressions can be encoded in a larger window. Aside from the classical controls already implemented, we further refined our searching algorithm by taking into account the following:
-
Past continuous tense: We now track every triplet that contains a reference to this verbal form. Typically, the past continuous is used to express past events that were prolonged in time, or that continued before and after other actions. A classic example is the triplet “was doing drugs.” Notice that in this specific triplet a flag indicating the presence of an action was already implemented in the unigram phase. However, the bigram “doing drugs” does not allow us to exclude the fact there was a negation before the verb was. Therefore, to refine the search for enduring past actions we implemented this check, which also has the benefit of removing any doubts regarding negations or other contradictory expressions.
-
Past tense: We enhanced the check regarding past tenses by identifying triplets that contained the past declination of the auxiliary verbs to be and to have. This phase allowed us to consider expressions such as “was on medication,” “had taken Percocet,” etc.
-
Negative and positive tests: We can track the presence of toxicology or blood alcohol content (BAC) tests in the narrative descriptions of the accidents. We are dealing only with phrases that contain at least one occurrence of a substance, so it is fair to assume that any mention of the terms positive and negative is related to some sort of intoxication test. Exploiting this assumption, we proceed to detect triplets such as “cocaine negative results,” “negative results drug,” “alcohol tested positive,” and “positive opiates cocaine.”
It is clear that triplets offer a broader view on the context of phrases. Just like a child learns to read, the algorithm takes baby steps toward a good comprehension of the meaning of documents.
As emphasized above, we are not declaring a comprehensive list of all the possible expressions that can point toward the correct identification of substances during accidents, which would take too much time. We are only trying to characterize a small set of rules that are at least able to understand the general context in which the crashes happened.
4.6.4. Fourgram
The design of the last batch of checks implemented is based on fourgrams and will be used to detect particular samples of false-positive patterns. The degree of complexity increases again, from the previous 24,900 instances with the trigram to 27,642 with the fourgram. We use this structure to detect the following patterns:
-
Prescription medication: In the accident narratives, it is common to come across this pattern. Reading the narrative, we know that it refers to a prescription; however, in the previous steps of the analysis we may have assigned contradictory flags to it. Because of the presence of the word medication, the algorithm may be deceptive and falsely attribute this pattern to the wrong class. By searching for the terms prescription and medication in a broad context, we were able to contextualize the terms and correctly classify them in the “prescription” category.
-
Prescription sunglasses: This is another pattern (like the previous one) that can be difficult to deal with. Identifying the presence or absence of prescription sunglasses (lenses or other eyewear items) is not one of our goals; therefore, we need to find a way to eliminate these mentions from the analysis. In order to exclude these patterns, we can build a flag that marks them as “off-topic,” so that they will have little importance in the overall picture.
Realistically, many patterns may escape our rule-based algorithms, but we are counting on the fact that the flags created in the unigram structure act as a safety net. This concept has its foundation in the filter phase executed upstream. Having retained all the phrases that include at least one occurrence of the presence of the substance, we are 100% sure that in the relative cases there is at least one substance involved. By trying to exclude from the picture all the possible negative expressions, we are only exposing ourselves to the possibility that some patterns for positive detection may be ignored. Nevertheless, by having structured flags that act only on the mere presence of substance names, we are hedging our exposure with regard to missed opportunities.
Finally, we have obtained a list of 24 text-related flags (e.g., “she/he was/was not taking medications/prescriptions/drugs,” “she/he was positive/negative to alcohol test,” “she/he was/was not wearing sunglasses,” “she/he was/was not calling someone,” etc.), where each flag is used to detect a particular pattern in the n-gram structure. Therefore, a flag (0/1 for the absence/presence of a particular pattern) will be associated with every phrase.
4.7. Applying the prediction model
The flags can be used to investigate the effect of a pattern on accidents. For example, the evidence of substances (legal and illegal) and their impact on motor vehicle crashes can be analyzed by studying the percentage of injuries (both minor and more serious, deaths included); we expect the percentage to be higher in accidents where these factors were present than in accidents where they were not present.
By using a logistic regression with an elastic net regularization (Friedman, Hastie, and Tibshirani 2010; Zou and Hastie 2005) to perform regression and variable selection by linearly combining both L1 and L2 penalties, we have estimated the probability of injury in accidents in which at least one substance was present. A justification of the need for this methodology is that text mining problems can be treated as problems, where p represents the number of the predictors and n represents the number of the records. Moreover, some variables may be highly correlated, and methods such as lasso regression will tend to pick only one of them and ignore the others, without preference as to which one has been selected. This is a limit that we do not find in ridge regressions. If the variables are highly correlated when the task at hand is described by an situation, it has been shown that the ridge regression always outperforms the lasso, but it does not allow unnecessary predictors to be filtered. The limits of the previous models do not apply to the elastic net algorithm, a regression analysis method that combines both the lasso and the ridge regressions, overcoming their shortcomings. In our case, briefly consider the logistic model
\ln\frac{\Pr\left( {Injury} \middle| \mathbf{x} \right)}{1 - \Pr\left( {Injury} \middle| \mathbf{x} \right)} = \beta_{0} + \mathbf{x}^{\mathbf{T}}\mathbf{\beta}
Let if the i-th report returns at least one injury or in the contrary case. Let Then the aim is to maximize the penalized log likelihood
\max_{\beta_{0},\mathbf{\beta}}\left\lbrack \frac{1}{n}\sum_{i}^{\mathstrut}{(y_{i}\ln{p\left( \mathbf{x}_{\mathbf{i}} \right)} + \left( 1 - y_{i} \right)\ln\left( 1 - p\left( \mathbf{x}_{\mathbf{i}} \right) \right) - \lambda P_{\alpha}\left( \mathbf{\beta} \right)} \right\rbrack
where and
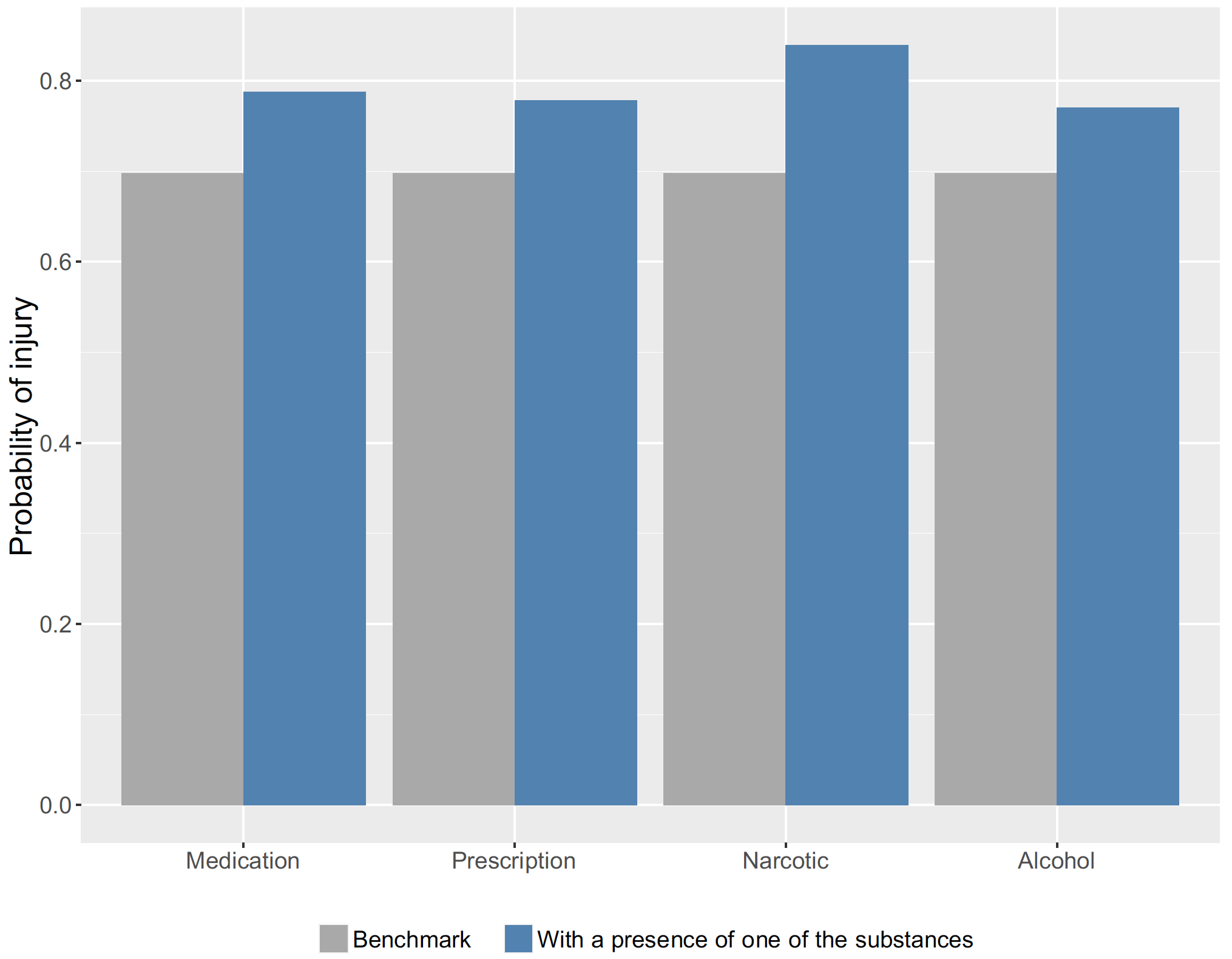
Figure 5 shows the probability of injury for all the factors (flags) we considered, ranging from 77% for alcohol to 83.4% for illegal narcotics; the probability is always greater than the benchmark computed using only the off-topic cases[5] (see also Borba 2013 for similar results obtained using logistic regression).

All factors present results that comply with our initial prediction. It is more likely that injuries will occur in crashes where at least one of the drivers had taken drugs or was under the effect of narcotics or alcohol. It is interesting to note that the probability of injury is higher in the presence of medications (78.78%) than in the cases in which prescription medicines are involved (77.7%). It is difficult to say whether the two percentages are statistically significantly different. Medications are available over the counter, so they are easier to access and should not affect common activities such as driving. However, it is possible that abuse is higher because of how easily they can be purchased. In addition, medications include antibiotic and other common drugs that are used to treat seasonal illnesses. Therefore, it is possible that in particular seasons more people are effected by allergies, or simply colds, and in order to treat them they use medications. This increases the number of individuals driving under the effect of medications, thus increasing the probability of injury, therefore biasing its real value. In general, this effect is difficult to assess because it is not available in the reports and it cannot be easily measured.
The results regarding alcoholic beverages and illegal narcotics are in line with expectations: it is well known that drug-impaired driving is a crime and can have some serious consequences. The same holds for alcohol-impaired driving, but we need to make a distinction. In the case of illegal narcotics, it may not be easy to detect DWI (driving while intoxicated) cases immediately after a crash. Tests for narcotics are lab tests that may take time. What can be recorded is the possession or possible use of narcotics. We need a list of substances and a series of flags that test their absence/presence at the time of the crash. For alcoholic beverages it gets trickier. Determining DUI (driving under the influence) might be difficult because of the different laws on the matter (in the United States, it is possible to drive with a BAC of 0.08%, while for drivers under 21 the zero-tolerance law imposes stricter limits, between 0.01% and 0.05%) and because sometimes the description includes the generic statement that alcoholic beverages have been found in the car. Thus, even if a document mentions that a driver had been drinking, this does not mean that he or she was driving under the influence of alcohol. We do not aim to determine the impact of alcohol infractions (DUI cases) but rather the general influence this factor can have on the way we drive. The results speak clearly: the mere mention of alcoholic beverages in an accident description is sufficient to detect crashes in which the probability of injury was higher than the benchmark.
4.8. Final step
Insurers may consider this data useful in the process of claim evaluations for the following reasons:
-
Detecting the presence of substances has implications on multiple levels: claim triage, subrogation opportunities, and decisions on whether to renew contracts.
-
Claims adjusters can exploit this information to investigate the circumstances in which crashes occurred, thereby obtaining a more reliable basis on which to begin settlement negotiations.
-
Actuaries can use this information to refine their pricing procedures.
Typically, actuaries base their policy premium calculations on a so-called Company DB, a data set containing details about their customers. Intuitively, a company cannot ignore what is taking place outside its pool of clients, and to correctly price new and existing products it needs to consider phenomena that affect the entire population of noncustomers and customers.
By using both structured and unstructured data extracted from the accident narratives, we can build a so-called Cloud DB. This data source should have some classes in common with the Company DB: age, gender, ethnicity, license state, etc. We can interpret these variables as identifying a risk profile that is common to the sources of information. This allows actuaries to use this text-related information in the definition of premiums, opening the door for more extensive exploration and use of documents in order to discover new risk covariates. When writing a policy, we do not aim to detect which individuals are taking narcotics but to explain how this information can be potentially used in order to modify the premium ratings of policyholders.
The rationale for this process is not new in ratemaking. First, we compare the risk of those who have been involved in accidents with those who have not been involved, given a set of covariates. Then we extend this risk to all the customers, mitigating the effect for those who were safe drivers but not reducing their risk to zero. The result is an integration into the premium model algorithm of a latent variable that represents the potential risk of driving under the influence of drugs.
On a more detailed level, our application could analyze the characteristics of every driver involved in the accidents. Using the fields derived from the XML cases, we were able to build a database including information such as the following for 12,300 drivers:
-
License origin, status, endorsements, and restrictions
-
Age, gender (see Figure 6), height, weight, and illness
-
External factors: emotions and stress
-
External factors: in a hurry, fast following, and traffic
-
External factors: distractions and conversation
-
Season, day of the week, and time of the accident
-
Year of production and make of the vehicle
-
Emergency transport in ambulance
-
Severity of the accident

We can match these profiles from the police reports with the profiles of the company’s own database to add new risk covariates (e.g., probability of using substances or, for some categories, of being under the influence of external factors). To sum up these factors, in practice we built a model that classifies the accident outcome of each driver to predict whether drivers were injured or not during motor vehicle accidents. The variables we used as predictors were those extracted from the XML cases in a structured form, including the four text-related flags referring to medications, prescriptions, illegal narcotics, and alcohol. To test the classification accuracy for each driver, we used an elastic net regularized regression.
Figure 7 reports the receiver operating characteristic (ROC) of our classification procedure, which can be interpreted as the ability of the method to correctly identify the classification categories. In our case, we obtained an area under the ROC of 72.25%, a good measure for a classifier that needs to take into account multiple variables and that uses predictors obtained directly from the text.

5. Conclusions
We provided a case study that shows how valuable text mining can be for actuarial procedures in pricing models. However, the analysis barely scratched the surface of the possible applications for artificial intelligence methods in actuarial and insurance contexts in the near future. The aim was to create text-related risk covariates that may affect ratemaking.
The same process can be reproduced using different contexts. New applications are emerging in terms of analyzing the GPS coordinates of social media posts to obtain proxy measures for the exposure to accidents. Researchers have found a way to use Twitter posts to estimate drinking-while-tweeting patterns to detect particular string patterns (features). This is another example of how it is possible to create new risk covariates linked to data mining of unstructured text documents.
The steps of the algorithm we propose are based on a data-driven process. In each step, the algorithm becomes “more conscious” of the context in which it is operating. It first detects the substances that are present in the documents and then proceeds to learn about the expressions that are present in the text. Each step allows us to create specific flags that increase the understanding of the text. The algorithm exploits concepts derived from different areas, with the specific aim to maximize interpretability thereby avoiding the use of black boxes.
Future challenges involve the application of these methods to business activities using topic modeling. The insurance industry is well suited to the implementation of these advanced models because of the large quantity of data available to carriers. Text mining represents one example of unconventional methods that could be used to refine insurers’ traditional approach to measuring the risk profiles of their policyholders, thus opening the way for a wave of innovation. Appropriate application of these methods could provide the foundation for extending a data mining approach to big data projects.
Acknowledgments
This work was sponsored by the Casualty Actuarial Society (CAS). The authors wish to thank the editor and two anonymous referees for their careful reading and the suggestions that helped to improve the quality of the paper. The authors wish to give special thanks to David Core, director of professional education and research at CAS, and Jody Allen, professional education and research coordinator, for their support.
Finally, the opinions expressed in this paper are solely those of the authors. Their employers do not guarantee the accuracy or reliability of the contents provided herein nor do they take a position on them.
At the time of this paper submission, the NHTSA database was available at https://crashviewer.nhtsa.dot.gov/LegacyNMVCCS/Search. It is beyond the scope of this paper to give details about it. We simply highlight some relevant goals of the NHTSA research: understanding the pre-crash environment; investigating the causes of the rollover problem; and describing the traffic environment in which the crash occurred, the behavior of the individuals and vehicle involved, the specific outcomes, any drug impairment, etc.
To further compress the table, for each document we may compute the average tf-idf statistic associated with every stem. A document with a high value means there are words in it that are on average more peculiar compared to others.
Recall that off-topic cases are those reports in which medications, prescriptions, and alcohol were not mentioned (4,270 cases).