
1. Introduction
Parametric statistical models for insurance claims severity are continuous, right-skewed, and frequently heavy-tailed (see Klugman, Panjer, and Willmot 2012). The data sets to which such models are usually fitted contain outliers that are difficult to identify and separate from genuine data. Moreover, due to commonly used loss mitigation techniques, the random variables we observe and wish to model are affected by data truncation (due to deductibles), censoring (due to policy limits), and scaling (due to coinsurance). In the current practice, statistical inference for loss models is ablmost exclusively maximum likelihood estimation (MLE)–based, which typically results in nonrobust parameter estimators, pricing models, and risk measurements.
Construction of robust actuarial models includes many ideas from the mainstream robust statistics literature (see, e.g., Huber and Ronchetti 2009), but there are additional nuances that need to be addressed. Namely, actuaries have to deal with heavy-tailed and skewed distributions, data truncation and censoring, identification and recycling of outliers, and aggregate loss, just to name a few. The actuarial literature is home to a number of specialized studies addressing some of these issues; see, e.g., Künsch (1992), Gisler and Reinhard (1993), Brazauskas and Serfling (2003), Garrido and Pitselis (2000), Marceau and Rioux (2001), Serfling (2002), and Dornheim and Brazauskas (2007). Further, those and other actuarial studies motivated the development of two broad classes of robust estimators—the methods of trimmed moments (see, e.g., Brazauskas 2009; Brazauskas, Jones, and Zitikis 2009) and winsorized moments (see, e.g., Zhao, Brazauskas, and Ghorai 2018a, 2018b). Those two approaches, called - and -estimators for short, are sufficiently general and flexible for fitting continuous parametric models based on completely observed ground-up loss data. In Figure 1.1, we illustrate how and methods act on data and control the influence of extremes. First of all, notice that typical loss mitigation techniques employed in insurance practice (e.g., deductibles and policy limits) are closely related to data winsorizing or its variants. Second, we see that in order to taper the effects of rare but high severity claims on parameter estimates, data should be “preprocessed” using trimming or winsorizing. Thenceforth, and estimates can be found by applying the classical method of moments. Note that these initial modifications of data have to be taken into account when deriving corresponding theoretical moments. This yields an additional benefit. Specifically, unlike the parameter estimatbors based on the standard method of moments, which may not exist for heavy-tailed models (due to the nonexistence of finite moments), theoretical and moments are always finite. Finally, for trimmed or winsorized data, estimation of parameters via the method of moments is not the only option. Indeed, one might choose to apply another estimation procedure (e.g., properly constructed MLE) and gain similar robustness properties. In this paper, however, we focus on rigorous treatment of moment-type estimators.

-estimators have been discussed in the operational risk literature by Opdyke and Cavallo (2012), used in credibility studies by Kim and Jeon (2013), and further tested in risk measurement exercises by Abu Bakar and Nadarajah (2018). Also, the idea of trimming has been gaining popularity in modeling extremes (see Bhattacharya, Kallitsis, and Stoev 2019; Bladt, Albrecher, and Beirlant 2020). Thus we anticipate the methodology developed in this paper will be useful and transferable to all these and other areas of research.
Moreover, besides the typical nonrobustness of MLE-based inference, the implementation of such procedures on real data is also technically challenging (see discussions by Frees 2017; Lee 2017). This issue is especially evident when one tries to fit complicated multiparameter models such as finite mixtures of distributions (see Verbelen et al. 2015; Miljkovic and Grün 2016; Reynkens et al. 2017). Thus, the primary objective of this paper is to go beyond the complete data scenario and develop - and -estimators for insurance data affected by the above-mentioned transformations. We show that, when properly redesigned, - and -estimators can be a robust and computationally efficient alternative to MLE-based inference for claim severity models that are affected by deductibles, policy limits, and coinsurance. In particular, we provide the definitions of - and -estimators and derive their asymptotic properties such as normality and consistency. Specific formulas or estimating equations for a single-parameter Pareto (Pareto I) model are provided. Finally, we illustrate the practical performance of the estimators by fitting Pareto I to the well-known Norwegian fire claims data. We use MLE and several - and -estimators, validate the fits, and apply the fitted models to price an insurance contract.
The remainder of the paper is organized as follows. In Section 2, we describe a series of loss variable (data) transformations, starting with complete data, continuing with truncated and censored data, and finishing with two types of insurance payments. Section 3 uses the data scenarios and models of the previous section and derives - and -estimators for the parameters of those models. Then asymptotic properties of those estimators are established. In Section 4, we develop specific formulas of the estimators when the underlying loss distribution is Pareto I, and we compare the asymptotic relative efficiency of - and -estimators with respect to MLE. Section 5 is devoted to practical applications of the Pareto I model; the effects of model fitting on insurance contract pricing are then investigated. Finally, concluding remarks are offered in Section 6.
2. Data and models
In this section, we review typical transformations of continuous random variables that one might encounter in modeling claim severity. For each type of variable transformation, the resulting probability density function (PDF), cumulative distribution function (CDF), and quantile function (QF) are specified.
2.1. Complete data
Let us start with the complete data scenario. Suppose the observable random variables X1,X2,…,Xn are independent and identically distributed (i.i.d.) and have the PDF CDF and QF Because loss random variables are nonnegative, the support of is the set
The complete data scenario is not common when claim severities are recorded, but it represents what are known as “ground-up” losses and thus is important to consider. Statistical properties of the ground-up variable are of great interest in risk analysis, in product design (for specifying insurance contract parameters), in risk transfer considerations, and for other business decisions.
2.2. Truncated data
Data truncation occurs when sample observations are restricted to some interval (not necessarily finite), say with Measurements and even a count of observations outside the interval are completely unknown. To formalize this discussion, we will say that we observe the i.i.d. data X∗1,X∗2,…,X∗n, where each is equal to the ground-up loss variable if falls between and and is undefined otherwise. That is, satisfies the following conditional event relationship: X∗d=X|t1<X<t2, where denotes “equal in distribution.” Due to that relationship, the CDF PDF and QF of variables are related to and (see Section 2.1) and are given by
F∗(x;t1,t2)=P[X≤x|t1<X<t2]={0,x≤t1;F(x)−F(t1)F(t2)−F(t1),t1<x<t2;1,x≥t2,
f∗(x;t1,t2)=ddx[F∗(x;t1,t2)]={f(x)F(t2)−F(t1),t1<x<t2;undefined,x=t1, x=t2;0,elsewhere,
F−1∗(v;t1,t2)=F−1(vF(t2)+(1−v)F(t1)),for 0≤v≤1.
In industrywide databases such as ORX Loss Data (managingrisktogether.orx.org), only losses above some prespecified threshold, say are collected, which results in left-truncated data at Thus, the observations available to the end user can be viewed as a realization of random variables (2.2) with and The latter condition slightly simplifies formulas (2.3)–(2.5); one just needs to replace with 1.
2.3. Censored data
Several versions of data censoring occur in statistical modeling: interval censoring (includes left and right censoring depending on which endpoint of the interval is infinite), type I censoring, type II censoring, and random censoring. For actuarial work, the most relevant type is interval censoring. It occurs when complete observations are available within some interval, say with but data outside the interval are only partially known. That is, counts are available but actual values are not. To formalize this discussion, we will say that we observe the i.i.d. data X∗∗1,X∗∗2,…,X∗∗n, where each is equal to the ground-up variable if falls between and and is equal to the corresponding endpoint of the interval if is beyond that point. That is, is given by X∗∗=min{max(t1,X),t2}={t1,X≤t1;X,t1<X<t2;t2,X≥t2.
Due to this relationship, the CDF PDF and QF of variables are related to and and have the following expressions:
F∗∗(x;t1,t2)=P[min{max(t1,X),t2}≤x]=P[X≤x]1{t1≤x<t2}+1{t2≤x}={0,x<t1;F(x),t1≤x<t2;1,x≥t2,
where denotes the indicator function. Further,
F−1∗∗(v;t1,t2)={t1,v<F(t1);F−1(v),F(t1)≤v<F(t2);t2,v≥F(t2).
Note that CDF (2.7) is a mixture of continuous CDF and discrete probability mass at (with probability and (with probability This results in a mixed PDF/probability mass function:
f∗∗(x;t1,t2)={F(t1),x=t1;f(x),t1<x<t2;1−F(t−2),x=t2;0,elsewhere.
2.4. Insurance payments
Insurance contracts have coverage modifications that need to be taken into account when modeling the underlying loss variable. Usually coverage modifications such as deductibles, policy limits, and coinsurance are introduced as loss control mechanisms so that unfavorable policyholder behavioral effects (e.g., adverse selection) can be minimized. There are also situations when certain features of the contract emerge naturally (e.g., the value of insured property in general insurance is a natural upper policy limit). Here we describe two common transformations of the loss variable along with the corresponding CDFs, PDFs, and QFs.
Suppose the insurance contract has ordinary deductible upper policy limit and coinsurance rate These coverage parameters imply that when a loss is reported, the insurance company is responsible for a proportion of exceeding but no more than
Next, if the loss severity below the deductible is completely unobservable (even its frequency is unknown), then the observed i.i.d. insurance payments can be viewed as realizations of left-truncated, right-censored, and linearly transformed (called the payment-per-payment variable):
Y d= c(min{X,u}−d)|X>d = {undefined,X≤d;c(X−d),d<X<u;c(u−d),u≤X.
We can see that the payment variable is a linear transformation of a composition of variables and (see Sections 2.2 and 2.3). Thus, similar to variables and its CDF PDF and QF are also related to and and are given by
GY(y;c,d,u)=P[c(min{X,u}−d)≤y|X>d]={0,y≤0;F(y/c+d)−F(d)1−F(d),0<y<c(u−d);1,y≥c(u−d),
gY(y;c,d,u)={f(y/c+d)c[1−F(d)],0<y<c(u−d);1−F(u−)1−F(d),y=c(u−d);0,elsewhere,
and
G−1Y(v;c,d,u)={c[F−1(v+(1−v)F(d))−d],0≤v<F(u)−F(d)1−F(d);c(u−d),F(u)−F(d)1−F(d)≤v≤1.
The scenario that no information is available about below is likely to occur when modeling is performed based on the data acquired from a third party (e.g., a data vendor). For payment data collected in-house, the information about the number of policies that did not report claims (equivalently, resulted in a payment of 0) would be available. This minor modification yields different payment variables, say which can be treated as i.i.d. realizations of interval-censored and linearly transformed (called the payment-per-loss variable):
Z=c(min{X,u}−min{X,d})={0,X≤d;c(X−d),d<X<u;c(u−d),u≤X.
Again, its CDF PDF and QF are related to and and given by
GZ(z;c,d,u)=P[c(min{X,u}−min{X,d})≤z]={0,z<0;F(z/c+d),0≤z<c(u−d);1,z≥c(u−d),
gZ(z;c,d,u)={F(d),z=0;f(z/c+d)/c,0<z<c(u−d);1−F(u−),z=c(u−d);0,elsewhere,
and
G−1Z(v;c,d,u)={0,0≤v≤F(d);c(F−1(v)−d),F(d)<v<F(u);c(u−d),F(u)≤v≤1.
3. - and -estimation
In this section, we first provide definitions of parameter estimators obtained by using the method of trimmed moments (MTM) -estimators; Section 3.1) and the method of winsorized moments (MWM) -estimators; Section 3.2) under the data scenarios of Sections 2.1–2.4. Then, in Section 3.3, we specify the asymptotic distribution of the resulting estimators. Also, throughout the section we assume that the ground-up losses follow a continuous parametric distribution with PDF and CDF that are indexed by unknown parameters The goal is to estimate those parameters using - and -estimators by taking into account the probabilistic relationships between the CDF and the distribution function of observed data.
3.1. -estimators
-estimators are derived by following the standard method-of-moments approach, but instead of standard moments we match sample and population trimmed moments (or their variants). The advantage of such an approach over the standard one is that the population moments always exist irrespective of the tail-heaviness of the underlying distribution. The following definition lists the formulas of sample and population moments for the data scenarios of Sections 2.1–2.4.
Definition 3.1. For data scenarios and models of Sections 2.1–2.4, let us denote the sample and population moments as and respectively. If is an ordered realization of variables (2.1), (2.2), (2.6), (2.10), or (2.14) with QF denoted (which depending upon the data scenario equals to QF (2.5), (2.8), (2.13), or (2.17), then the sample and population moments, with the trimming proportions (lower) and (upper), have the following expressions:
ˆTj=1n−mn−m∗nn−m∗n∑i=mn+1[h(wi:n)]j,j=1,…,k,
\begin{aligned} T_j(\mathbf{\theta}) & = \frac{1}{1-a-b} \int_{a}^{1-b} \big[ h (F_V^{-1}(v \, | \, \mathbf{\theta})) \big]^j \, dv, \\ j & = 1, \ldots, k. \end{aligned}\tag{3.2}
Under all the data scenarios, the trimming proportions and and function are chosen by the researcher. Also, integers and are such that and when In finite samples, the integers and are computed as and where denotes the greatest integer part.
Note 3.1. In the original formulation of MTM estimators for complete data (Brazauskas, Jones, and Zitikis 2009), the trimming proportions and and function were allowed to vary for different which makes the technique more flexible. On the other hand, for implementation of MTM estimators in practice, such flexibility requires one to make more decisions regarding the and interaction with each other and for different The follow-up research that used MTMs usually had not varied these constants and functions, which seems like a reasonable choice. Therefore, in this paper we choose to work with non-varying and for all
Note 3.2. For incomplete data scenarios, possible permutations between and have to be taken into account. For truncated data, there is only one possibility: For censored data, however, it is possible to use part or all of the censored data in estimation. Thus, we can have six arrangements:
Among these, the sixth case makes the most sense because it uses the available data in the most effective way. For the sake of completeness, however, we will investigate the other cases as well (see Section 4). Note that the insurance payments and are special (mixed) cases of truncated and censored data and thus will possess similar properties. Moreover, the -estimators based on case 6 will be resistant to outliers, i.e., observations that are inconsistent with the assumed model and most likely appearing at the boundaries and
Note 3.3. In view of Notes 3.1 and 3.2, the -estimators with and are globally robust with the lower and upper breakdown points given by and respectively. The robustness of such estimators against small or large outliers comes from the fact that in the computation of estimates the influence of the order statistics with the index less than or greater than is limited. For more details on and see Brazauskas and Serfling (2000) and Serfling (2002).
3.2. -estimators
-estimators are derived by following the standard method-of-moments approach, but instead of standard moments we match sample and population winsorized moments (or their variants). Similar to -estimators, the population moments also always exist. The following definition lists the formulas of sample and population moments for the data scenarios of Sections 2.1–2.4.
Definition 3.2. For data scenarios and models of Sections 2.1–2.4, let us denote the sample and population moments as and respectively. If is an ordered realization of variables (2.1), (2.2), (2.6), (2.10), or (2.14) with QF denoted (which depending upon the data scenario equals to QF (2.5), (2.8), (2.13), or (2.17), then the sample and population moments, with the winsorizing proportions (lower) and (upper), have the following expressions:
\begin{aligned}\widehat{W}_j = &\frac{1}{n}\Biggl\lbrack m_n\left[h\left(w_{m_n+1: n}\right)\right]^j \\ &+\sum_{i=m_n+1}^{n-m_n^*}\left[h\left(w_{i: n}\right)\right]^j \\ &+m_n^*\left[h\left(w_{n-m_n^*: n}\right)\right]^j\Biggr\rbrack,\end{aligned}\tag{3.3}
\begin{aligned}W_j(\mathbf{\theta}) =&\ a\left[h\left(F_V^{-1}(a \mid \mathbf{\theta})\right)\right]^j \\&+\int_a^{1-b}\left[h\left(F_V^{-1}(v \mid \mathbf{\theta})\right)\right]^j d v \\& +b\left[h\left(F_V^{-1}(1-b \mid \mathbf{\theta})\right)\right]^j\end{aligned}\tag{3.4}
where the winsorizing proportions and and function are chosen by the researcher, and the integers and are defined and computed the same way as in Definition 3.1.
Note 3.4. In the original formulation of MWM estimators for complete data, Zhao, Brazauskas, and Ghorai (2018a), the winsorizing proportions and and function were allowed to vary for different Based on arguments similar to those made in Note 3.1, in this paper we will choose the same and for all Further, the focus will be on the case when and fall within the interval : Finally, the breakdown points of -estimators are identical to those of -estimators, i.e., and
3.3. Asymptotic properties
In this section, we specify the asymptotically normal distributions for the - and -estimators of Sections 3.1–3.2. It follows immediately from the parametric structure of those asymptotic distributions that all the estimators under consideration are consistent. Throughout the section the notation is used to denote “asymptotically normal.”
3.3.1. T-estimators
-estimators are found by matching sample moments (3.1) with population moments (3.2) for and then solving the system of equations with respect to The obtained solutions, which we denote by are, by definition, the -estimators of Note that the functions are such that
The asymptotic distribution of these estimators for complete data has been derived by Brazauskas, Jones, and Zitikis (2009). It also follows from a more general theorem established by Zhao et al. (2018a, Note 2.4), which relies on the central limit theory of -statistics (Chernoff, Gastwirth, and Johns 1967). The following theorem generalizes those results to all data scenarios of Sections 2.1–2.4.
Theorem 3.1. Suppose an i.i.d. realization of variables (2.1), (2.2), (2.6), (2.10), or (2.14) has been generated by CDF which depending upon the data scenario equals to CDF (2.3), (2.7), (2.11), or (2.15), respectively. Let denote a -estimator of Then
\widehat{\mathbf{\theta}}_{\small\text{T}} = \left( \widehat{\theta}_1, \ldots, \widehat{\theta}_k \right) ~~is~~ {\cal{AN}} \left( \big( \theta_1, \ldots, \theta_k \big), \, \frac{1}{n} \, \mathbf{D}_t \mathbf{\Sigma}_t \mathbf{D}_t' \right),
where
is the Jacobian of the transformations evaluated at and is the covariance-variance matrix with the entries
\begin{aligned}\sigma^2_{ij} = \ & \frac{1}{(1-a-b)(1-a-b)} \\ &\cdot \int_{a}^{1-b} \int_{a}^{1-b} \bigg\{\big( \min \{ v, w \} - v w \big) \; \mbox{d} \left[ h \big( F_V^{-1}(v) \big) \right]^j \, \\ &\hspace{45mm}\cdot \ \mbox{d} \left[ h \big( F_V^{-1}(w) \big) \right]^i\bigg\}.\end{aligned}
Proof. For complete data, generated by (2.1) and with the assumption that is continuous, see Brazauskas, Jones, and Zitikis (2009) or Zhao et al. (2018a, Note 2.4).
For truncated data, generated by (2.2), the CDF given by (2.3) is still continuous and hence the results established for complete data can be directly applied to
For the remaining data scenarios, generated by (2.6), (2.10), or (2.14), the QF is not smooth and the functions have points of non-differentiability (see Lemma A.1 in Zhao, Brazauskas, and Ghorai 2018a). The set of such points, however, has probability zero, which means that the CDFs and are almost everywhere continuous under the Borel probability measures induced by and (see, e.g., Folland 1999, Theorem 1.16). Therefore, shall be replaced with whenever it is not defined; see Chernoff et al. (1967, Assumption A*).
Note 3.5. Theorem 3.1 states that -estimators for the parameters of loss models considered in this paper are asymptotically unbiased with the entries of the covariance-variance matrix diminishing at the rate Using these properties in conjunction with the multidimensional Chebyshev’s inequality it is a straightforward exercise to establish the fact that -estimators are consistent.
3.3.2. W-estimators
-estimators are found by matching sample moments (3.3) with population moments (3.4) for and then solving the system of equations with respect to The obtained solutions, which we denote by are, by definition, the -estimators of Note that the functions are such that
The asymptotic distribution of these estimators for complete data has been established by Zhao et al. (2018a, Theorem 2.1 and Lemma A.1). The following theorem summarizes the asymptotic distribution of -estimators to all data scenarios of Section 2.
Theorem 3.2. Suppose an i.i.d. realization of variables (2.1), (2.2), (2.6), (2.10), or (2.14) has been generated by CDF which depending upon the data scenario equals to CDF (2.3), (2.7), (2.11), or (2.15), respectively. Let denote a -estimator of Then \widehat{\mathbf{\theta}}_{\small\text{W}} = \left( \widehat{\theta}_1, \ldots, \widehat{\theta}_k \right) ~~is~~ {\cal{AN}} \left( \big( \theta_1, \ldots, \theta_k \big), \, \frac{1}{n} \, \mathbf{D}_w \mathbf{\Sigma}_w \mathbf{D}_w' \right), where is the Jacobian of the transformations evaluated at and is the covariance-variance matrix with the entries \sigma^2_{ij} = \widehat{A}_{i,j}^{(1)} + \widehat{A}_{i,j}^{(2)} + \widehat{A}_{i,j}^{(3)} + \widehat{A}_{i,j}^{(4)}, where the terms are specified in Zhao et al. (2018a, Lemma A.1).
Proof. The proof can be established by following the same arguments as in Theorem 3.1.
Note 3.6. Similar to the discussion of Note 3.5, the asymptotic normality statement of this theorem implies that -estimators are consistent.
4. Analytic examples: Pareto I
In this section, we first derive the MLE and - and -estimators for the tail parameter of a single-parameter Pareto distribution, abbreviated as Pareto I, when the observed data are in the form of either insurance payments defined by (2.10), or defined by (2.14). The corresponding MLE and -estimators for lognormal distribution have recently been investigated by Poudyal (2021a). Note that Pareto I is the distribution of the ground-up variable The CDF, PDF, and QF of Pareto I are defined as follows:
\begin{aligned}
\small\text{CDF:} \qquad
F(x) & = 1 - (x_0/x)^{\alpha}, \qquad x > x_0,
\end{aligned}\tag{4.1}
\begin{aligned}\small\text{PDF:} \qquad
f(x) & = (\alpha/x_0) (x_0/x)^{\alpha + 1}, \qquad x > x_0,
\end{aligned}\tag{4.2}
\begin{aligned}
\small\text{ QF:} \quad ~
F^{-1}(v) & = x_0 (1-v)^{-1/\alpha}, \qquad 0 \leq v \leq 1,
\end{aligned}\tag{4.3}
where is the shape (tail) parameter and is a known constant.
Then, the definitions of the estimators are complemented with their asymptotic distributions. Using the asymptotic normality results, we evaluate the asymptotic relative efficiency (ARE) of the - and -estimators with respect to the MLE: \mbox{ARE$\big($Q, MLE$\big)$} ~=~ \frac{\mbox{asymptotic variance of MLE estimator}} {\mbox{asymptotic variance of Q estimator}} \, , where Q represents the - or -estimator. Since for Pareto I the asymptotic variance of MLE reaches the Cramér-Rao lower bound, the other estimators’ efficiency will be between 0 and 1. Estimators with AREs close to 1 are preferred.
Also, for the complete data scenario, formulas of and are available in Brazauskas, Jones, and Zitikis (2009). Derivations for the other data scenarios of Section 2 (truncated and censored data) are analogous to the ones presented in this section and thus will be skipped.
4.1. MLE
4.1.1. Payments Y
If is a realization of variables (2.10) with PDF (2.12) and CDF (2.11), where and are given by (4.1) and (4.2), respectively, then the log-likelihood function can be specified by following standard results presented in Klugman et al. (2012, Chapter 11):
\begin{aligned} {\cal{L}}_{P_Y} & \big( \alpha \, \big| \, y_1, \ldots, y_n \big) \\ = & \sum_{i=1}^n \log \big[ f(y_i/c+d) / c \big] \large\mathbf{1}\normalsize \{ 0 < y_i < c(u-d) \} \\& -~ n \log \big[ 1 - F(d) \big] \\&~+~ \log \big[ 1 - F(u^-) \big] \sum_{i=1}^n \large\mathbf{1}\normalsize \{ y_i = c(u-d) \} \\ = & \sum_{i=1}^n \Biggl\{ \left[ \log \left( \frac{\alpha}{c x_0} \right) - (\alpha+1) \log \left( \frac{y_i/c+d}{x_0} \right) \right] \\ &\hspace{15mm}\cdot \large\mathbf{1}\normalsize \{ 0 < y_i < c(u-d) \} \Biggr\} \\&-~ \alpha n \log (x_0/d) ~+~ \alpha \log (x_0/u) \sum_{i=1}^n \large\mathbf{1}\normalsize \{ y_i = c(u-d) \},\end{aligned}
where denotes the indicator function. Straightforward maximization of yields an explicit formula of the MLE of :
\begin{align} \widehat{\alpha}_{\small\text{MLE}} = \,& \Biggl\lbrack\sum_{i=1}^n \large\mathbf{1}\normalsize \{ 0 < y_i < c(u-d) \}\Biggr\rbrack \\ &\div \Biggl\lbrack\sum_{i=1}^n \log \left( \frac{y_i}{cd} + 1 \right) \\ &\hspace{20mm} \cdot \large\mathbf{1}\normalsize \{ 0 < y_i < c(u-d) \} \\ &\hspace{10mm}+ \log \left(\frac{u}{d}\right) \sum_{i=1}^n \large\mathbf{1}\normalsize \{ y_i = c(u-d) \}\Biggr\rbrack. \end{align} \tag{4.4}
The asymptotic distribution of follows from standard results for MLEs (see, e.g., Serfling 1980, Section 4.2). In this case, the Fisher information matrix has a single entry:
\begin{aligned}I_{11} & ~=~ - \mathbf{E} \left[ \frac{\partial^2 \log g_Y(Y \, | \, \alpha)}{\partial \alpha^2} \right] \\& ~=~ - \mathbf{E} \left[ - \frac{1}{\alpha^2} \large\mathbf{1}\normalsize \{ 0 < Y < c(u-d) \} \right] \\& ~=~ \frac{1}{\alpha^2} \big[ 1 - ( d/u )^{\alpha} \big].\end{aligned}
Hence, the estimator defined by (4.4), has the following asymptotic distribution:
\widehat{\alpha}_{\small\text{MLE}} ~~is~~ {\cal{AN}} \left( \alpha, \, \frac{1}{n} \, \frac{\alpha^2}{1 - ( d/u )^{\alpha}} \right). \tag{4.5}
A few observations can be made from this result. First, the coinsurance factor has no effect on (4.5). Second, the corresponding result for the complete data scenario is obtained when there is no deductible (i.e., and no policy limit (i.e., Third, if then the asymptotic properties of remain equivalent to those of the complete data case irrespective of the choice of Also, notice that (4.4) implies that is a consistent and efficient estimator.
4.1.2. Payments Z
If is a realization of variables (2.14) with PDF (2.16) and CDF (2.15), where and are given by (4.1) and (4.2), respectively, then the log-likelihood function can be specified by following standard results presented in Klugman et al. (2012, Chapter 11):
\begin{aligned} {\cal{L}}_{P_Z}& \big( \alpha \, \big| \, z_1, \ldots, z_n \big) \\ =&\ \log \big[ F(d) \big] \sum_{i=1}^n \large\mathbf{1}\normalsize \{ z_i = 0 \} \\&~+~ \log \big[ 1 - F(u^-) \big] \sum_{i=1}^n \large\mathbf{1}\normalsize \{ z_i = c(u-d) \} \nonumber \\&+ \sum_{i=1}^n \log \big[ f(z_i /c + d) / c \big] \\ &\hspace{20mm}\cdot\large\mathbf{1}\normalsize \{ 0 < z_i < c(u-d) \} \nonumber \\ =&\ \log \big[ 1 - (x_0/d)^{\alpha} \big] \sum_{i=1}^n \large\mathbf{1}\normalsize \{ z_i = 0 \} \\&+ \alpha \log (x_0/u) \sum_{i=1}^n \large\mathbf{1}\normalsize \{ z_i = c(u-d) \} \nonumber \\ &+ \sum_{i=1}^n \Biggl[ \log \left( \frac{\alpha}{cx_0} \right) \\ &\hspace{20mm}- (\alpha+1) \log \left( \frac{\frac{z_i}{c}+d}{x_0} \right) \Biggr] \\ &\hspace{15mm}\cdot\large\mathbf{1}\normalsize \{ 0 < z_i < c(u-d) \}.~ \end{aligned}\tag{4.6}
It is clear from the expression of that it has to be maximized numerically. Suppose that a unique solution for the maximization of (4.6) with respect to is found, and let us denote it
Further, the asymptotic distribution of follows from standard results for MLEs (see, e.g., Serfling 1980, Section 4.2). In this case, the single entry of the Fisher information matrix is
\begin{aligned} I_{11} &=-\mathbf{E}\left[\frac{\partial^2 \log g_Z(Z \mid \alpha)}{\partial \alpha^2}\right] \\&= -\mathbf{E}\Biggl\lbrack-\frac{\left(x_0 / d\right)^\alpha \log ^2\left(x_0 / d\right)}{\left(1-\left(x_0 / d\right)^\alpha\right)^2} \mathbf{1}\{Z=0\} \\ &\hspace{20mm}-\frac{1}{\alpha^2} \mathbf{1}\{ 0 < Z < c(u-d)\}\Biggr\rbrack \\&=\alpha^{-2}\Biggl\lbrack\frac{\left(x_0 / d\right)^\alpha}{1-\left(x_0 / d\right)^\alpha} \log ^2\left[\left(x_0 / d\right)^\alpha\right] \\ &\hspace{20mm}+\left(x_0 / d\right)^\alpha-\left(x_0 / u\right)^\alpha\Biggr\rbrack.\end{aligned}
Hence, the estimator found by numerically maximizing (4.6), has the following asymptotic distribution:
\begin{align} \widehat{\widehat{\alpha}}_{\small\text{MLE}} \ is\hspace{30mm}& \\ {\cal{AN}} \Bigg( \alpha, \, \frac{\alpha^2}{n} \, \bigg[ \frac{(x_0/d)^{\alpha}}{1-(x_0/d)^{\alpha}} \log^2 \big[ (x_0/d)^{\alpha} \big]& \\ + (x_0/d)^{\alpha} - (x_0/u)^{\alpha} \bigg]^{-1} \Bigg).& \end{align} \tag{4.7}
Here, we again emphasize several points. First, as in Section 4.1.1, the coinsurance factor has no effect on (4.7). Second, the corresponding result for the complete data scenario is obtained when there is no deductible (to eliminate from (4.7), take the limit as and no policy limit (i.e., Third, (4.7) implies that is a consistent and efficient estimator.
4.2. -estimators
4.2.1. Payments Y
Let denote an ordered realization of variables (2.10) with QF (2.13), where and are given by (4.1) and (4.3), respectively. Since Pareto I has only one unknown parameter, we need only one moment equation to estimate it. Also, since payments are left-truncated and right-censored, it follows from Note 3.2 that only the last three permutations between the trimming proportions and are possible (i.e., cannot be less than That is, after converting and into the notation involving and we get from (3.2) the following arrangements:
Case 1: (estimation based on censored data only).
Case 2: (estimation based on observed and censored data).
Case 3: (estimation based on observed data only).
In all these cases, the sample moments (3.1) can be easily computed by first estimating the probability as then selecting and finally choosing Note that and are known constants, and the logarithmic transformation will linearize the QF in terms of (at least for the observed data part). With these choices in mind, let us examine what happens to the population moments (3.2) under the cases 1–3. The following steps can be easily verified:
\begin{aligned} (1-a-b) \, & T_{1(y)} (\alpha) = \int_a^{1-b} h_Y \left( G_Y^{-1} (v \, | \, \alpha) \right) \, dv \\~=~&\ \int_a^{1-b} \log \left( \frac{G_Y^{-1} (v \, | \, \alpha)}{cd} + 1 \right) \, dv \\= & \int_a^{1-b} \Bigg[ \log \left( \frac{1}{d} \, F^{-1} \Big( v + (1-v) F(d) \Big) \right)\\ \cdot&\ \large\mathbf{1}\normalsize \left\{ 0 \leq v < \frac{F(u)-F(d)}{1-F(d)} \right\} \\ & ~+~ \log \left( u/d \right) \large\mathbf{1}\normalsize \left\{ \frac{F(u)-F(d)}{1-F(d)} \leq v \leq 1 \right\} \Bigg] \, dv \\= & \left\{ \begin{array}{cl} (1-a-b) \log (u/d),\\ \mbox{Case 1}; \\ \alpha^{-1} \Big[ (1-a) \big( 1 - \log (1-a) \big) + b \log \left( d/u \right)^{\alpha} - \left( d/u \right)^{\alpha} \Big],\\ \mbox{Case 2}; \\ \alpha^{-1} \Big[ (1-a) \big( 1 - \log (1-a) \big) - b \big( 1 - \log b \big) \Big],\\ \mbox{Case 3}. \\ \end{array} \right.\end{aligned}
It is clear from these expressions that estimation of is impossible in Case 1 because there is no in the formula of In Case 2, has to be estimated numerically by solving the following equation:
\begin{aligned}\alpha^{-1}& \Big[ (1-a) \big( 1 - \log (1-a) \big) + b \log \left( d/u \right)^{\alpha} - \left( d/u \right)^{\alpha} \Big] \\& ~=~ (1-a-b) \widehat{T}_{1(y)},\end{aligned} \tag{4.8}
where Suppose a unique solution of (4.8) with respect to is found. Let us denote it and remember that it is a function of say Finally, if Case 3 is chosen, we then have an explicit formula for a -estimator of :
\widehat{\alpha}_{\small\text{T}}^{(3)} = \frac{I_t(a,1-b)}{(1-a-b) \widehat{T}_{1(y)}} ~=:~ s_1^{(3)}(\widehat{T}_{1(y)}), \tag{4.9}
where \begin{aligned}I_t(a,1-b) & := - \int_a^{1-b} \log (1-v) \, dv \\ & = (1-a) (1 - \log (1-a)) - b (1 - \log b)\end{aligned} and the sample moment is computed as before; see (4.8).
Next, we specify the asymptotic distributions and compute AREs of and The asymptotic distributions of and follow from Theorem 3.1. In both cases, the Jacobian and the covariance-variance matrix are scalar. Denoting and the Jacobian entries for Cases 2 and 3, respectively, we get the following expressions:
\begin{aligned} d_{11}^{(2)} &=\left.\frac{\partial \widehat{\alpha}_T^{(2)}}{\partial \widehat{T}_{1(y)}}\right|_{\widehat{T}_{1(y)}=T_{1(y)}}=\left.\frac{\partial s_1^{(2)}\left(\widehat{T}_{1(y)}\right)}{\partial \widehat{T}_{1(y)}}\right|_{\widehat{T}_{1(y)}=T_{1(y)}} \\ &=\frac{(1-a-b) \alpha^2}{(d / u)^\alpha\left(1-\log (d / u)^\alpha\right)-(1-a)(1-\log (1-a))}\\&=\ -\frac{(1-a-b) \alpha^2}{I_t\left(a, 1-(d / u)^\alpha\right)}, \\ d_{11}^{(3)} &=\left.\frac{\partial \widehat{\alpha}_T^{(3)}}{\partial \widehat{T}_{1(y)}}\right|_{\widehat{T}_{1(y)}=T_{1(y)}}=\left.\frac{\partial s_1^{(3)}\left(\widehat{T}_{1(y)}\right)}{\partial \widehat{T}_{1(y)}}\right|_{\widehat{T}_{1(y)}=T_{1(y)}}\\&\ =-\frac{(1-a-b) \alpha^2}{I_t(a, 1-b)}. \end{aligned}
Note that is found by implicitly differentiating (4.8). Further, denoting and the entries for Cases 2 and 3, respectively, we get the following expressions:
\begin{aligned} (1-a&-b)^2 \sigma_{11(2)}^{2} \\=&\ \int_{a}^{1-b} \int_{a}^{1-b} \big( \min \{ v, w \} - v w \big) \;\\& \cdot\mbox{d} h_Y \big( G_Y^{-1}(v) \big) \, \mbox{d} h_Y \big( G_Y^{-1}(w) \big) \\[1ex] =&\ \alpha^{-2} \int_{a}^{1-(d/u)^{\alpha}} \int_{a}^{1-(d/u)^{\alpha}} \big( \min \{ v, w \} - v w \big) \;\\&\cdot\ \mbox{d} \log (1-v) \, \mbox{d} \log (1-w) \\[1ex] \; =:&\ \alpha^{-2} J_t (a,1-(d/u)^{\alpha}; a, 1-(d/u)^{\alpha})\end{aligned}
and
\begin{aligned} (1-a&-b)^2 \sigma_{11(3)}^{2} \\=&\ \int_{a}^{1-b} \int_{a}^{1-b} \big( \min \{ v, w \} - v w \big) \; \\& \cdot\mbox{d} h_Y \big( G_Y^{-1}(v) \big) \, \mbox{d} h_Y \big( G_Y^{-1}(w) \big) \\[1ex] =&\ \alpha^{-2} \int_{a}^{1-b} \int_{a}^{1-b} \big( \min \{ v, w \} - v w \big) \; \\& \cdot\mbox{d} \log (1-v) \, \mbox{d} \log (1-w) \\[1ex] =&\ \alpha^{-2} J_t (a,1-b; a, 1-b).\end{aligned}
Now, as follows from Theorem 3.1, the asymptotic variances of these two estimators of are equal to for This implies that the estimators found by numerically solving (4.8), and given by (4.9), have the following asymptotic distributions:
\small{\begin{aligned}\widehat{\alpha}_{\small\text{T}}^{(2)} ~~is~~& \\ {\cal{AN}}& \big( \alpha, \, \frac{\alpha^2}{n} \, \frac{J_t (a,1-(d/u)^{\alpha}; a,1-(d/u)^{\alpha})}{I_t^2(a,1-(d/u)^{\alpha})} \big)\end{aligned} \tag{4.10}}
and
\widehat{\alpha}_{\small\text{T}}^{(3)} ~~is~~ {\cal{AN}} \left( \alpha, \, \frac{\alpha^2}{n} \, \frac{J_t(a,1-b; a,1-b)}{I_t^2(a,1-b)} \right). \tag{4.11}
From (4.10) we see that the asymptotic variance of does not depend on the upper trimming proportion where As expected, both estimators and their asymptotic distributions coincide when Thus, for all practical purposes is a better estimator (i.e., it has an explicit formula and it becomes equivalent to if one chooses therefore (more generally, Case 2) will be discarded from further consideration.
As discussed in Note 3.3, the -estimators are globally robust if and This is achieved by sacrificing the estimator’s efficiency (i.e., the more robust the estimator the larger its variance). From (4.5) and (4.11), we find that the asymptotic relative efficiency of with respect to is
\begin{aligned}\mbox{ARE} & \left( \widehat{\alpha}_{\small\text{T}}^{(3)}, \widehat{\alpha}_{\small\text{MLE}} \right) \\&=~ \frac{\frac{\alpha^2}{n} \, \frac{1}{1 - ( d/u )^{\alpha}}} {\frac{\alpha^2}{n} \, \frac{J_t(a,1-b; a,1-b)}{I_t^2(a,1-b)}} \\&~=~ \frac{I_t^2(a,1-b)}{[ 1 - ( d/u )^{\alpha} ] J_t(a,1-b; a,1-b)} \, .\end{aligned}
In this case the integrals and can be derived analytically, but in general it is easier and faster to approximate them numerically; see Appendix A.2 in Brazauskas and Kleefeld (2009) for specific approximation formulas of the bivariate integrals In Table 4.1, we present ARE computations.
It is obvious from the table that for a fixed the effect of the lower trimming proportion on the ARE is negligible. As increases, -estimators become more robust but less efficient, yet their AREs are still sufficiently high (all at least 0.67; more than half above 0.85). Also, all estimators’ efficiency improves as the proportion of right-censored data increases. Take, for example, : the -estimator’s efficiency grows from 0.857 (when to 0.943 (when
4.2.2. Payments Z
Let denote an ordered realization of variables (2.14) with QF (2.17), where and are given by (4.1) and (4.3), respectively. Payments are left- and right-censored, and it follows from Note 3.2 that six permutations are possible between the trimming proportions and However, analysis similar to that done in Section 4.2.1 shows that two of those scenarios (estimation based on censored data only) have no in the formulas of population moments and three (estimation based on observed and censored data) are inferior to the estimation scenario based on fully observed data. (Due to space limitations we do not present those investigations here.) Thus, from now on we will focus on the following arrangement: 0 \leq F(d) \leq a < 1-b \leq F(u) \leq 1.
Similar to the previous section, standard empirical estimates of and provide guidance about the choice of and However, the function is defined differently: For Pareto I only the first moment is needed, and it is equal:
\begin{aligned} (1-a-b) \, T_{1(z)}(\alpha) &= \int_a^{1-b} h_Z \left( G_Z^{-1} (v \, | \, \alpha) \right) \, dv \\&~=~ \int_a^{1-b} \log (F^{-1}(v)) \, dv \\&= (1-a-b) \log (x_0) + \alpha^{-1} I_t(a, 1-b). \end{aligned}
Matching the expression with yields an explicit formula for a -estimator of :
\begin{aligned}\widehat{\widehat \alpha}_{\small\text{T}} &= \frac{I_t(a,1-b)}{(1-a-b) [ \widehat{T}_{1(z)} - \log (x_0) ]} \\&~=:~ s (\widehat{T}_{1(z)}).\end{aligned} \tag{4.12}
To specify the asymptotic distribution and compute AREs of we again rely on Theorem 3.1. The single Jacobian entry for estimator (4.12) is given by
\begin{aligned}d_{11}& = \frac{\partial \widehat{\widehat \alpha}_{\small\text{T}}} {\partial \widehat{T}_{1(z)}} \Bigg|_{\widehat{T}_{1(z)} = T_{1(z)}} \\&~=~ \frac{\partial s (\widehat {T}_{1(z)})} {\partial \widehat{T}_{1(z)}} \Bigg|_{\widehat{T}_{1(z)} = T_{1(z)}} \\&~=~ - \frac{(1-a-b) \alpha^2}{I_t(a,1-b)}.\end{aligned}
The single covariance-variance matrix entry, is found as before:
(1-a-b)^2 \sigma_{11}^{2} ~=~ \alpha^{-2} J_t (a,1-b; a, 1-b).
Hence, the estimator given by (4.12), has the following asymptotic distribution:
\widehat{\widehat \alpha}_{\small\text{T}} ~~is~~ {\cal{AN}} \left( \alpha, \, \frac{\alpha^2}{n} \, \frac{J_t(a,1-b; a,1-b)}{I_t^2(a,1-b)} \right). \tag{4.13}
Now, from (4.7) and (4.13) we find that the ARE of with respect to is
\begin{aligned} &\mbox{ARE} \left( \widehat{\widehat \alpha}_{\small\text{T}}, \widehat{\widehat \alpha}_{\small\text{MLE}} \right) \\&\ = \frac{\frac{\alpha^2}{n} \, \left[ \frac{(x_0/d)^{\alpha}}{1-(x_0/d)^{\alpha}} \log^2 \left[ (x_0/d)^{\alpha} \right] + (x_0/d)^{\alpha} - (x_0/u)^{\alpha} \right]^{-1}} {\frac{\alpha^2}{n} \, \frac{J_t(a,1-b; a,1-b)}{I_t^2(a,1-b)}} \\[1ex] \\&\ = I_t^2(a,1-b) \div \Bigg\{ \bigg[ \frac{(x_0/d)^{\alpha}}{1-(x_0/d)^{\alpha}} \log^2 \left[ (x_0/d)^{\alpha} \right] \\ &\ \quad + (x_0/d)^{\alpha} - (x_0/u)^{\alpha} \bigg] J_t(a,1-b; a,1-b) \Bigg\} .\end{aligned}
In Table 4.2, we present ARE computations for selected scenarios of data censoring.
Patterns in Table 4.2 are similar to those in Table 4.1, but in this case we also observe that -estimators become more efficient as one or both censoring proportions increase. Take, for example, and : the -estimator’s efficiency grows from 0.737 to 0.812 or from 0.768 to 0.850
4.3. W-estimators
As is evident from (3.1) and (3.3), the “central” part of winsorized data is equal to trimmed data times Therefore, -estimators will be closely related to the corresponding -estimators. Choosing the same functions and trimming/winsorizing scenarios as in Section 4.2, we can derive -estimators of and their asymptotic distributions in a straightforward fashion.
4.3.1. Payments Y
Let denote an ordered realization of payments, and The population moment given by equation (3.4), is related to and equal to
\begin{aligned} W_{1(y)}(\alpha) = & a \left[ h_Y \left( G_{Y}^{-1}(a \, | \, \alpha) \right) \right] \\ & + \int_a^{1-b} h_Y \left( G_Y^{-1} (v \, | \, \alpha) \right) \, dv \\ &+ b \left[ h_Y \left( G_{Y}^{-1}(1-b \, | \, \alpha) \right) \right] \\[1ex] = &\ a \left[ -\alpha^{-1} \log{(1-a)} \right] \\&+ \alpha^{-1} I_t(a,1-b) + b \left[ -\alpha^{-1} \log{b} \right] \\[1ex] = &\ \alpha^{-1} \left[ 1-a-b -\log (1-a) \right] ~=:~ \ \alpha^{-1} I_w(a,1-b).\end{aligned}
Matching with the empirical moment
\begin{aligned}\widehat{W}_{1(y)} = &\ n^{-1} \Big[ m_{n} \log{\big( y_{m_n+1:n}/(cd)+1 \big)} \\& + \sum_{i=m_{n}+1}^{n-m_{n}^{*}}\log{\big( y_{i:n}/(cd)+1 \big)} \\& + m_{n}^{*}\log{\big( y_{n-m_{n}^{*}:n}/(cd)+1 \big)} \Big]\end{aligned}
yields an explicit formula for a -estimator of :
\widehat{\alpha}_{\small\text{W}} ~=~ \frac{I_w(a,1-b)}{\widehat{W}_{1(y)}} ~=:~ r_y (\widehat{W}_{1(y)}). \tag{4.14}
The asymptotic distribution of follows from Theorem 3.2. The single Jacobian entry for estimator (4.14) is given by
\begin{aligned}d_{11} &= \frac{\partial \widehat{\alpha}_{\small\text{W}}}{\partial \widehat{W}_{1(y)}} \Bigg|_{\widehat{W}_{1(y)}=W_{1(y)}} \\&=~ \frac{\partial r_y (\widehat{W}_{1(y)})}{\partial \widehat{W}_{1(y)}} \Bigg|_{\widehat{W}_{1(y)}=W_{1(y)}} \\&=~ - \frac{\alpha^2}{I_w(a,1-b)}.\end{aligned}
The entry is equal to (see Lemma A.1 in Zhao, Brazauskas, and Ghorai 2018a), where are derived as follows. Given that
\begin{aligned} H_{1}(v) & = h_Y \left( G_{Y}^{-1}(v) \right) ~=~ \log \left( \frac{G_{Y}^{-1}(v \, | \, \alpha)}{cd}+1 \right) \\[1ex] & = - \alpha^{-1} \log (1-v) \, \large\mathbf{1}\normalsize \left\{ 0 \leq v < \frac{F(u)-F(d)}{1-F(d)} \right\} \\+&\ \log (u/d) \, \large\mathbf{1}\normalsize \left\{ \frac{F(u)-F(d)}{1-F(d)} \leq v \leq 1 \right\},\end{aligned}
and we have:
\begin{aligned} \widehat{A}_{1,1}^{(1)} & = \alpha^{-2} J_t (a,1-b; a,1-b), \\[0.5ex] \widehat{A}_{1,1}^{(2)} ~=~ \widehat{A}_{1,1}^{(3)} & = \alpha^{-2} \left[ (1-a-b) \left( \frac{a^2}{1-a} - b \right) \\ + b \log(1-a) - b \log b \right], \\[0.5ex] \widehat{A}_{1,1}^{(4)} & = \alpha^{-2} \left[ \frac{a^2}{1-a}(a+2b) + b(1-b) \right].\end{aligned}
This yields
\begin{aligned} \sigma_{11}^{2} = &\ \alpha^{-2} \Big[ J_t (a,1-b; a,1-b) + \frac{a^2(2-a)}{1-a} \\&- b \big[ 1-2a-b + 2 \log b - 2 \log(1-a) \big] \Big] \\[0.5ex] \ \, =:&\ \alpha^{-2} J_w (a,1-b; a,1-b).\end{aligned}
Putting it all together, given by (3.4), has the following asymptotic distribution:
\widehat{\alpha}_{\small\text{W}} ~~is~~ {\cal{AN}} \left( \alpha, \, \frac{\alpha^2}{n} \, \frac{J_w(a,1-b; a,1-b)}{I_w^2(a,1-b)} \right). \tag{4.15}
Consequently,
\begin{aligned}\mbox{ARE} \left( \widehat{\alpha}_{\small\text{W}}, \widehat{\alpha}_{\small\text{MLE}} \right) =~ & \frac{\frac{\alpha^2}{n} \, \frac{1}{1 - ( d/u )^{\alpha}}} {\frac{\alpha^2}{n} \, \frac{J_w(a,1-b; a,1-b)}{I_w^2(a,1-b)}} \\~=~ & \frac{I_w^2(a,1-b)}{[ 1 - ( d/u )^{\alpha} ] J_w(a,1-b; a,1-b)} \, .\end{aligned}
In Table 4.3, we present ARE computations for selected scenarios of data censoring.
Patterns in Tables 4.1 and 4.3 are identical. However, it is worth noting that for a fixed censoring scenario and fixed and each -estimator is slightly more efficient than its counterpart.
4.3.2. Payments Z
Let denote an ordered realization of payments, and Then the population moment is equal to
\begin{aligned} W_{1(z)}(\alpha) = &\ a \left[ h_Z \left( G_{Z}^{-1}(a \, | \, \alpha) \right) \right] \\& + \int_a^{1-b} h_Z \left( G_Z^{-1} (v \, | \, \alpha) \right) \, dv \\&+ b \left[ h_Z \left( G_{Z}^{-1}(1-b \, | \, \alpha) \right) \right] \\[1ex] = &\ a \left[ \log x_0 - \alpha^{-1} \log(1-a) \right] + (1-a-b) \\& \cdot\ \log x_0 + \alpha^{-1} I_t(a,1-b) + b \left[ \log x_0 - \alpha^{-1} \log b \right] \\[1ex] = &\ \log x_0 + \alpha^{-1} I_w(a,1-b).\end{aligned}
Matching with the empirical moment
\begin{aligned}\widehat{W}_{1(z)} =&\ n^{-1} \Big[ m_{n}\log{(z_{m_{n}+1:n}/c+d)} \\&+ \sum_{i=m_{n}+1}^{n-m_{n}^{*}}\log{(z_{i:n}/c+d)} + m_{n}^{*}\log{(z_{n-m_{n}^{*}:n}/c+d)} \Big]\end{aligned}
yields an explicit formula for a -estimator of :
\widehat{\widehat \alpha}_{\small\text{W}} ~=~ \frac{I_w(a,1-b)}{\widehat{W}_{1(z)} - \log x_0} ~=:~ r_z (\widehat{W}_{1(z)}). \tag{4.16}
We derive the asymptotic distribution of by following the same steps as in Section 4.3.1. That is,
\begin{aligned}d_{11} &= \frac{\partial \widehat{\widehat{\alpha}}_{\small\text{W}}}{\partial \widehat{W}_{1(z)}} \Bigg|_{\widehat{W}_{1(z)}=W_{1(z)}} =~ \frac{\partial r_z (\widehat{W}_{1(z)})}{\partial \widehat{W}_{1(z)}} \Bigg|_{\widehat{W}_{1(z)}=W_{1(z)}} \\&=~ - \frac{\alpha^2}{I_w(a,1-b)}.\end{aligned}
Then, given that and, for we have
\begin{aligned} \sigma_{11}^{2} = &\ \alpha^{-2} \Big[ J_t (a,1-b; a,1-b) \\&+ \frac{a^2(2-a)}{1-a} - b \big[ 1-2a-b + 2 \log b - 2 \log(1-a) \big] \Big] \\[0.5ex] = &\ \alpha^{-2} J_w (a,1-b; a,1-b).\end{aligned}
Hence, given by (4.16), has the following asymptotic distribution:
\widehat{\widehat \alpha}_{\small\text{W}} ~~is~~ {\cal{AN}} \left( \alpha, \, \frac{\alpha^2}{n} \, \frac{J_w(a,1-b; a,1-b)}{I_w^2(a,1-b)} \right). \tag{4.17}
Consequently,
\scriptsize{\begin{aligned} \mbox{ARE} \left( \widehat{\widehat \alpha}_{\small\text{W}}, \widehat{\widehat \alpha}_{\small\text{MLE}} \right) & = \frac{\frac{\alpha^2}{n} \, \left[ \frac{(x_0/d)^{\alpha}}{1-(x_0/d)^{\alpha}} \log^2 \left[ (x_0/d)^{\alpha} \right] + (x_0/d)^{\alpha} - (x_0/u)^{\alpha} \right]^{-1}} {\frac{\alpha^2}{n} \, \frac{J_w(a,1-b; a,1-b)}{I_w^2(a,1-b)}} \\[1ex] & = \frac{I_w^2(a,1-b)} { \left[ \frac{(x_0/d)^{\alpha}}{1-(x_0/d)^{\alpha}} \log^2 \left[ (x_0/d)^{\alpha} \right] + (x_0/d)^{\alpha} - (x_0/u)^{\alpha} \right] J_w(a,1-b; a,1-b)} \, .\end{aligned}}
In Table 4.4, we present ARE computations for selected scenarios of data censoring.
Patterns in Table 4.4 are similar to those in Table 4.2. However, unlike the ARE results in Tables 4.1 and 4.3, for payments comparison of the -estimators versus the -estimators shows that neither method outperforms the other all the time. Each type of estimator can have a better ARE than the competitor, but that depends on the choice of and (which also depends on and
5. Real data example
In this section, we use MLE and several - and -estimators for fitting the Pareto I model to the well-studied Norwegian fire claims data (see Brazauskas and Serfling 2003; Nadarajah and Abu Bakar 2015; Brazauskas and Kleefeld 2016; Abu Bakar, Nadarajah, and Ngataman 2020), which are available at the following website:
http://lstat.kuleuven.be/Wiley (in Chapter 1, file norwegianfire.txt).
5.1. Data and preliminary diagnostics
The data represent the total damage done by fires in Norway for the years 1972 through 1992; only damages in excess of a priority of 500,000 Norwegian kroner (nok) are available. We will analyze the data set for the year 1975, which has observations with the most extreme loss of 52.6 million nok. The data for that year were also modeled with Pareto I by Brazauskas and Serfling (2003). Table 5.1 provides a summary of the data set.
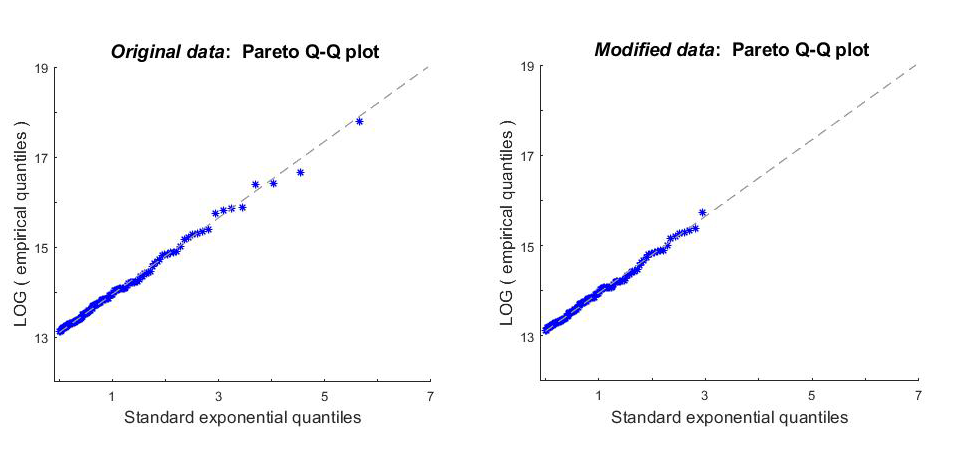
Since no information is given for damages of less than 500,000 nok and there is no policy limit and no coinsurance, the random variable that generated the data is related to payment —i.e., it is with and Moreover, as is evident from Table 5.1, the data are right-skewed and heavy-tailed suggesting that Pareto I, with CDF (4.1) and QF (4.3), might be an appropriate model in this case. To see how right-censoring changes the estimates of model fits, and ultimately premium estimates for a layer, we consider two data scenarios: original data and modified data
Further, we fit Pareto I under the original and modified data scenarios. Preliminary diagnostics—the quantile-quantile plots (Q-Q plots) presented in Figure 5.1—strongly suggest that the Pareto I assumption is reasonable. Note that the plots are parameter-free. That is, since Pareto I is a log-location-scale family, its Q-Q plot can be constructed without first estimating model parameters. Note also that only actual data can be used in these plots (i.e., no observations under the modified data scenario).

5.2. Model estimation and validation
To compute parameter estimates we use the following formulas: (4.4) for MLE, (4.9) for and (4.14) for To match the specifications of the fire claims data (denoted in (4.4) and is replaced with and in (4.9) and (4.14), function is now defined as Specifically, for modified data claims MLE is given by
\small{\widehat{\alpha}_{\small\text{MLE}} = \frac{\sum_{i=1}^{n} \large\mathbf{1}\normalsize \{ d < l_i < u \}} {\sum_{i=1}^{n} \log ( l_i/d ) \large\mathbf{1}\normalsize \{ d < l_i < u \} + \log (u/d) \sum_{i=1}^{n} \large\mathbf{1}\normalsize \{ l_i = u \}}},
and for original data claims it becomes Computational formulas for the - and -estimators remain the same for both data scenarios:
\begin{aligned}\widehat{\alpha}_{\small\text{T}} &= \frac{(1-a) (1 - \log (1-a)) - b (1 - \log b)}{(1-a-b) \, \widehat{T}_{1(y)}} \\& \mbox{and}\qquad \widehat{\alpha}_{\small\text{W}} = \frac{1-a-b- \log (1-a)}{\widehat{W}_{1(y)}},\end{aligned}
where and
\begin{aligned}\widehat{W}_{1(y)} =&\ n^{-1} \Big[ m_{n} \log{\big( l_{m_{n}+1} / d \big)} \\&+ \sum_{i=m_{n}+1}^{n-m_{n}^{*}}\log{\big( l_{i}/ d \big)} + m_{n}^{*}\log{\big( l_{n-m_{n}^{*}}/ d \big)} \Big],\end{aligned}
with several choices of and The corresponding asymptotic distributions are specified by (4.5), (4.11), and (4.15). They are used to construct the 90% confidence intervals for All computations are summarized in Table 5.2, where goodness-of-fit analysis is also provided; see Klugman, Panjer, and Willmot (2012) for how to perform the Kolmogorov–Smirnov (KS) test for right-censored data (Section 15.4.1) and how to estimate its -value using parametric bootstrapping (Section 19.4.5).
As is evident from Table 5.2, all estimators exhibit excellent goodness-of-fit performance, as one would expect after examining Figure 5.1. Irrespective of the method of estimation, the fitted Pareto I model has a very heavy right tail—i.e., for all its moments are infinite except the mean. The - and -estimators with match the estimates of MLE under the original data scenario. As discussed in Section 4.2, this choice of and however, would be inappropriate when data are censored at which corresponds to about 4.9% of censoring. Clearly, this level of censoring has no effect whatsoever on - and -estimators with and which demonstrates their robustness. The MLE, on the other hand, is affected by censoring. While the change in its estimated values of and the corresponding confidence intervals seems minimal (less than 2%), it gets magnified when applied to calculation of premiums, as will be shown next.
5.3. Contract pricing
Let us consider the estimation of the loss severity component of the pure premium for an insurance benefit that equals the amount by which a fire loss damage exceeds 7 million nok with a maximum benefit of 28 million nok. That is,
B = \begin{cases} 0, & \mbox{if} ~~ L \leq d^*; \\[0.25ex] L-d^*, & \mbox {if} ~~ d^* < L \leq u^*; \\[0.25ex] u^* - d^*, & \mbox {if} ~~ L > u^*, \end{cases}\tag{5.1}
and, if follows the distribution function we seek
\begin{aligned}\varPi [F] & ~=~ \mathbf{E}[B] \\& ~=~ \int_{d^*}^{u^*} (x - d^*) \, dF(x) + (u^* - d^*) [ 1-F(u^*) ] \\& ~=~ \int_{d^*}^{u^*} [ 1 - F(x) ] \, d x,\end{aligned}
where and (In U.S. dollars, this roughly corresponds to the layer from 1 to 5 million.) We will present premium estimates for two versions of : observed loss (corresponds to and ground-up loss (corresponds to The second version shows how different the premium is if all—observed and unobserved—data were available. It also facilitates evaluation of various loss variable characteristics; for example, if one switches from a priority of 500,000 to 250,000, the change in loss elimination ratio could be estimated, but such computations are impossible under the first version of
Now, straightforward derivations yield the following expression for :
\begin{aligned} \varPi [F] ~=~&\ C \times \frac{(u^*/C)^{1-\alpha} - (d^*/C)^{1-\alpha}}{1-\alpha},\\& \qquad \alpha \ne 1,\end{aligned}\tag{5.2}
where (for observed loss) or (for ground-up loss). If then To get point estimates we plug the estimates of from Table 5.2 into (5.2). To construct interval estimators, we rely on the delta method (see Serfling 1980, Section 3.3), which uses the asymptotic distributions (4.5), (4.11), and (4.15) and transforms according to (5.2). Thus, we have that is asymptotically normal with mean and variance where
\begin{aligned}\frac{\partial}{\partial \alpha} \Big[ \varPi [F] \Big] =~&\frac{C}{(1-\alpha)^2} \\ &\cdot \Biggl\{ (1-\alpha) \biggl\lbrack \left( \frac{d^*}{C} \right)^{1-\alpha} \log \left( \frac{d^*}{C} \right) \\ &\hspace{10mm}- \left( \frac{u^*}{C} \right)^{1-\alpha} \log \left( \frac{u^*}{C} \right) \biggr\rbrack \\&\hspace{10mm}+ \left( \frac{u^*}{C} \right)^{1-\alpha} - \left( \frac{d^*}{C} \right)^{1-\alpha} \Biggr\}\end{aligned}
and is taken from (4.5), (4.11), or (4.15). To ensure that the left endpoint of the confidence intervals is positive, we will construct log-transformed intervals, which have the following structure: for Table 5.3 presents point and 90% log-transformed interval estimates of premiums for observed and ground-up losses under the original and modified data scenarios.
As can be seen from Table 5.3, premiums for the ground-up loss are two orders of magnitude smaller than those for the observed loss. This was expected because the ground-up distribution automatically estimates that the number of losses below 500,000 is large while the observed loss distribution assumes that that number is zero. Further, as the data scenario changes from original to modified, the robust estimates of premiums and with and do not change, but those based on MLE increase by 5% (for observed loss) and 11% (for ground-up loss). Finally, note that such MLE-based premium changes occur even though Pareto I fits the data exceptionally well (see Table 5.2). If the model fits were less impressive, the premium swings would be more pronounced.
5.4. Additional illustrations
We mentioned in Section 1 that robust model fits can be achieved by other methods of estimation; one just needs to apply them to trimmed or winsorized data. Since for the Pareto I distribution - and -estimators of with coincide with MLE (see Table 5.2), it is reasonable to expect that left- and/or right-censored MLE should behave like a -estimator with similarly chosen winsorizing proportions. (Such a strategy is sometimes used in data analysis practice to robustify MLE.) In what follows, we investigate how the idea works on Norwegian fire claims.
First of all, the asymptotic properties of MLE as stated in Section 4.1 are valid when the right-censoring threshold is fixed; hence the probability to exceed it is random. The fixed-thresholds method of moments and some of its variants have been investigated by Poudyal (2021b). The corresponding properties for - and -estimators are established under the complete opposite scenario: data proportions are fixed but thresholds are random. To see what effect this difference has on actual estimates of we compute MLEs by matching its censoring points with those used for the - and -estimators in Table 5.2. In particular, for we have which implies that for observations from to their actual values are included in the computation of and for the remaining ones the minimum and maximum of actual observations are used, i.e., and When computing the censored MLE, this kind of effect on data can be achieved by choosing the left- and right-censoring levels and as follows: and Likewise, for and we have and and arrive at and Note that and are not fixed, which is required for derivations of asymptotic properties, but rather they are estimated threshold levels. Rigorous theoretical treatment of MLEs with estimated threshold levels is beyond the scope of the current paper and thus is deferred to future research projects. For illustrative purposes, however, we can assume that the threshold levels and are fixed and apply the methodology of Section 4.1.
Due to the left-truncation of Norwegian fire claims at and additional left- and right-censoring at and respectively, we are fitting Pareto I to payment data. Given these modifications, (censored at and is found by maximizing (4.6) of the following form:
\begin{aligned} &{\cal{L}}_{P_Z} \big( \alpha \, \big| \, l_1, \ldots, l_n \big) \\ &\ = \log \big[ 1 - (d/\widetilde{d})^{\alpha} \big] \sum_{i=1}^n \large\mathbf{1}\normalsize \{ l_i = \widetilde{d} \} \\& \quad \ +~ \alpha \log (d/\widetilde{u}) \sum_{i=1}^n \large\mathbf{1}\normalsize \{ l_i = \widetilde{u} \} \\& \quad \ + ~ \sum_{i=1}^n \big[ \log \left( \alpha/d \right) - (\alpha+1) \log \left( l_i/d \right) \big] \large\mathbf{1}\normalsize \{ \widetilde{d} < l_i < \widetilde{u} \}. \qquad ~\end{aligned}
Similarly, the asymptotic distribution (4.7) should be of the following form:
\begin{align} \widehat{\widehat{\alpha}}_{\small\text{MLE}} ~~is~~ \hspace{34mm} & \\ {\cal{AN}} \Bigg( \alpha, \, \frac{\alpha^2}{n} \, \Bigg[ \frac{\left(\frac{d}{\widetilde{d}}\right)^{\alpha}}{1-\left(\frac{d}{\widetilde{d}}\right)^{\alpha}} \log^2 \left[ \left(\frac{d}{\widetilde{d}}\right)^{\alpha} \right]& \\ + \left(\frac{d}{\widetilde{d}}\right)^{\alpha} - \left(\frac{d}{\widetilde{u}}\right)^{\alpha} \Biggr]^{-1} \Biggr).& \end{align}
Numerical implementation of these formulas is provided in Table 5.4, where we compare censored MLEs with estimators based on such and that act on data the same way as MLEs. It is clear from the table that censored MLEs do achieve the same degree of robustness as the corresponding -estimators. Moreover, the point and interval estimates produced by these two methods are very close but not identical. Finally, it should be emphasized once again that the MLE-based intervals are constructed using the assumed asymptotic distribution that is not proven and may be incorrect.
6. Concluding remarks
In the paper, we developed the methods of trimmed (called and winsorized (called moments for robust estimation of claim severity models that are affected by deductibles, policy limits, and coinsurance. We provided the definitions and asymptotic properties of those estimators for various data scenarios, including complete, truncated, and censored data, and two types of insurance payments. Further, we derived specific definitions and explicit asymptotic distributions of the maximum likelihood, -, and -estimators for insurance payments when the loss variable follows a single-parameter Pareto distribution. Those analytic examples clearly show that - and -estimators sacrifice little efficiency with respect to MLE but are robust and have explicit formulas (whereas MLE requires numerical optimization; see Section 4.1.2). These are highly desirable properties in practice. Finally, we illustrated the practical performance of the estimators under consideration using the well-known Norwegian fire claims data.
The research presented in the paper invites follow-up studies in several directions. For example, the most obvious direction would be to study small-sample properties of the estimators (for Pareto using simulations. A second direction might be to derive specific formulas and investigate the estimators’ efficiency properties for other loss models such as lognormal, gamma, log-logistic, folded- and GB2 distributions. A third avenue might be to consider robust estimation based on different influence functions such as Hampel’s redescending or Tukey’s biweight (bisquare) functions. A fourth line of inquiry could be to compare practical performance of our models’ robustness with that based on model distance and entropy. Note that the latter approach derives the worst-case risk measurements, relative to measurements from a baseline model, and has been used by authors in the actuarial literature (e.g., Blanchet et al. 2019) as well as in the financial risk management literature (see, e.g., Alexander and Sarabia 2012; Glasserman and Xu 2014). Fifth, it would also be of interest to see how well future insurance claims can be predicted using the robust parametric approach of this paper versus more general predictive techniques that are designed to incorporate model uncertainty (see, e.g., Liang Hong and Martin 2017; L. Hong, Kuffner, and Martin 2018).
Finally, to conclude the paper, we briefly discuss how our methodology based on - and -estimators could be extended to applications involving regression with heavy-tailed errors (and potentially incomplete data) and aggregate losses. These are recent and active areas of applied research in insurance (see, e.g., Shi 2014; Shi and Zhao 2020; Delong, Lindholm, and Wüthrich 2021). First of all, the specific examples we present in the paper demonstrate that - and -estimators are well suited for robust fitting of heavy-tailed distributions (e.g., Pareto I) when data are affected by deductibles and policy limits. Second, the regression framework is a major generalization of the underlying assumptions. In this context, several useful results are derived by Lien and Balakrishnan (2005, 2021). Motivated by the problems originating in accounting, those authors investigated the effects on parameter estimates (of a standard regression model) when the covariate data are first cleaned by applying symmetric trimming or winsorization. Those papers surely offer a good start for finding robust estimators of regression parameters, but to make - and -estimators work with heavy-tailed errors, one would have to apply trimming and/or winsorizing to the covariates and the response variable. Third, the aggregate losses are modeled using compound distributions. The severity part of the compound model could be handled directly with - and -estimators. However, at this time, it remains unclear how to modify these estimators to fit the frequency part of the model. This line of investigation is deferred to future research projects.
Acknowledgments
The authors are very appreciative of valuable insights and useful comments provided by editor-in-chief Dr. Peng Shi and an anonymous referee that helped to substantially improve the paper. Also, much of the work was completed while the first author was a PhD student in the Department of Mathematical Sciences at the University of Wisconsin–Milwaukee.