
1. Introduction
The loss reserve estimate is the most substantial liability on a non-life insurer’s balance sheet (Grace and Leverty 2011). Therefore, the accuracy in the reserve prediction is critical for insurers to prevent insolvency issues and remain competitive as reserve estimates affect pricing decisions and the decision-making of internal management, regulators, and investors (Friedland 2010).
In non-life insurance, loss reserve prediction is usually based on macro-level models that use aggregate claims data summarized in a run-off triangle, and the chain-ladder (CL) method is the most used macro-level model (Wüthrich and Merz 2008). The main strengths of the macro-level models are that they are easy to implement and interpret. In addition, the run-off triangle provides a convenient diagnostic tool to assess environmental changes. In the loss reserving literature, changes in the insurer’s business that can affect loss reserving are referred to as environmental changes. Simultaneously, the limited ability to handle heterogeneity and environmental changes is the most significant drawback of macro-level models, which may lead to inaccurate predictions. To deal with environmental changes under the macro-level framework, actuaries usually consider the trending techniques or the expected claim technique. In the former, the environmental change is treated as a trend to adjust the development projections. In the latter, actuaries incorporate a priori reserve estimate. However, both techniques could lead to problematic reserve estimates as they are highly dependent on actuaries’ judgments (Jin 2014).
Cappelletti (2020) highlights the impact of the COVID-19 pandemic on general insurance, which includes: an increase in the cost of commercial property claims due to supply chain issues and business interruptions, increase in workers compensation claims from workers infected through work, increase in claims severity on open claims as a result of an increase in cost due to challenges from the pandemic, increase in lawsuits against businesses alleging negligently exposing persons to COVID-19, and decrease in automobile accident claims as a result of people staying at home. It may be argued that pandemics are low probability events, and as such, the adverse effects on reserve projections caused by the changes due to the pandemic may be infrequent. But, there are other events, such as changes to underwriting practices, claims processing, and mix of products, that are encountered more regularly by general insurers that also lead to environmental changes.
Recently, micro-level reserving techniques have gained traction as it allows an analyst to use the information on the policy, the individual claim, and development process in the prediction of outstanding liabilities. Under the individual-level reserving literature, the marked Poisson processes (MPP) framework introduced by Arjas (1989), Jewell (1989), and Norberg (1993, 1999) and first applied in Antonio and Plat (2014) constitute the most dominant family of research. In conjunction with survival analysis, generalized linear models (GLMs) have also been applied to the loss reserving problem (Taylor and Campbell 2002; Taylor and McGuire 2004; Taylor, McGuire, and Sullivan 2008). Besides, a growing stream of research for individual-level reserving focuses on using machine learning algorithms. The machine learning algorithms do not assume a structural form for the claims data and provide a data-driven approach. Wüthrich (2018a) illustrates the use of regression trees, and Wüthrich (2018b) focused on the application of neural networks for individual-level reserving. See Baudry and Robert (2019), De Felice and Moriconi (2019), and Duval and Pigeon (2019) for other applications of machine learning algorithms to the reserving problem. Further, handling the association between the payment sizes and settlement times resulting from large claims taking a longer time to settle and vise versa has also garnered some attention in the literature. For example, Lopez, Milhaud, and Thérond (2019) proposes correcting the bias caused by censoring using an appropriate weighting scheme, while Okine, Frees, and Shi (2021) introduced the joint model for longitudinal and time-to-event data into the micro-level loss reserving literature and illustrated the improvement in reserve prediction when the payment-settlement association is incorporated into the predictive reserving process.
A recent survey to understand what reserving methods actuaries use to provide point reserve estimates shows that the chain ladder is the most commonly used model for point estimates, followed by the Bornhuetter-Ferguson (BF) method, and the Cape-Cod method (ASTIN Working Party on Non-Life Reserving 2016). The survey results also show the bootstrapping technique is the most used technique for reserve variability for macro-level models, followed by Mack’s model. This survey result affirms the popularity of the macro-level framework among practicing actuaries. However, evidence from the literature shows that by leveraging claim-level granular information to control for heterogeneity and environmental changes, the micro-level reserving techniques improve the accuracy in claim prediction compared to macro-level models under non-homogeneous environmental conditions. Practitioners have not widely used micro-level techniques because they are challenging to implement as past contributions on individual claim reserving were mainly focused on parametric models and likelihood maximization (Lopez, Milhaud, and Thérond 2019). But, with the growth in computing power in this era of big data analytics, insurance companies will enjoy a lesser burden concerning implementation. For the non-life insurer, ratemaking usually takes the micro-level approach (Parodi 2012). As a result, implementing micro-level loss reserving techniques ensures a consistent framework for ratemaking and reserving. Hence, the micro-level techniques provide a promising addition to actuaries’ tools for loss reserving.
This paper aims to underscore the importance of micro-level loss reserving methods, particularly under changes in environmental conditions. In doing so, we employ the joint model introduced in Okine, Frees, and Shi (2021). The joint model for reserving purposes consists of two submodels, the longitudinal submodel governs the payment process for a given claim, and the survival submodel concerns the settlement process of the claim. The two components are joined via shared latent variables. In addition to leveraging claim-level granular information to control for observed heterogeneity and environmental changes, the joint model framework improves the accuracy in claim prediction compared to macro-level models by accounting for unobserved heterogeneity.
Besides showing that the micro-level reserving techniques improve the accuracy in claim prediction compared to macro-level models, especially under non-homogeneous environmental conditions, the micro-level literature has also discussed the influence of covariates. For instance, Guszcza and Lommele (2006) discusses the use of covariates to capture differences in expected loss development patterns of different claims. Frees (2015) also discusses the essential role of covariates in insurance analytics in operations such as ratemaking, and claims management. This paper further adds to the discussion on the impact of covariates in insurance analytics under environmental changes.
We contribute to the literature in the following aspects: First, we identify several scenarios of unstable environment where the standard chain-ladder method fails while the joint model demonstrates superior performance. Second, we discuss the limitations of the trending techniques in dealing with environmental changes under the macro-level framework. Third, we expand on the influence of micro-level covariates on insurance analytics in the presence of changes in the environment.
The plan for the remainder of the paper. Section 2 presents the joint model framework. Section 3 evaluates the prediction performance of the joint model and the chain-ladder method under a stable environment using simulation studies. Section 4 identifies environmental changes where the joint model outperforms macro-level reserving methods and discusses the limitations of the trending techniques for macro-level reserving methods. Section 5 concludes the paper.
2. Statistical Model
Under this section, we summarize and state again the main points and definitions of the joint model framework developed in the statistical literature for longitudinal outcomes and time-to-event data called shared-parameter models and applied to the loss reserving problem in Okine, Frees, and Shi (2021).
2.1. Joint Model Framework and Estimation
In the statistical literature, the shared-parameter model consists of the longitudinal and survival submodels joined via shared latent variables (Rizopoulos 2012). For the loss reserving problem, the longitudinal submodel represents the payment process for a given claim where the sequence of payments from a reported claim forms the longitudinal outcomes, and the survival submodel drives the settlement process of the claim where the settlement time of the claim is the time-to-event outcome of interest.
For the th claim we set the time origin for a claim as its reporting time, and denote and as the settlement time and valuation time, respectively. We define and such that takes the value of 1 if the condition is satisfied, and 0 otherwise. We assume is independent of Thus, the observable time-to-settlement outcomes for claim consist of pairs where indicates whether the claim has been closed by the valuation time, if so, indicates the settlement time. For the longitudinal responses, let be the payment process, and denote as the vector of the complete cumulative payments for claim with payments at times We define as the observable payment times assuming there are payments by the time of valuation. Then, the vector of cumulative payments at observed time of payments is denoted by and denotes the vector of cumulative payments at future times after the valuation time.
We specify a generalized linear mixed effect model (GLMMs) for the cumulative payments where the claim-specific unobserved heterogeneity is accounted for through a vector of random effects Given the random effects and predictors the cumulative payment is assumed to be independent across time and from the exponential family. Using a link function the conditional mean is specified as a linear combination of covariates given by:
\eta_{it}=g(E[Y_{it}|\boldsymbol{b}_i])=\boldsymbol{x}_{it}'\boldsymbol{\beta}+ \boldsymbol{z}_{it}'\boldsymbol{b}_i.\tag{1}
where, and are the vectors of covariates in the fixed and random effects, respectively. is the vector of the parameters for the fixed effects and, we assume are independent of each other and follow a multivariate normal distribution.
The association between the claim payment process and the settlement process is introduced through the effects of on the hazard of settlement. Then the time-to-settlement outcome of a claim is modeled using a proportional hazard model specified as: \begin{array}{rl} h_i(t|\eta_{it})=h_0(t)\exp\{\boldsymbol{\gamma}'\boldsymbol{w}_{it} +\alpha \eta_{it} \}, \end{array}\tag{2}
where is the baseline hazard, is a vector of covariates and is the corresponding regression coefficients. The strength of the association is measured by where a positive payment-settlement association is given by a negative and implies larger payments take a longer time to settle and vice versa. From (2), the survival function of is \begin{array}{rl} S_i(t|\eta_{it})=\exp\left(-\int_0^t h_0(s)\exp\{\boldsymbol{\gamma}' \boldsymbol{w}_{it} +\alpha \eta_{it} \} ds\right). \end{array}\tag{3}
For the baseline hazard in (2) we consider the Weibull model or a more flexible model where the baseline hazard is approximated using splines. The Weibull baseline is given by: h_0(t)=\lambda kt^{k-1},\tag{4}
where is the scale parameter, and is the shape parameter. For the baseline hazard using splines, we have: \log h_0(t)=\boldsymbol{\lambda}_0+\sum_{k=1}^K \boldsymbol{\lambda}_{k} B_k(t,q).\tag{5}
Here, are the spline coefficients, is a -spline basis function, denotes the degree of the -spline basis function, and where is the number of interior knots.
In the joint model, it is assumed that the vector of time-independent random effects underlies both the longitudinal and survival processes. This means that conditioning on the shared random effects the joint likelihood for unknown parameters can be formulated as separate models for the longitudinal payment process and the settlement process. The parameters of the joint model are estimated using a likelihood-based method. See Okine, Frees, and Shi (2021) for more on the joint likelihood estimation.
The GLMM framework for the longitudinal submodel employed in (1) and the proportional hazard model framework employed for the survival submodel in (2) are very common in the actuarial and statistics literature. But the longitudinal model framework can be extended to handle heavy-tailed distributions such as the Pareto, and generalized beta distributions. For example, Rizopoulos, Papageorgiou, and Miranda Afonso (2022), under the Bayesian approach, develops the JMbayes2 R package for joint models that allow different distributions for the longitudinal model. It is worth noting that the choice of the distribution is an empirical problem. As discussed in Okine, Frees, and Shi (2021), goodness-of-fit tests need to be performed for the longitudinal model by analyzing the distribution and payment trend and the survival submodel by analyzing the baseline hazard model. The focus of this paper is showing the influence of environmental changes on the RBNS predictions via simulation studies hence the distribution choice in both the longitudinal and survival submodels will not be discussed further.
2.2. Prediction Using Joint Model
For the prediction of unpaid losses, the focus is on open claims at the valuation time. An open claim at valuation time implies that the settlement time and is marked by time since reporting longitudinal claim history With the fitted joint model, the RBNS reserve prediction for the th claim at the valuation time, can be obtained using the following steps from Okine, Frees, and Shi (2021):
-
Predict the future time when the th claim will be settled, given and using an estimate of the conditional survival probability shown as:
\hat{\pi}_i(u |c_i)=\frac{\hat{S}_i\left(u|\hat{\eta}_{iu},\boldsymbol{w}_{iu};\boldsymbol{\hat{\theta}}\right)}{\hat{S}_i\left(c_i|\hat{\eta}_{ic_i},\boldsymbol{w}_{ic_i};\boldsymbol{\hat{\theta}}\right)},\tag{6}
where the is an estimate of (3) using the MLE estimates and Here, are the fixed effects maximum likelihood estimates and are the empirical Bayes estimate for the random effects. The time-to-settlement for a RBNS claim, is given by:
\hat{u}_i=\int_{c_i}^\infty \hat{\pi}_i(u |c_i) du.\tag{7}
-
Predict the ultimate payment, using i.e., the expected cumulative payments at future time for the th claim conditional on longitudinal claim history given by:
\hat{Y}_i(u)=g^{-1}(\boldsymbol{x}'_{iu}\boldsymbol{\hat{\beta}}+\boldsymbol{z}'_{iu}\boldsymbol{\hat{b}}_i).\tag{8}
Here, is the inverse of the link function, and are covariates. The point prediction of the ultimate amount of claim is given by the mean of all expected cumulative payments at simulated future times
-
With the cumulative payment for the th claim at valuation time, we have: \hat{R}_i^{RBNS}(c_i)=\hat{Y}_i^{ULT}(u)-Y_i(c_i).\tag{9}
The total RBNS reserve amount is given by:
\hat{R}^{RBNS}(c)=\sum_{i=1}^m\hat{R}_i^{RBNS}(c_i).\tag{10}
Here m be the number of open claims at the valuation time, i.e.
3. Prediction Performance Evaluation Under Steady State
To highlight the strength of the joint model in comparison to the chain-ladder model, we first explore the performance of prediction routines described in Section 2.2 under a steady state, i.e., when there are no changes in the insurer’s business that can affect loss reserving.
3.1. Simulation Design
In the simulation, the steady state is generated from the base model where the longitudinal submodel is assumed to be a gamma regression with dispersion parameter The conditional mean is specified as \begin{aligned} \eta_{it}&=g(E[Y_{it}|\boldsymbol{b}_i])\\&=\boldsymbol{x}_{it}'\boldsymbol{\beta}+ \boldsymbol{z}_{it}'\boldsymbol{b}_i\\&=\beta_{10}+t\beta_{11}+x_{i1}\beta_{12}\\&\quad+ x_{i2}\beta_{13}+ b_{i0}.\end{aligned}\tag{11}
where and are regression coefficients used in the model. The payment times are assumed to be exogenous and are set at We assume representing a discrete predictor and corresponding to a continuous predictor. We specify a random intercept longitudinal submodel, where only the intercept parameter in (11) is random, and all slope parameters are fixed. The random effects are generated from a normal distribution The proportional hazards model with an exponential baseline model is employed for the survival submodel, where the payment-settlement association is induced through the effects of on the hazard of settlement. Specifically, the conditional hazard function is:
\small\begin{aligned}
\begin{array}{rl}
h_i(t|\eta_{it},\boldsymbol{w}_{it} )=&h_0(t)\exp\{\gamma_1x_{i1}+\gamma_2x_{i2} +\alpha \eta_{it}\} \quad \\& \mbox{and} \quad h_0(t)=\lambda.
\end{array}\end{aligned}\tag{12}
Here, hence The parameters used in data generation are summarized in Table 1. The claims are evenly and independently distributed among ten accident years, and the censoring time is the end of calendar year ten. See Algorithm 1 for a routine to construct the training and validation data in the simulation study based on the work of Sweeting and Thompson (2011). The Online Supplementary Materials provides sample R code for estimation and prediction based on simulated data.
3.2. Parameter Estimates
For the parameter estimation, we examine different sample sizes (number of claims) and report the results for N=500, 1000, and 1500 based on replications in Table 1. For each simulated sample, the parameter estimates and the associated standard error are obtained using the likelihood-based method.
We present the average bias (Bias), the average standard error (SE) of the estimates, the nominal standard deviation of the point estimates (SD), and report the standard deviation of the average bias calculated as SD/ We show in the table that both the estimate and the uncertainty of the average bias decrease as sample size increases, and that the bias in estimating parameters from the joint model is negligible. Further, the accuracy of the variance estimates is indicated by the similarity of the average standard error and the nominal standard deviation.
3.3. RBNS Prediction
Table 2 shows the average of the mean (Mean) and standard deviation (SD) of both settlement time and ultimate paid losses by accident year. As expected in the steady state, the distribution of both outcomes are stable over time. The results of reserving prediction from both the chain-ladder method and the joint model are displayed in Table 3. The table shows the true RBNS reserve, the estimated RBNS reserve, the error (estimated RBNS reserve minus the true RBNS reserve) as a percentage of the true RBNS reserve, and the standard error of prediction divided by the number of replications Not surprisingly, the chain-ladder method performs well under the steady state with a percentage error of 4.30%, although the joint model produced a superior percentage error of 0.55%. Despite the point prediction from the chain-ladder and joint model being close, it is worth stressing the difference in the predictive uncertainty from the two models. To illustrate this, we present in the top left panel of Figure 1 the predictive distribution of reserve errors. The data aggregation in the chain-ladder leads to information loss, which explains the higher predictive uncertainty compared to the joint model.

4. Prediction Performance Evaluation Under Different Environmental Changes
This section investigates the effects of environmental changes on reserving prediction. It is well known that the industry benchmark chain-ladder method relies on a stable environment, and is expected to fail when the insurer undergoes significant operational changes that change the claim development pattern. In contrast, individual-level reserving methods leverage granular claims level data and are thus capable of capturing such changes and reflecting them in predicting unpaid losses. We show that the joint model can easily accommodate environmental changes that affect reserving prediction. We consider various examples of environmental changes including changes in the underwriting criteria, claim processing, and product mix.
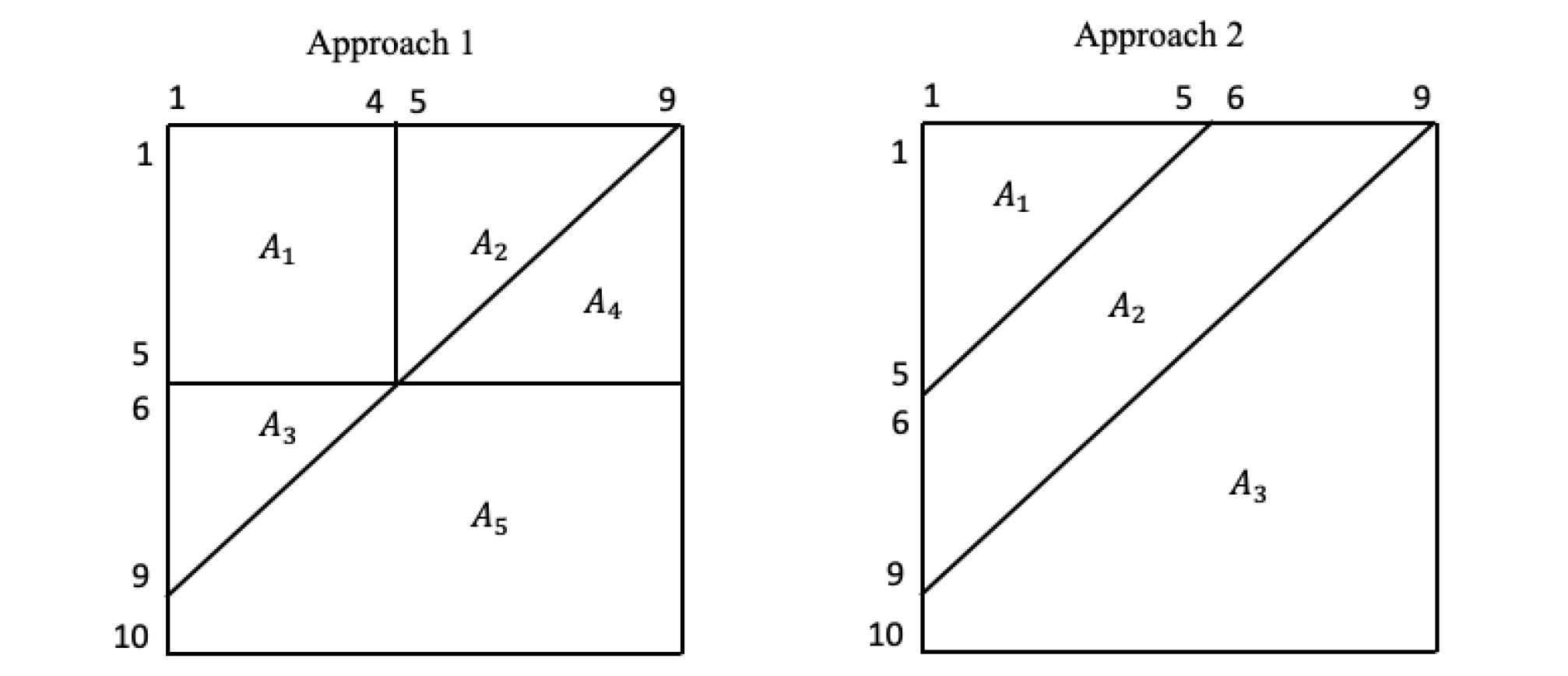
We also provide results using trended chain-ladder techniques. The trending techniques treat environmental changes as a trend to adjust the development projections. Berquist and Sherman (1977) presented case studies using a portfolio of U.S. medical malpractice insurance and selected trends to adjust for changes in operations based on a review of the insurer and industry’s historical experience. Here, we use a simple trending algorithm, following the work of Jin (2014), to estimate the trend rate and use the estimated trend rate to make appropriate adjustments prior to the application of traditional development techniques. Because the trending techniques are ad hoc and highly dependent on actuaries’ judgments, we provide results using two trending techniques. The first approach assumes that the actuaries are sure of the type of trend that they are dealing with; hence the trending technique accurately captures the environmental changes. Further, the second approach assumes actuaries are not sure of the trend and, therefore, do not accurately capture the environmental changes. See Appendix for details on the trending techniques. Other frequently used macro-level methods such as the Bornhuetter-Ferguson and Cape Cod techniques are based on the expected claim technique and, as such, are also highly dependent on actuaries’ judgments.
Environmental changes are implemented by using appropriate covariates in either the longitudinal submodel or the survival submodel or both. Table 4 provides a brief description of the scenarios that we consider in the numerical experiments. All the prediction results in this section are based on sample size and S=150 replications.
4.1. Change in Underwriting Practices
The first scenario of environmental changes that we consider is due to changes in underwriting practices. Insurers use underwriting to evaluate exposures of potential risks, and decide whether the risk is acceptable and how much coverage to provide. The underwriting practice could change due to either changes in the insurer’s underwriting guidelines or changes in the regulation. The change in underwriting practice only affects new risks but not existing risks, leading to a shift in the risk profile of the insurer’s book. In the reserving context, one would expect a change in loss ratios across accident years.
To implement the change in underwriting practice in simulation, we modify the mean structure of the longitudinal submodel by adding an additional covariate so that
\begin{align} \eta_{it}=&g(E[Y_{it}|\boldsymbol{b}_i])\\=&\boldsymbol{x}_{it}'\boldsymbol{\beta}+ \boldsymbol{z}_{it}'\boldsymbol{b}_i\\=&\beta_{10}+t\beta_{11}+x_{i1}\beta_{12}\\&+ x_{i2}\beta_{13}+x_{i3}\beta_{14}+ b_{i0}.\end{align}\tag{13}
The covariate is a binary variable that captures the change in the loss ratio across accident years. In the experiment, we set for accident years 1-5, and for accident years 6-10, i.e. the shift in loss ratio occurs in accident year 6. The regression coefficient controls the direction of the change. A positive (negative) value corresponds to a loosened (tightened) underwriting criteria and thus an increase (decrease) in the loss ratio.
We report the prediction results for Table 5 shows the descriptive statistics of ultimate paid losses and settlement time by accident year. A structural change in the loss amount and the corresponding change in the settlement process over time are observed. Table 6 compares the reserve prediction from the chain-ladder method and the joint model. The chain-ladder method does not capture the deteriorating loss ratio in most recent accident years, and thus the projection based on the lower loss ratio significantly underpredicts unpaid losses. In this specific simulation setting, the chain-ladder prediction error is -21.10% . In contrast, actuaries can easily incorporate the information of the change in underwriting in the specification of the joint model and thus adjust for such environmental change in the reserving prediction. Also, though the trended chain-ladder technique (Approach 1), which assumes the actuary is sure of the trend they are dealing with, improved the point estimate, it increased the prediction uncertainty. As expected, the trended chain-ladder technique (Approach 2), which assumes the actuary is not sure of the trend they are dealing with, did not improve the point estimate. The predictive distribution of reserve errors is presented in Figure 1, where one observes the bias and high uncertainty in the basic chain-ladder prediction and a higher uncertainty in the trended chain-ladder (Approach 1) prediction.
We also investigate the case as a result of tightening underwriting criteria. As reported in Table 7, the chain-ladder method overestimates the unpaid losses, as anticipated.
4.2. Changes in Claims Processing
Another common scenario of environmental change relates to the claim service. How claims are handled could be quite different from one insurer to another. Any change in the operation of claim management that affects the speed claims are settled will have a impact on reserving prediction. Such operational changes could be due to both internal or external reasons. For example, a catastrophic loss event could cause a backlog of claims due to short of staffing and thus lead to slowdown in the claim settlement, or an adoption of new information system or technology to streamline claim management that speeds up claim settlement. Another important reason is simply the philosophy in claim processing, for instance, claims could be prioritized based on either their sizes or the order they arrive, and claim adjusters could be assigned based on either the workload or the experience of adjusters.
To reflect the change in claim processing and thus the claim settlement speed, we modify the survival submodel in the data generating process by adding a covariate to indicate the change. It is worth noting the subtle difference in the effects of change in claim processing and change in underwriting criteria. The difference is in the timing. In a run-off triangle, the change in claim processing affects claims along calender years while the change in underwriting criteria affects claims along accident years; this is because the former applies to both existing and new policies and the latter only applies to new policies. we consider the survival submodel:
\small \begin{array}{rl} h_i(t|\eta_{it},\boldsymbol{w}_{it} )=h_0(t)\exp\{\gamma_1x_{i1}+\gamma_2x_{i2}+\gamma_3x_{i3t} +\alpha \eta_{it}\}, \end{array}\tag{14}
where if the payment time is in calendar years 1-5, and if the payment time is in calendar years 6-10. The coefficient measures the effects on the settlement speed, with a negative value indicating slowdown and a positive value speedup.
To illustrate the change of claim processing, we report in Table 8 the descriptive statistics of ultimate paid losses and settlement delay by accident year when setting One observes that the change affects the settlement time, with a negligible impact on the ultimate payments for claims. Table 9 reports the corresponding prediction error for RBNS reserves for both chain-ladder and the joint model. Because the chain-ladder assumes the same settlement speed even when the claims are actually closed faster, it overestimates the unpaid losses provided payment pattern stays the same. Again, the trended chain-ladder technique (Approach 1) improved the point estimate and increased the prediction uncertainty. The bottom left panel of Figure 1 provides the predictive distributions of reserve errors for the two models and shows a lower predictive uncertainty for the joint model.
4.3. Changes in Product Mix
In the last scenario, we consider the effects of a change in the product mix in the insurer’s book on the reserving prediction. Insurance products vary by the nature of the covered risks that could affect both the outstanding payments and the settlement delay. The product mix of an insurer’s portfolio could change due to the change in the target markets. For instance, an insurer who provides workers’ compensation could shift from low-risk to high-risk occupation class; or a property insurer could decide to expand to write liability insurance; or an insurer could switch target customers from one geographical region to another, etc.
In the simulation, we focus on a situation where the insurer increases exposure in long-tail businesses and reduces exposure in short-tail businesses. Because long-tail lines of business are usually associated with longer settlement and higher losses, we postulate that the change in exposure will increase both outstanding payments and time-to-settlement. To implement this change in the simulation, we use an indicator to indicate the timing of the change in both the longitudinal and survival submodels as below:
\begin{aligned}
\eta_{it}=& g(E[Y_{it}|\boldsymbol{b}_i])=\boldsymbol{x}_{it}'\boldsymbol{\beta} + \boldsymbol{z}_{it}'\boldsymbol{b}_i\\=&\beta_{10} +t\beta_{11}+x_{i1}\beta_{12}+ x_{i2}\beta_{13}\\&+x_{i3}\beta_{14}+ b_{i0}.\end{aligned}\tag{15}
\small \begin{array}{rl} h_i(t|\eta_{it},\boldsymbol{w}_{it} )=h_0(t)\exp\{\gamma_1x_{i1}+\gamma_2x_{i2}+\gamma_3x_{i3} +\alpha \eta_{it}\}. \end{array}\tag{16}
The regression coefficients and quantify the effects on the losses and settlement delay, respectively. Assuming the exposure change takes place in the sixth year, we set for accident years 1-5, and for accident years 6-10. Further we set and to reflect the expectation of larger ultimate losses and longer settlement time due to increasing exposure in long-tail lines of business.
Table 10 summarizes the average of the mean and standard deviation for both ultimate losses and settlement time by accident year. Because of the change in product mix, we observe an increase in both ultimate payments and settlement time starting from the sixth accident year. Note that for simplicity we implement the change as an exogenous shock, i.e. the insurer’s new portfolio is formed in the 6th year and is fixed afterwards. A gradual transition to the steady state of the new portfolio could be easily handled using an interaction with the time trend.
Reserve predictions from the chain-ladder method and the joint model are reported in Table 11. Once again, reserving error of the chain-ladder prediction is substantial. Specifically, the chain-ladder underestimates the unpaid loss considerably, because it applies the loss development pattern of short-tailed lines to the business with long-tails without adjustment for the change in the product mix. The trended chain-ladder technique (Approach 1) accurately captures the development pattern changes, hence producing an improved reserve prediction. Because of the limitations of the trending technique, the reserve uncertainty increased significantly. The joint model offers a framework to explicitly accommodate such changes in the model building stage, and thus makes the correction for the product mix change in the reserving prediction as illustrated in the predictive distribution of reserve errors in the bottom right panel of Figure 1.
5. Conclusion
In this paper, by employing the joint model, we showed that micro-level reserving methods could easily accommodate environmental changes such as a change in underwriting criteria, business mix, and claim processing, among others. Using carefully designed simulation studies, we showed that the industry benchmark chain-ladder method without adjusting for the environmental changes produced a substantial error in reserving prediction. The application of trending techniques under the macro-level framework leads to unbiased point reserve estimates and increased prediction uncertainty.
Historically, one main argument against micro-level models like the joint model over the years is that they are more difficult to implement in practice. However, with the growth in computing power in this era of big data analytics, insurance companies will enjoy a lesser burden with regard to implementation. Particularly, large companies with sophisticated personnel who are comfortable handling complex machine learning/AI-type algorithms can implement and take advantage of micro-level models.
