


1. Introduction
Many complex networks, such as cyberspace, the Internet, power grids, are critical infrastructures for commerce and communications that require extremely high reliability and safety standard. Significant attacks or failures on those complex networks could cause serious damage to society. Insurance is one of the possible ways to manage risk exposure for these complex networks. For example, cybersecurity insurance is designed to mitigate losses from a variety of cyber incidents, including data breaches, business interruption, and network damage (Department of Homeland Security 2019). In 2013, the Group of Twenty (G-20) urged to treat cyber-attacks as a threat to the global economy (Ackerman 2013). For the data and statistics from government, industry, and information technology related to the current state of cybersecurity threats in the United States and internationally, one can refer to (Tehan 2015). Recently, (Böhme, Laube, and Riek 2019) provided a general framework for actuaries to think about cyber risk and the approaches to cyber risk analysis. In this paper, “cyberspace” refers to the interactive domain composed of all digital networks used to store, modify, and communicate information, and the term “cyber risk” refers to a multitude of different sources of risk affecting the information and technology assets of a company (Biener, Eling, and Wirfs 2014). Since the internet is one of the most complex systems humanity has ever devised, cyber risk management becomes a prominent issue for society, especially for insurance companies (Zurich Insurance Company Ltd and Atlantic Council of the United States 2014). However, research on cyber risk, especially on evaluation and comparison of the risks in the insurance domain, is fairly limited. In addition, pricing for cybersecutiry insurance is a challenging problem since sybersecutiry insurance has no standard scoring systems or actuarial tables for rate making (Xu and Hua 2017). Moreover, there is a lack of open-source data for organizations’ internal networks for security breaches and losses due to the disinclination of organizations to disclose details of security breaches. As Böhme, Laube, and Riek (2019) pointed out, understanding cyber risk is a hard problem, therefore, comprehending how vulnerable is a cyber or physical network to attacks or failures and assessing the risks of a complex network is of great interest. There is an urgent need to develop advanced methodologies that can systematically assess the risk, robustness, reliability, or loss of availability of a network and comparing the risk and robustness of different networks.
Cyber risk is a fundamental measurement providing a quantitative measure of the security level, the capability of capturing attacks, and the lost of availability that results in loss of integrity and availability (Biener, Eling, and Wirfs 2014; Böhme, Laube, and Riek 2019). To evaluate the loss of availability of cyber networks, various heuristic methods were proposed to measure the resilience of cyber networks under malicious cyber attacks (Vespignani 2010; Havlin et al. 2014). However, those heuristic methods are often designed for a specific cyber network, which limited their applicability to diverse areas (Kotenko, Saenko, and Lauta 2018). In general, metric-based approaches use specific measures of individual properties of cyber system components to access resilience. For example, when evaluating the resilience of a computer system, (Ganin et al. 2016) considered the percentage of computers that are functioning and the ratio of a system’s actual flow to its maximum capacity for measuring resilience. This metric-based approach may not be appropriate for systems that the connections between the nodes (computers) have an important effect on the resilience of the system. Therefore, some high-order structures and topological measures of a network should be considered.
In managing cyber risk in the insurance domain, different tools and methods have been proposed for evaluating the network robustness in the past decades, however, algorithms/techniques based on statistical models and stochastic processes have not been broadly developed. In this paper, we aim to develop dependable and flexible statistical models and hypothesis testing procedures to assess the risk and robustness of a complex network which can provide useful information for cyber insurance providers. Specifically, we propose a modified Wiener process model with several statistical hypothesis testing procedures for this purpose. The Wiener process model is one of the widely used stochastic models for non-monotonic degradation processes which can provide a good description of the system’s behavior in the cascading failure process (Doksum, Hóyland, and Hoyland 1992; Chen et al. 2017; Lio et al. 2019). Compared with observing dynamics of the topological measures under attacks, the proposed modified Wiener process model can model the evolution of the degradation data in each network topological measure and also provide great flexibility in degradation modeling, e.g., non-linear degradation mechanisms. The proposed methodologies will expand the actuarial knowledge on the evaluation and comparison of risks for different physical and/or cyber networks and cybersecurity insurance pricing models.
The rest of this paper is organized as follows. In Section 2, the graph representation of the cyber network and the topological measures for evaluating the robustness/loss of availability of a network are discussed. In Section 3, the proposed Wiener process model for modeling the dynamics of a cyber network losing its functionality/connectivity upon the removal of nodes is presented. The proposed statistical testing procedures for comparing the risks of two networks are also presented in Section 3. In Section 4, illustrative examples based on real data sets of the Gnutella peer-to-peer (P2P) cyber networks and sampled subgraphs from the Enron email network are given in Section 4. A Monte Carlo simulation study is used to evaluate the performance of the proposed model and methods in Section 5. The performance and limitations of the proposed methods are discussed. Finally, in Section 6, some concluding remarks are provided.
2. Graph Representation of Cyber Network
Inherently, a cyber network, such as the P2P cyber network, can be viewed as a graph structure consisting of nodes and edges. For example, in a P2P cyber network, the hosts are considered as nodes in a graph, and the host’s neighbor set is described by the set of edges in a graph. A graph structure can be represented as where is a node set with cardinality (the number of elements in a set) of is an edge set, and is the adjacency matrix of which is an nonnegative symmetric matrix with entries i.e., for any and otherwise. In the study of cyber network, we consider unweighted and undirected graph, i.e., and for all Hence, we suppress the notation of the adjacency matrix in the graph representation and represent the graph as
To evaluate the robustness/loss of availability of a network, the decrease of network performance due to a selected removal of nodes or edges is considered. For example, in cyberspace, computers and hand-held devices are connected to servers over active Internet signals or local area network (LAN) lines. In this case, those computers, hand-held devices, and servers are the nodes and the LAN lines and Internet signals are edges of the network graph of interest. The failure of a server or broken LAN lines (due to physical or cyber attacks, or human errors) will reduce the functionality of the cyber network.
High-order structures are often called the building blocks of network (Maison et al. 2002). Compared with global network topology (e.g., graph diameter and average path length) (Cohen et al. 2000; Piraveenan, Uddin, and Chung 2012; Cuadra et al. 2015), through studying the high-order structures, we can capture more local information of network structure. For instance, feedforward loops have proven fundamental to understanding the mechanism of transcriptional regulation networks (Shen-Orr et al. 2002). Here, the robustness of a cyber network can be defined as the ability of a network to maintain its functionality/connectivity when it is subject to failure or attack. There is a variety of graph measures that provide robustness measures on a network (Newman 2010). For example, vertex connectivity is defined as the minimum number of vertices that need to be removed to disconnect the graph and the average cluster coefficient that represents the probability that neighbors of a node are also connected (Holland and Leinhardt 1971; Watts and Strogatz 1998). Another commonly used robustness measure is the network motifs introduced by (Milo et al. 2002) in conjunction with the assessment of the stability of biological networks and later have been studied in a variety of contexts (Alon 2007). Network motifs are subgraphs (smaller patterns) that the numbers of appearances are statistically significantly greater than a predefined threshold in a randomized network. A motif here is broadly defined as a recurrent multi-node subgraph pattern. Formally, a motif is an induced subgraph of Figure 1 shows all possible 4-node motifs in undirected graph. Recently, Dey, Gel, and Poor (2019) focused on incorporating network motifs to evaluate and estimate the power system reliability with the help of statistical models.

To obtain the exact motif counts of different motif types in a specific -size motif in a network, the RANDESU motif finder algorithm (Holland and Leinhardt 1970) can be used. For large network (> 10,000 edges), algorithms to approximate the exact motif counts can be used (Kashtan et al. 2004; Böhme, Laube, and Riek 2019), which introduces another layer of randomness in the data whereas suitable statistical models and techniques are required. To assess the robustness of a complex network like the cyber network, we focus on remaining motif distributions under various attacks like the physical or cyber-attack and cascading failure of attacks.
3. Wiener Process Model and Similarity Tests for Networks
In this paper, we assume that either the exact or approximate measures of network robustness can be obtained and focus on the development of novel statistical algorithms to assess the robustness and the risk, as well as to compare the risks of different networks. Although the methods described here focuses on network motifs, the proposed methodologies can be applied to any topological measures of network robustness/risk such as the Wasserstein distance and the weighted-pairwise distance. The process of reducing the functionality of the physical or cyber networks under removal of nodes and/or edges can be viewed as a degradation process (Chen et al. 2017) and hence, novel statistical models and algorithms for degradation data analysis can be applied to evaluate and compare the risks of different complex networks.
In this section, we investigate how local topological features (e.g., local network structures) evolve under the removal of nodes and/or edges. Our main postulate here is that a complex system can be considered more resilient if it tends to preserve its original properties longer under the removal of nodes and/or edges, and our primary focus is to quantify the risks of different networks through statistical modeling and analyses of the geometric properties of different network systems. A stochastic model, the Wiener process model, along with several statistical hypothesis testing procedures to compare the risks of different networks are developed. The mathematical notation and the Wiener process model are introduced in Section 3.1 and three statistical hypothesis testing procedures are proposed in Section 3.2.
3.1. Wiener process model
Suppose that there are networks and different topological features (e.g., network motifs, Wasserstein distance, and weighted-pairwise distance, etc.) are used to measure the risks of those networks, these topological features are observed at different time points where is the total number of observation points. The observation point can be considered as a specific fraction of random/selective nodes (e.g., nodes with the highest degrees or nodes with the largest betweenness) being removed from the network. We denote the observed value of the -th topological feature for network at the -th time point as For example, consider the 4-node motif in Figure 1 as the -th topological feature, then is the number of the 4-node motif in network when all the nodes and edges in the network are fully functioning (i.e., at time is the number of the 4-node motif in network when 10% of the nodes and edges in the network are removed (say, at time is the number of the 4-node motif in network when 20% of the nodes and edges in the network are removed (say, at time and so on.
Since the dynamics of the local topological measures upon removal of the nodes/edges may not necessarily be a monotonic deterioration process and due to the stochastic nature of this process, we thus propose using the Wiener process model to characterize the degradation paths of those topological measures of a complex network. We consider modeling the degeneration process of the functionality of the -th network based on the -th topological measure by using a Wiener process with drift parameter and diffusion coefficient Specifically, we consider as a stochastic process which is characterized by the following properties:
(i)
(ii) has stable independent increments, i.e., the increments are independent;
(iii) the increments follows a normal distribution
Since different topological measures may share similar characteristics, therefore, we modify the Wiener process model by introducing a correlation structure among the topological measures. Based on the modified Wiener process model, in our study, we define a -dimensional vector of random variables where and assume that the degradation process follows a Wiener process with drift and variance-covariance In other words, the -dimensional vector of random variables follows a -dimensional multivariate normal distribution denoted as
MW:xxi,k∼NJ(μμi,ΣΣi),
where represents the slope of the linear drift and represents an symmetric variance-covariance matrix
ΣΣi=(σi,11σi,12⋯σi,1Jσi,22⋯σi,2J⋱⋮σi,JJ)
which is also known as the diffusion coefficient. The joint probability density function of the random vector is
f(xxi,k;μμi,ΣΣi)=1(2π)J/2|ΣΣi|1/2exp{(xxi,k−μμi)′ΣΣ−1i(xxi,k−μμi)2},
for Under this setting, the log-likelihood function can be expressed
lnL(θθ|xx)=I∑i=1lnLi(θθi|xxi),
where
lnL(θθi∣xxi)=K∑k=1[−J2ln(2π)−12ln(|Σi|)−12(xxi,k−μμi)′Σ−1i(xxi,k−μμi)],
and = is an positive-semidefinite matrix is the parameter vector for the -th network. The maximum likelihood estimates (MLEs) of the model parameters can be obtained by maximizing in Eq. (5) with respect to and Iterative numerical algorithms for solving a non-linear system of equations with constraints, such as the limited-memory Broyden-Fletcher-Goldfarb-Shanno algorithm for box constraints (L-BFGS-B algorithm), can be utilized here to obtain the MLEs.
3.2. Similarity tests for two complex networks
In this subsection, we consider three different statistical procedures for testing the similarity of two complex networks (say, Network 1 and Network 2) in terms of their resilience/risk level based on the topological measures. We are interested in testing the hypotheses
H0:Network 1 and Network 2have the same resilience/risk levelagainst H1:Network 1 and Network 2do not have the same resilience/risk level
3.2.1. A test procedure based on resampling
The first proposed testing procedure is based on the Euclidean distance of degradation curves with resampling approach. Based on the observed degradation measurements and from Network 1 and Network 2, respectively, the algorithm to compute the -value for testing the hypotheses in (6) is described here. We name this procedure as Procedure A.
Step A1: Compute the Euclidean distance between and for the two networks: dobs=dobs(→xx1,→xx2)=[K∑k=1J∑j=1(xx1,k−xx2,k)2]1/2.
Step A2: Combine the two sets of observed degradation measurements and denote the combined data set as Based on the Wiener process model in Eq. (1), obtain the MLE of by maximizing the log-likelihood function in Eq. (5) with respect to The MLE of based on the combined data set under in (6) is denoted by
Step A3: Generate and from a -dimensional multivariate normal distribution for to obtain the parametric bootstrap samples and respectively.
Step A4: Compute the Euclidean distance between the two parametric bootstrap samples and as d(1)=d(1)(→xx(1)1,→xx(1)2)=[K∑k=1J∑j=1(xx(1)1,k−xx(1)2,k)2]1/2.
Step A5: Repeat Steps A3–A4 times to obtain a sequence of bootstrap Euclidean distances, for
Step A6: The -value of the test is computed as pA=1BB∑b=11{dobs>d(b)}, where is an indicator function defined as if event is true and otherwise.
The null hypothesis in (6) is rejected if where is a prefixed significant level. Note that Procedure A only uses the Wiener process model in the resampling process in Steps A3 and A4. In this procedure, we use the Euclidean distance as a measure of the distance between two vectors, however, other types of distance metrics such as the Manhattan distance can be used in place of the Euclidean distance.
3.2.2. Test procedures based on likelihood ratio test statistic
Under the Wiener process model described in Section 3.1, the hypotheses in (6) can be expressed as
H0:μμ1=μμ2=μμ and ΣΣ1=ΣΣ2=ΣΣ against H1:μμ1≠μμ2 or ΣΣ1≠ΣΣ2.
Let be the MLE of the that maximizes the log-likelihood function in Eq. (5) with respect to based on the data i.e.,
ˆθˆθi=argmaxθθilnL(θθi,→xxi),
for Similarly, based on the combined data set the MLE of that maximizes the log-likelihood function in Eq. (5) with respect to under in (7) is denoted as i.e.,
\hat{\boldsymbol{\theta}}_C=\underset{\boldsymbol{\theta}_C}{\arg \max } \ln L\left(\boldsymbol{\theta}_C, \overrightarrow{\boldsymbol{x}}_C\right) . \tag{9}
The likelihood ratio test statistic based on and is defined as
\Lambda\left(\overrightarrow{\pmb{x}}_1, \overrightarrow{\pmb{x}}_2\right)=-2 \ln \left[\frac{L\left(\hat{\pmb{\theta}}_C, \overrightarrow{\pmb{x}}_C\right)}{L\left(\hat{\pmb{\theta}}_1, \overrightarrow{\pmb{x}}_1\right) \times L\left(\hat{\pmb{\theta}}_2, \overrightarrow{\pmb{x}}_2\right)}\right] . \tag{10}
The Neyman–Pearson lemma states that the likelihood ratio test is the most powerful test at significance level As the sample size approaches the test statistic is asymptotically chi-squared distribution with degrees of freedom Two statistical hypothesis test procedures, namely Procedure B1 and Procedure B2, are developed here based on the likelihood ratio test statistic in Eq. (10). The -value of Procedure B1 is obtained based on the asymptotic distribution of the likelihood ratio test statistic while the -value of Procedure B2 is obtained based on resampling technique.
Based on the observed degradation measurements and from Network 1 and Network 2, respectively, the algorithm to computer the -value for Procedures B1 and B2 can be described as follows:
Step B1: Obtain the MLE of from based on Eq. (8).
Step B2: Combine the two sets of observed degradation measurements and obtain the MLE of from based on Eq. (9).
Step B3: Compute the likelihood ratio test statistic from Eq. (10).
Step B4: For Procedure B1, the -value is computed as
p_{B1} = \Pr(W \lt \Lambda_{obs})
where is random variable that follows a chi-square distribution with degrees of freedom
Step B5: Generate and from a -dimensional multivariate normal distribution for to obtain the parametric bootstrap samples and respectively.
Step B6: Compute the likelihood ratio test statistic based on the two parametric bootstrap samples as from Eq. (10).
Step B7: Repeat Steps B4’–B5’ times to obtain a sequence of bootstrap likelihood ratio test statistics, for
Step B8: For Procedure B2, the -value is computed as
p_{B2} = \frac{1}{B} \sum\limits_{b = 1}^{B} 1_{\{\Lambda_{obs} < \Lambda^{(b)}\}}.
The null hypothesis in (7) is rejected if for Procedure B1, and if for Procedure B2, where is a prefixed significant level.
4. Practical Data Analysis
In this section, we illustrate the proposed model and methods by analyzing two real network data sets for P2P service and email systems, which are two kinds of cyber systems that requires cybersecurity insurance. The background of the network data sets is presented in Section 4.1.1 and Section 4.2.1, and the results and discussions of the data analysis are presented in Section 4.1.2 and Section 4.2.2.
We also provide an illustration of actuarial applications of the proposed methodologies based on the P2P networks in Section 4.1.3.
4.1. Peer-to-peer network
4.1.1. Background of the peer-to-peer network datasets
In recent years, digital currency electronic payment has become more popular, and hence, many countries and companies are committed to strengthening security in digital payments to gain customer’s confidence. The number of people sending money using P2P payments was up 116% and the transactions increased by 207% in 2019 compared with the previous year (PYMNTS 2020). P2P networks are also used for sharing electronic files and digital media. Cybersecurity insurance is an indispensable part of the digital currency electronic payment and file-sharing system, especially for the P2P payments/services (Gao et al. 2005; Chandra, Srivastava, and Theng 2010; Kalinic et al. 2019; Lara-Rubio, Villarejo-Ramos, and Liébana-Cabanillas 2020) and the blockchain ecosystem which has a large number of clients and servers. Evaluating the reliability of the P2P systems is an important issue for P2P service providers since scammers can destruct the P2P platform.
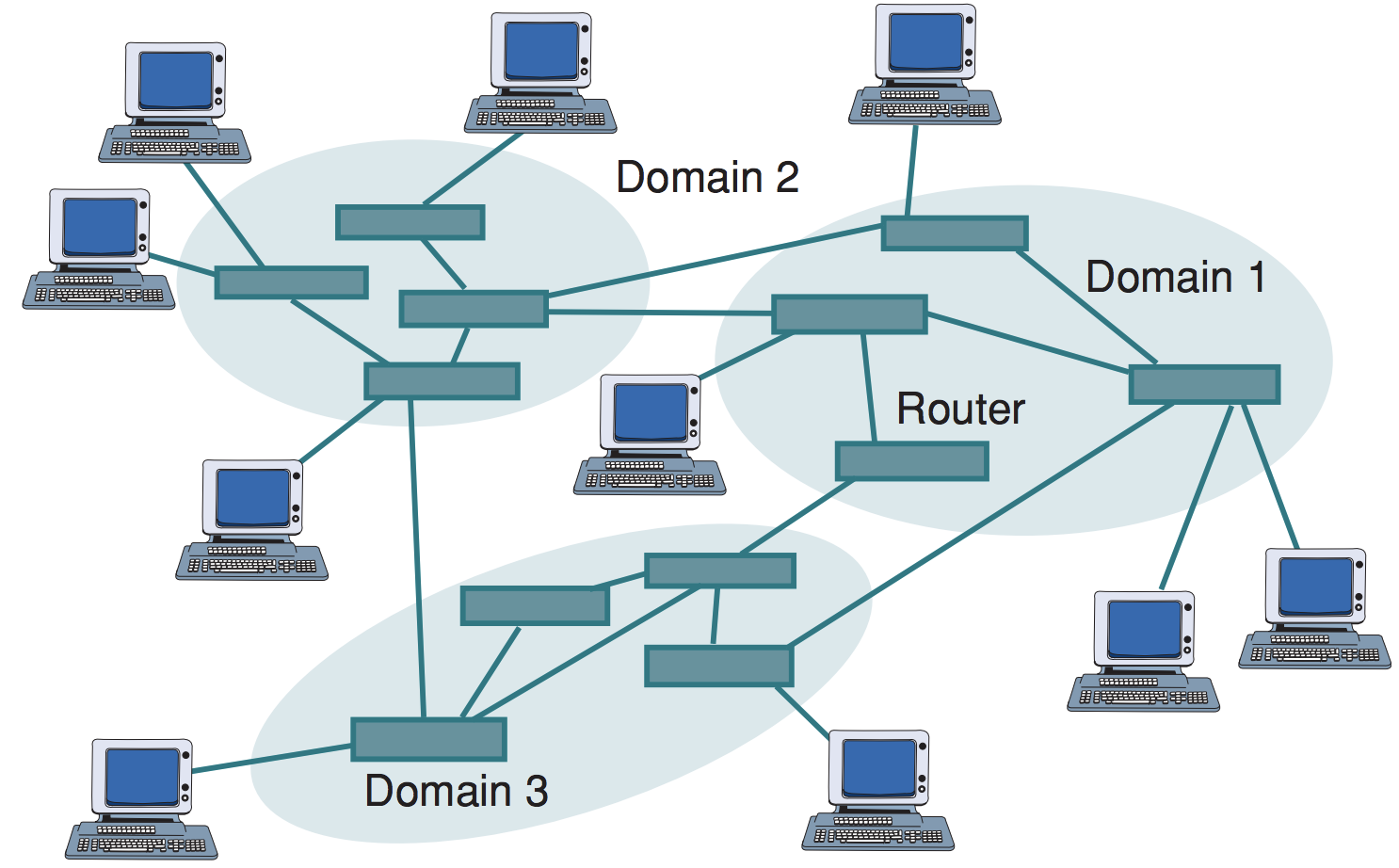
Gnutella is an open, decentralized, distributed, P2P search protocol that mainly used to find files (M. Ripeanu 2001). A P2P system can be considered as a cyber network in which individual computers connect directly with each other and share information and resources without using dedicated servers. The nodes in Gnutella perform tasks normally associated with both servers and clients. The nodes provide the client-side interfaces that users can issue queries and accept queries from other users. A synopsis of the network structure of a P2P system is illustrated in Figure 2. For illustrative purposes, in this example, we consider three snapshots of the Gnutella network collected on August 4, 6, and 9, 2002 from the Stanford Network Analysis Project (SNAP) (Leskovec, Kleinberg, and Faloutsos 2007; Matei Matei Ripeanu and Foster 2002). For notation convenience, we denote the Gnutella networks collected on August 4, 6, and 9, 2002 as P2P network by and respectively.

Here, nodes represent hosts in the Gnutella network topology and edges represent connections between the Gnutella hosts. The basic network structure information of the three Gnutella computer networks are presented in Table 1.
In this example, since P2P networks do not have fixed client and servers and the roles of peer nodes would be always changed across different days, the nodes (computers) in the P2P system are not likely to be the same on the three different dates. Therefore, it is reasonable to assume that the P2P network snapshots on August 4, 6, and 9, 2002 are independent and they are three cyber networks with different structures. We are interested in evaluating and comparing the risks of these three networks with different structures for the purpose of determining appropriate cyber insurance policies. For instance, if we find that the three cyber networks are different in terms of risk and reliability, the cyber insurance premium for the network with the highest risk should be higher than the others.
4.1.2. Peer-to-peer network similarity analysis under degree-based attack
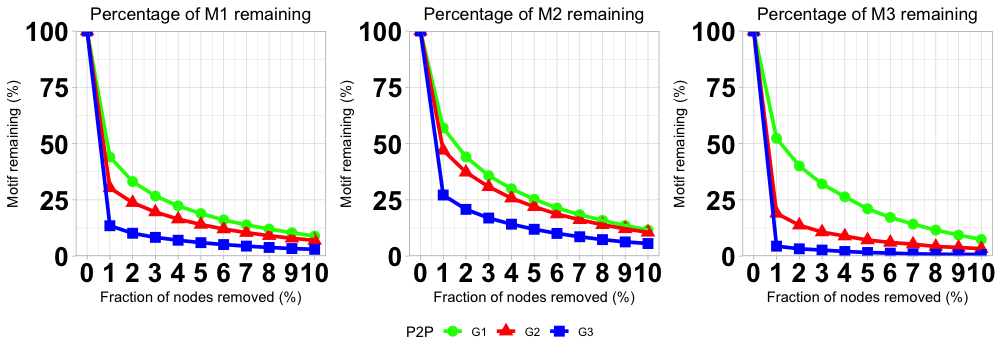
In this subsection, we apply the proposed Wiener process model and hypothesis testing procedures to assess and compare the cyber networks presented in Tables 1 in terms of the robustness and the risk of the cyber networks. The topological features for measuring the risks of the networks are the 4-node network motifs and presented in Figure 1. We remove the nodes in the cyber network based on the degree sequence of the graph (i.e., degree-based attacks), where the degree of a node in a graph is the number of edges that are connected to the node. In other words, the node with the largest degree will get removed first, and the counts of 4-node motifs are obtained when 1%, 2%, …, 10% of the nodes are removed. Figure 3 shows the dynamics of the degradation (in percentages) of the three 4-node motifs under degree-based attacks with observation points (including the initial status).
_of_the_three_4-node_motifs_of_the_three_n.png)
Following the notation defined in Section 3, corresponds to the counts of the 4-node motif when of the nodes are removed based on degree-based attack in cyber network and is a three-dimensional vector of random variables, where is assume to follow a trivariate normal distribution with mean vector and variance-covariance
For the Gnutella computer networks, the MLEs of the drift parameter and the diffusion coefficient for networks and under degree-based attack are presented in Table 2, where corresponding to the three 4-node motifs and respectively. The observed values of the test statistics and the corresponding -values based on Procedures A, B1 and B2 for the pairwise comparisons of the networks are presented in Tables 3. The number of bootstrap samples used in Procedure A and Procedure B2 is
Considering statistical significance at 5% level and compensating for multiple comparisons by using the Bonferroni correction (Bonferroni 1936), the -values presented in Table 3 that are smaller than are highlighted in bold to indicate the cases that the null hypothesis in (6) is rejected. From Table 3, we can see that all the three proposed testing procedures (Procedures A, B1, and B2) show that networks and are different in the resilience/risk levels, while networks and have no significant difference in the resilience/risk levels at the overall 5% significance level. For the comparison between networks and although the -value obtained from Procedure A is greater than the adjusted nominal significance level 0.01667, the small -values from the three test procedures suggests that networks and are different in terms of the resilience/risk levels.
From the estimates of the drift parameters presented in Table 2, we observe that for which indicates that the functionality of network drops slower than networks and network subject to the degree-based attacks. In other words, the smaller the values of the more robust (smaller the risk of) the P2P network. Thus, the results of the analysis based on the proposed methodologies suggest that network is the most reliable network among the three networks while networks and have similar risk levels. These conclusions agree with the observations obtained by looking at the graphs in Figure 3.
In this example, we can see that the proposed methodologies can qualify and compare the risks of different complex networks by using the -values of the hypothesis testing procedures as -value is in (0, 1), and the model parameter estimates. This information can be used in determining the premium of cybersecurity insurance. For example, based on the results in this example, the cybersecurity insurance premium for network should be lower than the premiums for networks and after adjusting for the sizes of those networks and other factors. In the next subsection, we construct concrete scenarios to illustrate how the proposed methodologies can be used to qualify the financial loss due to attack.
4.1.3. Actuarial Applications
In order to help the readers to understand how the proposed model and methods can be used in actuarial science to determine the premium for cybersecurity insurance, we construct several synthetic scenarios to illustrate the effectiveness of our proposed procedures and the role of network motifs on the resilience aspects of financial networks. Suppose each network described in Section 4.1.1 corresponds to a company providing P2P financial services and losing a network motif in the P2P network (i.e., a higher-order subgraph in the network) due to cyber-attack translates into a monetary loss to the company. For illustrative purposes, we simplify the problem by considering that the premium of cybersecurity insurance is determined based on (i) the size of the P2P network (the larger the network, the higher the premium); (ii) the cost of losing a network motif in the P2P network (the higher the cost of losing a network motif, the higher the premium); and (iii) the resilience/risk of the P2P network (the higher the risk, the higher the premium).
For the size of the P2P network, we assume that the premium is proportional to the number of nodes in the network. We further assume that the 4-node motifs and carry the same weight, but the cost incurred by losing a motif in the P2P network, which can be viewed as a group of customers and transactions, can be different for the three companies. We denote the cost of losing a motif in the P2P network for company with network as
For the case that there is no information on the resilience/risk levels of the three P2P networks, if the premium for company with network with 8114 nodes is $P3, then the premium for company with network with 10876 nodes can be determined as
\begin{aligned} \$P_{1} = \$P_{3} \times \left(\frac{10876}{8114} \right) \left(\frac{\mathcal{C}_1}{\mathcal{C}_3} \right), \end{aligned}
and the premium for company with network with 8717 nodes can be determined as
\begin{aligned} \$P_{2} = \$P_{3} \times \left(\frac{8717}{8114} \right) \left(\frac{\mathcal{C}_2}{\mathcal{C}_3} \right). \end{aligned}
Here, the values and can be viewed as the factor adjusted for the size of the network, and the values and can be viewed as the factor adjusted for the cost of losing a network motif in the P2P network.
The methodologies proposed in this paper can provide information on the resilience/risk levels of the three P2P networks by comparing the resilience/risk of these networks statistically which will lead to a more realistic approach to determining the premium of cybersecurity insurance. Specifically, based on the proposed model and methods, the results suggest that network is significantly more reliable than networks and and there is no significant difference between the risk levels of networks and Based on this information, we can conclude that the premium for the company with network should be \begin{aligned} \$P_{1} < \$P_{3} \times \left(\frac{10876}{8114} \right) \left(\frac{\mathcal{C}_1}{\mathcal{C}_3} \right). \end{aligned}
To obtain a factor that adjusted for the resilience/risk of the P2P network, based on the proposed methodologies in this paper, one possible way is to utilize the estimates from Table 2 by incorporating the decay rates. For example, from Table 2, we can obtain the average decay rate (i.e., average drift parameters), for companies with networks and as and respectively. Then, we can consider the factor to adjust the premium for company with network relative to the premium for company with network Note that other functions based on the estimates of the proposed modified Wiener process model can be used to construct a reasonable factor here.
The illustration here shows that the network motifs and our proposed statistical procedures can be applied in actuarial science with some reasonable explanations. In real practical applications of determining insurance premium, other factors that are relevant to cybersecurity insurance premium such as the country of the company providing P2P financial services registered in, losses covered/excluded by the insurance policy, security measures of the company, etc., should be considered (Romanosky et al. 2019).
4.2. Enron email network
4.2.1. Background of Enron email network
In the past few years, business email compromise (BEC) becomes one of the top cyber threats. According to the report from (American International Group (AIG) 2019), 23% of its 2018 cyber insurance claims in Europe, Middle East, and Africa (EMEA) region were BEC related. In this example, we consider the Enron email network data collected by the Cognitive Agent that Learns and Organizes (CALO) Project (Klimt and Yang 2004) which consists of more than half a million emails with 150 users sent over the period from May 1999 to July 2001. A node in the Enron email network represents an email address and an edge represents communication between two email addresses, i.e., there exists an edge between node and node if at least one email was sent in between email address and email address We define the Enron email network as an undirected graph where is a finite set of email addresses and is a set of edges (i.e., emails) with A snapshot of the Enron email network is presented in Figure 4.

In order to illustrate our proposed methodologies for evaluating the cybersecurity risk of the Enron email network, we generate three representative subgraphs by sampling nodes from the original Enron email network, i.e., randomly select nodes from the node set The numbers of nodes and the numbers of edges of these three subgraphs are presented in Table 4. Furthermore, due to the fact that the email addresses would be different at different time points, we assume that the sampled subgraphs are independent of each other. In a practical application to cybersecurity insurance pricing, we can consider three different companies with the email networks in Table 4 plan to insure their email networks and the insurance company needs to evaluate and compare the risks of these three email networks.
4.2.2. Enron email network security level evaluation under degree-based attack
In the evaluation and comparisons of the risks of the three email networks in Table 4, we consider the dynamics of three -node motif normalized concentrations (i.e., and under degree-based attack. The dynamics of the motifs and under degree-based attack for the three subgraphs and are presented in Figure 5.
_of_the_three_4-node_motifs_of_the_three_n.png)
For the three subgraphs sampled from the Enron email network, the MLEs of the drift parameter and the diffusion coefficient for networks and under degree-based attack are presented in Table 5, where corresponding to the three 4-node motifs and respectively. From Table 5, the estimates of the drift parameters, are consistent with the observations from the -node motif degradation curves presented in Figure 5. Specifically, except for motif the functionalities of networks and in terms of motifs decline more quickly than than the network as the fraction of nodes were removed. This suggests that the vanishing rates of the motifs are reflecting the robustness (security level) of the email networks. In general, the smaller the values of the higher the security level of the email network.
For the three Enron email networks, the observed values of the test statistics and the corresponding -values based on Procedures A, B1, and B2 for the pairwise comparisons of the networks are presented in Tables 6. The number of bootstrap samples used in Procedure A and Procedure B2 is In the analysis of the Enron networks, similar to the analysis of the Gnutella computer networks in Section 4.1.2, we utilize the Bonferroni correction for multiple comparisons, i.e., we can reject the null hypothesis if the corresponding -value is less than (highlighted in bold in Table 6). From Table 6, the results of the analysis based on the proposed methodologies suggest that networks and have different security levels, and have different security levels, and networks and have similar security levels. Since the smaller the values of the higher the security level of the email network, based on the estimates from Table 5, we can conclude that and are more robust than under the degree-based attacks. These conclusions agree with the observations obtained by looking at the graphs in Figure 5. Based on the results in this analysis, for insurance pricing, the premium for insuring networks and should be similar, while the premium for insuring network should be higher than and
5. Monte Carlo Simulation Studies
In this section, Monte Carlo simulation studies are used to verify the usefulness of the proposed Wiener process model and testing procedures for the similarity of two complex networks in terms of the resilience/risk level. We conduct (i) a simulation study based on a parametric statistical model in Section 5.1; (ii) a simulation study without relying on generating data from a parametric model in Section 5.2; (iii) a sensitivity analysis to evaluate the robustness of the proposed methodologies in Section 5.3. In these simulation studies, we compare the performance of the three proposed testing procedures, Procedure A, Procedure B1, and Procedure B2, for assessing the similarity of different complex networks based on the simulated type-I error rates and the simulated power values.
5.1. Network data generated from a parametric statistical model
In order to evaluate and validate the effectiveness of the proposed methodologies, we consider a simulation study in which the network data are generated based on the Wiener process model in Eq. (1). In this simulation, we assume that there are three different topological features for measuring the risks of two cyber-networks (i.e., and and these three topological features are observed at time points. We are interested in testing the hypotheses in Eq. (6). The topological features for Network 1 and Network 2 in Eq. (6) are simulated from the Wiener process model in Eq. (1) with the following parameter settings based on the networks and in the numerical example presented in Section 4:
-
Network 1:
and
and -
Network 2:
where
where
where
For each combination of the settings for Network 1 and Network 2, we simulated 1,000 sets of experiments and applied the three proposed testing procedures. The number of bootstrap samples used in Procedure A and Procedure B2 is Considering using 5% significance level, the simulated proportions of the -values less than 0.05 (i.e., rejecting the null hypothesis in (6) at 5% level of significance) are presented in Table 7. Note that when and the proportions of the -values less than 0.05 are corresponding to the simulated type-I error rates and when or the proportions of the -values less than 0.05 are corresponding to the simulated power values.
From the simulation results in Tables 7, we observe that the simulated type-I error rates (i.e., the simulation rejection rates when or for Procedure A are always controlled under the nominal 5% level for all the settings considered here, while the simulated type-I error rates for Procedures B1 and B2 can be higher than the nominal 5% level. Especially for setting 1(a), Procedure B1 has the simulated type-I error rate of 0.072. For the power of the three proposed procedures, we observe that the power values increases when the simulated settings are further away from the null hypothesis that Network 1 and Network 2 have the same resilience/risk level, i.e., when increases from 1.0 to 4.0 or decreases from 1.0 to 0.05, or increases from 0.0 to 0.20. These simulation results indicate that the proposed testing procedures can effectively detect the difference in resilience/risk levels between two complex networks. Although Procedure B1 gives larger power values compare to Procedures A and B2 in most cases, it may be due to the inflated type-I error rate. In comparing the power values of Procedures A and B2, the power values of these two procedures are similar, therefore, when taking the ability in controlling type-I error rate, we would recommend using Procedure A based on the simulation results.
5.2. Network data generated from nonparametric resampling of a real network data set
To evaluate the performance of the proposed model and test procedures when the network data are not simulated from a parametric model, we conduct a simulation study based on resampling the real Gnutella P2P network data set presented in Section 4. Based on the analysis of Gnutella P2P network data set presented in Section 4, we observed that there is a significant difference between networks and (i.e., the Gnutella P2P network snapshots on August 4 and 9, 2002, respectively). Therefore, we consider obtaining the simulated networks by resampling from networks and using the breadth-first search (BFS) method (Cormen et al. 2009) as the network sampling approach. The BFS method is known as an important traversing algorithm with many graph-processing applications and has low computational complexity. After deciding the starting target node arbitrarily, the BFS algorithm traverses the graph layerwise in a tree by exploring all of the neighbor nodes at the same layer before moving on to the nodes at a deeper layer until the required number of nodes is reached. In our study, we terminate the graph traversal procedure when we achieved nodes, where Once again, we are interested in testing the hypotheses in (6). Network 1 and Network 2 in (6) are simulated by resampling the of nodes as follows:
-
Network 1: Network 2:
-
Network 1: Network 2:
-
Network 1: Network 2:
The simulated rejection rates between two subgraphs under BFS sampling with nodes, where are presented in Table 8.
From the simulation results in Table 8, we observe that when Network 1 and Network 2 are resampled from and respectively, the three proposed test procedures reject the null hypothesis in (6) more than 90% of times for all the percentages of nodes being resampled considered here. Moreover, the simulated rejection rates increase when the percentage of nodes being resampled increases from 50% to 70%. As we observed in the results presented in Section 4, and are different in terms of their resilience/risk levels. When the two networks are resampled from the same P2P network (i.e., network or network we observed that the simulated rejection rates decrease when the percentage of nodes being resampled increases from 50% to 70%. This agrees with our intuition since the higher the percentage of the nodes being sampled from the same network, the similarity of the two sampled subgraphs is increasing. These simulation results indicate that the proposed testing procedures can effectively detect the difference in resilience/risk levels between two complex networks even when the two networks are not generated from the proposed Wiener process model.
5.3. Sensitivity Analysis
Since the proposed methodologies rely on the Wiener process model, it is important to investigate the sensitivity of the proposed methods when the underlying data generating mechanism deviates from the proposed Wiener process model. For this reason, in this section, we consider a Monte Carlo simulation study in which the simulated datasets are generated from a gamma process model, which is a commonly used model for degradation data analysis.
Following the notation in Section 3.1, we consider and and generate the -dimensional random vector where based on a gamma process model in which follows a gamma distribution with shape parameter and scale parameter (denoted as The probability density function of is
\begin{aligned} g(x_{i,j,k}; \lambda_{i,j}, \beta_i) &= \frac{\beta_{i}^{\lambda_{i,j}}}{\Gamma(\lambda_{i,j})} x_{i,j,k}^{\lambda_{i,j} - 1} \exp(-\beta_{i} x_{i,j,k}), \\ x_{i,j,k} &> 0, \end{aligned}\tag{11}
where is the gamma function. For Network and 2), the parameter vector for the gamma process model is In the simulation study, we consider the following settings for the datasets of Network 1 and Network 2 from the gamma process model:
-
Networks 1 and 2 share the same shape parameters but different scale parameter:
where and
where and
-
Networks 1 and 2 share the same scale parameter but different shape parameters:
where and
where and
Based on 1000 simulations with different values of and the simulated rejection rates of Procedures A, B1, and B2 under the proposed modified Wiener process model are presented in Table 9.
From Table 9, we can observe that the three proposed testing procedures, especially Procedure A, under the modified Wiener process model can effectively control the significance levels (i.e., when and close to the 5% level and provide reasonable power when the two target networks are different in terms of the resilience/risk level even when the underlying data-generating mechanism is not the assumed Wiener process model. Moreover, the power values of these three testing procedures increase with the values of and which indicates that these test procedures can effectively detect the dissimilarity between the two target networks.
6. Concluding Remarks
To comprehend how vulnerable is a cyber or physical network to attacks or failures and to assess the risks of a complex network, in this paper, we propose a statistical approach to assess and understand cyber risk. Specifically, we propose a Wiener process model to model the dynamics of the topological measures of the network under attacks or failures.
To illustrate the utility of the proposed model and testing procedures, we conduct experiments on the Gnutella P2P cyber network and Enron email datasets. Network motifs, which can capture local topological information of a network, are considered as the topological measure in the example. However, other topological measures that can reflect the functionality of the complex network, including global topological measures (e.g., giant component, degree distribution, APL, D, CC, BC, etc.) and local topological features (e.g., Betti numbers, Wasserstein distances, etc.) (Salles and Marino 2011; Kim and Obah 2007; Islambekov et al. 2018) can also be used with the proposed methodologies in this paper. In the practical data analysis, we observe that the proposed methodologies can qualify and compare the risks of different complex networks. Then, we further studied the validity of the proposed methodologies by using two Monte Carlo simulation studies in which the network data are generated from the proposed Weiner process model or resampling from the real Gnutella P2P cyber network data. From the simulation results, we observe that the proposed testing procedures can effectively detect the difference in resilience/risk levels between two complex networks.
To the best of our knowledge, this is the first study that evaluating the resilience/robustness of cyber networks by using a stochastic model with statistical hypothesis testing procedures. The results obtained from the proposed statistical methodologies can provide some important insights to manage and compare the risks of cyber networks and help cybersecurity insurance providers to determine insurance policy and insurance premium. The computer program to execute the proposed methodologies is written in R (R Core Team 2020) and is available from the authors upon request.
Acknowledgement
This research was supported by The Society of Actuaries’ Committee on Knowledge Extension Research and the Casualty Actuarial Society Individual Grant. The authors would like to thank reviewers in the oversight group of the Casualty Actuarial Society for reviewing our manuscript and for their constructive comments and suggestions. The authors are grateful for the two referees and the editor for their helpful and suggestions that improved the manuscript.