1. Introduction
Usually, an auto insurance policy consists of various types of coverage against claims, such as collision, bodily injury liability, or property damage liability. Upon the presence of available covariates, their impacts for each type of claim could be different so that one needs to apply different regression coefficients for each claim type. Besides, it is natural to expect that various types of claims have different correlations with the unobserved heterogeneity in risk, such as driving habits. For example, an at-fault liability claim is usually at the control of a driver, so that the occurrence of such a claim is strongly related with driving habits. However, glass damage claims (for example, due to a heavy hail storm) are almost out of the driver’s control, so that association with driving habits is quite low. In the end, a company needs to develop a predictive model that utilizes the covariate information to calculate a presumptive premium as well as the unobserved heterogeneity in risks, which can be indirectly captured by past claims history of each policyholder.
The idea of capturing the unobserved heterogeneity via past claims history has been discussed under the name of credibility theory. Bailey (1950) and Bühlmann (1967) suggested the credibility procedure, which usually arrives at the following formula:
Posterior premium=Z×Claim experience+(1−Z)×Prior premium,
where is the so-called credibility weight. Since then, credibility theory has been developed and explored in the actuarial science literature. For example, Mayerson (1964) and Jewell (1974) analyzed credibility theory from a Bayesian perspective. While these researchers working on credibility theory provided a way to incorporate the unobservable heterogeneity, both the observed and unobserved heterogeneities need to be addressed in actuarial ratemaking practice, as shown in Norberg (1986). In this regard, Frees, Young, and Luo (1999) provided a general framework that integrated well-known credibility theory and regression analysis based on the use of linear mixed models. The linear mixed model is an extension of the linear model, whereby the response variable is affected by both the observed covariates via associated regression coefficients (fixed effects) and unobserved quantities (random effects). Upon the use of both fixed and random effects with a mixed model, it is noteworthy that credibility premiums have a close connection with bonus-malus systems, which reward or penalize a policyholder based on past claims history. Frangos and Vrontos (2001) showed that, upon the presence of fixed effects, credibility premium (or posterior premium) for claim takes the following form:
Posterior premium=r+Actual claim experiencer+Expected claim experience×Prior premium,
where denotes a smoothing factor in the bonus-malus system so that larger values of put less weight on past claims history. Similar results have been shown in the recent literature such as Jeong (2020) and Jeong and Valdez (2020a). Boucher and Denuit (2008) and Boucher, Denuit, and Guillen (2009) considered the use of a zero-inflated Poisson distribution in panel data to derive credibility premiums.
However, one should also consider possible dependence among the claims from either multiple lines of business or multiple coverages, in order to apply to ratemaking practices. Frees, Meyers, and Cummings (2010) proposed dependence modeling for multi-peril insurance under the individual risk model, which decomposes the compound loss into occurrence (a binary response whether there is a claim or not) and total amounts given a claim. To model dependence among the occurrence of claims in multiple coverages, they utilized multivariate binary regression via Gaussian copulas. On the other hand, Frees, Lee, and Yang (2016) proposed dependence modeling for multi-peril insurance under the collective risk model, which decomposes the compound loss into claim frequency and severity components. They applied copulas to describe possible dependence among the multivariate frequencies and severities, respectively. Andrade e Silva and Centeno (2017) suggested using various generalized bivariate frequency distributions to capture multi-peril dependence, which also allow capturing possible overdispersion in the observed claim counts. Quan and Valdez (2018) proposed the use of a multivariate decision tree in multi-peril claim amounts regression.
Interestingly, there are only a few research papers that incorporated such multi-peril dependence and longitudinal property simultaneously. For example, Frees (2003) proposed a way to calculate credibility premium of compound loss for multi-peril policy by specifying only the mean and covariance structures of claim frequencies and severities. While Frees took a non-parametric approach, Bermúdez and Karlis (2015) applied bivariate Poisson distributions for a posteriori ratemaking of two types of claims. However, these papers are limited to non-parametric or parametric setting without covariates, so that it is hard to incorporate both the observed and unobserved heterogeneities of a policyholder simultaneously with their models. Abdallah, Boucher, and Cossette (2016) provided a sophisticated approach to utilizing a bivariate Sarmanov distribution to account for the dependence between two lines of business with time weight for past claims, which is appropriate to deal with two types of claims but difficult to extend to the case where there are more than two types of claims. Recently, Pechon et al. (2018; 2019, 2020) proposed credibility premium formulas with multiple types of claims using correlated lognormal random effects. Although they provided a comprehensive framework that considers possible dependence among multi-peril claims in a longitudinal setting, their method requires high-dimensional integration (six or seven) in order to obtain credibility factors and marginal frequency distributions for every single policyholder, which may be burdensome in practice where the number of policyholders is usually large.
A novel method is proposed in this article that enables us to consider both the observed and unobserved heterogeneities of a policyholder in a longitudinal setting for multi-peril insurance via shared random effects. The proposed method can handle more than two types of claims and leads to a readily available closed-form formula for multi-peril credibility premiums. In short, the shared random effect for a policyholder is a latent variable that cannot be observed but affects the claims from multiple perils over time and induces a natural dependence structure among the claims. This article is organized as follows. In Section 2, the proposed method—a shared random effects model for multi-peril frequency—is specified in detail, and important characteristics of the model are provided including the multi-peril credibility premium formula. In Section 3, an empirical data analysis is conducted using a data set provided by the Wisconsin Local Government Property Insurance Fund (LGPIF). We conclude this article in Section 4 with some remarks and possible directions for future work.
2. Methodology
Let us consider a usual data structure for multi-peril frequency. For an insurance policy of policyholder where we may observe the multi-peril claim frequencies over time for types of coverage as follows:
D={(N(1)it,…,N(j)it,…,N(J)it,xit)|i=1,…,I,t=1,…,T},
where is a -dimensional vector that captures the observable characteristics of the policy and is defined as the number of accident(s) from claim type for the policyholder in year respectively.
Based on the data structure, one can consider the following issues for multi-peril frequency modeling. Although the Poisson distribution is widely used for modeling frequency, it is often questionable whether it is valid due to possible overdispersion. In order to handle this issue, according to Wedderburn (1974), one can use a quasi-Poisson distribution to capture overdispersion in the observed data as follows:
N∼QP(ν,w)⟺wN∼P(wν),
for which and Here means follows a Poisson distribution with mean In that regard, the Poisson distribution is a special case of the quasi-Poisson distribution where Due to this nested property, some research results enable to test
H0:w=1 versus H1:w≠1.
For details, see Cameron and Trivedi (1990).
Secondly, recall that the data structure described in (2.1) has longitudinality, or repeated measurements of the same policyholder over time. Thus, it is natural to incorporate random effects, which may account for unobserved heterogeneity in risks of each policyholder. The following hypothetical example in Table 1 shows that one can capture the unobserved heterogeneity in risks by observing the residuals, after controlling for the effect of the observed covariates. The latter can be explained in terms of random effects for policyholders A and B. In Table 1, it is possible to observe that both policyholders have the same observable characteristics, whereas they exhibit quite different past claims experiences. In such a case, one may suspect that the observed covariates might not be sufficient to fully explain the heterogeneity in risks. Random effects can help capture such (unobserved) heterogeneity for both types of claims.
As we can see, the random effects model has connections with credibility theory and bonus-malus systems as well. Some papers have incorporated random effects in a ratemaking perspective, including but not limited to Gómez-Déniz and Vázquez-Polo (2005) and Jeong and Valdez (2020b).
Based on the observations from Table 1, let us assume that the number of claims is affected by both observable covariates via associated regression coefficients and the (common) unobserved heterogeneity factor It is shared for all types of coverages and every year of claims of policyholder as follows:
N(j)it|xit,eit,θiindep∼QP(θiν(j)it,w(j))⟺ w(j)N(j)it|xit,eit,θiindep∼P(θiw(j)ν(j)it) and E[θi]=1,
where is the exposure, and is the (unknown) weight for each line of business or type of coverage. Here accounts for the observed heterogeneity in risks of policyholder at time for coverage while multiplicative random effect accounts for the unobserved heterogeneity in risks of policyholder One can also find a very comprehensive setup of the Poisson model with a shared random effect in Shi and Valdez (2014a), which is helpful to understand the proposed setup of the quasi-Poisson model with a shared random effect. Though does not necessarily have integer-valued quantities with quasi-Poisson distribution, the proposed framework allows for obtaining the posterior distribution of Subsequently, distributional quantities of are easy to derive with the distribution, which are our main interest.
With the specification above, it is straightforward to derive that
E[w(j)N(j)it|θi]=w(j)ν(j)itθi and E[N(j)it]=ν(j)it,
since Therefore, can be interpreted as a prior mean of the number of claims at time for policyholder without any information on her/his unobserved heterogeneity. For notational convenience, we suppress the subscript from now on when there is no confusion. Figure 1 provides a graphical description of the proposed model specified in (2.2). Although we assume that the common random effect affects multiple types of peril simultaneously, we also allow to vary so that the impacts of to are not necessarily identical.

Note that the use of shared random effects is not the only way to capture possible dependence among multi-peril claims in a longitudinal setting. For example, one can utilize copulas to capture such dependence. For details, see Yang and Shi (2018).
The impact of the unobserved heterogeneity on the claim frequency is inherently unknown. Therefore, it needs to be described with a specified prior distribution. In a Bayesian analysis, it is usually recommended to use a noninformative prior or less informative prior on unless we have enough knowledge on the dynamics of the random parameter. In this sense, one can suggest to use Jeffreys’ prior, perhaps the most widely used noninformative prior in Bayesian analyses. According to Jeffreys (1946), Jeffreys’ prior is defined as the square root of the determinant of the Fisher information matrix. One can see that under the model specification in (2.2), Jeffreys’ prior of is given as and the corresponding posterior distribution is proportional to so that Here means follows a gamma distribution with mean and variance
The corresponding posterior is proper although Jeffreys’ prior itself is improper. Nevertheless, there is an identifiability issue, unless we impose a condition on the mean of the random effects. For example, it is customary to set when is an additive random effect. Likewise, since is a multiplicative random effect in our specified model, we need to impose that Therefore, in order to satisfy the identifiability condition as well as have a similar posterior as in the case of Jeffreys’ prior, one can propose the following prior on :
π(θ)∝θr−1e−θr so that θ∼G(r,1/r) and E[θ]=1,Var[θ]=1r.
Here is the so-called conjugate prior. This choice is not ad hoc but from the argument of prior elicitation, considering both informativeness of the prior and identifiability of the fixed effects. Based on the model specification in (2.2) and (2.3), it follows that
E[N(j)t]=ν(j)t and Var[N(j)t]=ν(j)t/w(j)+(ν(j)t)2/r,
since from Theorem 1. Here means follows a negative binomial distribution with mean and variance
It is also shown that
Cov(N(j)t,N(k)t′)=E[Cov(N(j)t,N(k)t′|θ)]+Cov(E[N(j)t|θ],E[N(k)t′|θ])=Cov(ν(j)tθ,ν(k)t′θ)=ν(j)tν(k)t′/r,Corr(N(j)t,N(k)t′)=Cov(N(j)t,N(k)t′)Var[N(j)t]Var[N(k)t′]=1√1+r/w(j)ν(j)t√1+r/w(k)ν(k)t′,
for and due to conditional independence of and given Therefore, the proposed model induces a natural dependence structure among the frequencies of the multiple insurance coverages over time. For example, if then the proposed model is reduced to an independent quasi-Poisson model. Further, if and for all then the proposed model is reduced to an independent Poisson model.
Since the multiplicative random effect can be understood as a bonus-malus factor on top of for determination of insurance premium. The value of hyperparameter can be determined by using either prior knowledge or the method of moments. For example, from to was once a common range of bonus-malus factors for the frequency premium according to Lemaire (1998). Therefore, one can incorporate this idea on choosing the hyperparameter for our proposed prior so that the highest posterior density (HPD) interval of can include One can also consistently estimate since the expectation of is for (Sutradhar and Jowaheer 2003) so that
ˆr=∑Ii=1∑t≠t′,j≠kˆν(j)itˆν(k)it′∑Ii=1∑t≠t′,j≠k(N(j)it−ˆν(j)it)(N(k)it′−ˆν(k)it′),
where is consistently estimated by solving generalized estimating equations (GEE) with a pre-specified mean structure (Liang and Zeger 1986; Purcaru, Guillén, and Denuit 2004; Denuit et al. 2007). According to this specification, one can easily observe that posterior density for as follows:
Lemma 1. Based on the model specification described in (2.2) and (2.3), we have
θ|n(1)T,…,n(J)T∼G(J∑j=1T∑t=1w(j)n(j)t+r,1∑Jj=1∑Tt=1w(j)ν(j)t+r),
where
Proof. It is easy to show that
π(θ|n(1)T,…,n(J)T)∝π(θ)J∏j=1T∏t=1p(w(j)n(j)t|θ)∝θr−1e−θrJ∏j=1T∏t=1θw(j)nte−ν(j)tθ=θ∑Jj=1∑Tt=1w(j)n(j)t+r−1exp(−θ(J∑j=1T∑t=1w(j)ν(j)t+r)),
which leads to
θ|n(1)T,…,n(J)T∼G(J∑j=1T∑t=1w(j)n(j)t+r,1∑Jj=1∑Tt=1w(j)ν(j)t+r).
□
Further, it is not difficult to show that the predictive distribution of given follows a negative binomial distribution as follows:
Theorem 1. Suppose that and follow the model specified in (2.2) and (2.3). Then we have
w(j)N(j)T+1|n(1)T,…,n(J)T∼NB(rT,w(j)ν(j)T+1˜rT+w(j)ν(j)T+1),
where and
E[N(j)T+1|n(1)T,…,n(J)T]=r+∑Jj=1(w(j)∑Tt=1n(j)t)r+∑Jj=1(w(j)∑Tt=1ν(j)t)ν(j)T+1.
Proof. It is sufficient to show that if and then
p(n)=∫∞0p(n|θ)π(θ)dθ=∫∞0λnθnn!e−θλβrθr−1Γ(r)e−θβ=νnβrn!Γ(r)∫∞0θn+r−1e−θ(β+ν)=νnβrn!Γ(r)Γ(n+r)(β+ν)n+r=Γ(n+r)n!Γ(r)(νβ+ν)n(ββ+ν)r,
so that and
□
Therefore, the predictive premium of with the previous years’ information, is given in the form of a product of a prior premium that depends on regression coefficients associated with observable covariates, and with a pooled estimate of the credibility factor, which accounts for the unobserved (shared) heterogeneity on the claim frequency of a specific policyholder. Note that (2.7) is a natural extension of Frangos and Vrontos (2001), whereby and For example, if and denote the claim frequencies due to at-fault liability and glass damage, respectively, then the pooled estimate of unobserved heterogeneity is given as
E[θ∣n(1)T,n(2)T]=r+w(1)∑Tt=1n(1)t+w(2)∑Tt=1n(2)tr+w(1)∑Tt=1ν(1)t+w(2)∑Tt=1ν(2)t= smoothing factor + weighted sum of actual frequencies smoothing factor + weighted sum of expected frequencies .
Therefore, the proposed model specification enables us to consider different levels of contribution to the credibility factor, by allowing varying dispersions for multiple perils.
In (2.8), the hyperparameter of the prior distribution of is working as a smoothing factor. For example, if then converges to a Dirac delta function at 1, which implies that and ends up with a very informative point-mass prior. On the other hand, any choice of a smaller leads to use of a less informative prior.
In light of the empirical Bayes method, the estimation of parameters for can be done by maximizing the following joint loglikelihood:
ℓ(α(1),…,α(J)∣n(1)T,…,n(J)T)=M∑i=1lnp(w(1)n(1)iT,…,w(J)n(J)iT),
where
p(w(1)n(1)iT,…,w(J)n(J)iT)=∫J∏j=1T∏t=1p(w(j)n(j)it|θi)π(θi)dθi∝J∏j=1T∏t=1[(w(j)ν(j)it∑Jj=1∑Tt=1w(j)ν(j)it+r)w(j)n(j)it×(r∑Jj=1∑Tt=1w(j)ν(j)it+r)r],
which follows a multivariate negative binomial (MVNB) distribution indeed.
3. Data Analysis
In this article, we use a public data set of insurance claims that has been provided by the Wisconsin Local Government Property Insurance Fund (LGPIF). The data set consists of six years of observations, from 2006 to 2011. We used a training set of 5,677 observations from 2006 to 2010 and a test set of 1,098 observations from 2011. Since there is a unique identifier that allows tracking of the claims of a policyholder over time, it is indeed longitudinal data. Furthermore, the data set contains the claims information for multiple lines of business so that one can try multivariate longitudinal frequency modeling. Here, information on inland marine claims (IM), collision claims from new vehicles (CN), and comprehensive claims from new vehicles (PN) is used with six categorical and four continuous explanatory variables. Table 2 provides a detailed summary of the observable policy characteristics of all lines of insurance business. Note that all of the categorical variables, which are dummy variables for location types, are commonly used for all types of coverage, but their impact is not necessarily identical.
Before the fixed effects are incorporated in the marginal models of the coverages, a variable selection was performed by using penalized Poisson likelihood with elastic net, which considers both and penalties. Since the location parameters are correlated with each other, it is desirable to consider penalty for performing variable selection group-wise on top of penalty. The variable selection was implemented using glmnet (Friedman et al. 2021) by setting so that weights on and penalties are equal. As shown in Figure 2, it turns out that the validation errors measured by Poisson deviances are minimized with no variable selection in all three coverages. Therefore, all the available covariates were used for the calibration of marginal models eventually.

Since the proposed model specified in (2.2) and (2.3) assumes the presence of both overdispersion and association among the numbers of claims from multiple coverages, one needs to investigate their effect in order to validate the application of more complicated models than the naive independent Poisson model. Table 3 shows the frequency tables for the number of IM, CN, and PN claims. By applying the usual measures to investigate the association between each pair of categorical responses, summarized in Table 4, one can observe that there are significant positive associations among the numbers of IM, CN, and PN claims, at least without controlling the possible impacts of common covariates. Note that these measures need to be used with precautions since they may not be appropriate for insurance claim counts with excessive zeros, due to possible ties in ranking. For discussions on effects of ties on the rank-based correlation, see Kendall (1945).
There has been some research on ways to estimate the dispersion parameter in a quasi-Poisson distribution. For example, McCullagh and Nelder (1989) proposed while Cameron and Trivedi (1990) proposed where is expected value of frequency response depending on the estimated parameter(s) from the calibrated model, is the number of estimated parameter(s), and is the number of total observations. According to Table 5, for all types of coverages, we can observe that dispersion parameters are estimated to be quite above one. (Remember that the dispersion parameter should equal one under the Poisson assumption.)
Cameron and Trivedi (1990) also showed that
˜Z=˜ϕ√1n∑mk=1(˜Rk−˜ϕ)2≃N(0,1) under H0:ϕ=1,
when is large enough and for are independent. For the given data, the values of for IM, CN, and PN claims are 2.7844, 4.1829, and 3.8956, respectively. Therefore, one can find significant evidence to reject the hypothesis that there is no overdispersion in all lines of business.
Since we have observed possible overdispersion from the data, it is natural to consider the following models that can capture overdispersion or possible dependence, except for the independent Poisson model:
-
Poisson: Independent Poisson model as an industry benchmark. Note that it is a special case of the proposed model where and
-
Poisson/gamma: Poisson random effects model where each coverage has unique unobserved heterogeneity as follows: N(j)it|xit,eit,θiindep∼P(θ(j)iν(j)it), θ(j)∼G(rj,1/rj). Note that the marginal mean of under Poisson/gamma model is as in the independent Poisson model, so that we use the same regression coefficients of as the independent Poisson model.
-
ZI-Poisson: Zero-inflated Poisson model with the following density: p(n(j)t;ν(j)t,η(j)t)={η(j)t+(1−η(j)t)exp(−ν(j)t),n(j)t=0(1−η(j)t)(ν(j)t)n(j)texp(−ν(j)t)n(j)t!,n(j)t≠0, which also assumes for all or Since captures the zero-inflated probability, it is usual to model as
-
Copula: While each marginal component is modeled with a Poisson distribution, possible dependence among the lines of business is captured by a copula, as proposed in Shi and Valdez (2014b), so that the joint probability of and is given as follows: p(n(1)t,n(2)t,n(3)t;ν(1)t,ν(2)t,ν(3)t,ϕ)=Cϕ(u(1)t+,u(2)t+,u(3)t+)−Cϕ(u(1)t−,u(2)t+,u(3)t+)−Cϕ(u(1)t+,u(2)t−,u(3)t+)+Cϕ(u(1)t−,u(2)t−,u(3)t+)−Cϕ(u(1)t+,u(2)t+,u(3)t−)+Cϕ(u(1)t−,u(2)t+,u(3)t−)+Cϕ(u(1)t+,u(2)t−,u(3)t−)−Cϕ(u(1)t−,u(2)t−,u(3)t−),
where means a copula function parametrized by and -
Proposed model: The model specified in (2.2) and (2.3).
In the calibration of the Proposed model, values of should be determined either by prior knowledge of the characteristics of the multiple perils or by some statistics determined by observations. As mentioned in (2.8), a pooled estimate of the credibility factor is given as the ratio of weighted sum of actual frequencies to weighted sum of expected frequencies. Therfore, can be interpreted as a peril-specific factor that provides information about the association between the peril and the unobserved heterogeneity, such as driving habits. For instance, suppose there are two types of coverage: property damage (PD) liability and glass damage to the driver’s own car. In that case, claims from PD liability are more positively associated with the unobserved heterogeneity in risks than claims from glass damage, since claims from PD liability are at-fault of the policyholder, whereas claims from the driver’s own glass damage may be due to external factors such as a heavy hail storm. In this regard, it is natural to put more weight on the past claims experiences from PD liability than those from drivers’ own glass damage in calculating the pooled estimate of the credibility factor, or, equivalently, set for PD liability higher than for drivers’ own glass damage. Therefore, the proposed method enables practitioners to incorporate their prior knowledge about the characteristics of multiple perils in the modeling process with flexibility.
If there is no strong evidence to pre-specify the values of with prior knowledge, then one can directly use the estimated overdispersion parameters to determine by matching the moments. Recall that from (2.4) we have
Ti∑t=1E[(N(j)it−ν(j)it)2]=Ti∑t=1Var[N(j)it]=Ti∑t=1νitw(j)+(ν(j)it)2r,
for and under the proposed model so that one can consistently estimate in a similar manner to (2.6):
ˆw(j)=∑Ii=1∑Tit=1ˆν(j)it∑Ii=1∑Tit=1[(N(j)it−ˆν(j)it)2−(ˆν(j)it)2/ˆr].
Once the overdispersion parameters for are specified, either from the prior knowledge or moment matching, one can estimate and from the joint likelihood after integrating out the shared random effect, as given in (2.10). In our analysis, we used the moment matching approach so that and are estimated to be and respectively. Since in our case, the relative contribution of IM frequencies to the proposed posterior ratemaking scheme is greater than those of CN and PN frequencies.
Tables 6, 7, and 8 provide the estimated regression coefficients for IM, CN, and PN frequencies, respectively. One can observe that the regression coefficients from the Poisson and Proposed models are similar while the coefficients from the other models are different. Further, as mentioned above, all types of frequencies share some dummy variables indicating location types, but their estimated coefficients are quite different from each other. This supports our model specification in that one can capture the fixed effects separately for each line of business while retaining a natural dependence structure by the shared random effects.
Figure 3 shows the distributions of the credibility factors under the proposed model, which are defined as the posterior expectations of given observations of past claims:
E[θ|n(1)T,n(2)T,n(3)T]=r+w(1)∑Tt=1n(1)t+w(2)∑Tt=1n(2)t+w(3)∑Tt=1n(3)tr+w(1)∑Tt=1ν(1)t+w(2)∑Tt=1ν(2)t+w(3)∑Tt=1ν(3)t.
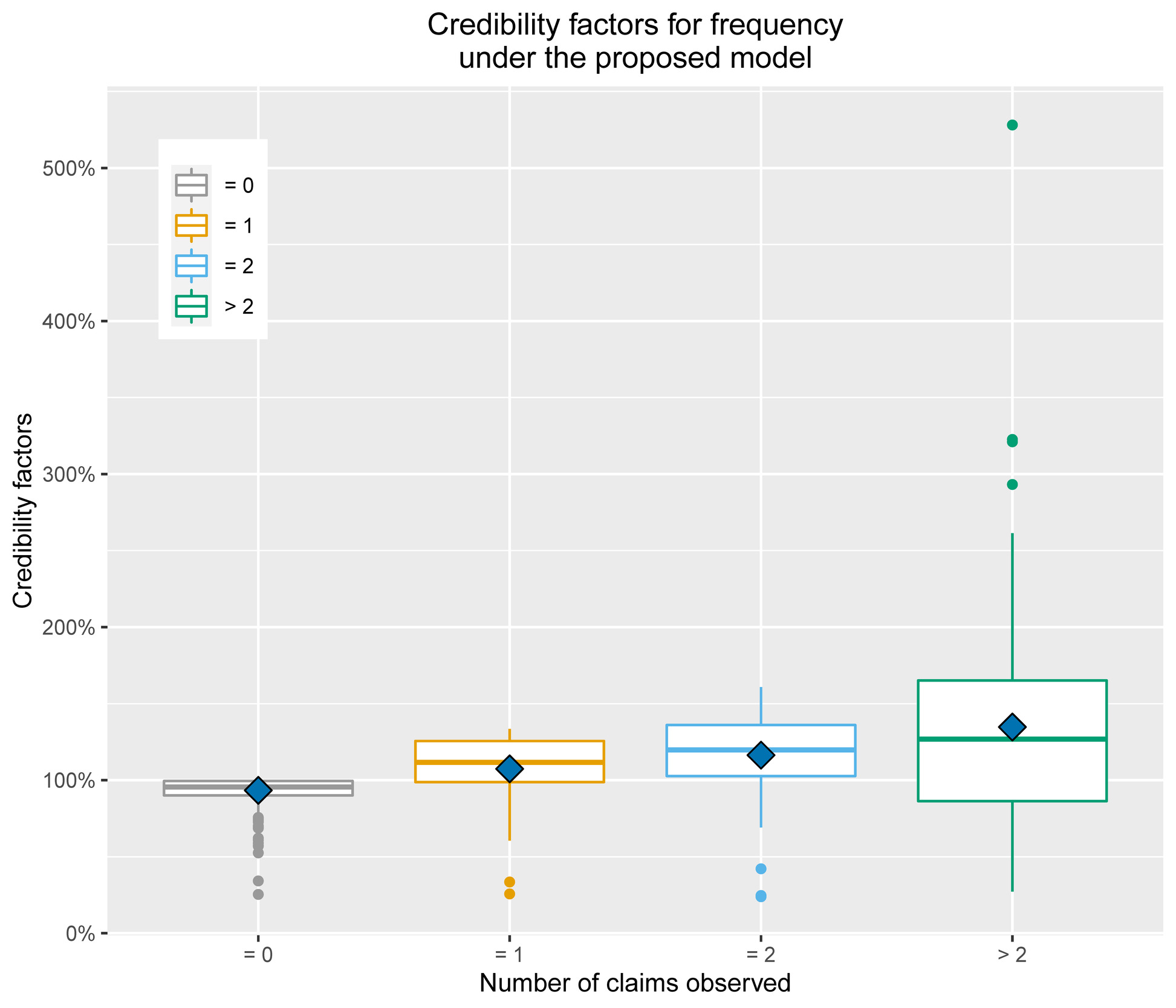
Blue squares mean the average of credibility factors for each group. From the figure, one can see that, if there are no past claims, then the insured can get a discount since while for all and It is also observed that, as a policyholder has more past claims, the credibility factor tends to rise on average. However, regardless of such general positive association between credibility factors and number of past claims, the latter varies because the proposed credibility premium formula utilizes both the actual claims and expected claims, which is based on the observable heterogeneity of risks. By doing so, an insurance company may avoid double discounts or surcharges due to segregating the impacts of the observable policy characteristics and unobservable heterogeneity in risks.
After all five models are calibrated, one can test the validity of each model by comparing the predicted performance via out-of-sample validation. In this case, it is natural to predict as under each model. Recall that
\begin{aligned} &{\mathbb E}\left[N_{T+1}^{(j)}|\mathbf{n}_T^{(1)},\mathbf{n}_T^{(2)}, \mathbf{n}_T^{(3)} \right]\\ &\quad= \frac{r + w^{(1)}\sum_{t=1}^T n_t^{(1)}+w^{(2)}\sum_{t=1}^T n_t^{(2)}+w^{(3)}\sum_{t=1}^T n_t^{(3)}}{r+ w^{(1)}\sum_{t=1}^T \nu_t^{(1)}+w^{(2)}\sum_{t=1}^T \nu_t^{(2)}+w^{(3)}\sum_{t=1}^T \nu_t^{(3)}} \\ &\qquad \cdot e^{\mathbf{x}_{T+1}\alpha^{(j)} } \end{aligned}
under the Proposed model from Theorem 1, whereas
{\mathbb E}\left[N_{T+1}^{(j)}|\mathbf{n}_T^{(1)},\mathbf{n}_T^{(2)}, \mathbf{n}_T^{(3)} \right]={\mathbb E}\left[N_{T+1}^{(j)}\right]=e^{\mathbf{x}_{T+1}\alpha^{(j)} }
under the Poisson model.
To compare the out-of-sample validation performance, we use root-mean-square error (RMSE), mean absolute error (MAE), and Poisson deviance (PDEV) for each coverage that are defined as follows:
\small{ \begin{aligned} \text{RMSE}&: \sqrt{\frac{1}{I}\sum_{i=1}^I (N^{(j)}_{i,T_i+1}- \hat{N}^{(j)}_{i,T_i+1} )^2}, \\ \text{MAE}&: \frac{1}{I}\sum_{i=1}^I |N^{(j)}_{i,T_i+1}- \hat{N}^{(j)}_{i,T_i+1} |, \\ \text{PDEV}&: 2 \sum_{i=1}^I \left[ N^{(j)}_{i,T_i+1} \log (N^{(j)}_{i,T_i+1}/\hat{N}^{(j)}_{i,T_i+1}) - (N^{(j)}_{i,T_i+1}- \hat{N}^{(j)}_{i,T_i+1}) \right], \end{aligned} }
where means the number of observed policyholders in the validation set. We prefer a model with lower RMSE, MAE, and/or PDEV. As shown in Tables 9, 10, and 11, the Proposed model outperforms Poisson, ZI-Poisson, and Copula models in all validation measures. It is also shown that the Proposed model is comparable to Poisson-gamma model in RMSE and MAE while prediction performance of Poisson-gamma in PDEV is outstanding. Such empirical results show that the interdependence among the unobserved heterogeneities of coverages may exist but not be substantial in the given data set.
4. Conclusion
It is quite natural that an insurance company observes the same policyholder over many years with multiple coverages. Inspired by such characteristics, a new method is explored in this article that allows us to incorporate distinct fixed effects capturing inherent characteristics of each type of coverage (or line of business), while retaining a natural dependence structure among the claims from multiple perils over time, via the shared random effects. The proposed model has a good interpretation that can explain both overdispersion and serial/multi-peril dependence. The model is also easy to implement due to the presence of the closed form of joint likelihood and multi-peril premium formula. The proposed method is tested using a public property and casualty insurance data set provided by LGPIF. From the empirical study, it is observed that the proposed method outperforms many existing benchmarks but is less powerful than the model with unique heterogeneity for each coverage. Based on the results, one can consider a compromise between the complete shared random effects model (all coverages share the same random effect) and the unique random effects model (each coverage has its own unique random effect) by investigating underlying interdependence among the unobserved heterogeneities, as a future research topic.
Electronic Supplementary Material
The code for data analysis and out-of-sample validation is available at https://github.com/ssauljin/multi-peril_cred_premium/.