1. Introduction
In collective risk theory, the total amount of losses an insurance company incurs during a time period is modeled by a compound random variable
S=M∑i=1Xi,
where is a discrete random variable representing the number of claims; are nonnegative independent and identically distributed (i.i.d.) claim size random variables independent of The tail probability,
θ=P[S>c]
for some specified value and the tail mean (mean excess loss), defined by
τ=E[(S−c)+],
where
(S−c)+={0S≤cS−cS>c
are important risk measures of because they are closely related to insurance/reinsurance pricing and capital requirement.
Evaluation of the tail probability and the tail mean is not easy, even when the distribution of and are known. One approach is to resort to recursive formulas, such as those proposed by Panjer (1981), for the case when the distribution of belongs to the class. There is extensive literature on further developments related to Panjer’s recursive formula. For details, see the comprehensive book by Sundt and Vernic (2009).
Transform-based techniques, such as fast Fourier transform (FFT), are also widely used in calculating the distribution of aggregated claims. For an introduction, see the papers by Robertson (1992) and Wang (1998) and the references therein. Embrechts and Frei (2008) provided an excellent comparison of the recursive and FFT methods.
Simulation methods are flexible and can be handy in estimation of the tail probability/moments of compound distributions. However, they are subject to sampling errors. That is, different runs of the same simulation method will give different results.
For example, the one-sample crude estimator for is
ˆθ0=I(S>c),
where is an indicator function that takes the value of one if the argument is true and zero otherwise. is an unbiased estimator of because
E[ˆθ0]=θ.
The variance of is
Var[ˆθ0]=θ(1−θ),
and the coefficient of variation (CoV) is
CoV(ˆθ0)=√θ(1−θ)θ=√(1−θ)θ.
Quite often, we are interested in a tail probability of so that is close to zero. Then the coefficient of variation is huge, which makes the crude method inefficient. Notice that when the simulation is conducted times, the estimator for is
ˆθ0,n=1nn∑j=1I(S(j)>c),
which has variance and CoV
CoV(ˆθ0,n)=√θ(1−θ)/nθ=1√n⋅√(1−θ)θ≃1√nˆθ0,n=(n∑j=1I(S(j)>c))−1/2.
When is large, the distribution of is approximately normal by the central limit theorem, based on which the confidence interval of is given by
(ˆθ0,n−z1−α/2√Var[ˆθ0,n],ˆθ0,n+z1−α/2√Var[ˆθ0,n]).
In other words,
P(|ˆθ0,n−θ|θ≤z1−α/2CoV(ˆθ0,n))=1−α.
Taking this means that with probability, the relative error of is less than Therefore, can be a measure for relative error.
In fact, for any estimator of some parameter similar reasoning applies. As a result, is a measure of relative error for Therefore, we say that an estimator (simulation method) with a smaller CoV is more efficient.
For our case, the relative error of is given in equation (1.3). When is close to zero, rarely equals one. So is small, resulting in a large CoV. For example, suppose that the value of is such that the tail probability is roughly (from prior knowledge) If we expect that is around Consequently, is approximately This means that with a probability of the relative error of is within which is not very satisfactory. Increasing the sample size to the relative error of is which is still not very accurate. Recalling that we see that in order to decrease the relative error (CoV) of an estimator tenfold, the sample size has to increase a hundredfold.
Remark 1.1. This discussion may remind actuaries of the situation in limited fluctuation credibility theory, in which the sample size of loss data is determined such that the sample mean will provide a credible (low relative error) estimate of the population mean. The idea there is similar and the same square rule applies. In limited fluctuation credibility, to double the credibility factor, the sample size has to be quadrupled.
In this paper, we study simulation methods (estimators) of the tail probability of compound random variables. As shown, increasing the sample size of the crude estimator is one way to reduce relative error. However, because of the square rule, it is costly and inefficient and sometimes not feasible. Therefore, instead of increasing the sample size, we propose several more efficient estimators of that, given the same sample size, are still unbiased, yet have a lower CoV (relative error).
Reducing the CoV requires reducing the variance of the estimator. In the simulation literature, various variance reduction methods exist. Commonly used techniques include importance sampling, stratified sampling, the conditioning method, and the control variates method, which we review briefly in the next section. For detailed introductions to variance reduction methods, see, for example, the books by Ross (2012) and Asmussen and Glynn (2007).
Needless to say, simulation methods for evaluating the tail probability and tail mean of compound variables are very important for actuaries. However, quite surprisingly, to our knowledge, the literature in this area is very thin. In addition to some examples from Ross (2012), one of the most relevant references is Peköz and Ross (2004), in which the conditioning method was introduced specifically for compound variables. Blanchet and Li (2011) introduced an efficient importance sampling algorithm for estimating the tail distribution of heavy-tailed compound sums. Glasserman, Heidelberger, and Shahabuddin (2000) proposed a method for simulating tail probability (value at risk) of the returns of investment portfolios by combining the importance sampling and stratified sampling methods.
In this paper, we first briefly review some commonly used general variance reduction methods for simulation, then we propose several novel combinations of variance reduction methods specifically for compound distributions. This includes the combination of importance sampling and the conditioning method and the combination of importance sampling and stratified sampling.
Secondly, we extend our methods to simulate the tail probability and tail mean of bivariate compound variables, defined by
(S1,S2)=(M∑i=1Xi,N∑j=1Yj),
where is a vector of (dependent) random variables representing the number of the claims in two lines of business. The claim size random variables and for are mutually independent and are independent of the claim numbers and
The remaining parts of the paper are organized as follows. Section 2 reviews commonly used variance reduction methods. Section 3 applies them in estimation of tail probability. Section 4 studies the simulation methods for the tail mean. Sections 5 and 6 extend the results to bivariate compound variables. Section 7 concludes.
2. Review of variance reduction methods
We start by briefly reviewing several variance reduction methods that will be used in this paper. For more comprehensive introductions to the topic, see books such as those by Ross (2012) and Asmussen and Glynn (2007).
2.1. Importance sampling
Let denote a vector of random variables having a joint density function and suppose that we want to estimate
θ=E[g(Z)]=∫g(z)f(z)dz,
where the integral is -dimensional and over the support of
Importance sampling finds the probability density function (PDF) such that whenever Since
θ=∫g(z)f(z)f∗(z)f∗(z)dz=E[g(Z∗)f(Z∗)f∗(Z∗)],
where has density
ˆθI=g(Z∗)f(Z∗)f∗(Z∗)
is an unbiased estimator for
The importance sampling approach aims to choose an appropriate so that has a smaller variance compared with the crude estimator
Since
Var[g(Z∗)f(Z∗)f∗(Z∗)]=E[(g(Z∗)f(Z∗)f∗(Z∗)−θ)2]=∫(g(z)f(z)−θf∗(z))2f∗(z)dz,
in order to achieve a smaller variance, should be chosen such that the numerator is close to zero. That is, is proportional to
If has a finite moment generating function (MGF)
MZ(t)=E[eZ⋅t]=E[eZ1t1+⋯+Zntn],
for some then it is usually handy to choose to be the Esscher transform (exponential tilting) of That is, we let have PDF
f∗(z)=eh⋅zf(z)MZ(h)
for some tilting parameter In addition, the MGF of is given by
MZ∗(t)=E[et⋅Z∗]=E[e(t+h)⋅Z]E[eh⋅Z]=MZ(t+h)MZ(h).
Notice that if is a discrete random variable, we interpret and as probability mass functions (PMFs).
For presentation simplicity, in the sequel, we assume that the goal is to estimate the mean of some random variable
θ=E[Z],
instead of for some function Doing so does not lead to loss of generality because can have any form, such as
2.2. The conditioning method
Suppose that is a random variable that is correlated with and can be simulated efficiently and that can be evaluated. Then
ˆθCD=E[Z∣W]
is a more efficient estimator of than the crude estimator because it is unbiased; that is,
E[ˆθCD]=E[E[Z∣W]]=E[Z],
and it has a smaller variance, as shown in the following line.
Var[Z]=Var[E[Z∣W]]+E[Var[Z∣W]]≥Var[E[Z∣W]].
2.3. Stratified sampling
Stratified sampling resembles the conditioning method in the sense that a random variable can help simulate the mean of a random variable Suppose that takes values in strata with probability for Then
E[Z]=k∑i=1E[Z∣W∈Wi]pi.
Suppose that is the total number of samples and is the number of samples from stratum Then the stratified estimate of is
ˆθS,n=k∑i=1ˉZipi,
where for is the sample average of s conditional on
Let then the variance of is
Var[ˆθS,n]=k∑i=1p2iσ2ini.
If we choose then must have a smaller variance than the crude simulation estimator because
Var[ˆθS,n]=1nk∑i=1piσ2i=1nE[Var[Z∣W]]≤1nVar[Z]=Var[ˆθ0,n].
It is worthwhile to note that is not necessarily the optimal number of simulations in stratum Particularly, if is chosen to be proportional to (Fishman 1995), then is minimized.
2.4. The control variates method
When using a control variable to reduce the variance of the estimator of we select a control variate that is strongly positively or negatively correlated with Then an unbiased estimator for is
ˆθCV=Z−γ(W−E[W])
for some constant Then we have
Var[ˆθCV]=Var[Z]+γ2Var[W]−2γCov(Z,W),
which is minimized if Note that the parameter can be estimated using the simulated values of and In fact, it is the least square estimate of the slope of the simple linear regression
Z=γ0+γ1W+ϵ.
Obviously, there are many other general-purpose simulation variance reduction methods in the literature. We have only introduced the four that we use for simulating the compound random variables in this paper. In the following sections, we illustrate how these methods can be used in combination to reduce the simulation variance even further.
3. Simulating tail probability
In this section, we apply the four variance reduction methods to the estimation of the tail probability where the compound random variable is defined in (1.1).
The one-sample crude estimator is simply The -sample estimator is given by defined in (1.2).
The problem with the crude method is that when is large, the sample size needs to be very large in order for to occur. Therefore, as shown in equation (1.3), the crude estimator is not efficient.
3.1. Importance sampling
Let be the PDF of [1] We assume that has finite MGF on the interval where
In importance sampling, instead of sampling we sample where has PDF Since we assume that has a finite MGF, we may choose to be the Esscher transform (exponential tilted transform) of That is, we let have PDF
f∗(x)=ehxf(x)MS(h),
for some tilting parameter Then we have θ=E[I(S>c)]=E[I(S∗>c)MS(h)ehS∗].
Hence, the importance sampling estimator of is given by
ˆθI=I(S∗>c)MS(h)exp(−hS∗).
If the sample size is then we have
ˆθI,n=MS(h)nn∑j=1I(S∗(j)>c)exp(−hS∗(j)), where is the th simulated value of
In order to apply the importance sampling method with exponential tilting, we need to (1) select an appropriate value for the tilting parameter and (2) simulate with the tilted distribution.
As mentioned in Section 1, the problem with the crude simulation method is that when is small, is zero for most rounds of simulation, which results in a large value of the CoV of In importance sampling, we choose such that is more likely to occur than An intuitively natural choice for the value of is This choice is indeed optimal, as the following note shows.
Note 3.1. As pointed out by Ross (2012),
ˆθI=I(S∗>c)MS(h)e−hS∗≤MS(h)e−hc.
Thus, one can stabilize the results of every round of simulation by choosing the value of to minimize the upper bound Setting the derivative of it to zero, we get
M′S(h)−cMS(h)=0.
Thus, the optimal should satisfy
c=M′S(h)MS(h)=E[SehSMS(h)]=E[S∗].
We next study the distribution of (in order to simulate it). The result is stated in the following note.
Note 3.2 The Esscher transform of with parameter is
S∗=M∗∑i=1X∗i,
where is the Esscher transform of with parameter and is the Esscher transform of with parameter
Proof. Firstly, the MGF of is
MS∗(t)=MS(t+h)MS(h)=PM(MX(t+h))PM(MX(h))=PM(MX(h)MX∗(t))PM(MX(h)),
where represents the probability generating function (PGF) of and is the Esscher transform of with parameter
Let and let be the Esscher transform of with parameter Then the PGF of is
PM∗(z)=E[ec(h)M⋅zM]E[ec(h)M]=PM(ec(h)⋅z)PM(ec(h))=PM(MX(h)z)PM(MX(h)).
Comparing (3.2) and (3.3) leads to
MS∗(t)=PM∗(MX∗(t)),
which shows that ◻
Note 3.2 suggests that is a compound sum of and Therefore, it can be easily simulated if the distribution of latter two are known. This is actually the case for many commonly used distributions; the following are Esscher transforms (with parameter of some commonly used distributions.
-
If with the PMF p_M(k)={n\choose k}p^k(1-p)^{n-k},\quad k=0,1,2,\dots, n, then
-
If with the PMF p_M(k)={k+r-1\choose k} (1-p)^r p^k,\quad k=0,1,2,\dots, then
-
If with the PMF p_M(k)=\frac{\lambda^k}{k!}e^{-\lambda}, \quad k=0,1,2,\dots, then
-
If with the PDF f_X(x)=\beta^\alpha x^{\alpha-1}e^{-\beta x}/\Gamma(\alpha),\quad x>0 , then
Example 3.1. Assume that and have common distribution Then
S^*=\sum\limits_{i=1}^{M^*}X_i^*,
where and
3.2. Combining importance sampling and stratified sampling
A method for applying stratified sampling in simulating quantities related to compound distribution was introduced by Ross (2012, Section 9.5.3). This is done by treating the claim number as a stratifying variable. Specifically, in order to simulate
\theta=\mathbf{E}[g_M(X_1, \dots, X_M)],
we choose a number such that is small and make use of the fact that
\begin{align} \theta&= \sum_{n=0}^{m} \mathbf{E}[g_{n}(X_1, \dots, X_{n})]p_n\\ &\quad + \mathbf{E}[g_M(X_1, \dots, X_M)|M>m]\left(1-\sum_{n=0}^{m}p_m\right). \end{align}
This method can be applied to estimate the tail probability if we let, for
g_m(X_1, \dots, X_m)= \mathbb{I}(X_1 + \cdots+ X_m>c).
However, directly applying the method is not efficient because when is large and is small, the function is likely to be zero on most strata, and more so with small values of
Therefore, we propose here a method to combine importance sampling and stratified sampling. For this purpose, we let be the Esscher transform of with parameter and
Define
\scriptsize{ g_m^*(x_1,\dots,x_m)= {M_S(h) \mathbb{I}\left(\sum_{i=1}^m x_i >c\right)} {\exp \left({-h\sum_{i=1}^m x_i}\right)}\tag{3.4}}
and
p_m^*=\mathbf{P}[M^*=m], \quad m=1,2,\dots.
Then we have, for a given value of such that is small,
\small{ \begin{aligned} \theta &=\mathbf{E}[\mathbb{I}(S>c)]\notag\\ &=\mathbf{E}\bigg[\mathbb{I}(S^*>c)\frac{M_S(h)}{e^{hS^*}}\bigg]\notag\\ &=\mathbf{E}[g^*_{M^*}(X_1^*, \dots, X_{M^*}^*)]\notag\\ &=\sum_{m=0}^{m_l} \mathbf{E}[g^*_{M^*}(X_1^*, \dots, X_{M^*}^*)\mid M^*=m]p_m^*\\ &\quad +\mathbf{E}[g^*_{M^*}(X_1^*, \dots, X_{M^*}^*)\mid M^*>m_l]\mathbf{P}[M^*>m_l]\notag\\ &=\sum_{m=0}^{m_l} \mathbf{E}[g^*_{m}(X_1^*, \dots, X_{m}^*)]p_m^*\\ &\quad +\mathbf{E}[g^*_{M^*}(X_1^*, \dots, X_{M^*}^*)\mid M^*>m_l](1-\sum_{m=0}^{m_l}p_m^*). \end{aligned} }
With this, we can follow the procedure from Ross (2012) to simulate Firstly, we generate a value of conditional on it exceeding Suppose the generated value is then we generate independent random variables Then the estimator of from this run is
\begin{align} \mathcal{E}&= \sum_{m=1}^{m_l} g^*_{m}(X_1^*, \dots, X_{m}^*)p_m^*\\ &\quad +g^*_{m'}(X_1^*, \dots, X_{m'}^*)(1-\sum_{m=0}^{m_l}p_m^*). \end{align} \tag{3.5}
As pointed out by Ross (2012), since it is easy to compute the functions we can use the data in the reverse order to obtain a second estimator and then average the two estimators. That is, we let
\begin{align} \mathcal{E}'&= \sum_{m=1}^{m_l} g^*_{m}(X_{m'}^*, \dots, X_{m'-m+1}^*)p_m^*\\ &\quad +g^*_{m'}(X_{m'}^*, \dots, X_1^*)(1-\sum_{m=0}^{m_l}p_m^*), \end{align}
then use
\hat{\theta}_{I+S}=\frac{1}{2}(\mathcal{E}+ \mathcal{E}')
as the estimator for
Remark 3.1. By equation (3.4), the second term in equation (3.5)
g^*_{m'}(X_1^*, \dots, X_{m'}^*)(1-\sum_{m=0}^{m_l}p_m^*)\leq M_S(h)\mathbf{P}[M^*>m_l].
Thus if we select a value for sufficiently large that is negligible, it can be omitted.
3.3. The conditioning method
Peköz and Ross (2004) introduced a very effective way of simulating the tail probability of compound distribution based on the conditioning method. Let
T(c)=\min \bigg(m: \sum\limits_{i=1}^m X_i>c\bigg).\tag{3.6}
Then, we have
S>c\Leftrightarrow M\geq T(c).\tag{3.7}
Equation (3.7) agrees with proposition 1.1 of Lin (1996).
Therefore,
\begin{aligned} \mathbf{E}[\mathbb{I}(S>c)]&= \mathbf{E}[\mathbf{E}[\mathbb{I}(S>c)\mid T(c)]]\\ &= \mathbf{E}[\mathbf{E}[\mathbb{I}(M \geq T(c))\mid T(c)]]. \end{aligned}
Thus, an estimator for applying the conditioning method is given by
\begin{aligned} \hat{\theta}_{CD} &= \mathbf{E}[\mathbb{I}(M \geq T(c))\mid T(c)]\notag\\ &= \mathbf{P}[M\geq T(c)\mid T(c)]\notag\\ &= \mathbf{P}[M\geq T(c)], \end{aligned}
where the last line is because and are independent.
To implement the method, we generate samples of in sequence until the sum of generated values exceeds If the generated value of is then is the estimate of for this run of simulation.
3.4. Combining the conditioning method and the control variates method
As shown by Peköz and Ross (2004), the estimator can be further improved by using a control variate. The idea is to select a control variate that is strongly positively or negatively correlated with Peköz and Ross (2004) suggested that one such choice is
W=\sum\limits_{i=1}^{T(c)}(X_i-\mathbf{E}[X]),
which has a mean of zero.
is positively correlated with because when is large, (1) is small, and (2) s are likely to be small so that will be small.
With this choice, when combining the conditioning method with the control variates method, the estimator for is
\hat{\theta}_{CD+CV} = \hat{\theta}_{CD} - \gamma W,
where which may be estimated using the simulated values of and
3.5. Combining importance sampling and the conditioning method
In the conditioning method, we need to simulate defined in equation (3.6), which may be time consuming if is large relative to the s. In this section, we introduce a method to improve this. The key is to replace with
T^*(c)=\min \bigg(m: \sum\limits_{i=1}^m X_i^*>c\bigg),
where is the Esscher transform of with tilting parameter This way, we combine the conditioning and importance sampling methods. The following estimator of is obtained.
\hat{\theta}_{I+CD}=\mathbf{P}[M\geq T^*(c)] \frac{M_X(h)^{T^*(c)}}{e^{h\sum_{i=1}^{T^*(c)}X_i^*}}.\tag{3.8}
The unbiasedness of this estimator is shown in Section A.1 of the Appendix.
To carry out the simulation, we generate samples of in sequence until the sum of generated values exceeds The values of and are stored and used in (3.8).
Remark 3.2. A control variate
W^*=\sum_{i=1}^{T^*(c)} (X_i^*-\mathbf{E}[X^*])
can be used to improve the estimator This results in
\hat{\theta}_{I+CD+CV} = \hat{\theta}_{I+CD} - \gamma W^*,
where
3.6. Numerical experiments
In this section, we compare the different estimators of introduced in Section 3 through a numerical example. We assume that and for Note that the distributional assumptions are entirely hypothetical and only for illustration purposes. Naturally, in actual application, the aggregate loss model and the parameters need to be estimated from data.
For each method, the tail probabilities at are estimated using 1000 simulated samples (one round). The standard deviation (SD) of each estimator is calculated based on 100 rounds of simulations. We will follow this convention in all the numerical examples in the rest of the paper. In addition, for estimator 3, in which stratified sampling is applied, we set
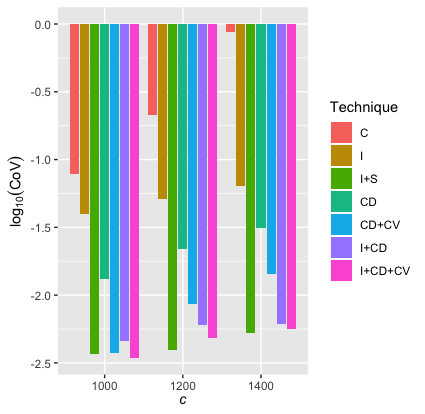
The simulation results are summarized in Table 3.1. A visual comparison of the CoV of different estimators is given in Figure 3.1.
__of_the_estimators_for___mathbf_p_(s_c)_.png)
To provide a reference point for comparing the estimators, we calculate the analytical result of the tail probability by
\small{ \mathbf{P}(S>c) = \sum_{m=1}^{\infty} \mathbf{P}(M=m) \mathbf{P}(X_1+\cdots + X_m >c). }
This formula is calculable for this simple example because when Thus, the probabilities for any can be computed easily. For the infinite sum, we can truncate it at some value such that is small enough. In the example, and we select so that is smaller than This means that our analytical result is accurate at least up to decimal points.
In addition, for comparison, we provide the normal approximation of the tail probability, which is calculated by
\mathbf{P}(S>c) \simeq 1- \Phi \left(\frac{c-\mathbf{E}[S]}{\sqrt{\mathbf{Var} (S)}}\right),
where stands for the normal cumulative distribution function. We can see that normal approximation is not very accurate even for this simple example, especially when is large.
As explained previously, estimators with smaller CoVs have smaller relative errors and, therefore, are better. Table 3.1 indicates that the combinations of importance sampling and stratified sampling (I+S); the conditioning method and the control variates method (CD+CV); importance sampling and the conditioning method (I+CD); and importance sampling, the conditioning method, and the control variates method (I+CD+CV) performed well. Methods involving importance sampling tend to have a small CoV when is large. Therefore, they are recommended for simulating small tail probabilities.
4. Simulating mean excess loss
In this section, we introduce variance reduction methods for simulating the mean excess losses
\tau=\mathbf{E}[(S-c)_+].
4.1. Combining importance sampling and stratified sampling
The importance sampling method for simulating is similar to that for : we simply replace with in equation (3.1). This yields
\hat{\tau}_I= (S^*-c)_+ {M_S(h)}{ \exp({-hS^*})}.
To combine importance and stratified sampling, we replace the function in (3.4) with
g_m^*(x_1,\dots,x_m)= \left(\sum_{i=1}^m x_i - c\right)_+ {M_S(h)}{e^{- h\sum_{i=1}^m x_i}}.
4.2. The conditioning method
The following method for simulating the mean excess loss using the conditioning method was discussed by Peköz and Ross (2004). Define
A=\sum_{i=1}^{T(c)} X_i -c.
Then the conditional expectation estimator is constructed as
\begin{aligned} \hat{\tau}_{C D} & =\mathbf{E}\left[(S-c)_{+} \mid {T}(c), {A}\right] \\ & =\sum_{i \geq {T}(c)}({A}+({i}-{T}(c)) \mathbf{E}[X]) \mathbf{P}[M=i] \\ & =({A}-{T}(c) \mathbf{E}[X]) \mathbf{P}[M \geq {T}(c)]\\ &\quad +\mathbf{E}[X] \mathbf{E}[M \mathbb{I}(M \geq {T}(c))] \\ & =({A}-{T}(c) \mathbf{E}[X]) \mathbf{P}[M \geq{ }T(c)]\\ &\quad +\mathbf{E}[X]\left(\mathbf{E}[M]-\sum_{{i}<{T}(c)} {i} \mathbf{P}[M=i]\right) \end{aligned}
The steps for implementing this simulation method are similar to those in Section 3.3; the only difference is that the value of must be recorded in addition to
4.3. Combining the conditioning method and the control variates method
The following two control variates can be used to enhance the performance of the conditioning method without increasing computational efforts:
W_1=\sum\limits_{i=1}^{T(c)} (X_i-\mathbf{E}[X])
and
W_2=A-\mathbf{E}[A].
This yields the estimator
\hat{\tau}_{CD+CV} = \hat{\tau}_{CD}-\gamma_1W_1-\gamma_2W_2,
where and are chosen to minimize the variance of This could be achieved by setting the values of and to the least square estimate of the corresponding coefficients of the linear regression
\hat{\tau}_{CD}= \gamma_0+\gamma_1W_1+\gamma_2W_2+\epsilon,
where the values of and are generated in simulation using the conditioning method.
For general discussions on least square or regression-based methods for using control variates, see the papers by Lavenberg and Welch (1981) and Davidson and MacKinnon (1992).
4.4. Combining importance sampling and the conditioning method
Similar to Section 3.5, importance sampling and the conditioning method can be combined. This results in the estimator
\scriptsize{ \begin{align} &\hat{\tau}_{I+CD}\\ &\quad = \bigg[(A^*-T^*(c)\mathbf{E}[X])\mathbf{P}[M\geq T^*(c)]+\mathbf{E}[X]\mathbf{E}\left[M \mathbb{I}(M\geq T^*(c)) \right]\bigg]\frac{M_X(h)^{T^*(c)}}{e^{h\sum_{i=1}^{T^*(c)}X_i^*}} \end{align} }
where
A^*=\sum_{i=1}^{T^*(c)}X_i^*-c.
The proof of the unbiasedness of this estimator is given in Section A.2 of the Appendix.
Remark 4.1. The quantity is related to the size-biased transform (see Denuit 2020). We have
\mathbf{E}[M \mathbb{I}(M\geq T^*(c))]= \mathbf{E}[M] \mathbf{P}[\tilde{M}\geq T^*(c)], \tag{4.1}
where is the size-biased transform of with distribution function
\mathbf{P}[\tilde{M} = k]=\frac{k \mathbf{P}[M=k]}{\mathbf{E}[M]}, \quad k=0,1, \dots.
Equation (4.1) can be calculated efficiently because the distribution of and are often related. For example, as shown by Ren (2021), if belongs to the class with parameter then is in the class with parameter Particularly, if follows the Poisson distribution with mean then also follows the Poisson distribution with mean Therefore, for this case, (4.1) becomes
\mathbf{E}[M \mathbb{I}(M\geq T^*(c))]= \lambda\mathbf{P}[M\geq T^*(c)-1],
which is straightforward to evaluate.
Remark 4.2. Control variates can be utilized to improve the results further. For example, let
W_1^*=\sum_{i=1}^{T^*(c)}(X_i^*-\mathbf{E}[X^*])
and
W_2^*=A^*-\mathbf{E}[A^*].
Then the estimator is
\hat{\tau}_{I+CD+CV} = \hat{\tau}_{I+CD} - \gamma_1 W_1^* - \gamma_2 W_2^*,
where the values of and can be estimated by running the linear regression
\hat{\tau}_{I+CD}= \gamma_0+\gamma_1W_1^*+\gamma_2W_2^*+\epsilon.
4.2. Numerical experiments
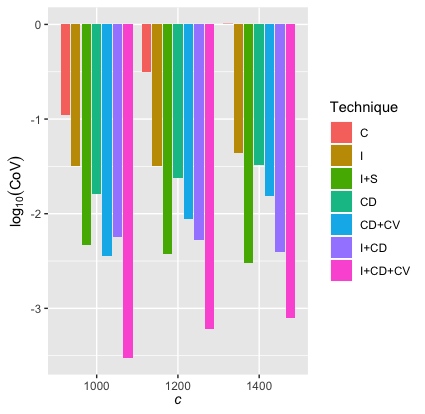
In this section, we compare the different methods for simulating with the example set forth in Section 3.6. The results are shown in Table 4.1 and Figure 4.1.
__of_the_estimators_for___mathbf_e__left_(s-c)_____right__.png)
In order to provide a reference point for the comparison, we list in the table values of estimated using the importance sampling (I) method, but with a huge sample size of These values are proxies for “analytical value” and labeled as “Target” in the table.
For this example, we did not provide the results for normal approximation of because the approximation would not be accurate. The reason is that the normal approximation results for the tail probabilities are already inaccurate.
Table 4.1 and Figure 4.1 show that the combinations I+S, I+CD, and I+CD+CV have small CoVs and thus are efficient for estimating mean excess losses. In particular, the I+CD+CV method has by far the smallest CoV.
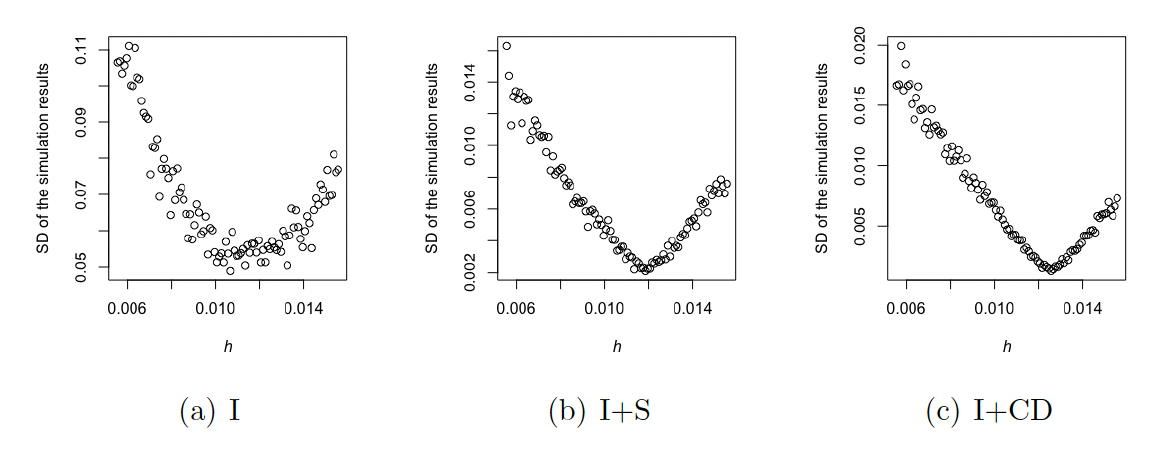
Remark 4.3. When carrying out the importance sampling methods, we have set the value of the tilting parameter to be the same as that for estimating the tail probability. That is, is such that However, this may not be the optimal choice.
For example, we have used for the case of in the previous example. To explore the optimal value of we experimented, and Figure 4.2 plots the SD of the estimator (based on repeating each method 100 times) against the values of The figure shows that compared with the tail probability case, it may be preferable to set to a greater value when estimating mean excess losses. Determining theoretical results for the optimal value of tilting parameter would be a great topic for future research.
_____right___with_different_value.png)
5. Simulating tail probability: The two-dimensional case
In this section, we study methods for simulating the tail probability
\theta= \mathbf{P}[S_1>c, S_2>d]
for the two-dimensional compound variable defined in equation (1.4). The crude estimator is simply
\hat{\theta}_{0}= \mathbb{I}\left(S_1> c, \, S_2> d\right).
As in the one-dimensional case, this crude estimator has a large CoV and is inefficient. Therefore, we introduce several variance reduction methods to improve it.
5.1. Importance sampling
When using importance sampling to simulate instead of sampling we sample
\hat{\theta}_I = \mathbb{I}({S_1^*}>c, S_2^*>d) \frac{f(S_1^*, S_2^*)}{f^*(S_1^*, S_2^*)}, \tag{5.1}
where has a joint PDF We assume that has finite moment generating function and choose to be the Esscher transform of That is,
f^*(x_1,x_2) = f(x_1,x_2) \frac{e^{h_1x_1+h_2x_2}}{M_{S_1, S_2}(h_1,h_2)} ,
where is the joint moment generating function of With this, (5.1) becomes
\hat{\theta}_I = \mathbb{I}({S_1^*}>c, S_2^*>d) \frac{M_{S_1, S_2}(h_1,h_2)}{e^{h_1S_1^*+h_2S_2^*}}. \tag{5.2}
As in Section 3.1, we need to determine the value of the tilting parameters and a method to simulate in order to apply importance sampling.
Note 5.1. Similar to the one-dimensional case, we have
\begin{align} \hat{\theta}_I&=\mathbb{I}(S_1^*>c, S_2^*>d) M_{S_1,S_2}(h_1,h_2)e^{-h_1S_1^*-h_2S_2^*}\\ &\leq M_{S_1,S_2}(h_1,h_2)e^{-h_1c-h_2d}. \end{align}
Then, a good choice for is to minimize the upper bound. To this end, taking the derivative of the upper bound on the right-hand side of the above equation with respect to and and setting to we have
\begin{align} c&=\frac{\frac{\partial}{\partial h_1}M_{(S_1,S_2)}(h_1,h_2)}{M_{(S_1,S_2)}(h_1,h_2)}\\ &=\frac{\mathbf{E}[S_1e^{h_1S_1+h_2S_2}]}{\mathbf{E}[e^{h_1S_1+h_2S_2}]}=\mathbf{E}[S_1^*], \end{align} \tag{5.3}
and
d=\mathbf{E}[S_2^*]. \tag{5.4}
The values of and can be determined from (5.3) and (5.4).
The next note provides a representation of the distribution of The proof of this statement is given in Section A.3 of the Appendix.
Note 5.2. The Esscher transform of with parameter is
(S_1^*,S_2^*)=\bigg(\sum_{i=1}^{M^*} X_i^*,\sum_{j=1}^{N^*} Y_j^*\bigg),
where and are the Esscher transforms of and with parameters and respectively, and is the Esscher transform of with parameter
In many important special cases, the distributions of and have similar structure, as the following examples show.
Example 5.1. Let Conditional on assume claim frequencies and Claim sizes are i.i.d. and follow a gamma distribution with parameters and are i.i.d. and follow a gamma distribution with parameters With this setup, we have
\small{ \begin{aligned} M_{S_1,S_2}(t_1,t_2)&=\mathbf{E}[e^{t_1S_1+t_2S_2}] \notag\\ &=\mathbf{E}_\Lambda \big[\mathbf{E}[e^{t_1S_1+t_2S_2}\mid \Lambda] \big]\notag\\ &=\mathbf{E}_\Lambda \big[ P_{M\mid\Lambda}\big(M_{X}(t_1)\big)\cdot P_{N\mid\Lambda}\big(M_{Y}(t_2)\big)\big]\notag\\ &=\mathbf{E}_\Lambda \big[ e^{\lambda_1\Lambda(M_X(t_1)-1)+\lambda_2\Lambda(M_Y(t_2)-1)}\big]\notag\\ &=M_\Lambda\big(\lambda_1(M_X(t_1)-1)+\lambda_2(M_Y(t_2)-1) \big)\notag\\ &=\bigg(1-\frac{\lambda_1M_X(t_1)+\lambda_2M_Y(t_2)-\lambda_1-\lambda_2}{\beta}\bigg)^{-\alpha}. \end{aligned} }
Therefore,
\scriptsize{ \begin{aligned} &M_{S_1^*,S_2^*}(t_1,t_2)\\ &\quad=\frac{M_{S_1,S_2}(t_1+h_1,t_2+h_2)}{M_{S_1,S_2}(h_1,h_2)}\notag\\ &\quad=\bigg(1-\frac{\lambda_1M_X(t_1+h_1)+\lambda_2M_Y(t_2+h_2)-\lambda_1M_X(h_1)-\lambda_2M_Y(h_2)}{\beta+\lambda_1+\lambda_2-\lambda_1M_X(h_1)-\lambda_2M_Y(h_2)}\bigg)^{-\alpha}\notag\\ &\quad=\bigg(1-\frac{\lambda_1M_X(h_1)(\frac{M_X(t_1+h_1)}{M_X(h_1)}-1)+\lambda_2M_Y(h_2)(\frac{M_Y(t_2+h_2)}{M_Y(h_2)}-1)}{\beta+\lambda_1+\lambda_2-\lambda_1M_X(h_1)-\lambda_2M_Y(h_2)}\bigg)^{-\alpha}, \end{aligned} }
which implies that has the representation
(S_1^*, S_2^*) = \left(\sum_{i=1}^{M^*} X_i^*, \sum_{j=1}^{N^*} Y_j^*\right),
where and, conditional on For the claim sizes, and
This result means that is still a bivariate compound Poisson with common mixture and can easily be simulated.
Example 5.2. Suppose that the claim frequencies and have an additive common shock. That is, and where and are independent. Let and then
(S_1^*, S_2^*) = \left(\sum_{i=1}^{M^*} X_i^*, \sum_{j=1}^{N^*} Y_j^*\right),\tag{5.5}
where and and where and are the Esscher transforms of and with parameters and respectively. In addition, and are the Esscher transforms of and with parameters and
This statement can be proved as follows.
Firstly,
\scriptsize{ \begin{aligned} M_{S_1^*,S_2^*}(t_1,t_2) &=\frac{P_{M,N}(e^a M_{X^*}(t_1),e^b M_{Y^*}(t_2))}{P_{M,N}(e^a,e^b)}\notag\\ &=\frac{P_{M_1}(e^a M_{X^*}(t_1))}{P_{M_1}(e^a)}\frac{P_{M_2}(e^b M_{Y^*}(t_2))}{P_{M_2}(e^b)}\frac{P_{M_0}(e^{a+b}M_{X^*}(t_1)M_{Y^*}(t_2))}{P_{M_0}(e^{a+b})}. \end{aligned} }
Secondly,
\small{ \begin{aligned} P_{M^*,N^*}(z_1,z_2)&=\mathbf{E}[z_1^{M^*}z_2^{N^*}]\notag\\ &=\mathbf{E}[z_1^{M_1^*}]\mathbf{E}[z_2^{M_2^*}]\mathbf{E}[(z_1z_2)^{M_0^*}]\notag\\ &=\frac{\mathbf{E}[e^{aM_1}z_1^{M_1}]}{\mathbf{E}[e^{aM_1}]}\frac{\mathbf{E}[e^{bM_2}z_2^{M_2}]}{\mathbf{E}[e^{bM_2}]}\frac{\mathbf{E}[e^{(a+b)M_0}(z_1z_2)^{M_0}]}{\mathbf{E}[e^{(a+b)M_0}]}\notag\\ &=\frac{P_{M_1}(e^a z_1)}{P_{M_1}(e^a)}\frac{P_{M_2}(e^b z_2)}{P_{M_2}(e^b)}\frac{P_{M_0}(e^{a+b}z_1z_2)}{P_{M_0}(e^{a+b})}. \end{aligned} }
Combining the above two equations, we have
M_{S_1^*,S_2^*}(t_1,t_2)=P_{M^*,N^*}(M_{X^*}(t_1),M_{Y^*}(t_2)),
which shows that has the compound representation of equation (5.5).
In particular,
-
If and then
andThus, follows a bivariate Poisson distribution with a common shock.
-
If and then
and Thus no longer follows a bivariate negative binomial distribution. However, the pair can be easily simulated.
5.2. Combining importance sampling and stratified sampling
As in Section 3.2, we define
\small{\begin{align} &g_{m,n}^*(x_1,\dots,x_m,y_1,\dots,y_n)\\ &\quad = \frac{M_{(S_1,S_2)}(h_1,h_2)}{e^{h_1\sum_{i=1}^m x_i+h_2\sum_{j=1}^n y_j}} \mathbb{I}\left(\sum_{i=1}^m x_i >c, \sum_{j=1}^n y_j >d\right) \end{align}\tag{5.6}}
and
p_{m,n}^*=\mathbf{P}[M^*=m, N^*=n], \quad m,n=0,1,2,\dots,
where is the Esscher transform of with parameters Then for given such that is small, an estimator for is given by
\scriptsize{ \begin{aligned} \mathcal{E}&= \sum_{m=1}^{m_l}\sum_{n=1}^{n_l} g^*_{m,n}(X_1^*, \dots, X_{m}^*, Y_1^*,\dots,Y_{n}^*)p_{m,n}^*\notag\\ &\qquad+g^*_{m',n'}(X_1^*, \dots, X_{m'}^*,Y_1^*,\dots,Y_{n'}^*)\left(1-\sum_{m=0}^{m_l}\sum_{n=0}^{n_l}p_{m,n}^*\right). \end{aligned} \tag{5.7}}
To carry out the simulation, we simulate samples of conditional on at least one of them exceeding Supposing that the simulated values are we generate and
Denote and As in Section 3.2, a second estimator can be constructed as
\scriptsize{ \begin{aligned} \mathcal{E}'&= \sum_{m=1}^{m_l}\sum_{n=1}^{n_l} g^*_{m,n}(X_{m_l'}^*, \dots, X_{m_l'-m+1}^*, Y_{n_l'}^*,\dots,Y_{n_l'-n+1}^*)p_{m,n}^*\notag\\ &\quad+g^*_{m',n'}(X_{m_l'}^*, \dots, X_{m_l'-m'+1}^*,Y_{n_l'}^*,\dots,Y_{n_l'-n'+1}^*)\\ &\qquad \times\left(1-\sum_{m=0}^{m_l}\sum_{n=0}^{n_l}p_{m,n}^*\right). \end{aligned}\tag{5.8} }
Combining them yields
\hat{\theta}_{I+S} = \frac{1}{2} (\mathcal{E}+\mathcal{E}'). \tag{5.9}
Remark 5.1. This method can be simplified if we choose so large that is negligible. This way, as in Remark 3.1, the second term in (5.7) and (5.8) can be ignored. In addition, and in the first term of (5.8) are replaced by and
5.3. The conditioning method
The conditioning method introduced in Section 3.3 can be extended to the multivariate case as follows.
Let
T_1(c)=\min\bigg(m: \sum_{i=1}^{m} X_i >c\bigg)
and
T_2(d)=\min\bigg(n: \sum_{j=1}^{n} Y_j >d\bigg).
Then
\mathbb{I}(S_1>c, S_2>d) \Leftrightarrow \mathbb{I}( M\geq T_1(c), N\geq T_2(d)).
Hence,
\begin{aligned} &\mathbf{E}[\mathbb{I}(S_1>c, S_2>d) \mid T_1(c),T_2(d)]\\ &\quad =\mathbf{P}[M\geq T_1(c), N\geq T_2(d)\mid T_1(c), T_2(d)]\\ &\quad=\mathbf{P}[M\geq T_1(c), N\geq T_2(d)], \end{aligned}
where the last line is due to the fact that and are independent.
Consequently, an estimator for using the conditioning method is \hat{\theta}_{CD}=\mathbf{P}[M\geq T_1(c), N\geq T_2(d)].
To implement the simulation, we first generate and If the generated values are and respectively, then is the estimate for this run.
5.4. Combining the conditioning method and the control variates method
The conditioning method can be improved by applying control variates. For example, similar to the discussions in Section 4.3, we can introduce the control variates W_1=\sum\limits_{i=1}^{T_1(c)} (X_i-\mathbf{E}[X]) and W_2= \sum\limits_{j=1}^{T_2(d)} (Y_j-\mathbf{E}[Y]), which are positively correlated with The resulting estimator is \hat{\theta}_{CD+CV}=\hat{\theta}_{CD} -\gamma_1 W_1- \gamma_2 W_2, where the values of and are the least square estimate of the coefficients of the regression \hat{\theta}_{CD}= \gamma_0 + \gamma_1 W_1+ \gamma_2 W_2+\epsilon.
5.5. Combining importance sampling and the conditioning method
Let and be the Esscher transforms of and with parameters and respectively. Define T^*_1(c)=\min \bigg(m: \sum\limits_{i=1}^m X_i^*>c\bigg), T^*_2(d)=\min \bigg(n: \sum\limits_{j=1}^n Y_j^*>d\bigg), and S^*_{1,M}=\sum_{i=1}^M X_i^*, S^*_{2,N}=\sum_{j=1}^N Y_j^*.
We have the following estimator by combining importance sampling and the conditioning method.
\small{ \hat{\theta}_{I+CD}= \mathbf{P}[M\geq T_1^*(c), N\geq T_2^*(d)]\frac{M_X(h_1)^{T_1^*(c)}M_Y(h_2)^{T_2^*(d)}}{e^{h_1\sum_{i=1}^{T_1^*(c)}X_i^*+h_2\sum_{j=1}^{T_2^*(d)}Y_j^*}}. }
The proof of the unbiasedness of this estimator is provided in Section A.4 of the Appendix.
Remark 5.2. As in remark 4.2, control variates can be used to improve this method further. For example, we may use
W_1^*=\sum_{i=1}^{T_1^*(c)}(X_i^*-\mathbf{E}[X^*])
and
W_2^*=\sum_{j=1}^{T_2^*(d)}(Y_j^*-\mathbf{E}[Y^*]).
This leads to
\hat{\theta}_{I+CD+CV} = \hat{\theta}_{I+CD} - \gamma_1 W_1^*- \gamma_2 W_2^*,
where the values of and can be estimated by running the regression
\hat{\theta}_{I+CD}= \gamma_0 + \gamma_1 W_1^*+ \gamma_2 W_2^* +\epsilon.
5.6. Numerical experiments
The goal of this section is to compare the different methods for simulating the tail probability
We assume the following hypothetical distribution of : Let Conditional on claim frequencies and follow Poisson distributions with mean and respectively. Claim severities and follow gamma distributions with parameters and respectively.
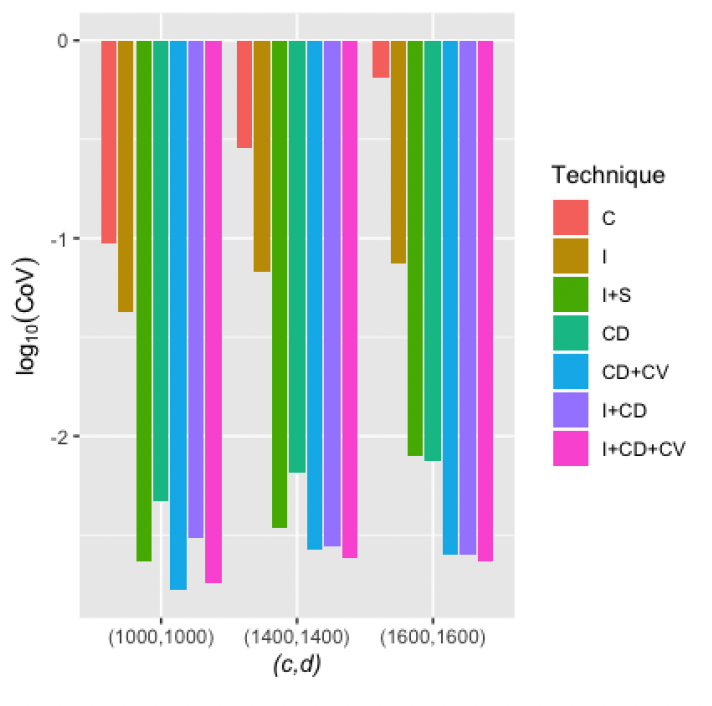
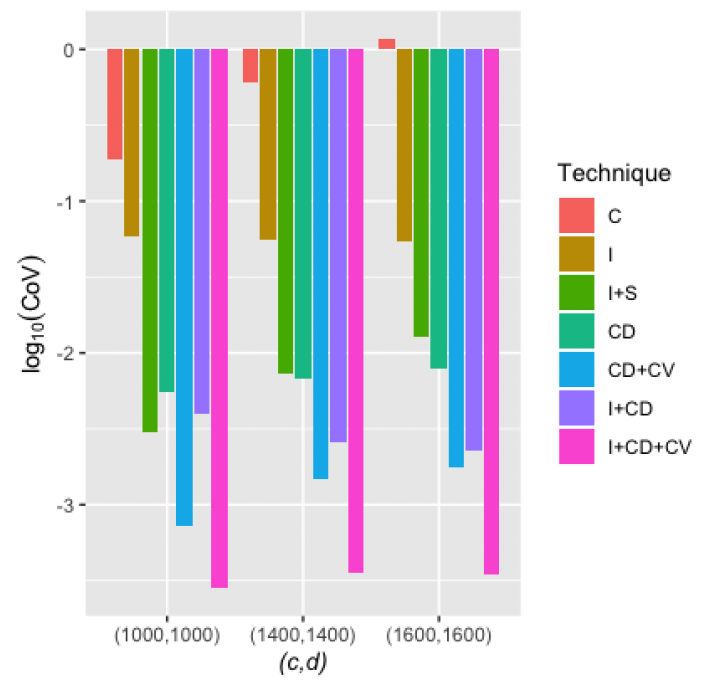
The numerical results of the simulations are reported in Table 5.1. A visual comparison of the CoVs of different estimators is given in Figure 5.1.
__of_the_estimators_for___mathbf_p__left_s_1_c__s_2_d_righ.png)
Similar to the univariate case, an estimator with a smaller CoV is better. The methods I+S, CD+CV, I+CD and I+CD+CV performed well.
To provide a reference point for comparing the estimators, the table also lists the analytical result of the tail probability calculated by
\begin{align} &\mathbf{P}(S_1>c, S_2>d) \\ &\quad = \sum_{m=1}^{\infty} \sum_{n=1}^{\infty} \mathbf{P}(M=m, N=n) \mathbf{P}\\ &\qquad \cdot (X_1+\cdots + X_m >c) \mathbf{P}(Y_1+\cdots + Y_n >d). \end{align}
This formula is calculable for this simple example because gamma distribution is closed under convolutions. Therefore, both and for all and follow gamma distributions. Consequently, all probabilities in the above equation can be easily evaluated. The infinite sum can be truncated at some value such that is small enough. In the example, we select and so that is smaller than As a result, our analytical result is accurate up to at least decimal points.
Further, Table 5.1 reports the tail probability calculated through normal approximation of The approximation results are not accurate, especially at the tail.
6. Simulating mean excess loss: The two-dimensional case
In this section, we introduce variance reduction methods for simulating the bivariate mean excess losses
\tau=\mathbf{E}[(S_1-c)_+\times (S_2-d)_+].
6.1. Combining importance sampling and stratified sampling
To simulate using importance sampling, we simply replace in equation (5.2) with This yields
\hat{\tau}_I =(S_1^*-c)_+\times (S_2^*-d)_+ \frac{M_{S_1,S_2}(h_1,h_2)}{e^{ h_1S_1^*+h_2S_2^*}}.
To combine importance sampling and stratified sampling, we replace the function in (5.6) with
\small{ \begin{align} g_{m,n}^*(x_1,\dots,x_m,y_1,\dots,y_n)&= \left(\sum_{i=1}^m x_i - c\right)_+\\ &\quad \times \left(\sum_{j=1}^n y_j - d\right)_+ \frac{M_{S_1,S_2}(h_1,h_2)}{e^{ h_1\sum_{i=1}^m x_i+h_2\sum_{j=1}^n y_j}}. \end{align} }
6.2. Combining the conditioning method and the control variates method
We use the notation in Section 5.3 and, in addition, for let and Define
A=S_{1, T_1(c)}-c and B=S_{2, T_2(d)}-d.
Then, since
\scriptsize{\tau=\mathbf{E}\bigg[\sum_i\sum_j (S_{1,i}-c)^+(S_{2,j}-d)^+\mathbf{P}[M=i,N=j]\bigg],}
an estimator for using the conditioning method is
\scriptsize{ \hat{\tau}_{CD}= \mathbf{E}\bigg[\sum_i\sum_j (S_{1,i}-c)^+(S_{2,j}-d)^+\mathbf{P}[M=i,N=j]\mid T_1(c),T_2(d),A,B \bigg]. }
After simulating the values of and can be evaluated as follows:
\scriptsize{ \begin{aligned} \hat{\tau}_{CD} &= \mathbf{E}\bigg[\sum_i\sum_j (S_{1,i}-c)^+(S_{2,j}-d)^+\mathbf{P}[M=i,N=j]\mid T_1(c),T_2(d),A,B \bigg]\notag\\ &=\sum_{i\geq T_1(c)}\sum_{j\geq T_2(d)}(A+(i-T_1(c))\mathbf{E}[X])(B+(j-T_2(d))\mathbf{E}[Y])\mathbf{P}[M=i,N=j]\notag\\ &=(A-T_1(c)\mathbf{E}[X])(B-T_2(d)\mathbf{E}[Y])\mathbf{P}[M\geq T_1(c),N\geq T_2(d)]\notag\\ &\quad+(B-T_2(d)\mathbf{E}[Y])\mathbf{E}[X]\sum_{i\geq T_1(c)}\sum_{j\geq T_2(d)}i\mathbf{P}[M=i,N=j]\notag\\ &\quad +(A-T_1(c)\mathbf{E}[X])\mathbf{E}[Y]\sum_{i\geq T_1(c)}\sum_{j\geq T_2(d)}j\mathbf{P}[M=i,N=j]\notag\\ &\quad+\mathbf{E}[X]\mathbf{E}[Y]\sum_{i\geq T_1(c)}\sum_{j\geq T_2(d)}ij\mathbf{P}[M=i,N=j]. \end{aligned}\tag{6.1} }
Remark 6.1. Equation (6.1) shows that when using the conditioning method, the problem of estimating the tail mean of the aggregate loss is replaced by the problem of computing the tail mean of the claim frequencies Note that the infinite sum needs to be evaluated carefully. In this paper, we simply truncate the sum to very large value of and
The estimator can be improved by introducing some control variates. For example, using W_1=\sum\limits_{i=1}^{T_1(c)} (X_i-\mathbf{E}[X]), W_2=\sum\limits_{j=1}^{T_2(d)} (Y_j-\mathbf{E}[Y]), W_3=A-\mathbf{E}[A], and W_4=B-\mathbf{E}[B] results in the estimator \hat{\tau}_{CD+CV}=\hat{\tau}_{CD} -\gamma_1 W_1- \gamma_2 W_2-\gamma_3 W_3- \gamma_4 W_4, where the parameters and can be determined by fitting the linear regression model \hat{\tau}_{CD} = \gamma_0+\gamma_1W_1+\gamma_2W_2+\gamma_3W_3+\gamma_4W_4+\epsilon.
6.3. Combining importance sampling and the conditioning method
We use the notation in Section 5.5 and, further, define
A^*=S^*_{1,T_1^*(c)}-c
and
B^*=S^*_{2,T_2^*(d)}-d.
Then,
\scriptsize{ \begin{aligned} \hat{\tau}_{I+CD} &=\bigg(\big(A^*-T_1^*(c)\mathbf{E}[X]\big)\big(B^*-T_2^*(d)\mathbf{E}[Y]\big)\mathbf{P}[M\geq T_1^*(c), N\geq T_2^*(d)]\notag\\ &\quad +\mathbf{E}[X]\big(B^*-T_2^*(d)\mathbf{E}[Y]\big)\mathbf{E}\big[M\mathbb{I}(M\geq T_1^*(c),N\geq T_2^*(d))\big]\notag\\ &\quad+\mathbf{E}[Y]\big(A^*-T_1^*(c)\mathbf{E}[X]\big)\mathbf{E}[N\mathbb{I}(M\geq T_1^*(c),N\geq T_2^*(d))]\notag\\ &\quad +\mathbf{E}[X]\mathbf{E}[Y]\mathbf{E}\big[MN\mathbb{I}(M\geq T_1^*(c),N\geq T_2^*(d))\big]\bigg)\frac{M_X(h_1)^{T_1^*(c)}M_Y(h_2)^{T_2^*(d)}}{e^{h_1\sum_{i=1}^{T_1^*(c)}X_i^*+h_2\sum_{j=1}^{T_2^*(d)}Y_j^*}}. \end{aligned} }
The expectations in the above equation can be evaluated by their definitions. For example, we have
\begin{align} &\mathbf{E}[M\mathbb{I}(M\geq T_1^*(c),N\geq T_2^*(d))]\\ &\quad= \sum_{i\geq T_1^*(c)}\sum_{j\geq T_2^*(d)}i\mathbf{P}[M=i,N=j]. \end{align}
The unbiasedness of this estimator is shown in Section A.5 of the Appendix.
Remark 6.2. Control variates can be introduced to improve the estimator further. For example, we may use
W_1=\sum_{i=1}^{T_1^*(c)}(X_i^*-\mathbf{E}[X^*]),
W_2=\sum_{j=1}^{T_2^*(d)}(Y_j^*-\mathbf{E}[Y^*]),
W_3=A^*-\mathbf{E}[A^*], and
W_4=B^*-\mathbf{E}[B^*].
This leads to the estimator
\hat{\tau}_{I+CD+CV}=\hat{\tau}_{I+CD} -\gamma_1 W_1- \gamma_2 W_2-\gamma_3 W_3- \gamma_4 W_4,
where the parameters and can be determined by fitting the linear regression
\hat{\tau}_{I+CD} = \gamma_0+\gamma_1W_1+\gamma_2W_2+\gamma_3W_3+\gamma_4W_4+\epsilon.
6.4. Numerical experiments
We simulated the tail mean for the example set forth in Section 5.6, and the results are reported in Table 6.1 and Figure 6.1. The “Target” values of are estimated by the importance sampling method with a huge sample size of They are the proxies for the true values.
__of_the_estimators_for___mathbf_e__left__left(s_1-c_right.png)
The I+CD+CV method has the smallest relative error among all methods introduced.
7. Conclusion
Methods for simulating tail probability and tail mean of both univariate and bivariate compound variables were studied in detail in this paper. We first reviewed some basic simulation variance reduction methods, then we proposed several novel combinations of variance reduction methods specifically for compound distributions. We showed that combinations of importance sampling, stratified sampling, the conditioning method, and the control variates method can greatly enhance the performance of the preliminary methods in estimating tail probability and tail mean. Among all the methods we studied, the I+CD+CV combination consistently performed well, with its CoV (relative error) among the smallest of all methods in all experiments. This combination is especially helpful for simulating the tail mean.
We have proposed the simulation methods for some simple and commonly used aggregate loss models. In practice, the scenarios that need to be simulated are much more complex and the methods introduced here may not be directly used. However, it is likely that the basic variance reduction methods and their combinations can still be applied after some adaptations to the actual problem. We argue that it is worthwhile for actuaries to spend the time and energy to discover ways to utilize them because they could enhance the accuracy of simulations and/or significantly reduce simulation times.
Acknowledgments
The authors are grateful to two anonymous reviewers for their valuable comments, which helped improving the paper greatly. We also appreciate the many discussions on the topic with Professors Edward Furman, Katsu Goda and Ricardas Zitikis. This research has been supported by the Natural Sciences and Engineering Research Council (NSERC) of Canada.