1. Introduction
Credibility theory is a quantitative method that insurance companies use to estimate future losses of a policyholder based on the loss experiences of the policyholder as well as the average loss experiences of all policyholders in the rating class. The main reason for combining the two sources of information is that the former is more relevant but also more volatile; the latter is less relevant but more stable. Credibility theory strives for a balance between the relevancy and statistical stability of the data.
In Bayesian credibility, one assumes that the loss from a policyholder in a rating class follows a parametric model with some risk parameter However, varies by policyholders and is modelled by a random variable that follows some prior distribution The Bayesian credibility premium is determined based on the posterior distribution of risk parameter conditional on the loss experiences of the policyholder. For detailed study of Bayesian credibility, one can refer to, for instance, Heilmann (1989), Klugman (1992), Goovaerts (1990), and references therein.
Bayesian credibility is theoretically sound and widely accepted by academics and practicing actuaries. However, as discussed in, for example, Bühlmann (1976), Eichenauer, Lehn, and Rettig (1988) and Deniz, Vazquez Polo, and Bastida (2000), one drawback of Bayesian credibility is that the parametric model as well as the prior distribution have to be specified. These assumptions can affect the resultant premiums greatly, yet it may be difficult to justify. Therefore, they suggested applying robust Bayesian premium methodology when the practitioner is unwilling or unable to choose a functional form for the prior distribution In particular, Eichenauer, Lehn, and Rettig (1988) derived -minimax credibility formula with respect to vague prior information given by moment restrictions on the priors in case of gamma risk models. Deniz, Vazquez Polo, and Bastida (2000) assumed that the loss model is known but the prior distribution of the model parameters is only known to be in some -contamination class. They obtained bounds for the Bayesian credibility premium under several types of premium principles. Gómez-Déniz (2009) assumed that the values of parameters of the prior distribution fall in some intervals, but their exact values are unknown, he proposed a procedure to determine the credibility premium based on the posterior regret -minimax principle, which can be regarded as a methodology between classical Bayesian and robust Bayesian methods.
Bühlmann (1967) introduced “the greatest accuracy” credibility model, in which the Bayesian credibility is approximated by a linear function of the loss experiences and the prior mean (named the credibility premium). Determining the credibility premium only requires up to the second moment information of the model and the prior. One benefit of this is that the resulting premium is less sensitive to model mis-specification (Hong and Martin 2020), another benefit is that the moment parameters are easier to be specified than the whole probability distribution. In fact, they are commonly determined by actuaries’ professional judgements when there is not enough information (data), as in for example, catastrophe insurance/reinsurance.
Further, Bühlmann (1976) studied the credibility problem when the moment information required by credibility premium is known only to a range. He proposed a minimax credibility premium principle based on the game-theoretic framework. Similar to Bühlmann (1976), Hong and Martin (2021) considered a case when the parameters in the Bühlmann credibility formula are known to be in some intervals and proposed a method for determining premium under the framework of imprecise probability. They argued that this method is “doubly robust” because it is less sensitive to model and prior distribution mis-specification.
In this paper, as in for example, Bühlmann (1976), Gómez-Déniz (2009) and Hong and Martin (2021), we study actuarial credibility problem when the information about the prior distribution of the risk parameter is imprecise or vague, so that the actuary cannot specify the exact prior distribution or the moments. However, instead of considering the imprecise information about the prior distribution from robust Bayesian analysis/ imprecise probability point of view, we propose to apply fuzzy set theory (FST).
FST was introduced in Zadeh (1965). It provides a systematic and rigorous mathematical approach to incorporate vague, fuzzy, or incomplete information. In conventional set theory, an element is either a member or not a member of a given set. In FST, however, an element can be a member of a fuzzy set to some degree. For example, in conventional set theory, the set young drivers can be defined to include all drivers whose age are less than, say 20. So a driver can be either a young driver or not - nothing in between. In FST, however, a member in the universe can belong to a set to a certain degree. For example, a 23 years old driver may belong to the fuzzy set young drivers with, say, membership; whereas a 16 years old belongs to the set with membership.
In credibility problems, information about the risk model and the prior distribution of the risk parameters is usually expressed in linguistic terms, such as “the policyholders in this rating class are rather heterogeneous”, or “the number of losses for this line of business are volatile, even when the risk parameter is fixed” (process variance is high). In such situations, actuaries may feel reluctant to assign certain prior distributions with fixed numerical parameters. We argue in this paper that FST can be a useful tool for such problems.
FST was introduced into the insurance and actuarial literature by de Wit (1982) and Lemaire (1990). It was subsequently applied to insurance rate making by Cummins and Derrig (1993), David Cummins and Derrig (1997), Young (1996) and Young (1997), and to risk classification by Derrig and Ostaszewski (1995) and Young (1993). For a comprehensive overview of the applications of fuzzy set theory in insurance and actuarial science, we refer to (Shapiro 2004).
The main contributions of this paper are two-folds:
-
First, we extend the results on robust Bayesian based on the posterior regret -minimax principle in Deniz, Vazquez Polo, and Bastida (2000) and Gómez-Déniz (2009) by assuming that the loss distribution is in the exponential dispersion family (EDF) and that the parameters of the prior distributions are TFNs.
-
Second, we extend the results on robust Bühlmann credibility in Bühlmann (1976) and Hong and Martin (2021) by assuming that the parameters involved are TFNs.
The rest of the paper is structured as follows. Section 2 first introduces basic concepts and results of FST and then reviews some fundamental results of actuarial credibility theory. Section 3 studies the fuzzy Bayesian premium and the fuzzy Bühlmann credibility in great detail. Section 4 illustrates the applications of the developed theory to both hypothetical and real-data examples. Section 5 concludes.
2. Preliminaries
This section reviews some preliminaries of fuzzy set and actuarial credibility theories.
2.1. Fuzzy set theory
We begin by providing a very brief introduction to FST, including fuzzy number and fuzzy arithmetic. For comprehensive review of the theory, please refer to textbooks such as Dubois and Prade (1980), Klir and Yuan (1995) and Zimmermann (1996).
Definition 2.1. Let be a collection of objects (universe of discourse). A fuzzy set in is defined as Zimmermann (1996)
˜A={(x,m˜A(x))|x∈X},
where called the membership function, represents the grade of membership of in
For example, let be the set (universe) of drivers of all ages. Then a fuzzy set of young drivers, defined on the universe may be characterized by a membership function
m˜Y(x)={30−x14, 16≤x≤300, Otherwise.
Therefore, a 16-year old driver is a full member of the fuzzy set and a 23-year old driver is a half member.
Definition 2.2. The -cut of a fuzzy set *is a crisp set defined by Aα={x∈X|m˜A(x)≥α}, ∀α∈[0,1].
For example, the -cut of the fuzzy set is a crisp set
Y0.5={x∈R|m˜Y(x)≥0.5}={x|16≤x≤23}.
Definition 2.3. A fuzzy set is convex if its -cuts of all levels are convex.
Definition 2.4. A fuzzy number is a convex and normalized fuzzy set defined on the real line such that and is piecewise continuous. The real numbers whose membership function take value 1 are called the core of the fuzzy number.
It is easy to verify that the fuzzy set of young drivers, is a fuzzy number. Its core is
Since a fuzzy number is a convex fuzzy set on the real line, its -cuts are closed intervals. Therefore, we may denote the -cuts of a fuzzy number by Aα=[A_(α),¯A(α)], where are continuously increasing (decreasing) functions of
One of the most commonly used types of fuzzy numbers used in practice is triangular fuzzy number, defined as follows.
Definition 2.5. A triangular fuzzy number (TFN) with representation is a fuzzy number that has the membership function
m˜A(x)={x−ALA−AL,AL≤x≤AAR−xAR−A,A≤x≤AR,
where is the core, and and are the left and right bounds respectively. We simply write
The -cuts of is given by For example,
The extension principle introduced by Zadeh (1965) provides a general method for extending non-fuzzy mathematical operations to fuzzy sets.
Let be fuzzy numbers defined on respectively. Let be a mapping from the Cartesian product to a universe According to the extension principle of Zadeh (1965), The function leads to a mapping from the vector of fuzzy numbers to a fuzzy set on with the membership function
m˜B(y)={supx1,…,xn,y=f(x1,…,xn)min(m˜A1(x1),…,m˜An(xn))if f−1(y)≠∅0if f−1(y)=∅,
where is the inverse image of We write
It is usually difficult to obtain explicit expression for the membership function of However, when are TFN, it can sometimes be obtained (approximated). As argued in Jiménez and Rivas (1998), the problems that arise with vague predicates are less concerned with precision and are more of a qualitative type, thus they are generally written as linearly as possible. Grzegorzewski and Pasternak-Winiarska (2014) stated that, complex shapes of FNs can produce drawbacks in calculations or when interpreting the results. Therefore, in actual applications, triangular or trapezoidal FNs are commonly used. Based on the above reasoning, in this paper, we assume that the parameters used in the credibility calculation are TFNs. As shown in our analysis in the sequel, this assumption of TFN leads to formulas that are easy to compute and to interpret.
The assumption of TFN allows us to apply the following useful results in the literature.
Lemma 2.1 (Buckley and Qu 1990). For let be a TFN with -cuts Let If is continuous, then the -cuts of is given by
Bα={y∈Y|y=f(x1,…,xn),xi∈Aiα}.
In addition, if is increasing with respect to the first variables and decreases in the last variables, then the -cuts of are given by
Bα=[B_(α),¯B(α)],
where
B_(α)=f(A1_(α),A2_(α),…,Am_(α),¯Am+1(α),¯Am+2(α),…,¯An(α)),
and
¯B(α)=f(¯A1(α),¯A2(α),…,¯Am(α),Am+1_(α),Am+2_(α),…,An_(α)).
When the function is nonlinear in general, it is difficult to obtain an explicit expression for by applying the above results. In such cases, as discussed in Kaufmann (1986) and de Andrés-Sánchez (2018), it is possible to approximate the result of nonlinear operations on TFNs by a TFN.
Definition 2.6. Let be TFNs defined on the universes respectively. A TFN approximation to is defined by where
BT=f(A1,…,An),BLT=minx1,…,xn∈X1×…×Xnf(x1,…,xn),BRT=maxx1,…,xn∈X1×…×Xnf(x1,…,xn).
Similar to Lemma 2.1, we have the following result.
Lemma 2.2. If is increasing with respect to the first variables and decreasing in the last variables, then the TFN approximation to is given by where
BT=f(A1,A2,…,Am,Am+1,Am+2,…,An),BLT=f(AL1,AL2,…,ALm,ARm+1,ARm+2,…,ARn),BRT=f(AR1,AR2,…,ARm,ALm+1,ALm+2,…,ALn).
Despite its simplicity, this approach has been verified by Kaufmann (1986) and Jiménez and Rivas (1998) to be effective for many nonlinear operations with TFNs. For actuarial/financial applications of the approximation, one is referred to, for example, Tercenõ et al. (2003) and Heberle and Thomas (2014). Lemma 2.2 is instrumental for our analysis in the sequel. In the numerical examples in Section 4, we compare the premium based on Lemma 2.1 and 2.2. The results are very quite similar.
In another aspect, arithmetic operations on fuzzy numbers result in a fuzzy number. However, when using fuzzy set theory to make business decision such as setting premium for an insurance policy, one needs to come up with a crisp number that reflects the information contained in the relevant fuzzy variables. This process is called defuzzification. There are many commonly used defuzzification methods, such as the “center of area (COA)”, the “center of gravity (COG)”, etc. See for example, Chapter 11 of Zimmermann (1996). In this paper, we adopt the “average index” (AI) method introduced in de Campos Ibáñez and González Muñoz (1989).
Definition 2.7. The AI of a FN is defined by
AI(˜A;λ;H)=∫[0,1]((1−λ)A_(α)+λ¯A(α))dH(α),0≤λ≤1,
where be is a probability distribution on
In the definition, the integrand represents the weighted average position of the -cuts of The parameter represents the “optimism-pessimism degree” (uncertainty aversion level) of the decision maker. For example, assuming that is the measure of risk with high value representing higher risk, then a pessimistic (uncertainty averse) decision maker will assign a greater value of than a optimistic one. Further, could be interpreted as the average positions of the -cuts of Y by applying weight function Intuitively, a weight of is given to the average -cuts position . For example, with equal weights are given to every -cut level; with more weights are given to levels with higher values of (more likely levels); with where is large, the weights are concentrated to levels close to 1.
For it is straightforward check that
AI(˜A;λ;H1)=12[A+(1−λ)AL+λAR],AI(˜A;λ;H2)=13[2A+(1−λ)AL+λAR],AI(˜A;λ;H12)=13[A+2(1−λ)AL+2λAR],limn→∞AI(˜A;λ;Hn)=A,limn→∞AI(˜A;λ;H1n)=(1−λ)AL+λAR.
AI defuzzification is fairly flexible. In fact, as illustrated in de Campos Ibáñez and González Muñoz (1989), it extends several other commonly used defuzzification approaches, such as center of gravity and center of maximum. The method has been applied in many areas. For actuarial/financial applications, one is referred to Heberle and Thomas (2014), de Andrés-Sánchez and González-Vila Puchades (2017), and references therein.
2.2. Credibility Theory
In this subsection, we review some basics of actuarial credibility theory that will be needed in the sequel.
2.2.1. Classical Bayesian credibility
Let the potential loss from a policyholder (individual risk) be denoted by a random variable The loss propensity of the individual risk is characterized by an unknown risk parameter so the distribution of is given by The risks in a rating class (risk collective) are heterogeneous and their risk parameters are different. The collection of risk parameters is represented by a random variable which is assumed to have a prior (structural) distribution
In insurance ratemaking, an actuary needs to determine the premium for a general risk exposure characterized by risk parameter Let be a loss function, which represents the loss sustained by the insurance company when the premium is and the realized loss is Then, the individual risk premium is determined by minimizing the expected value of the the loss function, (Heilmann 1989). For example, with which is the net premium principle; with which is the Esscher premium principle.
However, the value of is not observable. Thus, before observing a risk exposure’s loss experience, the insurer charges the collective premium, which is given by P_B(\pi_0) = \arg\min_{a\in \mathbb{R}^+} \mathbb{E}_{\pi_0}[L_\Theta(P(\theta),a)]\,, where is an expectation operator assuming that follows distribution Here, the subscript stands for “Bayesian” and is a loss function that represents the insurance company’s “loss” when the true premium should be but the charged premium is On the other hand, if loss experiences of time periods is observed to be then the Bayes premium is calculated by P_B(\pi_{\mathbf{x}}) = \arg\min_{a\in \mathbb{R}^+} \mathbb{E}_{\pi|\mathbf{x}}[L_\Theta(P(\theta),a)]\,, where is an expectation operator assuming that follows the posterior distribution
For example, with and we have P_B(\pi_0)=\mathbb{E}_{\pi_0}[P(\Theta)]=\mathbb{E}_{\pi_0}[\mathbb{E}[X|\Theta]] \,, and P_B(\pi_\mathbf{x})=\mathbb{E}_{\pi_\mathbf{x}}[P(\Theta)] =\mathbb{E}_{\pi_{\mathbf{x}}} [\mathbb{E}[X|\Theta]] \,.
A classical result in Bayesian credibility is available when the distribution of is in the Exponential dispersion family (EDF), with the probability density function (p.d.f.)
f(x|\theta,\tau)=\exp\{\tau(x\theta-k(\theta))\}q(x|\tau)\,, \quad \tau > 0\,,
and the distribution of the risk parameter is its conjugate prior, satisfying
\pi_0(\theta) \propto \exp\{x_0\theta-t_0k(\theta)\}\,.\tag{2.6}
For this case, the Bayesian net premium, is given by Landsman and Makov (1998)
\begin{align}P_{B}(\pi_\mathbf{x})&=\frac{x_0+n\tau\bar{x}}{t_0+n\tau}\\ &=Z_B\bar{x}+\left(1-Z_B\right)\mu_B\,,\end{align}\tag{2.7}
where
Z_B=\frac{n\tau}{t_0+n\tau}
is the credibility factor,
\mu_B=\frac{x_0}{t_0}
is the collective premium, and
\bar{x}=\sum_{i=1}^n\,x_i
is the sample mean.
2.2.2. Robust Bayesian credibility
The above result is quite general because the EDF includes many commonly used distributions. However, to apply it, one needs to know the exact values of the parameters of the prior distribution. This requirement can be restrictive and sometimes unachievable. For example, it could be difficult to justify the selected values. Or, in a group decision-making setting, people may have different opinions about the prior distribution. A common approach to solve this problem is to apply the robust Bayesian method. That is, to consider a class of prior distributions and then determine an action from the range of Bayesian actions. For example, one can apply the minimax criterion, where the action is selected to minimize the loss function under the worst-case scenario of the prior distribution. Readers are referred to Eichenauer, Lehn, and Rettig (1988) and Deniz, Vazquez Polo, and Bastida (2000) for discussions of such approaches. On the other hand, Gómez-Déniz (2009) considered the posterior regret -minimax methodology to deal with prior distribution uncertainties. In particular, the posterior regret of charging a premium for a risk exposure is defined as
\begin{align} r(\pi_{\mathbf{x}}, P)&= \mathbb{E}_{\pi_{\mathbf{x}}} [L_\Theta(P(\Theta),P)] \\ &\quad -\mathbb{E}_{\pi_{\mathbf{x}}} [L_\Theta(P(\Theta),P_B(\pi_{\mathbf{x}}))]\,, \end{align}
which represents the loss of optimality when is chosen instead of the optimal action The posterior regret -minimax action is defined to be
RP(\pi_{\mathbf{x}}) = \arg\min_{P}\max_{\pi_0 \in \Gamma} r(\pi_{\mathbf{x}}, P)\,.
It was shown in Gómez-Déniz (2009) that is given by
\small{ RP(\pi_\mathbf{x})=\frac{1}{2}\left(\inf_{\pi_0\in \Gamma} P_B(\pi_\mathbf{x})+\sup_{\pi_0\in \Gamma} P_B (\pi_\mathbf{x})\right)\,.\tag{2.8}}
To provide explicit expressions for Gómez-Déniz (2009) further assumed that the family of prior distributions has form (2.6) but the parameters are only known to be in some intervals. Specifically, they consider the family of distributions
\Gamma_1=\left\{\pi_0(\theta): x_0^{(1)}\le x_0\le x_0^{(2)},\, t_0^{(1)}\le t_0\le t_0^{(2)} \right\}\,.
Then applying (2.7) and (2.8) yields
\small{ RP_1(\pi_\mathbf{x})=\frac{1}{2}\left( \frac{x_0^{(1)}+n\tau\bar{x}}{t_0^{(2)}+n\tau} + \frac{x_0^{(2)}+n\tau\bar{x}}{t_0^{(1)}+n\tau} \right). }
Remark 2.1. According to the Imprecise credibility estimation methodology proposed by Hong and Martin (2021), actuaries will simply provide the interval \left[ \frac{x_0^{(1)}+n\tau\bar{x}}{t_0^{(2)}+ n\tau} , \, \frac{x_0^{(2)}+n\tau\bar{x}}{t_0^{(1)}+n\tau} \right] as suggested premium and acknowledge the inherent prior uncertainty. The posterior regret -minimax methodology, on the other hand, proposes that the premium equal to the midpoint of the interval.
2.2.3. Bühlmann credibility
Bühlmann (1967) proposed to use a linear function of loss experience of an individual risk, to approximate the individual pure premium in the sense that the quadratic loss function
\mathbb{E}[(\mu(\Theta)-P_C(\mathbf{X}))^2]
is minimized.
To determine only the following information about the risk model and the prior distribution of risk parameters are needed.
\begin{align} \mu&=\mathbb{E}[\mu(\Theta)],\\ v&=\mathbb{E}[v(\Theta)]\\ \text{and}\ \ w&=Var(\mu(\Theta))\, , \end{align}
where
\begin{align} \mu(\theta)&=\mathbb{E}[X|\Theta=\theta]\, , \\ v(\theta)&=Var(X|\Theta=\theta)\,.\end{align}\tag{2.9}
With this, we have
P_{C}(\mathbf{x}) = Z_C\bar{x}+\left(1-Z_C\right)\mu\,,\tag{2.10}
where
Z_C=\frac{nw}{nw+v}
is called the credibility factor.
As discussed in Hong and Martin (2021), in addition to its intuitiveness and simplicity, one benefit of using Bühlmann’s credibility premium is that one only needs to specify three parameters and which involves up to second-moment information of the model and the prior. The exact distributional information of the model and the prior are not needed. Therefore, it is less susceptible to model error than pure Bayesian methods.
A common practice to estimate the parameters is to apply empirical Bayesian method (e.g. Klugman, Panjer, and Willmot 2019). However, when data is scarce, one may have to rely on prior knowledge and professional judgment regarding the underlying risk. In addition, if there are more than one decision makers, they may disagree about the selection of the parameters. To allow these uncertainties about the model and parameters, Bühlmann (1976) considered the set of models/priors such that and are in the set
\scriptsize{\begin{align} &\Gamma_2 \\ &\quad= \left\{(\mu,v,w): \mu^L\le \mu\le \mu^R,\, v^L\le v \le v^R, \,w^L\le w \le w^R\right\}\,.\end{align}\tag{2.11}}
Under a game-theoretic framework, he showed that there exists a minimax strategy that solves
\small{\min_{\alpha_0, \alpha_1, \cdots, \alpha_n}\max_{(\mu,v,w)\in \Gamma_2} \mathbb{E}\left[\left(\mu(\Theta)-\alpha_0-\sum_{i=1}^{n}\alpha_i X_i\right)^2\right].}
Much more recently, (Hong and Martin 2021) applied the same assumption in (2.11) and suggested that the actuary can simply present the range of possible credibility premiums (called imprecise credibility estimator)
\bigg[\min_{(\mu,v,w)\in \Gamma_2}P_C(\mathbf{x}), \max_{(\mu,v,w)\in \Gamma_2}P_C(\mathbf{x})\bigg].\tag{2.12}
It is easy to show that
\min _{(\mu, v, w) \in \Gamma_2} P_C(\mathbf{x})=\min \left\{c_1, c_2, c_3, c_4\right\}
and
\max _{(\mu, v, w) \in \Gamma_2} P_C(\mathbf{x})=\max \left\{c_1, c_2, c_3, c_4\right\}
where
\begin{aligned} & c_1=\frac{n}{v^R / w^L+n} \bar{x}+\frac{v^R / w^L}{v^R / w^L+n} \mu^L, \\ & c_2=\frac{n}{v^R / w^L+n} \bar{x}+\frac{v^R / w^L}{v^R / w^L+n} \mu^R, \\ & c_3=\frac{n}{v^L / w^R+n} \bar{x}+\frac{v^L / w^R}{v^L / w^R+n} \mu^L, \\ & c_4=\frac{n}{v^L / w^R+n} \bar{x}+\frac{v^L / w^R}{v^L / w^R+n} \mu^R . \end{aligned}
Hong and Martin (2021) argued that the “imprecise credibility premium” in (2.12) is doubly-robust, with respect to the choice of model and prior distribution.
3. Fuzzy Credibility
In this section, we introduce a novel approach of determining credibility premium based on FST. Section 3.1 discusses fuzzy Bayesian credibility and Section 3.2 discusses fuzzy Bühlmann credibility.
3.1. Fuzzy Bayesian credibility
In this section, as in Gómez-Déniz (2009), we assume that the loss distribution is in the EDF family and the distribution of the risk parameter is the conjugate prior. Gómez-Déniz (2009) assumed that the values of the prior distribution parameters, and are within certain intervals. Here, we assume that they are represented by TFNs and Then the fuzzy Bayesian net premium is given by
\tilde{P}_{B}(\pi_\mathbf{x};F)=\frac{\tilde{x}_0+n\tau\bar{x}}{\tilde{t}_0+n\tau}\,,\tag{3.1}
where the arithmetic operators, such as addition and division, in fact stand for fuzzy arithmetic operations, which follow the extension principle of Zadeh (1965). For simplicity, we just use regular arithmetic operation symbols in this paper.
Let the -cuts of and be denoted by
\begin{align}x_{0\alpha}&=\left[\underline{x_0}(\alpha),\, \overline{x_0}(\alpha)\right] \\ &\text{and} \\ t_{0\alpha}&=\left[\underline{t_0}(\alpha),\, \overline{t_0}(\alpha)\right],\end{align}
respectively, then by (2.2) and (2.3), the -cuts of is
\small{ \begin{aligned} P_{B}(\pi_\mathbf{x};F)_{\alpha}&=\left[\frac{\underline{x_0}(\alpha)+n\tau \bar{x}}{\overline{t_0}(\alpha)+n\tau},\, \frac{\overline{x_0}(\alpha)+n\tau \bar{x}}{\underline{t_0}(\alpha)+n\tau}\right], \\ 0&\le \alpha \le 1\,. \end{aligned}\tag{3.2} }
and the AI of is given by
\small{ \begin{align} AI\left(\tilde{P}_{B}(\pi_\mathbf{x};F);\lambda\right)&=(1-\lambda)\int_0^1\frac{\underline{x_0}(\alpha)+n\tau \bar{x}}{\overline{t_0}(\alpha)+n\tau} \text{d} H(\alpha)\\ &\quad +\lambda\int_0^1\frac{\overline{x_0}(\alpha)+n\tau \bar{x}}{\underline{t_0}(\alpha)+n\tau}\text{d} H(\alpha)\,, \end{align} }
which can be numerically evaluated in general.
To simplify calculation and provide intuition, we next provide the analytical form of the TFN approximation of the fuzzy Bayesian premium.
Proposition 3.1. Assuming that and are TFNs having representations and respectively, then the fuzzy Bayesian premium can be approximated by a TFN
\small{ \tilde{P}_{B}(\pi_\mathbf{x};F) \approx \left( P_B^L(\pi_{\mathbf{x}}),\ P_B^0(\pi_{\mathbf{x}}),\ P_B^R(\pi_{\mathbf{x}})\right), \tag{3.3} }
where
P_B^L(\pi_{\mathbf{x}})=\frac{x_0^L+n\tau \bar{x}}{t_0^R+n\tau} = Z_B^L \bar{x} + (1-Z_B^L) \mu_B^L\,,
with and
P_B^0(\pi_{\mathbf{x}})=\frac{x_0+n\tau\bar{x}}{t_0+n\tau} = Z_B^0 \bar{x} + (1-Z_B^0) \mu_B^0\,,
with and and
P_B^R(\pi_{\mathbf{x}})=\frac{x_0^R+n\tau \bar{x}}{t_0^L+n\tau} = Z_B^R \bar{x} + (1-Z_B^R) \mu_B^R\,, with and
The AI of with is given by
\small{ \begin{align} &AI\left(\tilde{P}_{B}(\pi_\mathbf{x};F);\lambda\right) \\ &\quad = \frac{1}{2} \left[P_B^0(\pi_{\mathbf{x}})+ (1-\lambda) P_B^L(\pi_{\mathbf{x}}) + \lambda P_B^R(\pi_{\mathbf{x}})\right], \end{align} \tag{3.4} }
where
Proof. It is easy to see from (3.1) that is increasing in and decreasing in Then applying Lemma 2.2 yields (3.3). Equation (3.4) is obtained by applying (2.5).
Observe that the AI of the fuzzy Bayesian net premium contains information for both its core and the boundaries, as well as the uncertainty aversion level of the decision maker that is represented by the parameter This provides a more flexible approach than the posterior regret -minimax result proposed in Gómez-Déniz (2009).
Remark 3.1. Proposition (3.1) only provides formulas for AI of with As shown in Section 2.1, other forms of can be applied, which would result in premium being different combinations of the bounds and the core of In particular,
\lim_{n\to \infty} AI\left(\tilde{P}_{B}(\pi_\mathbf{x};{F});\lambda,H(\alpha)=\alpha^n \right)= P_B^0(\pi_{\mathbf{x}})\,,
which is the classical Bayesian premium.
In addition,
\small{ \begin{align} \lim_{n\to \infty} AI\left(\tilde{P}_{B}(\pi_\mathbf{x};{F});\lambda,H(\alpha)=\alpha^{\frac{1}{n}} \right)&= (1-\lambda) P_B^L(\pi_{\mathbf{x}}) \\ &\quad+ \lambda P_B^R(\pi_{\mathbf{x}})\,, \end{align} }
which is a generalization of the posterior regret -minimax result proposed in (Gómez-Déniz 2009).
3.2. Fuzzy Bühlmann credibility
In this section, we assume that the three parameters in the Bühlmann credibility are positive TFNs with representations and
Directly applying (2.10) would yield a fuzzy Bühlmann credibility estimator
\tilde{P}_{C}(\mathbf{x};F)=\frac{n\tilde{w}}{\tilde{v}+n\tilde{w}}\bar{x}+\frac{\tilde{v}}{\tilde{v}+n\tilde{w}}\tilde{\mu}\,.\tag{3.5}
Let the -cuts of and be denoted by
\begin{align}\mu_{\alpha}&=\left[\underline{\mu}(\alpha),\, \overline{\mu}(\alpha)\right], \\ v_{\alpha}&=\left[\underline{v}(\alpha),\, \overline{v}(\alpha)\right] \\ &\text{and} \ \\ w_{\alpha}&=\left[\underline{w}(\alpha),\, \overline{w}(\alpha)\right],\end{align}
respectively, then by (2.1), the -cuts of is
\small{\begin{aligned} &P_{C}(\mathbf{x};F)_{\alpha}\\ &\quad=\left[min\{c_{1\alpha},c_{2\alpha},c_{3\alpha},c_{4\alpha}\}, max\{c_{1\alpha},c_{2\alpha},c_{3\alpha},c_{4\alpha}\}\right], \\ 0&\le \alpha \le 1\,, \end{aligned}\tag{3.6}}
where
\begin{align}c_{1\alpha}&=\frac{n}{\overline{v}(\alpha)/\underline{w}(\alpha)+n}\bar{x}\\ &\quad+\frac{\overline{v}(\alpha)/\underline{w}(\alpha)}{\overline{v}(\alpha)/\underline{w}(\alpha)+n}\underline{\mu}(\alpha)\,,\end{align}\tag{3.7}
\begin{align}c_{2\alpha}&=\frac{n}{\overline{v}(\alpha)/\underline{w}(\alpha)+n}\bar{x}\\ &\quad+\frac{\overline{v}(\alpha)/\underline{w}(\alpha)}{\overline{v}(\alpha)/\underline{w}(\alpha)+n}\overline{\mu}(\alpha)\,,\end{align}\tag{3.8}
\begin{align}c_{3\alpha}&=\frac{n}{\underline{v}(\alpha)/\overline{w}(\alpha)+n}\bar{x}\\ &\quad+\frac{\underline{v}(\alpha)/\overline{w}(\alpha)}{\underline{v}(\alpha)/\overline{w}(\alpha)+n}\underline{\mu}(\alpha)\,,\end{align}\tag{3.9}
\begin{align}c_{4\alpha}&=\frac{n}{\underline{v}(\alpha)/\overline{w}(\alpha)+n}\bar{x}\\ &\quad+\frac{\underline{v}(\alpha)/\overline{w}(\alpha)}{\underline{v}(\alpha)/\overline{w}(\alpha)+n}\overline{\mu}(\alpha)\,. \end{align}\tag{3.10}
With this, the membership function of the fuzzy Bühlmann credibility premium can be determined numerically.
Equations (3.7) to (3.10) provide us a way to determine the membership function of However, it does not provide much intuition. Next we provide an explicit form for the fuzzy Bühlmann credibility premium by approximating it using a TFN.
Since it is more natural to express the credibility premium as a linear function of the mean loss experience and the prior mean, we rewrite (3.5) as
\tilde{P}_{C}(\mathbf{x};F)=\tilde{Z}_C \bar{x} + (1-\tilde{Z}_C)\tilde{\mu}\,,\tag{3.11}
where
\tilde{Z}_C=\frac{n}{\tilde{k}+n}
and It is understood that the two in (3.11) always take the same value.
Firstly, since is monotone in and by (2.4), it can be approximated by a TFN where
k^L=\frac{v^L}{w^R}\,,\ \ k^0=\frac{v^0}{w^0}\ \ \text{and}\ \ k^R=\frac{v^R}{w^L}\,.
Then, because the credibility factor is monotone in it can be approximated by a TFN with representation
\tilde{Z}_C=(Z_C^L,\, Z_C^0,\, Z_C^R)\,,\tag{3.12}
where
Z_C^L=\frac{n}{n+k^R}\,,\ \ Z_C^0=\frac{n}{n+k^0}\ \ \text{and}\ \ Z_C^R=\frac{n}{n+k^L}\,.
As a result, the AI of is given by
AI(\tilde{Z}_C, \lambda)=\frac{1}{2}\left(Z_C^0+(1-\lambda) Z_C^L+\lambda Z_C^R\right).
Now, because is increasing in if is positive and decreasing in if is negative, it cannot be approximated by directly applying Lemma 2.2. Therefore, we next propose a method to get around this. We start with the simple case when is a crisp number, which leads to the following result.
Proposition 3.2. Assume that is crisp and are TFNs. Let the fuzzy credibility be given by (3.12), then we have
-
When can be approximated by the TFN \scriptsize{\begin{align}&\tilde{P}_{C}(\mathbf{x};F_{Z};1)\\&\quad= \left({P}_{C}^L(\mathbf{x};F_{Z};1), {P}_{C}^0(\mathbf{x};F_{Z};1), {P}_{C}^R(\mathbf{x};F_{Z}; 1)\right),\end{align}\tag{3.13}} where {P}_{C}^L(\mathbf{x};F_{Z}; 1)=Z_C^R\bar{x} + (1-Z_C^R)\mu^0\,, {P}_{C}^0(\mathbf{x};F_{Z}; 1)=Z_C^0\bar{x} + (1-Z_C^0)\mu^0\,, and {P}_{C}^R(\mathbf{x};F_{Z}; 1)=Z_C^L\bar{x} + (1-Z_C^L)\mu^0\,.
-
When can be approximated by the TFN \scriptsize{\begin{align} &\tilde{P}_{C}(\mathbf{x};F_{Z}; 2)\\&\quad= \left({P}_{C}^L(\mathbf{x};F _{Z}; 2), {P}_{C}^0(\mathbf{x};F_{Z}; 2), {P}_{C}^R(\mathbf{x};F_{Z}; 2)\right),\end{align}\tag{3.14}} where {P}_{C}^L(\mathbf{x};F_{Z}; 2)=Z_C^L\bar{x} + (1-Z_C^L)\mu^0\,, {P}_{C}^0(\mathbf{x};F_{Z}; 2)=Z_C^0\bar{x} + (1-Z_C^0)\mu^0\,, and {P}_{C}^R(\mathbf{x};F_{Z}; 2)=Z_C^R\bar{x} + (1-Z_C^R)\mu^0\,.
In addition, the AI of the fuzzy premium is given by
\scriptsize{ \begin{aligned} &AI\left(\tilde{P}_{C}(\mathbf{x};F_{Z});\lambda\right)\\ &\quad= \begin{cases} \displaystyle{AI(\tilde{Z}_C, \lambda)\bar{x}+(1-AI(\tilde{Z}_C, \lambda))\mu^0}\,, & \bar{x}>\mu^0 \\ \displaystyle{AI(\tilde{Z}_C, 1-\lambda)\bar{x}+(1-AI(\tilde{Z}_C, 1-\lambda))\mu^0}\,, & \bar{x}<\mu^0 \end{cases}. \end{aligned}\tag{3.15} }
Proof. When is increasing in and the smallest and largest values of credibility premium are and respectively. Applying Lemma 2.2 yields (3.14). When is decreasing in Applying Lemma 2.2 leads to (3.13).
Further, applying (2.5) to (3.13) and (3.14), we could obtain the corresponding AI values. For example, when we have
\scriptsize{ \begin{aligned} &AI\left(\tilde{P}_{C}(\mathbf{x};F_{Z}; 1);\lambda\right)\\ &= \frac{1}{2}\left({P}_{C}^0(\mathbf{x};F_{Z}; 1)+(1-\lambda){P}_{C}^L(\mathbf{x};F_{Z}; 1)+\lambda{P}_{C}^R(\mathbf{x};F_{Z}; 1)\right) \notag\\ &= \frac{1}{2}\left(Z_C^0\bar{x}+(1-Z_C^0)\mu^0+(1-\lambda)(Z_C^R\bar{x}+(1-Z_C^R)\mu^0)+\lambda(Z_C^L\bar{x}+(1-Z_C^L)\mu^0)\right)\notag\\ &=AI(\tilde{Z}_C, 1-\lambda)\bar{x}+(1-AI(\tilde{Z}_C, 1-\lambda))\mu^0\,. \end{aligned} }
Similar calculation can be applied for the case
Remark 3.2. Interestingly, for with the credibility factor depends on the value of relative to If then Therefore, equation (3.15) indicates that more weight (credibility) is assigned to the loss experiences when than when This result makes sense because in our setting, means that the decision maker is pessimistic (uncertainty averse) and thus tends to penalize worse-than-expected loss experiences more than to award better-than-expected loss experiences. The opposite is true when When the credibility factor is simply regardless of the value of
Next, we consider the case when all three parameters and are TFNs. By considering the cases of and separately, we have the following result.
Proposition 2.3. When are TFNs, then we have the following results.
-
When the fuzzy credibility premium can be approximated by the TFN \scriptsize{\begin{align} &\tilde{P}_{C}(\mathbf{x};F_{Z,\mu}; 1)\\&\quad=\left(P^L_{C}(\mathbf{x};F_{Z,\mu}; 1), P^0_{C}(\mathbf{x};F_{Z,\mu}; 1), P^R_{C}(\mathbf{x};F_{Z,\mu}; 1)\right),\end{align}\tag{3.16}} where P^L_{C}(\mathbf{x};F_{Z,\mu}; 1)=Z_C^R\bar{x}+(1-Z_C^R)\mu^L, P^0_{C}(\mathbf{x};F_{Z,\mu}; 1)=Z_C^0\bar{x}+(1-Z_C^0)\mu^0, and P^R_{C}(\mathbf{x};F_{Z,\mu}; 1)=Z_C^L\bar{x}+(1-Z_C^L)\mu^R.
-
When it can be approximated by the TFN \scriptsize{\begin{align} &\tilde{P}_{C}(\mathbf{x};F_{Z,\mu}; 2)\\&\quad=\left(P^L_{C}(\mathbf{x};F_{Z,\mu}; 2), P^0_{C}(\mathbf{x};F_{Z,\mu}; 2), P^R_{C}(\mathbf{x};F_{Z,\mu}; 2)\right),\end{align}\tag{3.17}} where P^L_{C}(\mathbf{x};F_{Z,\mu}; 2)=Z_C^L\bar{x}+(1-Z_C^L)\mu^L, P^0_{C}(\mathbf{x};F_{Z,\mu}; 2)=Z_C^0\bar{x}+(1-Z_C^0)\mu^0, and P^R_{C}(\mathbf{x};F_{Z,\mu}; 2)=Z_C^L\bar{x}+(1-Z_C^L)\mu^R.
-
When it can be approximated by the TFN \scriptsize{\begin{align} &\tilde{P}_{C}(\mathbf{x};F_{Z,\mu}; 3)\\&\quad=\left(P^L_{C}(\mathbf{x};F_{Z,\mu}; 3), P^0_{C}(\mathbf{x};F_{Z,\mu}; 3), P^R_{C}(\mathbf{x};F_{Z,\mu}; 3)\right),\end{align}\tag{3.18}} where P^L_{C}(\mathbf{x};F_{Z,\mu}; 3)=Z_C^L\bar{x}+(1-Z_C^L)\mu^L, P^0_{C}(\mathbf{x};F_{Z,\mu}; 3)=Z_C^0\bar{x}+(1-Z_C^0)\mu^0, and P^R_{C}(\mathbf{x};F_{Z,\mu}; 3)=Z_C^R\bar{x}+(1-Z_C^R)\mu^R.
Further, the AI of resulting fuzzy premium is given by
\scriptsize{ \begin{aligned} &AI\left(\tilde{P}_{C}(\mathbf{x};F_{Z, \mu});\lambda\right)\notag\\ & =\begin{cases} AI(\tilde{Z}_C, 1-\lambda)\bar{x}+\frac{1}{2}\left((1-Z_C^0)\mu^0+(1-\lambda)(1-Z_C^R)\mu^L+\lambda(1-Z_C^L)\mu^R\right), \\\hspace{10em}\ \bar{x}<\mu^L \\ \frac{1}{2}\left(Z_C^0+Z_C^L\right)\bar{x}+\frac{1}{2}\left((1-Z_C^0)\mu^0+(1-\lambda)(1-Z_C^L)\mu^L+\lambda(1-Z_C^L)\mu^R\right), \\\hspace{10em}\ \mu^L<\bar{x}<\mu^R \\ AI(\tilde{Z}_C, \lambda)\bar{x}+\frac{1}{2}\left((1-Z_C^0)\mu^0+(1-\lambda)(1-Z_C^L)\mu^L+\lambda(1-Z_C^R)\mu^R\right), \\\hspace{10em}\ \bar{x}>\mu^R \end{cases} \end{aligned}\tag{3.19} }
Proof. Firstly, when the smallest and largest values of credibility premium are and respectively. Applying Lemma 2.2 yields (3.16).
Similarly, when the smallest and largest values of credibility premium are and respectively. Applying Lemma 2.2 results in (3.17).
Finally, when the smallest and largest values of credibility premium are and Applying Lemma 2.2 yields (3.18).
With (3.16), (3.17) and (3.18), the corresponding AI values can be calculated straightforwardly. For example, we have
\scriptsize{ \begin{aligned} & A I\left(\tilde{P}_C\left(\mathbf{x} ; F_{Z, \mu} ; 1\right) ; \lambda\right) \\ & =\frac{1}{2}\left(P_C^0\left(\mathbf{x} ; F_{Z, \mu} ; 1\right)+(1-\lambda) P_C^L\left(\mathbf{x} ; F_{Z, \mu} ; 1\right)+\lambda P_C^R\left(\mathbf{x} ; F_{Z, \mu} ; 1\right)\right) \\ & =\frac{1}{2}\left(Z_C^0 \bar{x}+\left(1-Z_C^0\right) \mu^0+(1-\lambda)\left(Z_C^R \bar{x}+\left(1-Z_C^R\right) \mu^L\right)+\lambda\left(Z_C^L \bar{x}+\left(1-Z_C^L\right) \mu^R\right)\right) \\ & =A I\left(\tilde{Z}_C, 1-\lambda\right) \bar{x}+\frac{1}{2}\left(\left(1-Z_C^0\right) \mu^0+(1-\lambda)\left(1-Z_C^R\right) \mu^L+\lambda\left(1-Z_C^L\right) \mu^R\right) \end{aligned} }
which is the first line of equation(3.19). The other two lines are obtained similarly.
Remark 3.3. It can be seen from equations (3.16), (3.17) and (3.18) that, in all cases, the lower bound of the fuzzy premium is weighted average of and the core is weighted average of and and the upper bound is weighted average of and However, the credibility assigned depends on the value of loss experience relative to the assumed values of and Specifically,
-
When minimal weight, is assigned to in determining the lower bound This is reasonable because seems to indicate that the assumed value of could be too large and not credible.
On the other hand, when maximal weight is assigned to in determining the lower bounds and This is reasonable because the fact that indicates that the assumed value of is credible.
-
When the assumed value of is credible, so maximal weight is assigned to it when determining the upper bound of the fuzzy premium and
When the assumed value of is not credible, so minimal weight is assigned to it in determining .
Remark 3.4. The lower and upper bounds on the fuzzy credibility premium given in (3.16), (3.17), and (3.18) in fact agree with the lower bound and upper bound derived in Hong and Martin (2021). Our results complement theirs by providing meaning to them. Particularly, our results reveal that the bounds are actually weighted average of the loss experience and the bounds of the prior assumption of The weights (credibility) assigned depend on the relative size of and
In addition, Hong and Martin (2021) suggested that one could just report the lower and upper bounds of the credibility and disclose the parameter uncertainty involved. Here, we propose to report the fuzzy premium, which provides information about the range of the premium level as well as the corresponding membership function. Further, if a crisp premium number is desired, we propose to use the AI of the fuzzy credibility, which summaries information about the core and the boundaries of the fuzzy premium, as well as the uncertainty aversion level of the decision maker.
Remark 3.5. In Proposition 3.3 for fuzzy Bühlmann credibility, the parameters and are independently chosen. On the contrary, for the fuzzy Bayesian credibility in proposition 3.1, both and are determined by the assumption of EDF risk model and the parameters and of the conjugate prior. In this sense, the fuzzy Bühlmann credibility formulae are less sensitive to model uncertainty than the Bayesian premium ones.
4. Numerical Examples
In this section, we provide examples to illustrate the results in Section 3.
4.1. A hypothetical example
As in Gómez-Déniz (2009), assume that follows a Poisson distribution with mean and follows a gamma distribution with parameters and which has p.d.f. The Bayesian net premium under this model is given by (see, for example, Heilmann (1989))
P_{B}(\pi_\mathbf{x})=\frac{a+n\bar{x}}{b+n}=Z_B\bar{x}+\left(1-Z_B\right)\mu_B\,,
where
Z_B=\frac{n}{b+n} \ \ \text{and} \ \ \mu_B=\frac{a}{b}\,.
Assume that and Then applying equation (3.2) gives
\small{\begin{aligned} P_{B}(\pi_\mathbf{x})_{\alpha}=\left[\frac{\underline{a}(\alpha)+n \bar{x}}{\overline{b}(\alpha)+n},\, \frac{\overline{a}(\alpha)+n \bar{x}}{\underline{b}(\alpha)+n\tau}\right], \quad 0\le \alpha \le 1\,, \end{aligned}\tag{4.1}}
which can be computed easily.
Explicit expressions for the membership function of can be obtained by approximating it with a TFN. Since
\tilde{Z}_B=\frac{n}{\tilde{b}+n}\approx TFN\left(\frac{1}{2},\,\frac{5}{8},\,\frac{5}{7}\right)\tag{4.2}
and
\tilde{\mu}_B=\frac{\tilde{a}}{\tilde{b}}\approx TFN(1,\,3,\,5)\,,
applying Proposition 3.1 yields
\small{ \tilde{P}_B(\pi_\mathbf{x}, F)=TFN \left(\frac{1}{2}\bar{x}+\frac{1}{2},\, \frac{5}{8}\bar{x}+\frac{9}{8},\,\frac{5}{7}\bar{x}+\frac{10}{7}\right),\tag{4.3}}
with which the corresponding AI value can be calculated as
\begin{align} AI\left(\tilde{P}_{B}(\pi_\mathbf{x};F);\lambda\right) &= \frac{1}{2} \left[\frac{5}{8}+\frac{1}{2}(1-\lambda)+\frac{5}{7}\lambda\right]\bar{x}\\ &\quad + \frac{1}{2} \left[\frac{9}{8}+\frac{1}{2}(1-\lambda)+\frac{10}{7}\lambda\right]. \end{align}
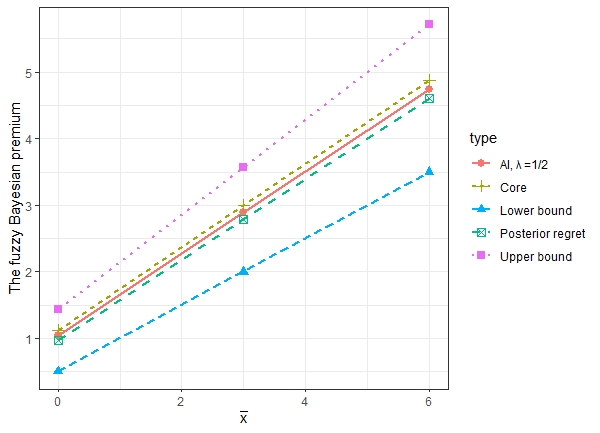
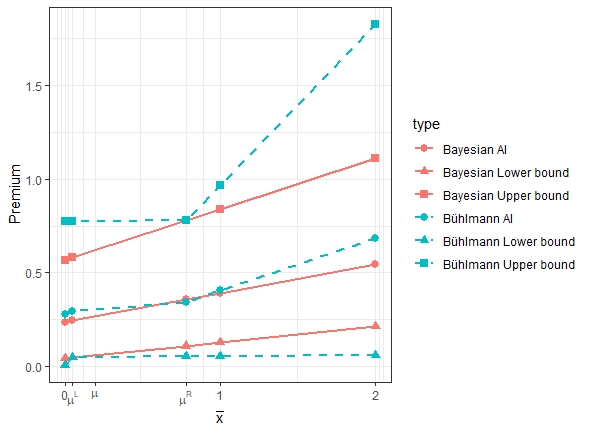
Figure 1 shows the bounds of the fuzzy Bayesian net premium obtained by (4.3) as well as the corresponding AI values with For comparison, we also display the posterior regret -minimax premium proposed in Gómez-Déniz (2009), which is just the average of the upper and lower bounds.
Next, we consider the fuzzy Bühlmann credibility. According to equation (2.9),
\tilde{\mu}=\tilde{v}=\frac{\tilde{a}}{\tilde{b}}\ \ \text{and} \ \ \tilde{w}=\frac{\tilde{a}}{\tilde{b}^2}\,.
With our assumed values of and we have
\begin{align} \tilde{\mu}&\approx TFN(1, 3, 5)\,, \\ \tilde{v}&\approx TFN(1, 3, 5) \ \ \text{and } \\ \tilde{w}&\approx TFN(0.2, 1, 2.5)\,. \end{align}
Applying equation (3.6) gives the -cuts of
\scriptsize{\begin{aligned} P_{C}(\mathbf{x})_{\alpha}&=\left[min\{c_{1\alpha},c_{2\alpha},c_{3\alpha},c_{4\alpha}\}, max\{c_{1\alpha},c_{2\alpha},c_{3\alpha},c_{4\alpha}\}\right], \\ 0&\le \alpha \le 1\,, \end{aligned}\tag{4.4}}
where are given in equations (3.7) to (3.10). They can be computed straightforwardly.
The fuzzy credibility premium can be obtained by applying Proposition 3.3. In particular, we have
\begin{aligned} &\tilde{k}=\frac{\tilde{v }}{\tilde{w}}\approx TFN(0.4,\, 3,\, 25)\,,\\ &\tilde{Z}_C=\frac{n}{\tilde{k}+n}\approx TFN\left(\frac{1}{6},\, \frac{5}{8},\, \frac{25}{27}\right). \end{aligned}
Note that has a much wider span than in (4.2). This makes intuitive sense because determining required the distributional information for the model and the prior, whereas only requires moment information.
Applying Proposition 3.3, we obtain the fuzzy Bühlmann credibility premium
\scriptsize{ \begin{aligned} \tilde{P}_{C}(\mathbf{x};F_{Z,\mu}) =\begin{cases} \left(\displaystyle{\frac{25}{27}\bar{x}+\frac{2}{27},\, \frac{5}{8}\bar{x}+\frac{9}{8},\, \frac{1}{6}\bar{x}+\frac{25}{6}}\right), & \bar{x}<1 \\ \left(\displaystyle{\frac{1}{6}\bar{x}+\frac{5}{6},\, \frac{5}{8}\bar{x}+\frac{9}{8},\, \frac{1}{6}\bar{x}+\frac{25}{6}}\right), & 1<\bar{x}<5 \\ \left(\displaystyle{\frac{1}{6}\bar{x}+\frac{5}{6},\, \frac{5}{8}\bar{x}+\frac{9}{8},\, \frac{25}{27}\bar{x}+\frac{10}{27}}\right), & \bar{x}>5 \end{cases}. \end{aligned} \tag{4.5} }
Then the AI of the fuzzy premium can be computed easily.
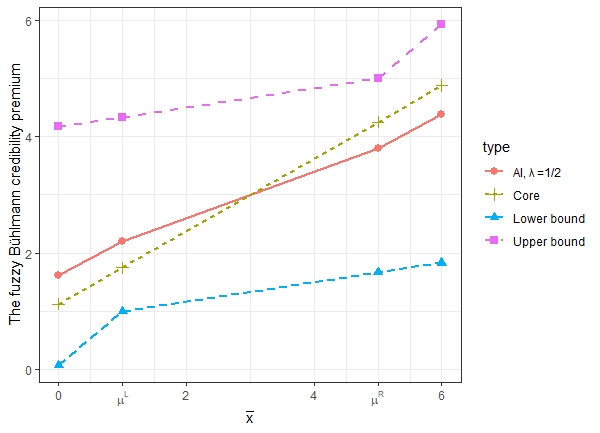
Figure 2 shows the AI of the fuzzy Bühlmann credibility for as well as the core, lower and upper bounds of the credibility calculated using equations (3.16), (3.17) and (3.18). As discussed in Remark 3.4 , the bounds actually coincide with those derived in Hong and Martin (2021).
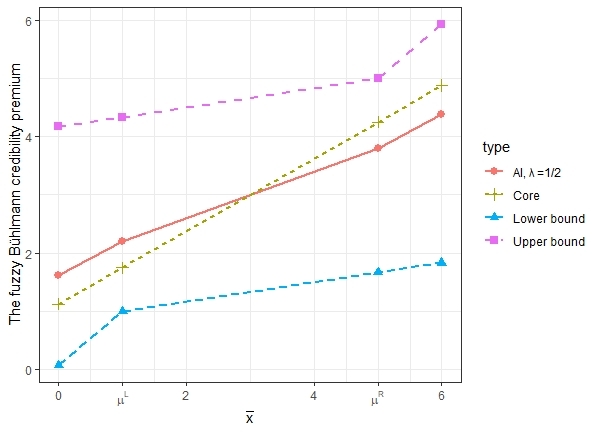
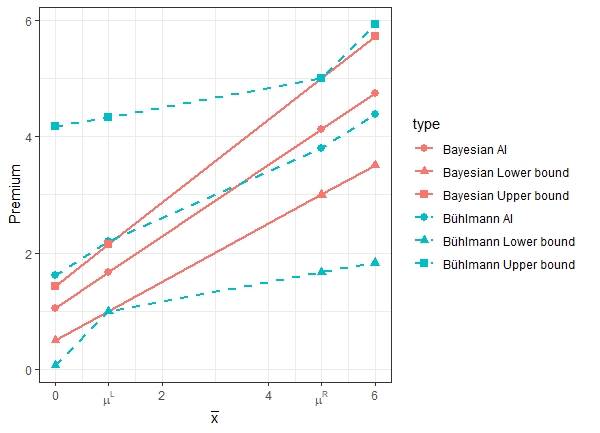
Figure 3 shows the bounds of the fuzzy Bayesian premium and the fuzzy Bühlmann credibility premium, as well as the premium levels with =1/2. We notice that the spread of the bounds of the fuzzy Bühlmann credibility premium are much wider than that of the fuzzy Bayesian. However, the premiums determined by AI with =1/2 are comparable.

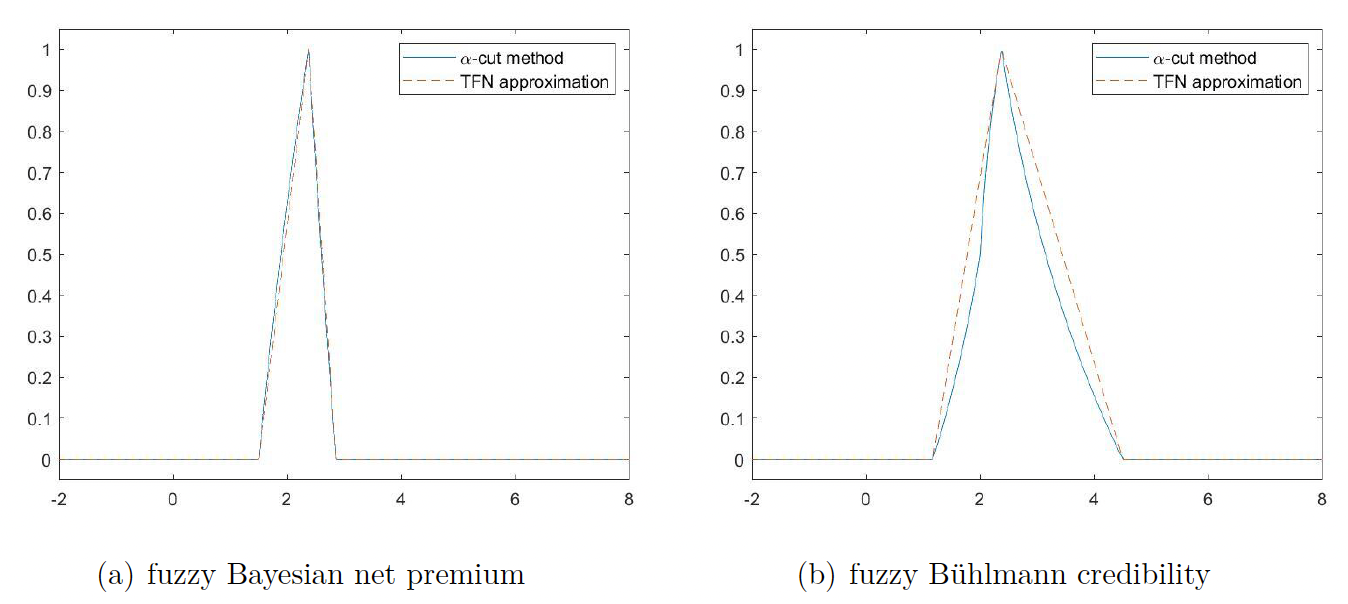
To evaluate the accuracy of the TFN approximation, we set and and compute the fuzzy Bayesian and Bühlmann credibility premium using the -cut methods by applying equations (4.1) and (4.4) and compare them with the TFN approximation in (4.3) and (4.5). The results in Figure 4 illustrate that the approximation methods provide quite reasonable results.

4.2. Real data example 1
Consider the automobile insurance claim number data in Example 18.6 of Klugman, Panjer, and Willmot (2019), which includes loss experiences of 1875 policyholders over one year. The data is included in Table 1. Our goal is to use the data to estimate the parameter value of the fuzzy numbers used in fuzzy Bayesian and fuzzy credibility premium, and then use them to predict the policyholders’ expected number of losses next year.
Let’s first consider the fuzzy Bayesian credibility method. Assume that conditional on an individual’s risk parameter the number of losses in a year follows a Poisson distribution with mean Assume that follows a Gamma distribution with p.d.f. However, the values of and are not known with certainty and represented by TFNs and respectively.
Following Buckley and Qu (2005), we could elicit the membership function of and by making use of the confidence intervals of and For example, we can use
\small{ \tilde{a}=\operatorname{TFN}\left(\hat{a}-z_{(1-\alpha / 2)} S E(\hat{a}), \hat{a}, \hat{a}+z_{(1-\alpha / 2)} S E(\hat{a})\right) \tag{4.6}}
and
\small{ \tilde{b}=T F N\left(\hat{b}-z_{(1-\alpha / 2)} S E(\hat{b}), \hat{b}, \hat{b}+z_{(1-\alpha / 2)} S E(\hat{b})\right) \tag{4.7}}
where and are point estimates of and is a small probability level, such as or and is the th quantile of a standard normal distribution.
For this Poisson-Gamma model, it is well known that follows a Negative Binomial distribution with probability mass function (p.m.f.)
\small{\begin{aligned} P(X=k)=\begin{pmatrix} k+a-1 \\ a-1\end{pmatrix}\left(\frac{1}{b+1}\right)^k \left(\frac{b}{b+1}\right)^a , \ \ k=0, 1, 2 \ldots \end{aligned}}
Then the log-likelihood function for the observations is simply
\begin{align} l(a, b)&= \sum_{i=1}^n \log (\Gamma(x_i+a))-\sum_{i=1}^n \log(\Gamma(x_i+1))\\ &\quad-n \log(\Gamma(a))+\sum_{i=1}^n x_i \log\left(\frac{1}{b+1}\right)\\ &\quad+na \log\left(\frac{b}{b+1}\right)\,. \end{align}
Therefore, the values of and can be estimated by MLE method. Using the R software package “maxLik” (Henningsen and Toomet 2010), we obtain and with the corresponding standard errors and
Applying (4.6) and (4.7) with we have
\tilde{a}=TFN(0.5229,\, 1.3096 ,\, 2.0963)\,,
and
\tilde{b}=TFN(2.6872,\, 6.7462,\, 10.8051)\,.
Consequently,
\tilde{Z}_B=\frac{n}{\tilde{b}+n}\approx TFN(0.0847,\,0.1291,\,0.2712)\,,
and
\tilde{\mu}_B=\frac{\tilde{a}}{\tilde{b}}\approx TFN(0.0484,\,0.1941,\,0.7801)\,.
Then the fuzzy Bayesian premium can be calculated by applying Proposition 3.1.
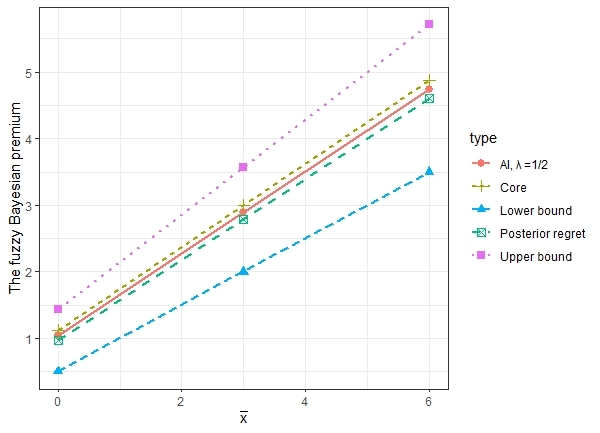
Table 2 reports the calculated fuzzy Bayesian premium and the corresponding AI values. Note that the classical Bayesian premium is given by the core of the fuzzy Bayesian premium and the imprecise credibility premium proposed by Hong and Martin (2021) is given by the bounds. For comparison, we also report the posterior regret -minimax premium proposed in Gómez-Déniz (2009), which is simply the average of two bounds.
Now, we consider the fuzzy Bühlmann credibility. Since we only have loss data for one time period, pure non-parametric empirical Bayesian method cannot be applied to estimate parameters and for Bühlmann credibility premium computation. Here, to illustrate our methodology, we simply utilize the estimated and above to infer the values of and In this case, we have
\tilde{\mu}=\tilde{v}=\frac{\tilde{a}}{\tilde{b}}\approx TFN(0.0484,\, 0.1941,\, 0.7801)\,, and \tilde{w}=\frac{\tilde{a}}{\tilde{b}^2}\approx TFN(0.0045,\, 0.0288,\, 0.2903)\,.
Consequently,
\tilde{k}=\frac{\tilde{v}}{\tilde{w}}\approx TFN(0.1667,\, 6.7462,\, 174.1691)\,,
\tilde{Z}_C= \frac{1}{1+\tilde{k}}\approx TFN(0.0057,\, 0.1291,\, 0.8571)\,,
and the fuzzy Bühlmann credibility premium can be calculated by applying Proposition 3.2.
The fuzzy Bühlmann credibility, the corresponding AI values, as well as the posterior regret -minimax premium are provided in Table 3. Again, the traditional Bühlmann credibility premium is given by the core of the fuzzy Bühlmann credibility, the imprecise credibility premium studied in Hong and Martin (2021) corresponds to the bounds and the average of the bounds gives the posterior regret -minimax premium.
Figure 5 compares the fuzzy Bayesian premium and the fuzzy Bühlmann credibility premium. We observe that the fuzzy Bühlmann credibility has a much wider range than the fuzzy Baysian premium. This can be explained by the fact that the assumptions of Bühlmann credibility method are less restrictive than Bayesian credibility method, thus can encompass more model uncertainty.

We can also observe that, for the fuzzy Bühlmann credibility method we proposed, the credibility assigned to loss data may change based on the value of average loss experience and the prior assumed bounds For example, may indicate that the prior upper bound for is too small and not credible, thus, in determining the upper bound of the fuzzy premium, less weight is given to the prior bounds and more go to the loss experience. This explains the steeper slope of the upper bound of the Bühlmann credibility premium when
4.3. Real data example 2
In this section, we consider a workers’ compensation insurance dataset that originated from the National Council on Compensation Insurance. The dataset includes loss experiences for occupation classes over 7 years. It was examined in Klugman (1992) using Bayesian credibility and analyzed in Frees, Young, and Luo (2001) using panel data regression models. Here we apply Bühlmann-Straub credibility method (eg. Klugman, Panjer, and Willmot 2019) to predict the losses per dollar of PAYROLL (pure premium) for every occupational class. However, we assume that there are uncertainties about the estimated parameters. Therefore, we provide the pure premium using fuzzy Bühlmann credibility theory developed in Section 3.2.
Assume that occupation class is observed for years and the loss exposure (PAYROLL) of class in year is denoted by Then the total loss exposure for group over all years is given by m_i=\sum_{j=1}^{n_i} m_{ij}\,, and the total exposure for all occupation classes and over all years is m=\sum_{i=1}^{r} m_{i}\,. Let the experienced loss per exposure for group in year be denoted by then its average loss per exposure over all years is \bar{x}_i=\frac{\sum_{j=1}^{n_i}m_{ij}x_{ij}}{m_i}\,, and the average over all classes and year is \bar{x}=\frac{\sum_{i=1}^{j}m_{i}\bar{x}_{i}}{m}\,.
Applying the Bühlmann-Straub credibility formulas (see for example, Klugman, Panjer, and Willmot 2019), the predicted loss per exposure (pure premium) of class is given by \hat{P}_i=\hat{Z}_i \bar{x}_i+(1-\hat{Z}_i)\hat{\mu}\,, where \hat{Z}_i= \frac{m_i}{m_i+\hat{k}}\,, and \hat{\mu}=\frac{\sum_{i=1}^r \sum_{j=1}^{n_i} m_{ij}x_{ij}}{m}, \hat{v}=\frac{\sum_{i=1}^r \sum_{j=1}^{n_i} m_{ij}(x_{ij}-\bar{x}_i)^2}{\sum_{i=1}^r(n_i-1)}, and \hat{w}=\frac{\sum_{i=1}^r m_i(\bar{x}_i-\bar{x})^2-\hat{v}(r-1)}{m-m^{-1}\sum_{i=1}^rm_i^2}. For the dataset, with PAYROLL in millions, we obtain and
Now, we suppose that there is uncertainty/ambiguity about these parameter values and that different actuaries have different expert opinions about these values. In this case, we can consider a fuzzy Bühlmann credibility solution.
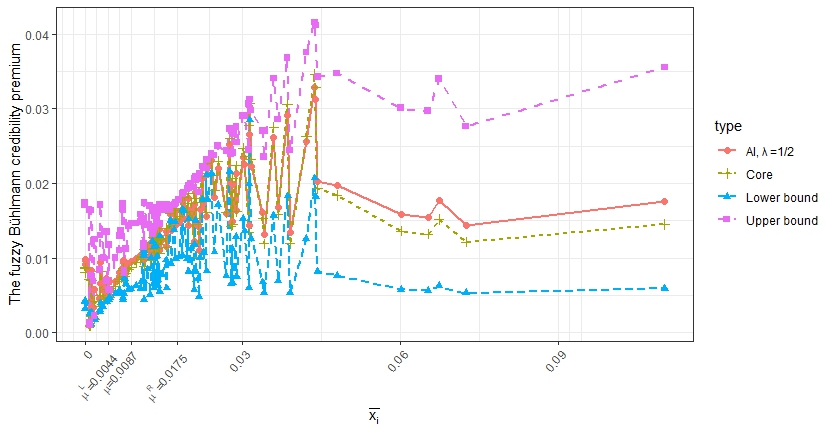
For instance, we may suppose that the credibility parameters are TFNs and with cores and respectively. For their bounds, we applied a method introduced in Hong and Martin (2020), which assumed that the parameter’s fuzzy upper bound is given by multiplying the core value by a so-called imprecision factor and the lower bound by dividing the core value by
For illustration, we arbitrarily choose and obtain
\begin{aligned} \tilde{\mu}=TFN(\phi^{-1}\hat{\mu}, \,\hat{\mu},\, \phi\hat{\mu})=TFN(0.0044,\, 0.0087,\, 0.0175)\,, \end{aligned}
\tilde{v}=TFN(\phi^{-1}\hat{v}, \,\hat{v},\, \phi\hat{v})=TFN(0.0038,\, 0.0076,\, 0.0151)\,,
and
\begin{align} \tilde{w}&=TFN(\phi^{-1}\hat{w}, \,\hat{w},\, \phi\hat{w})\\ &=TFN(0.000035,\, 0.000078,\, 0.000151)\,. \end{align}
Consequently,
\begin{align} \tilde{k}&=\frac{\tilde{v}}{\tilde{w}}\approx TFN(24.1406,\, 96.5623,\, 386.2494)\,, \end{align}
\tilde{Z}_i= \frac{m_i}{m_i+\tilde{k}}\,,
and the fuzzy Bühlmann credibility premium can be calculated by applying the results in Proposition 3.3.
We emphasize that the triangular fuzzy membership and the bounds values are arbitrarily selected here for illustration purposes. In practice, they could be decided considering the weights that are assigned to different opinions.
To illustrate the results, we calculate the fuzzy credibility pure premium for all occupational classes. The results are shown in Figure 6.
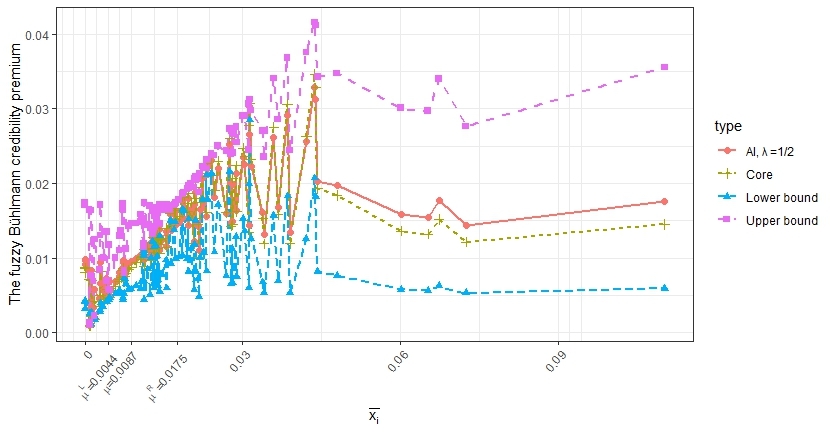
Since different occupational classes have different exposures, it becomes difficult to generalize the relationship between loss experience and the predicted pure premium. However, one may conclude that two situations can contribute to larger distances between the upper and lower bounds: (1) when the loss exposure is small, which indicates that the loss experience is not credible; and (2) when the loss experiences are outside the range of hypothetical mean or which cast doubts on the hypothetical mean.
In addition, recall that the traditional Bühlmann credibility premium is given by the core. The reported AI values are based on the arbitrarily chosen value of In practice, the values can be adjusted according to the user’s preferences, as discussed after Definition 2.7.
5. Conclusions
Fuzzy set theory aims at modeling imprecise, incomplete or vague information and/or subjectivity in decision making in a formal and mathematically rigorous way. As pointed out in Shapiro (2004), fuzzy set theory have been applied in many insurance areas. In this paper, we propose to apply the theory to study the actuarial credibility theory when there are uncertainty about the loss model or the prior distribution of risk parameters. Both Bayesian and Bühlmann credibility methods are considered. Our results generalize those in Gómez-Déniz (2009), which applied posterior regret -minimax principle, and those in Hong and Martin (2021), which applied imprecise probability method. We note that Koissi and Shapiro (2012) discussed the concept of credibility of a fuzzy set, which is based on the possibility and necessity measure of fuzzy sets (Liu 2007). This concept is different from the actuarial credibility theory. However, as noted in Koissi and Shapiro (2012), there are connections, and the former could find applications in solving actuarial problems. This could be a future research topic.
Acknowledgment
The second author of the paper gratefully acknowledges the financial support of the Natural Sciences and Engineering Research Council (NSERC) of Canada, grant number RGPIN-2019-06561.