1. Introduction
Natural catastrophe reinsurance plays a vital role in the financial system by enabling homeowners, insurance companies, and governments to manage the negative consequences of large losses from hurricanes, earthquakes, severe storms, and inland and coastal flood events. One of the most common and important examples of natural catastrophe reinsurance is the catastrophe excess of loss (catXL) contract. CatXL contracts are typically purchased by primary insurance companies from reinsurers. CatXL coverage enables primary insurers to improve their risk/return profiles and remain solvent after the occurrence of severe natural catastrophes. Technical pricing of catXL reinsurance is fundamental to the workings of the insurance value chain. In nearly all cases, technical prices are derived from natural catastrophe simulation models using proprietary software, models, and data. Over the past two decades, significant resources have been devoted to the development of complex natural catastrophe risk models based in physics, statistics, and engineering. This reflects both the materiality of the risks involved and their complex nature.
The process of generating a technical price for a given catXL contract is best understood by example. Consider a primary insurance company whose portfolio of residential properties is scattered throughout the southeastern United States. We first create a database which stores all the relevant information about the buildings that compose the portfolio. A catastrophe modelling software is then run to generate a so-called timeline simulation of losses (accounting for limits and deductibles in the underlying homeowner policies) arising from various natural perils (e.g., hurricanes and severe convective storms). The timeline simulation of losses is then used as the basis for generating a technical price for a catXL reinsurance contract under various terms and conditions. Typically a large number of “simulation years” is used to avoid convergence errors (it is not uncommon to use 1 million years of simulation). In this work, we make a mathematical abstraction where we view the timeline simulation for a specific portfolio as being generated from a frequency distribution (which describes the random number of events per year) and a severity distribution (which describes the random financial loss in dollars given an event occurrence).
In this paper we look at the timeline simulations from the perspective of the so-called order statistics. Each year of simulation has an annual maximum loss, a second annual maximum, and so on. These ordered annual maxima are what we refer to as the order statistics. Previous studies have addressed the importance of the various order statistics in analysis of technical pricing metrics for catXL contracts (Khare and Roy 2021). As discussed in Khare and Roy (2021), the exceedance probabilities of the order statistics for various loss thresholds are fundamental to understanding which ordered maxima make the largest contributions to pricing metrics. With this in mind, the objective of this work is to develop and demonstrate a framework to quantify the implications of changes to the underlying catastrophe models (expressed through changes in the frequency and severity for the exceedance probabilities of the order statistics in timeline simulations. We presume that changes to the underlying frequency and severity arise for a number of reasons, but the primary reason we have in mind is climate change. In other words, this paper builds a mathematical framework that can be used as the basis for understanding the implications of climate change for technical reinsurance pricing. Given the urgent need to address issues related to climate change and the central role that reinsurance plays in risk transfer, this paper addresses an issue of clear societal relevance. While the focus in this paper is on the fundamental and mathematical aspects of this problem, we also discuss how our results can be used by practitioners to address the impacts of model changes arising from climate change on reinsurance pricing.
The mathematical problem of interest in this work is the order statistics of samples from a continuous distribution with random sample sizes drawn from a discrete distribution A series of papers addressing the order statistics under random sample sizes dates back to the 1970s (e.g., Barakat and El-Shandidy 2004; Buhrman 1973; Consul 1984; David and Nagaraja 2003; Gupta and Gupta 1984; Young 1970). Recently Khare and Roy (2021) discussed the order statistics problem within the context of reinsurance pricing, providing analytical expressions for the cumulative probability of all order statistics, the application to the commonly used Poisson and negative binomial distributions, as well as an analysis of the correlation structure of the order statistics. This paper builds on Khare and Roy (2021) by formalizing the presentation of the general formula for the cumulative probability of all order statistics, also casting the general formula into a form that is more useful from a practitioner’s point of view, and it explores the application of the general formula to a broader set of frequency distributions (including the binomial, the Generalized Poisson, and the Conway-Maxwell-Poisson). We use the mathematical machinery discussed in this paper to numerically demonstrate the sensitivity of the order statistic exceedance probabilities to changing model assumptions, achieving our main objective of building a framework which can aid in understanding the effect of climate change on reinsurance pricing metrics.
More specifically, the key contributions of this paper are as follows:
-
We review the key result, which is the general expression of all order statistic cumulative probability distributions for a given frequency and severity (Theorem 3.2). The main result is equivalent to equation 9 in Khare and Roy (2021), but we provide a more clear, concise, and formal proof.
-
We show that the main result, Theorem 3.2, can be reformulated in a form that is particularly appropriate for risk modelling, as it references explicitly the commonly discussed distribution of the annual maximum. The reformulated but mathematically equivalent result is provided in Corollary 3.3.
-
We apply the general formulation in Corollary 3.3 to what we call the canonical frequency (consisting of the negative binomial, Poisson, and binomial distributions) to develop closed form expressions for the order statistic cumulative probability distributions. The results for the Poisson and negative binomial distributions are equivalent to those found in Khare and Roy (2021) but are reformulated into a simpler and more useful form. The result for the binomial distribution is new, as far as we know. The result is provided in Proposition 3.4.
-
We provide a novel set of numerical experiments in which we apply the result from Corollary 3.3 to two commonly applied generalized frequency distributions, the Generalized Poisson (Consul and Jain 1973) and Cromwell-Maxwell-Poisson (Conway and Maxwell 1962). Our results suggest that the order statistics implied by the Generalized Poisson and Cromwell-Maxwell-Poisson are nearly identical to the canonical case. This is useful background knowledge in circumstances where the Generalized Poisson and/or Cromwell-Maxwell-Poisson distributions are applied (the generalized distributions have particular advantages discussed in Consul and Famoye 1990 and Sellers and Shmueli 2010).
-
To address our central goal of understanding the implications of model changes to reinsurance pricing metrics, we provide a comprehensive investigation into how order statistic exceedance probabilities change as a function of altered frequency model assumptions. We achieve this by plotting what we call “Sensitivity Spaces” using the analytical formulas for the canonical case (Proposition 3.4). A number of new insights are achieved through our visualizations. Incidentally, our Sensitivity Space plots also shed light on a potential benefit of using one of the generalized frequency distributions rather than the canonical distribution (when the so-called frequency distribution dispersion is less than
-
Finally, we tie together our mathematical and numerical work by discussing how practitioners can leverage our results to understand the potential impacts of climate change on reinsurance pricing metrics.
This paper is organized as follows. In Section 2 we discuss preliminaries, where we make clear various mathematical definitions, including the order statistic random variable, our notation, and various assumptions. In Section 3 we provide the analytical formulations of the order statistic distributions for a generic frequency and severity as well as closed form solutions for the canonical frequency (negative binomial, Poisson, and binomial). In Section 4 we discuss our numerical experiments and their implications. In Section 5 we discuss how practitioners can use the results in this paper to understand the implications of climate change for reinsurance pricing metrics. Section 6 provides a summary, draws conclusions, and discusses future research directions.
2. Preliminaries
The risk models central to this work consist of a discrete frequency distribution and a continuous severity distribution to generate so-called timeline simulations of event and loss occurrences that form the basis for risk quantification. We start here with preliminaries to make clear various mathematical definitions, the problem statement, and our intended application to risk modelling. Some elementary definitions are provided for completeness and context. We start with the discrete frequency distribution.
Definition 2.1. Frequency distribution: The random number of events over a specified time interval (taken to be 1 year without loss of generality) is given by and has a discrete frequency distribution where and
The expectation and variance of the frequency distribution are denoted by and respectively, and their ratio is the well-known dispersion parameter defined as follows.
Definition 2.2. Dispersion: The dispersion of a frequency distribution is
D=V[N]E[N],
where
One of the main goals of this work is to explore the sensitivity of practically important risk model metrics to the expectation and variance over the full range of dispersion To enable this, we define what we call the canonical frequency distribution, consisting of the triad of frequency distributions given by the negative binomial for the Poisson for and the binomial for We label this combination of frequency distributions as the canonical case due to its common application in risk modelling and various well-known mathematical properties (Klugman, Panjer, and Willmot 2008).
Definition 2.3. Canonical frequency distribution: For is given by the negative binomial distribution,
PN(k)=Γ(k+r)k!Γ(r)pr(1−p)k,
where is the gamma function (for and (which confirms and note that
For is given by the Poisson distribution,
PN(k)=e−λλkk!,
where is a positive real number with (which confirms
For is given by the binomial distribution,
PN(k)=(nk)qk(1−q)n−k,
where is a positive integer such that and (which confirms For the binomial distribution we note that and for the factorial term is defined to be and hence
The canonical frequency distribution defined above unifies the commonly applied and well-understood negative binomial, Poisson, and binomial cases. In practical applications, the canonical frequency distribution is not without issues. For dispersion (binomial), we are restricted to positive integer values of which implies that for (empirical) target values of and some approximation may be required due to rounding of Secondly, in a regression context, other more general frequency distributions that cover the full range of in one expression for have certain advantages (Consul and Famoye 1990; Sellers and Shmueli 2010). In this work, to compare and contrast with the canonical case, we study two commonly applied generalized frequency distributions. Following Consul and Jain (1973) and Scollnik (1998), we define the Generalized Poisson as follows.
Definition 2.4. Generalized Poisson distribution: For dispersion values the Generalized Poisson is given by
PN(k)=α(α+kβ)k−1e−(α+kβ)k!,
where and We note that when the Generalized Poisson is equivalent to the Poisson distribution.
For the under-dispersive case where with we must generally include a normalization factor such that
PN(k)=α(α+kβ)k−1e−(α+kβ)k!C(α,β),(k)=0,
and
PN(k)=0
for
k≥m,
where is the smallest positive integer value that satisfies
α+mβ≤0.
We are not aware of closed form solutions for or when but these are readily computed (only finite sums are required due to truncation). Our definition follows Scollnik (1998), which discusses and rectifies some of the issues discussed in the original formulation (Consul and Jain 1973)—in particular for the under-dispersive case, where one can easily construct cases that prove a normalization factor is required, and that the analytical forms for and when do not hold when
The Generalized Poisson enables one to cover the full range of dispersion values and in some sense does so in a “smooth” manner, as the analytical form for is fixed (aside from the normalization factor required when Another generalized frequency distribution is the Cromwell-Maxwell-Poisson (CMP) distribution that has been used in risk analysis (Guikema and Coffelt 2008). Following Conway and Maxwell (1962) we now provide the definition.
Definition 2.5. Cromwell-Maxwell-Poisson frequency distribution: The CMP distribution is given by
PN(k)=γk(k!)νZ(γ,ν),
where and We note that and when (Poisson) when and for we must have (note that requires
Much like the Generalized Poisson, the CMP distribution enables us to model the full range of dispersion values without requiring a change in the analytical form. Taking stock, all three distributions defined so far describe the random number of so-called event occurrences within a year. To complete the picture for the risk model, we assign a financial loss to each event occurrence. For this we use a severity distribution defined as follows.
Definition 2.6. Severity distribution: The continuous severity distribution, written as a density, is given by
fX(x),
where the financial loss for a specific portfolio of assets is (and so
Definition 2.7. Hereafter we use the convenient shorthand to denote the cumulative probability at a given loss threshold where
f≡∫l0fX(x)dx.
Having established the definitions for the frequency and severity distributions, we impose the assumption that samples from and are drawn independently (often assumed in insurance applications, but see Shi, Feng, and Ivantsova [2015] to explore relaxing this assumption). The combination of the frequency and severity represents a mathematical abstraction of a risk model applied to a specific portfolio of assets. For example, this may represent the application of a hurricane catastrophe model to a primary insurance portfolio. While a complex bottom-up process is required to build a useful hurricane catastrophe model, our top-down abstraction enables us to assess the impact of alternative (high-level) model assumptions on important loss metrics in a straightforward way.
The practical application of risk modelling typically makes use of what we call timeline simulation. Timeline simulation involves sampling both and in a sequence that generates losses for a specified set of simulation years. One advantage of timeline simulation is the ability to apply complex financial contracts. A formal definition makes the notion of timeline simulation clear.
Definition 2.8. Timeline simulation: A timeline simulation for years is defined by the following process:
-
For all years indexed by
-
draw a random number from the frequency distribution
-
for each year let the random realization be which implies that we must take random (loss) samples from the severity (all samples are tagged with year
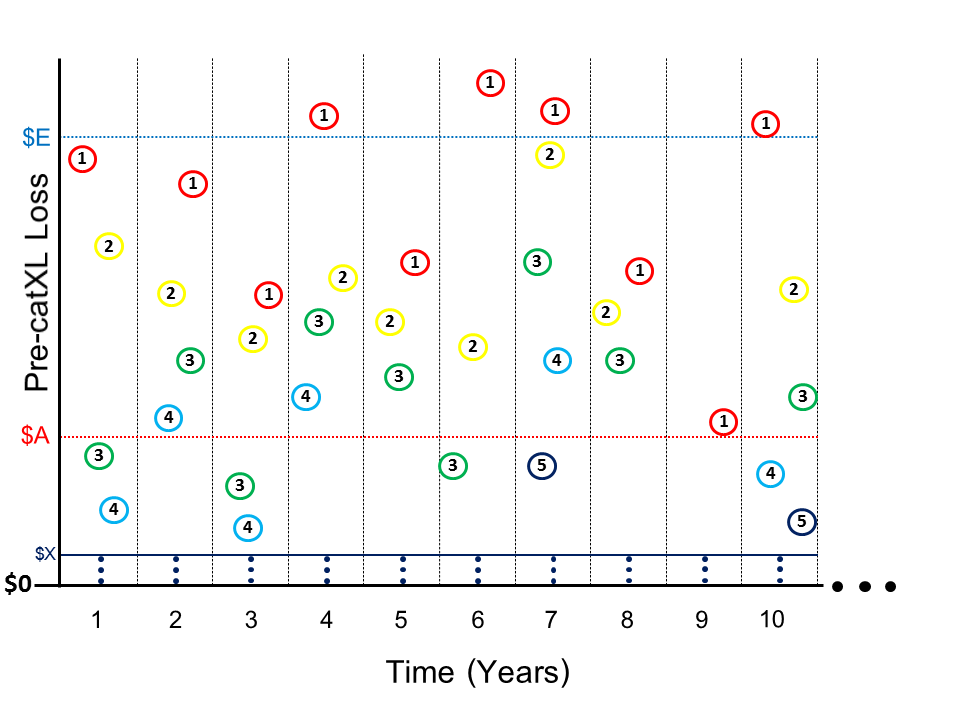
To better understand Definition 2.8, we provide a visualization in Figure 1.
__and_severity__f_x(x)_.png)
Figure 1 depicts a timeline simulation generated from a given and The y-axis represents loss to a primary insurer before the application of reinsurance (and “Pre-catXL” makes clear the losses are depicted before the application of a catXL contract). In Figure 1, the catXL contract is represented by the attachment point $A and exhaustion point $E. Depending on the type of catXL contract, losses within this layer are the responsibility of the reinsurer (see Mata [2000], Khare and Roy [2021], and Cummins, Lewis, and Phillips [1991] for formal mathematical definitions). Figure 1 visualizes the order statistics that are central to this study. The 1s in red circles depict the annual maxima, the 2s in yellow circles depict the second annual maxima, and so on. We use the following notation for the order statistics.
Definition 2.9. We adopt the classical compound claims notation (Klugman, Panjer, and Willmot 2008) with a slight modification to meet our needs. Suppose that, for a given year of timeline simulation using and the number of events For this particular year, we take random draws from and order them in the following way:
(X1=x1)≥(X2=x2)≥...≥(Xk=xk)≥(Xk+1=0)=...=(X∞=0).
Note that we assign the value of to all order statistics labelled by and above. This deviates from our interpretation of the classical compound claims notation in that we formally recognize the losses indexed by and above (which are assigned a value of Note that is the realized value of the annual maximum (recall we are using one-year time periods), is the realized value of the second maximum, and so on. This labelling of the order statistics also deviates from convention in that is typically labelled the smallest loss (David and Nagaraja 2003). Our notation suits our study where there is not a fixed number of events in a given year, and is perhaps more intuitive in that the subscript 1 is used to indicate the maximum (an ordinal ranking).
With our notation in hand, we now provide the mathematical definition of the order statistics.
Definition 2.10. For a given and severity the th order statistic random variable is where and the integer index
We have set the stage for the next section, where we provide the mathematical formulation of the order statistic distributions.
3. Order statistics in frequency and severity modelling
With Figure 1, Definition 2.10, and Notation 2.9 in hand, our goal is to formulate the cumulative probability of the random variable for some loss threshold and integer We first show the general formula for a generic discrete frequency distribution, and later apply the formula to the canonical case where closed form solutions are achieved. We also discuss the application to the Generalized Poisson and CMP distributions. We start with the definition of the order statistic cumulative probability.
Definition 3.1. Order statistic cumulative probability: The order statistic cumulative probability is
FXM(l)=∞∑k=0PN(k)FXM(l∣N=k),
where is the cumulative probability of the th order statistic random variable, up to loss threshold given events, with
The definition of the order statistic cumulative probability involves both frequency and severity. The frequency term accounts for the probabilities associated with different realizations of the number of events (in a one-year time period). The cumulative probability term is conditional on the ordering/configuration of the events about the loss threshold (hence the conditional notation). It is clear that when the number of events is less than the order (i.e., it must be that (following Definition 2.10 using Notation 2.9). Hence, when for all The terms in Definition 2.11 where require some careful argumentation that leads to the following key result stated as a theorem.
Theorem 3.2. Order statistic cumulative distribution: The order statistic cumulative probability up to loss threshold is given by
FXM(l)=M−1∑k=0PN(k)+∞∑k=MPN(k)M−1∑i=0(ki)(1−f)if(k−i,
where is the th order statistic random variable, is the frequency distribution, the severity (for loss threshold and A proof is provided in Appendix A.
We note that where the notation commonly stands for the “occurrence exceedance probability.” In reinsurance applications, the is one of the most important distributions, as it is associated with the annual maximum which in many cases explains a large proportion of reinsurance pricing metrics (Khare and Roy 2021). With the importance of the in mind, we are motivated to reformulate Equation (3.1) in a way that makes explicit reference to the function. Doing so will enable insight as to how the higher orders amplify (or add to) the We first note that, using Equation (3.1) for we obtain
FX1(l)=∞∑k=0PN(k)f(k.
The above formula is the probability generating function of (the formula is intuitive in that when we require all events to be below which has probability The following corollary demonstrates how we can rewrite Equation (3.1) making explicit reference to
Corollary 3.3. Alternative formulation of the general formula for : The th order order statistic cumulative probability can be written as follows:
FXM(l)=FX1(l)+M−1∑i=1∞∑k=iPN(k)(ki)(1−f)ifk−i,
for A proof is provided in Appendix B.
We now discuss the application of Equation (3.3) from Corollary 3.3 to the canonical frequency distributions, where we are able to obtain closed form solutions. Our aim is to write the expressions as functions of and This formulation is helpful as we later explore the values of these functions in space (for various fixed loss thresholds and therefore as a way of understanding sensitivity of the order statistic distributions to model assumptions. The result for the canonical case is stated as a proposition.
Proposition 3.4. The canonical distribution for : For dispersion the canonical frequency distribution is the negative binomial, for which the function is
FXM,(nb(l)=FX1,(nb(l)(1+M−1∑i=1Γ(i+E[N]D−1)Γ(E[N]D−1)i!(D(1−f)+f−1D(1−f)+f)i),
where from Definition 2.3), and
For the canonical frequency distribution is the Poisson, for which the function is given by
FXM,(pois(l)=FX1,(pois(l)(1+M−1∑i=1(E[N](1−f))ii!),
where from Definition 2.3), and (note that is what we refer to as the “Event Exceedance Frequency” or commonly discussed in the risk modelling community).
For the canonical frequency distribution is the binomial, for which the function is given by
FXM,(bn(l)=FXM,(bn(l)(1+M−1∑i=1(E[N]1−Di)((1−f)(1−D)D+(1−D)f)i),
where and (note that is an integer and evaluates to when
Proofs of Equations (3.4, 3.5, 3.6) are provided in Appendix C, D, and E respectively.
Proposition 3.4 provides the functions for the canonical frequency and enables us to model cases which cover the full range dispersion values The three functions and are interesting in that the higher order terms are achieved by multiplying the “base” function associated with the annual maximum by the terms in the brackets, which amplify the base annual maximum function. It is clear that the amplification factors grow with the order (since all terms in the brackets are positive numbers), as we would expect given the ordering inherent to the order statistic random variables. Finally, we note that, as the order increases, the amplification factor must converge since the cumulative probability has an upper bound of This can be seen formally by taking a limit as (omitted for brevity). For the binomial case this is immediately clear since the factorial term evaluates to when (so higher orders do not contribute to amplification of the base annual maximum cumulative probability). In the case of the Poisson and negative binomial, all orders contribute to the amplification factor (although marginally for larger contrasting with the binomial case where at some point the contribution of the higher orders to the amplification factor is nil.
We have also explored the application of Corollary 3.3 to the generalized frequency distributions discussed above. For the Generalized Poisson case, as far as we are aware, there is no closed form solution where we can eliminate the infinite sum. The CMP is even more challenging as there is no closed form solution for the distribution itself. In what follows, we use numerical approximations when applying Corollary 3.3 to the Generalized Poisson and CMP distributions (where the main considerations are computational complexity and accuracy).
With the above analytical formulations in hand, we proceed with numerical experimentation in the next section.
4. Numerical experiments
Here we provide a brief set of numerical results with two objectives in mind. Our first objective is to visualize the order statistic distributions for the canonical case, make some qualitative observations as to how the distributions change as a function of and and make comparisons with results generated from the Generalized Poisson and CMP distributions for specific cases. Secondly, we demonstrate what we call Sensitivity Spaces where, using analytical equations for the canonical case, we visualize the order statistic exceedance probability distributions as a function of for a variety of orders and fixed values of (and implicitly loss thresholds The Sensitivity Space analysis for the canonical case enables us to quickly understand the degree to which important loss metrics change as a function of altered frequency model assumptions (this has relevance for understanding changes to reinsurance attachment probabilities under changing climates). Our Sensitivity Space analysis also enables us to make clear a potential advantage of using one of the generalized frequency distributions compared with the canonical frequency.
4.1. Comparison of the canonical and generalized frequency distribution order statistic distributions
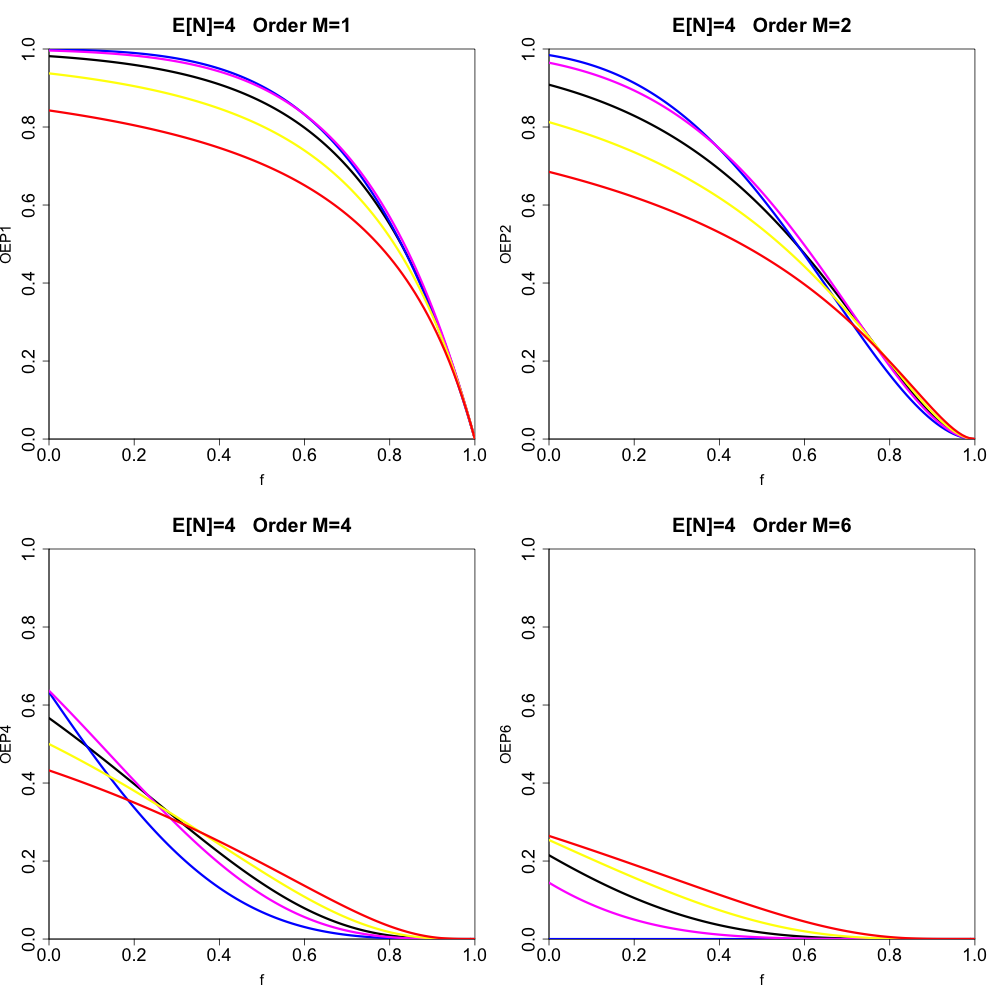
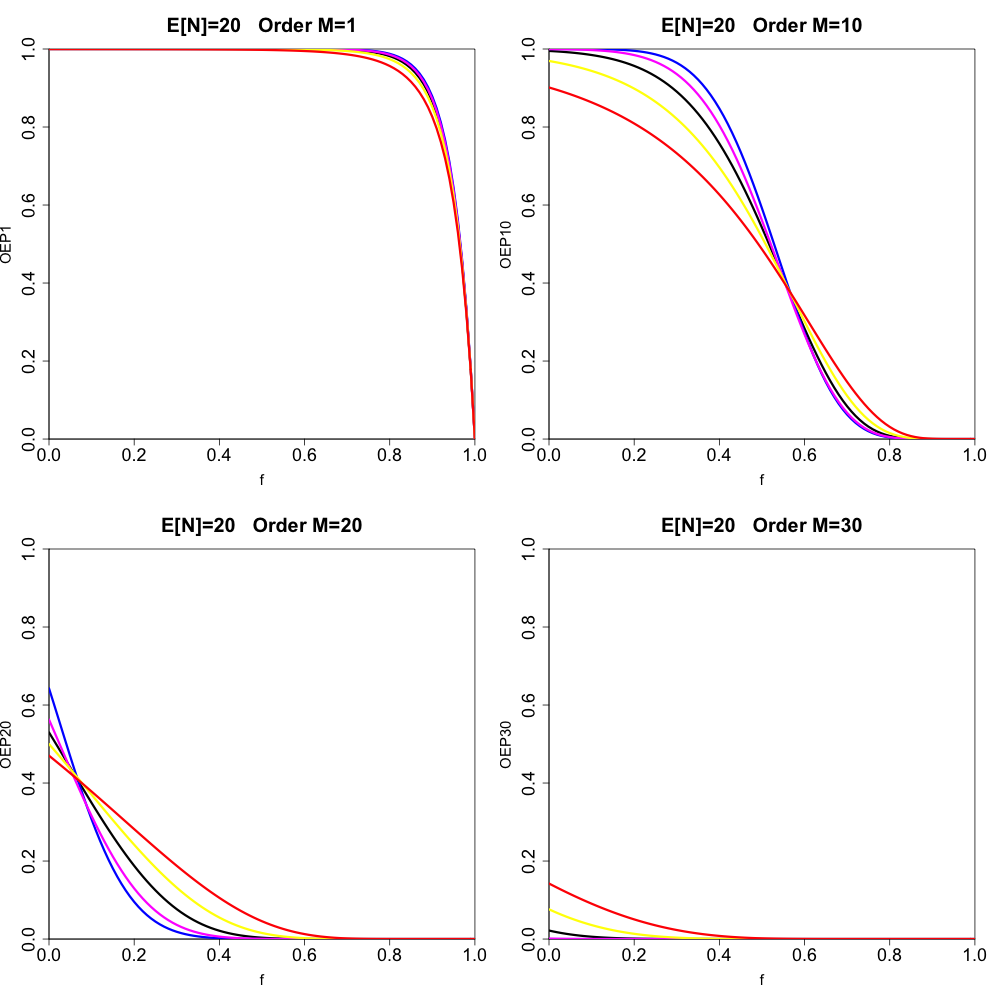
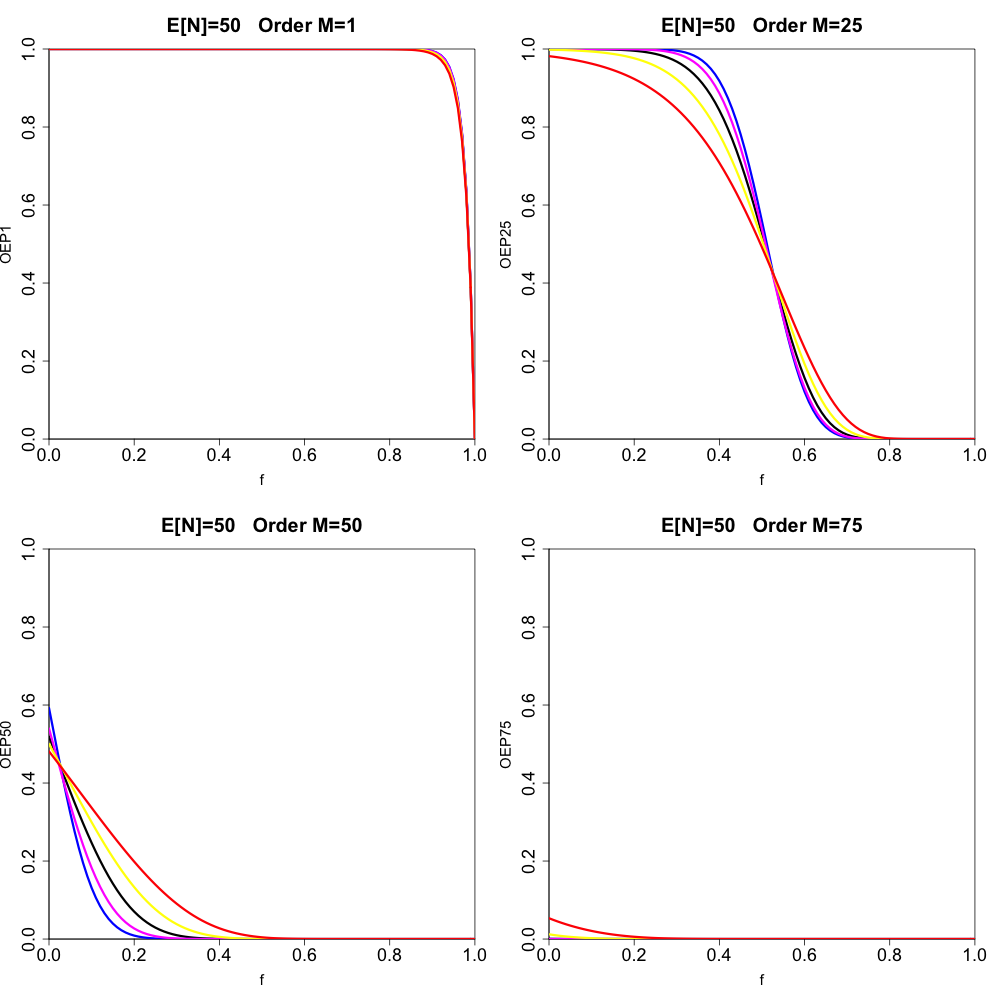
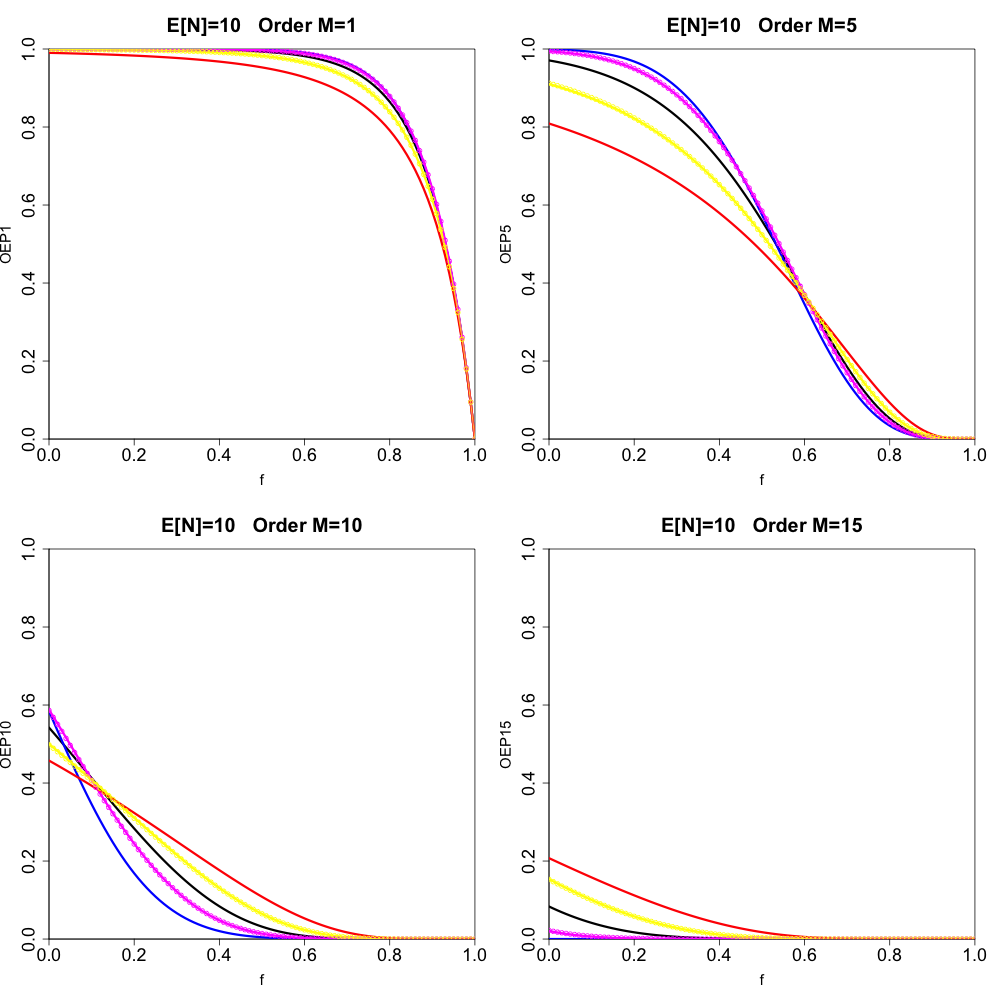
We start by simply displaying the canonical order statistic exceedance probabilities for a variety of cases (using Proposition 3.4). The upper-left panel of Figure 2 displays results for the case where with dispersion values (black), (red), (yellow), (magenta), and (blue) for order Exceedance probability is displayed on the y-axis, and is displayed on the x-axis (ranging from to in increments of Higher orders are plotted on the upper-right, lower-left, and lower-right panels (chosen so that we display order and In Figures 3 and 4 we show cases where and (and we have chosen the orders scaled to in the same way as in Figure 2). We note that, for the under-dispersive cases and we use the following convention to get the parameters and from Definition 2.3. We first obtain by solving the equation We then let (the floor function), which introduces a slight (unavoidable) approximation. Now, looking at the combined results displayed in Figures 2, 3, and 4, we make some qualitative observations:

_except_that___mathbb_e__n__20__and_for_orders__m__.png)
_except_that___mathbb_e__n__50__and_for_orders__m__.png)
The upper-left panel of Figure 2 demonstrates that, for the order distribution, over-dispersion lowers the exceedance probability, whereas under-dispersion increases the exceedance probability.
Again for the upper-left panel of Figure 2, we see that the two under-dispersive exceedance probability curves cross each other, unlike the over-dispersive case where the curves do not cross (which we have checked numerically).
For orders it appears that the over-/under-dispersive cases cross over with the Poisson case for some value of
Looking at Figures 2, 3, and 4 as a whole, we see that, for a fixed value of changes in the value of the dispersion parameter have a more prominent effect on the variation in the various exceedance probabilities curves for smaller values of For example, the over-/under-dispersive cases are further apart in Figure 2 than in Figure 4.
We believe it is possible to formalize most of the above qualitative observations into precise mathematical statements. This is left to future work.
We now focus on two specific cases where we compare the order statistic distributions from the generalized frequency distributions to those obtained with the canonical frequency. A priori, we do not expect to see vast differences, as the frequency distributions can be shown to align (to a good approximation) with the canonical frequency distributions (Consul and Jain 1973). Still, we are motivated to investigate this given the advantages of the generalized frequency distributions discussed in the literature (Consul and Famoye 1990; Sellers and Shmueli 2010). We start with the Generalized Poisson distribution.
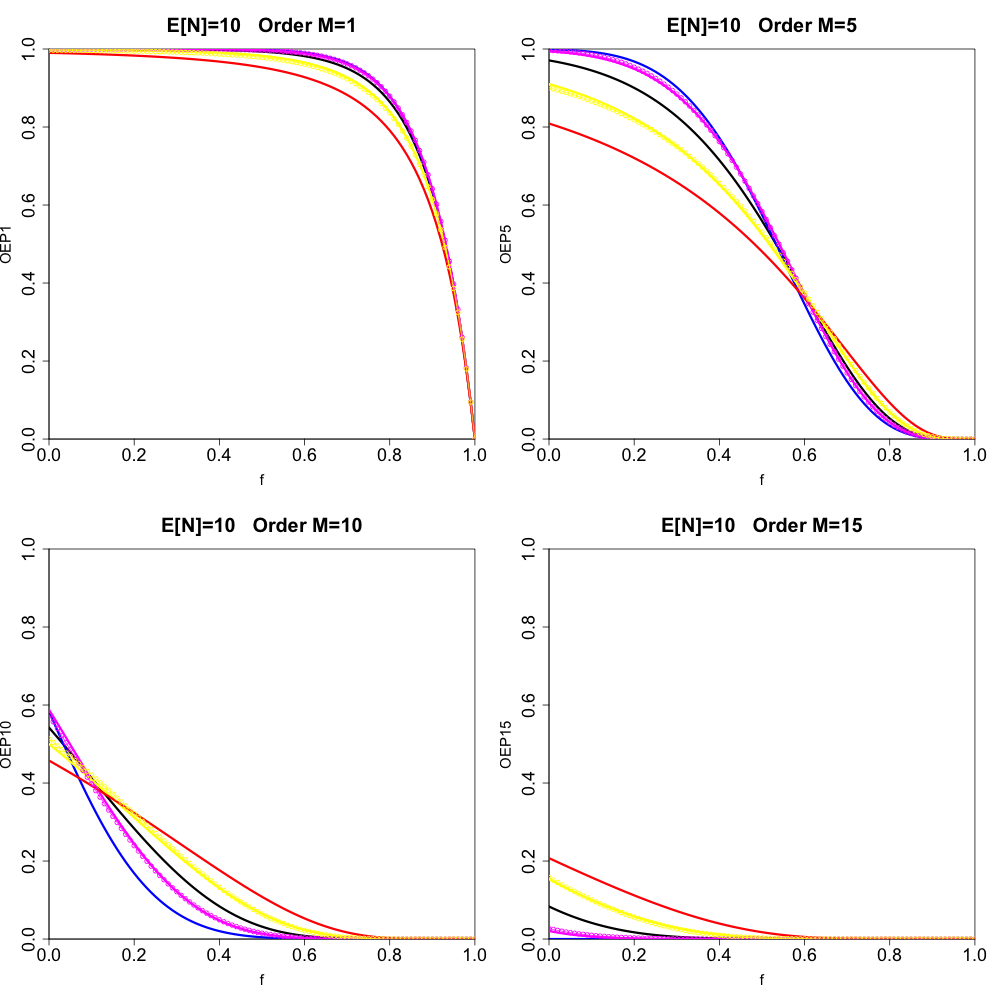
As discussed above, we do not have a closed form solution for the order statistic cumulative probability when we assume a Generalized Poisson, hence we resort to numerical calculation using the general formula given by Equation (3.1) from Theorem 3.2. In all instances when we use Equation (3.1), we truncate the infinite sum such that the maximum value of is We have found this to be an accurate value for the truncation (which we ascertained by computing the percentage difference to the case with maximum of deemed to be small enough; details are omitted for brevity). We have generated results for the over-dispersive case where and using the analytic formulas in Definition 2.4, yielding parameter values and (hereafter all such numbers are displayed with 8 significant digits). For the under-dispersive case with target dispersion we have done a numerical search over and space, which yields parameter values and with and which implies This was deemed sufficiently accurate to enable a valid comparison to the canonical case where The results are displayed in Figure 5, whose presentation is analogous to Figure 2 but with the addition of the over- and under-dispersive Generalized Poisson cases indicated by the yellow and magenta circle markings. We see that for all orders there is very little difference between the canonical and Generalized Poisson results (despite the numerical approximation required for the under-dispersive case for both the canonical and Generalized Poisson). Our results hint at a general principle: the implied order statistic distributions from the Generalized Poisson closely approximate those obtained using the canonical frequency distribution. This is useful to know in contexts where the Generalized Poisson is applied.
_except_that___mathbb_e__n__10__and_for_orders__m__.png)
Figure 6 displays results analogous to Figure 5, replacing the Generalized Poisson with the CMP distribution. Recall from Definition 3.4 that the CMP has no closed form solution for the frequency itself. To compute the frequency distribution values in Definition 2.5, we use maximum values of of in computing and (we have tested accuracy by checking maximum values computed for of 100 and deemed the results to be accurate; details are omitted for brevity). We also use numerical calculation in our application of Equation (3.1) from Theorem 3.2 (using the same maximum value for of in the infinite sum, again found to have an accurate solution). To determine the values of the CMP model parameters that capture the target dispersion values of and (for we perform a search algorithm in space. For the target case, we find that gives and implied For the under-dispersive target dispersion we find that gives and implied These numerical results were deemed accurate enough for a valid comparison to the canonical case. The results in Figure 6 (with identical format to Figure 5) demonstrate that the CMP distribution also yields similar order statistic distributions across orders displayed in Figure 5. Our results for the CMP again hint at a general principle: that the generalized frequency distributions yield similar order statistic distributions.
_with_results_from_the_generalized_poisson_replaced.png)
4.2. Sensitivity of order statistic exceedance probabilities to canonical frequency model assumptions
Here we investigate how exceedance probabilities, for various fixed values of (and implicitly loss thresholds), change as we vary and (and implicitly The visualizations to follow are what we call “Sensitivity Spaces.” Our over-arching motivation is to provide useful insight as to how key loss exceedance probability metrics change as model assumptions change. We generate results for the canonical frequency distribution only, taking advantage of the analytical solutions provided by Proposition 3.4, which enables us to plot the exceedance probabilities in and space at high resolution.
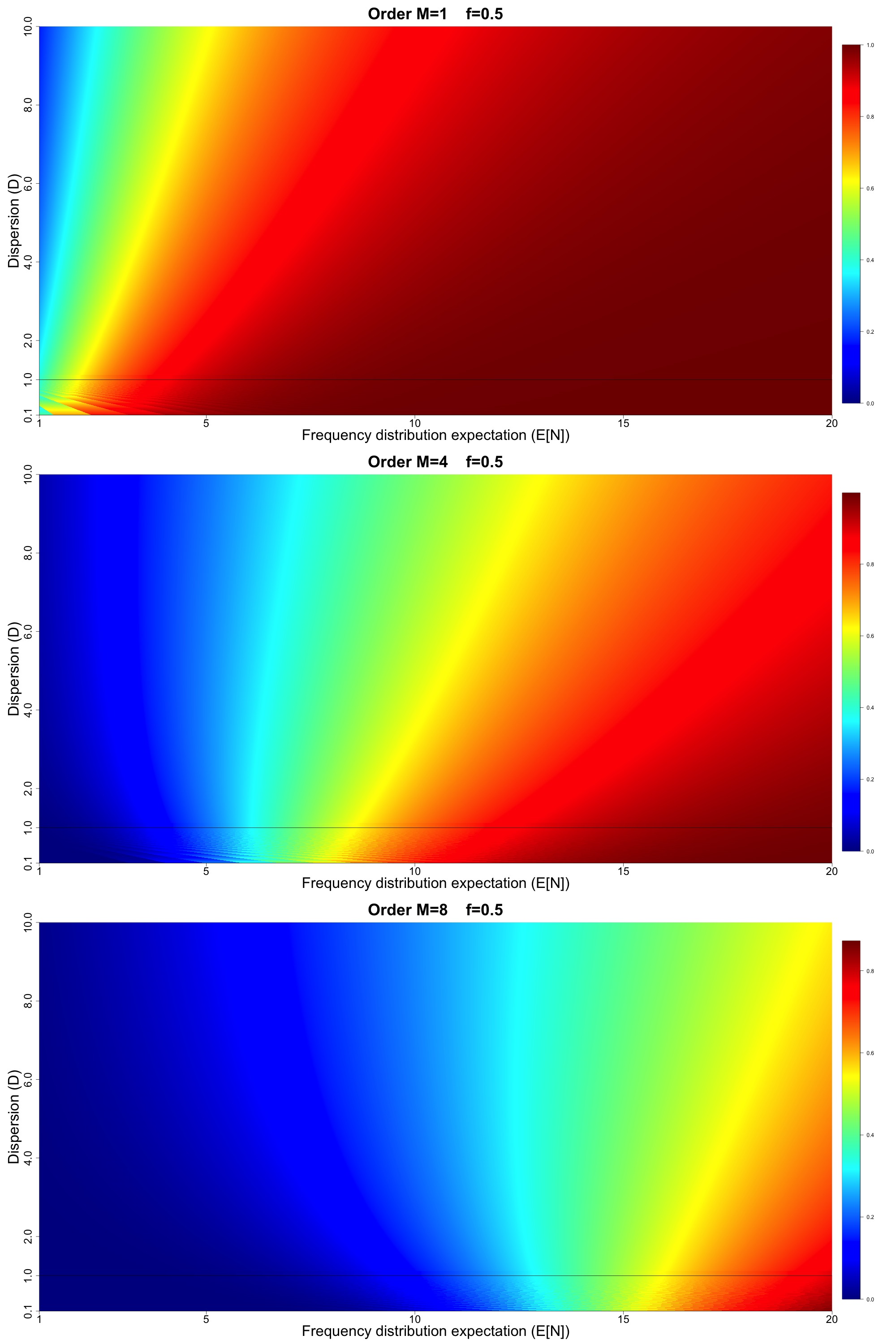
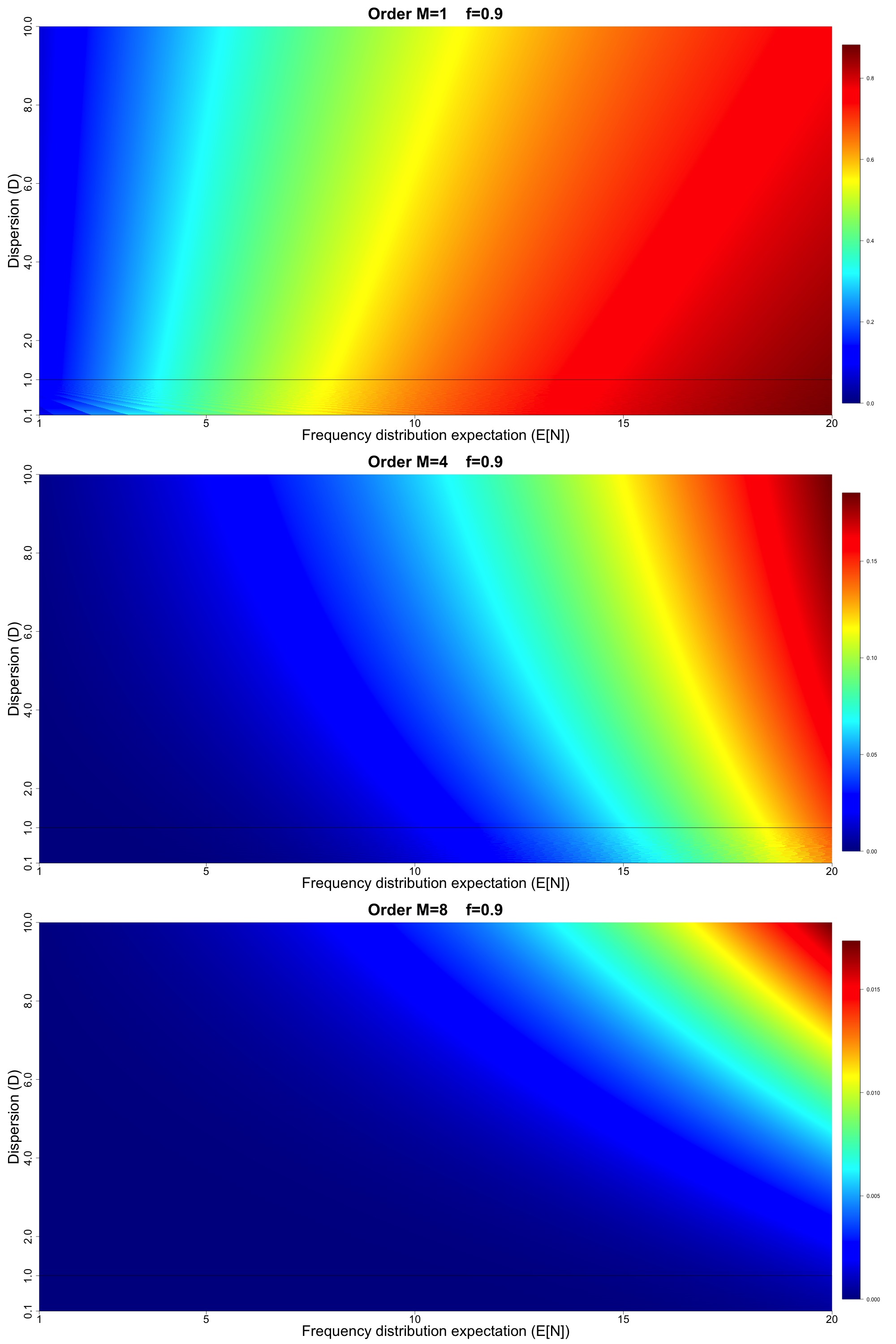
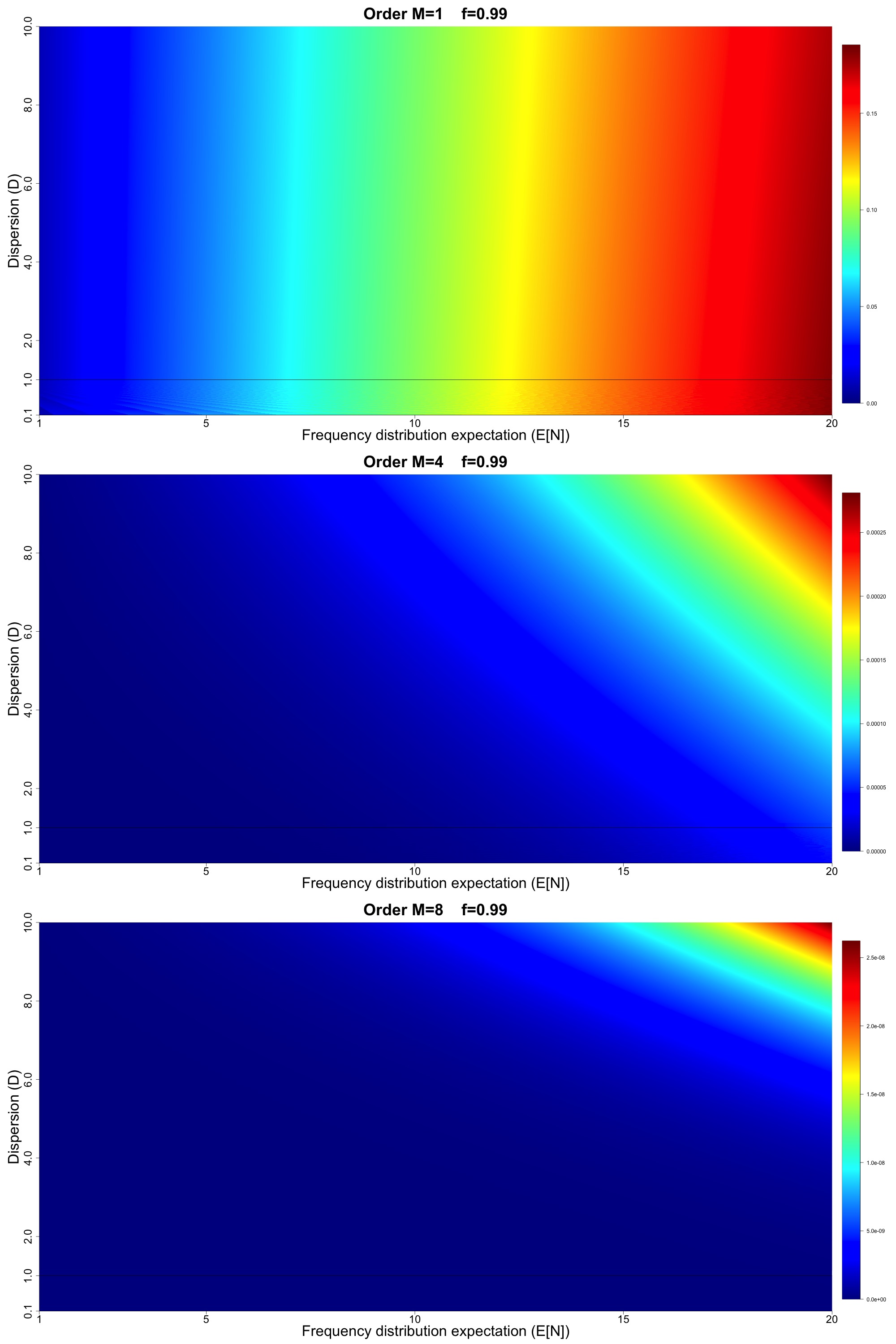
The upper panel of Figure 7 displays the order exceedance probability values for Figure 7 displays results for in increments of and in increments of 0.0025 (for a total of over million model configurations). The middle panel of Figure 7 displays the analogous results for order and the lower panel displays results for order All panels in Figure 7 have a thin black horizontal line at to indicate the crossover point between under- and over-dispersive.
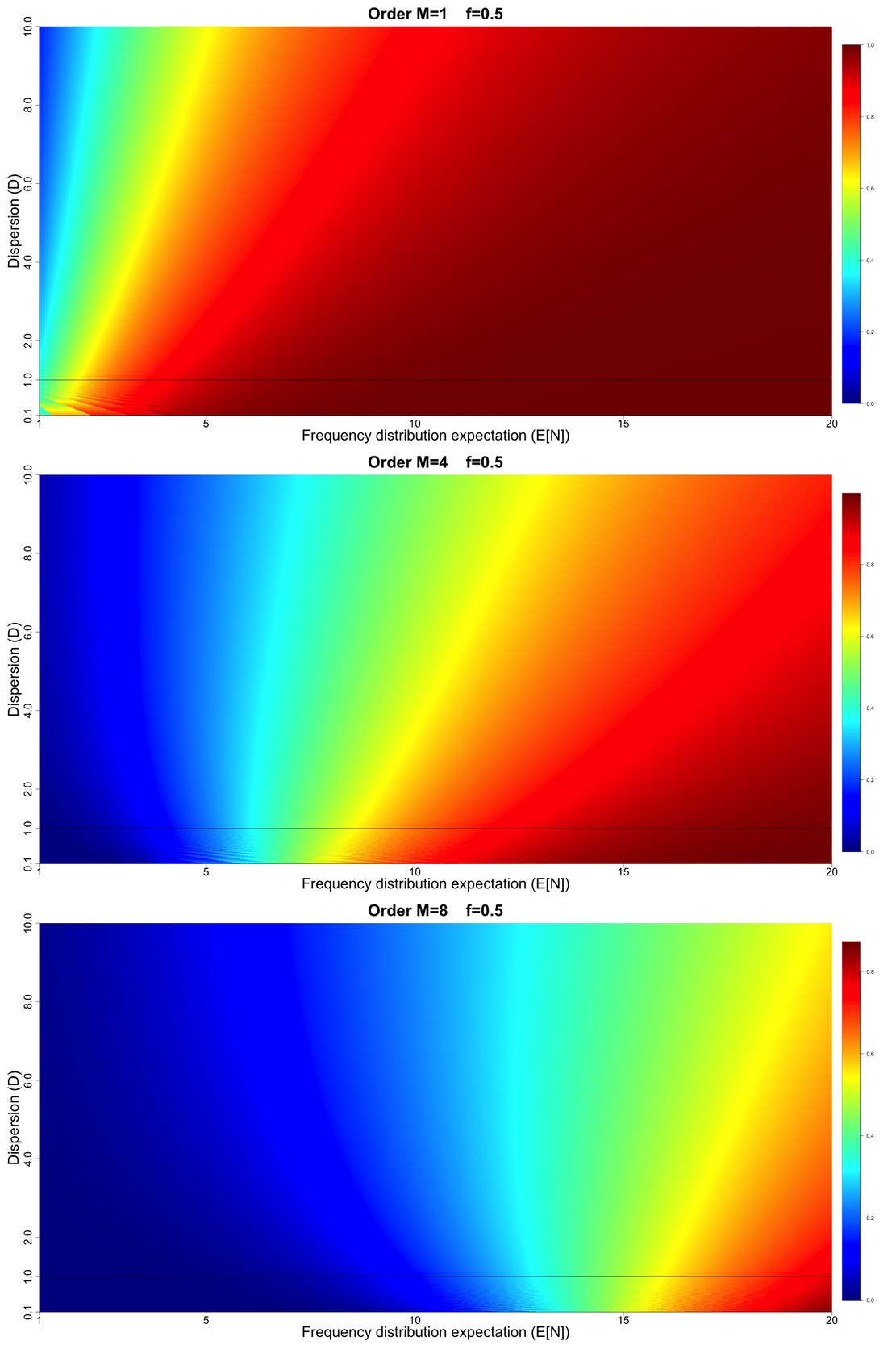
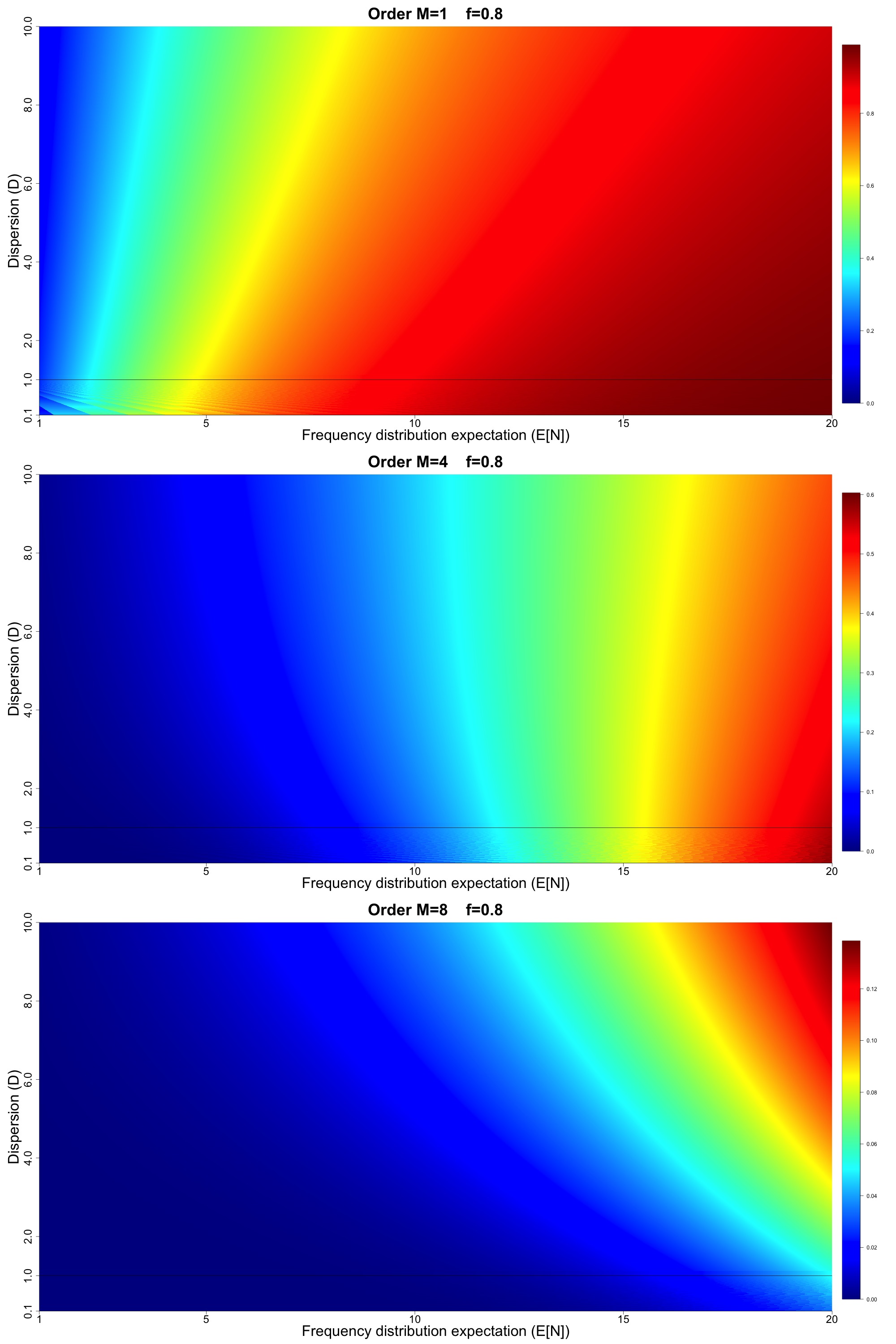
Figures 8, 9, and 10 display results analogous to Figure 7 but for higher loss threshold such that and respectively. Note that in all of Figures 7, 8, 9, and 10, we have intentionally not fixed the numerical scales associated with the different colors in the heat map to emphasize the shapes of the gradients in and space (which is the main focus of the discussion to follow).
__except_that_the_chosen_loss_th.jpg)
__except_that_the_chosen_loss_th.jpg)
__except_that_the_chosen_loss_t.jpg)
With Figures 7, 8, 9, and 10 in hand, we are able to make some interesting qualitative observations:
-
For all values of and all orders higher rate implies increasing exceedance probability, and for high and high orders larger gains in exceedance probability are achieved for higher values of dispersion.
-
For order we generally see that increasing dispersion leads to lower exceedance probability.
-
As we progress to higher orders and more extreme values of loss thresholds (larger values of we see the rightward tilting exceedance probability surface changes to a leftward tilting surface. Therefore, for higher orders, we see that increasing dispersion increases exceedance probability (unlike the lowest order This has implications for pricing so-called catXL reinsurance contracts with multiple reinstatements, which attach at high loss thresholds.
-
The more extreme the loss metric, the more pronounced the gain in exceedance probability is for increasing dispersion (seen for example by comparing Figures 8 and 9).
-
Notice that in all panels of Figures 7, 8, 9, and 10, below the dispersion line, we see the effect of the numerical rounding inherent to the binomial model. This is particularly noticeable in Figure 7 where we see the appearance of “waves” in the exceedance probability surfaces below the line, attributable to the numerical rounding. This shows the consequences of the fact that we cannot smoothly cover the and space using the canonical frequency. Our results point to a potential advantage in using the Generalized Poisson and/or CMP to model the cases, as we presume that it is possible to smoothly cover the full and space. We imagine that if we were to plot the Sensitivity Spaces for the Generalized Poisson and CMP, they would look qualitatively similar, but without the appearance of numerical waves for This assertion is based on Figures 5 and 6, where our results hinted at the equivalence of the order statistic distributions derived from the Generalized Poisson and CMP in comparison with the canonical frequency.
Figures 7, 8, 9, and 10 collectively demonstrate how we can visualize sensitivity of important exceedance probability metrics to model assumptions. The mathematical result for the in the case of the canonical frequency distribution (Proposition 3.4) is particularly useful in this context, as we can easily visualize many model configurations without the need for timeline simulations and other related approximations. We view Figures 7, 8, 9, and 10 as a demonstration of a top-down approach to understanding the implications of model changes to important loss metrics. In particular, such Sensitivity Spaces are conceptually useful in understanding the effects of changing model assumptions in the context of natural catastrophe reinsurance pricing. Similar types of analysis could be extended to address a broader set of questions; for example, what is the sensitivity to changes in the characteristics of the severity distribution itself? Our brief numerical treatment in this work motivates further exploration in this direction using societally relevant practical examples.
5. Practical application for quantifying the impacts of climate change on reinsurance pricing metrics
The Sensitivity Space plots in Figures 7, 8, 9, and 10 show the exceedance probabilities of various order statistics, for a variety of loss thresholds, and for a range of expected frequencies and dispersion values As discussed in Khare and Roy (2021), these exceedance probabilities are key to understanding which order statistics contribute to reinsurance pricing metrics. The higher the exceedance probability the higher the contribution of a given order statistic. Here we discuss how market practitioners can make use of our Sensitivity Space plots for given model output. We assume that one has access to catastrophe model output run against a particular portfolio prior to the application of a catXL reinsurance contract at a particular loss threshold of interest. We assume that this model output comes in the form of a timeline simulation or an event loss table (e.g., Homer and Li 2017).
One of the remarkable aspects of our results in Figures 7, 8, 9, and 10 is that the gradient of the order statistic exceedance probabilities (in the and direction) depends strongly on where in the and space our model sits for a given loss threshold and order For example, in Figure 7, for the change in the exceedance probability is small for but much higher (in a relative sense) for the surface. Figure 8 reveals a different gradient for the same range of frequency and In other words, the sensitivity of the exceedance probabilities of the order statistics depends on the model characteristics and the loss threshold of interest that corresponds to the attachment point of a given catXL contract. While our Figures 7, 8, 9, and 10 only cover four particular loss thresholds, similar Sensitivity Space plots can be made for any loss threshold of interest. The practical application of our Sensitivity Space plots boils down to computing the and for a given model output and determining the value of for a given loss threshold We now provide a brief discussion of how to do so for two common forms of model output in the market.
5.1. Timeline simulation models
We assume that the timeline simulation model output is collected into a matrix with rows and columns (number of simulation years as in Definition 2.8). is the maximum number of event occurrences across all simulation years The annual maximum losses are stored in the first row, and so on. The columns of may contain values corresponding to years where the number of events is less than We assume all event occurrences have losses greater than Consistent with our assumption in Section 2, we assume frequency and severity are independent. Under this assumption, we can use the losses in to compute and (for a chosen loss threshold This requires the following steps:
-
Compute a sample estimate of by counting the number of non-zero losses in and dividing by Call this estimate where is the number of non-zero loss events.
-
For each year of simulation compute the number of events implied by (by simply counting the number of non-zero losses per year). With these samples of compute the sample variance, and call it The estimate of the dispersion is
-
To approximate the cumulative probability of the severity at loss threshold collect all the non-zero losses in and place them in a vector of dimension is made up of random samples of the severity For a given catXL contract with attachment point compute a sample estimate of by determining the number of events in that are less than and divide this by This is our sample estimate we call
For the sake of this discussion, we assume that is one of (to correspond to Figure 7, 8, 9, or 10). This need not be the case, as the Sensitivity Space plots can be recreated for any specific value of (or for that matter an expanded range of and The next step is to look at the corresponding Figure 7, 8, 9, or 10 and determine which values of the model output from the timeline simulation corresponds to. The Sensitivity Space plots then enable us to determine the changes in the exceedance probabilities of the various order statistics in a region around the model for both changing expected frequency and dispersion. We note that the Sensitivity Space plots in Figures 7, 8, 9, and 10 correspond to the canonical frequency, but our contention is that qualitatively the results apply to generalized frequency distributions (given our results for the Generalized Poisson and CMP distributions). We leave aside the important question of the appropriate size of the region to look at in space to correspond to various climate change scenarios and time scales (we note that market practitioners can leverage commercial solutions for climate change models to help quantify this region). The above straightforward process makes use of sample statistics from the timeline simulation matrix Next we discuss the use of event loss table model output.
5.2. Event loss table models
In this case, model output comes in the form of a matrix we call which is an matrix here is distinct from the total number of events in the timeline simulation discussed above). The number of rows corresponds to the number of events The first row contains information about the first event. The first column (of the first row) corresponds to the average annual frequency of the first event, the second column is the mean loss given an occurrence of this event, and the third column is its standard deviation. Rows to in have the same information for events to We assume the occurrences of the different events are independent. We also assume that, while the matrix supplies the mean and standard deviation of the loss for each event, there is some parameterization, which gives an analytical probability density of loss for each event. Further, consistent with Section 2, we assume that for each individual event the frequency and severity are independent. Once again, to make use of the Sensitivity Space plots, we must compute estimates of and using the model output stored in :
-
To obtain the estimate of simply sum the first column in the matrix.
-
The value of is dictated by the model formulation, and this information is not stored in the matrix. For example, one could assume each individual event is Poisson (and therefore the overall frequency distribution is Poisson), which would imply that
-
The average annual rates of the events are labelled as where Given an event, assume the probability of getting a particular event is (and The severity is given by the probability weighted sum of the individual event severities which label as The severity is a mixture model:
-
Using the severity, numerical integration can be used to obtain an estimate of by numerically computing the integral
With the above estimates of and in hand, one can follow a similar process to the one discussed above for timeline simulations to quantify model sensitivity to implied ranges from climate change (once again, sensible ranges to explore are available through commercial solutions).
6. Summary and Conclusions
This paper addresses the problem of quantifying changes to reinsurance pricing metrics arising from changes to frequency and severity assumptions. We are motivated by the notion that climate change implies changes to the underlying frequencies and severities (e.g., Knutson et al. 2020) that underpin technical reinsurance pricing. To do so we build on the results in Khare and Roy (2021), which demonstrate the importance of the order statistics in understanding the composition of catXL pricing metrics. In particular, Khare and Roy (2021) show that the exceedance probabilities (for a variety of loss thresholds) of the order statistics are one of the key drivers of technical pricing metrics. This paper augments Khare and Roy (2021) by demonstrating a framework to quantify changes to exceedance probabilities of the order statistics under changes to model assumptions. In particular we focus on changes arising from altered frequency distribution assumptions (although the same analysis can be extended to alterations in severity). Our framework enables one to explore the full range of dispersion values and average annual frequency
This paper is focussed on the foundational and mathematical aspects of this problem, but we envision our study being useful as a basis for a variety of applied studies. As a first step we have provided a brief discussion on how to make use of results from model output commonly found in the market. The key contributions and conclusions from this paper are as follows:
-
Section 3 provides a clear proof of the general formula of the cumulative probability of for a given frequency and severity the result is given in Theorem 3.2. We then reformulate the main result to write the cumulative probability as an explicit function of the cumulative probability of the annual maximum (one of the most commonly discussed distributions in practice). Our result is provided in Corollary 3.3}. We then apply the result from Corollary 3.3 to what we call the canonical frequency (negative binomial, Poisson, and binomial) which is able to “cover” the full range of dispersion values (Definition 2.2). We achieve a closed form solution (Proposition 3.4) that can be used to rapidly explore the sensitivity of the exceedance probabilities to frequency model assumptions.
-
Section 4 presents and discusses a novel set of numerical experiments. First, we compare and contrast the order statistics from the canonical frequency with those obtained using two particular generalized frequency distributions (Generalized Poisson and CMP). The generalized frequency distributions are able to cover the full dispersion range without changes to the analytical form, which has advantages in various applications (Consul and Famoye 1990; Sellers and Shmueli 2010). Our results suggest that the generalized frequency distributions appear to generate nearly identical order statistics (which is useful background knowledge in applications of the generalized frequencies). In line with our stated goal of exploring sensitivity of exceedance probabilities of the order statistics to model assumptions, we also plot a series of Sensitivity Spaces (Figures 7, 8, 9, and 10) where we use the canonical frequency results from Proposition 3.4 to plot exceedance probabilities (for a variety of loss thresholds) as a function of the dispersion and the expectation of the frequency From this we achieve a number of useful insights, discussed in the main text, that enable understanding of reinsurance pricing metrics under model changes. Our Sensitivity Space exercise also sheds further light on an issue with the canonical frequency that is likely to be overcome with one of the generalized frequency distributions studied here. In particular, for the case where the canonical exceedance probability surfaces suffer from the numerical approximation inherent to the use of the binomial distribution, which we contend can be alleviated by the use of the Generalized Poisson and/or CMP distributions.
-
Section 5 discusses how practitioners can make use of model output commonly found in the market to address the impact of model changes on exceedance probabilities of the order statistics (motivated by our desire to quantify the impact of climate change on key reinsurance pricing metrics).
Our work can serve as a reference for practitioners interested in developing insights into reinsurance pricing under changing model assumptions. From the work in this paper, we envision a number of future studies of societal relevance. In particular, it would be interesting to use our methods for visualizing real-world examples from natural catastrophe risk models. For example, one could run a global suite of natural catastrophe models against the current-day economic exposure and establish a baseline portfolio-level frequency and severity. One could then perturb the model to capture changes to frequency, dispersion, and severity distribution characteristics under changing climates, and use our analytical results to understand changes to exceedance probabilities of One could do this exercise for a series of future economic scenarios, also capturing the uncertainty inherent to such projections. This type of work would serve to map out, at a high level, the implications of climate change on reinsurance pricing metrics.