
1. Introduction
Recent years have seen development in individual claim reserving techniques that model the actual claims process instead of using aggregated triangle data. Actuaries can use such models to generate point estimates for reserves or to incorporate simulation to develop a distribution of unpaid claim estimates. This paper develops a way to calculate policy-level unreported frequency distributions for use in such models. Those distributions can be used to simulate unreported claim counts at a policy level. The actuary can employ this method, combined with a close-with-pay probability model and a severity distribution, to simulate the pure incurred but not reported (IBNR) component of reserves.
Many existing methods for estimating unreported claim counts rely on applying development factors to reported claim counts. Those development factors can be calculated using chain-ladder techniques or using a report lag distribution. Such methods are relatively simple to implement, but they give no information on the variability around the estimate. In contrast, the method described herein has the following desirable characteristics at the cost of requiring more granular claim- and policy-level data:
-
There is no need to develop the claim count data to ultimate.
-
Developing claim count data is difficult (especially for policy-level data).
-
Developing claim count data can mask some of the variability in the frequency distribution.
-
-
An unreported frequency distribution for each individual policy is created.
-
Unlike aggregate distributions, this method controls for uneven policy writings throughout a year (e.g., due to growing or shrinking).
-
This also means that the output of this model is frequency at an individual policy level. This can feed other models that simulate closed-with-pay counts or severity and need policy characteristics.
-
-
A Markov chain Monte Carlo (MCMC) process can be set up to incorporate parameter risk into the unreported claims simulation.
- This allows the model to produce a full range of potential future payments, which is useful for developing confidence intervals or coefficient-of-variation estimates for reserves.
1.1. Note on Frequency Distribution Selections
Throughout the paper, we show results assuming that the ultimate frequency follows either a Poisson distribution or a negative binomial distribution. We show the Poisson case first because the derivations are simpler and usually easier to follow. However, the negative binomial distribution will likely be a better candidate for many lines of business.
The memoryless property of the Poisson distribution implies that the number of unreported claims for a policy is independent of claims that have been reported to date. In contrast, a negative binomial frequency distribution implies that a positive correlation exists between claims that have been reported to date and the number of unreported claims. This may be a more realistic assumption for many lines of business. We discuss this further in Section 5.
1.2. Close-with-Pay Probability and Pure IBNR Severity Models
In Section 6 we discuss a technique for simulating pure IBNR that requires a close-with-pay probability model and a pure IBNR severity model. A full discussion of these topics is outside the scope of this paper. Section 3.2 of Korn (2016) provides a framework the reader can use to model close-with-pay probability. In addition, the reader can turn to a number of sources to learn more about pure IBNR severity models. Goldburd et al. (2019) discusses fitting generalized linear models to insurance data, which can be useful in severity modeling. Meyers (2005) provides a framework by which to use Bayesian models to fit severity distributions by report lag. That author also discusses how to use Bayesian methodology to help mitigate both parameter and model uncertainty. McNulty (2017) provides examples of how mean loss amounts tend to shift with age and provides one model that attempts to address this. That author also provides a short survey of other approaches.
1.3. Outline
In Section 2 we discuss how to fit an ultimate frequency distribution to undeveloped policy-level claim count data based on the simplifying assumption that all policies have the same expected frequency. Section 3 modifies the method discussed in Section 2 to allow for the expected frequency of each policy to be proportional to some frequency exposure. In Section 4, we discuss why a report lag distribution is necessary to accurately model frequency and how to develop such a distribution. Section 5 shows how to transform the ultimate frequency distribution discussed in Sections 2 and 3 into an unreported frequency distribution for each policy. In Section 6, we explain how to use the unreported frequency distributions to help simulate pure IBNR dollars and discuss the Excel companion file that accompanies this paper. Section 7 develops methods that the actuary can use to evaluate how well the ultimate frequency distribution fits the data, and Section 8 discusses how to build an MCMC process to incorporate parameter risk. In the appendices we provide derivations of some of the important formulas as well as a summary of the notation we use in the paper.
2. Fitting a Frequency Distribution on Undeveloped Data
When modeling policy-level frequency, it is common to assume that ultimate claim counts for each policy follow some discrete parametric distribution (Poisson, negative binomial, etc.). Ideally, we would have a fully developed policy-level claim count data set with which to fit this distribution. However, in practice, data are available only as of some evaluation date and are therefore undeveloped. Using older, more developed policy years can sidestep this issue but may lead to results that are not relevant to newer and future policy years. Another method is to develop frequency data to ultimate before fitting the distribution, but that is challenging at a policy level and the uncertainty around development is lost. In this section, we discuss a method by which we can fit frequency distributions directly on undeveloped data.
2.1. Poisson Frequency on an Individual Policy
Let’s look at a single recently expired policy, policy evaluated at time At some future point, every claim on policy will be reported, but at evaluation time only a fraction of claims have been reported. The claims reported to date, then, can be thought of as a compounding of two distributions. Let
N=the ultimate number of claims on policy A;X=the number of claims reported by evaluation time T on policy A; andq=the probability that a claim on policy A is reported by evaluation time T.
If and are known, follows a binomial distribution with parameters and The rest of this section will show that if follows a Poisson or negative binomial distribution, it follows that the unconditional distribution of is the same distribution as with modified parameters.
Note that in this section the value of is assumed to be known. We can estimate this value using a report lag distribution, which we discuss in Section 4.
We start by looking at the case where is assumed to follow a Poisson distribution. Assume that follows a Poisson distribution with mean This implies that
N∼Poisson(λ), andX|N∼Binomial(N,q).
Since is unknown, the conditional distribution of is not particularly useful. However, it can be shown that this relationship between and implies that
X∼Poisson(λ∗q) (Appendix A).
This fact will allow the parameter of the ultimate frequency distribution to be estimated using undeveloped claim count data.
2.2. Applying Poisson Frequency to Multiple Policies
Now this logic can be expanded to multiple policies in a data set. Assume that a data set contains policy-level claim count data for policies For each policy, the ultimate number of claim counts are represented by Assume that, for each policy there is a known value that represents the probability that a claim that occurred during the policy period would have been reported by the evaluation date. Now let be the claims that have been reported for each policy as of the evaluation date. Assume that for in follows a Poisson distribution with mean Notice that
Ni∼Poisson(λ), andXi|Ni∼Binomial(Ni,qi).
It follows that
Xi∼Poisson(λ∗qi).
Since the and values are known, this allows a log-likelihood function to be derived for the parameter This log-likelihood function can be written as
LL(λ)=M∑i=1ln(fλ∗qi(Xi)),
where is the probability mass function (PMF) for a Poisson distribution with mean Using an optimization procedure on this equation, we can now calculate the maximum likelihood parameter estimate for This fitted Poisson distribution represents an estimate for the distribution of ultimate claim counts for a single policy.
2.3. Assuming a Negative Binomial Distribution
Next, we show how an ultimate claim count distribution can be estimated when frequency is assumed to follow a negative binomial distribution.
Assume now that the values in the policy-level data set discussed earlier follow a negative binomial distribution with common parameters and Then
Ni∼NegativeBinomial(k,p), andXi|Ni∼Binomial(Ni,qi).
It can be shown that
Xi∼NegativeBinomial(k,pp+qi−p∗qi) (Appendix A).
Similar to the Poisson case, this allows for the derivation of a log-likelihood function for the and parameters. This function can be written as
LL(k,p)=M∑i=1ln(gk,p/(p+qi−p∗qi)(Xi)),
where is the PMF for a negative binomial distribution with parameters and The MLE (maximum likelihood estimation) estimates of the and parameters can be calculated using an optimization procedure on
3. Adjusting for Nonhomogeneous Exposures
Notice that to derive the results in the previous section, we assumed that all policies in the data set share one common ultimate frequency distribution. That assumption is very strict and will likely not be reasonable when working with real-world data. An example of a violation of that assumption is when the data set contains policies that have been in force for different amounts of time. For instance, in general one would expect a two-year policy to have a higher frequency than a one-year policy.
To allow for different policies to have different expected frequencies we introduce the idea of a frequency exposure. A frequency exposure is defined such that the expected frequency for a policy is proportional to its frequency exposure. For example, if policy has a frequency exposure of 1 and policy has a frequency exposure of 2, the expected number of ultimate claim counts on policy would be twice that of policy One can base the frequency exposure on a wide range of policy characteristics such as earned premium, exposure period length, or attachment point.
Continuing with the data set from the previous section, we now loosen the assumption that follows the same frequency distribution for all values of We instead assume that each policy has a frequency exposure associated with it, denoted by that can be calculated based on policy-level characteristics.
Once the frequency exposure values are calculated for each policy in the data set, we can adjust the Poisson and negative binomial log-likelihood functions developed in Section 2 to incorporate the exposure differences. We can use the modified log-likelihood functions to fit a frequency distribution for a policy where
We start with the Poisson case:
Assume that the ultimate frequency for a policy that has a single unit of frequency exposure follows a Poisson distribution with mean
We first look at policies where These policies can be thought of as risks that had a full frequency exposure, but the policy covered only of this exposure. Let be the ultimate number of claims that occurred for this full frequency exposure. Notice, the probability that each of the claims was covered by the policy is equal to This implies that if were known, would follow a binomial distribution with parameters and Thus,
Bi∼Poisson(λ), andNi|Bi∼Binomial(Bi,Ei).
This implies
Ni∼Poisson(λ∗Ei).
Now we look at the case when Let be the ultimate number of claims that occurred for a single frequency exposure within the exposure. Notice, there is a chance that each of the claims occurred within this single frequency exposure. It follows that if were known, would follow a binomial distribution with parameters and So,
Oi|Ni∼Binomial(Ni,1/Ei).
Notice that is the ultimate claim count for a single frequency exposure. So,
Oi∼Poisson(λ).
This implies
Ni∼Poisson(λ∗Ei).
Notice that for both and
Ni∼Poisson(λ∗Ei).
Now recall from the previous section that
Xi|Ni∼Binomial(Ni,qi).
So,
Xi∼Poisson(λ∗Ei∗qi).
The log-likelihood function for can now be written as
LL(λ)=M∑i=1ln(fλ∗Ei∗qi(Xi)).
Now assume that the ultimate frequency distribution for a policy that has a single unit of frequency exposure follows a negative binomial distribution with parameters and Following the same process as the Poisson case, it can be shown that
Ni∼NegativeBinomial(k,pp+Ei−p∗Ei).
And since
Xi|Ni∼Binomial(Ni,qi),
this implies
Xi∼NegativeBinomial(k,pp+Ei∗qi−p∗Ei∗qi).
In this case, the log-likelihood for and can be written as
LL(k,p)=M∑i=1ln(gk,p/(p+Ei∗qi−p∗Ei∗qi)(Xi)).
3.1. Examples of Exposure Adjustments
In the remainder of the section, we discuss methods of calculating the frequency exposure for each policy based on some common assumptions.
Assumption 1: Frequency is proportional to the length of the exposure period.
Notice that if we assume frequency is proportional to the exposure period length, then can be set equal to where is the time in days the policy has been in force. In this case the frequency distribution represented by the fitted parameters would represent a policy that has been in force for 1 year
Assumption 2: Frequency is proportional to earned premium.
If we assume frequency is proportional to premium, then should be proportional to the premium on the policy. Let be some base-level premium and be the earned premium on policy If then this will assume frequency is proportional to premium and the parameters being fit would represent the frequency distribution for a policy were
Assumption 3: Frequency is dependent on the attachment point for a policy.
Sometimes frequency is assumed to differ for different attachment points. In general, frequency should decrease as the attachment point increases because it becomes less likely that a claim will breach the attachment. If a severity distribution is available, then this can be explicitly accounted for in the calculation of the frequency exposure. In this case, if is the attachment point on policy and is the survival function of the ground-up severity distribution, then This will reflect the fact that policies with higher attachments have lower frequencies. In this case the parameters being fit would represent the frequency distribution for a policy with no attachment since
Assumption 4: Frequency is subject to a policy year frequency trend.
If the policy year frequency trend is equal to then where is the policy year for policy and is the most recent policy year. The parameters being fit in this case would represent a policy that was written in the most recent policy year.
Assumption 5: Frequency is proportional to the length of the exposure period and dependent on the attachment point.
Many cases exist where we would expect frequency to be dependent on multiple factors simultaneously. Consider the case where frequency is proportional to exposure period length and is affected by attachment points. To adjust for this, we can simply combine the values calculated for Assumption 1 and Assumption 3. The appropriate frequency exposure in this case is In this case the parameters being fit would represent the frequency distribution for a 1-year policy with no attachment.
4. Calculating Using a Report Lag Distribution
Recall that in the previous sections, the probability that a claim that occurred during policy has been reported by the evaluation date, was assumed to be known for each policy in the data set. In this section, we discuss how to calculate such probabilities using a report lag distribution and how to fit that distribution.
The report lag of a claim is calculated by subtracting the occurrence date from the report date of the claim. If we know the report lag distribution, then we can calculate the probability that a claim that occurred days ago has been reported to date as where is the cumulative distribution function (CDF) for the report lag distribution.
If we assume that accidents occur uniformly throughout a policy period, then we can use this report lag distribution to calculate the probability that a claim that occurred during the policy period has been reported by the evaluation date. For a claim on policy let
V=length of the earned policy period=min(evaluation date, policy expiration date)−policy effective date;W=the occurrence date−the policy effective date;Y=the report lag for the claim = the report date−the occurrence date; andZ=the evaluation date−the policy effective date.
Notice that the probability that a claim occurring on policy A is reported by the evaluation date can be written as If we assume that claims occur uniformly throughout the policy period, then
W∼Uniform(0,V).
This implies
P(W+Y≤Z)=∫V0∫Z−W0r(y)∗1Vdydw,
where is the probability density function (PDF) for the report lag distribution.
Note that for many report lag distributions there is no closed-form solution for this double integral and it will need to be solved numerically. This probability will need to be calculated for every policy in the data set, so using numeric methods to solve for it can be cumbersome. Fortunately, if we make one additional simplifying assumption, the equation becomes much simpler to solve.
If we can instead assume that all claims on a policy occur at the midpoint of the policy period, then is no longer a random variable and can be set equal to [1] Now notice,
P(W+Y<Z)=P(Y<Z−W)=P(Y<Z−V2)=R(Z−V2).
We can use this report lag method to calculate the values that were assumed to be known in the previous sections. Let
Vi=length of the earned policy period for policy Ai, andZi=the evaluation date−the policy effective date for policy Ai.
Then
qi=R(Zi−Vi2).
4.1. Fitting a Report Lag Distribution
Now that we have established that a report lag distribution is sufficient to calculate the values, let’s discuss how to fit this distribution. This will require a claim-level data set with three fields: occurrence date, report date, and evaluation date.
For each claim in this data set, let
Yi=report lag, andGi=evaluation date−report date.
It may be tempting to simply fit a distribution to the values using standard MLE, but that method would be flawed. Fitting a distribution in such a way would assume that the data set is not subject to development, which is not the case. Since the data are available only as of the evaluation date, the data are right truncated. Specifically, the report lag of each claim in the data set is right truncated at To handle right truncation, the likelihood function for each observation must be divided by the CDF at the truncation point.[2] If there are claims in the claim-level data set, then the log-likelihood function for a specified report lag distribution is
N∑i=1ln(r(Yi)R(Gi)).
We can use this log-likelihood function to calculate the MLE parameters for any specified distribution. Common choices for this distribution include exponential, gamma, and Weibull.
4.2. Piecewise Report Lag Distributions
For many lines of business, the probability is high that a claim will be reported relatively quickly (within a month). Often, however, a significant probability exists that a claim will take much longer to report (a year or two). If that is the case, then the standard distributions mentioned in the previous section will not fit the data well. These distributions cannot have a high point mass at early periods while simultaneously having a reasonable probability that claims will take much longer to report.
A solution to this is to model the report lag as a piecewise distribution that gives some weight to a uniform distribution and some weight to a shifted version of one of the standard distributions mentioned earlier. We can use the uniform portion of the distribution to assign a high point mass to early periods. The shifted exponential/gamma/Weibull portion of this distribution can allow for the possibility that a claim takes much longer to report.
Below, we show the general PDF and CDF for these piecewise distributions. In these functions, and represent the PDF and CDF, respectively, for either an exponential, gamma, or Weibull distribution. Notice that these distributions require the selection of a value, that will dictate the range of the uniform distribution and the shift of the other selected distribution. Also, they require one additional parameter, to be fit that indicates the probability that an observation comes from the uniform portion of the distribution.
PDF:
r(t)={0t≤0w∗1s0<t≤s(1−w)∗h(t−s)t>s
CDF:
R(t)={0t≤0w∗ts0<t≤sw+(1−w)∗H(t−s)t>s
Notice that if is set to a relatively small value (around 1 month) and is sufficiently large, the uniform portion of the distribution allows there to be a high point mass at early periods. Simultaneously, the exponential/gamma/Weibull portion of the distribution allows for there to be a relatively high probability that claims will be reported at a much later date.
Figure 1 shows three examples of piecewise uniform-gamma distributions. The gamma portions of all three distributions are the same and The and parameters differ for each distribution to illustrate how modifying those parameters affects the shape of the CDF. The values for the and parameters appear at the top of the chart.
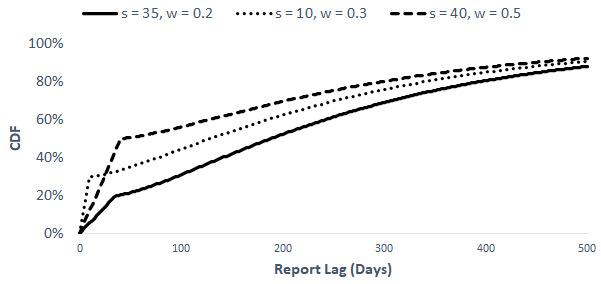
Notice that each of the CDFs begins with a steep line from to This represents the uniform portion of the distributions. After the initial steep increase, a noticeable kink appears in each of the curves and the CDFs begin to increase more gradually. This represents the distributions shifting from the uniform portion to the gamma portion.
When fitting the piecewise report lag distributions, one must use judgment to select the value of To aid in the selection process, we can compare fitted distributions based on different values. That comparison can be done by looking at the log-likelihood values and probability–probability (P-P) plots of the different fitted distributions.
Note that when looking at P-P plots for the report lag distributions, one needs to take into consideration the fact that the data are right truncated. To reflect the truncation, the predicted probabilities are set equal to
5. Developing an Unreported Claims Distribution
So far, we have developed a framework for calculating ultimate frequency distributions based on undeveloped claim count data. We now look at how those distributions can be modified to represent the frequency of unreported claims for each policy.
To illustrate how to develop the unreported frequency distributions, we return to the policy-level data set that we discussed in Section 2. For simplicity, the first part of this section assumes that all policies in the data set have homogeneous frequency exposures. The formulas will be generalized in Section 5.1 to allow for nonhomogeneous frequency exposures.
Recall that the method in Section 2 allowed us to fit a distribution to ultimate frequency for each policy. We now want to generate a distribution for the unreported frequency for each policy. We start by looking at the case where is assumed to follow a Poisson distribution.
Recall
Ni∼Poisson(λ), andXi|Ni∼Binomial(Ni,qi).
It can be shown that
Ni−Xi|Xi∼Poisson(λ∗(1−qi)) (Appendix B).
Now we look at the case where follows a negative binomial distribution. Recall
Ni∼NegativeBinomial(k,p), andXi|Ni∼Binomial(Ni,qi).
It can be shown that
Ni−Xi|Xi∼NegativeBinomial(k+Xi,p+qi−p∗qi) (Appendix B).
Since the values have already been observed, the parameters for the unreported frequency distributions can be directly calculated for both the Poisson and negative binomial cases.
Notice that the unreported frequency distributions differ for each policy based on the value of the parameter. As increases, the average unreported frequency implied by the distribution decreases. This makes intuitive sense because if is larger, we would expect a larger proportion of claims to already have been reported. This would imply that we would expect fewer claims to be reported in the future.
Also notice that in the Poisson case, is independent of but the same cannot be said for the negative binomial case. That is because the Poisson distribution is memoryless, so future frequency is assumed to be independent of the past. However, the negative binomial distribution is not memoryless, so reported frequency for each policy provides information about the unreported frequency. As increases, the expected unreported frequency increases.
5.1. Incorporating Nonhomogeneous Frequency Exposures
Recall that in Section 3 we generalized the ultimate frequency fit to allow for the possibility of nonhomogeneous frequency exposures. We can similarly generalize the calculations of the unreported frequency distribution parameters. We again start with the Poisson case.
Recall from Section 3 that
Ni∼Poisson(λ∗Ei),Xi|Ni∼Binomial(Ni,qi), andXi∼Poisson(λ∗Ei∗qi).
Now let
λi=λ∗Ei.
Then
Ni∼Poisson(λi), andXi∼Poisson(λi∗qi).
This implies that
Ni−Xi|Xi∼Poisson(λi∗(1−qi)).
Similarly, for the negative binomial case it can be shown that
Ni−Xi|Xi∼NegativeBinomial(k+Xi,pi+qi−pi∗qi),
where
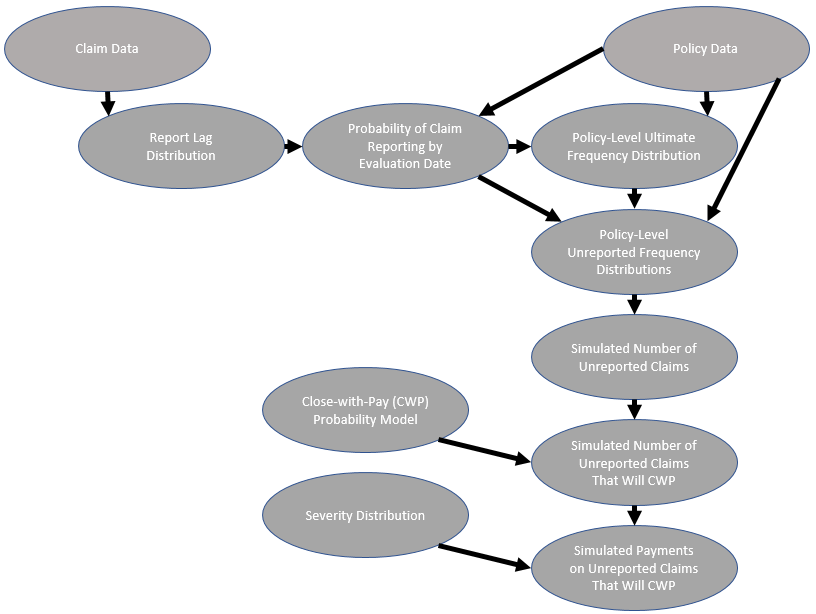
6. Summarizing the Process and Simulating Pure IBNR
So far, we have discussed the steps necessary to develop policy-level unreported frequency distributions for each policy for a given line of business. In this section, we summarize that process and explain how to use the distributions, in combination with a close-with-pay probability model and a severity distribution, to simulate pure IBNR dollars.
The following list outlines the steps necessary to use our frequency model to simulate pure IBNR loss dollars. Figure 2 shows a visual representation of this process.
-
The first step in the process is to gather the necessary claim- and policy-level data. Those data sets require the following fields:
-
Claim data fields: occurrence date, report date, evaluation date
-
Policy data fields: policy effective date, length of policy period, reported claim counts, evaluation date, frequency exposure
-
-
Next, we fit a report lag distribution based on the claim-level data using the process described in Section 4.
-
For each policy, the report lag distribution is then used to calculate the probability that a claim that occurred on the policy has been reported by the evaluation date.
-
We then use those probabilities, along with the policy-level data, to fit an ultimate frequency distribution for a policy with a frequency exposure of 1 using the process described in Sections 2 and 3.
-
With the method described in Section 5, we then estimate an unreported frequency distribution for each policy using the ultimate frequency distribution, the policy-level data, and the probabilities calculated from the report lag distribution.
-
Using the unreported frequency distributions, the number of unreported claims on each policy is then simulated.
-
Next, for each simulated claim, we calculate the probability that each claim will close with pay from the close-with-pay probability model.
-
Finally, for each claim that closes with payment, we can simulate the severity on the claim based on the severity distribution.

The simulation portion of the process can be done multiple times to generate a distribution around the pure IBNR estimates. Such simulations can be used to generate a point estimate for pure IBNR by taking the mean of the simulated values. It can also help in understanding the variability around pure IBNR by looking at the distribution of the simulations.
Note that it may be useful to include policy-level predictive variables in the close-with-pay probability model and the severity distribution model. If that is the case, then simulating unreported claims at an individual policy level is particularly useful. That allows each simulated claim to be tied to a specific policy, which means that these policy-level predictive variables can be used in the simulation process.
6.1. Excel Companion File Discussion
The Excel file that accompanies the paper provides a worked example for the process shown in Figure 2 using simulated claim- and policy-level data. The file assumes that the report lag follows a gamma distribution and that policy-level frequency is proportional to the length of the policy period. In the tabs labeled (Poisson), policy-level frequency is assumed to follow a Poisson distribution. In the tabs labeled (Negative Binomial), policy-level frequency is assumed to follow a negative binomial distribution. The following is a more detailed description of each of the tabs in the Excel file:
-
The CWP Prob & Severity Param tab provides inputs for the probability that a claim will close with payment and the lognormal severity distribution parameters for use in the pure IBNR simulation.
-
The Report Lag Fit tab fits a gamma report lag distribution to a claim-level data set. This is done by solving for the parameters in cells A7 and B7, which maximize the log-likelihood in cell A3 (this is done using the Excel solver tool).
-
The Freq Fit (Poisson) and Freq Fit (Negative Binomial) tabs show how the gamma report lag distribution, along with a policy-level data set, can be used to develop an unreported frequency distribution for each policy. The fitted parameters in cells A7 and B7 of these tabs are solved for by maximizing the log-likelihood in cell A3 (this is done using the Excel solver tool). The policy-level unreported frequency parameters are calculated in columns N and O.
-
The Simulation (Poisson) and Simulation (Negative Binomial) tabs show how the pure IBNR is simulated based on the policy-level unreported frequency distributions, the close-with-pay probability, and the severity distribution. The simulated pure IBNR counts and dollars appear in cells A4 and B4 of these tabs.
-
The Output (Poisson) and Output (Negative Binomial) tabs capture multiple iterations of the processes performed in the Simulation tabs. Columns D and E show the raw output from the simulations, the histograms in those tabs show the distributions implied by the simulations, and the table in cells H1:J4 provides some statistics from the simulations. The number of simulations can be modified by changing the value in cell A3 and pressing the button in cell A5. This runs a macro that copies cells A4:B4 from the Simulation tabs and pastes the result in columns D:E of this tab. For each simulation, the formulas are recalculated to get new random draws. Macros must be enabled in the Excel file for the simulation to work.
Note that the close-with-pay probability and the severity distribution used in this example are very simplistic. In practice, it may be more suitable to differ the close-with-pay probability and severity distribution based on report lag or some policy-level characteristics. It also may be necessary to take differing limits/attachments into account when simulating severity.
6.2. Simulating Pure IBNR Emergence in a Period
So far, we have discussed developing a model to simulate ultimate pure IBNR, but sometimes it is useful to model pure IBNR development over a finite period. For example, it may be beneficial to understand how much pure IBNR will emerge in the next 12 months.
If the goal is to model pure IBNR development over the next days, we need to modify the unreported frequency distributions to reflect only the emergence in that period.
For each policy let be the probability that an unreported claim will be reported in the next days. We can use the report lag distribution from Section 4 to estimate these values. Notice
ji=Prob(Claim Reports between Evaluation Date and Evaluation Date + L Given Claim Reports after Evaluation Date)=[R(time since midpoint of policy period+L)−R(time since midpoint of policy period)]÷[1−R(time since midpoint of policy period)]=R(Zi−Vi/2+L)−R(Zi−Vi/2)1−R(Zi−Vi/2).
Now let be the number of claims that will be reported in the next days for policy Notice that
Ui|Ni−Xi∼Binomial(Ni−Xi,ji).
This implies that when frequency is assumed to follow a Poisson distribution,
Ui|Xi∼Poisson(λi∗(1−qi)∗ji).
Similarly, when frequency is assumed to follow a negative binomial distribution,
Ui|Xi∼NegativeBinomial(k+Xi,pi+qi−pi∗qipi+qi−pi∗qi+ji−ji∗(pi+qi−pi∗qi)).
Using these formulas for we can now develop a process for modeling the pure IBNR emergence over the next days. The process will be identical to the process described to simulate ultimate IBNR dollars, except instead of using the distributions to simulate frequency, we will use the distributions. Note that the close-with-pay probability model and the severity distribution will also need to be modified to reflect the fact that we are modeling development only over the next days.
7. Diagnostic Check on the Frequency Fit
After fitting a frequency distribution using the methods described in this paper, we need to run diagnostic checks to assess the adequacy of the fit. If we were working with developed claim count data with homogeneous frequency exposures, we could calculate the probability of different frequencies implied by the fitted distribution and compare that with the observed frequencies in the data. However, in our data set, the reported frequency for each policy follows a different distribution based on the time since the average accident date and the frequency exposure, so this test will not work.
To get around this issue, we will use the average probability of observing a particular reported frequency. Let be the PMF for the reported frequency distribution for policy implied by the fitted frequency parameters. Recall that this PMF will differ for each policy based on the values of and The average probability of observing a reported frequency can be written as
¯b(w)=1mm∑i=1bxi(w).
We can compare this value to the actual percentage of policies that had a reported frequency of We denote this actual percentage as If there are cases where and differ significantly, then that would indicate a poor fit and the distribution should be reevaluated.
Note that in many cases frequency distributions have a high point mass at 0. This means that and may be very small for values above 0 and therefore hard to compare. It may be useful to instead look at the and conditional on being nonzero. This can be done by comparing and for values of greater than 0.
7.1. Historic Actual versus Expected Comparison
Recall that in Section 6.1, we developed a method for simulating the unreported claim counts that will emerge in a specified time period. We can use that method to retroactively test the performance of this unreported frequency model.
If the unreported frequency model described in this paper is fit on data that are evaluated as of 12 months ago, then one can use the method discussed in Section 6.1 to simulate the 12-month unreported claim count emergence. The actual claim count emergence can then be compared with these simulations. The further the observed emergence is from the mean of the simulations, the more likely it is that the parameters need to be revised. Note that this method is a good gut check to test model performance, but it should not be the only metric one uses to assess the model, as it relies on only one data point.
7.2. Other Diagnostic Checks
In Section 3 of a summary report, the Working Party on Quantifying Variability in Reserve Estimates (2005) lists several useful diagnostic tests. In the list that follows we present a few of the tests from that report as well as some examples of how one might apply them to the modeling framework we discuss in this paper:
-
The coefficient of variation should generally be larger for older policy years than for more recent policy years.
- Because our model produces pure IBNR at a policy level, the simulations can be aggregated by policy year. That allows the coefficient of variation to be calculated for each policy year separately to ensure that this relationship holds.
-
The standard error should be larger for all policy years combined than for any individual year.
- The policy-level output from our model allows the standard deviation to be calculated in aggregate and for each policy year to test whether this relationship holds.
-
Model parameters should be checked for consistency with actuarially informed common sense.
-
Oftentimes actuaries have an a priori expectation about how long it should take for claim counts to be fully reported. If that is the case, then the report lag distribution used in this model should be compared against that expectation. For example, if an actuary expects the vast majority of claims to be reported within 10 years, then the report lag distribution should indicate that the probability of a claim being reported after 10 years is relatively small.
-
In addition, an actuary may have an a priori expectation about the average number of claim counts per policy. The implied mean frequency per policy coming out of this model can be compared against that expectation.
-
8. Incorporating Parameter Variance with MCMC
Throughout this paper, we developed log-likelihood functions for the frequency and report lag fits. We can use those log-likelihood functions to generate the MLE parameters for the fits. However, if we are interested in using those distributions to get an estimate for the variability of unreported claim counts, then using the MLE parameters to simulate will not be sufficient. That is because relying solely on the MLE parameters will ignore parameter risk.
One way to incorporate parameter risk into the simulations is to use MCMC techniques. MCMC methods take in a log-likelihood function and a prior distribution for each parameter that needs to be estimated and produce a list of parameter estimates. The parameter estimates are chosen according to their likelihood, which is determined by the log-likelihood function and selected prior distributions.[3]
If we use an MCMC process to generate multiple parameter estimates, each simulation of unreported claim counts could be run using a different set of parameters. The distribution of unreported claims implied by those simulations would incorporate parameter risk as well as process risk.
Initially it would appear that if we wish to incorporate parameter risk for the report lag distribution and the frequency distribution, we could set up two MCMC processes (one for each distribution). However, that procedure would not appropriately reflect the parameter risk associated with the frequency distribution. Recall that the log-likelihood function for frequency is based on the values of for each policy, and is in turn based on the fitted report lag distribution. This implies that the log-likelihood function of the frequency distribution is affected by the selected parameters for the report lag distribution. This means that the parameter risk in the frequency distribution is affected by the parameter risk in the report lag distribution. One way to accurately account for this relationship is to create a single MCMC process that generates parameters for both distributions simultaneously. That will allow the log-likelihood function for the frequency distribution to be dependent on the selected parameters for the report lag distribution.
Of the many programs available to implement MCMC processes, we would recommend using Stan due to the seamless communication with R, the extensive documentation, and the efficient algorithm that is used. To learn more please refer to the documentation on Stan’s website: https://mc-stan.org/.
9. Conclusion
We present a method actuaries can use to predict unreported claim frequency at an individual policy level. It can be used in the estimation of pure IBNR and in the understanding of the variability around the pure IBNR estimate. It requires only some basic claim- and policy-level data and allows for frequency to be related to any policy characteristic through the frequency exposure component. This makes the model relatively simple to implement and flexible enough to adapt to different lines of business. This method of modeling unreported claim frequency can be a powerful tool for use in any reserving model that relies on individual claim- and policy-level data.
Addendum
In section 4 of our paper, formula 4.1 was derived which can be used to estimate the probability that a claim on policy has been reported by the evaluation date. Since publishing this paper, it has come to our attention that a similar formula was derived in section 4, formula 4.5 of Robbin (2004) and a similar idea was explored in Robbin (1988).
Also, it has come to our attention that there is a minor notational error in formula 4.1 of our paper. The W in the second integration limit was capitalized when it should have been lower case. The corrected formula is provided below:
P(W+Y≤Z)=∫V0∫Z−w0r(y)∗1Vdydw
References
Robbin, Ira. 2018. “The Average Maturity of Loss Approximation of Loss.” CAS E-Forum, Spring, vol. 2, 1-22.
Robbin, I. 2004. “Exposure Dependent Modeling of Percent of Ultimate Loss Development Curves.” Casualty Actuarial Society Forum.
Robbin, I. and Homer, D., 1988. “Analysis of Loss Development Patterns Using Infinitely Decomposable Percent of Ultimate Curves.” CAS Discussion Paper Program, May, 503-538.