1. Introduction
This paper explores the use of predictive models that can be used for underwriting and ratemaking in homeowners insurance. Homeowners represents a large segment of the personal property and casualty insurance business; for example, in the United States, homeowners accounted for 13.6% of all property and casualty insurance premiums and 26.8% of personal lines insurance, for a total of over $57 billion (Insurance Information Institute 2010). Many actuaries interested in pricing homeowners insurance are now decomposing the set of dependent variables (ri, yi) by peril, or cause of loss (e.g., Modlin 2005). Homeowners is typically sold as an all-risk policy, which covers all causes of loss except those specifically excluded.
Decomposing risks by peril is not unique to personal lines insurance, nor is it new. For example, it is customary in population projections to study mortality by cause of death (e.g., Board of Trustees, Federal Old-Age and Survivors Insurance and Disability Insurance Trust Funds 2009). Further, in 1958, Robert Hurley discussed statistical considerations of multiple peril rating in the context of homeowners insurance. Referring to “multiple peril rating,” Hurley stated: “The very name, whatever its inadequacies semantically, can stir up such partialities that the rational approach is overwhelmed in an arena of turbulent emotions.”
Rating by multiple perils does not cause nearly as much excitement in today’s world. Nonetheless, Rollins (2005) argues that multi-peril rating is critical for maintaining economic efficiency and actuarial equity. Decomposing risks by peril is intuitively appealing because some predictors do well in predicting certain perils but not in others. For example, “dwelling in an urban area” may be an excellent predictor for the theft peril but provide little useful information for the hail peril.
Current multi-peril rating practice is based on modeling each peril in isolation from the others. From a modeling point of view, this amounts to assuming that
-
perils are independent of one another, and
-
sets of parameters from each peril are unrelated to one another.
Although allowing sets of parameters to be unrelated to one another (sometimes called functionally independent) is plausible, it seems unlikely that perils are independent. Event classification can be ambiguous (e.g., fires triggered by lightning) and unobserved latent characteristics of policyholders (e.g., cautious homeowners who are sensitive to potential losses due to theft-vandalism as well as liability) may induce dependencies among perils. Prior empirical investigations reported in Frees, Meyers, and Cummings (2010) demonstrated statistically significant dependence among perils.
To accommodate potential dependencies, we introduce an instrumental variables approach. Instrumental variables is an estimation technique that is commonly used in econometrics to handle dependencies that arise among systems of equations. In this paper, we hypothesize that multiple peril models are jointly determined and that a methodology such as instrumental variables can be used to quantify these dependencies.
Although examining the multiple peril nature of homeowners insurance is intuitively plausible, not all insurers will wish to consider this complex model. In homeowners, consumers are charged a single price, meaning that the decomposition by peril may not be necessary for financial transactions. Moreover, from statistical learning it is well known (e.g., Hastie, Tibshirani, and Friedman 2001) that there is a price to be paid for complexity; other things equal, more complex models fare poorly compared to simpler alternatives for prediction purposes.
Thus, in this paper we compare our many alternative models using out-of-sample validation techniques. Section 1 introduces our data and Section 2 presents several baseline models. We consider both pure premium and frequency-severity approaches, as well as both a single- and multi-peril modeling framework in this work. Section 3 introduces the instrumental variable approach. We then show how these competing approaches fare in the context of a held-out validation sample in Section 4.
Loss distributions are not even approximately symmetric nor normally distributed; to illustrate, in our data 94% of the losses are zeros (corresponding to no claims) and when losses are positive, the distribution tends to be right-skewed and thick-tailed. Thus, the usual mean square metrics, such as variance and R2, are not informative for capturing differences between predictions and held-out data. Thus, we use recent developments (Frees, Meyers, and Cummings 2011) on a statistical measure called a Gini index to compare predictors in Section 2. Section 5 explores nonparametric regression, an alternative validation measure. Both approaches allow us to compare, among other things, a single peril pure premium model with one dependent variable to a multiple peril model with many dependent variables. Section 6 closes with a summary and a few additional remarks.
2. Data and preliminary models
2.1. Data
To calibrate our models, we drew two random samples from a homeowners database maintained by the Insurance Services Office. This database contains over 4.2 million policyholder years. It is based on the policies issued by several major insurance companies in the United States, thought to be representative of most geographic areas. These policies are almost all for one year and so we will use a constant exposure (one) for our models.
Our in-sample, or “training,” dataset consists of a representative sample of 404,664 records taken from this database. The summary measures in this section are based on this training sample. In Section 4, we will test our calibrated models on a second held-out, or “validation,” sample that was also randomly selected from this database.
For each record, we have information on whether there are any claims due to a peril and the amount associated with that peril. Table 1 displays summary statistics for nine perils from our sample of 404,664 records. This table shows that WaterNonWeather is the most frequently occurring peril, whereas Liability is the least frequent. (WaterNonWeather is water damage from causes other than weather, e.g., the bursting of a water pipe in a house.) When a claim occurs, Hail is the most severe peril (based on the median claim amount), whereas the Other category is the least severe. In Table 1, we note that neither the Frequency nor the Number of claims sum to the totals due to jointly occurring perils within a policy.
In this work, we consider two sets of explanatory variables. The goal is to show how the predictive modeling techniques work over a range of information available to the analyst. The first set of variables is a base set that consists of the amount of insurance dwelling coverage, a building adjustment, the construction age of the building, policy deductibles, the homeowners policy form, and base cost loss costs. Here, the “base cost loss costs” are the ISO base class loss costs at the home address, a very reasonable proxy for territory.
The second set of variables is an “extended” list of variables that consists of many (over 100) explanatory variables to predict homeowners claims. These are a variety of geographic-based plus several standard industry variables that account for
-
weather and elevation,
-
vicinity,
-
commercial and geographic features,
-
experience and trend, and
-
rating variables.
The Web site http://www.iso.com/Products/ISO-Risk-Analyzer/ISO-Risk-Analyzer-Homeowners.html provides more information on these explanatory variables.
2.2. Baseline models
Like most analysts, we do not wish to advocate one model as superior to others for every dataset. Rather, we view the collection of models as tools that the analyst has at his or her disposal—the job of the analyst is to pick the right tool for a dataset under consideration. Below is the collection of baseline models that we consider here. Note that in the empirical data section, we calibrate each model with the base and the extended list of predictor variables described in Section 1
-
Single-peril models—the dependent variable is the outcome for the total policy, not disaggregated by peril.
-
Pure premium models—there is a single dependent variable for this model that represents the total loss for a policy.
-
Frequency-severity models—there are two dependent variables in this type of model, one for the frequency and one for the severity.
-
-
Multi-peril models—there are c = 9 separate outcomes for each policy, one for each peril.
-
Independence pure premium models—there is a dependent variable for each peril, resulting in c = 9 dependent variables. Under the “Independence” framework, one assumes independence among dependent variables.
-
Independence frequency-severity models—for each peril, there are two dependent variables, one for the frequency and one for the severity. This means that there are 2 × 9 = 18 dependent variables. Under the “Independence” framework, one assumes independence among dependent variables.
-
Dependence ratio models—these have the same set of dependent variables as the Independence Frequency-Severity Models. However, a dependence structure is introduced in the frequencies to accommodate potential dependencies.
-
A more detailed description of these models may be found in Appendix B.
A piece of advice, sometimes attributed to Albert Einstein, is to “Use the simplest model possible, but no simpler.” Many analysts prefer the simpler single-peril models because of their ease of implementation and interpretability. Moreover, based on the discussion in the introductory Section 1, industry analysts also find a need for multi-peril models. Previous work in Frees, Meyers, and Cummings (2010) established statistically significant dependence among perils. (Appendix Section A gives readers a feel for the type of dependencies discussed in that work.) Thus, based on empirical evidence and intuition, a goal of this paper is to improve upon the assumption of independence in the multi-peril models. One approach is the “Dependence Ratio Model” that we introduced in Frees, Meyers, and Cummings (2010). A drawback of this approach is that it is based on a maximum likelihood estimation routine that is cumbersome to interpret and calibrate. Thus, in this paper, we introduce an instrumental variable approach that can be implemented without specialized software to accommodate the dependence among perils.
2.3. Overview of the instrumental variables approach
An instrumental variable approach to estimation can be used to improve upon the predictions under the independence models. To illustrate, suppose that we are interested in predicting fire claims and believe that there exists an association between fire and theft/vandalism claims. One would like to use the information in theft/vandalism claims to predict fire claims; however, the number and severity of theft/vandalism claims are unknown when making the predictions. We can, however, use estimates of theft/vandalism claims as predictors of fire claims. This is the essence of the instrumental variable estimation method where one substitutes proxies for variables that are not available a priori.
To provide motivation for someone to adopt this approach, consider a classic economic demand and supply problem that is summarized by two equations:
y1i=β1y2i+γ10+γ11x1i+ε1i(price)y2i=β2y1i+γ20+γ21x2i+ε2i(quantity)
Here, we assume that quantity (y2) linearly affects price (y1), and vice versa. Further, let x1 be the purchasers’ income and x2 be the suppliers’ wage rate. The other explanatory variables (x’s) are assumed to be exogenous for the demand and supply equations.
For simplicity, assume that we have i = 1, . . . , n independent observations that follow display (1). One estimation strategy is to use ordinary linear regression. This strategy yields biased regression coefficient estimates because the right-hand side of display (2.1), the “conditioning” or explanatory variables, contains a y variable that is also a dependent variable. The difficulty with ordinary least squares estimation of the model in display (2.1) is that the right-hand side variables are correlated with the disturbance term. For example, looking at the price equation, one can see that quantity (y2) is correlated with ε1. This is because y2 depends on y1 (from the supply equation), which in turn depends on ε1 (from the demand equation). This circular dependency structure induces the correlation that leads to biased regression coefficient estimation.
The instrumental variable approach is to use ordinary least squares with approximate values for the right-hand side dependent variables. To see how this works, we focus on the price equation and assume that we have available “instruments” w to approximate y2. Then, we employ a two-stage strategy:
-
Run a regression of w on y2 to get fitted values of the form
-
Run a regression of x1 and on y1.
As one would expect, the key difficulties are coming up with suitable instruments w that provide the basis for creating reasonable proxies for y2 that do not have endogeneity problems. In our example, we might use x2, the suppliers’ wage rate, as our instrument in the stage 1 estimate of y2, the quantity demanded. This variable is exogenous and not perfectly related to x1, purchaser’s income. Not surprisingly, there are conditions on the instruments. Typically, they may include a subset of the model predictor variables but must also include additional variables. Appendix C provides additional details.
3. Multi-peril models with instrumental variables
As discussed above, when modeling systems of c = 9 perils, it seems reasonable to posit that there may be associations among perils and, if so, attempt to use these associations to provide better predictors. For example, in prior work (see Appendix A), statistically significant associations between claims from fire and theft/vandalism were established. Sections 1 and 2 describe the estimation procedures in the pure premium and frequency/severity contexts, respectively.
3.1. Pure premium modeling
Under our independence pure premium model framework, we assume that the claim amount follows a Tweedie (1984) distribution. The shape and dispersion parameters vary by peril and the mean parameter is a function of explanatory variables available for that peril. Using notation, we assume that
yij∼Tweedie(μi,j,ϕj,pj),i=1,…,n=404,664,j=1,…,c=9.
Here, is the dispersion parameter, pj is the shape parameter, and = exp(x′i,jβj) is the mean parameter using a logarithmic link function. There are many procedures for estimating the parameters in Equation (3.1); we use maximum likelihood. See, for example, Frees (2010) for an introduction to the Tweedie distribution in the context of regression modeling.
Estimating independence pure premium models with Equation (3.1) allows us to determine regression coefficient estimates bIND,j. These coefficients allow us to compute (independence model) pure premium estimates of the form
For instrumental variable predictors, we use logarithmic fitted values from other perils as additional explanatory variables. For example, suppose we wish to estimate a pure premium model for the first peril. For the peril, we already have predictors We augment with the additional predictor variables
\ln \hat{\mu}_{I N D, i, j}, j=2, \ldots, c=9 .
We then estimate the pure premium model in Equation (3.1) using both sets of explanatory variables.
We summarize the procedure as follows.
-
Stage 1. For each of the nine perils, fit a pure premium model in accordance with Equation (3.1). These explanatory variables differ by peril. Calculate fitted values, denoted as Because these fits are unrelated to one another, these are called the “independence” pure premium model fits.
-
Stage 2. For each of the nine perils, fit a pure premium model using the Stage 1 explanatory variables as well as logarithmic fitted values from the other eight perils. Denote the predictions resulting from this model as
Table 2 summarizes the regression coefficient estimates for the fit of the instrumental variable pure premium model. This table shows results only for the additional instruments, the logarithmic fitted values. This is because our interest is in the extent that these additional variables improve the model fit when compared to the independence models. Table 2 shows that the additional variables are statistically significant, at least when one examines individual t-statistics. Although we do not include the calculations here, this is also true when examining collections of variables (using a likelihood ratio test). However, this is not surprising because we are working with a relatively large sample size, n = 404,664. We defer our more critical assessment of model comparisons to Section 4 where we compare models on an out-of-sample basis. There, we will label the resulting insurance scores as “IV_PurePrem.”
We use logarithmic fitted values because of the logarithmic link function; in this way the additional predictors are on the same scale as the fitted values. Moreover, by using a natural logarithm, they can be interpreted as elasticities, or percentage changes. For example, to interpret the lightning coefficient of the fire fitted value, we have
0.220=\frac{\partial \ln \hat{\mu}_{IV ,FIRE}}{\partial \ln \hat{\mu}_{IND ,LIGHT}}=\frac{\left(\frac{\partial \hat{\mu}_{IV ,FIRE}}{\hat{\mu}_{IV ,FIRE}}\right)}{\left(\frac{\partial \hat{\mu}_{IND ,LIGHT}}{\hat{\mu}_{IND ,LIGHT}}\right)} .
That is, holding other variables fixed, a 1% change in the fitted value for lightning is associated with a 0.22% change in the fitted value for fire.
3.2. Frequency and severity modeling
The approach to instrumental variable estimation for frequency and severity modeling is similar to the pure premium case but more complex. At the first stage, we calculate independence, frequency, and severity fits; we now have many instruments that can be used as predictor variables for second stage instrumental variable estimation. That is, in principle it is possible to use both fitted probabilities and severities in our instrumental variable frequency and severity models.
Based on our empirical work, we have found that the fitted probabilities provide better predictions than using both fitted probabilities and severities as instruments. Intuitively, coefficients for fitted severities are based on smaller sample sizes (when there is claim) and may contain less information in some sense than fitted probabilities. Thus, for our main model we feature fitted probabilities and include fitted severities for a robustness check (Appendix D).
The algorithm is similar to the pure premium modeling in Section 1. We summarize the procedure as follows.
-
Stage 1. Compute independence frequency and severity model fitted values. Specifically, for each of the j = 1, . . . , 9 perils:
-
Fit a logistic regression model using the explanatory variables xF,i,j. These explanatory variables differ by peril j. Calculate fitted values to get predicted probabilities, denoted as
-
Fit a gamma regression model using the explanatory variables xS,i,j with a logarithmic link function. These explanatory variables may differ by peril and from those used in the frequency model. Calculate fitted values to get predicted severities (by peril), denoted as
-
-
Stage 2. Incorporate additional instruments into the frequency model estimation. Specifically, for each of the j = 1, . . . , 9 perils:
- Fit a logistic regression model using the explan-atory variables xF,i,j and the logarithm of the predicted probabilities developed in step 1(a),
In Section 4 we will label the resulting insurance scores as “IV_FreqSevA.” We remark that this procedure could easily be adapted to distributions other than the gamma, as well as link functions other than logarithmic. These choices simply worked well for our data.
As with the Section 1 pure premium instrumental variable model, we found many instruments to be statistically significant when this model was estimated with our in-sample data. This is not surprising because it is common to find effects that are “statistically significant” using large samples. Thus, we defer discussions of model selection to our out-of-sample validation beginning in Section 4. In this section, we examine alternative instrumental variable models. In particular, using additional instruments in the severity model (instead of the frequency model) will result in insurance scores labeled as “IV_FreqSevB.” Use of additional instruments in frequency and severity, described in detail in Appendix D, will result in insurance scores labeled as “IV_FreqSevC.”
4. Out-of-sample analysis
Qualitative model characteristics will drive some modelers to choose one approach over another. However, others will seek to understand how these competing approaches fare in the context of empirical evidence. As noted earlier, in-sample summary statistics are not very helpful for model comparisons. Measures of (in-sample) statistical significance provide little guidance because we are working with a large sample size (404,664 records); with large sample sizes, coefficient estimates tend to be statistically significant using traditional measures. Moreover, goodness-of-fit measures are also not very helpful. In the basic frequency-severity model, there are two dependent variables and in the multi-peril version, there are 18 dependent variables. Goodness-of-fit measures typically focus on a single dependent variable.
We rely instead on out-of-sample comparisons of models. In predictive modeling, the “gold standard” is model validation through examining performance of an independent held-out sample of data (e.g., Hastie, Tibshirani, and Friedman 2001). Specifically, we use our in-sample data of 404,664 records to compute parameter estimates. We then use the estimated parameters from the in-sample model fit as well as predictor variables from a held-out, or validation, sample of 359,454 records, whose claims we wish to predict. For us, the important advantage of this approach is that we are able to compare models with different dependent variables by aggregating predictions into a single score for a record.
To illustrate, consider the independence frequency severity model with 18 dependent variables. We can use estimators from this model to compute an overall predicted amount as
\begin{aligned} \text{IND} \_ \text{FreqSev}_{i}= & \sum_{j=1}^{c} \widehat{\operatorname{Prob}}_{i, j} \times \widehat{\text { Fit }}_{i, j} \\ = & \sum_{j=1}^{c} \frac{\exp \left(\boldsymbol{x}_{F, i, j}^{\prime} \boldsymbol{b}_{F, j}\right)}{1+\exp \left(\boldsymbol{x}_{F, i, j}^{\prime} \boldsymbol{b}_{F, j}\right)} \\ & \times \exp \left(\boldsymbol{x}_{s, i, j}^{\prime} \boldsymbol{b}_{s, j}\right) . \end{aligned} \tag{4.1}
Here, is the predicted probability using logistic regression model parameter estimates, bF,j, and frequency covariates xF,ij, for the jth peril. Further, is the predicted amount based on a logarithmic link using gamma regression model parameter estimates, bS,j, and severity covariates xS,i,j, for the jth peril. This predicted amount, or “score,” provides a basic input for ratemaking. We focus on this measure in this section.
In the following, Section 4.1 provides global comparisons of scores to actual claims. Section 4.2 provides cumulative comparisons using a Gini index. Section 5 provides local comparisons using nonparametric regression.
4.1. Comparison of scores
We examine the 14 scores that are listed in the legend of Table 3. This table summarizes the distribution of each score on the held-out data. Not surprisingly, each distribution is right-skewed.
Table 3 also shows that the single-peril frequency severity model using the extended set of variables (SP_FreqSev) provides the lowest score, both for the mean and at each percentile (below the 75th percentile). Except for this, no model seems to give a score that is consistently high or low for all percentiles. All scores have a lower average than the average held-out actual claims (TotClaims).
Table 3 shows that the distributions for the 14 scores appear to be similar. For an individual policy, to what extent do the scores differ? As one response to this question, Table 4 provides correlations among the 14 scores and total claims. This table shows strong positive correlations among the scores, and a positive correlation between claims and each score. Because the distributions are markedly skewed, we use a nonparametric Spearman correlation to assess these relationships. Recall that a Spearman correlation is a regular (Pearson) correlation based on ranks, so that skewness does not affect this measure of association. See, for example, Miller and Wichern (1977) for an introduction to the Spearman correlation coefficient.
Table 4 shows strong associations within scores based on the basic explanatory variables (SP_FreqSev_Basic, SP_PurePrem_Basic, IND_PurePrem_Basic, and IV_PurePrem_Basic). In contrast, associations are weaker between scores based on basic explanatory variables and those based on the extended set of explanatory variables. For scores based on the extended set of explanatory variables, there is a strong association between the single peril scores (0.892, for SP_FreqSev and SP_PurePrem). It also shows strong associations within the multi-peril measures, particularly those of the same type (either frequency-severity or pure premium). The weakest associations are between the single- and multi-peril measures. For example, the smallest correlation, 0.798, is between SP_FreqSev and IND_FreqSev.
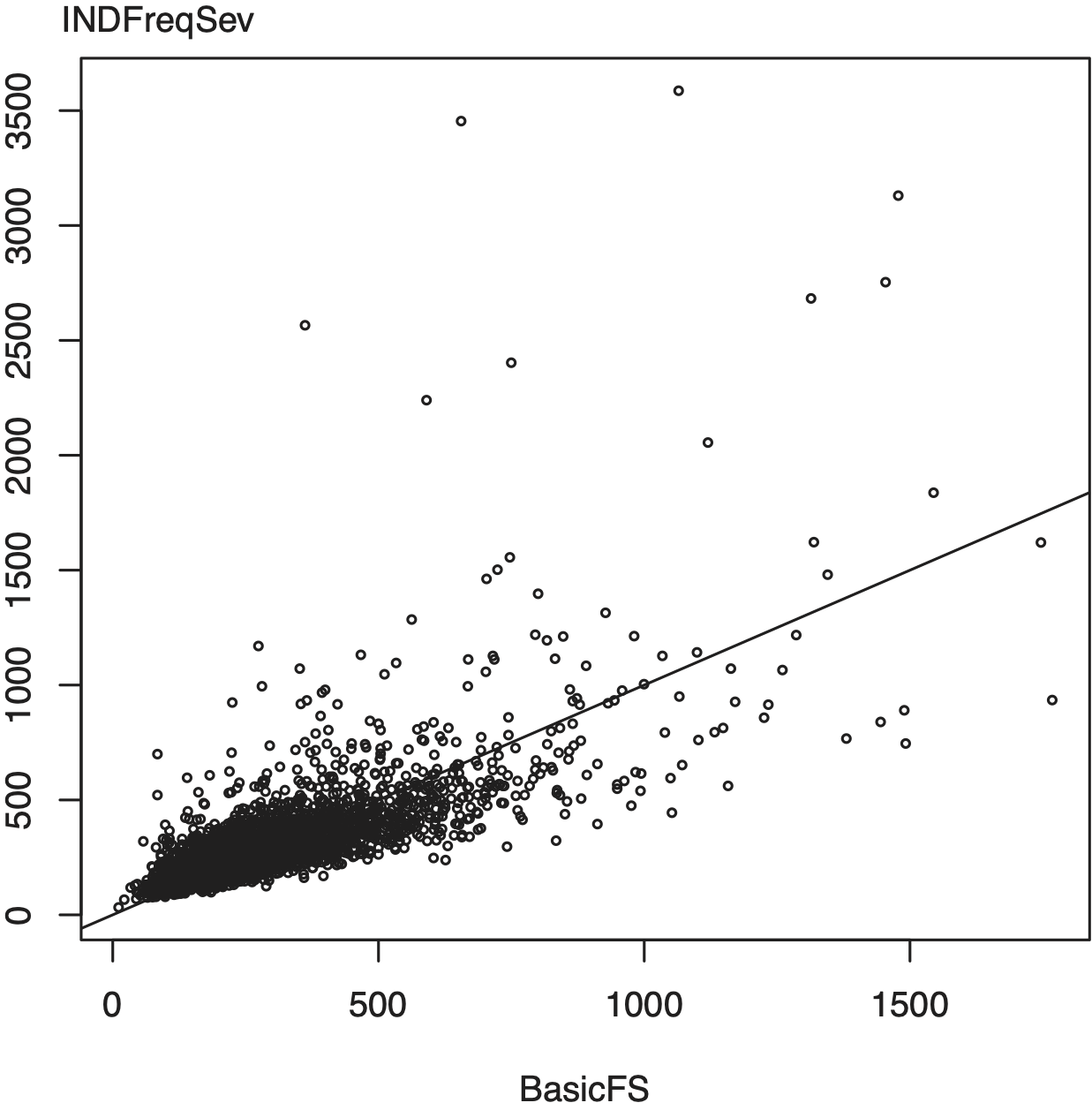
Although strongly associated, do the different scoring methods provide economically important differences in predictions? To answer this, Figure 1 shows the relationship between SP_FreqSev and IND_FreqSev. So that patterns are not obscured, only a 1% sample is plotted. This figure shows substantial variation between the two sets of scores. Particularly for larger scores, we see percentage differences that are 20% and higher.

4.2. Out-of-sample analysis using a Gini index
In insurance claims modeling, standard out-of-sample validation measures are not the most informative due to the high proportions of zeros (corresponding to no claim) and the skewed fat-tailed distribution of the positive values. We use an alternative validation measure, the Gini index, that is motivated by the economics of insurance. Properties of the insurance scoring version of the Gini index have been recently established in Frees, Meyers, and Cummings (2011). Intuitively, the Gini index measures the negative covariance between a policy’s “profit” (P − y, premium minus loss) and the rank of the relativity (R, score divided by premium). That is, the close approximation
\widehat{Gini} \approx-\frac{2}{n} \widehat{Cov}((P-y), {rank}(R))
was established in Frees, Meyers, and Cummings (forthcoming).
4.2.1. Comparing scoring methods to a selected base premium
Assume that the insurer has adopted a base premium for rating purposes; to illustrate, we use the “SP_FreqSev_Basic” for this premium. Recall from Section 1 that this method uses only a basic set of rating variables to determine insurance scores from a single-peril, frequency and severity model. Assume that the insurer wishes to investigate alternative scoring methods to understand the potential vulnerabilities of this premium base; Table 5 summarizes several comparisons using the Gini index. This table includes the comparison with the alternative score IND_FreqSev as well as twelve other scores.
The standard errors were derived in Frees, Meyers, and Cummings (2011) where the asymptotic normality of the Gini index was proved. Thus, to interpret Table 5, one may use the usual rules of thumb and reference to the standard normal distribution to assess statistical significance. For the three scores that use the basic set of variables, SP_PurePrem_Basic, IND_PurePrem_Basic, and IV_PurePrem_Basic, all have Gini indices less than two standard errors, indicating a lack of statistical significance. In contrast, the other Gini indices all are more than three standard errors above zero, indicating that the ordering used by each score helps detect important differences between losses and premiums.
The paper of Frees, Meyers, and Cummings (2011) also derived distribution theory to assess statistical differences between Gini indices. Although we do not review that theory here, we did perform these calculations for our data. It turns out that there are no statistically significant differences among the ten Gini indices that are based on the extended set of explanatory variables.
In summary, Table 5 suggests that there are important advantages to using extended sets of variables compared to the basic variables, regardless of the scoring techniques used. Moreover, this table suggests that the instrumental variable scores provide improved “lift” when compared to the scores generated by the independence model.
5. Out-of-sample analysis using local comparisons of claims to scores
As noted in Section 2, one interpretation of the Gini index is as the covariance between y − P (loss minus premium) and the rank of relativities. Another interpretation is as an area between cumulative distributions of premiums and losses. Through the accumulation process, models may be locally inadequate and such deficiencies may not be detected by a Gini index. Thus, this section describes an alternative graphical approach that can help us assess the performance of scores locally.
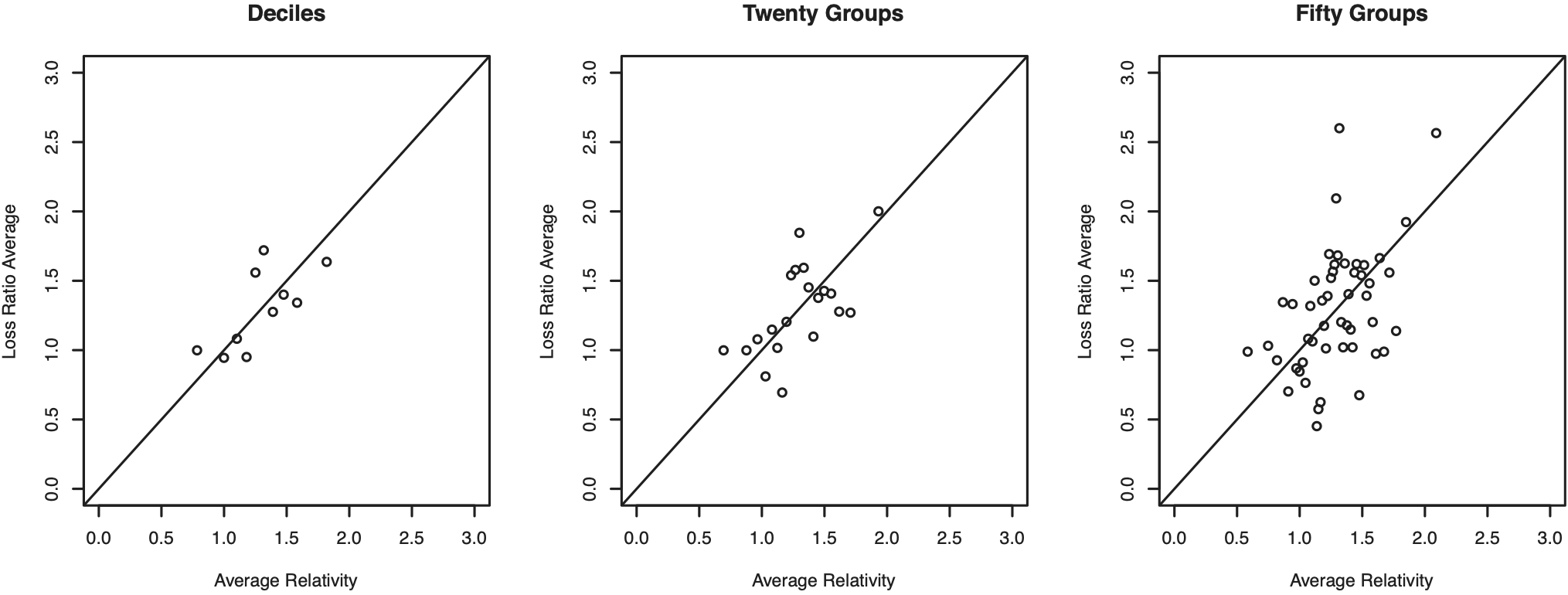
One method of making local comparisons used in practice involves comparing averages of relativities and loss ratios for homogenous subgroups. Intuitively, if a score S is a good predictor of loss y, then a graph of scores versus losses should be approximately a straight line with slope one. This is also true if we rescale by a premium P. To illustrate, let (Si, yi) represent the score and loss for the ith policy and, when rescaled by premium Pi, let Ri = Si/Pi and LRi = yi/Pi be the corresponding relativity and loss ratio. To make homogenous subgroups, we could group the policies by relativity deciles and compare average loss ratios for each decile.
The left-hand panel of Figure 2 shows this comparison for the premium P = “SP_FreqSev_Basic” and score S = “SP_FreqSev”. A more primitive comparison of relativities and loss ratios would involve a plot of Ri versus LRi; however, personal lines insurance typically has many zero losses, rendering such a graph ineffective. For our application, each decile is the average over 35,945 policies, making this comparison reliable. This panel shows a linear relation between the average loss ratio and relativity, indicating that the score SP_FreqSev is a desirable predictor of the loss.

An overall summary of the plot of relativities to loss ratios is analogous to the Gini index calculation. In the former, the relationship of interest is versus R; in the latter, it is y − P versus rank(R). The differences are (a) the rescaling of losses by premiums and (b) the use of rank relativities versus relativities. The Gini index summarizes the entire curve whereas the graphs in this section will allow us to examine relationships “locally,” as described below.
Of course, extensive aggregation such as at the decile level may hide important patterns. The middle and right-hand panels of Figure 2 show comparisons for 20 and 50 bins, respectively. In the right-hand panel, each of the 50 bins represents an average of 2% of our hold-out data (= 7,189 records per bin). This panel shows substantial variability between the average relativity and loss ratio, so we consider alternative comparison methods.
Specifically, we use nonparametric regression to assess score performance. Although nonparametric regression is well known in the predictive modeling community (e.g., Hastie, Tibshirani, and Friedman 2001), it is less widely used in actuarial applications. The ideas are straightforward. Consider a set of relativities and loss ratios of the form (Ri, LRi), i = 1, . . . , n. Suppose that we are interested in a prediction at relativity x. Then, for some neighborhood about x, say, [x − b, x + b], one takes the average loss ratio over all sets whose score falls in that neighborhood. Using notation, we can express this average as
\hat{\mathrm{m}}(x)=\frac{\sum_{i=1}^{n} w\left(x, R_{i}\right) L R_{i}}{\sum_{i=1}^{n} w\left(x, R_{i}\right)} \tag{5.1}
where the weight function w(x, Ri) is 1 if Ri falls in [x − b, x + b] and 0 otherwise. By taking an average of all those observations with scores that are “close” to R = x, we get a good idea as to what one can expect LR to be—that is, E(LR⎥R = x), the regression function. It is called “nonparametric” because there is no assumption about a functional form such as linearity.
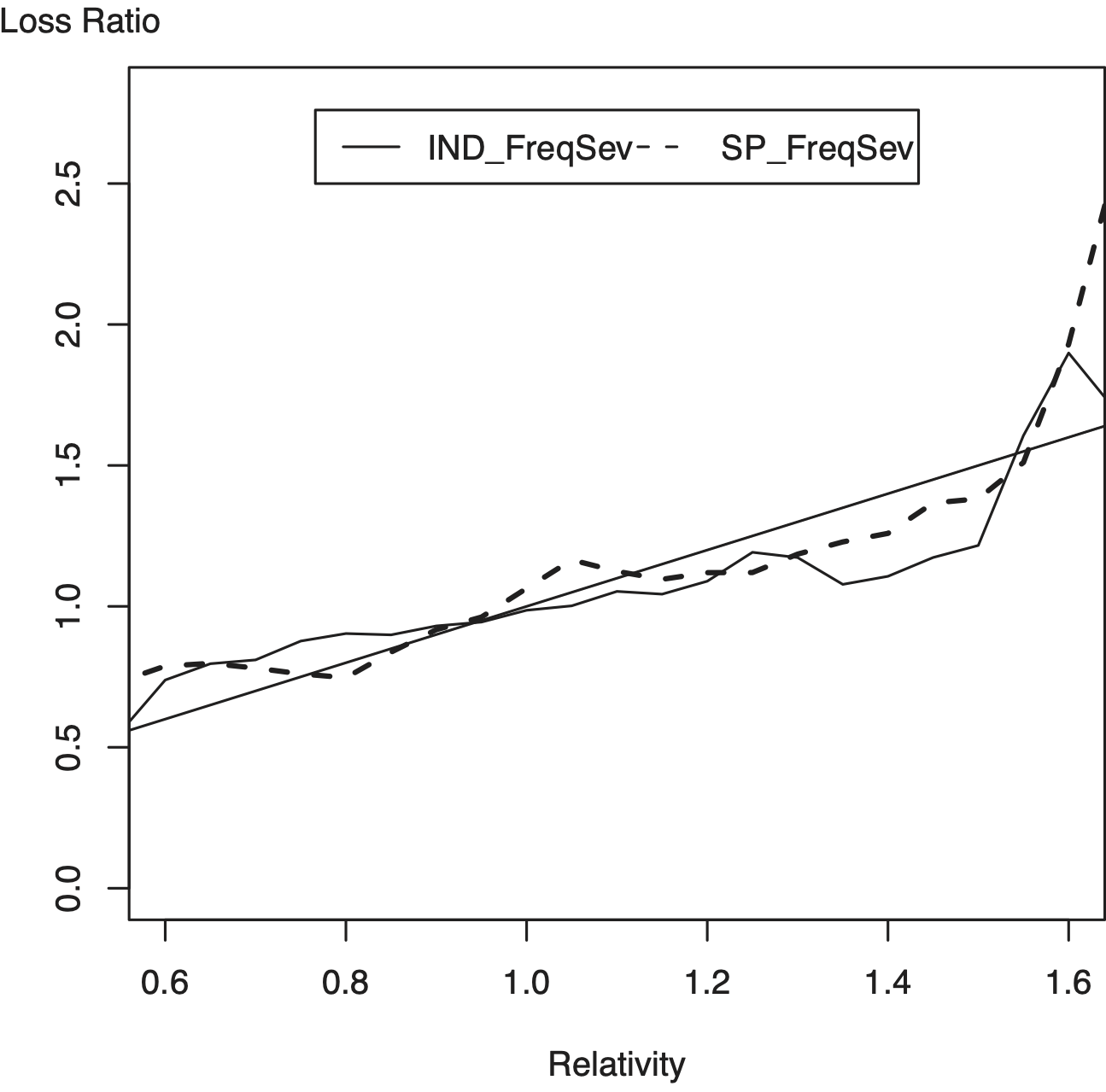
To see how this works, Figure 3 provides a plot for the basic frequency severity score, SP_FreqSev, and its multi-peril version assuming independence, IND_FreqSev. To calculate the nonparametric fits, this figure is based on b = 0.1. For our data, this choice of b (known as a “bandwidth”) means that the averages were calculated using at least 13,000 records. For example, at x = 0.6, there were 27,492 policies with relativities that fell in the interval [0.5,0.7]. These policies had an average loss ratio of 0.7085, resulting in a deviation of 0.1085. We plot the fits in increments of 0.05 for the value of x, meaning that there is some overlap in adjacent neighborhoods. This overlap is not a concern for estimating average fits, as we are doing here. We plot only relativities in the interval [0.6, 1.6] because the data become sparse outside of that interval. Figure 3 shows that the deviations from IND_FreqSev and SP_FreqSev are comparable; it is difficult to say which score is uniformly better.

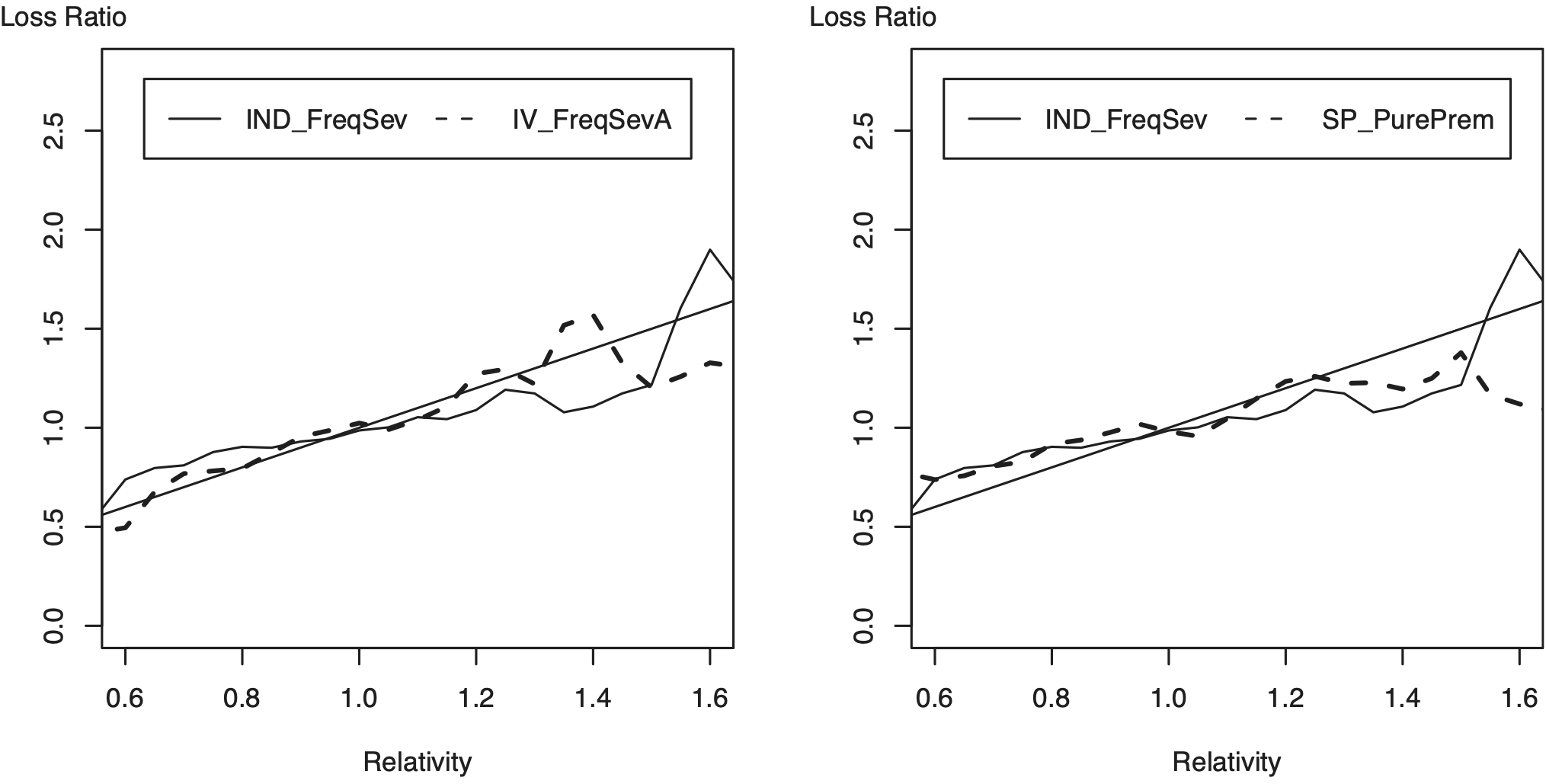
Figure 4 provides additional comparisons. The left panel compares the error in IND_FreqSev to one of the instrumental variable alternatives, IV_FreqSevA. Here, the IV_FreqSevA error is smaller for low relativities (0.6 through 0.8) and medium size relativities (1.2 through 1.4) and approximately similar elsewhere (0.8 through 1.2). Based on this comparison, the score IV_FreqSevA is clearly preferred to the score IND_FreqSev.

The right panel of Figure 4 compares the error in IND_FreqSev to the basic pure premium score, SP_PurePrem. This panel shows that these two measures perform about the same for most of the data, suggesting that neither is uniformly superior to the other.
For each illustration, we seek a score that is close to the 45 degree line. For our applications, we interpret to be the deviation when using the relativity R to predict loss ratios LR. Compared to Gini indices, this measure allows us to see the differences between relativities and loss ratios locally over regions of x.
6. Summary and concluding remarks
In this paper, we considered several models for predicting losses for homeowners insurance. The models considered include
-
single versus multiple perils, and
-
pure premium versus frequency-severity approaches.
Moreover, in the case of multiple perils, we also compared
-
independence to instrumental variable models.
The instrumental variable estimation technique is motivated by systems of equations, where the presence and amount of one peril may affect another. We show in Section 3 that instrumental variable estimators accommodate statistically significant relationships that we attribute to associations among perils.
For our data, each accident event was assigned to a single peril. For other databases where an event may give rise to losses for multiple perils, we expect greater association among perils. Intuitively, more severe accidents give rise to greater losses and this severity tendency will be shared among losses from an event. Thus, we conjecture that instrumental variable estimators will be even more helpful for companies that track accident event level data.
This paper applies the instrumental variable estimation strategy to homeowners insurance, where a claim type may be due to fire, liability, and so forth. One could also use this strategy to model homeowners and automobile policies jointly or umbrella policies that consider several coverages simultaneously. As another example, in health care, expenditures are often broken down by diagnostic-related groups.
Although an important contribution of our work is the introduction of instrumental variable techniques to handle dependencies among perils, we do not wish to advocate one technique or approach as optimal in all situations. Sections 2 and 3, as well as Appendix B, introduce many models, each of which has advantages compared to alternatives. For example, models that do not decompose claims by peril have the advantage of relative simplicity and hence interpretability. The “independence” multi-peril models allow analysts to separate claims by peril, thus permitting greater focus in the choice of explanatory variables. The instrumental variable models allow analysts to accommodate associations among perils. When comparing the pure premium to the frequency-severity approaches, the pure premium has the advantage of relative simplicity. In contrast, the frequency-severity has the advantage of permitting greater focus, and hence interpretability, on the choice of explanatory variables.
This paper supplements these qualitative considerations through quantitative comparisons of predictors based on a held-out, validation sample. For our data, we found substantial differences among scoring methods, suggesting that the choice of methods could have an important impact on an insurer’s pricing structure. We found that the instrumental variable alternatives provided genuine “lift” compared to baseline multi-peril rating methods that implicitly assume independence, for both the pure premium and frequency-severity approaches. We used nonparametric regression techniques to explore local differences in the scores. Although we did not develop this point extensively, we conjecture that insurers could use the nonparametric techniques to identify regions where one scoring method is superior to an alternative (using covariate information) and possibly develop a next stage “hybrid” score.