
1. Introduction
In the literature, we often see the application of a single-parameter Pareto (SPP) distribution as a model to describe income and wealth. In insurance applications, heavy-tailed distributions of the SPP sort are essential tools for modeling extreme losses, especially for more risky types of insurance, such as medical malpractice insurance. In the field of actuarial science, the SPP distribution is combined with another distribution to model the portion of data characterized by large claims with low frequencies, i.e., high-severity risks. For the other portion of data characterized by small claims with high frequencies, i.e., low-severity risks, other distributions such as the exponential or the log-normal are used. Such models are called composite models. Deng and Aminzadeh (2020) developed a Bayesian predictive Weibull-Pareto composite model, and Aminzadeh and Deng (2019) developed a Bayesian predictive inverse gamma–Pareto composite model. Recent work in the field of network traffic has considered an SPP distribution as the interarrival distribution. Fras et al. (2010) considered the distribution for modeling self-similar network traffic. Harrison et al. (2014) used a network simulator to generate statistics on arrival times of traffic and concluded that an SPP distribution is more appropriate than the conventional exponential distribution in modeling interarrival times on a bursty network. The SPP distribution has also been used for insurance models: Hanafy (2020) used the distribution for interarrivals of claims on data from Egyptian fire insurance companies.
The Lomax distribution (also known as a Pareto Type II distribution) is a heavy-tailed probability distribution used in business, economics, actuarial science, queueing theory, and Internet traffic modeling. It is essentially the SPP distribution, but its support begins at zero and it has a probability density function (PDF) given as
f(x)=αm(1+xm)−(α+1),x>0, α,m>0
The above PDF can also be written as
f(x)=αm(xm)−(α+1),x>m, α,m>0.
which is the standard form of the PDF for the SPP and which is also used by Ramsay (2006). Garsva et al. (2014) considered a Pareto Type II distribution as a model for the packet interarrival time distribution in an academic computer network, and they concluded via a Kolmogorov-Smirnov test that it was an appropriate choice.
In this paper, we analyze flood and tornado insurance damage data sets (provided in the Emergency Events Database (EM-DAT); see appendix) in the United States from the year 2000 to the year 2020. We show that both data sets fit the SPP distribution well. The interarrivals between two insured damages are defined as the difference between the start date of an occurrence and the start date of the subsequent occurrence.
Our purpose in this paper is to use SPP as the interarrival distribution of a renewal process and provide the ML- and MCMC-based Bayes estimators of the renewal function. Martino (2018) provides a thorough review of MCMC methods and compares them with numerical methods. In the current paper, we use the Metropolis-Hastings algorithm—see Casella and Berger (2004)—for the MCMC method to estimate the renewal function.
In Section 2, we define the renewal function and give computational formulas for the renewal function based on Ramsay (2006). These formulas are used in the Mathematica code for simulations and estimation of the renewal function. Section 3 provides the ML estimation for the parameters of the SPP distribution. Section 4 provides the derivation of two conditional posterior distributions that are based on shifted-exponential and gamma priors. In Section 5 we outline the steps taken in the Mathematica code to use the MCMC algorithm and discuss a summary of the simulation results. Section 6 provides numerical examples to illustrate the computations, and Section 7 concludes. The Mathematica code used for the simulations and the estimation of the renewal function in this paper is available from the authors.
2. Renewal function of the SPP distribution
Let be a counting process, where denotes the number of events that occur by time Let denote the time between the st and th events of this process, If is a sequence of independent identically distributed (iid) random variables, then the process is called a renewal process.
Renewal theory has many applications in stochastic modeling, and as a result, statistical inference with respect to the renewal function is of interest in many applied fields. For example, in reliability theory, a renewal process can be used to model successive repairs of a failed machine. In actuarial science, a renewal process can be used to model the successive occurrences of risks. Hardy (2006) provides many examples for risk measures with actuarial applications, such as in property and casualty (P&C) insurance, life insurance, and the banking industry. Necir, Rassoul, and Meraghni (2010) provide a semiparametric estimate of the renewal function for heavy-tailed risks. Woo (2011) provides two-sided bounds for the renewal function considering a variety of reliability classifications.
In this paper, we consider ML- and MCMC-based Bayes estimators of the renewal function. Actuaries should find the results useful in applications where events (risks) occur according to a counting process and the renewal random variable has an SPP distribution. One of the measures associated with a renewal process is the renewal function, In some applications of renewal processes, one is interested in estimating the number of renewals by time Provided that the parameters associated with the interarrival distribution are known or estimated, the computation can be accomplished by using the integral equation
M(t)=E[N(t)]=∫∞0E[N(t)|X1=x]f(x)dx=F(t)+∫∞0M(t−x)f(x)dx,
where and are, respectively, the PDF and the cumulative distribution function (CDF) of the interarrival random variable For example: (a) for the uniform(0,1) interarrival distribution, and (b) for the exponential interarrival distribution with the PDF where is the scale parameter, the reason being that when the interarrival times have an exponential distribution, However, the derivation of in a closed form for many interarrival distributions is not straightforward. Let denote the time of th renewal. It can be shown that
M(t)=∞∑n=1FSn(t),
∂M(t)/∂t=M′(t)=∞∑n=1fSn(t),
where and respectively, are the PDF and the CDF of Therefore, to find in a closed form, not only must we identify the distribution of but we must also evaluate which may not be trivial.
Ross (2007) supplies us with a method to approximate the renewal function. The method computes …, recursively to approximate the renewal function using
Mr(t)=∑r−1k=1(1+Mr−k(t))E(Xke−δrX)(δkr/k!)+E(e−δrX)1−E(e−δrX), M1(t)=E(e−δ1X)1−E(e−δ1X),
where is used for the computation of Therefore, are found consecutively to approximate the renewal function Ross indicates that for a large is approximated by quite well. The method is useful when and have explicit expressions for an interarrival distribution. For example, if the interarrival distribution is gamma (2,1) (shape parameter = 2, and scale parameter = 1), then
E[Xke−rXt]=t2(r+tt)−kΓ(2+k)(r+t)2, rt>−1,
Then using (2) it can be shown that the exact expression for the renewal function is
M(t)=.5t−.25(1−e−2t),t>0.
For is the exact value, where its approximate value based on is calculated in Ross (2007) as 4.75. As another example, for the interarrival random variable with PDF and CDF is approximated as 15.5089 (see Ross 2007). For some interarrival distributions, cannot be derived in a closed form. For example, consider the inverse Gaussian (IG) distribution and let it can be shown that but cannot be written in a closed form. See Aminzadeh (2011), where the author provides a Bayes estimator of the renewal function using IG distributed interarrivals. For with given values for and and unknown values for and Mathematica cannot provide a closed form for
∫∞0xke−(r/t)xf(x;ϕ,λ)dx.
However, for example, with and for the above expected value we get
2k31/4+k/251/4+k/2e1.5BesselK[.5−k,√15/2]/√π
via Mathematica with a long integration time, and the expression is quite complicated. SPP which is considered in the current paper, is an even more difficult case, as
∫∞mxke−(r/t)xf(x;m,α)dx
cannot be obtained in a closed formula, even for selected values of and
For the SPP distribution, the approximation Ross provides is not practical. The reason is that cannot be written in a closed form and therefore an approximate expression for the expected values must be derived or evaluated numerically, which would depend on Even if a "good"expression for the expected value is found, different values of would produce different expressions/approximations for the expected value. In addition, the recursive formula for uses previous approximations for the expected value. Therefore even for a small value of in the above sum has to be approximated for In addition to the approximation errors, one has to take into account the accumulated approximation errors for the expected value that are involved in the computation of Thus, due to the many accumulated approximation errors involved for approximating and Ross’s method is not considered in this paper.
The PDF of the SPP random variable with parameters and is given by
fX(x;α,m)=αx−(α+1)mα,x>m, and α,m>0.
Consider a renewal process and let the time between the st and th renewal, be distributed as SPP Suppose from this process a random sample is collected. The random sample will be used to find the ML and an approximate Bayes estimate for via an MCMC algorithm.
Ramsay (2006) applied Laplace transforms and generalized exponential integrals to develop the following exact expressions for PDF and CDF of under the assumption that are iid from the SPP distribution and that is a positive integer. Recall that is the time of th renewal. The following formulas are from Ramsay (2006):
fSn(s)=1nm∫∞0e−(1+snm)vϕα,n(vn)dv,
where,
ϕα,n(v)=(−1)n+1αn⌊(n−1)/2⌋∑r=0(−π2)r(n2r+1)(Gα+1(v))n−2r−1(vαα!)2r+1,
Gα(v)=vα−1(α−1)![γ+ln(v)−α−1∑r=11r]+∞∑r=0,r≠α−1vr(r−α+1)r!,γ=.5772156649,
and
FSn(t)=∫t0fSn(s)ds=∫∞01v(1−e−tvm)e−nvϕα,n(v)dv.
The approach for computing in Ramsay is to use a series expansion and then use
e−nvϕα,n(v)=(−1)n+1αn⌊(n−1)/2⌋∑r=0(−π2)r(n2r+1)(e−vGα+1(v))n−2r−1(e−vvαα!)2r+1
in (4) to compute The above formulas are built into the Mathematica code of the current paper, and the NIntegrate function of Mathematica is used to compute (4) based on input values and
Although the results given in Ramsay assume that is a positive integer, simulation studies confirm that for both ML and Bayes estimates of the renewal function, once the ML and Bayes estimates of the parameters and are obtained, the estimated values of can be rounded to the nearest integer so that and as a result an estimate for can be obtained. The reason that in Ramsay is assumed to be a positive integer is that to derive (4), for complex and Re it is shown that the Laplace transform of is given by where and for is the generalized exponential integral. And then is inverted to get the Bromwich integral for and consequently the CDF in (4) is derived. Simulations confirm that by rounding the estimated values of the average squared error (ASE) of the ML and Bayes estimates of the renewal function is still quite small and that the MCMC-based Bayesian method outperforms the ML method with regard to accuracy when the sample size is small. For large sample sizes, the ML and Bayes methods have comparable accuracies.
3. Maximum likelihood estimation of M(t)
Based on a random sample from SPP and using the likelihood function
L(α,m)=αH(H∏i=1Xi)−(α+1)mHα,Xi>m,i=1,2,...,H,
it can be shown that the ML estimates of and are
ˆm=X(1),ˆα=HT−Hln(X(1)),T=H∑i=1ln(Xi),
and that is a minimal sufficient statistic for is the first-order statistic. The goal is to estimate
M(t)=∫t0M′(s)ds=∞∑n=1FSn(t).
Therefore, for each value of in (6), and given estimates of (based on a random sample we can compute via (4). Computations confirm that for selected values and the CDF in (4) is a decreasing function of The Mathematica code in a while loop searches for an appropriate upper limit for the sum in (6). The loop starts with and continues until and, using the value of computes as an estimate for
It is also noted that through an estimate of where is a truncated time, the excess life of a renewal at time can be estimated. Let denote the excess life at and be the mean of interarrival random variable We can use the well-known formula
M(τ)=τμ−1+E[Y(τ)]μ,
to find the ML estimate of via the ML estimate and the ML estimate of The same formula above can be used to get an approximate (using simple substitution) Bayes estimate of once Bayes estimates of and are found through the MCMC algorithm given in Section 5.
4. Bayesian estimation of M(t)
In the literature, we find many instances where authors consider Bayesian inference for the parameters of the SPP distribution. Sun et al. (2021) adopt the Jeffreys prior to obtain Bayes estimates for and Kim, Kang, and Lee (2009) also provide Bayes estimates via the non-informative Jeffreys prior for SPP. Noor and Aslam (2012) provide non-informative as well as informative Bayes estimates of SPP parameters; however, in their paper, gamma priors are used for both and
The characteristics of the shifted exponential distribution with regard to its support are similar to the support of SPP. This is the main reason that in the current paper we use the shifted exponential prior as opposed to another distribution with support The PDF of the shifted exponential prior is given as
ρ(m|a,b)=1be−(m−ab), m>a, a,b>0,
where (location parameter) and (scale parameter) are hyperparameters associated with the prior distribution.
For the conditional prior of gamma is selected, with the PDF
ρ(α|m)∝αc−1e−αd, c,d>0,
where (shape parameter) and (scale parameter) are hyperparameters associated with the conditional prior distribution. As mentioned earlier, although computation of the CDF requires that be an integer (as the formulas in (4) use only positive integers for using a gamma distribution for the conditional prior does not cause an issue with regard to the accuracy of the ML and Bayes estimates of the renewal function. For the current paper, in the Mathematica code for simulations, once a Bayes estimate for is obtained, it is rounded to the nearest integer for computational purposes. From (7) and (8), we get the joint prior as
ρ(α,m)∝αc−1e−(αd+mb), m>a.
Now, using the likelihood function for a sample of size the joint posterior is given by
π(α,m|x_)∝αH+c−1e−α(1d+T)mHαe−mb, m>a.
To apply an MCMC algorithm, (11) is used to find the conditional posteriors as
π(α|x_,m)∝αH+c−1e−α(1d+T)mHα,
and
π(m|x_,α)∝e−mbm(Hα+1)−1, m>a.
Simon and Adler (2021) provide a thorough reference on MCMC algorithms and compare several MCMC methods for estimating the parameters of the Pareto/negative binomial distribution (NBD) model and their performance. The Handbook of Markov Chain Monte Carlo (Brooks et al. 2011) covers MCMC foundations, methodology, and algorithms, as well as MCMC’s use in a variety of practical applications in areas such as educational research, astrophysics, brain imaging, ecology, and sociology. Many authors have discussed the MCMC method via conditional posterior distributions and the Metropolis algorithm. In particular, the description and implementation of the Metropolis algorithm can be found in Casella and Berger (2004), among other books and articles.
Ji, Aminzadeh, and Deng (2020) propose an MCMC Bayesian approach using the Metropolis algorithm and conditional posteriors to obtain estimates of the parameters as well as an approximate predictive density via simulation, which can be used to compute life expectancy and other measures of interest in a Bayesian framework. Aminzadeh and Deng (2021) employ an MCMC method based on the Metropolis algorithm and conditional posterior distributions to estimate ruin probability based on nonhomogeneous Poisson process claim arrivals and inverse Gaussian–distributed claim aggregates. The MCMC algorithm we use in this paper is based on the same logic as the aforementioned articles.
Considering the conditional posterior distributions in (12) and (13), we can see that the kernel of the PDF in (12) does not belong to the gamma distribution, due to the extra term Therefore, we use gamma as a proposal distribution for the PDF in (12) within the MCMC algorithm. and are, respectively, the shape and scale parameters of the proposal distribution gamma For selected "true"values of and in simulation studies, values of and are selected in such a way that is close enough to while is very small. This is because the expected value and variance of the proposal gamma distribution are, respectively, and
As for the conditional posterior (13), we can see that it resembles the kernel of the generalized gamma distribution with the PDF
f(y|g,β,ξ,μ)=ξe−(y−μβ)ξ(y−μβ)gξ−1,y>μ,
where and Note that is the location parameter and is the scale parameter.
5. Simulation
For selected values of the Mathematica code (available from the authors upon request) first computes the "true"value of the renewal function via (4). The code then generates random samples from the SPP distribution using a built-in function in Mathematica. For the generated sample the following steps are taken:
-
ML estimates of and are computed via the formulas in Section 3.
-
For each value of in the While loop, ML estimates from Step 1 are used to compute the CDF in (4). The while loop starts with and computes via (4). Then for each value of is calculated. Computations confirm that for given values of and the CDF in (4) is a decreasing function of The Mathematica code in the while loop searches for an appropriate upper limit for the sum in (6). Computations continue until And, using the value of the loop ends and is reported as the ML estimate of the renewal function based on sample It is noted that in this step, the ML estimates of and which are based on a generated sample of size from the SPP, are used in (4) to find for and that is a symbolic notation in the CDF The computation of (4) does not depend on a value of
-
The mean and ASE of estimates of the renewal function based on simulated samples are respectively computed as
¯ˆMML(t)=∑Ni=1Mi,ML(t)N,ξML(ˆM(t))=∑Ni=1(Mi,ML(t)−M(t))2N.
Note that the term MSE (mean squared error) refers to the expected value of an estimator under the squared-error loss function. In this paper, the term ASE refers to where is an estimate of the "true"parameter based on a generated sample
To compute the MCMC-based Bayes estimate of the renewal function, we use the conditional posterior distributions in (12) and (13). Let denote the conditional posterior PDF (RHS in (12)) of given and is the PDF of the proposal distribution gamma for As mentioned earlier, in simulation studies, for selected "true"values of and the values of and are selected in such a way that is close enough to while is very small. Also, the hyperparameters and are selected such that while is small. Again, this is due to the expected value and variance of the gamma distribution. For example, if we select in simulation, then one possibility would be and
It is noted that the expected value and the variance of the generalized gamma which is used as the conditional posterior of are, respectively,
E[m|α]=a+Hbα,Var(m|α)=b2(Hα+1),
Therefore, the hyperparameters and are selected so that We choose a value for so that it is close to and then find the corresponding value for This way the Bayes estimates of will be stable with a higher precision. For example, if the selected values are and then one possibility is and In practice, given a sample from the SPP distribution, one does not have information on the "true"values of and If and are selected such that their product is close to the ML estimate of while is small, the Bayes estimates of and would be stable with a small ASE, and as a result the renewal function can be estimated with a higher accuracy.
For example, if the ML estimates are and then we can choose hyperparameters as
c=500,d=.001,P1=10,P2=.5,a=2,b=ˆm−aHα∗=.0525
The same approach is used in Aminzadeh and Deng (2018) and Deng and Aminzadeh (2020) for the selection of hyperparameter values. Using ML estimates through a random sample helps to identify appropriate values for hyperparameters that are consistent with the sample information. Selection of hyperparameters using ML estimates is considered in the simulation studies (see Section 5 for a summary of results) as well as in the numerical example in Section 6.
- The MCMC algorithm in this step is based on the Metropolis algorithm (see Casella and Berger 2004). The idea is to use a proposal distribution that is close enough to a conditional posterior distribution such as (12), which is not a recognizable distribution, and implement the Metropolis algorithm through a very large number of iterations (we used 20,000) so that the Bayes estimates converge.
To get the MCMC-based estimate of the renewal function, for each generated sample from SPP the following steps are taken:
(a) Generate an initial value from gamma and set the first entry of the array The method for choosing the shape parameter and the scale paremeter is outlined in the step 3.
(b) Generate a random observation from the generalized gamma set and let the first entry of the array be where is the number of iterations based on the MCMC method.
(c) For repeat the following steps:
(i) Generate from uniform(0,1).
(ii) Generate from gamma
(iii) Let
(iv) If otherwise set
(v) Generate from the generalized gamma set and
(vi) Let and go to (i).
The first initial = 5,000 estimates of and are discarded as burned-in values, and Bayes estimates of the parameters based on sample are found as
^miB=∑nsj=τ+1m[j]ns−τ, ^αiB=∑nsj=τ+1α[j]ns−τ.
- Given and the code uses (4) and the same process as in step 2 above (except this time Bayes estimates of the parameters and are used in computations) to compute an approximate Bayes estimate of the renewal function. The mean of Bayes estimates for the renewal function and ASE are computed
¯MBayes(t)=∑Ni=1M(i,B)(t)N,ξB(ˆM(t))=∑Ni=1(M(B,i)(t)−M(t))2N
The following tables provide a summary of the simulations. To compare the accuracy of the ML method versus the Bayesian method, the same sample is used to compute both and The line over a parameter estimate such as denotes the average of estimated values in simulations.
Tables 1 and 3 reveal that as sample size increases, the ASE of the ML and Bayes estimates for and decrease. Also, we can see that for a small sample size the Bayes estimator of outperforms the ML, as the ASE of the Bayes estimator is much smaller. Furthermore, for large values of the accuracies of the ML and Bayes estimators are comparable.
For the same generated samples used in Tables 1 and 3, we test the goodness of fit of the generated samples using Mathematica. Four distributions are considered: SPP, gamma, exponential, and inverse Gaussian. Given selected values of parameters 100 samples of size are generated from the SPP, and the averages of the 100 p-values under the null hypotheses that the samples are from those distributions are listed in Tables 2 and 4. Tables 2 and 4 reveal that, in fact, the SPP is an appropriate distribution for the generated samples, as the p-values under the SPP distribution are large.
Table 5 shows a summary of the simulation studies when ML estimates are used to choose hyperparameter values (see step 3 in Section 5). The conclusion is the same as for Tables 1 and 3. That is, the Bayes estimator is more accurate than the ML estimator when the sample size is small. For larger samples, they have a similar precision.
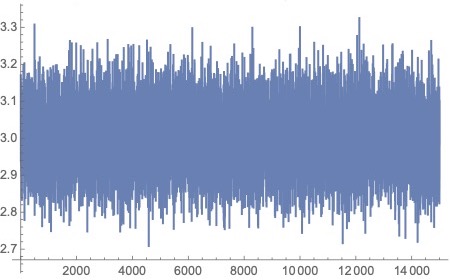
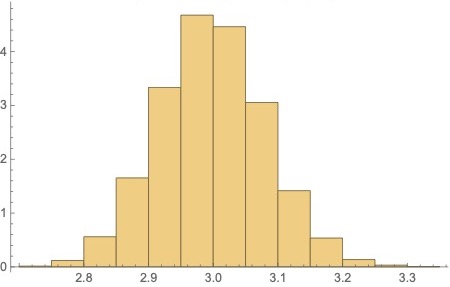
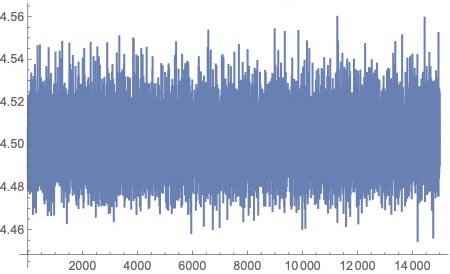
To confirm convergence of MCMC-based estimators for and Figures 1 through 4, which are based on a generated sample of size from the SPP respectively provide an MCMC trace plot for the Bayes estimate of ("true"value 3.0), a histogram for estimated values of an MCMC trace plot for the Bayes estimate of ("true"value 4.5), and a histogram for estimated values of in iterations.

.jpg)

.jpg)
6. Numerical examples
EM-DAT provides worldwide data on dates and impacts of natural events from 1900 to the present. As an illustration of computations, we consider flood and tornado insurance damage in the United States from the year 2000 to the year 2020. The detailed flood and tornado data sets and examples of interarrival calculations are given in the appendix. Interarrivals between two insured damages are defined as the difference between the end date of an occurrence and the start date of the subsequent occurrence. To confirm that, in fact, both data sets fit SPP we use the goodness-of-fit test from Gulati and Shapiro (2008), given below. A review of goodness-of-fit tests for the SPP distribution can be found in Chu, Dickin, and Nadarajah (2019). The data sets are sorted for computational convenience to find the ML estimate of Using notation from Chu, Dickin, and Nadarajah (2019), let
Λ0=Λ21+Λ22
where
Λ1=√12H−1(¯U−.5),Λ2=√54(H+2)(H−1)(H−2)(H−2+6H¯U−12H−1∑i=1iUiH−1),
¯U=H−1∑i=1UiH−1, Y∗i=i∑j=1Yi,Ui=Y∗iY∗n, Yi=(H−i+1)[Xi:H−Xi−1,H],X0:H=0.
Under the null hypothesis the sample is from SPP the test statistic is and is rejected if where is a significance level. The following Mathematica code is used to find the p-value associated with a calculated value of
x: is the list for the sample observations
H is the sample size
Array[Y, H];
Array[U, H];
Array[YS, H];
Y[1] = H*x[[1]];
YS[1] = Y[1];
j = 2;
While[j < H + 1,
Y[j]= (H - j + 1) (x[[j]] - x[[j - 1]]);
YS[j] = Sum[Y[i], {i, 1, j}];
j++;
];
i = 1;
While[i < H + 1,
U[i] = YS[i]/YS[H];
i++;
];
Ubar = Sum[U[i]/(H - 1), {i, 1, H - 1}];
Λ₁ = Sqrt[12/(H - 1)] (Ubar - .5);
Λ₂ = Sqrt[5/(4 (H + 2) (H - 1) (H - 2))]
(H - 2 + 6 HUbar - 12 Sum[(i U[i])/(H - 1),
{i, 1, H - 1}]);
Λ₀ = Λ₁² + Λ₂²
P-value = 1 - CDF[ChiSquareDistribution[2], Λ₀]
Flood data
The following denote values: 1.1, 1.2, 1.266, 2.066, 2.233, 2.433, 3.633, 5.6, 5.766, 6.5, 6.833, 7.5, 7.6, 8.666, 9.4, 10.733, 13.5, 18.9, 22.433, 23.628, 25.1, 30.996.
For the flood data, we get with p-value = .999. Therefore, there is no significant evidence against the SPP distribution. We have As mentioned earlier, we can use ML estimates to choose hyperparameters and We let and and is calculated as Using the above information, the Mathematica code based on provides
\hat{\alpha}_B=.99054, \ \ \hat{m}_B=1.490,\ \ \hat{M}_B(30)=7.28, \ \ \hat{M}_{ML}(30)=9.16.
Table 6 lists the p-values for goodness of fit of the flood data under four null hypotheses that data are from the four distributions (SPP, gamma, exponential, and inverse Gaussian). We can see that there is no strong evidence against SPP and exponential; however, the p-value for SPP is the largest among the four p-values.
Tornado data
The following denote values:
0.033, .1, 0.133, 0.166, 0.266, 0.3, 0.333, 0.366, 0.4, 0.4, 0.466, 0.566, 0.633, 0.766, 0.833, 0.9, 0.966, 1, 1.0333, 1.133, 1.2333, 1.266, 1.3, 1.466, 1.866, 2.066, 3.533, 4.233, 4.266, 5.133, 5.266, 5.333, 6.066, 7.366, 7.7, 8.066, 8.466, 8.466, 8.533, 8.9, 8.9, 9.533, 9.8, 10.8, 10.933, 13.066, 14.1, 16.23, 16.566, 24.133
For the tornado data, we get with p-value = .9989. Therefore, there is no significant evidence against the SPP distribution. We have and As mentioned earlier, we can use ML estimates to choose the hyperparameters and We let and and is calculated as Using the above information, the Mathematica code based on provides
\begin{align} \hat{\alpha}_B=0.874733&, \ \ \hat{m}_B=0.0410618,\\ \hat{M}_B(20)=54.1&, \ \ \hat{M}_{ML}(20)=55.6 \end{align}
Table 7 lists the p-values for goodness of fit of the tornado data under four null hypotheses that data are from the four distributions (SPP, gamma, exponential, and inverse Gaussian). We can see that there is no strong evidence against the SPP distribution, as the p-values for the other three distributions are very small.
It is noted that estimates for the tornado data are larger than for the flood data. This is because the average interarrival for the flood data is 9.36 and for the tornado data, 4.90. Therefore, for a specified the number of floods by time would be smaller than the number of tornados.
We also note that for both of the above data sets, the ML and Bayes estimates for are less than 1. For computation of estimates of as outlined in Section 2 using Ramsay (2006), we need to be a positive integer. Therefore, in the Mathematica code both estimates are rounded up to 1 to obtain estimates for the renewal function. It is also noted that the expected value and the variance of the SPP random variable are defined, respectively, if and Hence, even though the first and the second moments are not defined when the delta moment for SPP is defined as
E[X^\delta]=\frac{\alpha m^\delta}{\alpha-\delta}, \hskip .1in 0 < \delta < \alpha.
A generated sample from SPP
The following data are generated from the SPP distribution using the built-in program in Mathematica, and the following denote values:
4.53749, 4.62575, 4.63825, 4.72415, 4.84672, 4.8955, 5.15921, 5.23818, 5.248, 5.39497, 5.54926, 5.62348, 5.69356, 5.72578, 5.87845, 6.42667, 6.51168, 8.86315, 9.56578, 16.6426.
For the above sample, we get with p-value = .952. Therefore, as expected, the interarrivals have an SPP distribution. The p-values for goodness of fit of gamma, exponential, and inverse Gaussian, respectively, are .0003, 3.8x and .006.
and Based on ML estimates, we choose appropriate values for the hyperparameters, as follows:
\begin{align} a&=4.4, b=\frac{\ \hat{m}_{Ml}-a}{H \hat{\alpha}_{Ml}}=.00184, c=400, \\ d&=.01,, P_1=1,000, P_2=.004. \end{align}
Based on the above information, the Mathematica code computes the ML- and MCMC-based estimates for the renewal function at times and as
\begin{align} \hat{M}_B(30)=20.75, \ \ \hat{M}_{ML}(30)=20.70, \\ \hat{M}_B(50)=30.14, \ \ \hat{M}_{ML}(50)=30.11. \end{align}
Table 9 shows data extracted from FEMA.gov (https://www.fema.gov/openfema-data-page/fima-nfip-redacted-claims-v1) for hurricanes hitting New Orleans from September 29, 2021, through January 18, 2022. Table 10 shows the p-values for goodness of fit of the SPP, gamma, exponential, and inverse Gaussian distributions for the third column, interarrivals (days).
Table 10 reveals that whereas all four distributions can be used for the data, the p-value for the SPP distribution is the largest.
7. Summary
SPP distribution is considered as an inter-arrival distribution of a renewal process. Computational formulas from Ramsay (2006), for the sum of iid random variables from the SPP distribution, are used to provide ML- and MCMC-based Bayes estimates for the renewal function. The Bayes estimates of parameters are based on shifted exponential and gamma priors. Two conditional posterior distributions and are derived. Since is not a recognized PDF, an MCMC method based on the Metropolis algorithm is employed. The parameter estimates are then used to compute the ML estimate and an approximate Bayes estimate for the renewal function. Simulation studies confirm that if selected values for hyperparameters of the prior distributions of and are consistent with selected "true"values of and in simulations, then the Bayes estimator for the renewal function would have a much smaller ASE and it outperforms the MLE with regard to accuracy for small samples. Also, for large samples, simulations confirm that the accuracies of the ML and Bayes estimators are comparable. In practice, only one sample is available from the SPP distribution, and choosing hyperparameters that are consistent with the ML estimates of and as outlined in Section 5, would provide more stable Bayes estimates for the renewal function, as demonstrated in Table 5. For illustration purposes of the computations, three data sets are considered: two data sets from EM-DAT and one data set from FEMA.gov for hurricanes hitting New Orleans.