


1. Introduction and motivation
For many apparent reasons including ease of implementation, there has been an increase in popularity even among practitioners of the use of generalized linear models (GLMs) for insurance ratemaking, risk classification, and many other actuarial applications. See, for example, Antonio and Valdez (2011); Frees, Derrig, and Meyers (2014); and Frees, Derrig, and Meyers (2016). Originally synthesized by Nelder and Wedderburn (1972), GLMs extend the ordinary regression models to accommodate response variables that are not normally distributed and are rather members of the exponential family of distributions. As pointed out in Chapter 5 of Frees, Derrig, and Meyers (2014), the primary features of GLMs include a function that links the response variable to a set of predictor variables and a variance structure that is not necessarily constant across independent observations. GLM comprises a wide variety of models including the normal regression, Poisson regression, logistic regression, and probit regression, to name a few. More important, it has been used by Garrido, Genest, and Schulz (2016) to model the dependence between loss frequency and loss severity.
Following the formulation in Garrido, Genest, and Schulz (2016), consider an insurer’s portfolio with a class of policyholders where for a fixed time period, the number of claims incurred is N and the corresponding individual amounts of claims are denoted by C1, C2, …, CN. The total loss incurred can be written as the sum
S=C1+C2+…+CN,
with the convention that when the total loss is also 0. In the case where N > 0, we define the average claim severity by so that the aggregate loss can be expressed as Let be a set of p covariates within the class of policyholders. These p covariates may affect the means for loss frequency and loss severity differently. However, dependence is introduced in the model with the addition of as a covariate affecting the mean for loss severity.
Both frequency and average severity are modeled as a GLM that incorporates the effect of the various covariates. However, individual claims C1, C2, …, CN are assumed to be independent with each Ci to have a reproductive exponential dispersion family structure, that is, conditional on knowing N. This is necessary so that conditionally on the average severity is also a member of the exponential dispersion family, that is, With link functions and for frequency and severity, respectively, it follows that
ν=E[N|x]=g−1N(xα)andμθ=E[¯C|x,N]=g−1C(xβ+θN).
With this specification, testing for independence is equivalent to testing whether or not.
Using the tower property of expectation, the mean of aggregate loss can be expressed as
E[S|x]=E[NE[¯C|x,N]|x]≠E[N|x]E[C|x]
which clearly demonstrates the possibility of dependence. It has been shown in Garrido, Genest, and Schulz (2016) that the variance of aggregate loss can be expressed as
Var(S|x)=ϕθE[NVC(μeθN)|x]+μ2[14M′′N(2θ|x)−(M′N(θ|x))2].
In a simulation study in Garrido, Genest, and Schulz (2016), the presence of dependence can have serious biases on the value of the regression coefficients, their standard errors, and the mean and variance of the portfolio’s aggregate loss. Using a real data set, the authors’ work also found strong evidence of the presence of negative dependence between loss frequency and loss severity. This is an interesting result because it indicates that an increasing number of claims decreases their severity. An interesting observation in the paper is that “claim counts and amounts are often negatively associated in collision automobile insurance because drivers who file several claims per year are typically involved in minor accidents” (Garrido, Genest, and Schulz 2016, 205).
The dependent GLM in Garrido, Genest, and Schulz (2016) has a structure similar to that of the two-part frequency-severity model in Frees, Gao, and Rosenberg (2011) wherein the authors considered that the amount of healthcare expenditures is affected by the number of either inpatient stays or outpatient visits. According to their results, inpatient stays did not significantly affect the total annual healthcare expenditure, but outpatient visits had a significantly negative impact on the total annual healthcare expenditure.
In Lee, Park, and Ahn (2019), a similar dependent frequency-severity model was considered that compared the effect of constant and varying dispersion parameters. The frequency is a Poisson regression model, while the severity is a gamma regression model with a deterministic and assumed known function of frequency as an additional covariate. The model was calibrated using an auto insurance data set from Massachusetts in 2006. Interesting to note, the result indicated a positive effect of frequency on severity, that is, high frequency led to an increase in average severity.
Following an approach similar to that in Garrido, Genest, and Schulz (2016), Park, Kim, and Ahn (2018) calibrated the dependent two-part GLM with claims data from a Korean insurance company. Interesting to note, the authors used the level of bonus-malus as an explanatory variable for predicting average severity. Bonus-malus is a quite common practice in Korea and other countries for penalizing bad drivers while rewarding good drivers. Their estimation results showed that for claims related to collisions, the dependency tends to change from positive to negative as the level of bonus-malus of a policyholder increases. However, statistical evidence of dependency for liability claims was lacking.
Shi, Feng, and Ivantsova (2015) applied a conditional two-part model with zero-truncated negative binomial distribution for frequency and a generalized gamma distribution for the average severity. To incorporate the dependency between frequency and average severity, they proposed the use of copulas but compared the results to the dependent two-part GLM used in Garrido, Genest, and Schulz (2016). According to Shi, Feng, and Ivantsova’s study, in both the two-part model and the copula model, frequency had a positive correlation with average severity. Furthermore, they found using out-of-sample validation that the copula model outperforms the dependent two-part GLM.
The work of Shi, Feng, and Ivantsova (2015) proposed a model that can accommodate heavy tail distribution for claim severity as an extension of Czado et al. (2012) and Frees, Gao, and Rosenberg (2011). The model estimation yielded a positive dependence between frequency and average severity. According to Shi, Feng, and Ivantsova’s interpretation, this is because insureds with high frequency may have riskier driving habits, leading to more severe claims when accidents happen.
There are certainly varied results regarding the relationship between frequency and average severity, and this may be attributed to the differences in the type of model used and the characteristics inherent in the data set used to calibrate the corresponding model.
For a typical portfolio of insurance policies, it is not uncommon for observations of independent policyholders to be in a longitudinal format such as
(Nit,Citj,xit,eit)′,
for calendar year t, for t = 1, … , Ti, where and for policyholder i, for i = 1, … , M. There is a fixed number of calendar years T, and we allow for unbalanced data. xit refers to the vector of covariates describing policyholder characteristics, and eit refers to the length of exposure of the policyholder within calendar year t where The subscript j will become clear when we define our dependent compound risk model. Random effects models are typically used for such longitudinal observations, with generalized linear mixed models (GLMMs) as a special case. Molenberghs and Verbeke (2005) provide an overview of statistical models for analyzing longitudinal data from clinical studies emphasizing the importance of “model formulation and parameter estimation.”
In this paper, we extend the GLM framework with dependent frequency and severity model suggested by Garrido, Genest, and Schulz (2016) to the GLMM framework with dependent frequency and severity model. The primary contribution of our model is the addition of random, or subject-specific, effects in the linear predictor within a dependent frequency and severity model. Here our subject is the policyholder or the insured in a portfolio of insurance contracts. Including random effects in the linear predictor reflects the idea that there is a natural heterogeneity across subjects (policyholders) and that the observations on the same subject may share common characteristics.
Longitudinal data models including GLMMs are not new in the actuarial literature. Frees, Young, and Luo (1999) demonstrate the link between longitudinal data models and credibility models. Such a link allows for a more convenient statistical analysis of credibility models as part of a ratemaking process; see Frees, Young, and Luo (2001). On a similar note, Garrido and Zhou (2009) examine limited fluctuations credibility of GLMM estimators. Antonio and Beirlant (2007) provide motivations for using GLMMs for analyzing longitudinal data in actuarial science; in particular, claims data sets arising from a portfolio of workers’ compensation insurance were used to calibrate GLMMs. The authors not only provide the GLMM formulation but also discuss estimation, inference, and prediction useful for analyzing the data. In Antonio and Valdez (2011), GLMM is discussed as a modern technique for risk classification, the process of “grouping of risks into various classes that share a homogeneous set of characteristics allowing the actuary to reasonably price discriminate” (187). Finally, Boucher, Denuit, and Guillén (2008) suggest the use of a random effects model for claim counts with time dependence. Indeed, they compare such a model with other types of models such as time-independent marginal models, models based on conditional distributions with artificial marginals, integer-valued autoregressive models, common shock models, and copula models. Using an automobile insurance portfolio from a major company in Spain with data from 1991 to 1998, they conclude that the random effects model is the superior model for insurance claims data with time dependence.
Inspired by the work of Garrido, Genest, and Schulz (2016) and the growing interest in the use of GLMM in insurance ratemaking and risk classification, we examine the usefulness of GLMM for modeling dependent compound risk. This appears to be a natural extension, making insurance data typically take the form of equation (1.1). For example, auto insurance companies usually have data with policyholders observed for a period of consecutive years; such data provide a richer set of information for improved prediction, pricing, and reserving. Preserving the GLM dependent frequency-severity structure proposed in Garrido, Genest, and Schulz (2016), the extension is achieved with the addition of random effects to the linear predictor in a GLM framework. This addition of random effects allows us to capture the heterogeneity typically found when observations are not independent but may be repeated. As stated in Frees, Derrig, and Meyers (2014, Chapter 16, 400), this “enables cluster-specific prediction … and structure correlation within cluster.”
The remainder of this paper is organized as follows. In Section 2, we introduce GLMMs. The purpose of this is to make the paper self-contained and introduce the notations adopted throughout the paper. In Section 3, we describe the data used, some preliminary investigation of the data, and the specification of the GLMM used in model calibration. In Section 4, we give numerical results of our estimation. We also provide some methods we used in model validation. Finally, we conclude this paper with some remarks in Section 5. The appendices provide for details of the calculation of the likelihood equations and the derivation of the mean and variance of the aggregate loss.
2. GLMM and the dependent compound risk model
In this section, we introduce the concept of a GLMM by first briefly explaining GLM. This section also clarifies many of the notations adopted in this paper. Assume we have M independent observations with response variable yi and known covariates GLMs extend ordinary linear models with normally distributed responses to include members from the exponential family with a density expressed in canonical form as
f(yi|β,τ)=exp(yiγi−ψ(γi)τ+c(yi,τ)),for i=1,…,M.
Within this exponential family, the relations and hold for the mean and variance, respectively, where Here, is the variance function, while is called the link function that links the mean to the linear predictor. denotes a p × 1 fixed effects parameter vector in the linear predictor that is typically estimated from observed data.
Note that this model can be extended for longitudinal data by allowing for random, or subject-specific, effects in the linear predictor. Including random effects in the linear predictor reflects the idea that there is a natural heterogeneity across subjects (such as the insured) and that the observations on the same subject share common characteristics.
To further fix ideas, suppose we now have a data set consisting of M independent subjects with response variable yit and known covariates Here, i refers to the subject, for observed during calendar year for where and T is the overall total number of calendar years observed. Given the vector Ri describing the random effects for subject (or policyholder within the context of insurance applications) i, the response variable yit has a density from the exponential family of the form
f(yit|Ri,β,τ)=exp(yitγit−ψ(γit)τ+c(yit,τ)).
Within this framework, the following relations hold:
μit=E[yit|Ri]=ψ′(γit)andVar(yit|Ri)=τψ′′(γit)=τV(μit),
where is referred to as the variance function. Similar to the GLM construction, we model a transformation of the mean using the link function Clearly, the link function provides a link between the mean and the linear form of the predictors including the random effects. Furthermore, denotes a fixed effects parameter vector, and is a random effects vector. and describe each subject i’s covariate information for the fixed and random effects, respectively.
The specification of the GLMM is completed by assuming that the random effects, Ri, are mutually independent and identically distributed with density function where denotes the parameter vector in the density. For practical purposes, it is commonly assumed that the random effects follow a multivariate normal distribution with a 0 mean vector and covariance matrix described by This covariance structure allows us the flexibility to specify correlation within the subjects. It is clear, therefore, that within this framework, the dependence between observations on the same subject arises as a result of sharing the same random effects Ri.
Invoking the tower property of expectation, we find some general form of the unconditional mean
E[yit]=E[E[yit|Ri]]=E[g−1(x′itβ+zitRi)],
and based on the usual breakdown of the components of the variance, we also find some general form of the unconditional variance
Var[yit]=Var[E[yit|Ri]]+E[Var[yit|Ri]]=Var[μit]+E[τV(μit)]]=Var[g−1(x′itβ+z′itRi)]+E[τV(μit)].
To better understand the consequences of adding random effects, as a simple illustration, consider the log link function and It can easily be shown that the mean is
E[yit]=E[exp(x′itβ+Ri)]=exp(x′itβ)E[exp(Ri)]=exp(x′itβ)exp(σ2R/2),
while the variance is
Var(yit)=Var(ex′itβ+Ri)+τE[e(2x′itβ+2Ri)]=e2x′itβ+σ2R[eσ2R(1+τ)−1].
See Chapter 8 of McCulloch and Searle (2001).
For estimation purposes, the likelihood function for the unknown parameters and can be expressed as an integral as follows:
L(β,σ,τ;y)=M∏i=1∫Ti∏t=1f(yit|σ,β,τ)f(Ri|σ)dRi,
where and the integration is done with respect to the q-dimensional vector Ri. This integration presents some computational challenges for maximum likelihood estimation. To have results that can give some kind of explicit expressions, we need to specify what are ostensibly referred to as conjugate distributions. For instance, when both the data and the random effects are normally distributed, the integral can be worked out analytically, and explicit expressions easily can be derived. For more complex distributional assumptions, some approximations have been proposed in the literature. See McCulloch and Searle (2001). This is beyond the purpose of this paper. We will stick to the usual normal assumptions typically specified for the random effects.
2.1. The dependent compound risk GLMM
As briefly stated in the Introduction, a typical portfolio of insurance policies would contain observations of independent policyholders in a longitudinal format for calendar year t, for t = 1, … , Ti, where and for policyholder i, for i = 1, … , M. There is a fixed number of calendar years T, and we allow for unbalanced data. xit refers to the vector of covariates describing policyholder characteristics, and eit refers to the length of exposure of the policyholder within calendar year t where
For our purposes, Nit denotes the number of claims, and Citj denotes the claim size observed, where j is an additional subscript needed to distinguish the many possible claims that may be incurred for each calendar year; hence, j = 1, … , Nit. For each calendar year, we specify the distribution of claim severity applicable for the average claim in each calendar year where we define
¯Cit=1NitNit∑j=1Citj.
The joint distribution for our dependent compound risk model therefore can be written as
f(n,¯c|α,β,b,u)=fN(n|α,b)×f¯C|N(¯c|β,u,n),
where the subscripts it have been suppressed for convenience and N > 0. The subscripts N and are used to distinguish the density functions for frequency and severity, respectively. b is the random effects vector for the frequency, while u is the random effects for the average severity. The construction in equation (2.6) is typically similar in structure to the two-part model of frequency and severity, with the exception of the addition of random effects and the addition of possible dependence between frequency and severity.
It is understood that when N = 0, the joint distribution simplifies to f(0, 0) = fN(0) and represents the probability of zero claims. In addition, when N = 0, the average severity also will be 0. Here we choose distributions for both frequency and average severity from the family of GLMM distributions. As a final specification of this dependent compound risk GLMM, we incorporate dependence between frequency and severity by adding the number of claims N as a linear predictor in the mean function for the average severity. While we assume that only the number of claims N of the current year can affect the mean of the severity of the current year just for simplicity of the model, this assumption can be generalized to assume that the number of claims N can affect the severity even though they are not in the same year. In particular, for the frequency component, we write the mean in terms of the linear predictor as
μf=E[N|x]=g−1N(x′α+z′Nb),
where is a parameter vector for the covariates associated with frequency. For the severity component, we write
μs=E[¯C|x,N]=g−1C(x′β+z′Cu+θN),
where is a parameter vector for the covariates associated with average severity for which they may be different from that of frequency.
Finally, we can define the compound sum as
Sit=Nit∑j=1Citj=Nit¯Cit
to represent the aggregate claims for policyholder i in calendar year t. Suppressing the subscripts, it is straightforward that the unconditional mean of S can be expressed as
E[S|x]=E[N¯C|x]=E[NE[¯C|N,u]|x]=E[Ng−1C(x′β+z′u+θN)|x]
and the unconditional variance as
Var(S|x)=Var(E[N¯C|N,x])+E[Var(N¯C|N,x)]=Var(NE[¯C|N,x]|x)+E[N2Var(¯C|N,x)|x]=Var(Ng−1C(x′β+z′u+θN)|x)+E[N2τV(g−1C(x′β+z′u+θN))|x].
Note that if we are interested in the aggregate claims for calendar year t alone, we can easily define this as
St=M∑i=1Nit¯Cit,
where M here is the total number of policies for each year. This should not preclude us from assuming that the number of policies may vary by year.
2.2. Negative binomial for frequency and gamma for average severity
To illustrate further the concepts, we now consider a negative binomial distribution for the frequency and a gamma distribution for the average severity.
Starting with the frequency component, we have the following model specification:
N|b∼ indep. NB(νeb,r) with density fN(N|b),
where
fN(n|b)=(n+r−1n)(rr+νeb)r×(νebr+νeb)n.
Based on the log-link function, we have where is a p × 1 vector of regression coefficients. The following relations hold:
E[N|b]=ex′α+bandVar[N|b]=ex′α+b(1+ex′α+b/r).
It is clear from these relations that unlike the Poisson distribution, overdispersion can be handled easily by the negative binomial distribution. An additional item to note is the accounting of the exposure, and this is accomplished through an adjustment to the mean parameter by multiplying it with eit.
We assume that the random effect b has a normal distribution with mean 0 and variance We will need the density function of b, and for our purposes, we will denote it by
fb(b)=dFbdb=1√2πσbe−b2/2σ2bso thatE[h(b)]=∫((h(b)1√2πσ2be−b2/2σ2bdb=∫((h(b)dFb.
For the average severity component, given N > 0, we have the following model specification:
¯C|N,u∼ indep. Gamma(μeu+θn,ϕn)with density f¯C|N(¯c|n,u),
where
f¯C|N(¯c|n,u)=1Γ(n/ϕ)(nμeu+θnϕ)n/ϕׯcn/ϕ−1exp(−n¯cμeu+θnϕ).
Similar to the frequency component, we assume a log-link function so that where is a p × 1 vector of regression coefficients. The set of covariates selected for the severity component may be different from that of the frequency component. Any covariate that will not be considered significant simply may be ignored, and naturally this implies a corresponding beta coefficient of 0. In addition, we will introduce the number of claims n as a covariate with coefficient With this specification, the following relations hold:
E[¯C|N,u]=ex′β+θn+uand Var[¯C|N,u]=e2(x′β+θn+u)ϕ/n.
Note that both the negative binomial for frequency and the gamma for average severity fall within the class of GLMMs. This is easy to verify.
We assume that the random effect u has a normal distribution with mean 0 and variance and that its density function will similarly be denoted by and defined as
In summary, our observed data consist of
(Nit,¯Cit,xit,eit)′
for calendar year t, for t = 1, … , Ti, where and for policyholder i, for i = 1, … , M. The general form of the likelihood then can be expressed as
L=∫∫(∏i(∏tf(nit,¯cit|b,u)dFbdFu.
One key property here is that the likelihood function L in equation (2.13) is divided into two product terms, where one term is related with parameters only for frequency while the other term is related with parameters only for severity. By using our proposed model, essentially we are optimizing two separate parts while still considering dependence between frequency and severity. Such decomposition of the likelihood function L enables us to optimize L using existing generalized linear mixed-effect model packages in most statistical software packages.
To derive maximum likelihood estimates, we maximize log L with respect to all the parameters by taking partial derivatives and setting each to 0. This leads us to the following set of (2p + 3) estimating equations that solve for and for :
(∑i[∫((∑(tx′it(k)r+ex′itα+b(nit−ex′itα+b)∏(tfN(nit)dFb∫((∏(tfN(nit)dFb]=0,
(∑i[∫(((b2−σ2b)∏(tfN(nit)dFb∫((∏(tfN(nit)dFb]=0,
(∑i{[∫(((∑tnitx′it(k)ex′itβ+θnit+u(¯cit−ex′itβ+θnit+u)×(∏tf¯C|N(¯cit|nit)dFu]÷[∫(((∏tf¯C|N(¯cit|nit)dFu]}=0,
∑i{[∫∑tn2itex′itβ+θnit+u(¯cit−ex′itβ+θnit+u)×∏tf¯C|N(¯cit|nit)dFu]÷[∫∏tf¯C|N(¯cit|nit)dFu]}=0,
(∑i[∫(((u2−σ2u)∏(tf¯C|N(¯cit|nit)dFu∫((∏(tf¯C|N(¯cit|nit)dFu]=0.
For the additional parameters r in the frequency model and φ in the average severity model, we find that there is no explicit form for the respective partial derivatives. We can estimate these parameters by using the method of moments. Additional details about the derivation of the likelihood estimating equations developed above are in Appendix A.
It is interesting to note that in this special case wherein we have a negative binomial for frequency and gamma for average severity, we find that the unconditional mean is
E[S|x]=μνE[[1−(νeb/r)(eθ−1)]−r−1]×eσ2u/2+θ
and the unconditional variance is
Var(S|x)=μ2eσ2u+2θ×(ϕE[νeb[1−(νeb/r)×(e2θ−1)]−r−1]eσ2u+E[ν2e2b+2θ(1+1/r)×[1−(νeb/r)(e2θ−1)]−r−2]eσ2u+E[νeb[1−(νeb/r)×(e2θ−1)]−r−1]eσ2u−E[νeb[1−(νeb/r)×(eθ−1)]−r−1]2),
provided all the terms with expectation exist. Details of the derivation for equations (2.14) and (2.15) are provided in Appendix B.
As a final remark, we broadly call the model constructed in this subsection to be the dependent GLMM. In the special case wherein we do not have random effects, that is, we will call this the dependent GLM, which is equivalent to that developed by Garrido, Genest, and Schulz (2016). In the additional special case where we have the independent GLM. In the validation section, we compared these three models together with the Tweedie GLM and the Tweedie GLMM. The Tweedie models will be described later.
3. Data characteristics and preliminary investigation
For the empirical investigation in this paper, we calibrated our proposed dependent GLMM frequency-severity model using the policy and claims experience data of a portfolio of automobile insurance policies from a general insurer in Singapore. The observed data are from a period of six years, 1994 to 1999. These data were obtained from the General Insurance Association of Singapore, a trade association with representations from all the general insurance companies doing business in Singapore during the said six-year period. All claim amounts are in Singapore dollar (SGD) currency. These data or some extracted form of these data have been used in several papers including, but not limited to, Frees and Valdez (2008) and Shi and Valdez (2012).
Automobile insurance is one of the largest, if not the most important, lines of insurance offered by general insurers in the Singapore insurance market; its annual gross premium historically has accounted for more than a third of the entire insurance market. As is the case in most developed countries, auto insurance provides coverage at different layers, with the minimum layer’s being mandatory, providing protection against death or bodily harm to third parties regardless of who is at fault. In many countries, this is called third-party liability coverage.
For estimation purposes, we used policy and claims information for the first 5 years, 1994 to 1998, which we call the training data set. For validation, we used the observed information for 1999. Our summary statistics in the rest of this section consist only of the training data. Here, we have a total number of M = 41,831 unique policyholders, each of which is observed Ti years, and in essence, the maximum value of Ti is 5 years.
Observations in the portfolio consist of policies with comprehensive coverage for first-party property damage and bodily injury as well as third-party liability for property damage and bodily injury. We considered the total claims arising from all types of coverage.
We used observed policy characteristics from the portfolio as covariates in both the frequency and the severity components, and simple summary statistics for these covariates are provided in Table 1. We have a total of nine variables, including those classified as categorical or continuous and those transformed, in our policy file. Furthermore, it is typical for companies to classify automobile insurance policyholders according to both driver information and vehicle information; in our policy file, gender and issue age are driver information, and the rest of the information pertains to the vehicle. The table is indeed self-explanatory, but there are a few items worth noting about the insured portfolio used in this analysis. First, although motorbike insurance is not uncommon in Singapore, in our data set, usually cars are the insured vehicles. Second, unlike in the United States, it is not uncommon to have fewer female drivers in the portfolio. Third, an examination of the age of vehicle measured in years indicates that vehicles can be age –1; it is possible to purchase a vehicle with a model year after the purchase year. Also, the average age of vehicles is about 7 years, indicating that insured vehicles are generally newer and less than 10 years old. In Singapore, this is not at all surprising given the government restriction on allowing entitlement of vehicle ownership that usually expires in 10 years.
Table 2 provides a summary of the claim frequency distribution from calendar years 1994 to 1998. For each year, there is a significant percentage of zero claims. On average, each year shows 91.6% zero claims, with this percentage ranging from 90.2% to 92.2%. This large percentage of zero claims is not uncommon for a portfolio of automobile insurance, thereby allowing insurance companies the pooling of homogeneous risks through diversification. The aggregated total number of observations is 108,017; when compared to the number of unique policyholders observed, which is M = 41,831, this number indicates that there are repeated observations for each unique policyholder, who is observed, on average, for a little more than 3 years. Moreover, notice that the number of policies observed varies each year, indicating the unbalanced nature of our data. In some years, policies either lapse (leave the company) or newly join the company. In a calendar year, the most frequent number of times a policyholder makes a claim is just once. There are very few policyholders with more than three claims in a calendar year.
Table 3 presents the average claim severity amounts for numbers of claims and for calendar years. The overall average claim amount is 4,655.09, ranging from 4,377.50 to 5,087.05. The more interesting observation we can deduce from this table is an examination of the last column: we see an increasing average amount of severity for increasing numbers of claims. For most calendar years, this positive correlation can be observed. However, such a positive correlation cannot be deduced from Figure 1. This figure provides further examination of the possible dependency between frequency and average severity. It is difficult to find a more conclusive relationship between frequency and average severity in this figure. However, this preliminary investigation of the data suggests that we can probably find more conclusive statistical evidence of the relationship when we inject the relation of number of claims to average severity within either the GLM or the GLMM framework.

Figure 2 provides yet another preliminary observation of the possible relationship between frequency and average severity. In this figure, the x-axis indicates frequency, and the y-axis indicates average severity. Here we can see wider variation of average severity for smaller numbers of claims. While this may indicate some evidence of a possible relationship between frequency and average severity, because the effect of the heterogeneity of policyholders is not controlled for, it is difficult to draw a strong deduction of this relationship.

In practice, the use of the Poisson model for frequency is not uncommon. However, it is well known that the Poisson model cannot accommodate the large dispersion that is frequently observed with number of claims. For our data, the overall average number of claims is 0.091, with a variance of 0.099. These values indicate a slight possibility of overdispersion. Using a negative binomial to accommodate this possible overdispersion is also widely accepted in the actuarial literature; see, for example, Frees and Valdez (2008).
To further support our choice of a negative binomial for frequency, we provide a goodness-of-fit test for the Poisson model compared to the negative binomial. As shown in Table 4, the smaller test statistic observed for the negative binomial indicates that it is a better choice than the Poisson model.
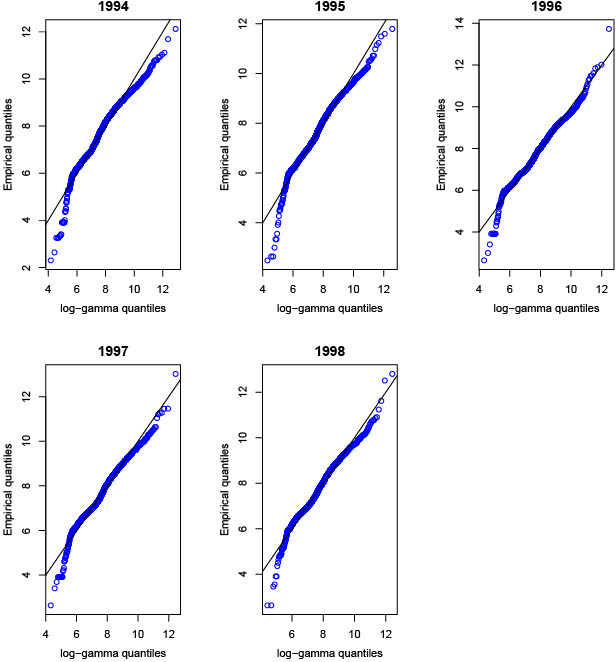
To conclude this section on data, we provide the quality of the goodness of fit of choosing a gamma distribution model for average severity. Figure 3 provides log quantile-quantile (log-QQ) plots of fitting the gamma distribution for each calendar year for the period from 1994 to 1998. We use the log transformation here to summarize the quantiles because this helps us justify using a log-link function within the GLM framework later. It is well known that the gamma model typically provides a good fit for lines of business with claims that have medium-sized tails. It is marginally clear from these log-QQ plots that we may have a somewhat weak fit on both ends of the tail of the distribution for most calendar years. We wanted to restrict our marginal choice for the average severity to be within the class of the exponential, or GLM, family. Furthermore, these plots are preliminary and do not consider the effect of policy characteristics for covariates or even the effect of the number of claims where we saw earlier that there may be some possible effect of varying average severity by frequency of claims. However, we feel that for future research, we need to address the quality of the fit on the tail of the severity distributions.
4. Results of estimation and model validation
This section provides details about the numerical results of calibrating the various models described in Section 2. Recall that in that section we described the two-part frequency-severity model that is often used for fitting insurance claims data. The first component is the frequency model for which preliminary investigation of our data in Section 3 suggested the use of a negative binomial. For the second component, we described the average severity model, given the number of claims observed. It was understood that the average severity is 0 for zero claims. For a positive number of claims, we described in Section 2 the use of a gamma distribution for average severity, one that falls within the class of GLM distributions. In addition, we provided some motivation for this choice in Section 3.

4.1. Numerical results
As was earlier suggested and also is widely known in the actuarial literature, the negative binomial model usually is a better choice for the frequency component than is the Poisson model. The justifications in this case are the accommodation of overdispersion that is typically present in insurance claims and the possible influence of unobserved random effects. Table 5 summarizes the regression estimates for the negative binomial for both the GLM and the GLMM.
We now compare the two negative binomial regression models for the frequency component. First, we note that the only difference between these two models is the presence of random effects in the GLMM. Second, we compare the regression coefficient estimates and their levels of significance. Note that because historically we have known the nonlinearity of age to claims, we added the square and cubic factors for age in our regression models. Broadly speaking, the effects of each of the explanatory variables summarized in Table 5 are not much different between the two models. One can deduce that if a random effect is added as in the GLMM, there is a slight decrease of the p-values of the corresponding coefficients. The signs of the coefficients are consistent between the two models and appear to be intuitive. For example, when compared to cars, motorbikes are less likely to claim, and this might partly be because cars are more frequently on the road. Older vehicles are less likely to claim, and this may be explained by fewer older vehicles’ being insured. Male drivers are more likely to claim; historically, this has been intuitively explained by the more aggressive driving behavior of males than of females. The effect of the policyholder’s age does not seem to be significant in this portfolio. With respect to the effect of a premium discount, this is measured by the no claim discount score, and the result is statistically significant and indeed quite intuitive. The negative sign indicates that policyholders with higher discounts are considered less risky drivers and hence tend to have lower likelihoods of making claims.
Finally, we can examine the quality of the model fit by comparing the goodness-of-fit statistics that include the value of the log-likelihood, the Akaike information criterion (AIC) and Bayesian information criterion (BIC). All three statistics are reported at the bottom of Table 5. Because we maximize the log-likelihood, we consider a greater value to be superior. For either AIC or BIC, we consider a lower value to be superior. An examination of all three model fit statistics suggests that the GLMM is slightly superior to the GLM.
We now turn to the average severity component, conditional on the event of at least one claim. There are three regression models we compared: the independent GLM, the dependent GLM, and the dependent GLMM. Each of these was discussed in Section 2.
There are a few interesting observations we can draw from the regression estimates summarized in Table 6. First, for the most part, the regression estimates are consistent among all three models. To illustrate, consider the effect of vehicle type. The estimates suggest that claim amounts are larger for motorbikes than for any other types of vehicles. Although we found in the frequency component that motorbike drivers are less likely to make claims, the result here suggests that when motorbike policyholders make claims, the severity impact is worse. This is consistent with studies that suggest that the risk of fatal crashes among motorbike drivers is far greater than among passenger car drivers. Moreover, these same studies suggest that the seriousness of the injuries in motorbike crashes is worse than that in passenger car crashes. Furthermore, not only do younger drivers have a higher likelihood of claims, but the severity of claims is far worse for younger drivers. Generally, younger drivers exhibit more aggressive behavior when it comes to driving, and they have poorer judgment when intoxicated. Second, there also are some clear differences. For example, in the dependent GLMM, the regression estimate for the presence of comprehensive coverage has a positive sign, and the corresponding p-value suggests the significance of this variable. In each of the other two models, the effect of the presence of comprehensive coverage is not statistically significant. The more interesting difference has to do with the coefficient estimate associated with count between the dependent GLM and dependent GLMM. While both models provide significant evidence of dependence, the signs are opposite, suggesting there is inconsistency in the possible relationship between frequency and claims. However, this inconsistency in sign is attributable to the presence of the random effects in the dependent GLMM. Controlling for the presence of the random effects accounts for the resulting differences in means among groups of policyholders implied by the random effects. This is a favorable argument for using a dependent GLMM.
Finally, we examine the quality of the model fit by comparing the goodness-of-fit statistics that include the value of the log-likelihood, the AIC and BIC. All three statistics are reported at the bottom of Table 6. An examination of all three model fit statistics suggests that the GLMM is far superior to the other two models.
In practice and in the actuarial literature, there is increased interest in the use of the Tweedie exponential dispersion family model to fit compound loss models. See, for example, Frees, Lee, and Yang (2016). The Tweedie family of distributions belongs to the exponential family, with a variance function of the power form as for p not in (0, 1). Special cases include the normal distribution when p = 0, the Poisson distribution when p = 1, and the gamma distribution when p = 2. However, when 1 < p < 2, the Tweedie distribution can be derived as a compound Poisson-gamma distribution with a probability mass at 0. Although in this case, there is no explicit expression for the density function, the primary advantage of fitting such Tweedie models is to fit both the claim frequency and the claim severity simultaneously. It is interesting to note that Tweedie models have been applied in biostatistics and climatology.
Because of the increasing interest in this family of distributions for fitting loss models, we consider here the Tweedie regression models based on both the GLM with only fixed effects and the GLMM with the addition of random effects. These Tweedie models explicitly ignore the possible dependence between frequency and severity. The results are summarized in Table 7 wherein according to the goodness-of-fit statistics, the Tweedie GLM outperforms the Tweedie GLMM. In the next section, we will compare the performance of all the models described in this section.
4.2. Validation results
As we earlier alluded to, we made the observations for 1999 our holdout sample that we now use for model validation. The process of this model validation predicts both the frequency (or count) and the average severity (or claim amount) to derive the total claim amount and to compare the predicted with the actual (or observed) total claim amount for the policies in 1999.
For our purposes, the actual value of the total claim amount is denoted by si, and the corresponding predicted values, for the various models, by Here, for policyholder i in 1999. Two validation measures were used to compare the models:
\begin{align} \text{Mean Squared Error:}\ \ MSE = \frac{1}{M}\sum_{i = 1}^{M}({\widehat{s}}_{i} - s_{i})^{2}, \\ \text{Mean Absolute Error:}\ \ MAE = \frac{1}{M}\sum_{i = 1}^{M}\left| {\widehat{s}}_{i} - s_{i} \right|.\end{align}
Between two models, we would normally conclude that the one that produces (1) a lower MSE is better, and (2) a lower MAE is better. These two validation measures provide the prediction accuracy of the various models. The difference between these two measures has to do with the norm used. Larger deviations relatively have a greater effect on MSE than do smaller deviations. When compared to MSE, MAE is relatively less sensitive to large deviations. As such, MSE is much more sensitive to observations that are considered outliers.
Note that we have a total of five models being compared: the two-part independent GLM, the two-part dependent GLM, the two-part dependent GLMM, the Tweedie GLM, and the Tweedie GLMM. Table 8 compares these validation measures produced by the two-part models and the Tweedie models, respectively. The values summarized in the table are self-explanatory.
For instance, the dependent GLMM outperforms the other models in terms of both validation measures for the prediction of total loss. This provides a strong argument for choosing the dependent GLMM.
Besides using MSE and MAE, to simultaneously make a valid comparison among these five models, we applied the idea of the Lorenz curve and calculated the Gini index for each model. Details about drawing the Lorenz curve and eventually computing the Gini index can be found in Chapter 2 of Frees, Derrig, and Meyers (2016). The Gini index also has been used as a model validation measure in Frees, Lee, and Yang (2016).
Within the context of this paper, we proceed with the following three-step process to draw the Lorenz curve. We repeat this procedure for each model using the holdout sample. From this Lorenz curve, we compute the corresponding Gini index.
-
From our holdout sample, for i = 1, 2, … , M, sort the observed loss Yi according to the risk score Si, which in our case is the predicted value from each model, in an ascending manner. That is, calculate the rank Ri of Si between 1 and M with R1 = argmin(Si).
-
Compute the cumulative percentage of exposures, and the cumulative percentage of loss, for each
-
Plot Fscore(m/M) on the x-axis and Floss(m/M) on the y-axis.
The predicted value as defined above is our pure premium according to the model being considered. The Gini index is equal to two times the area between the line of equality and the Lorenz curve drawn above. We choose the model with the highest Gini index. According to Figure 4, the dependent GLMM is the best among all five models, with a Gini index equal to 45.7%.

5. Concluding remarks
In this paper, we offered the use of the GLMMs as alternative models with dependent claim frequency and claim severity. The concept is a natural extension of the dependent frequency-severity model based on GLM introduced by Garrido, Genest, and Schulz (2016). With dependent GLMM, we similarly introduced dependence by inducing frequency as an explanatory variable for the average severity but added random effects typically used to capture dependence because of the repeated observations. The GLMM is a natural extension of GLM when claims are observed for policyholders over a period of time. The GLMM has the advantage of being able to control for the random effects of groupings of policyholders, especially in terms of degrees of riskiness. This model is called the dependent GLMM throughout the paper.
To calibrate our model, we used the policy and claims experience data of a portfolio of automobile insurance policies from a general insurer in Singapore. The observed data are from a period of six years, 1994 to 1999. We used the first five years’ experience data as the training set for model estimation and used the final year, 1999, as the holdout sample for validation. To provide a strong argument for the superiority of our proposed model, we considered four other models that we called the independent GLM, the dependent GLM (Garrido, Genest, and Schulz 2016), the Tweedie GLM, and the Tweedie GLMM. In most measures of model comparison, model validation, and even the Gini index, the dependent GLMM outperforms the four other models.
In future research, we need to examine a better model for severity. As indicated by our preliminary investigation, the gamma model did not do well capturing the long tail of the loss distribution. For most insurance lines of business, this is usually the case, and hence we need further investigation. This paper is a very good start to justify the use of random effects within the class of GLMs.