

1. Introduction
The finance and insurance industries rely heavily on the use of models in decision making (e.g., in the determination of regulatory capital requirements and pricing). However, such models are subject to error. Specifically, model risk can be defined as the potential loss that can result from the misspecification or misuse of models (inspired by the definition in Capital Requirements Directive IV, Article 3.1.11). Model failures have had serious consequences in the past—e.g., in 1997, the hedge fund Long-Term Capital Management lost around $4.5 billion as a consequence of relying on normality assumptions while neglecting the importance of stress testing (Lowenstein 2008). In 2008, investors that had a poor understanding of the Gaussian copula in the David Li’s pricing formula relied on it excessively in pricing credit derivatives. That over-reliance was one of the drivers of the 2008 financial crisis (Salmon 2009). Nowadays it is well understood that model risk is a key concern, and hence its quantification is of vital importance.
Recent regulations related to model risk management
Regulators nowadays regard the calculation of capital requirements based on models that are neither challenged nor backtested as not being credible. We cite Deloitte Center for Regulatory Strategy (2018): “Supervisors will neither approve nor place reliance on the firm’s strategic and operational use of a model, including for risk assessment and capital planning, unless satisfied with a firm’s model risk management.” In 2011, the first supervisory guidance on model risk management, SR 11-7, was published by the Office of the Comptroller of the Currency and the Federal Reserve (Board of Governors of the Federal Reserve System 2011). The key focus of SR 11-7 is on ensuring an effective challenge of models. In 2013, the Basel Committee on Banking Supervision expressed its concern about model uncertainty. It conducted surveys and found that risk weightings for the same assets may differ among banks—that observation undermines the credibility of the models used by banks (Basel Committee on Banking Supervision 2013). In its discussion paper on the review of specific items in the Solvency II Delegated Regulation, the Actuarial Association of Europe insists on focusing more on model risk assessment (Actuarial Association of Europe 2017). A recent supervisory statement from the Prudential Regulation Authority of the Bank of England highlights the necessity of understanding and accounting for the assessment of model uncertainties. That document also presents some model risk management principles that the authority deems important to apply when using stress test models (Prudential Regulation Authority 2018). Whereas regulators stress the necessity of accounting for model risk assessment in the decision-making processes of financial institutions, in practice such an accounting is not always obvious, and if it is done, it tends to be of a qualitative rather than a quantitative nature. A major obstacle is that the quantitative methods developed by researchers so far are either not well suited to deal with the assessment of model risk in practice or not yet recognized by practitioners.
Current practices of model risk assessment
Banks and insurance companies around the globe tend to employ risk management frameworks that are similar to the ones that local or international professional organizations have proposed. For example, insurance companies in the United States, Canada, and most other countries in North and South America are known to follow the frameworks suggested by the Society of Actuaries (SOA) and the Canadian Institute of Actuaries. Three main approaches to model risk assessment can be distinguished.
First, the practice most commonly demanded by and applied in the market is to assess model risk using what is called a risk-rating scheme—a practice commonly known as the qualitative scoring method (Dionne and Howard 2017). In other words, to assess a model, one evaluates various common inherent risk factors, such as model complexity, the expertise of the model’s users, the quality of its reporting, the frequency of its usage, its financial impact, and so on. The risk manager assigns a score to each factor and sums up the individual scores to get a comprehensive view of the model risk. Although such an approach is easy to understand and to implement, it is also very imperfect. Indeed, this methodology may confuse the risk that results from improper implementation of the model with the risk that results from model uncertainty—the first risk is in principle already accounted for in the operational risk assessment, but the second one needs particular consideration. Moreover, the scores and weights attributed to each factor are highly subjective, as they depend heavily on expert judgment, which makes this approach far from robust. Finally, risk mitigation controls can be misleading. To decrease the model risk in accordance with the qualitative scoring methodology, one would aim to decrease the final score by, say, decreasing the complexity of the model; however, a decrease in complexity does not necessarily decrease the model risk.
Second, a method known as modern operational risk management offers practitioners a quantitative approach to modeling risk measurement. In this approach one views model risk as a type of operational risk and measures it by modeling the frequency and severity of model risk events. A presentation of this approach can be found in Samad-Khan (2008) and OpRisk Advisory and Towers Perrin (2010). Although modern operational risk management offers consistency with the way other types of risk are assessed and allows for interdependencies among risks, it has some serious drawbacks. Empirical data on model risk losses can be scarce and inaccurate. In addition, the approach in itself is subject to potential high model risk. These major limitations hinder the use of this approach in practice.
Third, the Institute and Faculty of Actuaries’ (IFoA’s) Model Risk Working Party opined recently that a quantitative assessment based on model comparison is highly preferable but unfortunately is not ready for practical use; in their words, “Where alternative methodological choices to those employed in a model are plausible, the impact of method changes on model outputs can also be tested … However, … methodological changes (e.g., a change in dependence structure or valuation method) are too time-consuming to implement for test purposes” (Black et al. 2017). A quantitative approach along the lines of what IFoA suggests is the model uncertainty approach (MUA). That approach is based on the principle of model risk sensitivity. Such sensitivity is measured using benchmarking, backtesting, and comparison with alternative models (Jacobs 2015). In addition, it is a bottom-up approach to aggregating model risk in that it consists of evaluating the model risk inherent in each individual modeling and then aggregating individual model risks using models’ dependencies. Compared with the other aforementioned approaches, the MUA offers various advantages. It is much less subjective and provides a clear and traceable process with the ability to provide guidance on the level of capital that is needed to account for model risk. However, the expertise, time, and resources this approach requires make it less desirable by practitioners.
In this paper, we develop a quantitative approach to model risk assessment that aligns with the MUA. Our approach is based on the theory of risk bounds that studies the behavior of a model under worst-case and best-case scenarios. To compute risk bounds, one first selects the model assumptions that can be fully trusted, hence distrusting all other assumptions. Next, one determines a model (a worst-case scenario) that is consistent with those trusted assumptions and that leads to the highest possible value for the risk measure. Similarly, one determines the model that yields the lowest possible value. Those two extreme values are the risk bounds. Our contributions are as follows. First, we define a new notion of model risk that enables one to quantify the model risk contribution of each assumption by making use of the extensive literature on risk bounds. Second, we extend the notion of risk bounds by assigning a “credibility score” to each assumption of interest instead of making a binary decision on whether it is fully trusted or distrusted. This results in tighter bounds that better reflect experts’ opinions and are more useful in practice. Our third contribution is to propose new measures that make it possible to establish the capital buffer for model risk.
The paper is organized as follows. In Section 2, we review the recent academic literature on risk bounds. To ensure that the paper is self-contained and to facilitate its use, we recall the main theorems on risk bounds in the extended Appendix C. In Section 3, we present our model risk assessment approach that incorporates the abovementioned contributions. Section 4 consists of a case study where we apply our approach to a real-world data set, the SOA medical data set (Grazier 1997). Section 5 concludes.
2. Review of the literature on risk bounds
The quantitative approach to model risk assessment aims to assess the uncertainty arising from the choice of the probability model (e.g., the assumption that the loss distribution belongs to the exponential family of distributions), the adoption of parameter calibration techniques (since different techniques may actually lead to different parameter estimates), and the limitation of the collected data. Over the past decades, many researchers have explored this topic. A standard approach to assessing model risk consists of comparing the capital value (or more generally speaking, the value of a risk measure) resulting from the model used with the one resulting from extreme models—extreme models are the models adopted in worst- and best-case scenarios. The extreme values taken by the adopted risk measure are referred to as risk bounds. In this approach to model risk assessment, a first step consists of specifying which assumptions we can be certain about and which ones we cannot. The bounds thus clearly depend on the model assumptions that are considered fully reliable. For instance, one might trust that the distributions of the portfolio components are fully known, but not the interdependence. Or, one might be certain that the loss distribution is unimodal and has a known mean and variance.
Researchers have bestowed special attention on dependence uncertainty bounds—i.e., risk bounds when the dependence structure is unknown but information on the marginals is available. This stream of the literature finds its pedigree in Rüschendorf (1981) and Makarov (1982). In the homogeneous case—i.e., when the distribution functions of the marginals are identical—B. Wang and Wang (2011) and Puccetti and Rüschendorf (2013) obtained sharp tail bounds in the case of monotone densities and concave densities, R. Wang, Peng, and Yang (2013) found explicit formulas for the worst value-at-risk when the marginal densities are monotone or tail-monotone, and R. Wang (2014) studied asymptotic bounds. In the inhomogeneous case, the analysis becomes more complicated, and approximations of bounds were needed. Therefore, Puccetti and Rüschendorf (2012a) and Embrechts, Puccetti, and Rüschendorf (2013) developed a new algorithm, known as the rearrangement algorithm, that can numerically approximate value-at-risk sharp bounds (i.e., attainable bounds) for the distribution of the aggregate risk. Furthermore, Bernard, Rüschendorf, and Vanduffel (2017) provided explicit (but non-sharp) upper and lower bounds of the value-at-risk of the portfolio loss when we have information only on the marginal distributions (see Theorem 1 in Appendix C).
Various attempts to include dependence information have been made in the literature. Puccetti and Rüschendorf (2012b) offered an improvement on some existing bounds for the distribution function and the tail probabilities of portfolios by adding a positive dependence restriction on the dependence structure. Bignozzi, Puccetti, and Rüschendorf (2015) and Rüschendorf (2017) showed that an assumption of a negative dependence would mainly affect the upper bound of the value-at-risk but an assumption of a positive dependence would affect the lower bound (see Theorems 2 and 3). Puccetti, Rüschendorf, and Manko (2016) considered the value-at-risk upper bounds in the case where positive dependence information is assumed in the tails or some central part of the distribution function. In Puccetti et al. (2017), independence among (some) subgroups of the marginal components is assumed, a fact that leads to a considerable improvement in the value-at-risk bounds as compared with the case where only the marginals are known (see Theorems 4 and 5).
In practical situations, estimating the dependence structure can be challenging and can lead to inaccurate results. In contrast, one can perform moment estimates with a reasonable degree of accuracy (note that the accuracy decreases with the increase in the order of the moment). This observation constitutes a motivation for the many papers that replaced the assumption on the dependence structure with a constraint on the variance as some source of dependence information. In fact, it is intuitive to see that adding variance and higher-order moments constraints to a setting in which only the marginals are fully known is likely to improve the risk bounds as that addition captures information that cannot be represented by the marginals. Bernard, Rüschendorf, and Vanduffel (2017) derived value-at-risk bounds based on the knowledge of the marginal distributions and the variance of the portfolio risk (see Theorem 6). Bernard et al. (2015) studied these bounds under the knowledge of higher-order moments (skewness, for instance). Interestingly, Bernard, Denuit, and Vanduffel (2018) provided evidence that replacing the knowledge of the marginal distributions with the knowledge of the collective mean does not cause a significant loss of information. In fact, a considerable number of papers have studied risk bounds in scenarios in which information on the mean and higher-order moments of the portfolio risk is assumed instead of assuming knowledge on marginal distributions and dependence structure—see, for example, Kaas and Goovaerts (1986), Hürlimann (1998), Hürlimann (2002), De Schepper and Heijnen (2010), and Zymler, Kuhn, and Rustem (2013), among others. Bertsimas, Lauprete, and Samarov (2004) derived value-at-risk bounds when only the mean and a maximum variance of the portfolio loss can be trusted (see Theorem 7). Moreover, Puccetti et al. (2017) derived bounds when information on the maximum variance of the portfolio loss is assumed in addition to the knowledge of the marginals and the independence among some subgroups of the marginals (see Theorem 8).
Another case of interest is the factor model in which each individual risk depends on a common risk factor. Many important models in risk management can be seen as factor models, e.g., the multivariate normal mean-variance mixture model. Bernard et al. (2017) derived risk bounds (mainly of the value-at-risk and the tail value-at-risk) when factor models are only partially specified (see Theorems 9 and 10).
Other sets of assumptions that were considered in the literature are the shape and the domain of the loss distribution. Bernard, Rüschendorf, and Vanduffel (2017) derived the upper bound of the value-at-risk of a nonnegative portfolio loss whose mean is the only assumption that can be fully trusted (Theorem 11). Bernard, Denuit, and Vanduffel (2018) derived risk bounds when the portfolio loss is bounded and information on marginals and maximum moments are available (see Theorems 12 and 13). Bernard, Kazzi, and Vanduffel (2020) derived risk bounds for unimodal portfolio distributions and considered the case of nonnegative portfolios with possibly a theoretically infinite variance (see Theorems 14, 15, and 16). Additional results can be found in the literature, such as in Li et al. (2018) and Bernard, Kazzi, and Vanduffel (2022), where information on the shape (unimodality and symmetry) of either the individual risks or the total risk is taken into account.
3. Model risk assessment
An adopted model is composed of a set of adopted assumptions. The traditional way, as seen in the academic literature, of assessing the model risk inherent in an adopted model consists of following a three-step approach. First, one specifies all assumptions that can be fully trusted. In general, there exist many models that are consistent with these assumptions, and the adopted model is merely one among them. Next, one maximizes and minimizes the risk measure over the set of all plausible models—that is, one determines the worst-case and best-case values (i.e., the bounds). Finally, in the third step, one compares the risk bounds with the value the risk measure takes under the adopted model.
Under the traditional approach, however, all the assumptions that are not fully credible are completely neglected. In this section, we work on improving the traditional approach by overcoming that drawback. First, we propose a method to assess the contribution of each assumption to the total model risk. This analysis will provide the modeler with insight as to how risky it is to adopt each of the assumptions in terms of model risk. Second, we present a novel approach to improve the risk bounds by making use of the assumptions that are not fully credible. Finally, we introduce a new measure for the model risk capital buffer.
3.1. Setting
Consider a portfolio of individual risks and denote the portfolio loss variable by Note that unless otherwise stated we do not assume the portfolio to be homogeneous.
We write to express that is the cumulative distribution function of And we denote by and the mean, variance, and standard deviation of respectively.
Let be a risk measure where is the set of all real-valued random variables defined on a probability space (i.e., is a set of measurable functions). Let be the cumulative distribution function of the adopted model and let be a set of assumptions that characterizes —i.e., adopting the set of assumptions is equivalent to adopting We define a decreasing sequence of sets with
In a scenario where only the assumptions are adopted, we define the corresponding upper and lower bounds of the risk measure by
¯ρk=supX∈Akρ(X),
and
ρ_k=infX∈Akρ(X),
respectively.
Without loss of generality of the methods we propose, the risk measure that we consider in this paper is the value-at-risk (VaR). Note that VaR is indeed commonly used as the reference measure for computing the capital requirement in the industry. In fact, the VaR at a probability level represents the amount of capital necessary to ensure with a confidence level that the insurance company or financial institution will not be technically insolvent after a specific period. Formally, VaR is defined as
VaRα(S)=inf{x∈R | FS(x)≥α}, α∈(0,1),
where is the cumulative distribution function of the aggregate risk
3.2. Model risk allocation
A fully trusted model (i.e., when the assumptions leading to the model are all fully trusted) poses no model risk. However, such a model does not exist. Typically, only some of the assumptions can be fully trusted, say The risk bounds and corresponding to those fully trusted assumptions reveal the uncertainty coming from the non–fully trusted assumptions the wider the bounds, the more uncertainty we have in the non–fully trusted assumptions. This uncertainty is seen as a representation of the total model risk entailed by the non–fully trusted assumptions.
However, if we calculate only risk bounds in the one scenario where we split fully trusted versus non–fully trusted assumptions, we will be assessing only the uncertainty that arises from completely distrusting the whole set Such an approach is incomplete as it ignores the actual impact of each assumption on the total model risk.
In order to reveal the impact of a specific set of assumptions, say on the total model risk inherent in it would be intuitive to observe how sensitive the risk bounds are to the addition or removal of from the set of assumptions responsible for the total model risk.
In other words, to assess the model risk contribution of a subset of the non–fully trusted assumptions, we can assume knowledge of that subset and translate it into additional constraints in the maximization and minimization of the adopted risk measure. We can then compare the newly derived risk bounds with the risk bounds derived before adding the new constraints. The risk bounds, if changed, will get tighter as the uncertainty decreases when more information is added. The decrease in uncertainty will reveal the contribution this subset of non–fully trusted assumptions had to the total model risk. Following this reasoning, we can define a measure of the contribution of any set of assumptions to the total model risk conditional on the knowledge of another set of assumptions. This measure is introduced in mathematical terms in Definition 3.1.
Definition 3.1 (Conditional model risk contribution measure). Let be a risk measure. Let be the cumulative distribution function of the adopted model and let be a set of assumptions that characterizes Let us define a decreasing sequence of sets with Then, for we can define a measure of the contribution of assumptions to the total model risk given full knowledge of when using the risk measure as follows:
C(ρ,Ak,Al)=1−¯ρl−ρ_l¯ρk−ρ_k,
where and
3.3. Example
Let us consider an adopted model where the assumptions of interest are = = the mean is 10, = the variance is equal to 4, = the distribution is unimodal, = the distribution is normal}. Let be the adopted risk measure. To assess how much the unimodality assumption contributes to the total model risk left after fully trusting that the mean and the variance are equal to 10 and 4, respectively, we calculate Using the bounds of Theorems 7 and 14, Hence, given the knowledge of the mean and the variance, the unimodality assumption constitutes 33.44% of the total model risk.
We can see that is a relative measure of model risk contribution whose value is between 0 and 1. Specifically, we observe only when and which means that assuming after already having assumed does not bring any additional model risk. In the case of the other extreme, we observe when which means that assuming constitutes the whole model risk conditional to the knowledge of
Remark 3.1. We actually have, in several cases, explicit formulas for the risk bounds, which leads to an explicit formula for the conditional model risk contribution For instance, in the previous example, in order to calculate the model risk contribution of adding a unimodality assumption, given the information on the mean and the maximum variance when using the risk measure we used the bounds of Theorems 7 and 14 and easily obtained an explicit form of In this particular scenario, interestingly, the conditional model risk contribution depends only on the probability level —i.e., if we assume knowledge of the mean and the maximum variance, the model risk contribution of adding the unimodality assumption is independent of the values of the mean and the maximum variance.
Remark 3.2. Note that, based on the difference between the sets and different types of risk can be assessed. For example, if the difference in the sets results from adding an assumption on the parameter, then a parameter risk is being assessed and so on.
Furthermore, the measure in Definition 3.1 can be used sequentially to perform what is called a “model risk allocation.” This can be explained as follows:
-
We look at the adopted model, and we try to disassemble the assumptions upon which it was built. This can be done in a backward order in the sense that we start with a set of assumptions that fully define the adopted model and then we start to remove one assumption or subset of assumptions at a time until we obtain a set of the most basic and credible assumptions (i.e., the set of the fully trusted assumptions).
-
After arriving at the most basic scenario, a comparison of the distance between the upper and lower bounds among the different relevant scenarios can be performed. Specifically, the comparison can be performed using by moving forward from the most basic scenario to the adopted model. This would reveal the marginal effect on model risk of adding each assumption conditional on the already adopted assumptions.
This idea will become clearer as we present and explain the methodology of model risk allocation more thoroughly using diagrams in the following subsection.
3.3. Summary diagrams
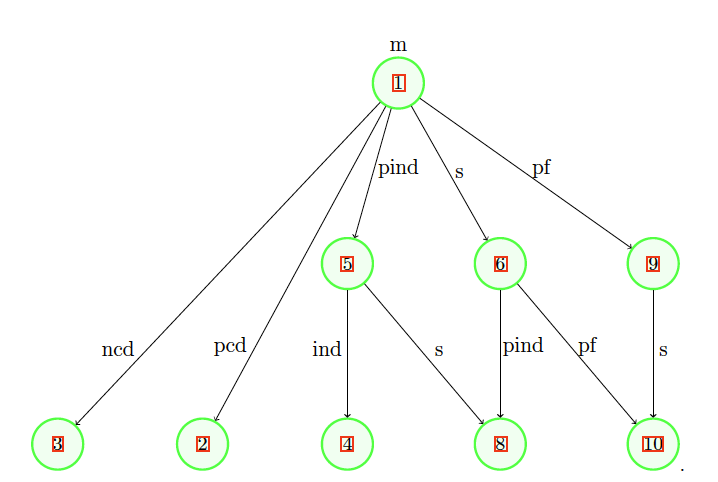
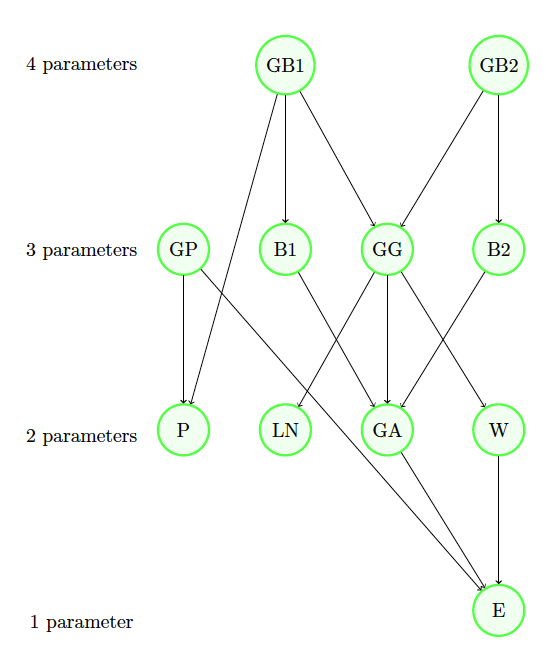
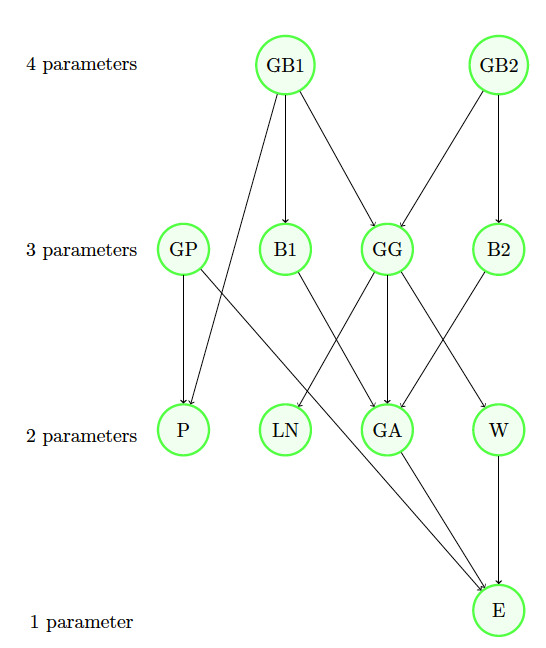
The literature offers risk bounds in many scenarios of interest. We present here a few of them with their interrelations in diagrams. Indeed, we present three diagrams that can be useful in performing the model risk allocation. Note that we use VaR as the risk measure Each scenario of the first two diagrams corresponds to a theorem that stems from the literature. To ensure that the paper is self-contained and to facilitate its use, we recall each theorem in Appendix C using consistent notations. The first diagram (in Figure 1) presents particular assumptions that can be made for the dependence among the individual components of a portfolio, whereas the other two diagrams serve to deal particularly with assumptions made for the portfolio loss when seen as a univariate random variable.

To perform the model risk allocation on an adopted model described by a specific probability distribution, we can begin by relaxing some of its assumptions while staying in the same distribution family, i.e., by studying the position of our model compared with its family of distributions (e.g., Diagram in Figure 3). Then we can make a bigger relaxation to drop the family of distribution assumptions and move backward to the more basic assumptions (e.g., Diagrams 1 and 2, respectively, displayed in Figures 1 and 2). Note that the assumptions of at least one of the root scenarios should be respected during the whole backward path—that root scenario is often seen as easy to fully trust. Note also that the assumption of knowledge of the portfolio mean in Diagram 2 can easily be replaced by an assumption of knowledge of an interval of the mean; this would be calculated by maximizing/minimizing the bounds as functions of the mean.

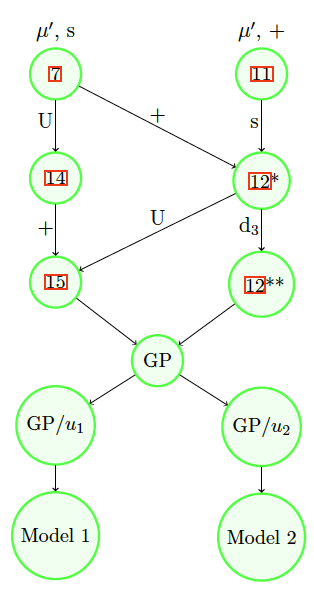
Illustration
We present a toy example to illustrate the methodology. Assume that a variable of interest is modeled using an exponential distribution with mean and variance i.e., Then the third quartile of is equal to Assuming an exponential distribution with a specific parameter is a rather strong and restrictive assumption. If the data allow being fully confident only about the fact that the mean belongs to the interval and the variance is less than 196, then all other assumptions that led to the adopted model should be tested. Disassembling assumptions by walking backward in the graphs would lead to several paths. We provide a few examples for illustrative purposes:
-
If we consider that we trust only the intervals of the mean and the variance, the risk bounds based on Theorem 7 are (-0.08, 36.25). Those bounds are very wide and very far from 13.86, which makes them, if used on their own, almost useless in practice.
-
We start by choosing one simple backward path, say, E GA 15 14 7 (see Figures 2 and 3).
-
At this step, we start the allocation of model risk. Moving from the bounds of 7 to the ones of 14, we compare the two bounds to assess how much model risk is allocated to the unimodality assumption assuming that we trust the information on the intervals of the mean and the variance. The bounds of 14 are in this case (1.27, 27.87). Using the notations introduced in Definition 3.1, we have that and is unimodal}, and we obtain Hence, assuming that we trust the intervals of the mean and the variance, the unimodality assumption constitutes 26.78% of the total model risk.
-
The bounds in 15 are (1.27, 23.68). Since the lower bound is not sharp, the conditional model risk contribution of the nonnegativity assumption, i.e., is at least 15.75%. However, for simplicity, we take here the exact value of 15.75% (for more details on the sharpness of bounds refer to Appendix 6).
-
It is interesting as well to study the model risk inherent in the choice of a bigger family of the exponential and gamma distributions. This is aimed to answer the question of whether the risky choice was the adoption of the gamma family or the choice of the exponential among the gamma family members. The VaR bounds for a gamma distributed random variable whose mean and variance respect the given intervals are (8.11, 16.64). The conditional model risk contribution of choosing a gamma distribution after having knowledge of the intervals on the mean and the variance and of the unimodality and nonnegativity, i.e., is 61.94%.
-
Let us now assess the parameter risk inherent in choosing an exponential distribution family. The lower and upper bounds of the within the exponential distribution while respecting the intervals of the mean and variance are The conditional parameter risk contribution is 34.94%.
To formally summarize the results using the notations of Definition 3.1, we express the assumptions in Table 1, where the notations are as defined in Figures 2 and 3, but with and referring particularly to and respectively.
We then display our estimates for the conditional risk contributions in Table 2. The first three columns of Table 2 reflect what was discussed previously. The last column of Table 2 presents how much the aggregate assumptions constitute of the total model risk. This measure is conditional only on the basic scenario, which we assume fully credible by default. Hence, can be seen (in some sense) as the unconditional measure of model risk contribution of assumptions
3.4. Credibility-based bounds
In the literature, risk bounds are based on assigning either full or zero credibility to the assumptions on which the adopted model is built. As a result, the bounds are usually either very wide (because of trusting very few assumptions) or unrealistic (because of assigning full credibility to assumptions that cannot be fully trusted). A solution to this problem would be to assign partial credibility to the assumptions and calculate the bounds accordingly. This can be expressed formally in the following analysis.
Our analysis is based on having a non-null set of assumptions that we can easily consider as almost sure, i.e., Hence, for an adopted model and a set of assumptions we can compute upper bounds—i.e., we can calculate the decreasing sequence of upper bounds estimates where is the corresponding risk value for the set of assumptions We see these values as the possible realizations of a random variable UB, and we aim to estimate the mean of UB. We find that
P(UB≤¯ρk)=P({ai}i≤k are correct)={P(ak is correct∖{ai}i≤k−1 are correct)×P({ai}i≤k−1 are correct)for k∈{r+1,...,n},1for k∈{1,...,r},={∏kj=r+1P(aj is correct∖{ai}i≤j−1 are correct)for k∈{r+1,...,n},1for k∈{1,...,r}.
Indeed, can be seen as a conditional credibility factor and can be denoted as Thus, we can express the cumulative distribution function of UB as
P(UB≤¯ρk)={∏kj=r+1zjfor k∈{r+1,...,n},1for k∈{1,...,r}.
After specifying the credibility factors, the cumulative distribution function of UB can be calculated and therefore the can be determined; we denote it as the credibility-based upper bound (CUB). The same analysis can be performed to determine the credibility-based lower bounds (CLB). We provide explicit expressions for the CUB and CLB in the following definition.
Definition 3.2 (Credibility-based upper and lower bounds). Let be a risk measure. Let be the cumulative distribution function of the adopted model and let be a set of assumptions that characterizes where can be fully trusted. Let us define a decreasing sequence of sets with Let us denote by the credibility assigned to given the knowledge of Then we can define the credibility-based upper bound CUB and lower bound CLB as follows:
CUB(ρ,{Am}m,{zj}j)=¯ρr+n∑m=r+1(m∏j=r+1zj)(¯ρm−¯ρm−1),
and
CLB(ρ,{Am}m,{zj}j)=ρ_r+n∑m=r+1(m∏j=r+1zj)(ρ_m−ρ_m−1),
where and
The credibility factors are to be assessed/specified differently according to each type of assumptions. For example, one may use a specific statistical test to demonstrate confidence about the unimodality property (e.g., the dip test of unimodality—see J. A. Hartigan and Hartigan (1985) and P. M. Hartigan (1985)), another test to demonstrate how trustworthy a specific parameter estimation is (e.g., hypothesis testing), yet another test to see how credible the normality assumption is (e.g., the numerous normality tests), and so on. Nevertheless, the assessment of credibility factors based on statistical tests or expert opinion is considered out of the scope of this paper.
Remark 3.3. The traditional approach to risk bounds can be seen as a particular case of the credibility-based approach where the credibility factors are dummy variables (i.e., can take only the values 0 or 1).
Illustration
Let us elaborate on our toy example introduced in Section 3.3. We specify the conditional credibility factors in Table 3. The sequence of fully trusted initial assumptions in this case is i.e., the intervals on the mean and the variance, and hence we have The adopted model is reached after adding the assumption and we thus have The credibility-based bounds would then be and
Remark 3.4. Table 4 helps us examine the reasoning behind Definition 3.2 from a different angle. In the first column, the bounds improve (i.e., become tighter) when assumptions are added (i.e., when increases). However, this improvement (shown in the fourth column) cannot be realized when adding assumptions that cannot be fully trusted. A reasonable way of incorporating these improvements is to adjust each improvement according to the credibility (shown in the third column) that the corresponding added assumption holds. This perspective automatically leads to the bounds shown in the fifth column.
Model risk measures
One of the ultimate objectives of assessing model risk is to discover a possible buffer we can use to calculate the corresponding capital requirement. In this section, we propose an intuitive formula that can be used for that purpose.
Following the early work of Cont (2006) on model risk measurement, Barrieu and Scandolo (2015) define the absolute and the relative measures of model risk. The absolute measure reflects the position of the value of the risk measure applied to the adopted model compared with the upper risk bound derived based on the scenario of fully trusted assumptions, whereas the relative measure reflects the position of the adopted model compared with both the lower and the upper risk bounds. In formal terms, if and is the set of fully trusted assumptions, then the two measures are defined as follows:
Definition 3.3 (Absolute measure of model risk, (Barrieu and Scandolo 2015). AM(ρ,Ar,X∗)=¯ρr−ρ(X∗)ρ(X∗).
Definition 3.4 (Relative measure of model risk, (Barrieu and Scandolo 2015).
\mathrm{RM}(\rho, \mathcal{A}_r, X^*) = \frac{\overline{\rho}_r- \rho(X^*)}{\overline{\rho}_r - \underline{\rho}_r}. \tag{3.9}
However, in practice, and are very different from (i.e., the risk bounds are wide), meaning that in many cases of interest these two model risk measures are not very informative. We thus propose using the credibility-based upper and lower bounds to extend these definitions to the credibility-based absolute and relative measures of model risk as follows.
Definition 3.5 (Credibility-based absolute measure of model risk).
\mathrm{CAM}(\rho, \mathrm{CUB}, \mathrm{CLB}, X^*) = \frac{\mathrm{CUB} - \rho(X^*)}{\rho(X^*)}.\tag{3.10}
Definition 3.6 (Credibility-based relative measure of model risk).
\mathrm{CRM}(\rho, \mathrm{CUB}, \mathrm{CLB}, X^*) = \frac{\mathrm{CUB} - \rho(X^*)}{\mathrm{CUB} - \mathrm{CLB}}.\tag{3.11}
The four measures are positive increasing functions of model risk with a value of 0 for no model risk. CRM, similar to RM, is unitless and reaches 1 when the model risk is maximal. Indeed, CRM incorporates information on the worst-case and best-case models, on the adopted model, and on the credibility assigned to each assumption. Hence, it would be interesting to incorporate CRM as a factor in the model risk capital formula. In addition, the difference between the CUB and the CLB represents the maximum model risk capital that could be required when using a model that adopts the corresponding assumptions and credibility factors. These ideas lead us to Definition 3.7.
Definition 3.7 (Model risk capital). For a continuous increasing function with and we can define the model risk capital (MoRC) by
\small{ \begin{align} \mathrm{MoRC(CRM, CUB, CLB, f)}&= f(\mathrm{CRM}) \\ &\quad \times \mathrm{(CUB - CLB)}. \end{align} } \tag{3.12}
We can look at as the percentage of the maximum capital that can be allocated to model risk, starting from 0 for no model risk and reaching 100% for full model risk. The regulator and the model risk manager decide on the degree of conservatism toward model risk. This can be translated into the choice of i.e., how the percentage of the maximum capital increases with the increase in model risk. One suggestion would be to use the convex function then the higher the the less conservative the MoRC. Indeed, any continuous increasing function can lead to an admissible function
Illustration
In our toy example, and If we choose then
Sometimes it is interesting to compare the model risks of two possible models. This can be done by comparing the corresponding CAMs and CRMs. In addition, noting that the CUBs and CLBs are basically model specific, it can be meaningful to compare the width of the credibility-based bounds of two different models adopted for the same data set; a higher difference is an indicator of a higher uncertainty in the model.
Interestingly, the more assumptions that are challenged and the more credibility a modeler can assign to his or her assumptions, the lower the CAM and (CUB CLB) are expected to be. That fact encourages the modeler to strive for higher credibility in his or her assumptions and to challenge as many assumptions as possible.
Remark 3.5. The measures presented in definitions 3.3, 3.4, 3.5, and 3.6 focus on the risk of underestimation of the risk measure. Even though this is the case that calls for a buffer in the capital requirement, one can easily construct complementary measures to reflect the risk of overestimation of the risk measure.
4. Case study: SOA medical dataset
In this section, we present an application of the ideas developed in this paper to an SOA Group Medical Insurance Large Claims Database described thoroughly in Grazier (1997). The data are collected from 26 insurers and cover the total claim amounts exceeding $25,000 over the year 1991. We study the total claim amounts as a univariate variable, which makes it possible to challenge the two different univariate models suggested for this same data set by two scientific papers, namely, Cebrián, Denuit, and Lambert (2003) and Zisheng and Chi (2006).
4.1. Data and model description
The data set is composed of 75,789 observations. The average total claim amount is $58,413 and the largest observed total claim is $4,518,420. The standard deviation among the total claims is $66,005, and the VaR at a probability level of 99.5% is $406,190.
Both Cebrián, Denuit, and Lambert (2003) and Zisheng and Chi (2006) adopted an extreme value theory perspective and fit a generalized Pareto distribution (GPD), which is known as the “natural” distribution for modeling the excess-of-loss over high thresholds.
Let denote the random variable of the total claim and the threshold after which the data are fit to a GPD, and let represent the generalized Pareto distribution function with a shape parameter a location parameter and a scale parameter Then, one can easily prove that implies for (see Appendix B for more details on the GPD). To fit the GPD model to the data set, one has to choose a threshold and then fit the GPD to the conditional distribution of the excesses above the threshold Typically, is calculated empirically.
Cebrián, Denuit, and Lambert (2003) found that the best choice for the threshold is 200,000, which gives 2,013 exceedances. The estimated parameters are and 93,901. The mean, standard deviation, and VaR at 99.5% of under the adopted model are 58,405, 66,178, and 406,161.
On the other hand, Zisheng and Chi (2006) chose a threshold of 162,402, which gives 3,083 exceedances and leads to the estimated parameters and 82,652.07. The mean, standard deviation, and VaR at 99.5% of under this model are 58,422, 66,110, and 406,928.
4.2. Model risk allocation
The first step in the model risk assessment is to disassemble the assumptions upon which the adopted model was built and try to assess the model risk contribution of each assumption of interest. Using the tools provided in the literature (many of which are stated in Figures 1, 2, and 3), some of the assumptions that are of interest to challenge are questioned as follows:
-
Given the threshold, what is the parameter risk in the estimation of the scale and shape parameters of the GPD?
-
Given that a GPD is adopted, what is the parameter risk in choosing the threshold?
-
Given mean, variance, nonnegativity, and unimodality, how risky is it, in terms of model risk, to choose a GPD?
-
How much does each of the assumptions on the moments, nonnegativity, and unimodality contribute to the total model risk of the adopted model?
The diagram in Figure 4 shows some possible paths from two basic scenarios to the adopted models. Motivated by the large number of observations, we calculate the interval on the mean and the maximum standard deviation based on the standard confidence interval procedure. Indeed, refers to the assumption that the average total claim amount belongs to the interval and refers to the assumption that the standard deviation is lower than or equal to 66,339 calculated based on the formula of the upper limit presented on pages 197–198 of (Sheskin 2003).

The value of the maximum third moment is calculated by bootstrapping; we simulated 100,000 samples of 10,000 data points each taken from the set of 75,789 observations, calculated the third moment of each bootstrap sample, and then calculated the third quartile of the set of third moment values and adopted the third quartile as the upper limit for the third moment. Indeed, refers to the assumption that the upper limit of the third moment of the portfolio loss random variable is equal to
The feature of unimodality can easily be detected from the data and in the two adopted models when complemented by the empirical distribution for the values that are lower than the threshold (the GPD model is usually fitted to the tail of the distribution starting at the threshold, whereas the rest of the distribution is usually modeled empirically).
Remark 4.1. It is important to note that the methods adopted in the estimation of the moments intervals are just a choice from many others; indeed, this case study does not aim to adopt the best estimation methods but rather solely to assess the model risk.
The risk measure adopted in this case study is the one that is most used in the calculation of the capital requirement in Solvency II, the value-at-risk at a probability level of 99.5% In the diagrams of Figure 5, the risk bounds and the conditional model risk contributions under the various assumptions are presented. At this step, one can directly make several observations:
-
The nonnegativity assumption does not contribute to the model risk (0%).
-
Assuming a maximum value for the third moment after already having information on the first two moments is not risky in terms of model risk (2.02%).
-
Adding information on the variance after having already assumed an interval for the mean has a great effect on the model risk and should be done cautiously (92%).
-
Being able to trust the unimodality feature of the data inspires much more confidence in choosing the GPD compared with being able to trust some information on the third moment (56.29% vs. 70.3%).
-
Even when one trusts the information on the moments, nonnegativity, and unimodality, the choice of GPD still contributes significantly in the total model risk (56.29%).
-
Choosing a threshold after having already chosen to adopt a GPD model can have a relatively higher contribution to the model risk than choosing the GPD itself after having already trusted the unimodality property and some information on the moments (e.g., 78.12% vs. 56.29%).
-
The threshold chosen by (Zisheng and Chi 2006) is a stronger assumption (in terms of model risk) than the one chosen by (Cebrián, Denuit, and Lambert 2003) (78.12% vs. 68.38%).

The conditional model risk contribution of the last assumption that leads to the adopted model is by definition 100% and hence is not very helpful in interpreting specific assumptions. For that, one can use the relative measure of model risk (RM) defined in Definition 3.4. The parameter risk inherent in choosing the couple after already having chosen the threshold can be presented by whereas in the case of Model 2 we have This directly implies that the parameter risk in choosing the scale and the shape parameters of Model 1 after having already chosen the threshold of Model 1 is greater than the one in choosing the scale and shape parameters of Model 2 after having already chosen the threshold of Model 2.
4.3. Model risk measurement
The next step in our model risk assessment framework is to assess the model risk in the model as a whole. We can do that using the credibility-based bounds defined in Definition 3.2. We first choose the assumptions we will use in the calculation and assign the corresponding conditional credibility factors Based on the results obtained so far, a meaningful set of assumptions that leads to the adopted model is
Before proceeding to the assessment of credibility factors, it should be noted that this case study does not aim to show the best way of assigning credibility factors but rather to give a simplistic illustration of how the framework works.
The interval on the mean and the maximum variance are both calculated based on a 95% confidence level, so it is not unreasonable to start with this information as the fully trusted basic assumptions.
The sample of observations clearly features unimodality; we can even verify this by performing some unimodality tests (e.g., the dip test of unimodality—see J. A. Hartigan and Hartigan (1985) and P. M. Hartigan (1985). Hence, one can confidently give a 95% credibility to the unimodality property.
Our risk measure is evaluated at the very end of the tail, at a probability level of 99.5%, which makes the GPD a good choice for the model. We choose to assign a 50% conditional credibility factor for the GPD assumption.
To choose the threshold, Cebrián, Denuit, and Lambert (2003) used the Gerstengarbe plot proposed in Gerstengarbe and Werner (1989), whereas Zisheng and Chi (2006) used the goodness-of-fit test for the GPD developed in Choulakian and Stephens (2001). A statistician would have to compare the two tests and assign the corresponding conditional credibility factors. In this illustrative example, we choose to correlate the credibility of the method with the number of times it was cited. Choulakian and Stephens (2001) is currently cited 390 times, whereas Gerstengarbe and Werner (1989) is cited only 24 times, and hence we will consider the goodness-of-fit test as more credible. The Gerstengarbe plot and the goodness-of-fit test are respectively given 50% and 75% as conditional credibility factors.
The scale and shape parameters are estimated in both models using maximum likelihood estimation. However, the parameters are estimated based on 2,013 and 3,083 data points in (Cebrián, Denuit, and Lambert 2003) and (Zisheng and Chi 2006), respectively. Hence, the estimates of the second model are more reliable, and we choose to give conditional credibility factors of 60% and 80% to the estimates of Model 1 and Model 2, respectively. A summary is presented in Table 5 and Table 6.
We can now apply the formula for the credibility-based bounds of Definition 3.2 and obtain the following: 168,833, 587,001, 194,876, and 576,548. Hence, the credibility-based absolute and relative measures of model risk for the two models are 44.52%, 43.25%, 41.68%, and 44.44%. The widths of credibility-based bounds of the two models are 418,168 and 381,672. The two CRMs are very close, but the comparisons of the CAMs and the s show that Model 2 has the least model risk.
Finally, we calculate the suggested MoRC for each of the two models. To theoretically eliminate the model risk, one should add a buffer that, as a percentage of the risk value, is equal to the CAM. However, the CAM is quite high in our case and amounts to more than 40% of the value of the risk measure. Additionally, the CAM may misrepresent the model risk since it does not account for the position of the risk value compared with the CLB. A solution would be to adopt the MoRC in Definition 3.7 with a convex function The choice of is based on how conservative the risk management team or the regulators are. If then the higher the less security is required. If we take for example, we get and i.e., respectively and of the risk values of the two adopted models.
5. Conclusion
In this paper, we establish a practical framework for quantitative model risk assessment that builds on the literature of risk bounds (theory of model risk). First, we disassemble an adopted model into a set of assumptions and use our novel model risk contribution measure to allocate the model risk to the various assumptions. In so doing, we aim to enlighten the modeler on how cautious he or she is expected to be when making every assumption in the model-building process. Second, we acknowledge that every single assumption can have its own level of credibility and we incorporate this information into the model risk assessment. Third, we define new measures of model risk that the modeler can use for model risk capital allocation. Last, we conduct a case study in which we apply our framework to a real-world data set, the SOA Group Medical Insurance Large Claims Database.
Our framework incorporates previous findings from the literature on risk bounds and is built in a way to embrace future findings in this currently active research area.
Funding
The authors acknowledge funding from the 2019 Individual Grants Competition of the CAS.